使用Pytorch训练一个图像分类器
一、准备数据集
一般来说,当你不得不与图像、文本或者视频资料打交道时,会选择使用python的标准库将原始数据加载转化成numpy数组,甚至可以继续转换成torch.*Tensor。
- 对图片而言,可以使用Pillow库和OpenCV库
- 对视频而言,可以使用scipy库和librosa库
- 对文本而言,可以使用基于原生Python或Cython加载,或NLTK和SpaCy等。
Pytorch特别针对视觉方面创建torchvision库,其中包含能够加载ImageNet、CIFAR10和MNIST等数据集的数据加载功能,对图像的数据增强功能,即torchvision.datasets和torch.utils.data.DataLoader。
这为大家搭建数据集提供了极大的便利,避免了需要自己写样板代码的情况。
本次我们使用CIFAR10数据集。这是一个含有“飞机”、“汽车”、“鸟”、“猫”、“鹿”、“狗”、“青蛙”、“马”、“轮船”和“卡车”等10个分类的数据集。数据集中每张图像均为[C×H×W]=[3×32×32]即3通道的高32像素宽32像素的彩色图像。

CIFAR-10数据集示例
二、训练图像分类器
下面的步骤大概可以分成5个有序部分:
- 用 torchvision 载入(loading)并归一化(normalize)CIFAR10训练数据集和测试数据集
- 定义卷积神经网络(CNN)
- 定义损失函数和优化器
- 训练网络
- 测试网络
P.S. 以下给出的代码均为在CPU上运行的代码。但本人在pycharm中运行的为自己修改过的在GPU上训练的代码,示例结果和截图也都是GPU运行的结果。
2.1 载入并归一化CIFAR10数据集
用torchvision载入CIFAR10
import torch
import torchvision
import torchvision.transforms as transformstorchvision加载的数据集是PILImage,数据范围[0,1]。我们需要使用transform函数将其归一化(normalize)为[-1,1]。
细心的伙伴发现了我将英文的normalize翻译成了“归一化”而不是标准化,这是因为接下来的代码你会看到预处理阶段transformer变量存储的处理操作仅仅是运用了normalize的计算规则将数据范围进行了缩放,并没有改变数据的分布,因此翻译成“归一化”更合理。
NOTE.(抄的原文,以防有小伙伴真的遇到这个意外问题)
If running on Windows and you get a BrokenPipeError,
try setting the num_worker of torch.utils.data.DataLoader() to 0。
--snip--transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])batch_size = 4trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')transform中的ToTensor和Normalize函数究竟在做什么,以及为什么要归一化等问题感兴趣的小伙伴可以阅读附录中的序号1~3文章,其中
- 博主“小研一枚”[1]通过源码为我们讲解函数的计算行为定义等知识点
- 答主"Transformer"[2]通过知乎专栏为我们做了几组代码实例。而我们则要看清文章、留言区争论的核心与我们真正求索的问题之间的区别和联系,避免被争论本身误导
- 答主“JMD”[3]则为我们科普归一化的相关知识
书归正题,上述代码第一次运行的结果可能是这样子的:
数据集加载运行日志
此时,我们可以使用numpy库和matplotlib库查看数据集中的图片和标签。
import matplotlib.pyplot as plt
import numpy as np# functions to show an image
def imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))但是如果你就这样将代码copy+paste在pycharm中直接接续在载入数据的代码下面点击“运行”,有可能得到的是一个RuntimeError,并建议你按照惯例设置if __name__ == '__main__':
所以,我建议将目前为止的代码优化成下面的样子:
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader # 如果torch.utils.data.DataLoader()有报错提示“在 '__init__.py' 中找不到引用 'data'则增加此语句或者其他语句 ”
import matplotlib.pyplot as plt
import numpy as np
# ①←后续如果继续导入packages,请直接在这里插入代码transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])batch_size = 4trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')def imshow(img):"""显示图像的函数"""img = img / 2 + 0.5 # 去归一化npimg = img.numpy()# 上面transform.ToTensor()操作后数据编程CHW[通道靠前模式],需要转换成HWC[通道靠后模式]才能plt.imshow()plt.imshow(np.transpose(npimg, (1, 2, 0))) # 转置前将排在第0位的Channel(C)放在最后,所以是(1,2,0)plt.show()# ②←后续再有定义class、function等在此插入代码编写if __name__ == '__main__':# 随机输出一个mini-batch的图像dataiter_tr = iter(trainloader) # 取一个batch的训练集数据# images_tr, labels_tr = dataiter_tr.next() 根据你的python选择迭代器调用语句images_tr, labels_tr = next(dataiter_tr) # 切分数据和标签imshow(torchvision.utils.make_grid(images_tr)) # 生成网格图print(' '.join(f'{classes[labels_tr[j]]:5s}' for j in range(batch_size))) # 打印标签值# print(' '.join('%5s' % classes[labels_tr[j]] for j in range(batch_size))) 如果你使用python3.6之前的版本,那么有可能无法使用f字符串语句,只能使用.format()方法# ③←后续的程序执行语句在此插入输出图像示例:

随机输出一个mini-batch的训练集图像
标签输出:bird cat deer ship
2.2 定义一个卷积神经网络
可以将之前写过的识别手写数字MNIST的神经网络迁移到这里来。
# 在①后插入import代码
import torch.nn as nn
import torch.nn.functional as F# 在②后插入神经网络定义代码
class Net(nn.Module):"""定义一个卷积神经网络及前馈函数"""def __init__(self):"""初始化网络:定义卷积层、池化层和全链接层"""super().__init__() # 继承父类属性。P.S. 如果看到super(Net, self).__init__()写法亦可self.conv1 = nn.Conv2d(3, 6, 5) # 使用2套卷积核。输入(B×3×32×32),输出(B×6×28×28)self.pool = nn.MaxPool2d(2, 2) # 最大池化操作,输出时高、宽减半,(B×6×14×14) (B×16×5×5)self.conv2 = nn.Conv2d(6, 16, 5) # 使用4套卷积核,卷积核大小为5×5。(B×16×10×10)self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全链接层。将数据扁平化成一维,共400个输入,120个输出self.fc2 = nn.Linear(120, 84) # 全链接层。120个输入,84个输出self.fc3 = nn.Linear(84, 10) # 全链接层。84个输入,10个输出用于分类def forward(self, x):"""前馈函数,规定数据正向传播的规则"""x = self.pool(F.relu(self.conv1(x))) # 输入 > conv1卷积 > ReLu激活 > maxpool最大池化x = self.pool(F.relu(self.conv2(x))) # > conv2卷积 > ReLu激活 > maxpool最大池化# x = torch.flatten(x, 1) # 如果你不喜欢下一种写法实现扁平化,可以使用这条语句代替x = x.view(-1, 16 * 5 * 5) # 相当于numpy的reshape。此处是将输入数据变换成不固定行数,因此第一个参数是-1,完成扁平化x = F.relu(self.fc1(x)) # 扁平化数据 > fc1全链接层 > ReLu激活x = F.relu(self.fc2(x)) # > fc2全链接层 > ReLu激活x = self.fc3(x) # > fc3全链接层 > 输出return x# 在③后插入神经网络实例化代码
net = Net() # 实例化神经网络2.3 定义损失函数和优化器
我们使用多分类交叉熵损失函数(Classification Cross-Entropy loss)[4]和随机梯度下降法(SGD)的动量改进版(momentum)[5][6]
# 在①后插入import代码
import torch.optim as optim# 在③后插入代码
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)这里必须做一个扩展。
在2.2中我们可以看到神经网络中,每个层的输出都经过了激活函数的激活作用。但是在输出层后却缺少了激活函数而貌似“直接作用了损失函数”。
简单地说,原因就在于torch.nn.CrossEntropyLoss()将nn.LogSoftmax()激活函数和nn.NLLLoss()负对数似然损失函数集成在一起。
logsoftmax是argmax => softargmax => softmax => logsoftmax逐步优化的求极大值的index的期望的方法。负对数似然损失函数(Negtive Log Likehood)就是计算最小化真实分布 P(y|x) 与模型输出分布 P(y^|x) 的距离,等价于最小化两者的交叉熵。实际使用函数时,是one-hot编码后的标签与logsoftmax结果相乘再求均值再取反,这个过程博主“不愿透漏姓名的王建森”在他的博客中做过实验[7]讲解。
上述结论的详尽说明请参考知乎上Cassie的创作《吃透torch.nn.CrossEntropyLoss()》[8]、知乎上Gordon Lee的创作《交叉熵和极大似然估计的再理解》[9]。
P.S. 对于torch.nn.CrossEntropyLoss()的官网Doc中提到的"This is particularly useful when you have an unbalanced training set."关于如何处理不均衡样品的几个解决办法,可以参考Quora上的问答《In classification, how do you handle an unbalanced training set?》[10]以及热心网友对此问答的翻译[11]。
2.4 训练神经网络
事情变得有趣起来了!我们只需要遍历我们的迭代器,将其输入进神经网络和优化器即可。
如果想在GPU上训练请参考文章开头给出的【学习源】链接中的末尾部分有教授如何修改代码的部分。
--snip--# 在③后插入代码for epoch in range(5): # 数据被遍历的次数running_loss = 0.0 # 每次遍历前重新初始化loss值for i, data in enumerate(trainloader, 0):inputs, labels = data # 切分数据集optimizer.zero_grad() # 梯度清零,避免上一个batch迭代的影响# 前向传递 + 反向传递 + 权重优化outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 输出日志running_loss += loss.item() # Tensor.item()方法是将tensor的值转化成python numberif i % 2000 == 1999: # 每2000个mini batches输出一次# print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) 如果python3.6之前版本可以使用这个代码print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')running_loss = 0.0print('Finished Training')Out:
model will be trained on device: 'cuda:0'
某一次输出结果日志整理一下如下表:

Finished Training
将loss数据整理并画图(选做):
--snip--x = np.linspace(2000, 12000, 6, dtype=np.int32)
# 数据每次训练输出都不一样,给出画图代码,至于数据,大家寄几填吧~
epoch_01 = np.array([...])
epoch_02 = np.array([...])
epoch_03 = np.array([...])
epoch_04 = np.array([...])
epoch_05 = np.array([...])plt.plot(x, epoch_01, 'ro-.', x, epoch_02, 'bo-.', x, epoch_03, 'yo-.', x, epoch_04, 'ko-.', x, epoch_05, 'go-.')
plt.legend(['Epoch_1', 'Epoch_2', 'Epoch_3', 'Epoch_4', 'Epoch_5'])
plt.xlabel('number of mini-batches')
plt.ylabel('loss')
plt.title('Loss during CIFAR-10 training procedure in Convolution Neural Networks')
plt.show()
通过数据我们可以看出loss的下降趋势:
- 第一个epoch的最明显
- 第二个epoch继续降低,但趋势更平缓
- 后三个epoch在开始较前一个epoch有较明显下降,但下降幅度递减
- *后三个epoch在该epoch内下降趋势平缓,或出现小幅震荡并保持低于前一个epoch
现在我们可以快速保存训练完成的模型到指定的路径。
--snip--PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)保存的文件

