【复盘与分享】第十一届泰迪杯B题:产品订单的数据分析与需求预测
文章目录
- 题目
- 第一问
- 第二问
- 2.1 数据预处理
- 2.2 数据集分析
- 2.2.1 训练集
- 2.2.2 预测集
- 2.3 特征工程
- 2.4 模型建立
- 2.4.1 模型框架和评价指标
- 2.4.2 模型建立
- 2.4.3 误差分析和特征筛选
- 2.4.4 新品模型
- 2.5 模型融合
- 2.6 预测方法
- 2.7 总结
- 结尾
距离比赛结束已经过去两个多月了。
整个过程还是非常辛苦的,在前期整个团队都在进行学习铺垫,精力主要集中在全部数据给出后的建模
收到了答辩的通知,可惜评委问的问题太过离谱,没能展现出我们的创新点,最终没能获得特等奖,是个国一
因为感觉对我们的工作进行一个总结,对很多准备相关比赛的同学还是挺有帮助的,所以还是复盘一下
用Prophet一个个商品预测肯定是错误的,训练时间太长。先整合成结构化数据,再上机器学习才是合理的做法
题目
任务1:数据分析
针对提供的历史销售数据(order_train1.csv),需要进行深入的数据分析。分析主题包括但不限于:
1.1 产品的不同价格对需求量的影响
1.2 产品所在区域对需求量的影响,以及不同区域的产品需求量有何特性
1.3 不同销售方式(线上和线下)的产品需求量的特性
1.4 不同品类之间的产品需求量有何不同点和共同点
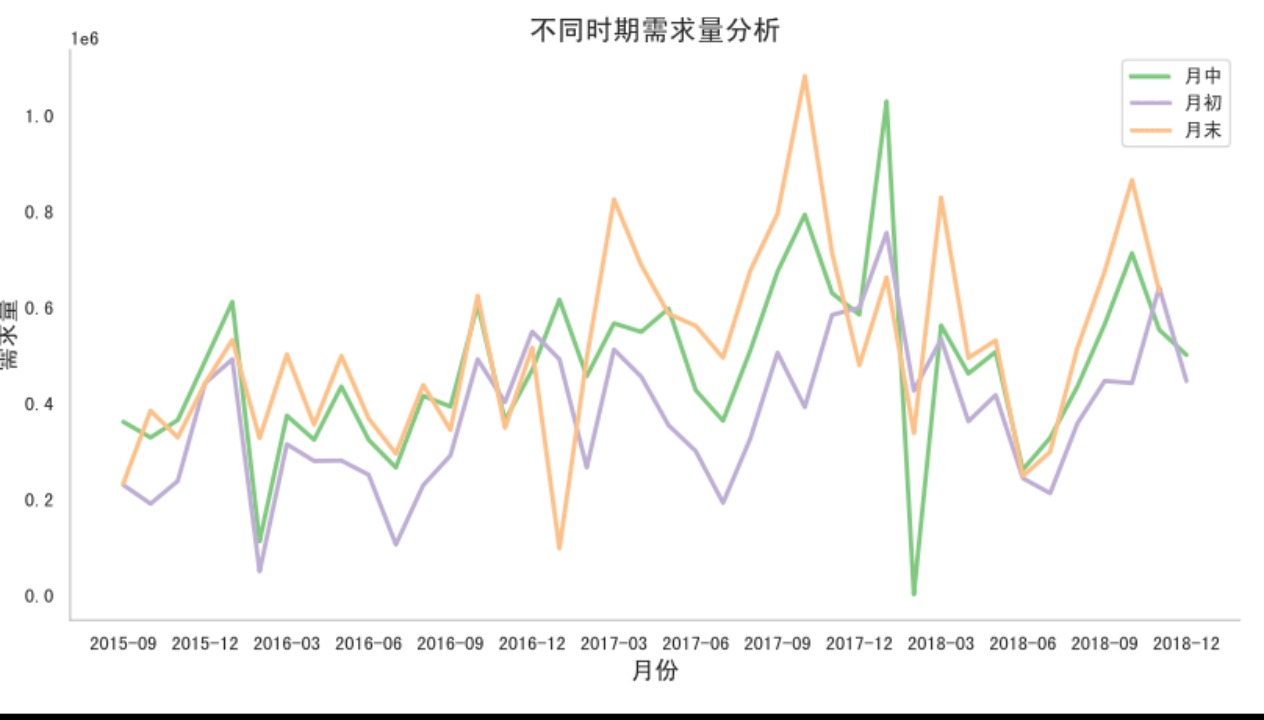
1.5 不同时间段(例如月头、月中、月末等)产品需求量有何特性
1.6 节假日对产品需求量的影响
1.7 促销(如618、双十一等)对产品需求量的影响
1.8 季节因素对产品需求量的影响
任务2:需求预测
基于上述分析,需要建立数学模型,对给出的产品(predict_sku1.csv)进行未来3个月(即2019年1月、2月、3月)的月需求量预测。预测结果需要按照给定格式保存为文件result1.xlsx。
请分别按照天、周、月的时间粒度进行预测,并尝试分析不同的预测粒度对预测精度可能产生的影响。
第一问
第一问就是数据探索性分析,没啥好说的,现在会调chatgpt并且进行简单的修改就能做出不错的图了。
虽然题目的意思可能是通过第一问的分析,对第二问的建模起到什么帮助,可能会在论文里看起来不错,但说实话屁用没有。第二问预测靠的还是特征工程等经验。所以第一问不是重点,展示几个图吧,不细讲了。
- 价格与需求量散点图

