deepseek 本地化部署和小模型微调
安装ollama
因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报

所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama
启动命令
docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama查看ollama 是否启动成功,Ollama 没有用户界面,在后台运行。
打开浏览器,输入 “http://xx:11434/”,显示 “Ollama is running”。

docker exec -it ollama ollama list
deepseek-r1 目前有7b, 32b, 70b, 671b 多个版本, 考虑到下载时间目前只下载最大70b的模型

应该说Deepseek 底层应该是很牛,两张40卡都能跑70B参数的模型

安装openwebui
Open-webui 则提供直观的 Web 用户界面来与 Ollama 平台进行交互。直接使用docker进行部署
docker run -d --privileged -p 3000:8080 \--add-host=host.docker.internal:host-gateway \-v /data/openwebui:/app/backend/data \-e TRANSFORMERS_CACHE=/app/backend/data/huggingface/cache \-e HF_DATASETS_CACHE=/app/backend/data/huggingface/datasets \-e HF_ENDPOINT=https://hf-mirror.com \--name open-webui --restart always \ghcr.io/open-webui/open-webui:main打开3000端口选择70b的模型

使用下deepseek的深度思考模式

下面演示下如何对DeepSeek-V1:7b模型进行微调,让模型成为一位算命大师
微调代码参考self-llm/models/DeepSeek at master · datawhalechina/self-llm · GitHub
R1 和 V1 的区别集中在 优化方向(速度、领域、资源)或 迭代阶段(V1 为初版,R1 为改进版)模型微调通过 peft 库来实现模型的 LoRA 微调。peft 库是 huggingface 开发的第三方库,其中封装了包括 LoRA、Adapt Tuning、P-tuning 等多种高效微调方法,可以基于此便捷地实现模型的 LoRA 微调。
微调数据格式化
准备一份微调数据

instruction:用户指令,告知模型其需要完成的任务;
input:用户输入,是完成用户指令所必须的输入内容;
output:模型应该给出的输出。
如果你的 JSON 文件包含多个 JSON 对象而不是一个有效的 JSON 数组,Pandas 将无法处理。例如,以下格式是不正确的:
{"key1": "value1"}
{"key2": "value2"}转化下该格式到正确json格式
import jsoninput_file = 'data.json'
output_file = 'corrected_data.json'json_objects = []with open(input_file, 'r', encoding='utf-8') as f:for line in f:line = line.strip() # 去除前后空白if line: # 确保行不为空try:json_objects.append(json.loads(line))except json.JSONDecodeError as e:print(f"Error decoding JSON: {e} - Line: {line}")if json_objects:with open(output_file, 'w', encoding='utf-8') as f:json.dump(json_objects, f, ensure_ascii=False, indent=4)print(f"Corrected JSON format has been saved to {output_file}.")后面训练的时候会使用,是从一个 JSON 文件中读取数据,将其转换为 Pandas DataFrame,然后进一步转换为 Hugging Face 的 Dataset 对象。接着,它对这个数据集应用一个名为 process_func 的处理函数,最终返回一个经过处理的 tokenized 数据集,返回处理后的数据集 tokenized_id,通常是一个包含 token ID 或其他处理结果的新数据集。
def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id安装了huggingface_cli库,可以使用进行安装。
pip install huggingface-cli修改下载源:
export HF_ENDPOINT="https://hf-mirror.com"
下载deepseek-vl-7b-chat 到models文件夹
huggingface-cli download deepseek-ai/deepseek-vl-7b-chat --local-dir ./models
通过加载DeepSeek-7B-chat 模型完成微调数据的初始化,以保证微调时数据的一致性。
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-ai/deepseek-llm-7b-chat/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''设置lora相关的参数
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 模型类型# 需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # False:训练模式 True:推理模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.01
)
各模块含义
这些名称对应 Transformer 模型中的关键投影层(Projection Layers):
-
q_proj,k_proj,v_proj:
自注意力机制中的 查询(Query)、键(Key)、值(Value) 的投影矩阵,用于生成注意力权重。 -
o_proj:
自注意力机制的 输出投影矩阵,将注意力计算结果映射回原始维度。 -
gate_proj,up_proj,down_proj:
Transformer 中 MLP 层(多层感知机)的投影矩阵:-
gate_proj: 门控投影(用于激活函数前的门控控制,如 SwiGLU)。 -
up_proj和down_proj: 上下投影矩阵(用于特征维度的升维和降维)。
-
2. 为什么选择这些层?
这些层是模型的核心计算单元,对模型行为影响显著:
-
注意力层:控制信息交互(如关注哪些词);
-
MLP 层:负责非线性特征变换。
对它们进行微调,能以较少参数高效调整模型行为。
3. 底层原理

