循环神经网络(RNN)+pytorch实现情感分析
目录
一、背景引入
二、网络介绍
2.1 输入层
2.2 循环层
2.3 输出层
2.4 举例
2.5 深层网络
三、网络的训练
3.1 训练过程举例
1)输出层
2)循环层
3.2 BPTT 算法
1)输出层
2)循环层
3)算法流程
四、循环神经网络实现情感分析
4.1 实验介绍
4.2 数据集介绍
4.3 Embedding操作
4.4 pytorch实现
1)数据处理
2)模型设计
3)训练配置
4)训练过程
5)测试模型
一、背景引入
全连接神经网络和卷积神经网络在运行时每次处理的都是独立的输入数据,没有记忆功能。
有些应用需要神经网络具有记忆能力, 典型的是输入数据为时间序列的问题, 时间序列可以抽象地表示为一个向量序列:。
其中, 是向量, 下标 i 为时刻。 各个时刻的向量之间存在相关。 例如, 在说话时当前要说的词和之前已经说出去的词之间存在关系, 依赖于上下文语境。算法需要根据输入序列来产生输出值, 这类问题称为序列预测问题, 需要注意的是输入序列的长度可能不固定。
语音识别和自然语言处理是序列预测问题的典型代表。 语音识别的输入是一个语音信号序列, 自然语言处理的输入是文字序列。 下面用一个实际例子来说明序列预测问题, 假设神经网络要用来完成汉语填空, 考虑下面这个句子:
现在已经下午 2 点了, 我们还没有吃饭, 非常饿, 赶快去餐馆_____ 。
根据上下文的理解, 这个空的最佳答案是“吃饭”, 如果没有上下文, 去参观可以喝咖啡或者歇一会, 但结合前面的饿了, 最佳答案显然是“吃饭”。 为了完成这个预测, 神经网络需要依次输入前面的每一个词, 最后输入“餐馆” 这个词时, 得到预测结果。
神经网络的每次输入为一个词, 最后要预测出这个空的内容, 这需要神经网络能够理解语义, 并记住之前输入的信息, 即语句上下文。 神经网络要根据之前的输入词序列计算出当前使用哪个词的概率最大。
二、网络介绍
循环神经网络(Recurrent Neural Network, 简称 RNN) 是一种能够处理序列数据的神经网络模型。 RNN 具有记忆功能, 它会记住网络在上一时刻运行时产生的状态值, 并将该值用于当前时刻输出值的生成。
RNN 由输入层、 循环层和输出层构成, 也有可能还包含全连接层。 输入层和输出层与前馈型神经网络类似, 唯一不同的是循环层。
2.1 输入层
输入值通常是一个时间序列。每个输入样本由一系列按时间顺序排列的数据点组成,每个数据点可以是向量、标量或其他形式的数据。例如,在自然语言处理中,一个句子可以被视为一个时间序列,其中每个单词或字符代表一个时间步的输入。
2.2 循环层

循环神经网络的输入为向量序列, 每个时刻接收一个输入 , 网络会产生一个输出
, 而这个输出是由之前时刻的输入序列
共同决定的。
假设 t 时刻的状态值为 , 它由上一时刻的状态值
以及当前时刻的输入值
共同决定, 即:
是输入层到隐藏层的权重矩阵
是隐藏层内的权重矩阵,可以看作状态转移权重。其并不会随着时间变化, 在每个时刻进行计算时使用的是同一个矩阵。 这样做的好处是一方面减少了模型参数, 另一方面也记住了之前的信息。
为偏置向量
一个神经元更形象的表示如下:

循环神经网络中循环层可以只有一层, 也可以有多个循环层。
2.3 输出层
输出层以循环层的输出值作为输入并产生循环神经网络最终的输出, 它不具有记忆功能。 输出层实现的变换为:
为权重矩阵
为偏置向量
为激活函数。对于分类任务,
2.4 举例
一个简单的循环神经网络, 这个网络有一个输入层、 一个循环层和一个输出层。其中输入层有 2 个神经元, 循环层有 3 个神经元, 输出层有 2 个神经元。

