线性神经网路——线性回归随笔【深度学习】【PyTorch】【d2l】
文章目录
- 3.1、线性回归
- 3.1.1、PyTorch 从零实现线性回归
- 3.1.2、简单实现线性回归
3.1、线性回归
线性回归是显式解,深度学习中绝大多数遇到的都是隐式解。
3.1.1、PyTorch 从零实现线性回归
%matplotlib inline
import random
import torch
#d2l库中的torch模块,并将其用别名d2l引用。d2l库是《动手学深度学习》(Dive into Deep Learning)这本书的配套库,包含了一些自定义的函数和工具,以及对PyTorch库的包装和扩展。
from d2l import torch as d2l
生成数据集及标签
def synthetic_data(w,b,num_examples):"""生成 y = Xw + b + 噪声"""X = torch.normal(0,1,(num_examples,len(w)))#创建一个大小为(num_examples, len(w))的张量X,并使用均值为0,标准差为1的正态分布对其进行初始化。这个张量代表输入特征,其中 num_examples 是样本数量,len(w) 是特征向量的长度。y = torch.matmul(X,w) + by += torch.normal(0, 0.01, y.shape)#预测值y中添加一个均值为0,标准差为0.01的正态分布噪声,以增加模型的随机性和泛化能力。return X, y.reshape((-1,1))#预测值y通过reshape方法被转换成一个列向量
true_w = torch.tensor([2,-3.4])
true_b = 4.2
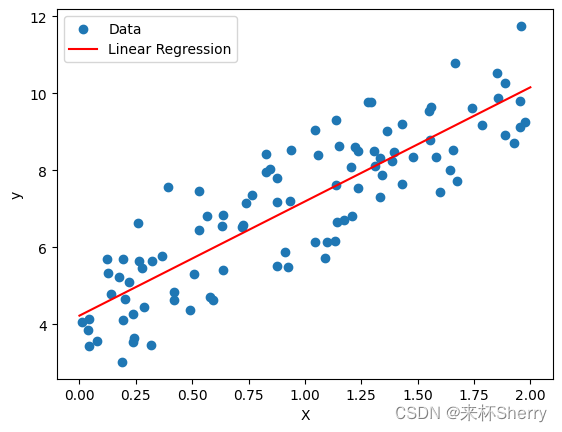
features, labels = synthetic_data(true_w,true_b,1000)print('features:',features[0],'\nlabel:',labels[0])d2l.set_figsize()#设置图表尺寸
d2l.plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1);
d2l.plt.scatter(,,),使用d2l库中的绘图函数来创建散点图。这个函数接受三个参数:
features[:,1].detach().numpy() 是一个二维张量features的切片操作,选择了所有行的第二列数据。detach()函数用于将张量从计算图中分离,numpy()方法将张量转换为NumPy数组。这样得到的是一个NumPy数组,代表散点图中的x轴数据。
labels.detach().numpy() 是一个二维张量labels的分离和转换操作,得到一个NumPy数组,代表散点图中的y轴数据。
1 是可选参数,用于设置散点的标记尺寸。在这里,设置为1表示每个散点的大小为1个点。
这里为什么要用detach()?
尝试去掉后结果是不变的,应对某些pytorch版本转numpy必须这样做。
def data_iter(batch_size, features, labels):num_examples = len(features)#创建一个包含0到num_examples-1的整数列表,表示样本索引。indices = list(range(num_examples))#随机打乱样本索引的顺序,样本是随机读取的,没有特定顺序。random.shuffle(indices)for i in range(0, num_examples, batch_size):# 根据当前批次的起始索引,创建一个包含当前批次样本索引的张量。min(i + batch_size, num_examples)确保最后一个批次的大小不超过剩余样本数量。batch_indices = torch.tensor(indices[i:min(i + batch_size,num_examples)])# 使用生成器返回当前批次的特征和标签。yield features[batch_indices],labels[batch_indices]batch_size = 10for X,y in data_iter(batch_size, features, labels):print(X,'\n',y)break
小插叙,synthetic_data()返回值中X敲成了小写,直接导致后面矩阵乘法形状对不上,找了半天错误。
yield 预备知识:
当一个函数包含
yield语句时,它就变成了一个生成器函数。生成器函数用于生成一个序列的值,而不是一次性返回所有值。每次调用生成器函数时,它会暂停执行,并返回一个值。当下一次调用生成器函数时,它会从上次暂停的地方继续执行,直到遇到下一个yield语句或函数结束。
