扩散模型(一)
在生成领域,迄今为止有几个主流的模型,分别是 GAN, VAE,Flow 以及 Diffusion 模型。
- GAN:GAN 的学习机制是对抗性学习,通过生成器和判别器的对抗博弈来进行学习,这种竞争机制促使生成器不断提升生成能力,以生成更逼真的数据来欺骗判别器,而判别器也不断提高辨别真假数据的能力。
- VAE:VAE 的学习机制是隐空间编码与重建解码,学习到的潜在空间具有连续性和可解释性,潜在变量的微小变化通常会导致生成结果在语义上的平滑变化,可以通过对潜在变量的操作来实现对生成结果的某种控制。
- Flow:Flow 的学习机制是基于可逆的变换函数构建模型,能够精确地计算数据在不同空间之间的变换,以及相应的概率密度变化,通过一系列可逆变换将简单的先验分布映射到复杂的数据分布。
上面几类模型它们在生成高质量样本方面取得了巨大成功,但每个模型都有其自身的局限性。生成对抗网络(GAN)模型因其对抗训练的特性,存在训练可能不稳定以及生成多样性不足的问题。变分自编码器(VAE)依赖替代损失。流模型(Flow)则必须使用专门的架构来构建可逆变换。

- 图 1:GAN, VAE, FLOW, Diffusion 模型
扩散模型的灵感源自非平衡热力学。它们定义了一个扩散步骤的马尔可夫链,用于逐步向数据中缓慢添加随机噪声,然后学习逆转扩散过程,以便从噪声中构建出所需的数据样本。与变分自编码器(VAE)或流模型不同,扩散模型通过固定的流程进行学习,并且其潜在变量具有高维度(与原始数据维度相同)。
Forward diffusion process
给定一个从真实数据分布中采样得到的数据点 x 0 ∼ q ( x ) \mathbf{x}_0 \sim q(\mathbf{x}) x0∼q(x),我们定义一个正向扩散过程。在这个过程中,我们分 T T T 步向该样本中添加少量高斯噪声,从而生成一系列含噪样本, x 1 , … , x T \mathbf{x}_1, \dots, \mathbf{x}_T x1,…,xT,每一步的步长由方差 { β t ∈ ( 0 , 1 ) } t = 1 T \{\beta_t \in (0, 1)\}_{t=1}^T {βt∈(0,1)}t=1T 控制。
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
随着采样步数 t t t 逐渐增加,数据样本 x 0 \mathbf{x}_0 x0 会逐渐失去其可辨别的特征,最终当 T → ∞ T \to \infty T→∞, x T \mathbf{x}_T xT 等同于一个各向同性的高斯分布。