- 循环层的输出
,其中输入向量是二维的, 输出向量是三维的
- 输出层的输出
,其中输入向量是三维的, 输出向量是二维的
递推:
按照时间轴进行展开, 当输入为 时, 网络的输出为:
当输入为 时, 网络的输出为:
输出值与都有关。 依此类推, 可以得到
时网络的输出值,
时的输出值与
都有关。
可以看出循环神经网络通过递推方式实现了记忆功能。
2.5 深层网络
可以构建含有多个隐藏层的网络,有3种方案
- Deep Input-to-Hidden Function:它在循环层之前加入多个全连接层, 将输入向量进行多层映射之后再送入循环层进行处理。
- Deep Hidden-to-Hidden Transition:它使用多个循环层, 这与前馈型神经网络类似, 唯一不同的是计算隐含层输出的时候需要利用本隐含层上一时刻的值。
- Deep Hidden-to-Output Function:它在循环层到输出层之间加入多个全连接层。
三、网络的训练
循环神经网络(RNN)处理序列数据,每个训练样本是一个时间序列,包含多个相同维度的向量。训练使用BPTT算法(Back Propagation Through Time 算法),先对序列中每个时刻的输入进行正向传播,再通过反向传播计算梯度并更新参数。每个训练样本的序列长度可以不同,前后时刻的输入值有关联。
3.1 训练过程举例
网络结构如下:

有一个训练样本, 其序列值为:。其中,
为输入向量,
为标签向量。 循环层状态的初始值设置为 0。
在 t=1 时刻, 网络的输出为:
在 t=2 时刻, 网络的输出为:
在 t=3 时刻, 网络的输出为:
对单个样本的序列数据, 定义 t 时刻的损失函数为:
样本的总损失函数为各个时刻损失函数之和:
1)输出层
如果输出层使用 softmax 变换, 则损失函数为 softmax 交叉熵:
梯度的计算公式为:
根据之前全连接神经网络中的推论:,
可以得到 t 时刻:
- 损失函数对输出层权重的梯度:
- 损失函数对偏置项的梯度为:
故得到总时刻:
- 总损失函数对权重的梯度为:
- 总损失函数对偏置项的梯度为:
2)循环层
按时间序列展开之后, 各个时刻在循环层的输出值是权重矩阵和偏置项的复合函数。
在 t=1 时刻,
根据全连接神经网络中的推论
可以得到损失函数对 的梯度:

由于 t=1 时循环层的输出值与 无关, 因此:
对偏置项的偏导为:
在 t=2 时刻, 。当前式子中
出现了两次, 因此损失函数对
的梯度为:
又由于:,故有
可以得到损失函数对 的梯度为:

损失函数对 的梯度为:

在 t=3 时刻, 。当前式子中
出现了三次, 因此损失函数对
的梯度为:
类似地, 可以计算出:

由此可以计算出 和
。 在计算出每个时刻的损失函数对各个参数的梯度之后, 把它们加起来得到总损失函数对各个参数的梯度:
接下来用梯度下降法更新参数。
3.2 BPTT 算法
将上面的例子推广到一般情况, 得到通用的 BPTT 算法。
循环神经网络的反向传播是基于时间轴进行的, 我们需要计算所有时刻的总损失函数对所有参数的梯度, 然后用梯度下降法进行更新。 另外循环神经网络在各个时刻的权重、 偏置都是相同的。
设 t 时刻的损失函数为:
总损失函数为:
1)输出层
首先计算输出层偏置项的梯度:
如果选择 softmax 作为输出层的激活函数, 交叉熵作为损失函数, 则上面的梯度为:
对输出层权重矩阵的梯度为:
2)循环层
因此有:
由此建立了 与
之间的递推关系。 定义误差项为:
在总损失函数 中, 比
更早的时刻的损失函数不含有
, 因此与
无关。由于
由
决定, 因此
与
直接相关。 比
晚的时刻的
,
…,
都与
有关, 因此有:
存在