其中:
-
BA是低秩适配器,仅训练 A和 B;
-
原始权重 W 冻结不更新,避免破坏预训练知识。
常见配置策略
1. 选择哪些层?
-
通用场景:覆盖所有注意力层 (
q_proj,k_proj,v_proj,o_proj) 和 MLP 层 (gate_proj,up_proj,down_proj)。 -
轻量化微调:仅选择注意力层(减少参数量)。
-
任务相关:根据任务特性调整(如代码生成任务可能更关注 MLP 层)。
2. 不同模型的层名差异
-
Llama、Mistral: 使用
q_proj,k_proj,v_proj,o_proj等命名。 -
GPT-2: 可能命名为
c_attn(合并 Q/K/V 投影)或c_proj(输出投影)。 -
BERT: 通常为
query,key,value,dense。
自定义 TrainingArguments 参数这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
配置如下
args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True#logging_dir="./logs" # 设置日志文件夹
)deepseek 微调训练代码
# -*- coding: utf-8 -*-from deepseek_vl.models import MultiModalityCausalLM
from peft import LoraConfig, TaskType, get_peft_model
from tokenizers import Tokenizer
from transformers import Trainer, TrainingArguments, AutoModelForCausalLM, GenerationConfig, \DataCollatorForSeq2Seqfrom tokenizer_text import get_tokenized_idtokenizer = Tokenizer.from_file("./models/tokenizer.json")
# tokenizer = AutoTokenizer.from_pretrained('./models/', use_fast=False, trust_remote_code=True)
# tokenizer.padding_side = 'right' # padding在右边model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
print('model', model)
# model = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
#model.generation_config = GenerationConfig.from_pretrained('./models/')
#model.generation_config.pad_token_id = model.generation_config.eos_token_id# 开启梯度
#model.enable_input_require_grads()
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 任务类型,常用于因果语言模型target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # 训练模式r=8, # LoRA 矩阵的秩,控制训练参数量,常用值为 4 或 8lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理:控制更新幅度的超参数lora_dropout=0.1 # Dropout 比例,防止过拟合
)model = get_peft_model(model, config)# 确保所有需要的参数启用梯度
for name, param in model.named_parameters():if param.requires_grad:print(f"Parameter {name} is trainable.")else:print(f"Parameter {name} is not trainable will set.")param.requires_grad = True'''
自定义 TrainingArguments 参数
TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
'''args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True# logging_dir="./logs" # 设置日志文件夹
)trainer = Trainer(model=model,args=args,train_dataset=get_tokenized_id('./data.json'),data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)trainer.train()# 直接合并模型开始。。。。。
# 将 adapter 合并进模型(去除 adapter 依赖)
model = model.merge_and_unload()
model.save_pretrained("./output/DeepSeek_full")
tokenizer.save_pretrained("./output/DeepSeek_full")# 直接合并模型结束。。。。。text = "现在你要扮演我碰到一位神秘的算命大师, 你是谁?今天我的事业运道如何?"inputs = tokenizer(f"User: {text}\n\n", return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
上面用到的tokenizer 相关代码
import tokenizer
import pandas as pd
from datasets import Datasetfrom transformers import AutoTokenizer# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-llm-7b/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''def process_func(example):MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性input_ids, attention_mask, labels = [], [], []instruction = tokenizer(f"User: {example['instruction'] + example['input']}\n\n",add_special_tokens=False) # add_special_tokens 不在开头加 special_tokensresponse = tokenizer(f"Assistant: {example['output']}<|end▁of▁sentence|>", add_special_tokens=False)input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id由于deepseek-v1是多模态模型,需要安装deepseek_vl 模块
git clone https://github.com/deepseek-ai/DeepSeek-VL
cd DeepSeek-VLpip install -e .加载模型时转为model: MultiModalityCausalLM,打印下模型结构
MultiModalityCausalLM(
(vision_model): HybridVisionTower(
(vision_tower_high): CLIPVisionTower(
(vision_tower): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(blocks): ModuleList(
(0-11): 12 x Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate='none')
)
)
)
(neck): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
(downsamples): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
)
(neck_hd): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