- 图 2
上述过程的一个优良特性是,我们可以利用重参数化技巧,以封闭形式在任意时间步 t t t 对 x t \mathbf{x}_t xt 进行采样。设 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 并且 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod_{i=1}^t \alpha_i αˉt=∏i=1tαi
x t = α t x t − 1 + 1 − α t ϵ t − 1 ;where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 ;where ϵ ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t ϵ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} & \text{ ;where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} & \text{ ;where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ=N(xt;αˉtx0,(1−αˉt)I) ;where ϵt−1,ϵt−2,⋯∼N(0,I) ;where ϵˉt−2 merges two Gaussians (*).
回想一下,当我们合并两个方差不同的高斯分布, N ( 0 , σ 1 2 I ) \mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I}) N(0,σ12I) 和 N ( 0 , σ 2 2 I ) \mathcal{N}(\mathbf{0}, \sigma_2^2\mathbf{I}) N(0,σ22I), 新的分布为 N ( 0 , ( σ 1 2 + σ 2 2 ) I ) \mathcal{N}(\mathbf{0}, (\sigma_1^2 + \sigma_2^2)\mathbf{I}) N(0,(σ12+σ22)I).合并后的标准差是 ( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1 \sqrt{(1 - \alpha_t) + \alpha_t (1-\alpha_{t-1})} = \sqrt{1 - \alpha_t\alpha_{t-1}} (1−αt)+αt(1−αt−1)=1−αtαt−1
通常,当样本的噪声更大时,我们可以采用更大的更新步长,, 所以 β 1 < β 2 < . . . < β T \beta_1 < \beta_2 < ... < \beta_T β1<β2<...<βT 因此 α ˉ 1 > . . . > α ˉ T \bar{\alpha}_1 > ... > \bar{\alpha}_T αˉ1>...>αˉT
Connection with stochastic gradient Langevin dynamics
朗之万动力学是物理学中的一个概念,用于对分子系统进行统计建模。与随机梯度下降相结合,随机梯度朗之万动力学可以仅利用梯度 ∇ x log p ( x ) \nabla_\mathbf{x} \log p(\mathbf{x}) ∇xlogp(x),通过马尔可夫链更新,从概率密度 p ( x ) p(\mathbf{x}) p(x) 中生成样本:
x t = x t − 1 + δ 2 ∇ x log p ( x t − 1 ) + δ ϵ t , where ϵ t ∼ N ( 0 , I ) \mathbf{x}_t = \mathbf{x}_{t-1} + \frac{\delta}{2} \nabla_\mathbf{x} \log p(\mathbf{x}_{t-1}) + \sqrt{\delta} \boldsymbol{\epsilon}_t ,\quad\text{where } \boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xt=xt−1+2δ∇xlogp(xt−1)+δϵt,where ϵt∼N(0,I)
其中 δ \delta δ 表示步长. 当 T → ∞ , ϵ → 0 T \to \infty, \epsilon \to 0 T→∞,ϵ→0 时, x T \mathbf{x}_T xT 等同于真实概率密度 p ( x ) p(\mathbf{x}) p(x)。
与标准随机梯度下降相比,随机梯度朗之万动力学在参数更新中注入高斯噪声,以避免陷入局部最小值。
Reverse diffusion process
如果我们能逆转上述过程,并且从 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 里进行采样, 我们就能从高斯噪声输入 x T ∼ N ( 0 , I ) \mathbf{x}_T \sim \mathcal{N}(\mathbf{0},\mathbf{I}) xT∼N(0,I) 中重建真实样本,需要注意的是,如果 β t \beta_t βt 如果足够小, q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 也将是高斯分布. 不过,我们难以轻易估算 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 因为这需要使用整个数据集。因此,为了执行反向扩散过程,我们需要训练一个模型 p θ p_\theta pθ 来近似这些条件概率。
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) \quad p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))