从而得到:
由此建立了误差项沿时间轴的递推公式, 递推的起点是最后一个时刻的误差:
根据误差项可以计算出损失函数对权重和偏置的梯度:
3)算法流程

四、循环神经网络实现情感分析
4.1 实验介绍
通过 RNN 模型对电影评论进行情感分类,判断评论是正面还是负面。
4.2 数据集介绍
IMDB 数据集包含 50,000 条电影评论, 其中一半用于训练(25,000 条), 另一半用于测试(25,000 条)。 每条评论都附带一个标签, 要么是'pos'表示正面评价, 要么是'neg'表示负面评价。 这些评论通常以文本文件的形式存在, 每个文件中包含一条评论。
4.3 Embedding操作
Embedding 过程:计算机无法直接处理一个单词或者一个汉字, 需要把一个 token 转化成计算机可以识别的向量 。
Embedding 是一种将高维数据(如文本或图像) 转换为较低维度的向量表示的技术。 这种表示捕捉了数据的关键特征, 使得在处理、 分析和机器学习任务中更加高效。 通常用于将离散的、 非连续的数据转换为连续的向量表示, 以便于计算机进行处理。
Embedding 技术通常会捕获数据的语义信息。 在 NLP 中, 这意味着相似的单词或短语在嵌入空间中会更接近, 而不同的单词或短语会远离彼此。 这有助于模型理解语言的含义和语义关系。
Embedding 技术通常是上下文感知的, 它们可以捕获数据点与其周围数据点的关系。 在 NLP 中, 单词的嵌入会考虑其周围的单词, 以更好地表示语法和语义。
简单的说, Embedding 就是把一个东西映射到一个向量 X。 如果这个东西很像, 那么得到的向量 x1 和 x2 的欧式距离就很小。
4.4 pytorch实现
1)数据处理
首先对数据集进行处理, 提取单词表, 单词表的最大尺寸是 10000。
# 加载数据
def load_data(data_dir):texts = [] # 存储文本数据labels = [] # 存储标签数据for label_type in ['neg', 'pos']: # 遍历负面和正面评论目录dir_name = os.path.join(data_dir, label_type) # 构建目录路径 /IMDB/train/neg/0_2.txtfor fname in os.listdir(dir_name): # 遍历目录中的文件if fname.endswith('.txt'): # 只处理文本文件with open(os.path.join(dir_name, fname), encoding="utf-8") as f:texts.append(f.read()) # 读取文本内容labels.append(0 if label_type == 'neg' else 1) # 根据目录确定标签(负面:0,正面:1)return texts, labels # 返回文本和标签# 加载训练和测试数据
train_texts, train_labels = load_data('./IMDB/train')
test_texts, test_labels = load_data('./IMDB/test')# 构建词汇表
max_features = 10000 # 词汇表大小,最多包含10000个单词
maxlen = 150 # 每个文本的最大长度为150tokenizer = Counter(" ".join(train_texts).split()) # 统计词频
# print(tokenizer.most_common(100))
# [('the', 287032), ('a', 155096), ('and', 152664), ('of', 142972),
# ('to', 132568), ('is', 103229), ('in', 85580), ('I', 65973), ('that', 64560), ('this', 57199), ('it', 54439), ('/><br', 50935), ('was', 46698), ('as', 42510), ('with', 41721), ('for', 41070), ('but', 33790), ('The', 33762), ('on', 30767), ('movie', 30506), ('are', 28499), ('his', 27687), ('film', 27402), ('have', 27126), ('not', 26266), ('be', 25512), ('you', 25123), ('he', 21676), ('by', 21426), ('at', 21295), ('one', 20692), ('an', 20626), ('from', 19239), ('who', 18838), ('like', 18133), ('all', 18048), ('they', 17840), ('has', 16472), ('so', 16336), ('just', 16326), ('about', 16286), ('or', 16224), ('her', 15830), ('out', 14368), ('some', 14207), ('very', 13082), ('more', 12950), ('This', 12279), ('would', 11923), ('what', 11685), ('when', 11488), ('good', 11436), ('only', 11106), ('their', 11008), ('It', 10952), ('if', 10899), ('had', 10876), ('really', 10815), ("it's", 10727), ('up', 10658), ('which', 10658), ('even', 10607), ('can', 10560), ('were', 10460), ('my', 10166), ('see', 10155), ('no', 10062), ('she', 9933), ('than', 9772), ('-', 9355), ('been', 9050), ('there', 9036), ('into', 8950), ('get', 8777), ('will', 8558), ('story', 8527), ('much', 8507), ('because', 8357), ('other', 7917), ('most', 7859), ('we', 7808), ('time', 7765), ('me', 7540), ('make', 7485), ('could', 7462), ('also', 7422), ('do', 7408), ('how', 7403), ('first', 7339), ('people', 7335), ('its', 7323), ('/>The', 7243), ('any', 7232), ('great', 7191), ("don't", 7007), ('made', 6962), ('think', 6659), ('bad', 6506), ('him', 6347), ('being', 6202)]
vocab = [word for word, num in tokenizer.most_common(max_features)] # 取出前10000个常用词