定义初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
定义模型
def linreg(X, w, b):"""线性回归模型"""return torch.matmul(X, w) + b #X, w进行矩阵乘法
定义损失函数
def squared_loss(y_hat,y): #(预测值,真实值)"""均方损失"""return (y_hat - y.reshape(y_hat.shape)) **2 / 2
这就是数据是张量的好处,
M S E ( y , y ′ ) = ∑ i = 1 n ( y i − y i ′ ) 2 n MSE(y,y') = \frac{\sum_{i=1}^n(y_i-y_i')^2}{n} MSE(y,y′)=n∑i=1n(yi−yi′)2
明明是含有求和操作的数学公式,在张量面前形同虚设,代码实现是这么简单。就像在写标量公式一样。
定义优化算法
def sgd(params, lr, batch_size):#一个包含待更新参数的列表,学习率,每个小批次中的样本数量)"""小批量随机梯度下降"""with torch.no_grad():for param in params:param -=lr * param.grad / batch_sizeparam.grad.zero_()
为什么执行的减法而不是加法?
梯度的负方向
优化算法是怎么跟损失函数合作来完成参数优化?
优化函数没有直接使用损失值,但通过使用损失函数和反向传播计算参数的梯度,并将这些梯度应用于参数更新,间接地优化了模型的损失。梯度下降算法利用了参数的梯度信息来更新参数,以使损失函数尽可能减小。
优化算法(例如随机梯度下降)是怎么拿到损失函数的梯度信息的?
损失函数梯度完整的说是 loss关于x,loss关于y的梯度 ,搞清楚这个概念就不难理解了【初学时,我误解成了
损失值的梯度和x,y的梯度是两个概念,显然后者是非常不准确的表述】,损失函数梯度就在 sgd的params中。l = loss(net(X, w, b), y) l.sum().backward()#此时损失函数梯度【关于w,b的梯度】存在w.grad,b.grad中 sgd([w,b], lr, batch_size) #使用参数梯度更新参数
param.grad.zero_()在这里有什么意义?谁会干扰梯度的求解?如果在循环的下一次迭代中不使用
param.grad.zero_()来清零参数的梯度,那么参数将会保留上一次迭代计算得到的梯度值,继续沿用该梯度值来求解梯度。就是说上次for循环的param会对下次param的梯度求解产生影响,所以才要清空梯度。
训练过程
#超参数
lr =0.03 #学习率(learning rate),控制每次参数更新的步幅大小。
num_epochs = 3 #数据集的扫描次数,即要重复训练模型的次数。
net =linreg #表示模型,这里使用了一个名为linreg的线性回归模型。
loss = squared_loss#表示损失函数,这里使用了一个名为squared_loss的均方损失函数。for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X 、y 的小批量损失#l形状是 (batch_size, 1),非标量l.sum().backward()sgd([w,b], lr, batch_size) #使用参数梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b),labels)print('epoch ',epoch+1,'loss ',float(train_l.mean()))
epoch 1 loss 0.032808780670166016 epoch 2 loss 0.00011459046800155193 epoch 3 loss 5.012870315113105e-05加
with torch.no_grad()有什么意义,毕竟没有backward()操作?对于
with torch.no_grad()块,在 PyTorch 中禁用梯度追踪和计算图的构建。在该块中执行的操作不会被记录到计算图中,因此不会生成梯度信息。其作用是告诉 PyTorch 不要跟踪计算梯度,这样可以节省计算资源。简单说,就是计算损失值的张量运算不会记录到计算图中,因为没必要,而且不建立计算图,求损失值更快了。
代码存在的小问题
最后一批次可能不足
batch_size,sgd 执行param -=lr * param.grad / batch_size取平均是有问题的,修改后:sgd([w,b], lr,min(batch_size, X.shape[0])) #使用参数梯度更新参数
比较真实参数与训练学到的参数评估训练成功程度
print('w的估计误差:',true_w - w.reshape(true_w.shape))