)
(image_norm): Normalize(mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711])
)
(vision_tower_low): CLIPVisionTower(
(vision_tower): VisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(patch_drop): Identity()
(norm_pre): Identity()
(blocks): Sequential(
(0): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(1): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(2): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(3): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(4): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(5): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(6): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(7): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(8): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(9): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(10): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(11): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(12): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(13): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(14): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(15): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(16): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(17): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(18): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(19): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(20): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(21): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(22): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(23): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn_pool): AttentionPoolLatent(
(q): Linear(in_features=1024, out_features=1024, bias=True)
(kv): Linear(in_features=1024, out_features=2048, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(fc_norm): Identity()
(head_drop): Dropout(p=0.0, inplace=False)
(head): Identity()
)
(image_norm): Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
)
(high_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(low_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(resize): Resize(size=384, interpolation=bilinear, max_size=None, antialias=True)
)
(aligner): MlpProjector(
(high_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(low_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(layers): Sequential(
(0): GELU(approximate='none')
(1): Linear(in_features=4096, out_features=4096, bias=True)
)
)
(language_model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(102400, 4096)
(layers): ModuleList(
(0-29): 30 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=102400, bias=False)
)
)
开始训练,受限于资源单机单线程开启
accelerate launch --num_processes=1 --num_machines=1 train_deepseek.py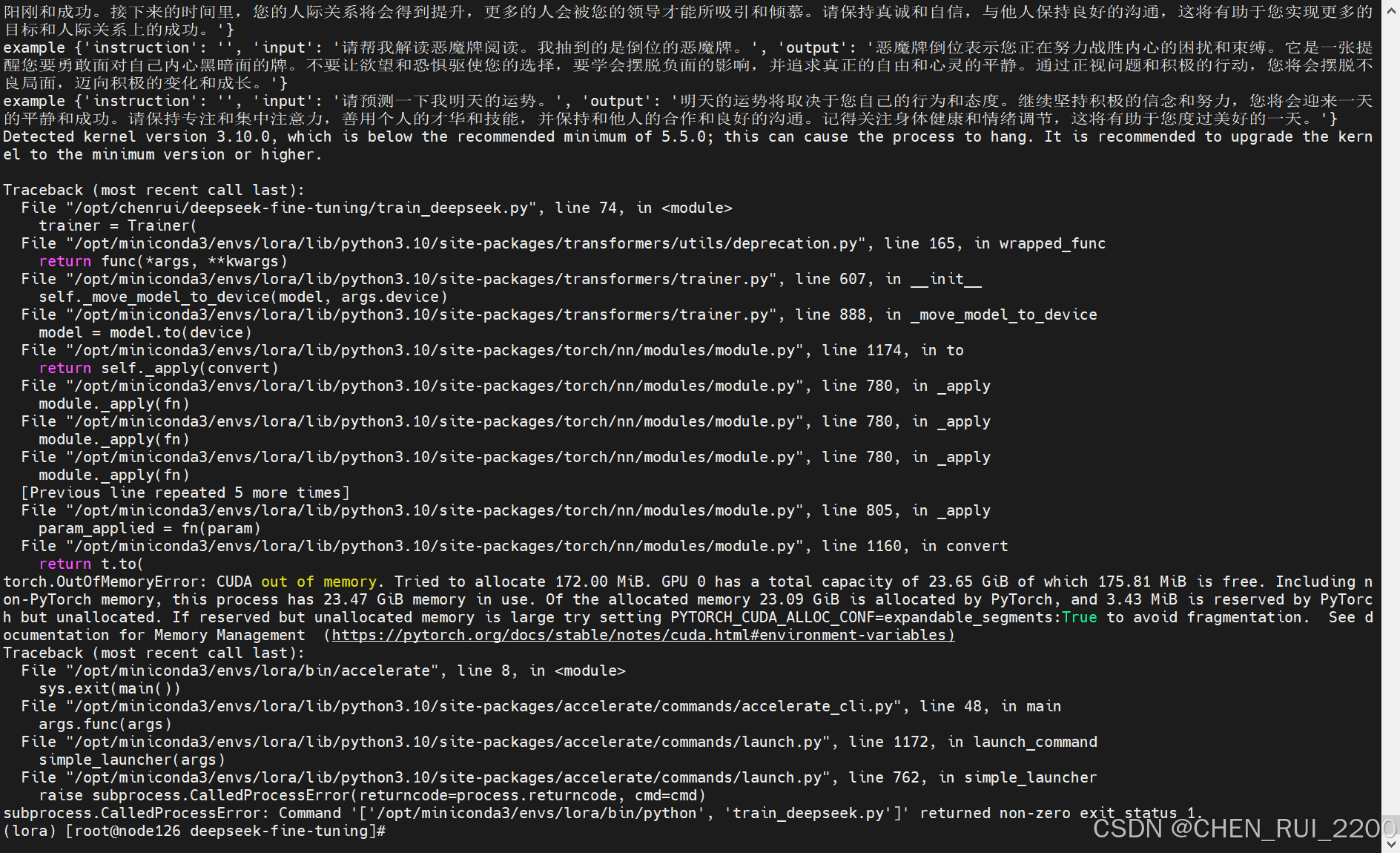
还是挺费显存的,试验受限于设备只能先进行到这里
附一段使用微调模型进行试验的代码(没有测试过)
# -*- coding: utf-8 -*-import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deepseek_vl.models import MultiModalityCausalLM, VLChatProcessorimport warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch.utils._pytree")# 指定合并后的模型路径
merged_model_path = "./output/DeepSeek_full"# 加载模型
# model = AutoModelForCausalLM.from_pretrained(merged_model_path, torch_dtype=torch.float16, device_map="auto")
model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
if hasattr(model, 'tie_weights'):model.tie_weights()tokenizer = AutoTokenizer.from_pretrained(merged_model_path)# 使用模型生成文本示例
input_text = '''
###重要信息-你是一个善于洞察人心的算命大师,请直接以算命大师的角度回复,注意角色不要混乱,你是算命大师,你是算命大师,你是算命大师,你会积极对用户调侃,长度20字。User:测一下我今天的运势'''inputs = tokenizer(input_text, return_tensors="pt").to("cuda")# 生成
with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=50, # 可调整生成长度do_sample=True,top_p=0.95,temperature=0.7,num_return_sequences=1)# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成的文本:", generated_text)相关文章:
deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