2.5 测试神经网络
我们已经用训练集数据将神经网络训练了5次(epoches=5)。但我们还需要核实神经网络是否真的学到了什么。
我们将以神经网络预测的类别标签和真实标签进行对比核实。如果预测正确,则将样本添加到正确预测列表中。
首先我们像查看训练集的一个mini batch图像一样,看一下一部分测试集图像。
--snip--dataiter_te = iter(testloader)images_te, labels_te = next(dataiter_te) # 另一种备用写法参考训练集部分imshow(torchvision.utils.make_grid(images_te))print('GroundTruth: ', ' '.join('%5s' % classes[labels_te[j]] for j in range(batch_size))) # 另一种备用写法参考训练集部分
随机输出一个mini-batch的测试集图像
Out:
GroundTruth: cat ship ship plane
下面,我们载入之前保存的模型(注:保存和再载入模型不是必要步骤,这里这么做是为了演示这些操作):
--snip--net = Net()
net.load_state_dict(torch.load(PATH))OK,现在让我们看看神经网络如何看待这些图像的分类的:
--snip--outputs = net(images) # 看一下神经网络对上述展示图片的预测结果输出的是10个分类的“能量(energy)”。某个分类的能量越高,意味着神经网络认为该图像越符合该分类。因此我们可以获得那个能量的索引。
--snip--_, predicted = torch.max(outputs, 1) # torch.max(input, dim)返回按照dim方向的最大值和其索引print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}' for j in range(batch_size)))Out:
Predicted: cat ship ship ship
看起来不错。下面就试一试在全部测试集上的表现:
correct = 0total = 0# 由于这不是在训练模型,因此对输出不需要计算梯度等反向传播过程with torch.no_grad():for data in testloader:images_pre, labels_pre = dataoutputs = net(images_pre) # 数据传入神经网络,计算输出_, predicted = torch.max(outputs.data, 1) # 获取最大能量的索引total += labels_pre.size(0) # 计算预测次数correct += (predicted == labels_pre).sum().item() # 计算正确预测次数print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')Out:
Accuracy of the network on the 10000 test images: 61 %

感觉预测的准确率比随机从10个类中蒙一个类(概率10%)要高,看来神经网络确实学到了一些东西。
当然,我们还可以看一下对于不同的类的学习效果:
--snip--# 生成两个dict,分别用来存放预测正确数量和总数量的个数
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}# 启动预测过程,无需计算梯度等
with torch.no_grad():for data in testloader:images_cl, labels_cl = dataoutputs = net(images_cl)_, predictions = torch.max(outputs, 1)# 开始计数for label, prediction in zip(labels_cl, predictions):if label == prediction:correct_pred[classes[label]] += 1total_pred[classes[label]] += 1# 分类别打印预测准确率
for classname, correct_count in correct_pred.items():accuracy = 100 * float(correct_count) / total_pred[classname]print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')Out:
Accuracy for class: plane is 66.2 %
Accuracy for class: car is 80.7 %
Accuracy for class: bird is 39.1 %
Accuracy for class: cat is 53.4 %
Accuracy for class: deer is 64.6 %
Accuracy for class: dog is 35.8 %
Accuracy for class: frog is 67.9 %
Accuracy for class: horse is 69.5 %
Accuracy for class: ship is 75.0 %
Accuracy for class: truck is 65.5 %

至此,我们完成了练习!
在结束前,让我们反思一下准确率为何会呈现上述样子,我推测:
- 数据集本身缺陷,如图片太小(32×32)不足以让卷积神经网络提取到足够特征,类别划分不合理(汽车&卡车,以及飞机&鸟等较其他类别而言是否太过相似),各类别图像数量和图像本身质量等
- 数据的预处理不足,预处理阶段对数据的增强不够,是否可以加入旋转/镜像/透视、裁剪、亮度调节、噪声/平滑等处理
- 神经网络本身的结构、参数设置等是否合理,如卷积/全链接层数的规定、卷积核相关的定义、损失函数的选择、batch size/epoch的平衡等(希望可以通过学习后续的Alexnet、VGG、Resnet、FastRCNN、YOLO等受到启发)
- 避免偶然。不能以单次的结果去评价,评价应当建立在若干次重复试验的基础上
本文翻译至:Training a Classifier — PyTorch Tutorials 2.6.0+cu124 documentation
参考
- pytorch的transform中ToTensor接着Normalize http://t.csdn.cn/bCDSU
- pytorch中归一化transforms.Normalize的真正计算过程 - Transformer的文章 - 知乎 https://zhuanlan.zhihu.com/p/414242338
- 标准化/归一化的目的和作用 - JMD的文章 - 知乎 https://zhuanlan.zhihu.com/p/465264729
- Doc--torch.nn.CrossEntropyLoss CrossEntropyLoss — PyTorch 2.6 documentation
- Doc-torch.optim.SGD SGD — PyTorch 2.6 documentation
- 深度学习中常用优化器的总结 - Alex Chung的文章 - 知乎 https://zhuanlan.zhihu.com/p/166362509
- ^交叉熵的数学原理及应用——pytorch中的CrossEntropyLoss()函数 交叉熵的数学原理及应用——pytorch中的CrossEntropyLoss()函数 - 不愿透漏姓名的王建森 - 博客园
- ^吃透torch.nn.CrossEntropyLoss() - Cassie的文章 - 知乎 https://zhuanlan.zhihu.com/p/159477597
- 交叉熵和极大似然估计的再理解 - Gordon Lee的文章 - 知乎 https://zhuanlan.zhihu.com/p/165139520
- In classification, how do you handle an unbalanced training set? https://www.quora.com/In-classification-how-do-you-handle-an-unbalanced-training-set
- 如何处理训练样本不均衡的问题 http://t.csdn.cn/FDVYJ
相关文章:
使用Pytorch训练一个图像分类器
一、准备数据集 一般来说,当你不得不与图像、文本或者视频资料打交道时,会选择使用python的标准库将原始数据加载转化成numpy数组,甚至可以继续转换成torch.*Tensor。 对图片而言,可以使用Pillow库和OpenCV库对视频而言…...