- 线下/线上订单需求量随时间变化趋势图

- 各大类/细类产品需求量占比双环图
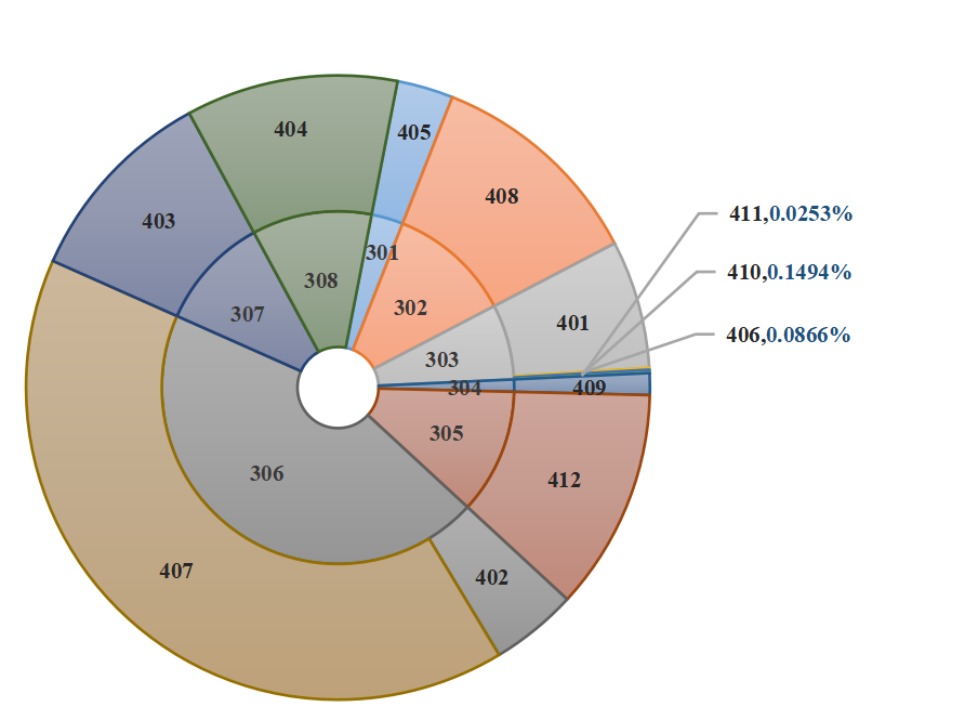
- 各大类产品月需求量气泡图
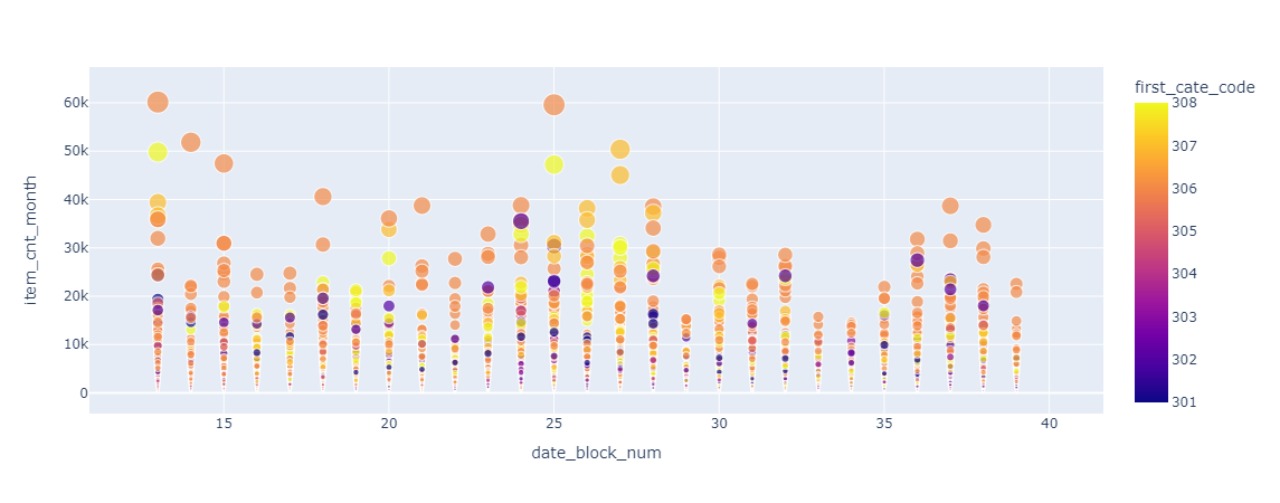
- 不同时段(月初、月中、月末)的产品需求量折线图
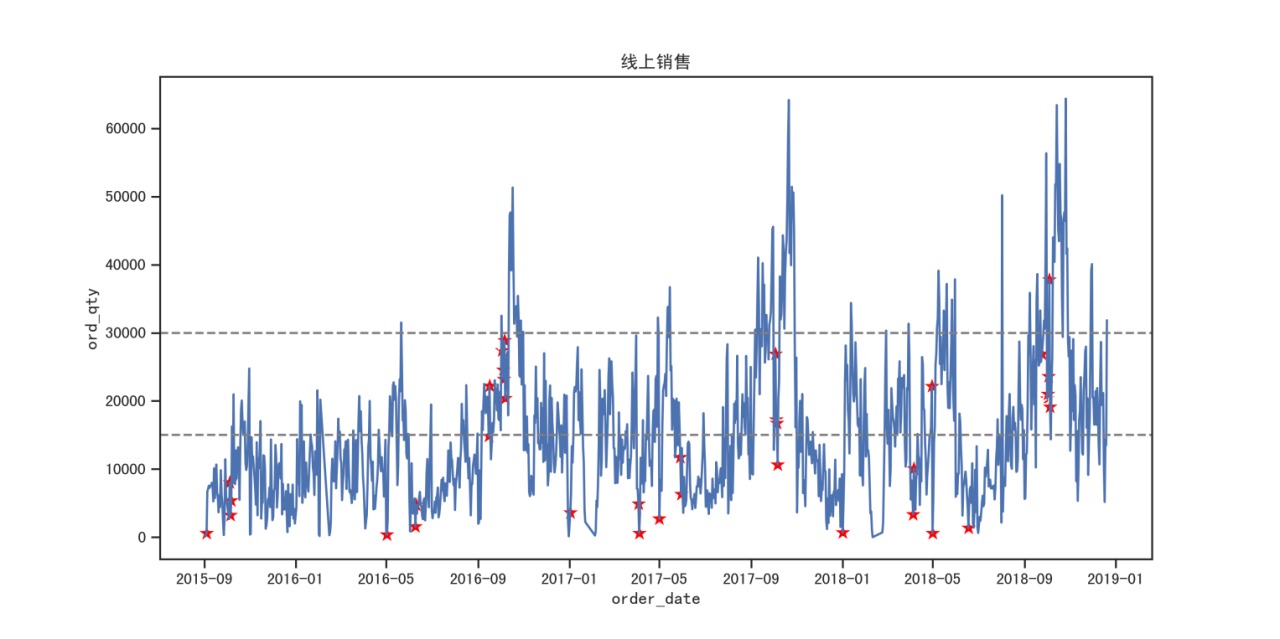
- 线下/上销售趋势

- “6.18”和“双十一”期间Top50促销产品所属细类双向柱状图

第二问
第二问要预测的精准,还是比较考验学习、代码能力的,当时是看了好几个销量预测的比赛代码,主要是kaggle上的,并且一步步自己改。搭出Baseline后,能先有一个预测的结果,再一步步的加上自己的想法。
以下内容都是先有Baseline后一步步试出来的,所以会有些跳跃性
一些链接(很多我找不到了):
详细的EDA和随机森林
1st place solution - Part 1 - “Hands on Data”
2.1 数据预处理
-
缺失值处理
-
异常值检测
- 对于检测出来有异常值的商品
- 在预测集中的商品单独建模(手动预测)
- 不再预测集中的商品直接删除
-
分类型数据转换成数值型
- 销售渠道
- 产品编号/产品类别/销售区域
-
对于波动很大的销量数据,我们有两种指标。
- 标签平滑处理:取对数,用RMSE指标
- 不对数处理:使用Tweedie偏差(Tweedie deviance)
-
如果你不处理,就用RMSE评价销量预测的精确度肯定有问题。
比如一只5块钱的笔(一个月销量大约5000个),预测偏差100个。跟一块2000块钱的手表(一个月销量大约500个),预测偏差100个。用RMSE评价是一样的,但实际上肯定是手表预测的偏差带来的问题更大。Tweedie偏差就能解决这种问题
当然如果先对数处理,倒也可以用RMSE
二选一即可,最后我还是使用了后者
2.2 数据集分析
2.2.1 训练集
这里我们对数据进行了很详细的分析,我自己单独去看每一类别中的每个商品的趋势,就能发现很多特征。尽管大部分因为时间原因没有用上,但这在现实业务的预测中是很重要的一步。我们要对这个数据集有详细的了解,才能针对性处理。
稍微列举几点:
- 403/404/405:最初线上,2017年起增加线下
- 406:线下,小规模订单;2018.3从105区域迁到其他区域
- 407:销售趋势呈多个小高峰,具有季节性趋势
- 411:于2017年11月上市
- 自2017年起,地区104停止销售,104地区大部分产品转移到105地区,编写函数实现数据迁移
- 有些商品有线上引领线下的销售特征,如果某个商品线上涨了,那个这个商品下个月大概率线下也会涨
- 数据按月整合,才能做特征工程和机器学习
- 对每个产品的需求量按区域和月份进行整合
- 建立一个包含销售区域、销售月份和产品等组合信息的结构化数据集
- 然后我们提出了一个比较有用的策略-商品分层。思路来源于营销课广告,因为不同性质定位的产品,其销售规律肯定有所不同,所以分类
- 新品:直至第36个月(date_block_num)才开始出现在市场上的产品。
- 流星品:突然出现的商品;但销售时长不超过5个月,销量会急剧下降。
- 睡眠品:一直保持客观的销量,却在某个时间点之后销售量骤减,但究其原因并非季节性因素的产品。
- 常规品:总有销量的产品;销售时长达39周以上或至少存在于市场中一年以上。
- 其实应该还有季节性商品的,但是大部分商品其存在时间都没到两年,所以算法不太能判断的出来,遂放弃
2.2.2 预测集
- 然后我们编写了分类函数,对预测集中的商品进行分类,来看看要预测的都是哪些商品