# print(vocab)
word_index = {word: idx + 1 for idx, word in enumerate(vocab)} # 为每个词分配一个索引
# print(word_index)# 将文本转换为序列
def texts_to_sequences(texts):return [[word_index.get(word, 0) for word in text.split()] for text in texts]# 转换训练和测试文本为序列
x_train = texts_to_sequences(train_texts)#{}
x_test = texts_to_sequences(test_texts)# 将序列填充到固定长度
x_train_padded = pad_sequence([torch.tensor(seq[:maxlen]) for seq in x_train], batch_first=True, padding_value=0)
x_test_padded = pad_sequence([torch.tensor(seq[:maxlen]) for seq in x_test], batch_first=True, padding_value=0)y_train = torch.tensor(train_labels) # 转换训练标签为张量
y_test = torch.tensor(test_labels) # 转换测试标签为张量# 创建 Dataset 和 DataLoader
class TextDataset(Dataset):def __init__(self, texts, labels):self.texts = texts # 文本数据self.labels = labels # 标签数据def __len__(self):return len(self.labels) # 返回数据集大小def __getitem__(self, idx):return self.texts[idx], self.labels[idx] # 返回指定索引的数据train_dataset = TextDataset(x_train_padded, y_train) # 创建训练数据集
test_dataset = TextDataset(x_test_padded, y_test) # 创建测试数据集train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 创建训练数据加载器
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) # 创建测试数据加载器2)模型设计
实现一个简单的循环神经网络, 第一层是 embedding 层, 词嵌入的大小是 100; 第二层是循环层, 循环层的输入尺寸是 100, 神经元数量是 256; 第三层是全连接层也就是输出层, 输入尺寸是 256, 输出是 1, 因为这是一个二分类问题, 所以输出尺寸是 1 即可。
class SimpleRNN(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):super(SimpleRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim) # 词嵌入层self.rnn = nn.RNN(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, text):embedded = self.embedding(text)output, hidden = self.rnn(embedded)out = self.fc(output[:, -1, :])return out3)训练配置
设置损失函数和优化器。
model = SimpleRNN(max_features + 1, 100, 256, 1) # 创建模型实例
# 编译模型
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
optimizer = optim.Adam(model.parameters()) # 使用 SGD/Adam 优化器4)训练过程
训练并保存模型
# 训练模型
def train(model, train_loader, optimizer, criterion, epochs):for epoch in range(epochs): # 训练一个周期model.train() # 设置模型为训练for texts, labels in train_loader: # 遍历训练数据optimizer.zero_grad() # 清零梯度outputs = model.forward(texts) # 前向传播loss = criterion(outputs.squeeze(), labels.float()) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 训练并测试模型
train(model, train_loader, optimizer, criterion, epochs=1)
# 模型保存并测试
torch.save(model.state_dict(), 'rnn_state_dict.pth')5)测试模型
评估模型性能
# 测试模型
def predict(model, test_loader):model.eval() # 设置模型为评估模式correct = 0total = 0with torch.no_grad(): # 不计算梯度for texts, labels in test_loader: # 遍历测试数据outputs = model.forward(texts) # 前向传播predicted = (outputs.squeeze() > 0.5).int() # 预测标签total += labels.size(0) # 总样本数correct += (predicted == labels).sum().item() # 正确预测数print(f'测试准确率: {correct / total}')# 模型评估
model = SimpleRNN(max_features + 1, 100, 256, 1)
model.load_state_dict(torch.load('rnn_state_dict.pth'))
predict(model, test_loader)
相关文章:
循环神经网络(RNN)+pytorch实现情感分析
目录 一、背景引入 二、网络介绍 2.1 输入层 2.2 循环层 2.3 输出层 2.4 举例 2.5 深层网络 三、网络的训练 3.1 训练过程举例 1)输出层 2)循环层 3.2 BPTT 算法 1)输出层 2)循环层 3)算法流程 四、循…...
css-background-color(transparent)
1.前言 在 CSS 中,background-color 属性用于设置元素的背景颜色。除了基本的颜色值(如 red、blue 等)和十六进制颜色值(如 #FF0000、#0000FF 等),还有一些特殊的属性值可以用来设置背景颜色。 2.backgrou…...

