一文速览DeepSeek-R1的本地部署——可联网、可实现本地知识库问答:包括671B满血版和各个蒸馏版的部署
前言
自从deepseek R1发布之后「详见《一文速览DeepSeek R1:如何通过纯RL训练大模型的推理能力以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》」,deepseek便爆火

爆火以后便应了“人红是非多”那句话,不但遭受各种大规模攻击,即便后来挡住了大部分攻击,但海内外大量闯入deepseek官网一探究竟的网友也把他们的服务器压得不堪重负
导致一提问,要么频繁显示:服务器繁忙,请稍后再试;要么回答了 但无法联网,致使我朋友圈内一些不知情的朋友说:看把媒体给能的,各种瞎吹,但其实不过尔尔..
怎么办呢?
- 一方面,微信上的好友老师木发圈表示
“ 这个春节有点特别,虽然没有休息一天,大家也没有怨言。看到DeepSeek创造的一个又一个奇迹,我很焦急但苦于没有资源,同事突发奇想:国产卡多,用国产卡吧 ”
于是,在25年的2.1日,硅基流动 x 华为云联合推出基于昇腾云的 DeepSeek R1 & V3 推理服务!
个人认为这是国产GPU替代英伟达GPU之路的里程碑时刻
虽然在此之前,华为以及不少国内公司在GPU国产化上做了很多工作、努力,而且在不少政务单位已经做了很多替代
但我们过去两年 对外接各种大模型项目的时候——我司「七月在线」除了开发一系列内部产品 也对外接各种项目,不论是客户还是我们内部,对国产GPU是否好适配、以及适配之后是否丝滑好用 始终存在着一定的担忧
我相信,这一情况会随着本次的「昇腾云的 DeepSeek R1 & V3 推理服务」而越来越好 - 二方面,我原本不想看什么本地部署的,也不得不关注下各种版本下的本地部署
本文便来重点探讨各种版本下、各种情况下的DeepSeek-R1的本地部署「当然,某乎上也有很多类似“ 如何在本地部署DeepSeek-R1模型?” 的帖子」
如此,本文来了,以下是本文的更新记录
- 2.3日下午,在我自己的iMac上本地部署了下R1 7B蒸馏版,详见下文的
2.1.1 Ollama下的终端命令行交互
2.1.2 Ollama下的open-webui交互:基于docker安装,且支持联网搜索 - 2.4日晚上,可能是自己早已习惯在博客中尽可能把所有细节一次性讲清楚
所以我自己又尝试了
2.1.3 通过 Ollama + chatboxai部署deepseek-r1:7b
2.1.4 基于Ollama + Page Assist搭建本地知识库问答系统:且支持联网搜索
且同时让同事文弱尝试了通过vLLM推理deepseek-r1:8b,也已更新在了下文的
2.2 通过vLLM推理deepseek-r1:8b:R1-Distill-Llama-8B
第一部分 本地部署之前的准备工作:各个版本、推理框架、硬件资源
1.1 DeepSeek-R1的多个版本:加上2个原装671B的,总计8个参数版本
在huggingface上总共有以下几种参数的deepseek R1
- DeepSeek-R1 671B
- DeepSeek-R1-Zero 671B
- DeepSeek-R1-Distill-Llama-70B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-1.5B
1.2 主流的大模型推理框架:分为PC端和Android端
首先,看推理框架,目前主流的大模型推理框架主要有以下5种:
- SGLang
完全支持 BF16 和 FP8 推理模式下的 DeepSeek-V3 模型 - Ollama,相对简单易用,大众用户首选
- vLLM,开发者首选,便于商业化诉求
支持 FP8 和 BF16 模式的 DeekSeek-V3 模型,用于张量并行和管道并行
详见:一文通透vLLM与其核心技术PagedAttention:减少KV Cache碎片、提高GPU显存利用率(推理加速利器) - LLaMA.cpp
- MNN-LLM,偏Android手机端
MNN-LLM展现了卓越的CPU性能,预填充速度相较于llama.cpp提高了8.6倍,相较于fastllm提升了20.5倍,解码速度分别快了2.3倍和8.9倍
更多详情,请参见论文《MNN-LLM: A Generic Inference Engine for Fast Large Language Model Deployment on Mobile Devices》
1.3 不同参数的模型所要求的硬件
其次,看硬件要求,很显然,不同参数的模型所要求的硬件各不相同(下表修改自微信好友杨老师整理的表格)
| 模型参数 | 最低GPU配置 | 最低CPU配置 | 建议内存 | 建议硬盘空间 |
|---|---|---|---|---|
| R1 or R1-Zero 满血版 | A/H100(80G) x 16-18 某乎上便有篇文章:16张H100部署模型DeepSeek-R1 值得一提的是,A100/A800原生并不支持FP8运算,如果A800要执行FP8精度计算,需要在指令层面进行模拟(存在精度转换计算) 如下图所示(图源)
| Xeon 8核 | 192GB | 2TB固态 |
| R1-distill-llama70B | RTX 4090(24GB) x 2 | i9-13900K | 64GB | 1TB固态 |
| R1-distill-Qwen32B | RTX 4090(24GB) | i7-13700K | 64GB | 1TB固态 |
| R1-distill-Qwen14B | RTX 4060S(16GB) | Ryzen 7 | 32GB | 500G固态 |