发现大部分是常规品,新品占比也不小。在搭出Baseline后我们进行了误差分析(后面会提,就是分析预测误差来源于哪里)。我们就发现很多的新品和一些波动大的商品,预测偏差很大,所以单独建立了新品模型。
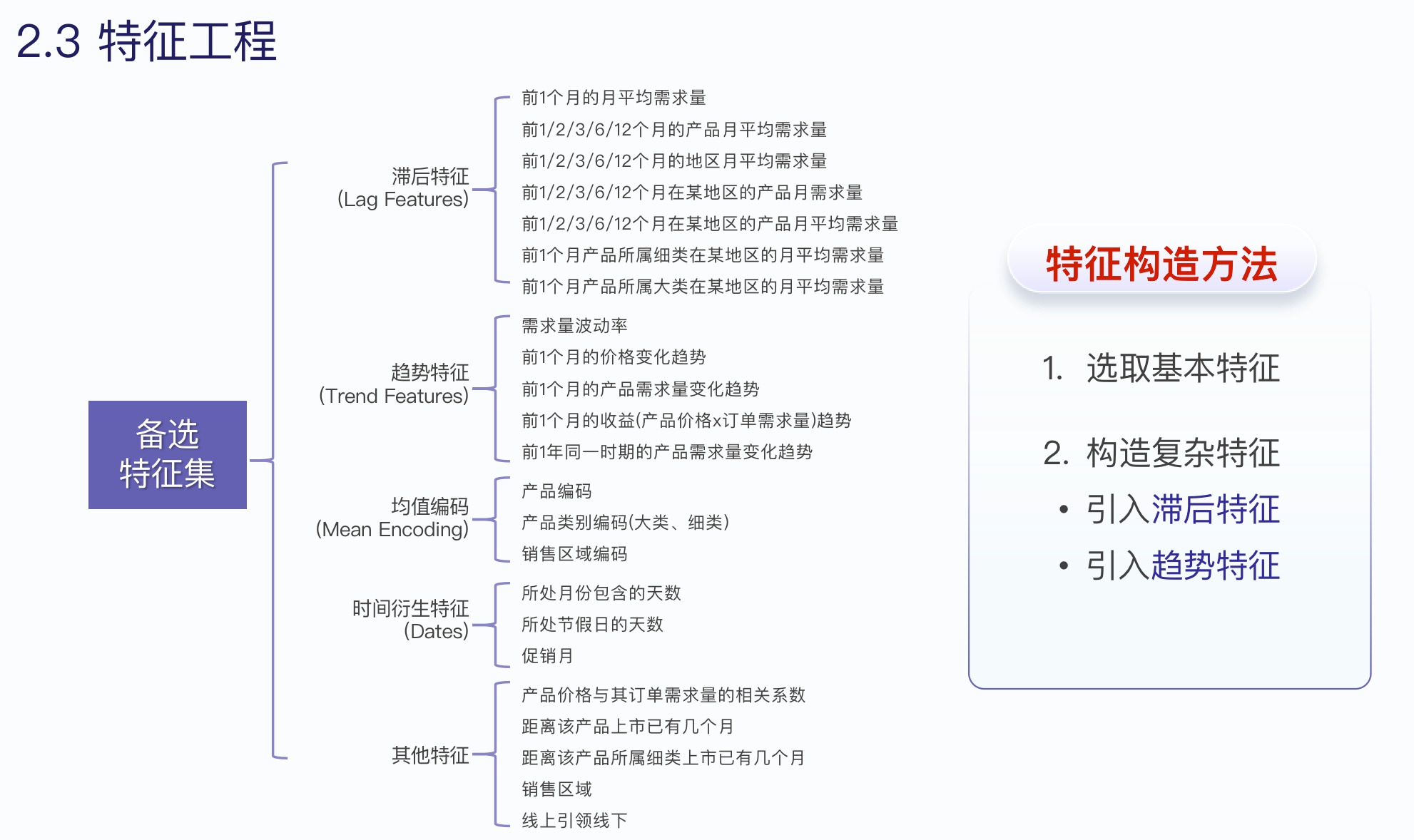
2.3 特征工程
特征工程是最重要的,也是决定模型最终预测精度的关键。常规的就是滞后特征、趋势特征等等。不断添加新特征,不断训练模型验证效果,最后没用的特征我们删除就好
- 切记不要数据泄漏,不要在做特征的时候引入未来的数据。比如趋势应该是上上个月->上个月的趋势,别是上个月->这个月的。这个月数据是要预测的
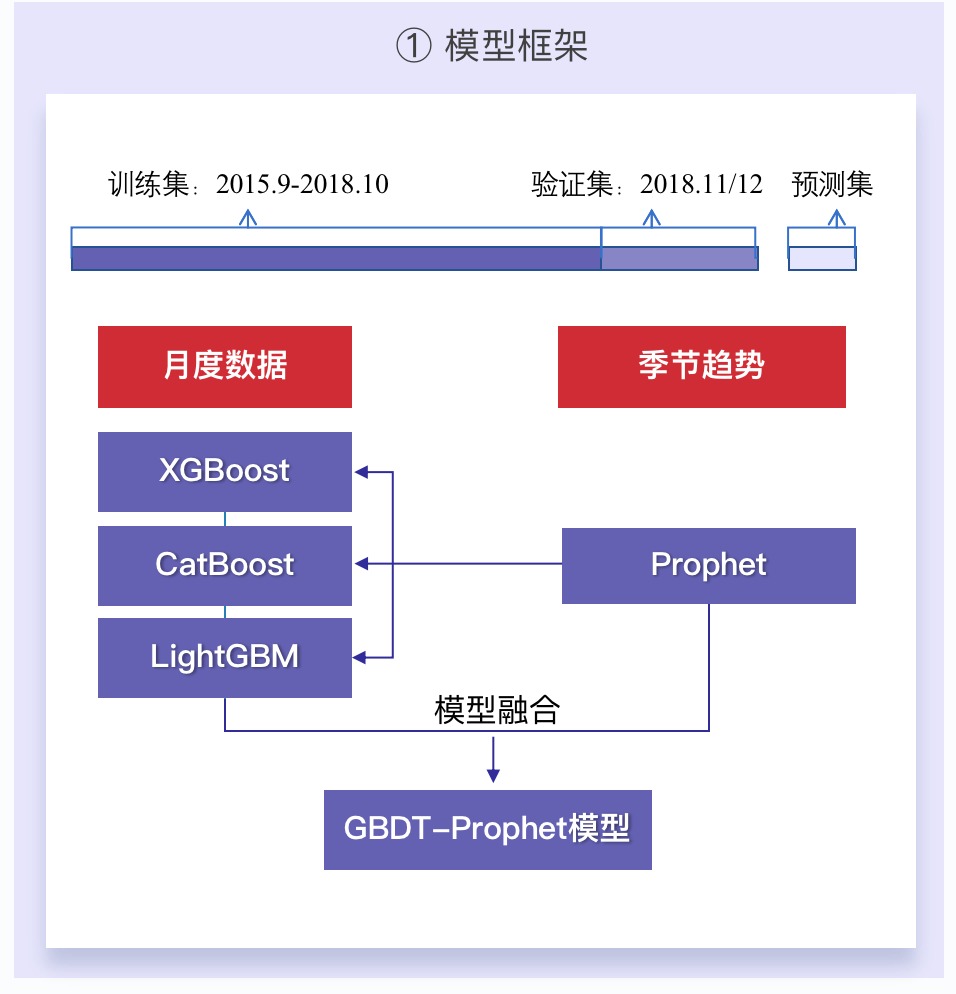
2.4 模型建立
2.4.1 模型框架和评价指标
-
题目非常离谱的要按日/周/月分别建模预测。实际上能做好月的就不错了,因为不然你要做三组特征,这是不可能的。
