对神经网络基础的理解
目录
一、《python神经网络编程》
二、一些粗浅的认识
1) 神经网络也是一种拟合
2)神经网络不是真的大脑
3)网络构建需要反复迭代
三、数字图像识别的实现思路
1)建立一个神经网络类
2)权重更新的具体实现
3)网络测试
四、总结
一、《python神经网络编程》
最近学习了一本书《python神经网络编程》,该书通过对一个数字识别案例的深入详细讲解,可以让读者对神经网络的思想有更加清晰的理解,明白计算机神经网络是如何工作的。在没有真正接触神经网络之前,总以为这是非常深奥的理论,也不明白神经网络是如何模拟人的大脑进行学习和判断的,难以理解计算机能够模拟人的大脑。《python神经网络编程》确实是一本很好的入门教材,它让读者能够真正踏入人工智能的门槛,奠定深入研究的基础。
二、一些粗浅的认识
1) 神经网络也是一种拟合
在数学中有很多拟合方法,比如线性拟合、多项式拟合等等。在这些拟合中,我们同样需要有确定的已知数据,然后通过这些拟合方法我们可以得到一个确定的数学解析表达式,并通过这个表达式来预测未知的结果。而神经网络的核心思想,我想也是一样的,只是这个实现过程相对复杂。我们最终能得到的是一个预测网络,也称模型,而不是一个精确的数学方程表达式。我们使用已知输入和输出的大量数据来训练神经网络,就是在让这个网络的输出结果逐渐逼近已知的输出结果。这个网络在训练的过程中,最终建立起了输入与输出之间的对应关系。但是这个对应关系我们无法用一个清晰的数学表达式来描述,可是我们可以使用这个网络来进行预测。正如对于图片中的数字而言,我们人看到图片中的数字就可以知道图中的数字是多少,因为在我们认识数字之前经过了学习,很多次有人告诉我们这个图形对应的数字就是这个数字。就像神经网络不能用一个准确的数学公式来描述输入与输出之间的关系一样,我们人类其实至今也还是不知道我们大脑学习的本质是什么。所以神经网络得到的拟合结果是一个黑盒子,我们针对特定的问题建立了一个黑盒子,然后训练了这个黑盒子,我们只知道给这个黑盒子一个输入,他能给出一个可信的结果。
2)神经网络不是真的大脑
神经网络只是借用了人类大脑神经元的形式。计算机神经网络是否真的能实现动物大脑的能力,我想还是难以断定。我们以前总是认为计算机的工作都是确定的,给它一个输入,我们必然能够准确预测它的输出结果。其实现在的神经网络也是一样的,虽然它是个黑盒子,但是给它相同的输入,它必然能够得到相同的结果,即使我们不知道它具体的计算逻辑,因为在这个网络中所有的参数经过训练后已经确定,计算机计算的每一步都是确定的。但计算机神经网络这种模糊拟合的实现,让我们认识到,当大量简单计算累计到一定数量时,在庞大的信息传递中是否就存在不可预测性。我们不理解自己为什么会思考,或许在不久的将来我们也无法确信庞大计算机系统的运行的真是我们人类设计的程序。
3)网络构建需要反复迭代
在构建神经网络过程中,输入与输出的节点数量需要根据实际问题进行分析。我们需要根据解决的实际问题,分析如何将问题的输入数字化,并设计相应的输入节点。而对于输出也是一样,我们需要分析如何用输出的数字信息来表达我们想要的结果形式,并设计相应的输出节点。我们常见的简单的神经网络通常是3层,包括输入、输出和中间的隐藏层,而隐藏层的层数以及每层的节点数该如何设计,这需要通过不断的尝试。较少的层数和节点数能够获得较高的计算效率,但是性能较低,误差较大,较多的层数和节点数能够获得较高的精度,但是计算效率低。因此,针对具体的问题需要综合考虑,反复迭代后确定网络构建形式。
三、数字图像识别的实现思路
1)建立一个神经网络类
《python神经网络编程》书中给出了一个实现数字识别的例子。在Python中首先定义一个3层神经网络类neuralNetwork。在类的初始化函数中确定网络的输入层节点数、隐藏层节点数、输出层节点数和学习率4个参数。并确定使用的激活函数。输入层与隐藏层、隐藏层和输出层之间的初始权重矩阵随机生成。
训练神经网络时,先根据训练数据的输入,正向逐层计算,最后得到网络的输出结果。然后计算网络输出结果与实际结果的误差值,然后再将误差进行反向传播,更新权重矩阵。这样,一组数据的训练就完成。
网络输出就是利用测试数据对网络进行一次正向输出的过程,最后根据输出数据给出网络的图像识别结果,具体实现后面再叙述。
class neuralNetwork:# 初始化函数def __int__(self, inputnodes, hiddennodes, outputnodes, learningrate):self.inodes = inputnodes # 输入节点数self.hnodes = hiddennodes # 隐藏节点数self.onodes = outputnodes # 输出节点数self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes)) # 随机生成初始的输入层到隐藏层的权重矩阵self.who = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes)) # 随机生成初始的隐藏层到输出层的权重矩阵self.learn = learningrate # 权重更新率self.active_function = lambda x: scipy.special.expit(x) # 选择需要使用的激活函数pass# 定义训练函数def train(self, input_list, target_list): # 提供已知的输入和输出结果inputs = numpy.array(input_list, ndmin=2).T # 将输入转换为二维矩阵形式targets = numpy.array(target_list, ndmin=2).Thidden_inputs = numpy.dot(self.wih, inputs) # 计算隐藏层的输入值,输入层到隐藏层的权重矩阵乘以输入hidden_outputs = self.active_function(hidden_inputs) # 计算隐藏层的输出值,将隐藏层的输入值带入激活函数final_inputs = numpy.dot(self.who, hidden_outputs) # 计算输出层的输入值,隐藏层到输出层的权重矩阵乘以隐藏层的输出值final_outputs = self.active_function(final_inputs) # 