print('b的估计误差:',true_b - b)
w的估计误差: tensor([-6.1035e-05, 2.5797e-04], grad_fn=<SubBackward0>) b的估计误差: tensor([0.0018], grad_fn=<RsubBackward1>)
3.1.2、简单实现线性回归
生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2ltrue_w = torch.tensor([2,-3.4])
true_b = 4.2
#d2l 的人造数据集函数
features, labels = d2l.synthetic_data(true_w, true_b,1000)
读取数据集
def load_array(data_arrays, batch_size, is_train=True):"""构造一个Pytorch数据迭代器"""#PyTorch提供的一个用于封装多个张量数据的数据集对象,*data_arrays用于将数据数组解包为多个参数。#*data_arrays解包等价于 dataset = data.TensorDataset(features, labels)dataset = data.TensorDataset(*data_arrays)#PyTorch提供的一个用于批量加载数据的迭代器return data.DataLoader(dataset, batch_size, shuffle= is_train)batch_size = 10
data_iter = load_array((features,labels), batch_size)
#iter() 函数将数据迭代器转换为迭代器对象,而 next() 函数用于获取迭代器的下一个元素。
next(iter(data_iter))
解包操作(见 python 预备知识)
星号
*在dataset = data.TensorDataset(*data_arrays)中的作用是将元组或列表中的元素解包,并作为独立的参数传递给函数或构造函数。这样可以更方便地传递多个参数。迭代器使用(见 python 预备知识)
iter()函数的主要目的是将可迭代对象转换为迭代器对象,以便于使用next()函数逐个访问其中的元素。
使用框架预定好的层
from torch import nn
#线性回归就是一个简单的单层神经网络
#一个全连接层,它接受大小为 2 的输入特征,并输出大小为 1 的特征。
net = nn.Sequential(nn.Linear(2,1))
初始化模型参数
#net[0] 表示模型中的第一个层,weight权重参数,正态分布初始化
net[0].weight.data.normal_(0,0.01)
#第一层加入偏差
net[0].bias.data.fill_(0)
实例化损失函数
loss = nn.MSELoss()
实例化优化算法( SGD)
#net.parameters() 返回一个迭代器,该迭代器包含了模型中所有可训练的参数。
trainer = torch.optim.SGD(net.parameters(),lr=0.03)
训练过程
num_epochs = 3
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y)trainer.zero_grad()l.backward()trainer.step()l = loss(net(features),labels)print(f'epoch {epoch+1}, loss {l:f}')
关于输出格式,最后一个明显最好
print('epoch ',epoch+1,',loss ',l) #epoch 1 ,loss tensor(9.9119e-05, grad_fn=<MseLossBackward0>)print('epoch ',epoch+1,',loss ',float(l))# epoch 1 ,loss 9.872819646261632e-05print(f'epoch {epoch+1}, loss {l:f}') # epoch 1, loss 0.000099还可以自定义保留有限小数位
print(f'epoch {epoch+1}, loss {l:.4f}')# 保留4位。
相关文章:
线性神经网路——线性回归随笔【深度学习】【PyTorch】【d2l】
文章目录 3.1、线性回归3.1.1、PyTorch 从零实现线性回归3.1.2、简单实现线性回归 3.1、线性回归 线性回归是显式解,深度学习中绝大多数遇到的都是隐式解。 3.1.1、PyTorch 从零实现线性回归 %matplotlib inline import random import torch #d2l库中的torch模块&a…...