socket实现HTTP请求,参考HttpURLConnection源码解析
背景 有台服务器,网卡绑定有2个ip地址,分别为: A:192.168.111.201 B:192.168.111.202 在这台服务器请求目标地址 C:192.168.111.203 时必须使用B作为源地址才能访问目标地址C,在这台服务器默认…...
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
Ubuntu下Tkinter绑定数字小键盘上的回车键(PySide6类似)
设计了一个tkinter程序,在Win下绑定回车键,直接绑定"<Return>"就可以使用主键盘和小键盘的回车键直接“提交”,到了ubuntu下就不行了。经过搜索,发现ubuntu下主键盘和数字小键盘的回车键,名称不一样。…...
的用法)
基础笔记|splice()的用法
一、三种用法 splice(index, 0, element) 插入 元素,不删除任何元素。splice(index, deleteCount) 删除 deleteCount 个元素。splice(index, deleteCount, element1, element2, ...) 替换 元素,即删除 deleteCount 个元素,同时插入新的元素。…...

Java BIO详解
一、简介 1.1 BIO概述 BIO(Blocking I/O),即同步阻塞IO(传统IO)。 BIO 全称是 Blocking IO,同步阻塞式IO,是JDK1.4之前的传统IO模型,就是传统的 java.io 包下面的代码实现。 服务…...