计算输出层的输出结果,将输出层的输入值带入激活函数output_errors = targets - final_outputs # 计算误差值,已知的输出结果-输出层的输出值hidden_errors = numpy.dot(self.who.T, output_errors) # 传递误差# 更新权重矩阵self.who += self.learn * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)),numpy.transpose(hidden_outputs))self.wih += self.learn * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)),numpy.transpose(inputs))pass# 定义输出函数def query(self, input_list):inputs = numpy.array(input_list, ndmin=2).Thidden_inputs = numpy.dot(self.wih, inputs)hidden_outputs = self.active_function(hidden_inputs)final_inputs = numpy.dot(self.who, hidden_outputs)final_outputs = self.active_function(final_inputs)return final_outputs
2)权重更新的具体实现
权重矩阵反复更新,就是神经网络不断学习,获得正确拟合结果的过程。权重更新根据严格的数学推导公式,程序实现过程不能直观反映具体的实现思想。它的核心就是利用每次训练的计算误差来修正权重矩阵。
(1)误差计算
在训练神经网络过程中计算误差时,程序中我们直接将实际结果与计算结果相减(output_errors = targets - final_outputs),得到一个误差向量。但是理论分析时,直接相减计算误差的方法并不合适,我们通常使用差的平方来表示,所有节点的总误差如下:
(2)误差传递
我们可以直接计算出输出层的误差,但是最终的误差是由前面的计算逐层、逐节点计算累计得到的,该如何将最终的误差反向分配到每个节点上呢?通常我们认为节点之间连接权重越大的链路,计算引入的误差也越大,因此,我们也同样通过权重来分配误差。针对本例而言,我们已经得到了输出层的误差,还需要计算隐藏层的误差。输入层不需要计算,因为默认输入层输入与输出是相同的,不需要使用激活函数。那么隐藏层的输出误差计算如下:
此处需要注意的是,误差反向传播计算的矩阵正好是正向计算时隐藏层到输出层权重矩阵的转置,至于为什么是转置,我们手动简单计算一下就知道了。同时需要注意的是,通过上式计算得到的总误差并不是输出层的总误差() 。因为,更新权重矩阵时,我们其实并不关心过程中的误差大小,而是更关心是哪个链路导致的误差更大,只要能体现出各链路误差的相对大小就可以。
(3)更新权重
在此例中使用跟新权重的方法是梯度下降法,这也是使用非常广泛的一种方法。我们需要建立起权重与误差之间的关系。我们以最后的输出层为例,输出层的输入是隐藏层的输出乘以隐藏层和输出层之间的权重矩阵:
将此结果代入激活函数,则输出层的结果为:
sigmoid函数为激活函数,形式为:
则每个节点的输出误差为:
将上述公式联合,然后对权重w求导,就可以得到误差相对于权重的导数(斜率):
权重更新公式为:
上述公式中,我们实际使用时并不关心常系数2,因此在代码实现时省略了。
3)网络测试
网络测试的具体实现可参见代码。
# 测试网络
scorecard = []
i = 0
for record in test_data_list:i += 1if(i != 10): # 可调整数字,逐张识别continuepassall_values = record.split(',')correct_label = int(all_values[0])inputs = (numpy.asarray(all_values[1:], numpy.float32) / 255.0 * 0.99) + 0.01image_array = numpy.asarray(all_values[1:], numpy.int32).reshape((28, 28))fig = matplotlib.pyplot.figure(figsize=(5, 5))matplotlib.pyplot.imshow(image_array, cmap='Greys', interpolation='None')matplotlib.pyplot.show()outputs = n.query(inputs) # 网络识别的结果label = numpy.argmax(outputs) # 输出结果中的最大值print("输入数字:", all_values[0], "识别结果:", label) # 打印出实际值if(label == correct_label):scorecard.append(1)else:scorecard.append(0)passpassscorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum() / scorecard_array.size)四、总结
《python神经网络编程》与书中的示例简明阐述了神经网络的核心思想和基本架构,任何复杂的神经网络均可基于此构建。我们可以通过使用不同的网络层数、节点数、激活函数以及链路连接方式等,构建不同的适用于各种应用的神经网络模型。或许正式因为神经网络内部的不可描述性,对网络结构的各种优化,为研究神经网络开辟了广阔空间。
相关文章:
对神经网络基础的理解
目录 一、《python神经网络编程》 二、一些粗浅的认识 1) 神经网络也是一种拟合 2)神经网络不是真的大脑 3)网络构建需要反复迭代 三、数字图像识别的实现思路 1)建立一个神经网络类 2)权重更新的具体实现 3&am…...
用法)
.strip()用法
.strip("") 是 Python 字符串方法 strip() 的一个用法,它会去除字符串两端指定字符集中的字符。 基本语法: string.strip([chars])string: 这是你要操作的字符串。chars: 可选参数,表示你想要去除的字符集(默认为空格…...