-
我们的解法就是按照月预测,不断的优化。日/周的就prophet随便预测一下就行。但在这个过程中,我们发现prophet不仅可以预测,还可以提取一些季节性特征。
-
因为我们做的特征实际上是缺少季节性的,所以就融入了这部分来自prophet提取的特征,也发现效果确实不错。
-
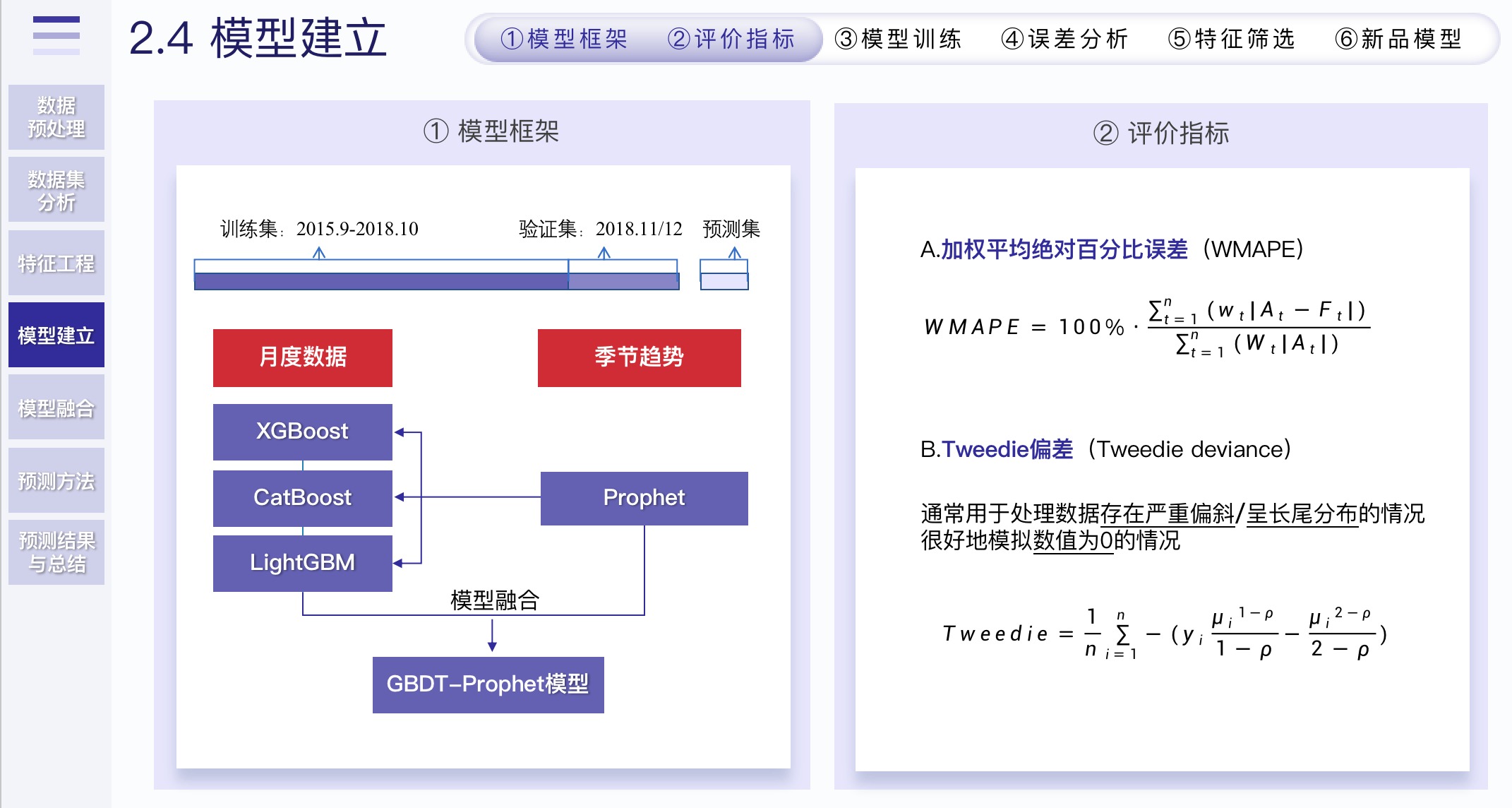
2.4.2 模型建立
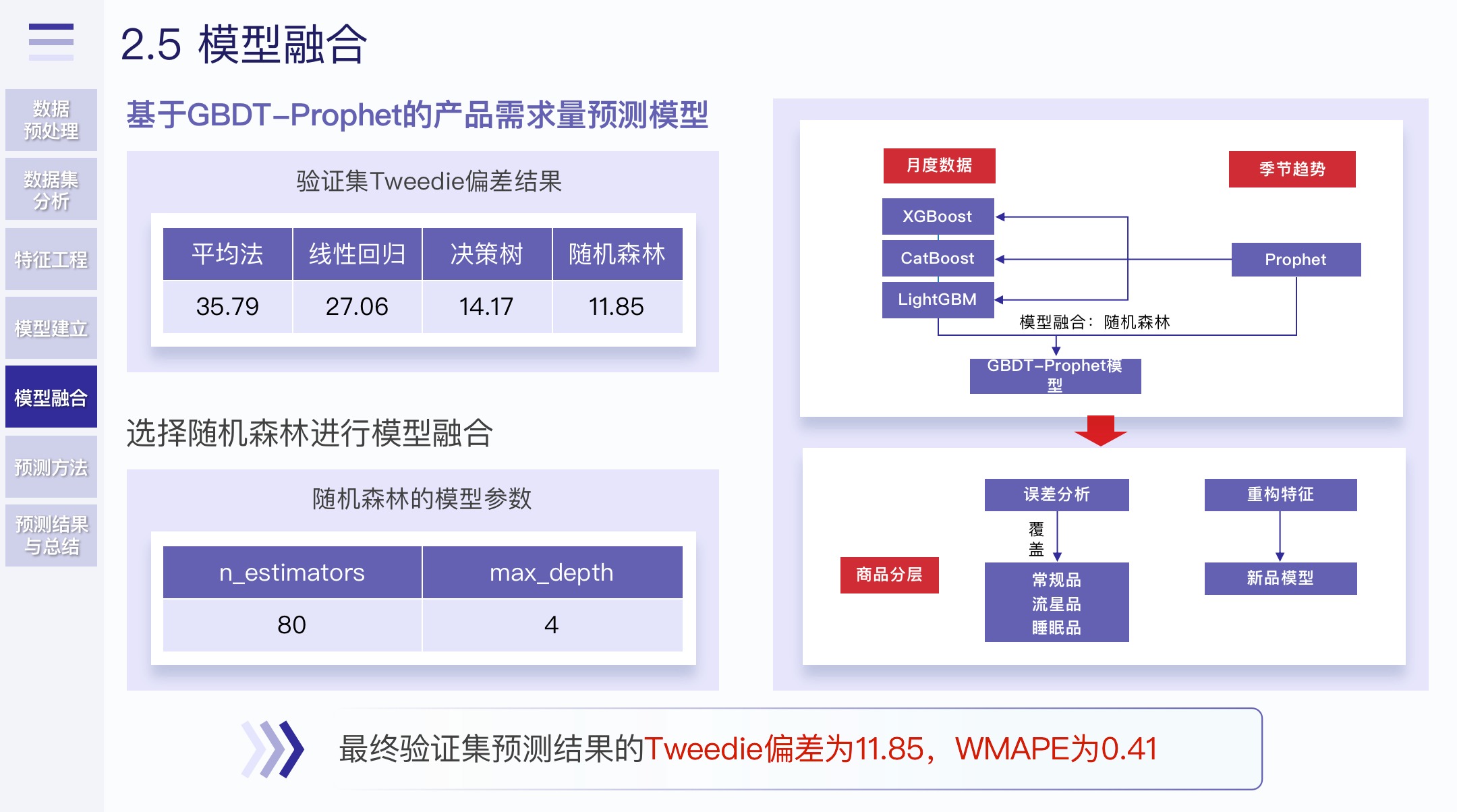
- 模型选择的话,我们Baseline使用LightGBM做的,因为其训练时间最快,方便我们不断优化
- 最后使用了三种梯度提升树算法(LightGBM、CatBoost、XGBoost)进行模型融合
- 该怎么说呢,效果肯定是很好的,但是这样也会带来过拟合。实际上,其实不用那么复杂,用一个模型也许效果最好