Haproxy+keepalived高可用集群,haproxy宕机的解决方案
Haproxykeepalived高可用集群,允许keepalived宕机,允许后端真实服务器宕机,但是不允许haproxy宕机, 所以下面就是解决方案 keepalived配置高可用检测脚本 ,master和backup都要添加 配置脚本 # vim /etc/keepalived…...

98,【6】 buuctf web [ISITDTU 2019]EasyPHP
进入靶场 代码 <?php // 高亮显示当前 PHP 文件的源代码,通常用于调试或展示代码,方便用户查看代码逻辑 highlight_file(__FILE__);// 从 GET 请求中获取名为 _ 的参数值,并赋值给变量 $_ // 符号用于抑制可能出现的错误信息ÿ…...

九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) 文章目录 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)1. RDB 概述2. RDB 持久化执行流程3. RDB 的详细配置4. RDB 备份&恢…...

小程序越来越智能化,作为设计师要如何进行创新设计
一、用户体验至上 (一)简洁高效的界面设计 小程序的特点之一是轻便快捷,用户期望能够在最短的时间内找到所需功能并完成操作。因此,设计师应致力于打造简洁高效的界面。避免过多的装饰元素和复杂的布局,采用清晰的导航…...

(done) MIT6.S081 2023 学习笔记 (Day7: LAB6 Multithreading)
网页:https://pdos.csail.mit.edu/6.S081/2023/labs/thread.html (任务1教会了你如何用 C 语言调用汇编,编译后链接即可) 任务1:Uthread: switching between threads (完成) 在这个练习中,你将设计一个用户级线程系统中的上下文切…...

C++泛型编程指南09 类模板实现和使用友元
文章目录 第2章 类模板 Stack 的实现2.1 类模板 Stack 的实现 (Implementation of Class Template Stack)2.1.1 声明类模板 (Declaration of Class Templates)2.1.2 成员函数实现 (Implementation of Member Functions) 2.2 使用类模板 Stack脚注改进后的叙述总结脚注2.3 类模板…...

PHP Composer:高效依赖管理工具详解
PHP Composer:高效依赖管理工具详解 引言 在PHP开发领域,依赖管理是项目构建过程中的重要环节。Composer的出现,极大地简化了PHP项目的依赖管理,使得开发者可以更加高效地构建和维护PHP应用程序。本文将深入探讨PHP Composer的使用方法、功能特点以及它在项目开发中的应用…...

JVM执行流程与架构(对应不同版本JDK)
直接上图(对应JDK8以及以后的HotSpot) 这里主要区分说明一下 方法区于 字符串常量池 的位置更迭: 方法区 JDK7 以及之前的版本将方法区存放在堆区域中的 永久代空间,堆的大小由虚拟机参数来控制。 JDK8 以及之后的版本将方法…...
)
C# 精炼题18道题(类,三木运算,Switch,计算器)
1.数组元素和 2.数组元素乘积 3.数组元素平均数 4.数组中最大值 5.数组中的偶数 6.数组中的阶乘 7.数组反转 8.字符串反转 9.回文字符串 10.检查回文 11.最小最大值 12.找素数 13.字符串中的最长无重复字符串 14.字符串去重 15.数组中计算两数之和 16.数字到字符…...

利用matlab寻找矩阵中最大值及其位置
目录 一、问题描述1.1 max函数用法1.2 MATLAB中 : : :的作用1.3 ind2sub函数用法 二、实现方法2.1 方法一:max和find2.2 方法二:max和ind2sub2.3 方法对比 三、参考文献 一、问题描述 matlab中求最大值可使用函数max,对于一维向量࿰…...

基于开源AI智能名片2 + 1链动模式S2B2C商城小程序视角下的个人IP人设构建研究
摘要:本文深入探讨在开源AI智能名片2 1链动模式S2B2C商城小程序的应用场景下,个人IP人设构建的理论与实践。通过剖析个人IP人设定义中的“诉求”“特质”“可感知”三要素,结合该小程序特点,阐述其对个人IP打造的影响与推动作用&…...