redis的分片集群模式
redis的分片集群模式 1 主从哨兵集群的问题和分片集群特点 主从哨兵集群可应对高并发写和高可用性,但是还有2个问题没有解决: (1)海量数据存储 (2)高并发写的问题 使用分片集群可解决,分片集群…...

【29】Word:李楠-学术期刊❗
目录 题目 NO1.2.3.4.5 NO6.7.8 NO9.10.11 NO12.13.14.15 NO16 题目 NO1.2.3.4.5 另存为手动/F12Fn光标来到开头位置处→插入→封面→选择花丝→根据样例图片,对应位置填入对应文字 (手动调整即可)复制样式:开始→样式对话框→管理…...

基于 AI Coding 「RTC + STT」 Web Demo
文章目录 1. 写在最前面1.1 旧测试流程1.2 新测试流程 2. Cursor 编程 vs Copilot 编程2.1 coding 速度2.2 coding 正确性 3. 碎碎念 1. 写在最前面 为了 Fix 语音转文字(STT)产品在 Json 协议支持上的问题,笔者需要将推送到 RTC 的数据按照…...

doris:Parquet导入数据
本文介绍如何在 Doris 中导入 Parquet 格式的数据文件。 支持的导入方式 以下导入方式支持 Parquet 格式的数据导入: Stream LoadBroker LoadINSERT INTO FROM S3 TVFINSERT INTO FROM HDFS TVF 使用示例 本节展示了不同导入方式下的 Parquet 格式使用方法…...

L2TP使用举例
下面是一个使用C和POSIX套接字API实现L2TP协议的简单示例。这个示例展示了如何创建一个L2TP客户端,连接到L2TP服务器并发送数据。请注意,这只是一个基本的示例,实际的L2TP实现会更复杂,通常需要处理更多的协议细节和错误处理。 L…...

dup2 + fgets + printf 实现文件拷贝
思路 将源文件的内容读取到内存中,然后将这些内容写入到目标文件。 1: 打开源文件、目标文件 fopen() 以读模式打开源文件。 open ()以写模式打开目标文件。 2: 读取源文件、写入目标文件 fgets ()从源文件中读取内容。 printf ()将内容写入目标文件。 printf…...
)
实验六 带函数查询和综合查询(1)
实验六 带函数查询和综合查询(1) 一、实验目的 1.掌握Management Studio的使用。 2.掌握带函数查询和综合查询的使用。 二、实验内容及要求 1统计年龄大于30岁的学生的人数。 select count(*) from student where year(getdate…...
:大阿卡那牌)
塔罗牌(基础):大阿卡那牌
塔罗牌(基础) 大啊卡那牌魔术师女祭司皇后皇帝教皇恋人战车力量隐士命运之轮正义吊人死神节制恶魔高塔星星月亮太阳审判世界 大啊卡那牌 魔术师 作为一个起点,象征:意识行动和创造力。 一个【显化】的概念,即是想法变…...