可以看到
- 完全开源的DeepSeek-R1 671B参数进行本地私有化部署的显卡资源要求极高
包括我司七月在线内部之前也最多用过8张80G的A100——通过1.5K条paper-review数据微调LLaMA2 70B「详见此文《七月论文审稿GPT第4.2版:通过15K条paper-review数据微调Llama2 70B(含各种坑)》」 - 由于 FP8 训练是Deepseek 的框架中原生采用的,故DeepSeek-R1/3均(DeepSeek-R1基于DeepSeek-V3-base后训练)均为FP8精度训练「详见此文《一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)》」,下图是各个精读的对比(图源)

因此提供的精度就是FP8(e4m3),占单个Byte空间
"quantization_config": {"activation_scheme": "dynamic""fmt": "e4m3","quant method": "fp8""weight_block_size": [128,128]}- 模型分片163个,模型的文件总计约为642G,如果以FP3精度加载到显存,模型参数就需要642GB空间
按PagedAttention论文预估的KV-Cache+和激化值估计至少要占到30%左石 - 在推理场景下,输出大多是长文本,那就更多了,而且具体模型还要实测,或用Nvidia Nisight+分析显存占用。估计常规部署都需要800GB以上,10张A800打底
而大部分消费者或开发者拥有的硬件资源是有限的,故关于网上大多数人所谓部署的R1都是其蒸馏Llama/Qwen后的8B/32B/70B版本,本质是微调后的Llama或Qwen模型
1.4 蒸馏版和满血版的两类部署
最后,咱们下面有两种部署对象
- 一个是部署各种蒸馏版
也不要小看蒸馏版,虽然R1蒸馏llama/qwen的版本效果上不及R1 671B满血版,但还是挺能打的
详见下图,在与GPT-4o 0513、o1 mini、QwQ-32B preview PK的过程中,各个蒸馏版在六个榜单中的五个榜单 都拿到了第一

- 一个是部署R1 or R1-Zero 满血版
第二部分 通过Ollama、vLLM本地部署DeepSeek-R1蒸馏版:支持联网搜索
2.1 4种交互方式:终端、open-webui、chatbox、Page Assist知识库问答
2.1.1 Ollama下的终端命令行交互
首先,671B的R1光模型本身就有688G:
- huggingface.co/deepseek-ai/DeepSeek-R1,没有一定的GPU集群 确实不好弄
- 即便是量化版本,最极端的Q1量化,也要94G:huggingface.co/bartowski/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-IQ1_S
- Q4量化版,则大概360G,如果有5张 A100 80G,则可以试一下
huggingface.co/bartowski/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-IQ4_XS
所以,一般用户比较好跑的还是R1的蒸馏版
- 如果是10G显存
可以跑这个R1蒸馏Qwen 2.5 14b的IQ4_NL版本huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ4_NL.gguf - 如果是16G显存
一方面,可以试试蒸馏的Qwen 2.5 32b的版本,IQ3_M量化,不过,有人实测后,说损失有点严重——相当于Q4以下量化都不太推荐
二方面,我司七月的《DeepSeek项目实战营》提供的GPU预装了DeepSeek-R1-Distill-Llama-8B:https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B,欢迎大伙体验
ollama目前支持部署多种模型,包括且不限于目前最流行的deepseek R1,也包括之前的llama 3.3等