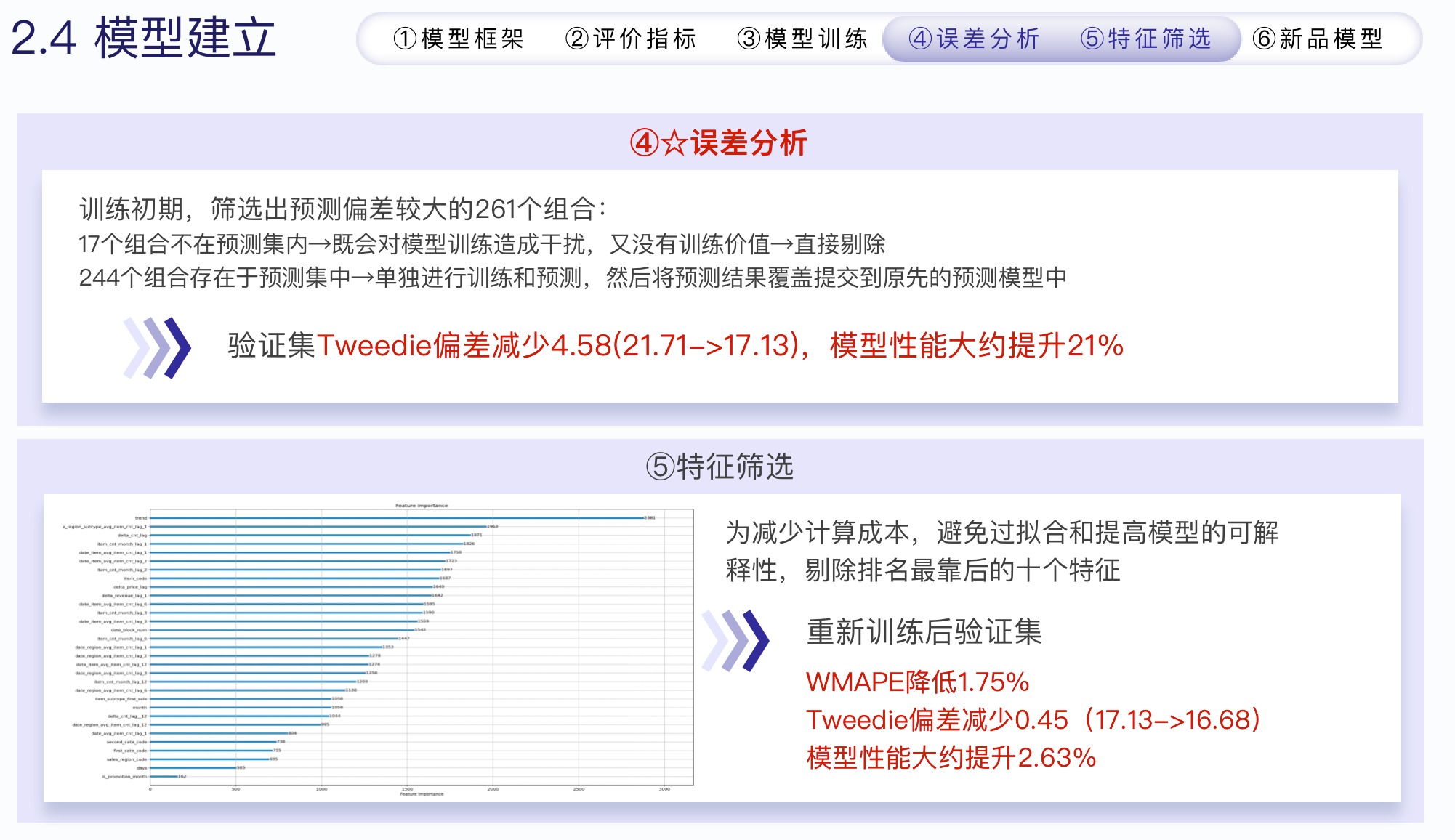
2.4.3 误差分析和特征筛选
- 误差分析
- 在训练前期的帮助很大
- 重新预测误差大的商品,并将预测值覆盖提交到原先的模型中
- 特征筛选
- 剔除没啥用的特征
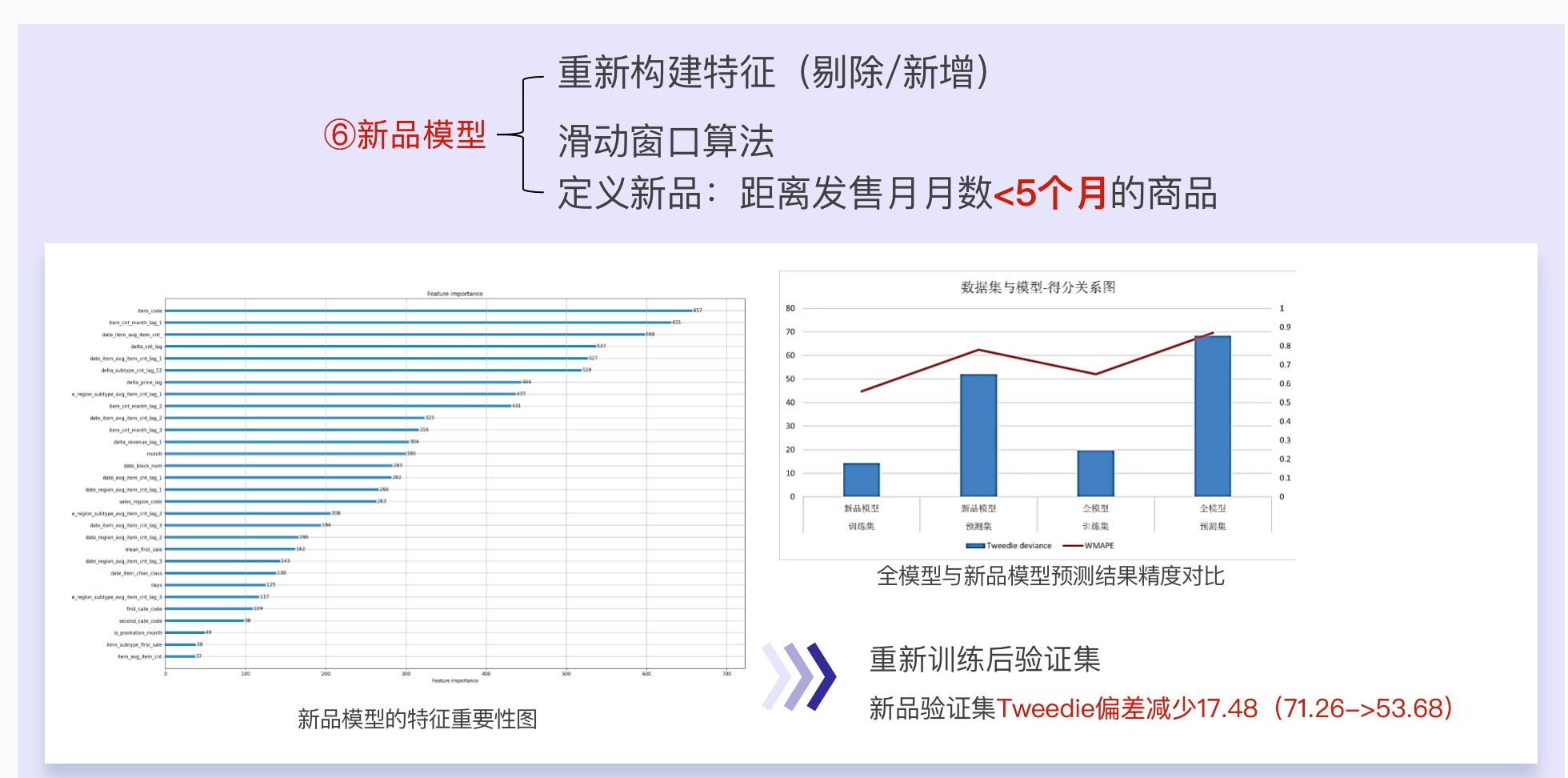
2.4.4 新品模型
- 对于新品,我们使用滑动窗口提取出每个月的新品,来组成新品模型的训练集和预测集
- 并且重新进行特征工程,因为新品没啥历史数据,预测只能靠同类商品的一些信息,所以我们做的特征往这个方向靠
2.5 模型融合
比较了一下,选定了进行模型融合的方法
还是那句话,模型太复杂并不代表真正的预测效果越好。但是这些工作在论文的展现中是需要的。
2.6 预测方法
我们还测试了三种预测方法。因为题目要求预测往后三个月的数据。
直接预测、滚动预测应该比较好理解。
滞后预测需要重新做特征,比如预测M+2月的销售量。我们是不能用M+1月的数据做特征的