LLM大模型推理中的常见数字
1. 聊天机器人Chatbot,一般,input tokens : output tokens 1100:15 2. LLama2的tokenizer,中文情况下,token:汉字1:1.01 3. prefilling阶段的吞吐量(tokens/s),一般是decoding阶段的50~100倍。 4. 4张带有NVLink的…...

[ACTF2020 新生赛]Upload1
题目 以为是前端验证,试了一下PHP传不上去 可以创建一个1.phtml文件。对.phtml文件的解释: 是一个嵌入了PHP脚本的html页面。将以下代码写入该文件中 <script languagephp>eval($_POST[md]);</script><script languagephp>system(cat /flag);&l…...

SpringBoot整合Swagger UI 用于提供接口可视化界面
目录 一、引入相关依赖 二、添加配置文件 三、测试 四、Swagger 相关注解 一、引入相关依赖 图像化依赖 Swagger UI 用于提供可视化界面: <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactI…...

深度学习项目--基于LSTM的糖尿病预测探究(pytorch实现)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 LSTM模型一直是一个很经典的模型,一般用于序列数据预测,这个可以很好的挖掘数据上下文信息,本文将使用LSTM进行糖尿病…...

LeetCode - Google 大模型校招10题 第1天 Attention 汇总 (3题)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145368666 GroupQueryAttention(分组查询注意力机制) 和 KVCache(键值缓存) 是大语言模型中的常见架构,GroupQueryAttention 是注意力…...

人工智能研究报告:技术、应用与未来趋势洞察
一、引言 1.1 研究背景 在当今科技飞速发展的时代,人工智能(Artificial Intelligence,简称 AI)已成为最为关键的技术领域之一。它犹如一股强大的变革力量,正深刻地重塑着各行业的发展格局,对社会的各个层…...

Kotlin开发(七):对象表达式、对象声明和委托的奥秘
Kotlin 让代码更优雅! 每个程序员都希望写出优雅高效的代码,但现实往往不尽人意。对象表达式、对象声明和 Kotlin 委托正是为了解决代码中的复杂性而诞生的。为什么选择这个主题?因为它不仅是 Kotlin 语言的亮点之一,还能极大地提…...

数据库、数据仓库、数据湖有什么不同
数据库、数据仓库和数据湖是三种不同的数据存储和管理技术,它们在用途、设计目标、数据处理方式以及适用场景上存在显著差异。以下将从多个角度详细说明它们之间的区别: 1. 数据结构与存储方式 数据库: 数据库主要用于存储结构化的数据&…...

【2024年华为OD机试】 (B卷,100分)- 字符串摘要(JavaScriptJava PythonC/C++)
一、问题描述 题目描述 给定一个字符串的摘要算法,请输出给定字符串的摘要值。具体步骤如下: 去除字符串中非字母的符号:只保留字母字符。处理连续字符:如果出现连续字符(不区分大小写),则输…...

DIY QMK量子键盘
最近放假了,趁这个空余在做一个分支项目,一款机械键盘,量子键盘取自固件名称QMK(Quantum Mechanical Keyboard)。 键盘作为计算机或其他电子设备的重要输入设备之一,通过将按键的物理动作转换为数字信号&am…...

mamba论文学习
rnn 1986 训练速度慢 testing很快 但是很快就忘了 lstm 1997 训练速度慢 testing很快 但是也会忘(序列很长的时候) GRU实在lstm的基础上改进,改变了一些门 transformer2017 训练很快,testing慢些,时间复杂度高&am…...

智慧消防营区一体化安全管控 2024 年度深度剖析与展望
在 2024 年,智慧消防营区一体化安全管控领域取得了令人瞩目的进展,成为保障营区安全稳定运行的关键力量。这一年,行业在政策驱动、技术创新应用、实践成果及合作交流等方面呈现出多元且深刻的发展态势,同时也面临着一系列亟待解决…...

