【LLM-agent】(task1)简单客服和阅卷智能体
note
- 一个完整的agent有模型 (Model)、工具 (Tools)、编排层 (Orchestration Layer)
- 一个好的结构化 Prompt 模板,某种意义上是构建了一个好的全局思维链。 如 LangGPT 中展示的模板设计时就考虑了如下思维链:Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
- Prompt设计要注意角色设置、背景描述、目标定义、约束条件等要点
- 注意为了保证LLM输出结果的正确json格式需要的prompt描述,参考
self.output_parser
文章目录
- note
- 零、相关背景
- 1. agent的核心组件
- 2. agent的运作
- 3. agent的优势
- 4. agent的应用
- 5. Agents的开发工具:从LangChain到Vertex AI
- 一、手搓一个简单agent
- 1. 结构化Prompt的定义
- 2. LangGPT 中的 Role (角色)模板
- Role: Your_Role_Name
- Rules
- Workflow
- Initialization
- 3. Prompt设计方法论
- 4. Prompt举例:智能客服
- 5. 完整的例子
- 二、openai库搭建阅卷智能体
- Reference
零、相关背景
生成式AI模型(LLMs)近年来取得了惊人的进步,能够创作文本、图像、代码等,展现出巨大的潜力。然而,LLMs仍然存在局限性:
- 知识局限性:LLMs的知识仅限于训练数据,无法获取实时信息和外部知识库。
- 行动局限性:LLMs无法与外界交互,无法执行实际操作。 为了克服这些局限性,谷歌的研究人员在《New whitepaper Agents》详细论述了“Agent”的概念,将LLMs与工具和编排层相结合,赋予其自主行动的能力。
1. agent的核心组件
一个完整的Agent主要由三个核心组件构成:
1.模型 (Model):
角色:作为Agent的“大脑”,负责理解用户输入,进行推理和规划,并选择合适的工具进行执行。
类型:常用的模型包括ReAct、Chain-of-Thought、Tree-of-Thought等,它们提供不同的推理框架,帮助Agent进行多轮交互和决策。
重要性:模型是Agent的核心,其推理能力决定了Agent的行动效率和准确性。
2.工具 (Tools):
角色:作为Agent与外界交互的“桥梁”,允许Agent访问外部数据和服务,执行各种任务。
类型:工具可以是各种API,例如数据库查询、搜索引擎、代码执行器、邮件发送器等。
重要性:工具扩展了Agent的能力,使其能够执行更复杂的任务。
3.编排层 (Orchestration Layer):
角色:负责管理Agent的内部状态,协调模型和工具的使用,并根据目标指导Agent的行动。
类型:编排层可以使用各种推理框架,例如ReAct、Chain-of-Thought等,帮助Agent进行规划和决策。
重要性:编排层是Agent的“指挥中心”,负责协调各个组件,确保Agent的行动符合目标。
2. agent的运作
Agent的运作过程可以概括为以下几个步骤:
接收输入:Agent接收用户的指令或问题。
理解输入:模型理解用户的意图,并提取关键信息。
推理规划:模型根据用户输入和当前状态,进行推理和规划,确定下一步行动。
选择工具:模型根据目标选择合适的工具。
执行行动:Agent使用工具执行行动,例如查询数据库、发送邮件等。
获取结果:Agent获取工具执行的结果。
输出结果:Agent将结果输出给用户,或进行下一步行动。
3. agent的优势
Agents具有以下优势:
- 知识扩展:通过工具,Agent可以访问实时信息和外部知识库,突破训练数据的限制,提供更准确和可靠的信息。
- 自主行动:Agent可以根据目标进行自主决策和行动,无需人工干预,提高效率和灵活性。
- 多轮交互:Agent可以管理对话历史和上下文,进行多轮交互,提供更自然和流畅的用户体验。
- 可扩展性:Agent可以通过添加新的工具和模型,扩展其功能和应用范围。
4. agent的应用
Agents的应用范围非常广泛,例如:
智能客服:Agent可以自动回答用户问题,处理订单,解决客户问题,提高客户满意度。
个性化推荐:Agent可以根据用户的兴趣和行为,推荐商品、内容、服务等,提升用户体验。
虚拟助手:Agent可以帮助用户管理日程、预订行程、发送邮件等,提高工作效率。
代码生成:Agent可以根据用户的需求,自动生成代码,提高开发效率。
智能创作:Agent可以根据用户的需求,创作诗歌、小说、剧本等,激发创作灵感。
知识图谱构建:Agent可以从文本中提取知识,构建知识图谱,用于知识管理和推理。
5. Agents的开发工具:从LangChain到Vertex AI
为了方便开发Agents,Google提供了多种工具和平台,例如:
LangChain:一个开源库,可以帮助开发者构建和部署Agents。LangChain提供了一套API,方便开发者将LLMs与工具和编排层结合,构建功能强大的Agents。
LangGraph:一个开源库,可以帮助开发者构建和可视化Agents。LangGraph提供了一套图形化界面,方便开发者设计和测试Agents。
Vertex AI:一个云平台,提供各种AI工具和服务,例如Vertex Agent Builder、Vertex Extensions、Vertex Function Calling等,可以帮助开发者快速构建和部署Agents。Vertex AI提供了强大的基础设施和工具,方便开发者进行Agent开发、测试、部署和管理。
一、手搓一个简单agent
注意事项:
(1)安装相关的库:
pip install openai python-dotenv
国内模型可以是智谱、Yi、千问deepseek等等。KIMI是不行的,因为Kimi家没有嵌入模型。 要想用openai库对接国内的大模型,对于每个厂家,我们都需要准备四样前菜:
第一:一个api_key,这个需要到各家的开放平台上去申请。
第二:一个base_url,这个需要到各家的开放平台上去拷贝。
第三:他们家的对话模型名称。
1. 结构化Prompt的定义
参考:https://github.com/EmbraceAGI/LangGPT
(1)LangGPT 变量:
- Markdown 的语法层级结构很好,适合编写 prompt,因此 LangGPT 的变量基于 markdown语法。实际上除 markdown外各种能实现标记作用,如 json,yaml, 甚至好好排版好格式 都可以。
- 变量为 Prompt 的编写带来了很大的灵活性。使用变量可以方便的引用角色内容,设置和更改角色属性。
(2)LangGPT 模板:
- 其实 prompt 的“角色声明”和类声明很像。因此 可以将 prompt 抽象为一个角色 (Role),包含名字,描述,技能,工作方法等描述,然后就得到了 LangGPT 的 Role 模板。
- 使用 Role 模板,只需要按照模板填写相应内容即可。
- 除了变量和模板外,LangGPT 还提供了命令,记忆器,条件句等语法设置方法。
(3)几个概念
标识符:#, <> 等符号(-, []也是),这两个符号依次标识标题,变量,控制内容层级,用于标识层次结构。
属性词:Role, Profile, Initialization 等等,属性词包含语义,是对模块下内容的总结和提示,用于标识语义结构。
(4)好的结构化prompt模板:
一个好的结构化 Prompt 模板,某种意义上是构建了一个好的全局思维链。 如 LangGPT 中展示的模板设计时就考虑了如下思维链:
Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
(5) 保持上下文语义一致性。包含两个方面,一个是格式语义一致性,一个是内容语义一致性。
- 格式语义一致性是指标识符的标识功能前后一致。 最好不要混用,比如 # 既用于标识标题,又用于标识变量这种行为就造成了前后不一致,这会对模型识别 Prompt 的层级结构造成干扰。
- 内容语义一致性是指思维链路上的属性词语义合适。 例如 LangGPT 中的 Profile 属性词,原来是 Features,但实践+思考后我更换为了 Profile,使之功能更加明确:即角色的简历。结构化 Prompt 思想被诸多朋友广泛使用后衍生出了许许多多的模板,但基本都保留了 Profile 的诸多设计,说明其设计是成功有效的。
(6)为什么前期会用 Features 呢? 因为 LangGPT 的结构化思想有受到 AI-Tutor[7] 项目很大启发,而 AI-Tutor 项目中并无 Profile 一说,与之功能近似的是 Features。但 AI-Tutor 项目中的提示词过于复杂,并不通用。
2. LangGPT 中的 Role (角色)模板
Role: Your_Role_Name
Profile
Author: YZFly
Version: 0.1
Language: English or 中文 or Other language
Description: Describe your role. Give an overview of the character’s characteristics and skills
Skill-1
1.技能描述1 2.技能描述2
Skill-2
1.技能描述1 2.技能描述2
Rules
Don’t break character under any circumstance.
Don’t talk nonsense and make up facts.
Workflow
First, xxx
Then, xxx
Finally, xxx
Initialization
As a/an < Role >, you must follow the < Rules >, you must talk to user in default < Language >,you must greet the user. Then introduce yourself and introduce the < Workflow >.
Prompt Chain 将原有需求分解,通过用多个小的 Prompt 来串联/并联,共同解决一项复杂任务。
Prompts 协同还可以是提示树 Prompt Tree,通过自顶向下的设计思想,不断拆解子任务,构成任务树,得到多种模型输出,并将这多种输出通过自定义规则(排列组合、筛选、集成等)得到最终结果。 API 版本的 Prompt Chain 结合编程可以将整个流程变得更加自动化
3. Prompt设计方法论
prompt设计方法论
- 数据准备。收集高质量的案例数据作为后续分析的基础。
- 模型选择。根据具体创作目的,选择合适的大语言模型。
- 提示词设计。结合案例数据,设计初版提示词;注意角色设置、背景描述、目标定义、约束条件等要点。
- 测试与迭代。将提示词输入 GPT 进行测试,分析结果;通过追问、深度交流、指出问题等方式与 GPT 进行交流,获取优化建议。
- 修正提示词。根据 GPT 提供的反馈,调整提示词的各个部分,强化有效因素,消除无效因素。
- 重复测试。输入经修正的提示词重新测试,比较结果,继续追问GPT并调整提示词。
- 循环迭代。重复上述测试-交流-修正过程,直到结果满意为止。
- 总结提炼。归纳提示词优化过程中获得的宝贵经验,形成设计提示词的最佳实践。
- 应用拓展。将掌握的方法论应用到其他创意内容的设计中,不断丰富提示词设计的技能。
4. Prompt举例:智能客服