我下午在我自己的iMac上本地部署了下R1 7B蒸馏版,还想办法支持了联网搜索,这一切确实比之前更平权了,速度可以的,效果的话 毕竟就7B嘛——和671B 满血版还是有很大差距的
具体怎么操作呢,进入Ollama页面
- Download Ollama,我个人电脑因为是iMac,故选择macOS版本——180M大小
- 在模型列表页面,下载deepseek R1模型:ollama.com/library/deepseek-r1,然后可以选择比如R1蒸馏qwen2 7B的蒸馏版

- 打开本地的命令提示符「我个人电脑是iMac,故在启动台的搜索框里:输入终端,即可打开」,输入以下命令后,回车键开始下载安装对应参数的模型:
下载完成后,可以通过ollama list指令查看所有本地模型占用的存储空间ollama pull deepseek-r1:7b
想看具体某一个模型的参数。可以使用ollama show指令:ollama list
具体如下图所示ollama show <模型名称>
- 然后再运行以下命令,便可以和deepseek R1对话了
ollama run deepseek-r1:7b比如可以提问它:为何deepseek影响力这么大

2.1.2 Ollama下的open-webui交互:基于docker安装,且支持联网搜索
当然,如果你希望有更好的交互方式,则可以考虑用ollama的标配前端open-webui
- 首先通过docker的官网下载docker
docker.p2hp.com
我直接用的Google账号注册
- 安装好后在右下角点击Terminal,打开控制台

- 输入以下命令——等待安装完成
然后在docker页面可以看到如下呈现docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- 点击上面的链接:http://localhost:3000/auth,创建相关管理员账号之后
即可开始和R1对话拉

可能有同学疑问,这个7B没法联网,有点弱智啊,好问题
- 巧的是,在管理员面板上:http://localhost:3000/admin/settings,可以打开联网搜索滴,如果有相应搜索引擎的API,则自行设置,否则可以选择免费的duckduckgo

- 然后点击聊天界面的左下角 + 按钮,选择联网搜索

- 则一切大功告成

2.1.3 基于Ollama + ChatBox部署deepseek-r1:7b
除了上面的open-webui之外,当然,也有人说,chatbox 是个很方便的图形界面,比open web-UI 好用
一不做二不休,那我们再试下这个chatbox
- 通过Ollama部署好deepseek-r1:7b之后,再通过chatbox官网下载对应的客户端:chatboxai
- 下载好chatbox之后,进行如下图所示的一系列设置「比如模型的提供方选择OLLAMA.API,且在下拉框处选择本地已经安装的模型deepseek-r1:7b」

- 接下来,便可以提问R1 7B拉
2.1.4 基于Ollama + Page Assist搭建本地知识库问答系统:且支持联网搜索
也有人称,Page Assist 直接提供了一个类似Open WebUI的交互界面来运行本地的大模型,故我们再试下这个Page Assist
在通过Ollama部署好deepseek-r1:7b之后,如果你想让DeepSeek R1不仅仅是一个问答机器人,而是一个具有专有知识的智能助手,那就需要搭建本地知识库了
实现也很简单——基于Page Assist即可
- 直接打开Chrome的插件市场,搜索并添加Page Assist插件