2.7 总结

结尾
先吐槽一下本次比赛的题目,题目的数据感觉质量不是太好,前期做起来很头疼,也许是销量数据的通病。第二问的按日/周/月精度分别预测让人很难理解。再吐槽一下评委,私以为能进入答辩的队伍应该都是用机器学习/深度学习对整个数据集一起训练的,评委应该focus我们工作的创新点。但是评委貌似无法理解,认为我们怎么能用到了Prophet但又不用一个个训练,好像很难理解用机器学习怎么对每个商品进行预测。我们达到的是全局最优而不是每个商品最优,这跟用不用Prophet无关(我们只是用了Prophet来一个个提取特征,总体的工作是用LGBM不断优化的)。
还有就是这个比赛需要先提交论文和预测数据(2019年1、2、3月的数据),提交的后一天又会给出1、2、3月的数据,要求在预测一遍4、5、6月的数据。当时都五一放假了喂,那天早上发现1月份的真实销售数据销量很高,总体大概是预测的2~3倍。然后我就发现5月的数据也有可能很高,就重新改代码,总结了每一类商品的每月销售特征,又预测了一天。最终相信效果应该是不错的。合理的运用Trick来提升预测精度也是获奖必不可少的部分!
最后致谢一下吧。感谢我的两位队友的努力,感谢npy的作图和比赛期间的理解、感谢学姐学长的帮助和答辩指导、感谢我的指导老师。希望这篇总结能帮助到别人。
相关文章:
【复盘与分享】第十一届泰迪杯B题:产品订单的数据分析与需求预测
文章目录 题目第一问第二问2.1 数据预处理2.2 数据集分析2.2.1 训练集2.2.2 预测集 2.3 特征工程2.4 模型建立2.4.1 模型框架和评价指标2.4.2 模型建立2.4.3 误差分析和特征筛选2.4.4 新品模型 2.5 模型融合2.6 预测方法2.7 总结 结尾 距离比赛结束已经过去两个多月了。 整个过…...
X - Transformer
回顾 Transformer 的发展 Transformer 最初是作为机器翻译的序列到序列模型提出的,而后来的研究表明,基于 Transformer 的预训练模型(PTM) 在各项任务中都有最优的表现。因此,Transformer 已成为 NLP 领域的首选架构&…...
ubuntu下畅玩Seer(via wine)
第一步:安装wine 部分exe文件的运行需要32位的指令集架构,需要向Ubuntu系统中添加一个新的架构(i386),以支持32位的软件包。因为在64位的Ubuntu系统中,默认情况下只能安装和运行64位的软件。 通过添加i386…...