sys_prompt = """你是一个聪明的客服。您将能够根据用户的问题将不同的任务分配给不同的人。您有以下业务线:
1.用户注册。如果用户想要执行这样的操作,您应该发送一个带有"registered workers"的特殊令牌。并告诉用户您正在调用它。
2.用户数据查询。如果用户想要执行这样的操作,您应该发送一个带有"query workers"的特殊令牌。并告诉用户您正在调用它。
3.删除用户数据。如果用户想执行这种类型的操作,您应该发送一个带有"delete workers"的特殊令牌。并告诉用户您正在调用它。
"""
registered_prompt = """
您的任务是根据用户信息存储数据。您需要从用户那里获得以下信息:
1.用户名、性别、年龄
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,您需要提示用户提供。如果用户提供了此信息,则需要将此信息存储在数据库中,并告诉用户注册成功。
存储方法是使用SQL语句。您可以使用SQL编写插入语句,并且需要生成用户ID并将其返回给用户。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
query_prompt = """
您的任务是查询用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
如果用户没有提供此信息,则需要提示用户提供。如果用户提供了此信息,那么需要查询数据库。如果用户ID和密码匹配,则需要返回用户的信息。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
delete_prompt = """
您的任务是删除用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,则需要提示用户提供该信息。
如果用户提供了这些信息,则需要查询数据库。如果用户ID和密码匹配,您需要通知用户验证码已发送到他们的电子邮件,需要进行验证。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
5. 完整的例子
import os
from dotenv import load_dotenv# 加载环境变量
load_dotenv()
# 初始化变量
base_url = None
chat_model = None
api_key = None# 使用with语句打开文件,确保文件使用完毕后自动关闭
env_path = ".env.txt"
with open(env_path, 'r') as file:# 逐行读取文件for line in file:# 移除字符串头尾的空白字符(包括'\n')line = line.strip()# 检查并解析变量if "base_url" in line:base_url = line.split('=', 1)[1].strip().strip('"')elif "chat_model" in line:chat_model = line.split('=', 1)[1].strip().strip('"')elif "ZHIPU_API_KEY" in line:api_key = line.split('=', 1)[1].strip().strip('"')# 打印变量以验证
print(f"base_url: {base_url}")
print(f"chat_model: {chat_model}")
print(f"ZHIPU_API_KEY: {api_key}")from openai import OpenAI
client = OpenAI(api_key = api_key,base_url = base_url
)
print(client)def get_completion(prompt):response = client.chat.completions.create(model="glm-4-flash", # 填写需要调用的模型名称messages=[{"role": "user", "content": prompt},],)return response.choices[0].message.contentsys_prompt = """你是一个聪明的客服。您将能够根据用户的问题将不同的任务分配给不同的人。您有以下业务线:
1.用户注册。如果用户想要执行这样的操作,您应该发送一个带有"registered workers"的特殊令牌。并告诉用户您正在调用它。
2.用户数据查询。如果用户想要执行这样的操作,您应该发送一个带有"query workers"的特殊令牌。并告诉用户您正在调用它。
3.删除用户数据。如果用户想执行这种类型的操作,您应该发送一个带有"delete workers"的特殊令牌。并告诉用户您正在调用它。
"""
registered_prompt = """
您的任务是根据用户信息存储数据。您需要从用户那里获得以下信息:
1.用户名、性别、年龄
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,您需要提示用户提供。如果用户提供了此信息,则需要将此信息存储在数据库中,并告诉用户注册成功。
存储方法是使用SQL语句。您可以使用SQL编写插入语句,并且需要生成用户ID并将其返回给用户。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
query_prompt = """
您的任务是查询用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