刷题汇总一览
文章目录 贪心动态规划数据结构滑动窗口与双指针前缀和动态规划 本题单设计力扣、牛客等多个刷题网站 贪心 贪心后悔 徒步旅行中的补给问题 LCP 30.魔塔游戏 题目使用到的思想解题分析徒步旅行中的补给问题每次我们都加入当前补给点的k个选择,同时进行升序排序&am…...

Java中的常见对象类型解析
在Java开发中,数据的组织和传递是一个重要的概念。为了确保代码的清晰性、可维护性和可扩展性,我们通常会根据不同的用途,设计和使用不同类型的对象。这些对象的作用各不相同,但它们共同为构建高效、模块化的软件架构提供支持。 …...

Jupyter Lab的使用
Lab与Notebook的区别: Jupyter Lab和Jupyter notebook有什么区别,这里找到一篇博客不过我没细看, Jupyter Lab和Jupyter Notebook的区别 - codersgl - 博客园 使用起来Lab就是一个更齐全、功能更高级的notebook, 启用滚动输出: 有时候一个…...

SpringBoot中关于knife4j 中的一些相关注解
1、效果图 对比可以明显的看到加了注解与没有加注解所表现出来的效果不同(加了注解的更加明了清晰) 2、实现效果 Tag注解用于为测试方法或测试类添加标签,以便在执行测试时根据标签进行过滤。使用Tag注解可以更灵活地控制测试的执行&#…...

【C++】static关键字
在 C 中,static 关键字有多种用途,主要用于控制变量和函数的存储期、作用域和链接性。以下是对 static 关键字的详细介绍,包括其不同用法和示例。 1. 静态局部变量 定义:在函数内部声明的静态变量,其生命周期从程序开…...

内核定时器3-用户空间定时器
用户空间定时器与内核定时器的关系 虽然用户空间定时器和内核定时器在实现上各自独立,但用户空间定时器通常依赖于内核定时器提供的基础设施。以下是具体关系: 依赖性 用户空间定时器的实现基于内核定时器。 例如,POSIX 定时器使用内核的 h…...

知识管理系统助力企业信息共享与创新思维的全面提升研究
内容概要 知识管理系统的引入极大地改变了企业内部的信息流程与创新机制。通过有效整合与管理组织内的知识资源,这些系统不仅降低了信息孤岛的现象,还提升了员工之间的协作能力。企业在信息共享方面,通过知识管理系统构建了一个透明、高效的…...

LLM - 基于LM Studio本地部署DeepSeek-R1的蒸馏量化模型
文章目录 前言开发环境快速开始LM Studio简单设置模型下载开始对话 模型选择常见错误最后 前言 目前,受限于设备性能,在本地部署的基本都是DeepSeek-R1的蒸馏量化模型,这些蒸馏量化模型的表现可能并没有你想象的那么好。绝大部分人并不需要本…...
本地部署 DeepSeek-R1:简单易上手,AI 随时可用!
🎯 先看看本地部署的运行效果 为了测试本地部署的 DeepSeek-R1 是否真的够强,我们随便问了一道经典的“鸡兔同笼”问题,考察它的推理能力。 📌 问题示例: 笼子里有鸡和兔,总共有 35 只头,94 只…...

实现网站内容快速被搜索引擎收录的方法
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/6.html 实现网站内容快速被搜索引擎收录,是网站运营和推广的重要目标之一。以下是一些有效的方法,可以帮助网站内容更快地被搜索引擎发现和收录: 一、确…...
)
浅谈量化感知训练(QAT)
1. 为什么要量化? 假设你训练了一个神经网络模型(比如人脸识别),效果很好,但模型太大(比如500MB),手机根本跑不动。于是你想压缩模型,让它变小、变快。 最直接的压缩方法…...

对象的实例化、内存布局与访问定位
一、创建对象的方式 二、创建对象的步骤: 一、判断对象对应的类是否加载、链接、初始化: 虚拟机遇到一条new指令,首先去检查这个指令的参数能否在Metaspace的常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化…...

制造业设备状态监控与生产优化实战:基于SQL的序列分析与状态机建模
目录 1. 背景与挑战 2. 数据建模与采集 2.1 数据表设计 设备状态表(记录设备实时状态变更)...