企业数据,大语言模型和矢量数据库

随着ChatGPT的推出,通用人工智能的时代缓缓拉开序幕。我们第一次看到市场在追求人工智能开发者,而不是以往的开发者寻找市场。每一个企业都有大量的数据,私有的用户数据,自己积累的行业数据,产品数据,生产线数据,市场数据,等等一应俱全。这些数据都不在基础大语言模型的记忆里,如何有效的用起来是目前通用人工智能在企业端的重要课题。
我们可以将私有数据作为微调语料来让大语言模型记住新知识,这种方法虽然可以让大模型更贴近企业应用场景更高效使用私有数据,但往往难度较大,另外企业数据涵盖了文本,图像,视频,时序,知识库等模态,接入单纯的大语言模型学习效果较差。我们今天来聊聊另一种更常见的方案,通过矢量数据库提取相关数据,注入到用户prompt context(提示语境)里,给大语言模型提供充分的背景知识进行有效推理。【如图一所示】
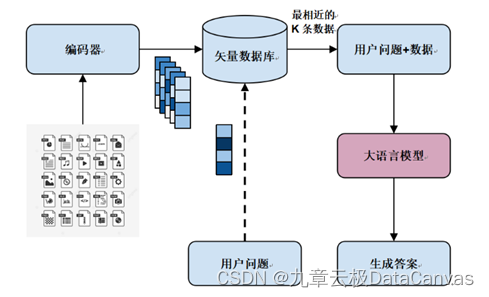
图一 基于数据提取的大语言模型应用架构
矢量数据库允许任何对象以矢量的形式表达成一组固定维度的数字,可以是一段技术文档,也可以是一幅产品配图。当用户的提示包含了相似语义的信息,我们就可以将提示编码成同样维度的矢量,通过矢量数据库查寻K-NearestNeighbor(近邻搜索)来获得相关的对象。Approximate NearestNeighbor(近似近邻搜索)作为矢量数据库的核心技术之一,在过去的十年里获得了长足进步。它可以通过损失一定的准确度在高维空间里快速搜索近邻矢量,比如NGT算法可以在接近一千维的矢量空间达到万次查询,而准确度不低于99%。如图二所示不同的算法展现了不同的妥协效果。
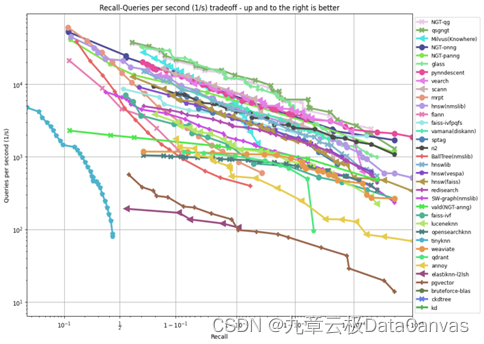
图二 查询QPS和返回准确度(召回)之间的妥协。数据集为fashion-mnist采用了784维矢量,
测试基于单个CPU的统一环境,测试时间为2023年四月。
这种语义搜索的方法起源于大语言模型时代之前,起初是为了降低企业搜索的工程复杂度,提升搜索结果的相关性,因为矢量本身和神经网络高度契合,也成为大语言模型应用的标准配置。甚至出现如Memorizing Transformer 和 KNN-LM这样的架构将近邻搜索算法和大语言模型结合来成功构造快速external memory(外部记忆)。
但是这样的架构依然存在一个重要的问题:从用户的提示生成矢量,通过近邻搜索找到有关数据,这两方面的矢量相似度高并不一定代表语义的相关性也高,因为两方的矢量可能并不在同一语义空间。如果企业数据的语义空间和大语言模型有比较大的区别,图一所示的架构就可能无法有效的关联重要数据而降低了可用性。这种语义空间差别在处理多模态数据时尤其明显,比如从文本到图像的对齐【如图三】,从文本到知识图谱的对齐【如图四】。同时,图像,视频,知识图谱,文档等等都蕴含大量的信息,压缩到单一矢量大大损失颗粒度,从而降低了近邻搜索的有效性。
如果将这些对象碎片化处理,再由大语言模型进行整合,除了复杂的碎片化工程,这种方法大大增加了提示语境的长度要求。尽管大量的研究工作已经从计算效率上解决了语境长度的瓶颈,比如Linear Transformer,Reformer,到最近的LongNet,理论上1B的Token已经是可行的,但实际的效果却显示当前的大语言模型并不能很好的利用长语境来获得相关信息【如图五】。归根结底将大量背景信息有效高效的投射到文本语义空间从而让后端的大语言模型可以更好发挥依然是目前应用开发的一大难点。
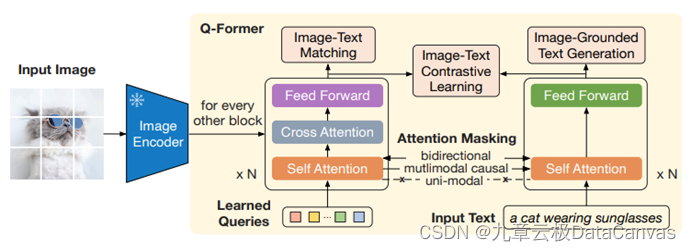
图三 图像文本通过交叉注意力机制对齐。借用BLIP2架构图
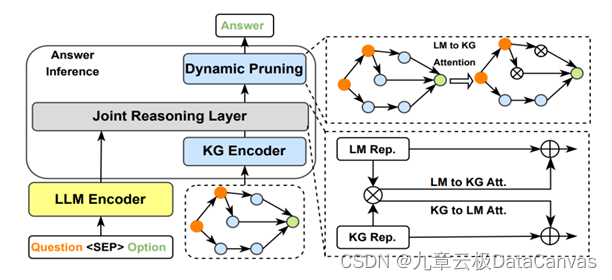
图四 知识图谱和文本通过交叉注意力机制对齐。借用动态知识图谱融合模型
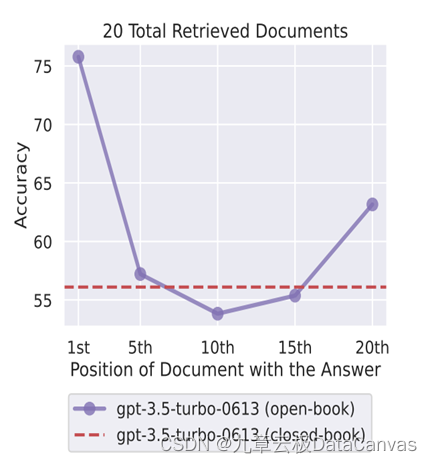
图五 相关的文档在提示语境中的位置会极大影响大语言模型的能力。来自于最近的研究
语义空间的投射可以看作是一个alignment(对齐)任务。在粗颗粒度上,单一矢量的空间对齐可以通过学习投射矩阵来实现【如图六所示】。这个投射空间小,可以用较少的标注数据训练,从而大大提升搜索结果的相关性,也已经成为业界广泛使用的技术。而细粒度的对齐工作依然是目前技术突破的焦点,从Perceiver IO,CLIP到BLIP2,我们也渐渐看到交叉注意力机制的通用对齐能力【如图三,四】,特别是大规模的无监督学习半监督学习大大提升了对齐的泛化能力。把这些对齐算法和矢量数据库结合起来提供快速高效的细粒度对齐将会极大提升大语言模型应用的用户体验,也是我们值得期待的方向。