如果用户没有提供此信息,则需要提示用户提供。如果用户提供了此信息,那么需要查询数据库。如果用户ID和密码匹配,则需要返回用户的信息。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
delete_prompt = """
您的任务是删除用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,则需要提示用户提供该信息。
如果用户提供了这些信息,则需要查询数据库。如果用户ID和密码匹配,您需要通知用户验证码已发送到他们的电子邮件,需要进行验证。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""# 定义智能客服
class SmartAssistant:def __init__(self):self.client = client self.system_prompt = sys_promptself.registered_prompt = registered_promptself.query_prompt = query_promptself.delete_prompt = delete_prompt# Using a dictionary to store different sets of messagesself.messages = {"system": [{"role": "system", "content": self.system_prompt}],"registered": [{"role": "system", "content": self.registered_prompt}],"query": [{"role": "system", "content": self.query_prompt}],"delete": [{"role": "system", "content": self.delete_prompt}]}# Current assignment for handling messagesself.current_assignment = "system"def get_response(self, user_input):self.messages[self.current_assignment].append({"role": "user", "content": user_input})while True:response = self.client.chat.completions.create(model=chat_model,messages=self.messages[self.current_assignment],temperature=0.9,stream=False,max_tokens=2000,)ai_response = response.choices[0].message.contentif "registered workers" in ai_response:self.current_assignment = "registered"print("意图识别:",ai_response)print("switch to <registered>")self.messages[self.current_assignment].append({"role": "user", "content": user_input})elif "query workers" in ai_response:self.current_assignment = "query"print("意图识别:",ai_response)print("switch to <query>")self.messages[self.current_assignment].append({"role": "user", "content": user_input})elif "delete workers" in ai_response:self.current_assignment = "delete"print("意图识别:",ai_response)print("switch to <delete>")self.messages[self.current_assignment].append({"role": "user", "content": user_input})elif "customer service" in ai_response:print("意图识别:",ai_response)print("switch to <customer service>")self.messages["system"] += self.messages[self.current_assignment]self.current_assignment = "system"return ai_responseelse:self.messages[self.current_assignment].append({"role": "assistant", "content": ai_response})return ai_responsedef start_conversation(self):while True:user_input = input("User: ")if user_input.lower() in ['exit', 'quit']:print("Exiting conversation.")breakresponse = self.get_response(user_input)print("Assistant:", response)assistant = SmartAssistant()
assistant.start_conversation()
得到的结果如下,即按要求输入个人信息,之后agent会读入并转为SQL并执行在数据库中:

优点:
①意图识别正确
1、成功识别了"忘记密码"的场景
2、正确识别了"注册账号"的需求
3、准确识别了"查询用户"的请求
②状态切换正常
1、从 system -> registered -> customer service 的切换正确
2、从 system -> query 的切换也正确
3、每次切换都有清晰的提示(“switch to ”)
③ 提示词执行到位
1、按照预设的 prompt 给出相应的回答
④要求用户提供必要的信息
1、给出了具体的SQL示例
2、交互流畅
3、对话自然
4、回答详细
5、引导清晰
需要改进的地方:
1、重复信息:在某些回答中出现了重复的内容,比如SQL语句示例重复出现状态管理
2、信息收集:可以更有条理地一步步收集用户信息,增加信息验证的环节
二、openai库搭建阅卷智能体
import os
from dotenv import load_dotenv# 加载环境变量
load_dotenv()
# 初始化变量
base_url = None
chat_model = None
api_key = None# 使用with语句打开文件,确保文件使用完毕后自动关闭
env_path = ".env.txt"
with open(env_path, 'r') as file:# 逐行读取文件for line in file:# 移除字符串头尾的空白字符(包括'\n')line = line.strip()# 检查并解析变量if "base_url" in line:base_url = line.split('=', 1)[1].strip().strip('"')elif "chat_model" in line:chat_model = line.split('=', 1)[1].strip().strip('"')elif "ZHIPU_API_KEY" in line:api_key = line.split('=', 1)[1].strip().strip('"')# 打印变量以验证
print(f"base_url: {base_url}")
print(f"chat_model: {chat_model}")
print(f"ZHIPU_API_KEY: {api_key}")from openai import OpenAI
client = OpenAI(api_key = api_key,base_url = base_url
)
print(client)def get_completion(prompt):response = client.chat.completions.create(model="glm-4-flash", # 填写需要调用的模型名称messages=[{"role": "user", "content": prompt},],)return response.choices[0].message.contentimport json
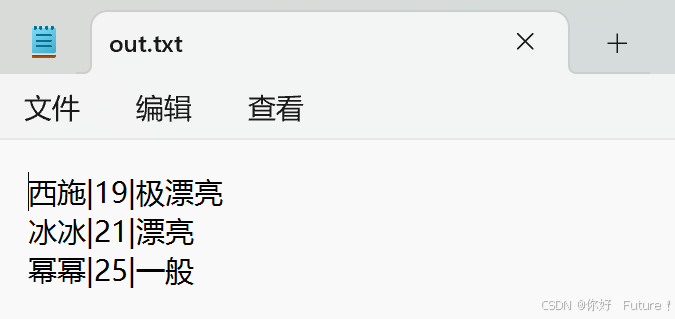
import redef extract_json_content(text):# 这个函数的目标是提取大模型输出内容中的json部分,并对json中的换行符、首位空白符进行删除text = text.replace("\n","")pattern = r"```json(.*?)```"matches = re.findall(pattern, text, re.DOTALL)if matches:return matches[0].strip()return textclass JsonOutputParser:def parse(self, result):# 这个函数的目标是把json字符串解析成python对象# 其实这里写的这个函数性能很差,经常解析失败,有很大的优化空间try:result = extract_json_content(result)parsed_result = json.loads(result)return parsed_resultexcept json.JSONDecodeError as e:raise Exception(f"Invalid json output: {result}") from eclass GradingOpenAI:def __init__(self):self.model = "glm-4-flash"self.output_parser = JsonOutputParser()self.template = """你是一位中国专利代理师考试阅卷专家,
擅长根据给定的题目和答案为考生生成符合要求的评分和中文评语,
并按照特定的格式输出。
你的任务是,根据我输入的考题和答案,针对考生的作答生成评分和中文的评语,并以JSON格式返回。
阅卷标准适当宽松一些,只要考生回答出基本的意思就应当给分。
答案如果有数字标注,含义是考生如果答出这个知识点,这道题就会得到几分。
生成的中文评语需要能够被json.loads()这个函数正确解析。
生成的整个中文评语需要用英文的双引号包裹,在被包裹的字符串内部,请用中文的双引号。
中文评语中不可以出现换行符、转义字符等等。输出格式为JSON:
{{"llmgetscore": 0,"llmcomments": "中文评语"
}}比较学生的回答与正确答案,
并给出满分为10分的评分和中文评语。
题目:{ques_title}
答案:{answer}
学生的回复:{reply}"""def create_prompt(self, ques_title, answer, reply):return self.template.format(ques_title=ques_title,answer=answer,reply=reply)def grade_answer(self, ques_title, answer, reply):success = Falsewhile not success:# 这里是一个不得已的权宜之计# 上面的json解析函数不是表现很差吗,那就多生成几遍,直到解析成功# 对大模型生成的内容先解析一下,如果解析失败,就再让大模型生成一遍try:response = client.chat.completions.create(model=self.model,messages=[{"role": "system", "content": "你是一位专业的考试阅卷专家。"},{"role": "user", "content": self.create_prompt(ques_title, answer, reply)}],temperature=0.7)result = self.output_parser.parse(response.choices[0].message.content)success = Trueexcept Exception as e:print(f"Error occurred: {e}")continuereturn result['llmgetscore'], result['llmcomments']def run(self, input_data):output = []for item in input_data:score, comment = self.grade_answer(item['ques_title'], item['answer'], item['reply'])item['llmgetscore'] = scoreitem['llmcomments'] = commentoutput.append(item)return output
grading_openai = GradingOpenAI()# 示例输入数据
input_data = [{'ques_title': '请解释共有技术特征、区别技术特征、附加技术特征、必要技术特征的含义','answer': '共有技术特征:与最接近的现有技术共有的技术特征(2.5分); 区别技术特征:区别于最接近的现有技术的技术特征(2.5分); 附加技术特征:对所引用的技术特征进一步限定的技术特征,增加的技术特征(2.5分); 必要技术特征:为解决其技术问题所不可缺少的技术特征(2.5分)。','fullscore': 10,'reply': '共有技术特征:与所对比的技术方案相同的技术特征\n区别技术特征:与所对比的技术方案相区别的技术特征\n附加技术特征:对引用的技术特征进一步限定的技术特征\n必要技术特征:解决技术问题必须可少的技术特征'},{'ques_title': '请解释前序部分、特征部分、引用部分、限定部分','answer': '前序部分:独权中,主题+与最接近的现有技术共有的技术特征,在其特征在于之前(2.5分); 特征部分:独权中,与区别于最接近的现有技术的技术特征,在其特征在于之后(2.5分);引用部分:从权中引用的权利要求编号及主题 (2.5分);限定部分:从权中附加技术特征(2.5分)。','fullscore': 10,'reply': '前序部分:独立权利要求中与现有技术相同的技术特征\n特征部分:独立权利要求中区别于现有技术的技术特征\n引用部分:从属权利要求中引用其他权利要求的部分\n限定部分:对所引用的权利要求进一步限定的技术特征'}]# 运行智能体
graded_data = grading_openai.run(input_data)
print(graded_data)
第二题为9分:

Reference
[1] https://github.com/EmbraceAGI/LangGPT
[2] https://github.com/datawhalechina/wow-agent
[3] https://www.datawhale.cn/learn/summary/86
相关文章:
【LLM-agent】(task1)简单客服和阅卷智能体
note 一个完整的agent有模型 (Model)、工具 (Tools)、编排层 (Orchestration Layer)一个好的结构化 Prompt 模板,某种意义上是构建了一个好的全局思维链。 如 LangGPT 中展示的模板设计时就考虑了如下思维链:Role (角色) -> Profile(角色…...

CAP 定理的 P 是什么
分布式系统 CAP 定理 P 代表什么含义 作者之前在看 CAP 定理时抱有很大的疑惑,CAP 定理的定义是指在分布式系统中三者只能满足其二,也就是存在分布式 CA 系统的。作者在网络上查阅了很多关于 CAP 文章,虽然这些文章对于 P 的解释五花八门&am…...
)
RK3568使用opencv(使用摄像头捕获图像数据显示)
文章目录 一、opencv相关的类1. **cv::VideoCapture**2. **cv::Mat**3. **cv::cvtColor**4. **QImage**5. **QPixmap**总结二、代码实现一、opencv相关的类 1. cv::VideoCapture cv::VideoCapture 是 OpenCV 中用于视频捕捉的类,常用于从摄像头、视频文件、或者图像序列中捕…...

