【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(二)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨
✨ 个人主页:余辉zmh–CSDN博客
✨ 文章所属专栏:贪心算法篇–CSDN博客

文章目录
- 前言
- 例题
- 1.买卖股票的最佳时机
- 2.买卖股票的最佳时机2
- 3.k次取反后的最大化数组和
- 4.按身高排序
- 5.优势洗牌
- 6.最长回文串
- 7.增减字符串匹配
- 8.分发饼干
前言
本篇文章是对贪心算法练习题的讲解,有关贪心算法的讲解可以看本系列的第一篇文章,这里就不再重复讲解,直接继续讲解例题。
例题
1.买卖股票的最佳时机
题目:

算法原理:
本道题的贪心策略很简单,既然要求获取最高的利润,而且本道题限制只能买卖一次,那么就在整个股票价格中选择最低点买入,最高点卖出即可,这样就能保证利润最大化。
设置两个变量,一个用来标记最低的买价,一个用来标记当前利润;遍历整个股票价格,现将当前价格减去最低的买价更新利润,然后更新当前价格是否是最低价。遍历完整个股票价格后,当前利润就是最大的利润。
代码实现:
int maxProfit(vector<int>& prices){//minnum表示最低的买价,ret表示最高的利润int minnum = INT_MAX, ret = INT_MIN;for(auto x : prices){ret = max(ret, x - minnum);minnum = min(minnum, x);}if(ret<0){return 0;}return ret;
}
2.买卖股票的最佳时机2
题目:

算法原理:
本道题和上一道题不同的是,不再局限于只能买卖一次,可以无限次买卖,只要保证最后的利润是最大的即可。
首先需要明白,什么时候买卖才能有利润不亏损,那就是下一个价格比当前价格低,也就是升序排列,所以在上升趋势段买卖,才会有利润,但是在上升趋势段的什么时候买卖才能最大利润,那肯定就是上升趋势段的最低点和最高点买入和卖出。因此找到所有升序段的利润然后相加就是整体的最大利润。这就是本道题的贪心策略。
这里有两种解法:第一种就是找到一个升序段,标记最低点和最高点的价格,然后直接两个端点相减就是当前整个升序段的利润和;第二种就是只要下一个的价格大于当前价格,就买入和卖出。比如说当前有连续三天的价格都是上升趋势,第一种方式就是在第一天买入,第三天卖出,只找开始和结尾。而第二种方式则是,第一天买入,第二天卖出,然后第二天再买入,第三天卖出,将整个升序段的利润拆分成每一天利润,最后每一天的利润和还是整个升序段的利润和。
代码实现:
//方法一:
int maxProfit(vector<int>& prices){//使用双指针找到上升趋势的最低点和最高点进行买卖int ret = 0;for (int buy = 0; buy < prices.size(); buy++){//卖指针从买指针位置开始找int sell = buy;//找到上身趋势的最高点while(sell+1<prices.size()&&prices[sell]<prices[sell+1]){sell++;}//在当前位置买卖ret += prices[sell] - prices[buy];//更新买指针指向当前位置buy = sell;}return ret;
}
//方法二:
int maxProfit(vector<int>& prices){//在上升趋势段,一天一天地买卖获取利润int ret = 0;for (int i = 0; i < prices.size(); i++){//如果下一个值大于当前值,就直接买卖if(i+1<prices.size()&&prices[i+1]>prices[i]){ret += prices[i + 1] - prices[i];}}return ret;
}
3.k次取反后的最大化数组和
题目:

算法原理:
本道题的题意要求,挑选数组中的一个数变化为相反数,总共需要变化k次,最后使变化后的数组和最大。注意一个数可以变化多次,没有次数限制。
既然题意要求变化后的数组和最大,那么每次变化都挑选最小的数变化不就行了吗,这样就能对数组和的影响减小。但是数组中有正数和负数之分,因此两种情况要分类讨论:如果是负数的话,负数的相反数是正数,可以使数组和变大,因此负数只需变化一次即可;如果是正数的话,还要继续分情况讨论:如果当前剩余的k次为偶数,正数变化两次后还是正数,所以变化偶数次后还是当前数,相当于不变,对数组和无影响直接结束;如果当前剩余的k次为奇数,只需让最小的正数变化一次为负数,这样对数组和的影响最小,然后剩余偶数次,变化偶数次后相当于不变,直接结束即可。这就是本道题的贪心策略。
这里我是用小根堆数据结构来实现,每次直接获取堆顶元素,然后判断正负,负数就变化一次,变化后存放到堆中,正数再判断剩余次数的奇偶,如果是偶数,直接结束,相当于变化偶数次不变;如果是奇数,当前正数因为是最小的正数所以变化一次,剩余偶数次,同理直接结束。最后返回变化后的元素和
代码实现:
struct Greater{bool operator()(const int p1,const int p2){return p1 > p2;}
};
int largestSumAfterKNegations(vector<int>& nums, int k){//建立一个小根堆priority_queue<int, vector<int>, Greater> heap(nums.begin(), nums.end());while(k>0){//获取堆顶元素int t = heap.top();heap.pop();//如果堆顶元素是负数,修改为正数if(t<0){heap.push(-t);k--;}//如果堆顶元素是正数,先判断当前剩余次数else{//如果次数为奇数,修改最小的正数为负数,次数减一,剩余次数就是偶数//下一个正数进行偶数次的变换,相当于不变,直接结束if(k%2==1){heap.push(-t);k = 0;}//如果剩余偶数次,当前正数变化完所有次数,相当于不变,直接结束else{heap.push(t);k = 0;}}}int ret = 0;while(!heap.empty()){ret+=heap.top();heap.pop();}return ret;
}
4.按身高排序
题目:

算法原理:
本道题其实并不是贪心算法题,但是本道题使用的策略会在下一道贪心算法题中用到,因此可以先用这道题练习一下。
本道题就是一道简单的排序问题,一个数组存放的是名字,一个数组存放的是身高,两个数组通过下标可以一一对应名字和身高,然后就是按照身高排序,返回排序后的名字。这里就存在了一个细节问题,如果直接对身高这个数组排序,排完序后,名字数组没有变,就会导致不能再通过下标一一对应名字和身高,最后返回的名字顺序也就是错误的。
本道题有多种解法,第一种就是可以使用二元数组,重新创建一个数组,数组里面存放的是键值对pair<string,int>,使每个名字一一对应各自的身高。然后将数组按照身高排序,最后遍历数组返回名字即可。第二种就是可以借助哈希表,建立名字和身高的映射关系,其实和第一种同理,只不过数据存储方式不一样,实现过程还是相同的。
上面两种方式都可以实现,但这里重点要介绍的还是第三种方式:直接对下标进行排序,建立一个新数组,存放的是每一个下标,然后通过Lambda表达式自定义排序规则,[&]是捕获列表,用于排序时可以访问的外部变量,这里排序的外部变量就是身高数组;()内是参数列表,对应下标数组中需要排序的两个下标;{}内是函数体,也就是排序规则的实现,按照下标对应的身高数组中的身高进行排序。这样自定义排序规则就可以实现下标按照身高排序,不改变原有的名字和身高数组,最后再遍历排序好的下标数组,通过下标就可以找到名字,返回即可。
代码实现:
vector<string> sortPeople(vector<string>& names, vector<int>& heights){//建立一个下标数组int n = names.size();vector<int> index(n);for (int i = 0; i < n; i++){index[i] = i;}//对下标数组进行排序sort(index.begin(), index.end(), [&](const int i, const int j){return heights[i] > heights[j]; });//提取结果vector<string> ret;for(auto i : index){ret.push_back(names[i]);}return ret;
}
5.优势洗牌
题目:

算法原理:

代码实现:
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2){int n = nums1.size(), m = nums2.size();//给数组2创建一个下标数组vector<int> index(m);for (int i = 0; i < m; i++){index[i] = i;}// 数组1直接排序,数组2通过下标数组排序,排升序sort(nums1.begin(), nums1.end());sort(index.begin(), index.end(), [&](const int i, const int j) {return nums2[i] < nums2[j]; });//创建一个结果数组用来存放数组1按题意要求的排序vector<int> ret(n);//两个指针用来指向下标数组的前后位置int left = 0, right = m - 1;for (int i = 0; i < ; i++){//如果第一个数组的值大于第二个数组的当前值,左指针指向下标数组中的位置就是结果数组中存放的下标if(nums1[i]>nums2[index[left]]){ret[index[left++]] = nums1[i];}//如果小于等于,存放到右指针指向的下标位置else{ret[index[right--]] = nums1[i];}}return ret;
}
6.最长回文串
题目:

算法原理:
本道题的贪心策略比较简单,构成回文串时尽可能多地选取字符,先统计所有字符的个数,有奇数个也有偶数个,如果当前字符是偶数个n,那么回文串中一定包含所有的当前字符n个,比如字符a有4个,回文串就是aa|aa,左右两侧平均分;如果当前字符是奇数个n,那么回文串中一定包含当前字符的n-1个,比如字符b有5个,回文串就是bb|bb;当统计完所有字符后,如果最后回文串的长度小于原字符串的长度,说明存在奇数个字符,随便选一个奇数个的字符放到中间|位置,回文串的长度再加一。
代码实现:
int longestPalindrome(string s){//建立哈希表,统计字符的个数unordered_map<char, int> hash;for(auto ch : s){hash[ch]++;}int ret = 0;for(auto& [ch,count] : hash){//不管个数是奇数还是偶数,都是先除以2再乘以2ret += count / 2 * 2;}//如果最后回文串的长度小于原字符串的长度,说明存在奇数个的字符,回文串长度再+1if(ret<s.size()){ret++;}return ret;
}
7.增减字符串匹配
题目:

算法原理:
本道题的贪心策略:原字符串的长度为n,从0到n挑选数字填充数组对应字符串中的每个字符,遇到’I’选择0到n中剩余的最小的数,因为下一个不管位置是字符’I’还是字符’D’,挑选的值都会比当前最小的数大,这样就能满足字符’I’的要求,下一个比当前的大;遇到’D’选择0到n中剩余的最大的数,因为下一个不管位置时字符’I’还是字符’D’,挑选的值都会比当前最大的数小,这样就能满足字符’D’的要求,下一个比当前的小,当遍历完所有的字符后,剩下的一个值填充到数组最后。
代码实现:
vector<int> diStringMatch(string s){//贪心策略:遇到'I'选择最小的数,遇到'D'选择最大的数int n = s.size();//两个指针表示0到n的数字,left表示最小的数,right表示最大的数int left = 0, right = n;vector<int> ret(n + 1);for (int i = 0; i < n; i++){if(s[i]=='I'){ret[i] = left++;}else{ret[i] = right--;}}//最后一个位置用剩下的一个值填充ret[n] = left;return ret;
}
8.分发饼干
题目:

算法原理:
本道题的贪心策略其实和上面优势洗牌一样,同样借助了田忌赛马的原理,只不过本道题比较简单,要求统计的是最多能满足的个数,不用按照数组的格式一一对应返回,所以贪心策略就可以简单化,还是先将两个数组排序然后一一比较,如果两个数能比过,也就是数组s的值大于数组g的值就直接比较下一对,满足个数加一;如果比不过,也就是数组s的值小于数组g的值,不用再和数组g中最大的值比较去拖累最大的值,因为即使和最大的比较也比过,题意要求返回的是满足个数,所以直接跳过当前数组s的值,用下一个比即可。
相较于优势洗牌那道题,本道题还是比较简单的。
代码实现:
int findContentChildren(vector<int>& g, vector<int>& s){//贪心策略,先将两个数组排序,在能满足当前胃口的情况下选择较小的饼干sort(g.begin(),g.end());sort(s.begin(), s.end());int ret = 0;for (int i = 0, j = 0; i < g.size() && j < s.size(); ){//如果当前饼干能满足当前胃口值,直接选择当前饼干if(s[j]>=g[i]){ret++;i++;j++;}//否则,跳过当前饼干else{j++;}}return ret;
}
以上就是关于贪心算法练习题第二部分的讲解,如果哪里有错的话,可以在评论区指正,也欢迎大家一起讨论学习,如果对你的学习有帮助的话,点点赞关注支持一下吧!!!

相关文章:
【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(二)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:贪心算法篇–CSDN博客 文章目录 前言例题1.买卖股票的最佳时机2.买卖股票的最佳时机23.k次取…...

oracle: 表分区>>范围分区,列表分区,散列分区/哈希分区,间隔分区,参考分区,组合分区,子分区/复合分区/组合分区
分区表 是将一个逻辑上的大表按照特定的规则划分为多个物理上的子表,这些子表称为分区。 分区可以基于不同的维度,如时间、数值范围、字符串值等,将数据分散存储在不同的分区 中,以提高数据管理的效率和查询性能,同时…...

基于SpringBoot 前端接收中文显示解决方案
一. 问题 返回给前端的的中文值会变成“???” 二. 解决方案 1. 在application.yml修改字符编码 (无效) 在网上看到说修改servlet字符集编码,尝试了不行 server:port: 8083servlet:encoding:charset: UTF-8enabled: trueforce: true2. …...

java练习(5)
ps:题目来自力扣 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这…...

python算法和数据结构刷题[3]:哈希表、滑动窗口、双指针、回溯算法、贪心算法
回溯算法 「所有可能的结果」,而不是「结果的个数」,一般情况下,我们就知道需要暴力搜索所有的可行解了,可以用「回溯法」。 回溯算法关键在于:不合适就退回上一步。在回溯算法中,递归用于深入到所有可能的分支&…...

大数据数仓实战项目(离线数仓+实时数仓)1
目录 1.课程目标 2.电商行业与电商系统介绍 3.数仓项目整体技术架构介绍 4.数仓项目架构-kylin补充 5.数仓具体技术介绍与项目环境介绍 6.kettle的介绍与安装 7.kettle入门案例 8.kettle输入组件之JSON输入与表输入 9.kettle输入组件之生成记录组件 10.kettle输出组件…...

【开源免费】基于Vue和SpringBoot的公寓报修管理系统(附论文)
本文项目编号 T 186 ,文末自助获取源码 \color{red}{T186,文末自助获取源码} T186,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

使用QMUI实现用户协议对话框
使用QMUI实现用户协议对话框 懒加载用于初始化 TermServiceDialogController 对象。 懒加载 lazy var 的作用 lazy var dialogController: TermServiceDialogController {let r TermServiceDialogController()r.primaryButton.addTarget(self, action: #selector(primaryC…...

女生年薪12万,算不算属于高收入人群
在繁华喧嚣的都市中,我们时常会听到关于收入、高薪与生活质量等话题的讨论。尤其是对于年轻女性而言,薪资水平不仅关乎个人价值的体现,更直接影响到生活质量与未来的规划。那么,女生年薪12万,是否可以被划入高收入人群…...

初识Cargo:Rust的强大构建工具与包管理器
初识Cargo:Rust的强大构建工具与包管理器 如果你刚刚开始学习Rust,一定会遇到一个名字:Cargo。Cargo是Rust的官方构建工具和包管理器,它让Rust项目的创建、编译、测试和依赖管理变得非常简单。本文将带你快速了解Cargo的基本用法…...