- 安装完插件后,点击插件图标,选择本地搭建的DeepSeek模型,进行配置,且支持联网搜索——背后还是基于免费的duckduckgo

- 且点击页面右上角的设置按钮,还可以进入RAG(RetrievalAugmented Generation)模式

- 上传你自己的知识库

2.2 通过vLLM推理deepseek-r1:8b:R1-Distill-Llama-8B
本2.2节基本为我司大模型项目组的文弱编写
- 首先,新建一个conda环境:
conda create -n vllm_test python=3.10 - 然后配置该conda环境:
conda activate vllm_testpip install vllm - 配置好以后,启动vllm推理服务:
vllm serve path_to/DeepSeek-R1-Distill-Llama-8B --tensor-parallel-size 1 --max-model-len 32768 --enforce-eager --gpu_memory_utilization=0.98 --enable-chunked-prefill --port 6060
默认是8000端口,可以修改port里的参数来改变服务端口
vllm serve后面的模型路径改为本地下载好的模型的实际绝对路径 - 启动vllm服务后,便可以直接提问了,比如输入如下命令行:
curl http://localhost:6060/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "path_to/DeepSeek-R1-Distill-Llama-8B ","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "题目:有五个人站成一排,每个人手中都拿着一顶帽子,帽子的颜色可以是红色、蓝色或绿色。每个人都能看到自己前面的人头上的帽子颜色,但看不见自己头上的帽子,且每个人只能看到前面人的帽子颜色,而无法看见自己的帽子和别人背后的帽子。每个人都可以听到别人说话的内容,但不能交换信息。规则:每个人都知道一共有三种颜色的帽子(红、蓝、绿),并且帽子是随机分配的,每种颜色可能有多个,但也可能没有。每个人会依次回答自己头上的帽子颜色,能正确猜出自己帽子颜色的人可以获得奖励。第一个人只能听到后面四个人的回答,无法知道任何自己的信息;第二个人只能听到后面三个人的回答,依此类推。第一个人可以先做一个声明,告知后面的人如何推理他们自己的帽子颜色。问题:如果所有人都能完美推理出自己头上的帽子颜色,问:第一个人应该如何开始,才能确保最多的人能够猜对自己帽子颜色?"}],"max_tokens": 2000,"temperature": 0.7,"top_p": 0.9}'
2.3(选读) 本地手机端部署DeepSeek-R1蒸馏Llama/Qwen后的版本
直接通过这个链接:mnn_llm_app_debug_0_1.apk,下载Android apk,安装之后,在应用内的模型列表最后一个,直接安装R1-1.5B-Qwen-MNN
// 待更
第三部分 无蒸馏前提下本地部署R1 or R1-Zero 671B满血版
本地部署R1 or R1-Zero 满血版又分为两种方式
- 一种是做了各种量化的,此乃属于追求满血版但资源还是有限不得不做的折中处理
- 一种是不做任何量化的,这种属于土豪路径,如果你是用的这个路线,请私我,原因很简单,我也想多一些土豪朋友
3.1 折中路径:无蒸馏但量化部署Deepseek-R1 671B满血版
3.1.1 本地CPU上运行 Deepseek-R1 的完整的硬件 + 软件设置
huggingface 的一工程师Matthew Carrigan展示了在本地CPU上运行 Deepseek-R1 的完整的硬件 + 软件设置「他使用的是 670B 模型,无蒸馏,Q8 量化,实现全质量,总成本 6,000 美元——GPU版本得10万美元+」
核心硬件方面
- 主板:技嘉 MZ73-LM0 或 MZ73-LM1。有 2 个 EPYC 插槽,以获得 24 个 DDR5 RAM 通道
- CPU:2x 任何 AMD EPYC 9004 或 9005 CPU
“LLM 一代的瓶颈在于内存带宽,因此您不需要高端产品。如果真的想降低成本,请购买 9115 甚至 9015” - RAM:24×32GB DDR5-RDIMM
因为需要 768GB(以适应模型)跨 24 个 RAM 通道(以获得足够快的带宽),故意味着 24 x 32GB DDR5-RDIMM 模块
关键组件方面
- 电源:该系统的功耗出奇地低!(<400W)
“但是,您需要大量的 CPU 电源线来为 2 个 EPYC CPU 供电。Corsair HX1000i 的功率足够了。” - 机箱:具有用于安装完整服务器主板的螺丝安装座