PythonStyle MVC 开发框架
在 Python 中,MVC(Model - View - Controller,模型 - 视图 - 控制器)是一种常见的软件设计模式,它将应用程序分为三个主要部分,各自承担不同的职责,以提高代码的可维护性、可扩展性和可测试性。…...

HTTP协议的无状态和无连接
无连接 ①无连接的含义 这里所说的无连接并不是指不连接,客户与服务器之间的HTTP连接是一种一次性连接,它限制每次连接只处理一个请求,当服务器返回本次请求的应答后便立即关闭连接,下次请求再重新建立连接。这种一次性连接主要考…...

毫秒级响应的VoIP中的系统组合推荐
在高并发、低延迟、毫秒级响应的 VoIP 场景中,选择合适的操作系统组合至关重要。以下是针对 Ubuntu linux-lowlatency、CentOS Stream kernel-rt 和 Debian 自定义 PREEMPT_RT 的详细对比及推荐: 1. 系统组合对比 特性Ubuntu linux-lowlatencyCentO…...

PWN--格式化字符串
简介 格式化字符串是指在编程过程中,通过特殊的占位符将相关对应的信息整合或提取的规则字符串。格式化字符串包括格式化输入和格式化输出,其本质是程序员调用相关格式化字符串的操作协议规定。错误的或不当的信息配置可能导致程序运行失效或产生未…...
使用记录2-基于tf.keras.layers创建层)
tf.Keras (tf-1.15)使用记录2-基于tf.keras.layers创建层
tf.keras.layers是keras的主要网络创建方法,里面已经有成熟的网络层,也可以通过继承的方式自定义神经网络层。 在keras的model定义中,为了保证所有对数据的操作都是可追溯、可保存、可反向传播,需要保证对数据的任何操作都是基于t…...

面试经典150题——栈
文章目录 1、有效的括号1.1 题目链接1.2 题目描述1.3 解题代码1.4 解题思路 2、2.1 题目链接2.2 题目描述2.3 解题代码2.4 解题思路 3、最小栈3.1 题目链接3.2 题目描述3.3 解题代码3.4 解题思路 4、逆波兰表达式求值4.1 题目链接4.2 题目描述4.3 解题代码4.4 解题思路 5、基本…...

FBX SDK的使用:读取Mesh
读取顶点数据 要将一个Mesh渲染出来,必须要有顶点的位置,法线,UV等顶点属性,和三角面的顶点索引数组。在提取这些数据之前,先理解FBX SDK里面的几个概念: Control Point 顶点的位置,就是x,y,z…...