js实现多种按钮
你可以使用JavaScript来实现多种类型的按钮,以下是几个常见的示例: 普通按钮(Normal Button): <button>Click me</button> 带图标的按钮(Button with Icon): <bu…...
)
getopt函数(未更新完)
2023年7月28日,周五上午 这是我目前碰到过的比较复杂的函数之一, 为了彻底弄懂这个函数,我花了几个小时。 为了更好的说明这个函数,之后我可能会录制讲解视频并上传到B站, 如果我上传到B站,我会在文章添…...
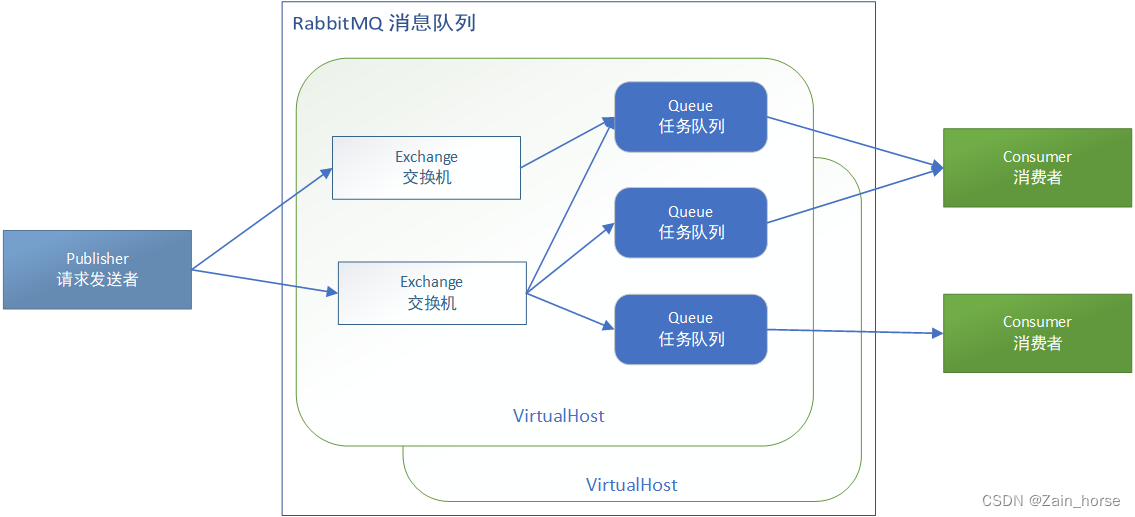
SpringCloud学习路线(9)——服务异步通讯RabbitMQ
一、初见MQ (一)什么是MQ? MQ(MessageQueue),意思是消息队列,也就是事件驱动架构中的Broker。 (二)同步调用 1、概念: 同步调用是指,某一服务…...
postcss-pxtorem适配插件动态配置rootValue(根据文件路径名称,动态改变vue.config里配置的值)
项目背景:一个项目里有两个分辨率的设计稿(1920和2400),不能拆开来打包 参考: 是参考vant插件:移动端Vant组件库rem适配下大小异常的解决方案:https://github.com/youzan/vant/issues/1181 说明: 因为vue.c…...