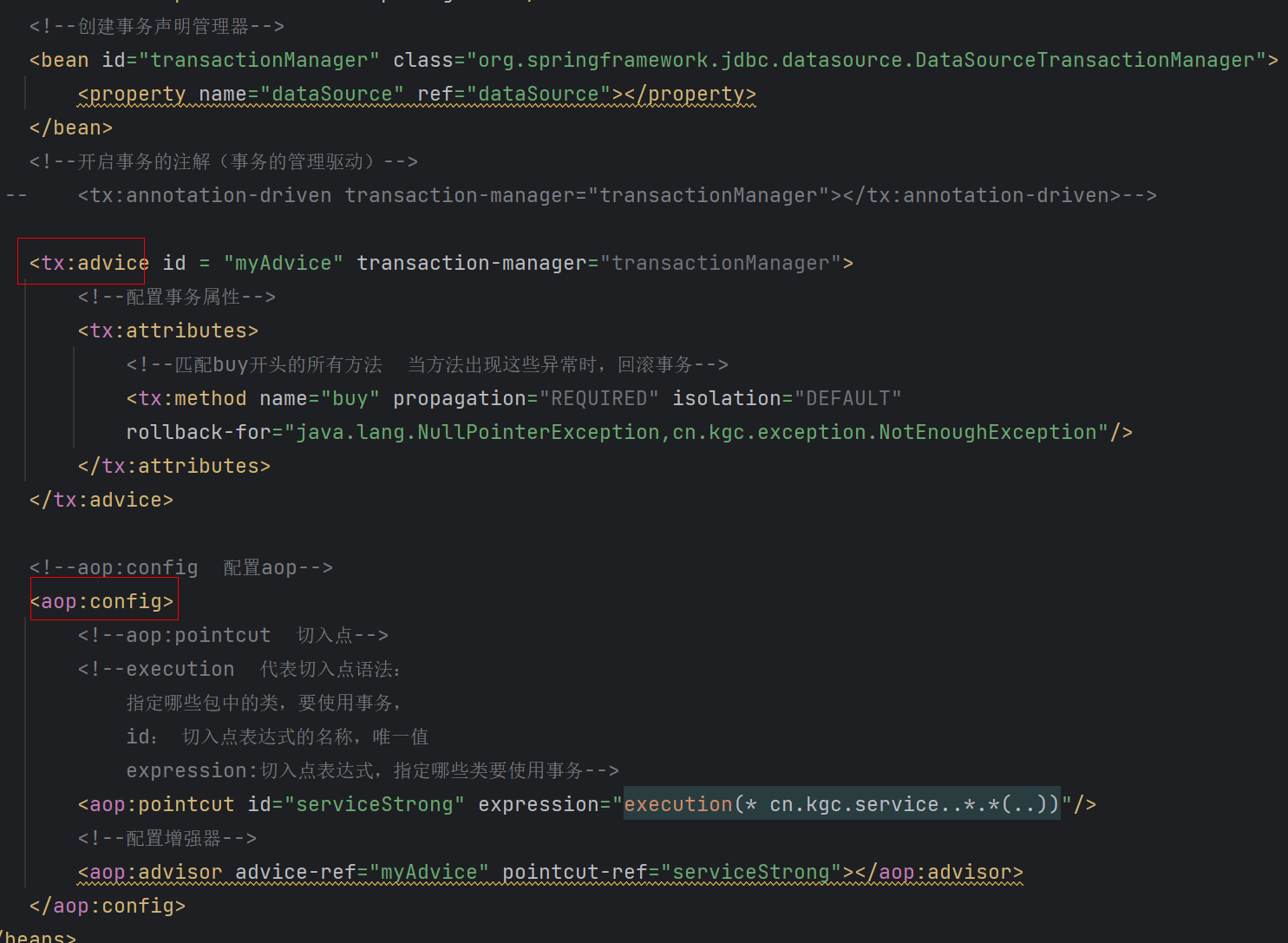
第五章:Spring下
第五章:Spring下 5.1:AOP 场景模拟 创建一个新的模块,spring_proxy_10,并引入下面的jar包。 <packaging>jar</packaging><dependencies><dependency><groupId>junit</groupId><artifactI…...
)
在CSDN学Golang云原生(Kubernetes基础)
一,k8s集群安装和升级 安装 Golang K8s 集群可以参照以下步骤: 准备环境:需要一组 Linux 服务器,并在每台服务器上安装 Docker 和 Kubernetes 工具。初始化集群:使用 kubeadm 工具初始化一个 Kubernetes 集群。例如&…...
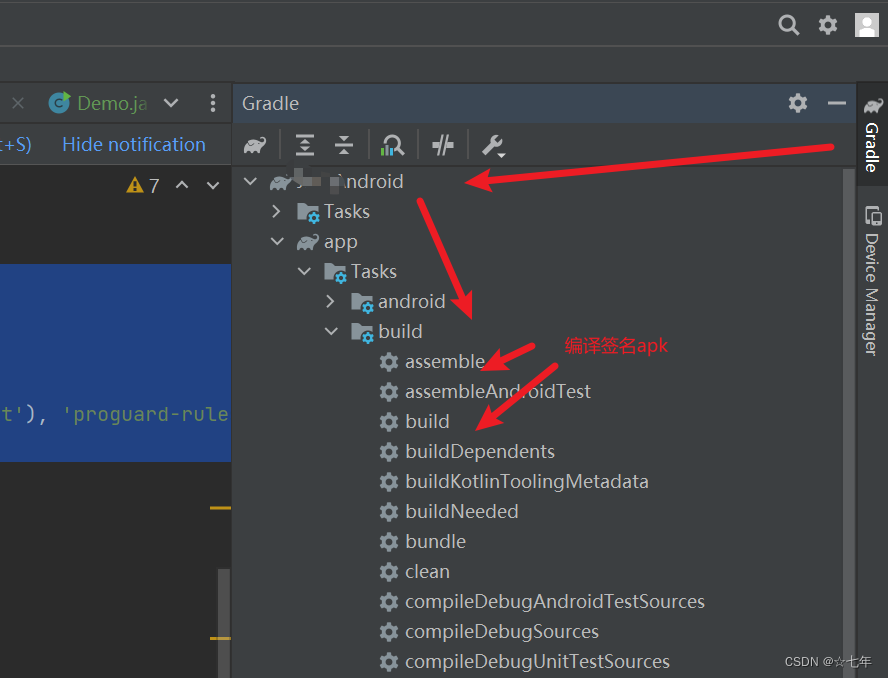
给APK签名—两种方式(flutter android 安装包)
前提:给未签名的apk签名,可以先检查下apk有没有签名 通过命令行查看:打开终端或命令行界面,导入包含APK文件的目录,并执行以下命令: keytool -printcert -jarfile your_app.apk 将 your_app.apk替换为要检查…...
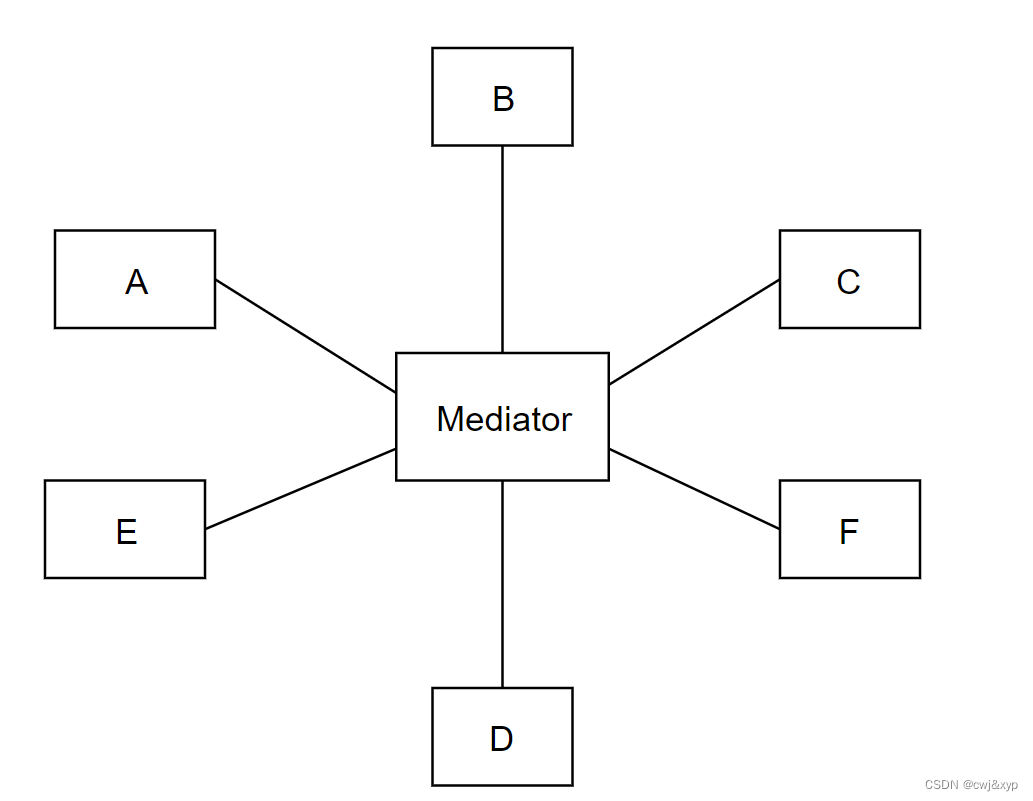
观察者模式、中介者模式和发布订阅模式
观察者模式 定义 观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新 观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式…...