【Leetcode 热题 100】32. 最长有效括号
问题背景 给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号 子串 的长度。 数据约束 0 ≤ s . l e n g t h ≤ 3 1 0 4 0 \le s.length \le 3 \times 10 ^ 4 0≤s.length≤3104 s [ i ] s[i] s[i] 为 ‘(’ 或 ‘…...

Linux网络 | 网络层IP报文解析、认识网段划分与IP地址
前言:本节内容为网络层。 主要讲解IP协议报文字段以及分离有效载荷。 另外, 本节也会带领友友认识一下IP地址的划分。 那么现在废话不多说, 开始我们的学习吧!! ps:本节正式进入网络层喽, 友友们…...

Google 和 Meta 携手 FHE 应对隐私挑战
1. 引言 为什么世界上最大的广告商,如谷歌和 Meta 这样的超大规模公司都选择全同态加密 (FHE)。 2. 定向广告 谷歌和 Meta 是搜索引擎和社交网络领域的两大巨头,它们本质上从事的是同一业务——广告。它们最近公布的年度广告收入数据显示,…...

将markdown文件转为word文件
通义千问等大模型生成的回答多数是markdown类型的,需要将他们转为Word文件 一 pypandoc 介绍 1. 项目介绍 pypandoc 是一个用于 pandoc 的轻量级 Python 包装器。pandoc 是一个通用的文档转换工具,支持多种格式的文档转换,如 Markdown、HTM…...

arkts bridge使用示例
接上一篇:arkui-x跨平台与android java联合开发-CSDN博客 本篇讲前端arkui如何与后端其他平台进行数据交互,接上一篇,后端os平台为Android java。 arkui-x框架提供了一个独特的机制:bridge。 1、前端接口定义实现 定义一个bri…...

2025年大年初一篇,C#调用GPU并行计算推荐
C#调用GPU库的主要目的是利用GPU的并行计算能力,加速计算密集型任务,提高程序性能,支持大规模数据处理,优化资源利用,满足特定应用场景的需求,并提升用户体验。在需要处理大量并行数据或进行复杂计算的场景…...

python算法和数据结构刷题[2]:链表、队列、栈
链表 链表的节点定义: class Node():def __init__(self,item,nextNone):self.itemitemself.nextNone 删除节点: 删除节点前的节点的next指针指向删除节点的后一个节点 添加节点: 单链表 class Node():"""单链表的结点&quo…...