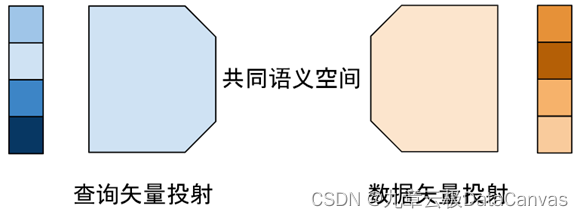
图六 粗粒度对齐
总体而言,通过矢量数据库将企业内部数据和大语言模型结合起来拥有广泛的应用场景,但技术挑战也仍然很大,我们今天讨论的这些技术点仅仅是诸多挑战中的一两个环节,还有很多没有触碰,后面有机会和大家继续探讨。
参考资料:
1.https://github.com/erikbern/ann-benchmarks
2.https://arxiv.org/pdf/1911.00172.pdf
3.https://arxiv.org/pdf/2203.08913.pdf
4.https://arxiv.org/pdf/2006.16236.pdf
5.https://arxiv.org/pdf/2001.04451.pdf
6.https://arxiv.org/pdf/2307.02486.pdf
7.https://arxiv.org/pdf/2301.12597.pdf
8.https://arxiv.org/pdf/2306.08302.pdf
9.https://arxiv.org/pdf/2307.03172.pdf
10.https://finetunerplus.jina.ai/
11.https://github.com/krasserm/perceiver-io
12.https://arxiv.org/pdf/2103.00020.pdf
13.https://arxiv.org/pdf/2301.12597.pdf
作者简介:
缪 旭 九章云极DataCanvas公司首席AI科学家
二十余年人工智能研究和管理经验,深耕人工智能的技术实现和应用,发表多篇学术文章,并拥有多项授权发明,专注将可推理可解释的人工智能、大模型、大规模实时机器学习、知识图谱等前沿AI技术加速应用于各行各业。
相关文章:
企业数据,大语言模型和矢量数据库
随着ChatGPT的推出,通用人工智能的时代缓缓拉开序幕。我们第一次看到市场在追求人工智能开发者,而不是以往的开发者寻找市场。每一个企业都有大量的数据,私有的用户数据,自己积累的行业数据,产品数据,生产线…...
LabVIEW使用支持向量机对脑磁共振成像进行图像分类
LabVIEW使用支持向量机对脑磁共振成像进行图像分类 医学成像是用于创建人体解剖学图像以进行临床研究、诊断和治疗的技术和过程。它现在是医疗技术发展最快的领域之一。通常用于获得医学图像的方式是X射线,计算机断层扫描(CT),磁…...
kafka面试题
kafka基本概念 Producer 生产者:负责将消息发送到 BrokerConsumer 消费者:从 Broker 接收消息Consumer Group 消费者组:由多个 Consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费&am…...
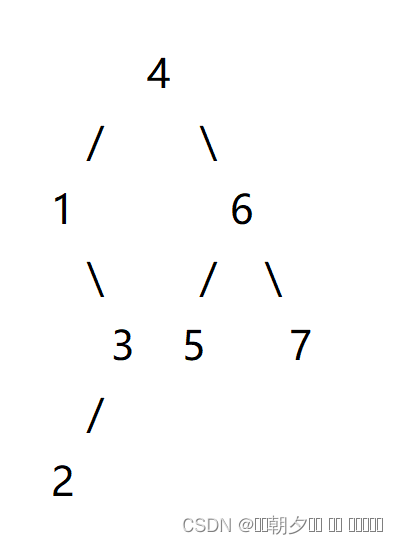
树的遍历(一题直接理解中序、后序、层序遍历,以及树的存储)
题目如下: 一个二叉树,树中每个节点的权值互不相同。 现在给出它的后序遍历和中序遍历,请你输出它的层序遍历。 输入格式 第一行包含整数 N,表示二叉树的节点数。 第二行包含 N 个整数,表示二叉树的后序遍历。 第…...
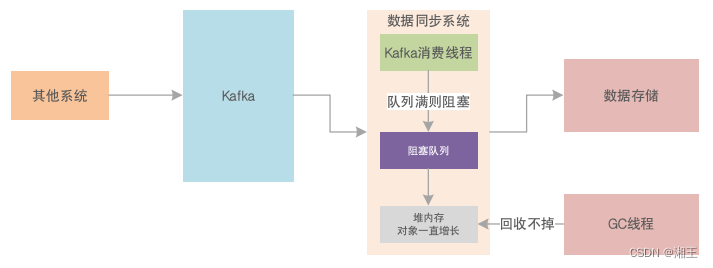
JVM系统优化实践(22):GC生产环境案例(五)
您好,这里是「码农镖局」CSDN博客,欢迎您来,欢迎您再来~ 除了Tomcat、Jetty,另一个常见的可能出现OOM的地方就是微服务架构下的一次RPC调用过程中。笔者曾经经历过的一次OOM就是基于Thrift框架封装出来的一个RPC框架导…...
DevOps系列文章 之GitLabCI模板库的流水线
目录结构,jobs目录用于存放作业模板。templates目录用于存放流水线模板。这次使用default-pipeline.yml作为所有作业的基础模板。 作业模板 作业分为Build、test、codeanalysis、artifactory、deploy部分,在每个作业中配置了rules功能开关&…...