解锁微服务:五大进阶业务场景深度剖析
目录 医疗行业:智能诊疗的加速引擎 电商领域:数据依赖的破局之道 金融行业:运维可观测性的提升之路 物流行业:智慧物流的创新架构 综合业务:服务依赖的优化策略 医疗行业:智能诊疗的加速引擎 在医疗行业迈…...

pip 安装 numpy 报错 AttributeError: module ‘pkgutil‘ has no attribute ‘ImpImporter‘
conda 环境下 pip 安装 numpy 1.x 版本,报如下错误 File "C:\Users\UserName\AppData\Local\Temp\pip-build-env-_lgbq70y\overlay\Lib\site-packages\pkg_resources\__init__.py", line 2191, in <module>register_finder(pkgutil.ImpImporter, fi…...

javascript-es6 (一)
作用域(scope) 规定了变量能够被访问的“范围”,离开了这个“范围”变量便不能被访问 局部作用域 函数作用域: 在函数内部声明的变量只能在函数内部被访问,外部无法直接访问 function getSum(){ //函数内部是函数作用…...

Babylon.js 中的 setHardwareScalingLevel和getHardwareScalingLevel:作用与配合修改内容
在 Babylon.js 中,Engine类提供了setHardwareScalingLevel和getHardwareScalingLevel方法,用于管理和调整渲染分辨率与屏幕分辨率的比例。这些方法在优化性能和提升画质方面非常有用。尤其是在某些平台不支持硬件反锯齿时,可以考虑使用setHar…...

二十三种设计模式-桥接模式
桥接模式(Bridge Pattern)是一种结构型设计模式,其核心思想是将抽象与实现解耦,让它们可以独立变化。桥接模式主要用于解决类的继承问题,避免由于继承而带来的类层次结构过于复杂和难以维护的问题。 1. 核心概念 桥接…...

jenkins-k8s pod方式动态生成slave节点
一. 简述: 使用 Jenkins 和 Kubernetes (k8s) 动态生成 Slave 节点是一种高效且灵活的方式来管理 CI/CD 流水线。通过这种方式,Jenkins 可以根据需要在 Kubernetes 集群中创建和销毁 Pod 来执行任务,从而充分利用集群资源并实现更好的隔离性…...

代码工艺:实践 Spring Boot TDD 测试驱动开发
TDD 的核心理念是 “先写测试,再写功能”,其过程遵循一个严格的循环,即 Red-Green-Refactor: TDD 的流程 1. Red(编写失败的测试) 根据需求,先编写一个测试用例,描述期望的行为。…...
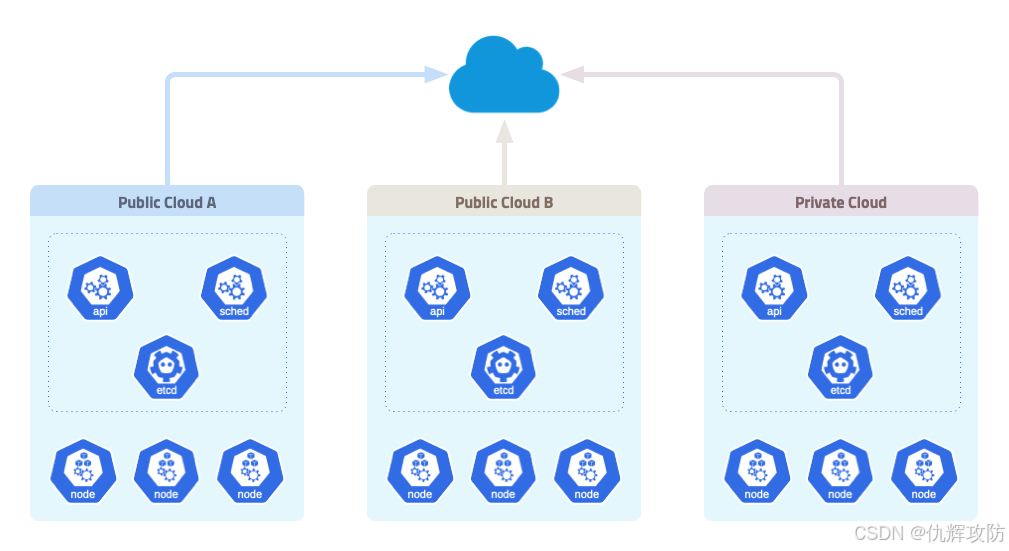
【云安全】云原生-K8S-简介
K8S简介 Kubernetes(简称K8S)是一种开源的容器编排平台,用于管理容器化应用的部署、扩展和运维。它由Google于2014年开源并交给CNCF(Cloud Native Computing Foundation)维护。K8S通过提供自动化、灵活的功能…...