EtherCAT主站IGH-- 49 -- 搭建xenomai系统及自己的IGH主站
EtherCAT主站IGH-- 49 -- 搭建xenomai系统及自己的IGH主站 0 Ubuntu18.04系统IGH博客、视频欣赏链接一 移植xenomai系统1,下载安装工具包2,下载linux内核及xenomai2.1,下载linux内核2.2,下载xenomai2.3,下载补丁ipipe2.4,解压缩包3,打补丁4,配置内核5,编译内核6,安装编译好的内…...

Java控制台登录系统示例代码
实现一个简单的登录系统需要包括用户输入用户名和密码、验证用户信息等功能。以下是一个简单的Java控制台登录系统示例代码。这个系统使用一个简单的用户信息存储方式(如数组或哈希表),并提供基本的登录验证功能。 示例代码 import java.ut…...
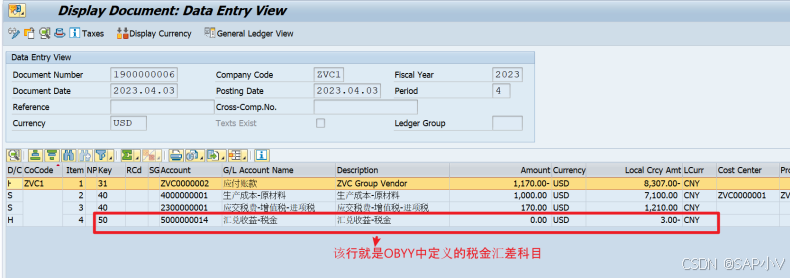
S4 HANA明确税金汇差科目(OBYY)
本文主要介绍在S4 HANA OP中明确税金汇差科目(OBYY)相关设置。具体请参照如下内容: 1. 明确税金汇差科目(OBYY) 以上配置点定义了在外币挂账时,当凭证抬头汇率和税金行项目汇率不一致时,造成的差异金额进入哪个科目。此类情况只发生在FB60/F…...
基础教程)
Web-3.0(Solidity)基础教程
Solidity 是 以太坊智能合约编程语言,用于编写 去中心化应用(DApp)。如果你想开发 Web3.0 应用,Solidity 是必学的。 Remix - Ethereum IDE(在线编写 Solidity) 特性Remix IDEHardhat适用场景适合 初学者 …...

深入理解linux中的文件(上)
1.前置知识: (1)文章 内容 属性 (2)访问文件之前,都必须打开它(打开文件,等价于把文件加载到内存中) 如果不打开文件,文件就在磁盘中 (3&am…...

背包问题和单调栈
背包问题(动态规划) 动态五步曲 dp数组及下标索引的含义递推公式dp数组如何初始化遍历顺序打印dp数组 01背包:n种物品,有一个,二维数组遍历顺序可以颠倒,(滚动数组)一维数组遍历顺序不可颠倒…...

Airflow:深入理解Apache Airflow Task
Apache Airflow是一个开源工作流管理平台,支持以编程方式编写、调度和监控工作流。由于其灵活性、可扩展性和强大的社区支持,它已迅速成为编排复杂数据管道的首选工具。在这篇博文中,我们将深入研究Apache Airflow 中的任务概念,探…...

WebSocket——环境搭建与多环境配置
一、前言:为什么要使用多环境配置? 在开发过程中,我们通常会遇到多个不同的环境,比如开发环境(Dev)、测试环境(Test)、生产环境(Prod)等。每个环境的配置和需…...

93,【1】buuctf web [网鼎杯 2020 朱雀组]phpweb
进入靶场 页面一直在刷新 在 PHP 中,date() 函数是一个非常常用的处理日期和时间的函数,所以应该用到了 再看看警告的那句话 Warning: date(): It is not safe to rely on the systems timezone settings. You are *required* to use the date.timez…...

ChatGPT怎么回事?
纯属发现,调侃一下~ 这段时间deepseek不是特别火吗,尤其是它的推理功能,突发奇想,想用deepseek回答一些问题,回答一个问题之后就回复服务器繁忙(估计还在被攻击吧~_~) 然后就转向了GPT…...