- 散热器:适合AMD EPYC 有 SP5 插槽的就行
系统调优方面
- 最后,SSD:任何适合 R1 的 1TB 或更大的 SSD 都可以。“推荐 NVMe,只是因为启动模型时你必须将 700GB 复制到 RAM 中
- 软件部分:安装 Linux,进入 BIOS 并将 NUMA 组数设置为 0。这将确保模型的每一层都交错在所有 RAM 芯片上,从而使我们的吞吐量加倍。安装 Llama。下载 700G 的DeepSeek-R1-Q8_0 版本
软件部署
- 安装llama.cpp:git clone https://github.com/ggerganov/llama.cpp
- 下载模型权重:HuggingFace Q8_0目录全量700GB(⚠️确保存储空间)
- 一切完成后,设置以下代码:
llama-cli -m ./DeepSeek-R1.Q8_0-00001-of-00015.gguf --temp 0.6 -no-cnv -c 16384 -p "<|User|>How many Rs are there in strawberry? <|Assistant|>"
这个版本没有 GPU,生成速度是每秒 6 到 8 个tokens,作者认为考虑到价格,这个非 GPU 硬件的方案可以接受。因为运行的是 Q8 量化的完整 670B 模型,因此质量应与 Deepseek API 无异
至于为什么不用GPU?
- 显存墙限制:保持Q8精度需700GB+显存,单张H100仅80GB → 需9张组集群 → 成本超10万美元
- 量化损耗困境:若降精度至FP16,8卡H100即可运行 → 但模型质量显著下降 ≈ 智商砍半
- 性价比暴击:本方案以1/20成本实现可用推理速度(对比GPU方案6-8tps vs 50-100tps)
3.1.2 GPU上跑无蒸馏但量化的Deepseek-R1 671B满血版
Unsloth AI 在 HuggingFace 上提供了 “动态量化” 版本来大幅缩减模型的体积
所谓“动态量化” 的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化
为什么可以做呢,原因在于他们观察到,DeepSeek 的前 3 层是全连接层,而非 MoE 层
作为回顾,MoE(专家混合)层使得能够在不增加模型计算量(FLOPs)的情况下增加参数数量,因为他们动态地将大多数条目掩码为 0,因此实际上跳过了对这些零值条目的矩阵乘法运算「更多请参阅此条推文:x.com/danielhanchen/status/1868748998783517093」
- 总之,通过这种方法,DeepSeek R1 全量模型可压缩至最小 131GB(1.58-bit 量化),极大降低了本地部署门槛,甚至能在单台 Mac Studio 上运行
- Unsloth AI 提供了4 种动态量化模型(1.58 至 2.51 比特,文件体积为 131GB 至 212GB)
MoE Bits Disk Size Type Quality Link Down_proj 1.58-bit 131GB IQ1_S Fair huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_S 2.06/1.56bit 1.73-bit 158GB IQ1_M Good huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_M 2.06bit 2.22-bit 183GB IQ2_XXS Better huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ2_XXS 2.5/2.06bit 2.51-bit 212GB Q2_K_XL Best huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-Q2_K_XL 3.5/2.5bit
部署此类大模型的主要瓶颈是内存+显存容量,建议配置如下:
- DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB
- DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
若硬件条件有限,可尝试体积更小的 1.58-bit 量化版(131GB),可运行于:
- 单台 Mac Studio
192GB 统一内存,参考案例可见 X 上的 @ggerganov,成本约 5600 美元 - 2×Nvidia H100 80GB
参考案例可见 X 上的 @hokazuya,成本约 4~5 美元 / 小时
且在这些硬件上的运行速度可达到 10+ token / 秒
// 待更
3.2 土豪路径:无蒸馏不量化部署Deepseek-R1 671B满血版
// 待更
相关文章:

一文速览DeepSeek-R1的本地部署——可联网、可实现本地知识库问答:包括671B满血版和各个蒸馏版的部署
前言 自从deepseek R1发布之后「详见《一文速览DeepSeek R1:如何通过纯RL训练大模型的推理能力以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》」,deepseek便爆火 爆火以后便应了“人红是非多”那句话,不但遭受各种大规模攻击,即便…...

Kubernetes学习之包管理工具(Helm)
一、基础知识 1.如果我们需要开发微服务架构的应用,组成应用的服务可能很多,使用原始的组织和管理方式就会非常臃肿和繁琐以及较难管理,此时我们需要一个更高层次的工具将这些配置组织起来。 2.helm架构: chart:一个应用的信息集合…...

2024美团春招硬件开发笔试真题及答案解析
目录 一、选择题 1、在 Linux,有一个名为 file 的文件,内容如下所示: 2、在 Linux 中,关于虚拟内存相关的说法正确的是() 3、AT89S52单片机中,在外部中断响应的期间,中断请求标志位查询占用了()。 4、下列关于8051单片机的结构与功能,说法不正确的是()? 5、…...

MyBatis-Plus速成指南:通用枚举 多数据源
通用枚举: 概述: 表中有些字段值是固定的,例如性别(男或女),此时我们可以使用 MyBatis-Plus 的通用枚举来实现 数据库表添加字段: 创建通用枚举类型: Getter public enum SexEnum {MALE(1, "男"…...
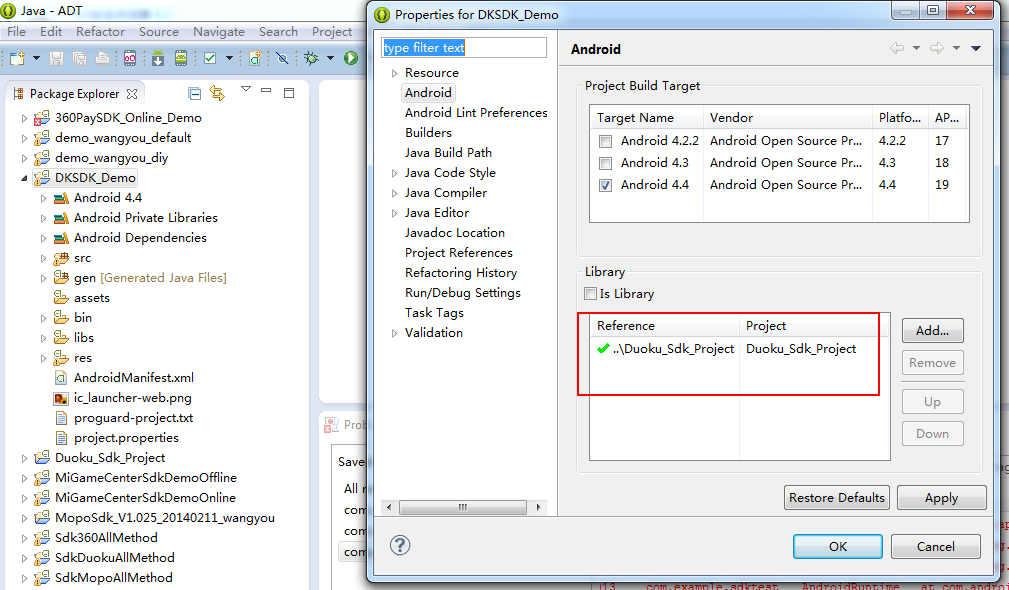
Android项目中使用Eclipse导出jar文件
2014年3月24日 天气晴朗 关于打包Android组件肯定是有用到的,比如开发了一个模块,为了更好的复用,我们可能会将它打包成jar文件方便其他项目引用。这个很好理解,也很简单。网上有一堆关于用Eclipse将Android项目打包成jar文件的&…...

网络安全学习 day4
防火墙的安全策略 规则--策略 条件 --- 检查报文的依据,防火墙将报文中携带的信息与条件逐一进行对比, 以此来判断报文是否是 匹配的 。不同的匹配条件之间属于 “ 与 ” 关系;相同的匹配条件中不同的参数信息之间的关系为 “ 或 ” 关系。…...

【SSM】Spring + SpringMVC + Mybatis
SSM课程,以下为该课程的笔记 bean:IOC容器创建的对象 P12 bean的生命周期 在bean中定义init()和destroy()方法,然后在xml中配置方法名,让bean对象能找到对应的生命周期方法。 或通过实现接口的方式定义声明周期方法。 P13 sett…...