PHP-Mysql图书管理系统--【白嫖项目】
强撸项目系列总目录在000集 PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 首页phpStudy 设置导数据库后台的管理界面数据库表结构项目目录如图:代码部分:主页的head 配套资源作业: 本系列校训 用免费公开视频&am…...
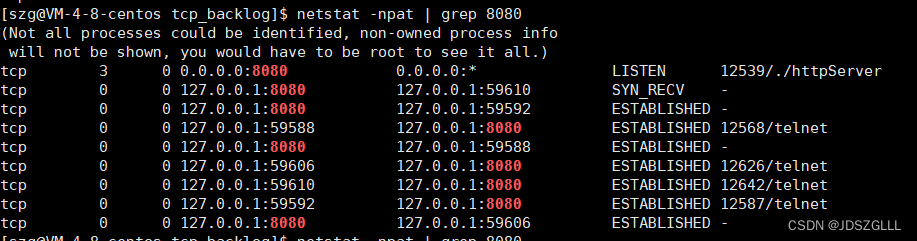
网络传输层协议:UDP和TCP
背景知识 再谈端口号 端口号(Port)标识了一个主机上进行通信的不同的应用程序; 在TCP/IP协议中, 用 "源IP", "源端口号", "目的IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信(可以通过 netstat -…...

ElementUI Select选择器如何根据value值显示对应的label
修改前效果如图所示,数据值状态应显示为可用,但实际上仅显示了状态码1,并没有显示其对应的状态信息。在排查了数据类型对应关系问题后,并没有产生实质性影响,只好对代码进行了如下修改。 修改前代码: <…...

Kotlin 内联函数语法之let、apply、also、run、with的用法与详解
一、介绍 kotlin的语法千奇百怪,今天我们将介绍项目中频率使用比较高的几个内联函数。 二、什么叫内联函数? 内联函数 的语义很简单:把函数体复制粘贴到函数调用处 。使用起来也毫无困难,用 inline关键字修饰函数即可。 语法&a…...

Swift 中如何判断是push 过来的页面 还是present过来的 页面
在 Swift 中,可以通过检查当前视图控制器的 presentingViewController 属性来判断是通过 push 过来的页面还是 present 过来的页面。 下面是一个示例代码,展示如何判断是通过 push 还是 present 过来的页面: if let presentingViewControll…...

基于K8s环境·使用ArgoCD部署Jenkins和静态Agent节点
今天是「DevOps云学堂」与你共同进步的第 47天 第⑦期DevOps实战训练营 7月15日已开营 实践环境升级基于K8s和ArgoCD 本文节选自第⑦期DevOps训练营 , 对于训练营的同学实践此文档依赖于基础环境配置文档, 运行K8s集群并配置NFS存储。实际上只要有个K8s集…...

874. 模拟行走机器人
874. 模拟行走机器人 机器人在一个无限大小的 XY 网格平面上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令 commands : -2 :向左转 90 度-1 :向右转 90 度1 < x < 9 :…...

【Linux】- RPM 与 YUM
RPM 与 YUM 1.1 rpm 包的管理1.2 rpm 包的简单查询指令1.3 rpm 包的其它查询指令:1.4 卸载 rpm 包:2.1 安装 rpm 包3.1 yum3.2 yum 的基本指令3.3 安装指定的 yum 包3.4 yum 应用实例: 1.1 rpm 包的管理 介绍 rpm 用于互联网下载包的打包及安…...

Visual Studio 2015编译器 自动生成 XXX_EXPORTS宏
XXX_EXPORTS宏 XXX_EXPORTS宏是由Visual Studio 2015编译器自动生成的。这个宏用于标识当前项目是一个导出符号的动态链接库(DLL)项目。在使用Visual Studio 2015创建Win32项目时,编译器会自动添加这个宏到项目的预定义宏中。 这个宏的作用…...

HTML5的应用现状与发展前景
HTML5,作为Web技术的核心,已经深深地改变了我们看待和使用Web的方式。它不仅提供了数不尽的新特性和功能,还使得Web设计和开发更加互动、更加直观。这篇文章将探讨HTML5的当前应用现状,以及它的未来发展前景。 HTML5的应用现状 H…...
day44-Spring_AOP
0目录 1.2.3 1.Spring_AOP 实体类: Mapper接口: Service和实现类: 测试1: 运行后: 测试2:无此型号时 测试3:库存不足时 解决方案1:事务声明管理器 测试:…...

selenium IDE 接入jenkins-转载
Selenium-IDE脚本录制,selenium-side-runner自动化测试教程_51CTO博客_selenium ide录制脚本 备忘录...
)
云计算结合数据科学突破信息泛滥(下)
大家好,本文将继续讨论云计算结合数据科学突破信息泛滥的相关内容,讲述其余三个关键组成部分。 3.数据清理和预处理 收集数据并将其存储在云端之后,下一步是将数据进行转换。因为原始数据经常包含错误、不一致和缺失的值,这些都…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构
深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构 【免费下载链接】zenodo_get Zenodo_get: Downloader for Zenodo records 项目地址: https://gitcode.com/gh_mirrors/ze/zenodo_get 在科研数据管理领域,高效的数据下载工具…...

LaTeX公式秒变Word格式:告别复制粘贴的烦恼,让数学表达更自由
LaTeX公式秒变Word格式:告别复制粘贴的烦恼,让数学表达更自由 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术…...

基于可解释机器学习的心电图预测胸片异常:技术原理与临床实践
1. 项目概述:当心电图“看见”胸片在急诊室或者基层医疗点,一个呼吸急促、胸痛的患者被送来,临床医生面临的首要决策往往是:是否需要立刻安排胸部X光检查?胸片是评估心肺和胸腔状况的基石,但它需要设备、技…...

Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目
Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目 【免费下载链接】mapbox-studio-classic 项目地址: https://gitcode.com/gh_mirrors/ma/mapbox-studio-classic Mapbox Studio Classic是一款强大的地图设计工具,通过直观的界面和简…...

VTube Studio插件开发终极教程:构建你的第一个互动工具
VTube Studio插件开发终极教程:构建你的第一个互动工具 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio VTube Studio是一款功能强大的虚拟主播软件,提供了丰富的API接…...

高光谱成像与机器学习:LDA+SVM/KNN实现蜂蜜植物源精准鉴别
1. 项目概述:当高光谱成像遇上机器学习,如何为蜂蜜“验明正身”?在食品行业,尤其是像蜂蜜这样的高价值农产品领域,“真实性”一直是消费者和生产者共同关注的焦点。一瓶标着“新西兰麦卢卡”或“东北椴树蜜”的蜂蜜&am…...