- 图 3
值得注意的是当以 x 0 \mathbf{x}_0 x0 为条件时,反向条件概率是易于处理的。
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I}) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
使用贝叶斯准则,可以得到:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1} \vert \mathbf{x}_0) }{ q(\mathbf{x}_t \vert \mathbf{x}_0) } \\ &\propto \exp \Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_t - \sqrt{\alpha_t} \mathbf{x}_{t-1})^2}{\beta_t} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp \Big(-\frac{1}{2} \big(\frac{\mathbf{x}_t^2 - 2\sqrt{\alpha_t} \mathbf{x}_t \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \alpha_t} \color{red}{\mathbf{x}_{t-1}^2} }{\beta_t} + \frac{ \color{red}{\mathbf{x}_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0} \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} \mathbf{x}_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp\Big( -\frac{1}{2} \big( \color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} \mathbf{x}_{t-1}^2 - \color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)} \mathbf{x}_{t-1} \color{black}{ + C(\mathbf{x}_t, \mathbf{x}_0) \big) \Big)} \end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
根据标准高斯密度函数,均值和方差可参数化如下:( α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt and α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod_{i=1}^t \alpha_i αˉt=∏i=1tαi)
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0\\ \end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
根据前面所述,我们可以将 x 0 \mathbf{x}_0 x0 表示成 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) x0=αˉt1(xt−1−αˉtϵt) 然后代入上式,可以得到:
μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \begin{aligned} \tilde{\boldsymbol{\mu}}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) \\ &= \color{red}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} \end{aligned} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)
如图 2 所示,这样的设置与变分自编码器(VAE)非常相似,因此我们可以使用变分下界来优化负对数似然。
− log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + D KL ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) ; KL is non-negative = − log p θ ( x 0 ) + E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] = E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] Let L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ − E q ( x 0 ) log p θ ( x 0 ) \begin{aligned} -\log p_\theta(\mathbf{x}_0) &\leq - \log p_\theta(\mathbf{x}_0) + D_\text{KL}(q(\mathbf{x}_{1:T}\vert\mathbf{x}_0) \| p_\theta(\mathbf{x}_{1:T}\vert\mathbf{x}_0) ) & \small{\text{; KL is non-negative}}\\ &= - \log p_\theta(\mathbf{x}_0) + \mathbb{E}_{\mathbf{x}_{1:T}\sim q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T}) / p_\theta(\mathbf{x}_0)} \Big] \\ &= - \log p_\theta(\mathbf{x}_0) + \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} + \log p_\theta(\mathbf{x}_0) \Big] \\ &= \mathbb{E}_q \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ \text{Let }L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \geq - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \end{aligned} −logpθ(x0)Let LVLB≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0); KL is non-negative
使用詹森不等式也能直接得出相同的结果。假设我们想将最小化交叉熵作为学习目标。
L CE = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ) ≤ − E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = L VLB \begin{aligned} L_\text{CE} &= - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int p_\theta(\mathbf{x}_{0:T}) d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \mathbb{E}_{q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \Big) \\ &\leq - \mathbb{E}_{q(\mathbf{x}_{0:T})} \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \\ &= \mathbb{E}_{q(\mathbf{x}_{0:T})}\Big[\log \frac{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})}{p_\theta(\mathbf{x}_{0:T})} \Big] = L_\text{VLB} \end{aligned} LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
为了使方程中的每一项都能通过解析方式计算,该目标函数可以进一步改写为几个 KL 散度和熵项的组合。
L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ L T + ∑ t = 2 T D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] \begin{aligned} L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ &= \mathbb{E}_q \Big[ \log\frac{\prod_{t=1}^T q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{ p_\theta(\mathbf{x}_T) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t) } \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \Big( \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)}\cdot \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1}\vert\mathbf{x}_0)} \Big) + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1} \vert \mathbf{x}_0)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{q(\mathbf{x}_1 \vert \mathbf{x}_0)} + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big]\\ &= \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_T)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \Big] \\ &= \mathbb{E}_q [\underbrace{D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T))}_{L_T} + \sum_{t=2}^T \underbrace{D_\text{KL}(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t))}_{L_{t-1}} \underbrace{- \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)}_{L_0} ] \end{aligned} LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LT DKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1 DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0 −logpθ(x0∣x1)]
我们分别标记变分下界损失中的每个组成部分:
L VLB = L T + L T − 1 + ⋯ + L 0 where L T = D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) L t = D KL ( q ( x t ∣ x t + 1 , x 0 ) ∥ p θ ( x t ∣ x t + 1 ) ) for 1 ≤ t ≤ T − 1 L 0 = − log p θ ( x 0 ∣ x 1 ) \begin{aligned} L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\ \text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\ L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\ L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \end{aligned} LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
L VLB L_\text{VLB} LVLB 中的每一个 KL 项 (除了 L 0 L_0 L0) 都是在比较两个高斯分布,因此可以用闭式解计算. L T L_T LT 是常数,在训练过程中可以忽略,因为 q q q 没有可学习的参数并且 x T \mathbf{x}_T xT 是一个高斯噪声. 模型 L 0 L_0 L0 依赖一个单独的解码器,该解码器源自 N ( x 0 ; μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 ) ) \mathcal{N}(\mathbf{x}_0; \boldsymbol{\mu}_\theta(\mathbf{x}_1, 1), \boldsymbol{\Sigma}_\theta(\mathbf{x}_1, 1)) N(x0;μθ(x1,1),Σθ(x1,1))
相关阅读:
- 扩散模型(二)
- 扩散模型(三)
参考:
What are Diffusion Models?
Weng, Lilian. (Jul 2021). What are diffusion models? Lil’Log. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/.
相关文章:
扩散模型(一)
在生成领域,迄今为止有几个主流的模型,分别是 GAN, VAE,Flow 以及 Diffusion 模型。 GAN:GAN 的学习机制是对抗性学习,通过生成器和判别器的对抗博弈来进行学习,这种竞争机制促使生成器不断提升生成能力&a…...

