TensorFlow简单的线性回归任务

如何使用 TensorFlow 和 Keras 创建、训练并进行预测
1. 数据准备与预处理
2. 构建模型
3. 编译模型
4. 训练模型
5. 评估模型
6. 模型应用与预测
7. 保存与加载模型
8.完整代码
1. 数据准备与预处理
我们将使用一个简单的线性回归问题,其中输入特征 x 和标签 y 之间存在线性关系。我们创建一个训练数据集,并将标签设置为输入特征的两倍加上一些噪声。
import numpy as np
import tensorflow as tf# 创建训练数据,x 是输入特征,y 是标签(y = 2 * x + 噪声)
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=float) # 输入数据
y = 2 * x + np.random.normal(0, 1, size=x.shape) # 标签数据,加一些噪声
2. 构建模型
我们使用一个简单的神经网络来进行线性回归。这个网络只有一个全连接层,激活函数是线性的。
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_dim=1, activation='linear') # 线性激活函数
])
3. 编译模型
使用 SGD 优化器和均方误差损失函数,适合线性回归问题。
model.compile(optimizer='sgd', loss='mean_squared_error')
4. 训练模型
训练模型时,我们设置 1000 个训练周期,并传入数据 x 和标签 y。
model.fit(x, y, epochs=1000)
5. 评估模型
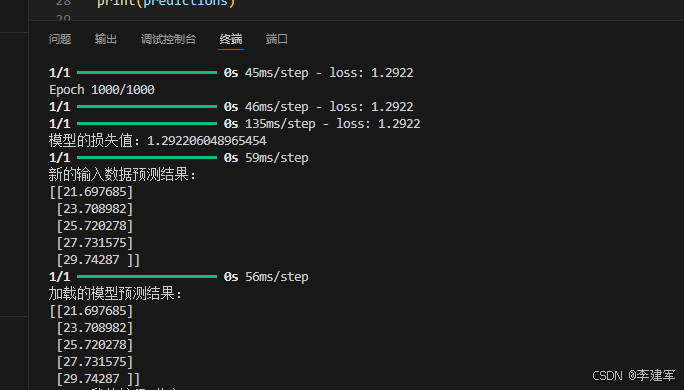
训练结束后,我们评估模型的表现,使用 evaluate 函数来查看损失值。
loss = model.evaluate(x, y)
print(f"模型的损失值:{loss}")
6. 模型应用与预测
训练完成后,我们使用 model.predict() 来进行预测。你可以将新的输入数据传入模型,得到预测结果。
# 使用模型进行预测
new_x = np.array([11, 12, 13, 14, 15], dtype=float)
predictions = model.predict(new_x)print("新的输入数据预测结果:")
print(predictions)
7. 保存与加载模型
你还可以保存和加载训练好的模型,以便在未来使用。\
# 保存模型
model.save('linear_model.keras')# 加载模型
loaded_model = tf.keras.models.load_model('linear_model.keras')# 使用加载的模型进行预测
loaded_predictions = loaded_model.predict(new_x)
print("加载的模型预测结果:")
print(loaded_predictions)
8.完整代码
import numpy as np
import tensorflow as tf# 创建训练数据,x 是输入特征,y 是标签(y = 2 * x + 噪声)
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=float)
y = 2 * x + np.random.normal(0, 1, size=x.shape)# 构建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_dim=1, activation='linear') # 线性激活函数
])# 编译模型
model.compile(optimizer='sgd', loss='mean_squared_error')# 训练模型
model.fit(x, y, epochs=1000)# 评估模型
loss = model.evaluate(x, y)
print(f"模型的损失值:{loss}")# 使用模型进行预测
new_x = np.array([11, 12, 13, 14, 15], dtype=float)
predictions = model.predict(new_x)print("新的输入数据预测结果:")
print(predictions)# 保存模型
model.save('linear_model.keras')# 加载模型
loaded_model = tf.keras.models.load_model('linear_model.keras')# 使用加载的模型进行预测
loaded_predictions = loaded_model.predict(new_x)
print("加载的模型预测结果:")
print(loaded_predictions)
相关文章:
TensorFlow简单的线性回归任务
如何使用 TensorFlow 和 Keras 创建、训练并进行预测 1. 数据准备与预处理 2. 构建模型 3. 编译模型 4. 训练模型 5. 评估模型 6. 模型应用与预测 7. 保存与加载模型 8.完整代码 1. 数据准备与预处理 我们将使用一个简单的线性回归问题,其中输入特征 x 和标…...

【memgpt】letta 课程1/2:从头实现一个自我编辑、记忆和多步骤推理的代理
llms-as-operating-systems-agent-memory llms-as-operating-systems-agent-memory内存 操作系统的内存管理...