【Windows7和Windows10下从零搭建Qt+Leaflet开发环境】
Windows7和Windows10下从零搭建QtLeaflet开发环境 本文开始编写于2025年1月27日星期一(农历:腊月二十八,苦逼的人,过年了还在忙工作)。 第一章 概述 整个开发环境搭建需要的资源: 操作系统 Windows7_x6…...

关于MySQL InnoDB存储引擎的一些认识
文章目录 一、存储引擎1.MySQL中执行一条SQL语句的过程是怎样的?1.1 MySQL的存储引擎有哪些?1.2 MyIsam和InnoDB有什么区别? 2.MySQL表的结构是什么?2.1 行结构是什么样呢?2.1.1 NULL列表?2.1.2 char和varc…...

WSL2中安装的ubuntu开启与关闭探讨
1. PC开机后,查询wsl状态 在cmd或者powersell中输入 wsl -l -vNAME STATE VERSION * Ubuntu Stopped 22. 从windows访问WSL2 wsl -l -vNAME STATE VERSION * Ubuntu Stopped 23. 在ubuntu中打开一个工作区后…...

LeetCode435周赛T2贪心
题目描述 给你一个由字符 N、S、E 和 W 组成的字符串 s,其中 s[i] 表示在无限网格中的移动操作: N:向北移动 1 个单位。S:向南移动 1 个单位。E:向东移动 1 个单位。W:向西移动 1 个单位。 初始时&#…...

π0:仅有3B数据模型打通Franka等7种机器人形态适配,实现0样本的完全由模型自主控制方法
Chelsea Finn引领的Physical Intelligence公司,专注于打造先进的机器人大模型,近日迎来了一个令人振奋的里程碑。在短短不到一年的时间内,该公司成功推出了他们的首个演示版本。这一成就不仅展示了团队的卓越技术实力,也预示着机器…...

DeepSeek-R1 低成本训练的根本原因是?
在人工智能领域,大语言模型(LLM)正以前所未有的速度发展,驱动着自然语言处理、内容生成、智能客服等众多应用的革新。然而,高性能的背后往往是高昂的训练成本,动辄数百万美元的投入让许多企业和研究机构望而…...

pandas(二)读取数据
一、读取数据 示例代码 import pandaspeople pandas.read_excel(../002/People.xlsx) #读取People数据 print(people.shape) # 打印people表的行数、列数 print(people.head(3)) # 默认打印前5行,当前打印前3行 print("") print(people.tail(3)) # 默…...

北京门头沟区房屋轮廓shp的arcgis数据建筑物轮廓无偏移坐标测评
在IT行业中,地理信息系统(GIS)是用于处理、分析和展示地理空间数据的重要工具,而ArcGIS则是GIS领域中的一款知名软件。本文将详细解析标题和描述中提及的知识点,并结合“门头沟区建筑物数据”这一标签,深入…...

【自学笔记】Java的重点知识点-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Java知识点概览一、Java简介二、Java基本语法三、面向对象编程(OOP)四、异常处理五、常用类库六、多线程编程七、网络编程 注意事项 总结 Ja…...
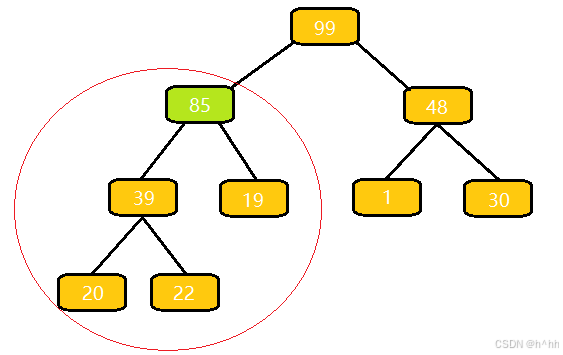
向上调整算法(详解)c++
算法流程: 与⽗结点的权值作⽐较,如果⽐它⼤,就与⽗亲交换; 交换完之后,重复 1 操作,直到⽐⽗亲⼩,或者换到根节点的位置 这里为什么插入85完后合法? 我们插入一个85,…...