【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.12 连续数组:为什么contiguous这么重要?
2.12 连续数组:为什么contiguous这么重要? 目录 #mermaid-svg-wxhozKbHdFIldAkj {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-wxhozKbHdFIldAkj .error-icon{fill:#552222;}#mermaid-svg-…...

O3 模型正式上线,能否与 DeepSeek 一较高下?
OpenAI 最近推出了 GPT O3 模型,并对 ChatGPT Plus 用户的 O3-mini 版本进行了升级,提升了每日消息限额,从 50 条增加至 150 条。这一调整大大提升了用户体验,让更多用户有机会深入体验 O3 模型的能力。那么,O3 模型的…...

在C++中,成员变量必须在对象构造完成前初始化,但初始化的方式有多种...
在C中,成员变量必须在对象构造完成前初始化,但初始化的方式可以有多种,具体取决于成员变量的类型和设计需求。以下是C中成员变量初始化的规则和相关机制: 1. 成员变量必须初始化 如果成员变量是基本类型(如 int、doub…...
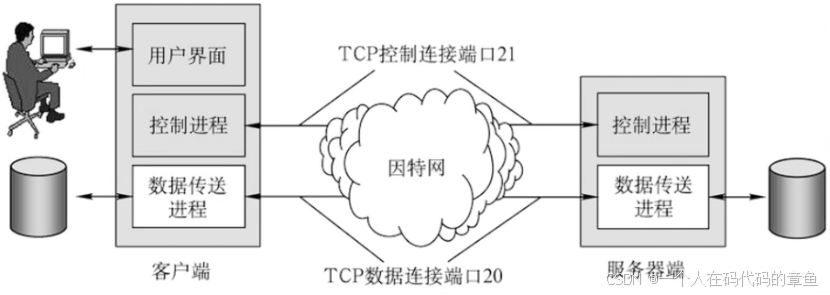
计算机网络 应用层 笔记1(C/S模型,P2P模型,FTP协议)
应用层概述: 功能: 常见协议 应用层与其他层的关系 网络应用模型 C/S模型: 优点 缺点 P2P模型: 优点 缺点 DNS系统: 基本功能 系统架构 域名空间: DNS 服务器 根服务器: 顶级域…...

新到手路由器宽带上网设置八步法
第一步,连接线 运营商接到家里的一般有光纤,然后光纤会接在一个他们提供的光猫上。我们只需将路由器的WAN口通过一截网线接到光猫对应的网口即可。通电并确认指示灯常亮或闪烁 第二步,手机搜索࿳…...

MATLAB的数据类型和各类数据类型转化示例
一、MATLAB的数据类型 在MATLAB中 ,数据类型是非常重要的概念,因为它们决定了如何存储和操作数据。MATLAB支持数值型、字符型、字符串型、逻辑型、结构体、单元数组、数组和矩阵等多种数据类型。MATLAB 是一种动态类型语言,这意味着变量的数…...

[SAP ABAP] SE11 / SE16N 修改标准表(慎用)
1.SE16N修改标准表 使用事务码ME16N进入到查询页面,填入要修改的标准表MARA,在事务码输入框中填入/H,回车之后点击按钮,进入Debug调试界面 把GD-SAPEDIT 与 GD-EDIT 的值更改为X然后点击按钮(快捷键按F8)进行下一步操作 可以在此…...