代码随想录算法训练营第二十三天 | 额外题目系列
额外题目 1365. 有多少小于当前数字的数字借着本题,学习一下各种排序未看解答自己编写的青春版重点代码随想录的代码我的代码(当天晚上理解后自己编写) 941.有效的山脉数组未看解答自己编写的青春版重点代码随想录的代码我的代码(当天晚上理解后自己编写) 1207. 独一…...

UiAutomator
运行Espresso和UI Automator测试时要使用模拟器。国内手机的ROM大多进行过修改,可能加入很多限制,导致测试无法正常运行。 Espresso只支持一个活动内部交互行为的测试。跨越多个活动、多个应用的场景需要使用UI Automator。使用Espresso和UI Automator的…...

stm32标准库开发常用函数的使用和代码说明
文章目录 GPIO(General Purpose Input/Output)NVIC(Nested Vectored Interrupt Controller)DMA(Direct Memory Access)USART(Universal Synchronous/Asynchronous Receiver/Transmitter…...

有关合泰BA45F5260中断的思考
最近看前辈写的代码,发现这样一段代码: #ifdef SUPPORT_RF_NET_FUNCTION if(UART_INT_is_L()) { TmrInsertTimer(eTmrHdlUartRxDelay,TMR_PERIOD(2000),NULL); break; } #endif 其中UART_INT_is_L&am…...

Numpy-算数函数与数学函数
⛳算数函数 如果参与运算的两个对象都是ndarray,并且形状相同,那么会对位彼此之间进 第 30 页 行( - * /)运算。NumPy 算术函数包含简单的加减乘除: add(),subtract(),multiply() 和divide()。 …...

Nginx在springboot中起到的作用
面试时这样回答: 在Spring Boot项目中使用Nginx可以有以下用途: 1. 反向代理:Nginx可以作为反向代理服务器,将外部请求转发到后端的Spring Boot应用,并可以实现负载均衡、高可用、缓存等功能,提高系统的性…...

12.(开发工具篇vscode+git)vscode 不能识别npm命令
1:vscode 不能识别npm命令 问题描述: 解决方式: (1)右击VSCode图标,选择以管理员身份运行; (2)在终端中执行get-ExecutionPolicy,显示Restrictedÿ…...

如何在MacBook上彻底删除mysql
好久以前安装过,但是现在配置mysql一直出错,索性全部删掉重新配置。 一、停止MySQL服务 首先,请确保 MySQL 服务器已经停止运行,以免影响后续的删除操作。 sudo /usr/local/mysql/support-files/mysql.server stop如果你输入之…...
)
web攻击面试|网络渗透面试(一)
Web攻击面试大纲 常见Web攻击类型 1.1 SQL注入攻击 1.2 XSS攻击 1.3 CSRF攻击 1.4 命令注入攻击SQL注入攻击 2.1 基本概念 2.2 攻击原理 2.3 防御措施XSS攻击 3.1 基本概念 3.2 攻击原理 3.3 防御措施CSRF攻击 4.1 基本概念 4.2 攻击原理 4.3 防御措施命令注入攻击 5.1 基本概…...
另存为不含宏的文档)
VBA操作WORD(六)另存为不含宏的文档
Sub 另存为不含宏的文档()Application.DisplayAlerts False Application.ScreenUpdating FalseDim oDoc As DocumentSet oDoc Word.ActiveDocumentDim oRng As RangeSet oRng oDoc.ContentDim sPath As String默认存储路径,当前用户桌面,注释掉的是当…...

分享69个Java源码,总有一款适合您
Java源码 分享69个Java源码,总有一款适合您 下面是文件的名字,我放了一些图片,文章里不是所有的图主要是放不下...,大家下载后可以看到。 源码下载链接: https://pan.baidu.com/s/1ZgbJhMNwIyFyqFzHsDdL5w 提取码&a…...

《cool! autodistill帮你标注数据训练yolov8模型》学习笔记
《cool! autodistill帮你标注数据训练yolov8模型》 Summary Autodistill是一个用于自动标注数据训练边缘模型的工具。 Highlights 💡 Autodistill由Robotflow推出,用于训练建立部署计算机视觉模型。💻 通过使用大模型自动标注和训练小模型…...

Rust vs Go:常用语法对比(十)
题图来自 Rust vs. Golang: Which One is Better?[1] 182. Quine program Output the source of the program. 输出程序的源代码 package mainimport "fmt"func main() { fmt.Printf("%s%c%s%c\n", s, 0x60, s, 0x60)}var s package mainimport "fm…...

SliverPersistentHeader组件 实现Flutter吸顶效果
效果: 20230723-212152-73_Trim 代码: import package:flutter/cupertino.dart; import package:flutter/material.dart;class StickHeaderPage extends StatefulWidget {overrideState<StatefulWidget> createState() {// TODO: implement creat…...

Nginx性能优化配置
一、全局优化 # 工作进程数 worker_processes auto; # 建议 CPU核心数|CPU线程数# 最大支持的连接(open-file)数量;最大值受限于 Linux open files (ulimit -n) # 建议公式:worker_rlimit_nofile > worker_processes * worker_connections…...