LabVIEW无线齿轮监测系统
本案例介绍了基于LabVIEW的无线齿轮监测系统设计。该系统利用LabVIEW编程语言和改进的天牛须算法优化支持向量机,实现了无线齿轮故障监测。通过LabVIEW软件和相关硬件,可以实现对齿轮箱振动信号的采集、传输和故障识别,集远程采集、数据库存储…...

用deepseek解决python问题——在cmd终端运行python指令弹出应用商店,检查路径已经加入环境变量
首先上结论:可行性非常强 当然我没有广泛对比,至少豆包解决方案基本上就是网络上能搜到的一些方法,没有帮我解决,下面直接看一下对话吧 我:在cmd运行python指令弹出应用商店,检查路径已经加入环境变量 D…...

力扣第435场周赛讲解
文章目录 题目总览题目详解3442.奇偶频次间的最大差值I3443.K次修改后的最大曼哈顿距离3444. 使数组包含目标值倍数的最少增量3445.奇偶频次间的最大差值 题目总览 奇偶频次间的最大差值I K次修改后的最大曼哈顿距离 使数组包含目标值倍数的最少增量 奇偶频次间的最大差值II …...

内存四区
一、内存四区模型 1. 操作系统把物理硬盘代码load到内存 2. 操作系统把c代码分成四个区 3. 操作系统遭到main函数入口执行 二、内存四区 1. 栈区(stack) 由编译器自动分配释放,存放函数的参数值,局部变量的值。其操作方式类似…...

大模型综合性能考题汇总
- K1.5长思考版本 一、创意写作能力 题目1:老爸笑话 要求:写五个原创的老爸笑话。 考察点:考察模型的幽默感和创意能力,以及对“原创”要求的理解和执行能力。 题目2:创意故事 要求:写一篇关于亚伯拉罕…...

Python - pyautogui库 模拟鼠标和键盘执行GUI任务
安装库: pip install pyautogui 导入库:import pyautogui 获取屏幕尺寸: s_width, s_height pyautogui.size() 获取鼠标当前位置: x, y pyautogui.position() 移动鼠标到指定位置(可以先使用用上一个函数调试获取当…...

c++ list的front和pop_front的概念和使用案例—第2版
在 C 标准库中,std::list 的 front() 和 pop_front() 是与链表头部元素密切相关的两个成员函数。以下是它们的核心概念和具体使用案例: 1. front() 方法 概念: 功能:返回链表中第一个元素的引用(直接访问头部元素&am…...

租赁管理系统在促进智能物业运营中的关键作用和优化策略分析
租赁管理系统在智能物业运营中的关键作用与优化策略 随着科技的飞速发展,租赁管理系统在智能物业运营中扮演着越来越重要的角色。这种系统不仅提高了物业管理的效率,更是促进了资源的优化配置和客户关系的加强。对于工业园、产业园、物流园、写字楼和公…...

【论文复现】基于Otsu方法的多阈值图像分割改进鲸鱼优化算法
目录 1.摘要2.鲸鱼优化算法WOA原理3.改进策略4.结果展示5.参考文献6.代码获取 1.摘要 本文提出了一种基于Otsu方法的多阈值图像分割改进鲸鱼优化算法(RAV-WOA)。RAV-WOA算法能够在分割灰度图像和彩色图像时,自动选择最优阈值,并确…...

TypeScript 运算符
TypeScript 运算符 TypeScript 作为 JavaScript 的超集,在 JavaScript 的基础上增加了静态类型系统,使得开发大型应用更加容易和维护。在 TypeScript 中,运算符是执行特定数学或逻辑运算的符号。本文将详细介绍 TypeScript 中常见的运算符,并对其使用方法进行详细阐述。 …...