Baklib解析内容中台与人工智能技术带来的价值与机遇
内容概要 在数字化转型的浪潮中,内容中台与人工智能技术的结合为企业提供了前所未有的发展机遇。内容中台作为一种新的内容管理和生产模式,通过统一管理和协调各种内容资源,帮助企业更高效地整合内外部数据。而人工智能技术则以其强大的数据…...
Flask框架基础入门教程_ezflaskapp
pip install flaskFlask 快速入门小应用 学东西,得先知道我们用这个东西,能做出来一个什么东西。 一个最小的基于flask 的应用可能看上去像下面这个样子: from flask import Flask app Flask(__name__)app.route(/) def hello_world():ret…...

黑马点评 - 商铺类型缓存练习题(Redis List实现)
首先明确返回值是一个 List<ShopType> 类型那么我们修改此函数并在 TypeService 中声明 queryTypeList 方法,并在其实现类中实现此方法 GetMapping("list")public Result queryTypeList() {return typeService.queryTypeList();}实现此方法首先需要…...

AI学习指南Ollama篇-使用Ollama构建自己的私有化知识库
一、引言 (一)背景介绍 随着企业对数据隐私和效率的重视,私有化知识库的需求日益增长。私有化知识库不仅可以保护企业数据的安全性,还能提供高效的知识管理和问答系统,提升企业内部的工作效率和创新能力。 (二)Ollama和AnythingLLM的结合 Ollama和AnythingLLM的结合…...

洛谷P4057 [Code+#1] 晨跑
题目链接:P4057 [Code#1] 晨跑 - 洛谷 | 计算机科学教育新生态 题目难度:普及一 题目分析:这道题很明显是求最大公倍数,写题解是为了帮助自己复习。 下面用两种方法介绍如何求最大公倍数: 暴力破解 #include<bits…...
)
嵌入式经典面试题之操作系统(一)
文章目录 1 请你说说常用的Linux命令有哪些?2 在linux中如何创建一个新的目录?3 Linux中查看进程运行状态的指令、tar解压文件的参数。4 在linux中,文件权限如何修改?5 怎样以root权限运行某个程序?6 在linux里如何查看…...
讯飞绘镜(ai生成视频)技术浅析(四):图像生成
1. 技术架构概述 讯飞绘镜的图像生成技术可以分为以下几个核心模块: 文本理解与视觉元素提取:解析脚本中的场景描述,提取关键视觉元素(如人物、场景、物体等)。 视觉元素生成:根据文本描述生成具体的视觉元素(如人物、场景、物体等)。 分镜画面生成:将视觉元素组合成…...

搜索引擎快速收录:关键词布局的艺术
本文来自:百万收录网 原文链接:https://www.baiwanshoulu.com/21.html 搜索引擎快速收录中的关键词布局,是一项既精细又富有策略性的工作。以下是对关键词布局艺术的详细阐述: 一、关键词布局的重要性 关键词布局影响着后期页面…...

[Effective C++]条款53-55 杂项讨论
本文初发于 “天目中云的小站”,同步转载于此。’ 学到这里, Effective C至此也算是告一段落了, 还剩下一些杂七杂八的讨论, 我们将在本文逐一列举. 条款53 : 不要忽视编译器的警告 我们应严肃对待编译器发出的警告信息, 努力在你的编译器最高警告级别下争取无警告…...

FreeRTOS从入门到精通 第十五章(事件标志组)
参考教程:【正点原子】手把手教你学FreeRTOS实时系统_哔哩哔哩_bilibili 一、事件标志组简介 1、概述 (1)事件标志位是一个“位”,用来表示事件是否发生。 (2)事件标志组是一组事件标志位的集合&#x…...
)
5 长度和距离计算模块(length.rs)
这段代码定义了一个泛型结构体 Length<T, Unit>,用于表示一维长度,其中 T 表示长度的数值类型,而 Unit 是一个编译时检查单位一致性的占位符类型,不会用于运行时表示长度的值。这个设计允许开发者在编译阶段确保不同单位之间…...