spring扩展点ApplicationContextAware解释
ApplicationContextAware是Spring框架中的一个扩展接口,用于获取和操作应用程序上下文(ApplicationContext)。通过实现ApplicationContextAware接口,可以在Bean中获取对应用程序上下文的引用,并进行进一步的操作。 具…...
力扣热门100题之最大子数组和【中等】【动态规划】
题目描述 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 示例 1: 输入:nums [-2,1,-3,4,-1,2,1,-5,4] 输出&a…...
导出为PDF加封面且分页处理dom元素分割
文章目录 正常展示页面导出后效果代码 正常展示页面 导出后效果 代码 组件内 <template><div><div><div class"content" id"content" style"padding: 0px 20px"><div class"item"><divstyle"…...
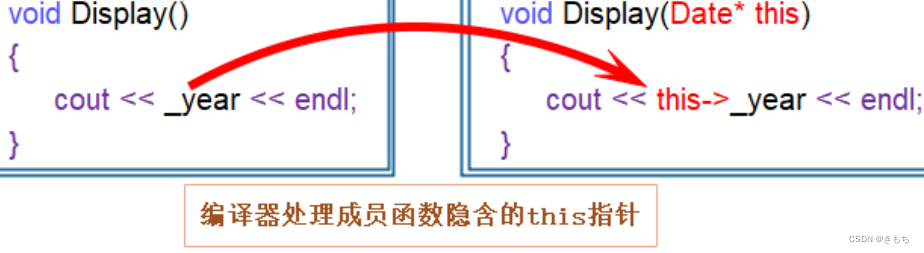
【C++入门】浅谈类、对象和 this 指针
文章目录 一、前言二、类1. 基本概念2. 类的封装3. 使用习惯成员函数定义习惯成员变量命名习惯 三、对象1. 基本概念2. 类对象的存储规则 四、this 指针1. 基本概念2. 注意事项3. 经典习题4. 常见面试题 一、前言 在 C 语言中,我们用结构体来描述一个事物的多种属性…...