ZZNUOJ(C/C++)基础练习1021——1030(详解版)
目录 1021 : 三数求大值 C语言版 C版 代码逻辑解释 1022 : 三整数排序 C语言版 C版 代码逻辑解释 补充 (C语言版,三目运算)C类似 代码逻辑解释 1023 : 大小写转换 C语言版 C版 1024 : 计算字母序号 C语言版 C版 代码逻辑总结…...

2025 年,链上固定收益领域迈向新时代
“基于期限的债券市场崛起与 Secured Finance 的坚定承诺” 2025年,传统资产——尤其是股票和债券——大规模涌入区块链的浪潮将创造历史。BlackRock 首席执行官 Larry Fink 近期在彭博直播中表示,代币化股票和债券将逐步融入链上生态,将进一…...

使用where子句筛选记录
默认情况下,SearchCursor将返回一个表或要素类的所有行.然而在很多情况下,常常需要某些条件来限制返回行数. 操作方法: 1.打开IDLE,加载先前编写的SearchCursor.py脚本 2.添加where子句,更新SearchCursor()函数,查找记录中有<>文本的<>字段 with arcpy.da.Searc…...

基于互联网+智慧水务信息化整体解决方案
智慧水务的概述与发展背景 智慧水务是基于互联网、云计算、大数据、物联网等先进技术,对水务行业的工程建设、生产管理、管网运营、营销服务及企业综合管理等业务进行全面智慧化管理的创新模式。它旨在解决水务企业分散经营、管理水平不高、投资不足等问题。 水务…...

FIDL:Flutter与原生通讯的新姿势,不局限于基础数据类型
void initUser(User user); } 2、执行命令./gradlew assembleDebug,生成IUserServiceStub类和fidl.json文件 3、打开通道,向Flutter公开方法 FidlChannel.openChannel(getFlutterEngine().getDartExecutor(), new IUserServiceStub() { Override void…...
文件读写操作
写入文本文件 #include <iostream> #include <fstream>//ofstream类需要包含的头文件 using namespace std;void test01() {//1、包含头文件 fstream//2、创建流对象ofstream fout;/*3、指定打开方式:1.ios::out、ios::trunc 清除文件内容后打开2.ios:…...

cf1000(div.2)
Minimal Coprime最小公倍数 输入: 6 1 2 1 10 49 49 69 420 1 1 9982 44353 输出: 1 9 0 351 1 34371 代码...

【2025年数学建模美赛E题】(农业生态系统)完整解析+模型代码+论文
生态共生与数值模拟:生态系统模型的物种种群动态研究 摘要1Introduction1.1Problem Background1.2Restatement of the Problem1.3Our Work 2 Assumptions and Justifications3 Notations4 模型的建立与求解4.1 农业生态系统模型的建立与求解4.1.1 模型建立4.1.2求解…...

jhat命令详解
jhat 命令通常与 jmap 搭配使用,用来分析 jmap 生成的 dump 文件,jhat 内置了一个微型的HTTP/HTML服务器,生成 dump 的分析结果后,可以在浏览器中查看。 命令的使用格式如下。(其中heap-dump-file为必填项)…...

FFmpeg(7.1版本)的基本组成
1. 前言 FFmpeg 是一个非常流行的开源项目,它提供了处理音频、视频以及其他多媒体内容的强大工具。FFmpeg 包含了大量的库,可以用来解码、编码、转码、处理和播放几乎所有类型的多媒体文件。它广泛用于视频和音频的录制、转换、流媒体传输等领域。 2. FFmpeg的组成 1. FFmp…...

DDD - 领域驱动设计分层架构:构建可演化的微服务架构
文章目录 引言1. 什么是DDD分层架构?1.1 DDD分层架构的演变1.2 四层架构的起源与问题1.3 依赖倒置和五层架构 2. DDD分层架构的核心层次2.1 用户接口层(User Interface Layer)2.2 应用层(Application Layer)2.3 领域层…...

大数据挖掘--两个角度理解相似度计算理论
文章目录 0 相似度计算可以转换成什么问题1 集合相似度的应用1.1 集合相似度1.1文档相似度1.2 协同过滤用户-用户协同过滤物品-物品协同过滤 1.2 文档的shingling--将文档表示成集合1.2.1 k-shingling1.2.2 基于停用词的 shingling 1.3 最小哈希签名1.4 局部敏感哈希算法&#…...

主流的AEB标准有哪些?
目录 1、AEB的技术构成与工作原理 2、典型应用场景举例 3、AEB的功能分类 4、AEB系统性能评估的关键因素 5、全球AEB技术标准概览 5.1、联合国欧洲经济委员会(UN ECE) 5.2、美国NHTSA法规 5.3、中国标准 5.4、印度AIS 185 5.5、澳大利亚ADR法规…...

开源智慧园区管理系统如何重塑企业管理模式与运营效率
内容概要 在如今快速发展的商业环境中,企业面临着日益复杂的管理挑战。开源智慧园区管理系统应运而生,旨在通过技术创新来应对这些挑战。它不仅是一个简单的软件工具,而是一个全面整合大数据、物联网和智能化功能的综合平台,为企…...

decison tree 决策树
熵 信息增益 信息增益描述的是在分叉过程中获得的熵减,信息增益即熵减。 熵减可以用来决定什么时候停止分叉,当熵减很小的时候你只是在不必要的增加树的深度,并且冒着过拟合的风险 决策树训练(构建)过程 离散值特征处理:One-Hot…...