使用Pygame制作“俄罗斯方块”游戏
1. 前言 俄罗斯方块(Tetris) 是一款由方块下落、行消除等核心规则构成的经典益智游戏: 每次从屏幕顶部出现一个随机的方块(由若干小方格组成),玩家可以左右移动或旋转该方块,让它合适地堆叠在…...

deepseek大模型本机部署
2024年1月20日晚,中国DeepSeek发布了最新推理模型DeepSeek-R1,引发广泛关注。这款模型不仅在性能上与OpenAI的GPT-4相媲美,更以开源和创新训练方法,为AI发展带来了新的可能性。 本文讲解如何在本地部署deepseek r1模型。deepseek官…...

常见“栈“相关题目
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: 优选算法专题 目录 1047.删除字符串中的所有相邻重复项 844.比较含退格的字符串 227.基本计算器 II 394.字符串解码 946.验证栈序列 104…...

QT实现有限元软件操作界面
本系列文章致力于实现“手搓有限元,干翻Ansys的目标”,基本框架为前端显示使用QT实现交互,后端计算采用Visual Studio C。 本篇将二维矩形截面梁单元(Rect_Beam2D2Node)组成的钢结构桥作为案例来展示软件功能。 也可以…...
软件工程经济学-日常作业+大作业
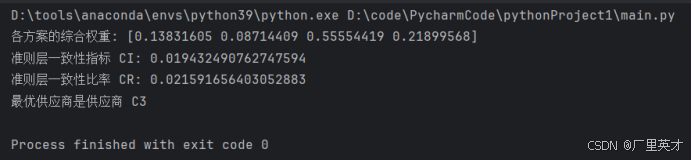
目录 一、作业1 作业内容 解答 二、作业2 作业内容 解答 三、作业3 作业内容 解答 四、大作业 作业内容 解答 1.建立层次结构模型 (1)目标层 (2)准则层 (3)方案层 2.构造判断矩阵 (1)准则层判断矩阵 (2)方案层判断矩阵 3.层次单排序及其一致性检验 代码 …...

深度学习篇---深度学习框架
文章目录 前言第一部分:框架简介1. PyTorch简介特点动态计算图易于上手强大的社区支持与Python的集成度高 核心组件 2. TensorFlow简介特点静态计算图跨平台强大的生态系统Keras集成 核心组件 3. PaddlePaddle简介特点易于使用高性能工业级应用丰富的预训练模型 核心…...

Go学习:Go语言中if、switch、for语句与其他编程语言中相应语句的格式区别
Go语言中的流程控制语句逻辑结构与其他编程语言类似,格式有些不同。Go语言的流程控制中,包括if、switch、for、range、goto等语句,没有while循环。 目录 1. if 语句 2. switch语句 3. for语句 4. range语句 5. goto语句(不常用…...
)
Java中初步使用websocket(springBoot版本)
一、什么是websocket WebSocket是一种在Web应用程序中实现实时双向通信的协议。它为浏览器和服务器之间提供了一种持久连接,在一个连接上可以双向传输数据。相比传统的HTTP协议,WebSocket具有更低的延迟和更高的效率。 WebSocket使用了类似于握手的方式来…...

Day50:字典的合并
在 Python 中,字典是一个可变的数据类型,经常需要将多个字典合并成一个字典。合并字典的方式有多种,今天我们将学习几种常见的方法。 1. 使用 update() 方法合并字典 update() 方法可以用来将一个字典中的键值对添加到另一个字典中。如果目…...

14-8C++STL的queue容器
一、queue容器 (1)queue容器的简介 queue为队列容器,“先进先出”的容器 (2)queue对象的构造 queue<T>q; queue<int>que Int;//存放一个int的queue容器 queue<string>queString;//存放一个string的queue容器 (3)queue容器的push()与pop()方…...