【Linux命令200例】indent对C语言代码进行缩进和格式化
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,2023年6月csdn上海赛道top4。 🏆本文已收录于专栏:Linux命令大全。 🏆本专栏我们会通过具体的系统的命令讲解加上鲜活的实操案例对各个命令进行深入…...

Hive 调优集锦(1)
一、前言 1.1 概念 Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在HDFS 中的数据进行分析和管理。 1.2 架…...
【C++详解】——智能指针
目录 为什么需要智能指针 抛异常引发内存泄漏 内存泄漏 什么是内存泄漏,内存泄漏的危害 内存泄漏分类 检测内存泄漏常用工具 如何避免内存泄漏 智能指针的使用及原理 RAII 智能指针的原理 各类智能指针介绍 auto_ptr unique_ptr shared_ptr weak_ptr …...
Jmeter接口/性能测试,Jmeter使用教程(超细整理)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、线程组 线程组…...

59,综合案例-演讲比赛流程管理系统
演讲比赛流程管理系统 59.1案例描述59.1.1比赛规则59.1.2程序功能 59.2创建管理类59.3菜单功能59.3.1添加成员函数59.3.2菜单功能实现 59.4退出功能59.4.1提供功能接口59.4.2实现退出功能 59.5演讲比赛功能59.5.1创建选手类59.5.2比赛59.5.2.1成员属性添加59.5.2.2初始化属性59…...

前端JS 展示上传图片缩略图(本地图片读取)
需求: 点击上传图片按钮,选择图片以后,不请求后端接口,直接将图片展示在缩略图中。 解决方案: 使用 FileReader 和 FileReader 中的 readAsDataURL 方法。 第一步 从input[type“file”] (上传文件标签) 里面拿到fil…...