Arduino大师练成手册 -- 控制 AS608 指纹识别模块
要在 Arduino 上控制 AS608 指纹识别模块,你可以按照以下步骤进行: 硬件连接 连接指纹模块:将 AS608 指纹模块与 Arduino 连接。通常,AS608 使用 UART 接口进行通信。你需要将 AS608 的 TX、RX、VCC 和 GND 引脚分别连接到 Ardu…...

[SAP ABAP] Debug Skill
SAP ABAP Debug相关资料 [SAP ABAP] DEBUG ABAP程序中的循环语句 [SAP ABAP] 静态断点的使用 [SAP ABAP] 在ABAP Debugger调试器中设置断点 [SAP ABAP] SE11 / SE16N 修改标准表(慎用)...

maven mysql jdk nvm node npm 环境安装
安装JDK 1.8 11 环境 maven环境安装 打开网站 下载 下载zip格式 解压 自己创建一个maven库 以后在idea 使用maven时候重新设置一下 这三个地方分别设置 这时候maven才算设置好 nvm 管理 npm nodejs nvm下载 安装 Releases coreybutler/nvm-windows GitHub 一键安装且若有…...

Java实现LFU缓存策略实战
LFU算法原理在Java中示例实现集成Caffeine的W-TinyLFU策略缓存实战总结LFU与LRU稍有不同,LFU是根据数据被访问的频率来决定去留。尽管它考虑了数据的近期使用,但它不会区分数据的首次访问和后续访问,淘汰那些访问次数最少的数据。 这种缓存策略主要用来处理以下场景: 数据…...

安卓(android)饭堂广播【Android移动开发基础案例教程(第2版)黑马程序员】
一、实验目的(如果代码有错漏,可查看源码) 1.熟悉广播机制的实现流程。 2.掌握广播接收者的创建方式。 3.掌握广播的类型以及自定义官博的创建。 二、实验条件 熟悉广播机制、广播接收者的概念、广播接收者的创建方式、自定广播实现方式以及有…...

基于改进的强跟踪技术的扩展Consider Kalman滤波算法在无人机导航系统中的应用研究
在无人机组合导航系统中,精确的状态估计对于任务的成功执行至关重要。然而,系统面临的非线性特性和不确定性,如传感器的量测偏差和动态环境变化,常常导致传统Kalman滤波算法失效。因此,提出一种鲁棒且有效的滤波算法&a…...

1.初识beamer
系列文章目录 初识beamer 文章目录 系列文章目录前言一、什么是beamer1.1 定义和背景1.2 使用场景1.3 Beamer优势 二、overleaf 入门beamer三、开始使用beamer3.1 新建一个beamer文件3.2 创建beamer页/帧3.3 目录页3.4 配置beamer整体风格 结束语 前言 工欲善其事,…...

DeepSeek R1本地化部署 Ollama + Chatbox 打造最强 AI 工具
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 Ollama 🦋 下载 Ollama🦋 选择模型🦋 运行模型🦋 使用 && 测试 二:🔥 Chat…...

C# 操作符重载对象详解
.NET学习资料 .NET学习资料 .NET学习资料 一、操作符重载的概念 在 C# 中,操作符重载允许我们为自定义的类或结构体定义操作符的行为。通常,我们熟悉的操作符,如加法()、减法(-)、乘法&#…...
)
Spring MVC学习——发送请求(@RequestMapping注解及请求参数绑定)
前言 Spring MVC作为Spring框架中的核心组件之一,其强大的功能在于能简洁高效地处理HTTP请求和响应。在开发Web应用时,理解和正确使用Spring MVC的注解,尤其是RequestMapping注解,至关重要。本文将详细讲解RequestMapping注解的使…...
)
数据结构与算法之栈: LeetCode 641. 设计循环双端队列 (Ts版)
设计循环双端队列 https://leetcode.cn/problems/design-circular-deque/description/ 描述 设计实现双端队列。 实现 MyCircularDeque 类: MyCircularDeque(int k) :构造函数,双端队列最大为 k 。boolean insertFront():将一个元素添加到双端队列头部…...