智慧园区综合管理系统如何实现多个维度的高效管理与安全风险控制
内容概要 在当前快速发展的城市环境中,智慧园区综合管理系统正在成为各类园区管理的重要工具,无论是工业园、产业园、物流园,还是写字楼与公寓,都在积极寻求如何提升管理效率和保障安全。通过快鲸智慧园区管理系统,用…...

【协议详解】卫星通信5G IoT NTN SIB33-NB 信令详解
一、SIB33信令概述 在5G非地面网络(NTN)中,卫星的高速移动性和广域覆盖特性使得地面设备(UE)需要频繁切换卫星以维持连接。SIB32提供了UE预测当前服务的卫星覆盖信息,SystemInformationBlockType33&#x…...

《LLM大语言模型深度探索与实践:构建智能应用的新范式,融合代理与数据库的高级整合》
文章目录 Langchain的定义Langchain的组成三个核心组件实现整个核心组成部分 为什么要使用LangchainLangchain的底层原理Langchain实战操作LangSmithLangChain调用LLM安装openAI库-国内镜像源代码运行结果小结 使用Langchain的提示模板部署Langchain程序安装langserve代码请求格…...

Debian 10 中 Linux 4.19 内核在 x86_64 架构上对中断嵌套的支持情况
一、中断嵌套的定义与原理 中断嵌套是指在一个中断处理程序(ISR)正在执行的过程中,另一个更高优先级的中断请求到来,系统暂停当前中断处理程序,转而处理新的高优先级中断。处理完高优先级中断后,系统返回到原来的中断处理程序继续执行。这种机制允许系统更高效地响应紧急…...

【Envi遥感图像处理】010:归一化植被指数NDVI计算方法
文章目录 一、NDVI简介二、NDVI计算方法1. NDVI工具2. 波段运算三、注意事项1. 计算结果为一片黑2. 计算结果超出范围一、NDVI简介 归一化植被指数,是反映农作物长势和营养信息的重要参数之一,应用于遥感影像。NDVI是通过植被在近红外波段(NIR)和红光波段(R)的反射率差异…...

优选算法合集————双指针(专题二)
好久都没给大家带来算法专题啦,今天给大家带来滑动窗口专题的训练 题目一:长度最小的子数组 题目描述: 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl1, …...

基于微信小程序的私家车位共享系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

糖化之前,为什么要进行麦芽粉碎?
糖化的目的是将麦芽中的淀粉转化为可发酵性的糖分,而糖化之前,进行麦芽粉碎是确保糖化效果的关键步骤。本文天泰将阐述麦芽粉碎的重要性及其对酿造过程的影响。 一、麦芽粉碎的目的 增加酶的作用面积:麦芽中的淀粉和蛋白质等物质需要通过酶…...
PAT甲级1052、Linked LIst Sorting
题目 A linked list consists of a series of structures, which are not necessarily adjacent in memory. We assume that each structure contains an integer key and a Next pointer to the next structure. Now given a linked list, you are supposed to sort the stru…...
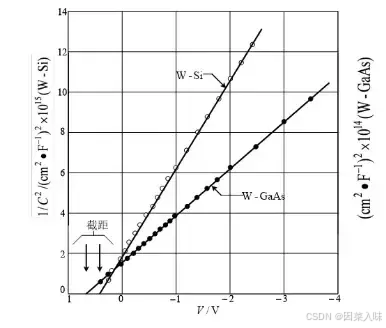
半导体器件与物理篇6 MESFET
金属-半导体接触 MESFET与MOSFET的相同点:它们的电压电流特性相似。都有源漏栅三极,强反型,漏极加正向电压,也会经历线性区、夹断点、饱和区三个阶段。 MESFET与MOSFET的不同点:在器件的栅电极部分,MESFE…...