Vue中$route和$router的区别
$router:用来操作路由,$route:用来获取路由信息 $router其实就是VueRouer的实例,对象包括了vue-router使用的实例方法,还有实例属性,我们可以理解为$router有一个设置的含义,比如设置当前的跳转…...
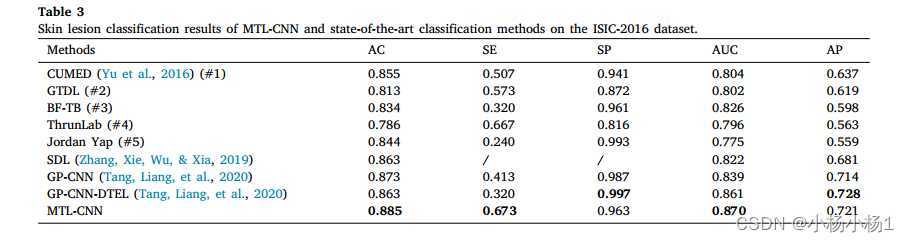
基于多任务学习卷积神经网络的皮肤损伤联合分割与分类
文章目录 Joint segmentation and classification of skin lesions via a multi-task learning convolutional neural network摘要本文方法实验结果 Joint segmentation and classification of skin lesions via a multi-task learning convolutional neural network 摘要 在…...
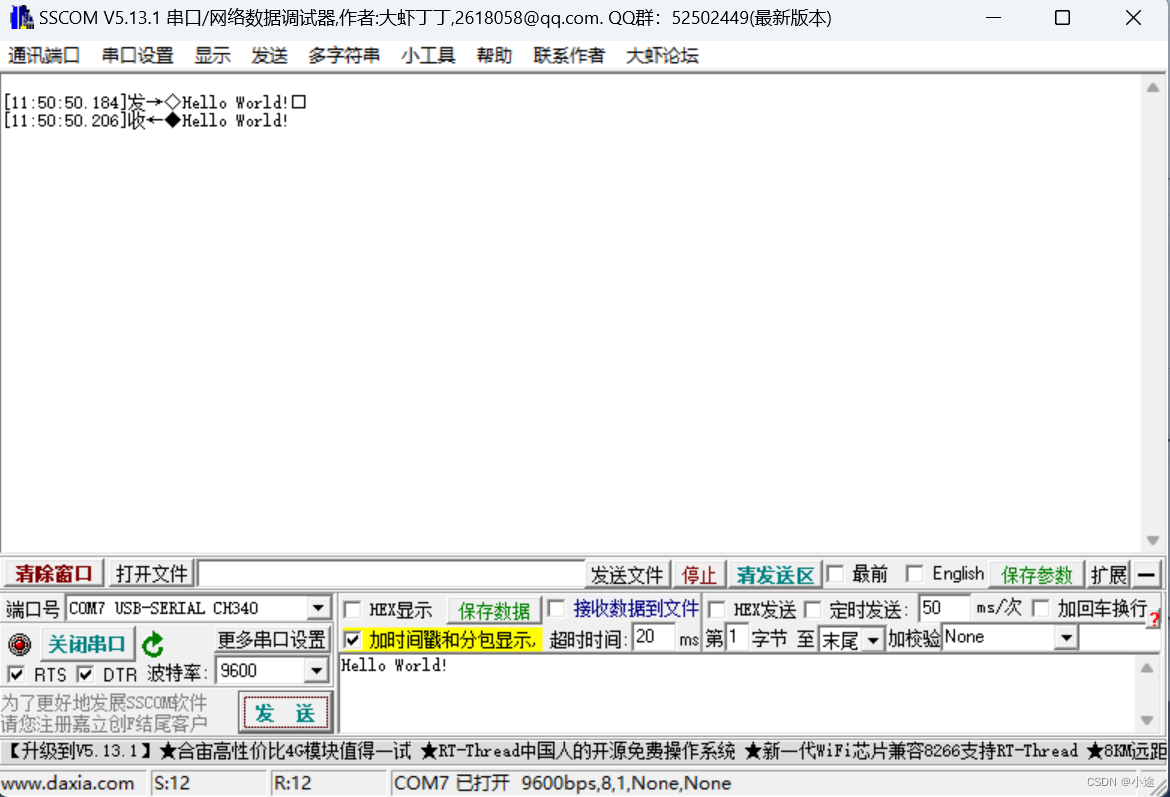
串口环形缓冲区
文章目录 一、串口环形缓冲区概念二、STC12例程(1)环形串口缓冲区结构体(2)串口环形缓冲区存和取数据(3)完整工程demo 一、串口环形缓冲区概念 串口环形缓冲区应用于嵌入式、物联网开发中处理接收串口数据…...