6-图像金字塔与轮廓检测
文章目录 6.图像金字塔与轮廓检测(1)图像金字塔定义(2)金字塔制作方法(3)轮廓检测方法(4)轮廓特征与近似(5)模板匹配方法6.图像金字塔与轮廓检测 (1)图像金字塔定义 高斯金字塔拉普拉斯金字塔 高斯金字塔:向下采样方法(缩小) 高斯金字塔:向上采样方法(放大)…...

深入理解Java引用传递
先看一段代码: public static void add(String a) {a "new";System.out.println("add: " a); // 输出内容:add: new}public static void main(String[] args) {String a null;add(a);System.out.println("main: " a);…...

925.长按键入
目录 一、题目二、思路三、解法四、收获 一、题目 你的朋友正在使用键盘输入他的名字 name。偶尔,在键入字符 c 时,按键可能会被长按,而字符可能被输入 1 次或多次。 你将会检查键盘输入的字符 typed。如果它对应的可能是你的朋友的名字&am…...

【Rust自学】15.2. Deref trait Pt.1:什么是Deref、解引用运算符*与实现Deref trait
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 15.2.1. 什么是Deref trait Deref的全写是Dereference,就是引用的英文reference加上"de"这个反义前缀,…...

图书管理系统 Axios 源码__新增图书
目录 功能介绍 核心代码解析 源码:新增图书功能 总结 本项目基于 HTML、Bootstrap、JavaScript 和 Axios 开发,实现了图书的增删改查功能。以下是新增图书的功能实现,适合前端开发学习和项目实践。 功能介绍 用户可以通过 模态框…...

吴恩达深度学习——超参数调试
内容来自https://www.bilibili.com/video/BV1FT4y1E74V,仅为本人学习所用。 文章目录 超参数调试调试选择范围 Batch归一化公式整合 Softmax 超参数调试 调试 目前学习的一些超参数有学习率 α \alpha α(最重要)、动量梯度下降法 β \bet…...

【赵渝强老师】K8s中Pod探针的ExecAction
在K8s集群中,当Pod处于运行状态时,kubelet通过使用探针(Probe)对容器的健康状态执行检查和诊断。K8s支持三种不同类型的探针,分别是:livenessProbe(存活探针)、readinessProbe&#…...

如何对系统调用进行扩展?
扩展系统调用是操作系统开发中的一个重要任务。系统调用是用户程序与操作系统内核之间的接口,允许用户程序执行内核级操作(如文件操作、进程管理、内存管理等)。扩展系统调用通常包括以下几个步骤: 一、定义新系统调用 扩展系统调用首先需要定义新的系统调用的功能。系统…...

ChatGPT与GPT的区别与联系
ChatGPT 和 GPT 都是基于 Transformer 架构的语言模型,但它们有不同的侧重点和应用。下面我们来探讨一下它们的区别与联系。 1. GPT(Generative Pre-trained Transformer) GPT 是一类由 OpenAI 开发的语言模型,基于 Transformer…...

安卓(android)订餐菜单【Android移动开发基础案例教程(第2版)黑马程序员】
一、实验目的(如果代码有错漏,可查看源码) 1.掌握Activity生命周的每个方法。 2.掌握Activity的创建、配置、启动和关闭。 3.掌握Intent和IntentFilter的使用。 4.掌握Activity之间的跳转方式、任务栈和四种启动模式。 5.掌握在Activity中添加…...

Python安居客二手小区数据爬取(2025年)
目录 2025年安居客二手小区数据爬取观察目标网页观察详情页数据准备工作:安装装备就像打游戏代码详解:每行代码都是你的小兵完整代码大放送爬取结果 2025年安居客二手小区数据爬取 这段时间需要爬取安居客二手小区数据,看了一下相关教程基本…...

happytime
happytime 一、查壳 无壳,64位 二、IDA分析 1.main 2.cry函数 总体:是魔改的XXTEA加密 在main中可以看到被加密且分段的flag在最后的循环中与V6进行比较,刚好和上面v6数组相同。 所以毫无疑问密文是v6. 而与flag一起进入加密函数的v5就…...

深度学习 DAY3:NLP发展史
NLP发展史 NLP发展脉络简要梳理如下: (远古模型,上图没有但也可以算NLP) 1940 - BOW(无序统计模型) 1950 - n-gram(基于词序的模型) (近代模型) 2001 - Neural language models&am…...

前端知识速记:节流与防抖
前端知识速记:节流与防抖 什么是防抖? 防抖是一种控制事件触发频率的方法,通常用于处理用户频繁触发事件的场景。防抖的核心思想是将多个连续触发事件合并为一个事件,以减少执行次数。它在以下场景中特别有效: 输入…...

家居EDI:Hom Furniture EDI需求分析
HOM Furniture 是一家成立于1977年的美国家具零售商,总部位于明尼苏达州。公司致力于提供高品质、时尚的家具和家居用品,满足各种家庭和办公需求。HOM Furniture 以广泛的产品线和优质的客户服务在市场上赢得了良好的口碑。公司经营的产品包括卧室、客厅…...