Spring Data JPA 实战:构建高性能数据访问层
1 简介 1.1 Spring Data JPA 概述 1.1.1 什么是 Spring Data JPA? Spring Data JPA 是 Spring Data 项目的一部分,旨在简化对基于 JPA 的数据库访问操作。它通过提供一致的编程模型和接口,使得开发者可以更轻松地与关系型数据库进行交互,同时减少了样板代码的编写。Spri…...

11 Spark面试真题
11 Spark大厂面试真题 1. 通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?2. hadoop和spark使用场景?3. spark如何保证宕机迅速恢复?4. hadoop和spark的相同点和不同点?…...

【AI论文】VideoAuteur:迈向长叙事视频
摘要:近期的视频生成模型在制作持续数秒的高质量视频片段方面已展现出令人鼓舞的成果。然而,这些模型在生成能传达清晰且富有信息量的长序列时面临挑战,限制了它们支持连贯叙事的能力。在本文中,我们提出了一个大规模烹饪视频数据…...

循环神经网络(RNN)+pytorch实现情感分析
目录 一、背景引入 二、网络介绍 2.1 输入层 2.2 循环层 2.3 输出层 2.4 举例 2.5 深层网络 三、网络的训练 3.1 训练过程举例 1)输出层 2)循环层 3.2 BPTT 算法 1)输出层 2)循环层 3)算法流程 四、循…...
css-background-color(transparent)
1.前言 在 CSS 中,background-color 属性用于设置元素的背景颜色。除了基本的颜色值(如 red、blue 等)和十六进制颜色值(如 #FF0000、#0000FF 等),还有一些特殊的属性值可以用来设置背景颜色。 2.backgrou…...

【Leetcode 热题 100】32. 最长有效括号
问题背景 给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号 子串 的长度。 数据约束 0 ≤ s . l e n g t h ≤ 3 1 0 4 0 \le s.length \le 3 \times 10 ^ 4 0≤s.length≤3104 s [ i ] s[i] s[i] 为 ‘(’ 或 ‘…...

Linux网络 | 网络层IP报文解析、认识网段划分与IP地址
前言:本节内容为网络层。 主要讲解IP协议报文字段以及分离有效载荷。 另外, 本节也会带领友友认识一下IP地址的划分。 那么现在废话不多说, 开始我们的学习吧!! ps:本节正式进入网络层喽, 友友们…...

Google 和 Meta 携手 FHE 应对隐私挑战
1. 引言 为什么世界上最大的广告商,如谷歌和 Meta 这样的超大规模公司都选择全同态加密 (FHE)。 2. 定向广告 谷歌和 Meta 是搜索引擎和社交网络领域的两大巨头,它们本质上从事的是同一业务——广告。它们最近公布的年度广告收入数据显示,…...

将markdown文件转为word文件
通义千问等大模型生成的回答多数是markdown类型的,需要将他们转为Word文件 一 pypandoc 介绍 1. 项目介绍 pypandoc 是一个用于 pandoc 的轻量级 Python 包装器。pandoc 是一个通用的文档转换工具,支持多种格式的文档转换,如 Markdown、HTM…...

arkts bridge使用示例
接上一篇:arkui-x跨平台与android java联合开发-CSDN博客 本篇讲前端arkui如何与后端其他平台进行数据交互,接上一篇,后端os平台为Android java。 arkui-x框架提供了一个独特的机制:bridge。 1、前端接口定义实现 定义一个bri…...

2025年大年初一篇,C#调用GPU并行计算推荐
C#调用GPU库的主要目的是利用GPU的并行计算能力,加速计算密集型任务,提高程序性能,支持大规模数据处理,优化资源利用,满足特定应用场景的需求,并提升用户体验。在需要处理大量并行数据或进行复杂计算的场景…...

python算法和数据结构刷题[2]:链表、队列、栈
链表 链表的节点定义: class Node():def __init__(self,item,nextNone):self.itemitemself.nextNone 删除节点: 删除节点前的节点的next指针指向删除节点的后一个节点 添加节点: 单链表 class Node():"""单链表的结点&quo…...