【腾讯云 Cloud Studio 实战训练营】基于Cloud Studio完成简易通讯录
目录 🔆Cloud Studio 简介 操作步骤 1.登录 2.创建工作空间 3.初始界面 4.开发空间 5.保存自定义模板 🔆简易通讯录 1.实验要求 2.操作环境 3.源代码介绍 3.1 定义通讯录类 3.2 定义通讯录列表 3.3 添加联系人功能 3.4 修改联系人 3.5 …...

RK3588嵌入式Linux开发实战:uboot任意键中断autoboot功能实现
1. 为什么需要任意键中断autoboot功能 在嵌入式Linux开发中,uboot作为系统启动的"引路人",承担着硬件初始化、内核加载等重要任务。RK3588这类高性能处理器在启动时,默认会进入autoboot倒计时流程。这个设计本意是好的——当系统正…...

MoMask:文本驱动3D运动生成技术全解析
MoMask:文本驱动3D运动生成技术全解析 【免费下载链接】momask-codes Official implementation of "MoMask: Generative Masked Modeling of 3D Human Motions (CVPR2024)" 项目地址: https://gitcode.com/gh_mirrors/mo/momask-codes 价值定位&am…...

DAMO-YOLO实战:用AI视觉系统做内容安全审核与统计
DAMO-YOLO实战:用AI视觉系统做内容安全审核与统计 1. 引言:当AI视觉遇见内容安全 在数字内容爆炸式增长的今天,如何高效地进行内容审核成为许多平台面临的挑战。传统人工审核不仅效率低下,而且容易因疲劳导致误判。本文将介绍如…...

WordPress建站避坑指南:Ubuntu服务器常见权限问题与安全配置
WordPress建站避坑指南:Ubuntu服务器常见权限问题与安全配置 引言:为什么你的WordPress网站总出问题? 每次看到新手开发者兴奋地宣布"我的WordPress网站上线了",我都忍不住想问:你真的检查过文件权限了吗&am…...

dynamic-datasource JVM调优:提升多数据源性能的7个实用技巧
dynamic-datasource JVM调优:提升多数据源性能的7个实用技巧 【免费下载链接】dynamic-datasource dynamic datasource for springboot 多数据源 动态数据源 主从分离 读写分离 分布式事务 项目地址: https://gitcode.com/gh_mirrors/dy/dynamic-datasource …...

【学术干货免费领】200+学术海报模板免费领|科研展示零成本,高效出图不内耗 | 学术会议海报模板,适配国际国内各类学术场合 | 硕博研究生必需,全学科适配,助力科研成果高光出圈
重磅福利来袭!200学术海报模板,全程免费领取,零成本解锁科研展示新方式!适配以下各类科研相关人群:硕博研究生群体包括硕士研究生和博士研究生适用于不同研究阶段:从开题报告撰写到学位论文完成特别适合需要…...

C# : 引用类型都存在堆上吗
不完全是,这里要精确区分:引用类型的实例大多数存在堆上,但引用本身不一定在堆上。我们拆开来说:引用类型本身 vs 引用变量对象实例(类的实例)绝大多数情况下分配在 堆上由 垃圾回收器 管理生命周期引用变量…...

精准匹配歌词:Foobar2000歌词插件配置完全指南
精准匹配歌词:Foobar2000歌词插件配置完全指南 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 3分钟完成版本适配检测 如何确定你的Foobar20…...

AI教材生成大揭秘!工具选择与低查重教材编写的实用干货
在教材编写的过程中,许多编辑者常常会感到遗憾:尽管正文章节已经经过了反复打磨,但因为缺乏必要的配套资源,整体教学效果却受到影响。课后练习的设计需要具有层次感,但缺乏灵活的想法;教学课件希望能做到形…...

5分钟完成专业级黑苹果配置:OpCore Simplify终极简化指南
5分钟完成专业级黑苹果配置:OpCore Simplify终极简化指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经为黑苹果配置的复杂性…...