BES2700源码解析之系统初始化
一 概述 bes2700凭借着超高的性能,超低的功耗,在可穿戴领域有着广泛的应用。笔者使用该芯片做了一些产品解决方案,发现该芯片的性能十分强大。这里做个系列的源码解析。 二 源码解析 1.GPIO和led灯的初始化: tgt_hardware_setup(…...
deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

socket实现HTTP请求,参考HttpURLConnection源码解析
背景 有台服务器,网卡绑定有2个ip地址,分别为: A:192.168.111.201 B:192.168.111.202 在这台服务器请求目标地址 C:192.168.111.203 时必须使用B作为源地址才能访问目标地址C,在这台服务器默认…...
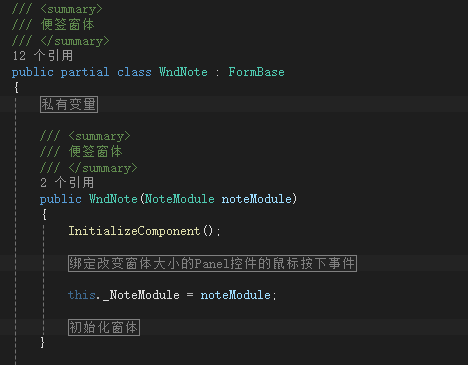
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
Ubuntu下Tkinter绑定数字小键盘上的回车键(PySide6类似)
设计了一个tkinter程序,在Win下绑定回车键,直接绑定"<Return>"就可以使用主键盘和小键盘的回车键直接“提交”,到了ubuntu下就不行了。经过搜索,发现ubuntu下主键盘和数字小键盘的回车键,名称不一样。…...
的用法)
基础笔记|splice()的用法
一、三种用法 splice(index, 0, element) 插入 元素,不删除任何元素。splice(index, deleteCount) 删除 deleteCount 个元素。splice(index, deleteCount, element1, element2, ...) 替换 元素,即删除 deleteCount 个元素,同时插入新的元素。…...

Java BIO详解
一、简介 1.1 BIO概述 BIO(Blocking I/O),即同步阻塞IO(传统IO)。 BIO 全称是 Blocking IO,同步阻塞式IO,是JDK1.4之前的传统IO模型,就是传统的 java.io 包下面的代码实现。 服务…...

Haproxy+keepalived高可用集群,haproxy宕机的解决方案
Haproxykeepalived高可用集群,允许keepalived宕机,允许后端真实服务器宕机,但是不允许haproxy宕机, 所以下面就是解决方案 keepalived配置高可用检测脚本 ,master和backup都要添加 配置脚本 # vim /etc/keepalived…...

98,【6】 buuctf web [ISITDTU 2019]EasyPHP
进入靶场 代码 <?php // 高亮显示当前 PHP 文件的源代码,通常用于调试或展示代码,方便用户查看代码逻辑 highlight_file(__FILE__);// 从 GET 请求中获取名为 _ 的参数值,并赋值给变量 $_ // 符号用于抑制可能出现的错误信息ÿ…...

九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) 文章目录 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)1. RDB 概述2. RDB 持久化执行流程3. RDB 的详细配置4. RDB 备份&恢…...

小程序越来越智能化,作为设计师要如何进行创新设计
一、用户体验至上 (一)简洁高效的界面设计 小程序的特点之一是轻便快捷,用户期望能够在最短的时间内找到所需功能并完成操作。因此,设计师应致力于打造简洁高效的界面。避免过多的装饰元素和复杂的布局,采用清晰的导航…...

(done) MIT6.S081 2023 学习笔记 (Day7: LAB6 Multithreading)
网页:https://pdos.csail.mit.edu/6.S081/2023/labs/thread.html (任务1教会了你如何用 C 语言调用汇编,编译后链接即可) 任务1:Uthread: switching between threads (完成) 在这个练习中,你将设计一个用户级线程系统中的上下文切…...

C++泛型编程指南09 类模板实现和使用友元
文章目录 第2章 类模板 Stack 的实现2.1 类模板 Stack 的实现 (Implementation of Class Template Stack)2.1.1 声明类模板 (Declaration of Class Templates)2.1.2 成员函数实现 (Implementation of Member Functions) 2.2 使用类模板 Stack脚注改进后的叙述总结脚注2.3 类模板…...