OpenAI 实战进阶教程 - 第二节:生成与解析结构化数据:从文本到表格
目标 学习如何使用 OpenAI API 生成结构化数据(如 JSON、CSV 格式)。掌握解析数据并导出表格文件的技巧,以便适用于不同实际场景。 场景背景 假设你是一名开发人员,需要快速生成一批产品信息列表(如名称、价格、描述…...

《基于Scapy的综合性网络扫描与通信工具集解析》
在网络管理和安全评估中,网络扫描和通信是两个至关重要的环节。Python 的 Scapy 库因其强大的网络数据包处理能力,成为开发和实现这些功能的理想工具。本文将介绍一个基于 Scapy 编写的 Python 脚本,该脚本集成了 ARP 扫描、端口扫描以及 TCP…...

MiniQMT与xtquant:量化交易的利器
MiniQMT与xtquant:量化交易的利器 在量化交易的世界里,工具的选择至关重要。今天,我们将深入探讨券商版的MiniQMT及其核心组件xtquant的使用技巧和实践心得。MiniQMT以其简洁的操作界面和强大的功能,在量化交易者中颇受欢迎。 技…...

如何实现一个CLI命令行功能 | python 小知识
如何实现一个CLI命令行功能 | python 小知识 在现代软件开发中,命令行界面(CLI)的设计与交互至关重要。Click是一个强大的Python库,专门用于快速创建命令行界面,以其简单易用性和丰富的功能赢得了开发者的青睐。本文将…...

基于Python的药物相互作用预测模型AI构建与优化(上.文字部分)
一、引言 1.1 研究背景与意义 在临床用药过程中,药物相互作用(Drug - Drug Interaction, DDI)是一个不可忽视的重要问题。当患者同时服用两种或两种以上药物时,药物之间可能会发生相互作用,从而改变药物的疗效、增加不良反应的发生风险,甚至危及患者的生命安全。例如,…...

Linux环境下的Java项目部署技巧:环境安装
安装 JDK: 第上传 jdk 压缩安装包到服务器 将压缩安装包解压缩: tar -xvf jdk-8uXXX-linux-x64.tar.gz 配置环境变量: 编辑 /etc/profile 文件,在文件末尾添加以下内容: export JAVA_HOME/path/to/jdk //JAVA_HOME…...

【系统迁移】将系统迁移到新硬盘中(G15 5520)
文章目录 前言问题描述解决步骤(红色为 debug 步骤)参考文献 前言 参数: 电脑 dell g15 5520硬盘:1T 自带硬盘 海力士 2230 -> 2T 西数蓝盘 2280 问题描述 电脑硬盘过小(且只有一个接口),将…...
:用于数据降维和特征提取)
pytorch实现主成分分析 (PCA):用于数据降维和特征提取
人工智能例子汇总:AI常见的算法和例子-CSDN博客 使用 PyTorch 实现主成分分析(PCA)可以通过以下步骤进行: 标准化数据:首先,需要对数据进行标准化处理,确保每个特征的均值为 0,方差…...

跨越通信障碍:深入了解ZeroMQ的魅力
在复杂的分布式系统开发中,进程间通信就像一座桥梁,连接着各个独立运行的进程,让它们能够协同工作。然而,传统的通信方式往往伴随着复杂的设置、高昂的性能开销以及有限的灵活性,成为了开发者们前进道路上的 “绊脚石”…...

pytorch实现文本摘要
人工智能例子汇总:AI常见的算法和例子-CSDN博客 import numpy as npfrom modelscope.hub.snapshot_download import snapshot_download from transformers import BertTokenizer, BertModel import torch# 下载模型到本地目录 model_dir snapshot_download(tians…...