OpenClaw+Qwen3-14b_int4_awq自动化写作:从资料收集到排版发布
OpenClawQwen3-14b_int4_awq自动化写作:从资料收集到排版发布 1. 为什么需要自动化写作工作流 作为一个技术博主,我经常面临这样的困境:明明有大量想分享的内容,却总被繁琐的写作流程拖累。从资料收集、大纲梳理到内容生成和格式…...

丹青幻境·Z-Image Atelier部署教程:Docker Compose一键启停方案
丹青幻境Z-Image Atelier部署教程:Docker Compose一键启停方案 1. 学习目标与前置准备 本教程将手把手教你如何使用Docker Compose快速部署丹青幻境Z-Image Atelier数字艺术创作平台。通过本教程,你将学会: 如何在5分钟内完成环境搭建如何…...
)
STM32F4 Flash读写避坑指南:如何安全存储关键数据(附完整代码)
STM32F4 Flash读写避坑指南:如何安全存储关键数据(附完整代码) 第一次在STM32F4上操作Flash时,我遇到了一个令人抓狂的问题——设备运行几小时后数据莫名其妙丢失。经过三天三夜的调试才发现,原来是在写入前忘记检查扇…...

曾经我和大模型交流业务实现记录
第一次: 我有一组子组件11个,通过子组件的不同组合,可以组成表单,这些表单让不同的用户使用,表单组成公共的内容,让大部分用户使用,当然用户可以在这些表单的基础上修改一些默认值,变…...

RT thread—iic—at24c04读写操作
at24c04介绍:存储容量:4 Kbits(即 512 字节)。内部结构为 32 页,每页 16 字节。地址0x000-0x1FF通信接口:标准 I2C(时钟线 SCL 和数据线 SDA),支持最高 400 kHz 的快速模…...
)
用Python写AI版石头剪刀布:教你用机器学习预测对手出拳(TensorFlow实战)
用Python构建AI驱动的石头剪刀布游戏:从数据收集到模型部署全流程 石头剪刀布这个看似简单的游戏,实际上蕴含着丰富的决策模式和人类行为规律。作为一名长期研究游戏AI的开发者,我发现用机器学习预测玩家出拳模式远比随机选择有趣得多。本文将…...

AI营销SaaS榜单评测:原圈科技如何助力品牌客户破局增长?
本文深度探讨AI营销行业趋势与SaaS产品评选标准。在众多解决方案中,原圈科技的AI营销SaaS平台凭借其领先的技术底层能力、产品成熟度及客户成功案例,在市场适配度与服务落地性等多个维度下表现突出,被普遍视为企业实现精细化营销升级的有力选…...
)
告别‘千人千脑’:用DMMR模型搞定EEG情感识别的跨被试难题(附PyTorch代码)
突破脑电情感识别的个体差异壁垒:DMMR模型实战指南与PyTorch实现 当你在实验室里看着屏幕上跳动的脑电波形时,是否曾为不同受试者数据间的巨大差异而头疼?这种被称为"脑电指纹"的个体特异性,一直是情感识别领域最棘手的…...

揭秘JVM创世过程之Call Stub进入Java世界的门票
前言 本文旨在记录近期研读Java源码的学习心得与疑难问题。由于个人理解水平有限,文中内容可能存在疏漏,恳请读者不吝指正。 前情回顾 在揭秘JVM创世过程之两种语言首席外交官JavaCalls,一文中将JVM看作Java世界中一个拥有两种语言的领事馆…...

钢链数智,赋能实业——千匠网络钢铁产业电商系统,破解行业困局,激活钢铁增长新动能
钢铁行业作为国民经济的支柱产业,贯穿基建、制造、房地产、机械装备等核心领域,正处于从“规模扩张”向“质量提升”转型的关键阶段:从铁矿开采、冶炼轧制、钢材加工,到多级分销、终端采购、工程交付,全链路环节繁杂、…...