机器学习day7
自定义数据集 使用pytorch框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测,对预测结果计算精确度和召回率及F1分数 代码 import numpy as np import torch import torch.nn as nn import torch.optim as optimizer import matplotlib.pyp…...

本地部署DeepSeek教程(Mac版本)
第一步、下载 Ollama 官网地址:Ollama 点击 Download 下载 我这里是 macOS 环境 以 macOS 环境为主 下载完成后是一个压缩包,双击解压之后移到应用程序: 打开后会提示你到命令行中运行一下命令,附上截图: 若遇…...

2月3日星期一今日早报简报微语报早读
2月3日星期一,农历正月初六,早报#微语早读。 1、多个景区发布公告:售票数量已达上限,请游客合理安排行程; 2、2025春节档总票房破70亿,《哪吒之魔童闹海》破31亿; 3、美宣布对中国商品加征10…...
本周回顾)
202周日复盘(159)本周回顾
1、当日总结。 定价相关内容,学习与思考。 第一性原理,分析游戏成本的构成。 ------------- 2、周总结 大思路,细节设计都有进展,每天都挖坑与加工。 a 学习游戏思想 任天堂游戏研发四大标准,创新,直…...

Linux基础 ——tmux vim 以及基本的shell语法
Linux 基础 ACWING y总的Linux基础课,看讲义作作笔记。 tmux tmux 可以干嘛? tmux可以分屏多开窗口,可以进行多个任务,断线,不会自动杀掉正在进行的进程。 tmux – session(会话,多个) – window(多个…...

error: RPC failed; curl 56 OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 10054
Descriptions: Solutions:...

WPF进阶 | WPF 动画特效揭秘:实现炫酷的界面交互效果
WPF进阶 | WPF 动画特效揭秘:实现炫酷的界面交互效果 前言一、WPF 动画基础概念1.1 什么是 WPF 动画1.2 动画的基本类型1.3 动画的核心元素 二、线性动画详解2.1 DoubleAnimation 的使用2.2 ColorAnimation 实现颜色渐变 三、关键帧动画深入3.1 DoubleAnimationUsin…...

DeepSeek 遭 DDoS 攻击背后:DDoS 攻击的 “千层套路” 与安全防御 “金钟罩”
当算力博弈升级为网络战争:拆解DDoS攻击背后的技术攻防战——从DeepSeek遇袭看全球网络安全新趋势 在数字化浪潮席卷全球的当下,网络已然成为人类社会运转的关键基础设施,深刻融入经济、生活、政务等各个领域。从金融交易的实时清算…...

本地部署DeepSeek-R1模型(新手保姆教程)
背景 最近deepseek太火了,无数的媒体都在报道,很多人争相着想本地部署试验一下。本文就简单教学一下,怎么本地部署。 首先大家要知道,使用deepseek有三种方式: 1.网页端或者是手机app直接使用 2.使用代码调用API …...

Scratch 《像素战场》系列综合游戏:像素战场游戏Ⅰ~Ⅲ 介绍
资源下载 Scratch《像素战场》系列综合游戏合集:像素战场游戏Ⅰ~Ⅲ压缩包 https://download.csdn.net/download/leyang0910/90332765 游戏操作介绍 Scratch 《像素战场Ⅰ》操作规则: 这是一款与朋友一起玩的 1v1 游戏。先赢得6轮胜利! WA…...

手机连接WIFI可以上网,笔记本电脑连接WIFI却不能上网? 解决方法?
原因:DNS受污染了 解决办法 step 1:清空域名解析记录(清空DNS) ipconfig /flushdns (Windows cmd命令行输入) step 2:重新从DHCP 获取IP ipconfig /release(释放当前IP地址) ipconfig /renew &…...

DRM系列七:Drm之CREATE_DUMB
本系列文章基于linux 5.15 DRM驱动的显存由GEM(Graphics execution management)管理。 一、创建流程 创建buf时,user层提供需要buf的width,height以及bpp(bite per pixel),然后调用drmIoctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, &…...