【3】阿里面试题整理
[1]. ES架构,如何进行路由以及选主 路由:在Elasticsearch(ES)中,默认的路由算法是基于文档的_id。具体来说,Elasticsearch会对文档的_id进行哈希计算,然后对分片数量取模,以确定该文…...

【08-飞线和布线与输出文件】
导入网表后 1.复制结构图(带板宽的) 在机械一层画好外围线 2.重新定义板子形状(根据选则对象取定义) 选中对象生成板子线条形状 3.PCB和原理图交叉选择模式 过滤器选择原理图里的元器件 过滤器"OFF",只开启Componnets,只是显示元器件 4. 模块化布局 PCB高亮元…...

python 从知网的期刊导航页面抓取与农业科技相关的数据
要从知网的期刊导航页面抓取与农业科技相关的数据,并提取《土壤学报》2016年06期的结果,可以使用requests库来获取网页内容,BeautifulSoup库来解析HTML。由于知网页面结构可能会发生变化,在实际使用中,需要根据页面结构…...

【单细胞第二节:单细胞示例数据分析-GSE218208】
GSE218208 1.创建Seurat对象 #untar(“GSE218208_RAW.tar”) rm(list ls()) a data.table::fread("GSM6736629_10x-PBMC-1_ds0.1974_CountMatrix.tsv.gz",data.table F) a[1:4,1:4] library(tidyverse) a$alias:gene str_split(a$alias:gene,":",si…...

机器学习优化算法:从梯度下降到Adam及其变种
机器学习优化算法:从梯度下降到Adam及其变种 引言 最近deepseek的爆火已然说明,在机器学习领域,优化算法是模型训练的核心驱动力。无论是简单的线性回归还是复杂的深度神经网络,优化算法的选择直接影响模型的收敛速度、泛化性能…...

.NET Core 中依赖注入的使用
ASP.NET Core中服务注入的地方 在ASP.NET Core项目中一般不需要自己创建ServiceCollection、IServiceProvider。在Program.cs的builder.Build()之前向builder.Services中注入。在Controller中可以通过构造方法注入服务。 低使用频率的服务 把Action用到的服务通过Action的参…...

XML Schema 数值数据类型
XML Schema 数值数据类型 引言 XML Schema 是一种用于描述 XML 文档结构的语言。它定义了 XML 文档中数据的有效性和结构。在 XML Schema 中,数值数据类型是非常重要的一部分,它定义了 XML 文档中可以包含的数值类型。本文将详细介绍 XML Schema 中常用的数值数据类型,以及…...

【机器学习理论】生成模型和判别模型
生成模型和判别模型是机器学习中两种不同的建模方式。生成模型关注的是联合概率分布 P ( X , Y ) P(X, Y) P(X,Y),即同时考虑数据 X X X和标签 Y Y Y的关系;判别模型则直接学习条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)或决策边界。 生成模型 生成模型的目…...

ZZNUOJ(C/C++)基础练习1031——1040(详解版)
1031 : 判断点在第几象限 题目描述 从键盘输入2个整数x、y值,表示平面上一个坐标点,判断该坐标点处于第几象限,并输出相应的结果。 输入 输入x,y值表示一个坐标点。坐标点不会处于x轴和y轴上,也不会在原点。 输出 输出…...

使用PyTorch实现逻辑回归:从训练到模型保存与性能评估
1. 引入必要的库 首先,需要引入必要的库。PyTorch用于构建和训练模型,pandas和numpy用于数据处理,scikit-learn用于计算性能指标。 import torch import torch.nn as nn import torch.optim as optim import pandas as pd import numpy as …...

【C语言】main函数解析
文章目录 一、前言二、main函数解析三、代码示例四、应用场景 一、前言 在学习编程的过程中,我们很早就接触到了main函数。在Linux系统中,当你运行一个可执行文件(例如 ./a.out)时,如果需要传入参数,就需要…...

本地部署 DeepSeek 模型并使用 WebUI 调用
概述 本文将详细介绍如何在本地部署 DeepSeek 模型,并通过 WebUI 调用该模型。我们将使用 open-webui 作为 Web 界面工具,展示如何将 DeepSeek 模型集成到 WebUI 中,并提供一个用户友好的交互界面。 环境准备 在开始之前,请确保你的系统满足以下要求: Python 3.11 或更高…...

深度学习练手小例子——cifar10数据集分类问题
CIFAR-10 是一个经典的计算机视觉数据集,广泛用于图像分类任务。它包含 10 个类别的 60,000 张彩色图像,每张图像的大小是 32x32 像素。数据集被分为 50,000 张训练图像和 10,000 张测试图像。每个类别包含 6,000 张图像,具体类别包括&#x…...