MapReduce分区
目录
- 1. MapReduce分区
- 1.1 哈希分区
- 1.2 自定义分区
- 2. 成绩分组
- 2.1 Map
- 2.2 Partition
- 2.3 Reduce
- 3. 代码和结果
- 3.1 pom.xml中依赖配置
- 3.2 工具类util
- 3.3 GroupScores
- 3.4 结果
- 参考
本文引用的Apache Hadoop源代码基于Apache许可证 2.0,详情请参阅 Apache许可证2.0。
1. MapReduce分区
在默认情况下,MapReduce认为Reduce函数处理的是数据汇总操作,因此其针对的必定是一个Map函数清洗处理后的相对规模较小的数据集,且需要对整个集群中所有Map的中间输出结果进行统一处理,因此只会启动一个Reduce计算节点来处理。
这与某些特殊的应用需求并不相匹配。在某些特定的时刻,开发人员希望启动更多的Reduce并发节点来优化最终结果统计的性能,减小数据处理的延迟,这通过简单的设置代码即可完成;而在更定制化的环境中,开发人员希望符合特定规则的Map中间输出结果交由特定的Reduce节点处理,这就需要使用MapReduce分区,开发人员还可以提供自定义的分区规则。
如果有很多个Reduce任务,每个Map任务就会针对输出进行分区,即为每个Reduce任务建立一个分区。每个分区中有很多键,但每个键对应的键值对记录都在同一分区中。如果不给定自定义的分区规则,则Hadoop使用默认的哈希函数来分区,效率较高。
1.1 哈希分区
下面是Apache Hadoop中默认哈希分区的源代码。在这个分区规则中,选择Reduce节点的计算方法是(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks。
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.mapreduce.lib.partition;import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapreduce.Partitioner;/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {/** Use {@link Object#hashCode()} to partition. */public int getPartition(K key, V value,int numReduceTasks) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;}}1.2 自定义分区
如果希望实现自定义分区,需要继承Hadoop提供的分区类org.apache.hadoop.mapreduce.Partitioner,下面是该类的声明。继承该分区类的自定义分区类需要实现public abstract int getPartition(KEY key, VALUE value, int numPartitions),该函数的作用是设置Map中间处理结果的分区规则,其中numPartitions是总分区的个数。此外,在自定义分区类时,通过函数返回了多少个分区,那么在MapReduce任务调度代码中需要设置Job.setNumReduceTasks(自定义分区个数)。
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.mapreduce;import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configurable;/** * Partitions the key space.* * <p><code>Partitioner</code> controls the partitioning of the keys of the * intermediate map-outputs. The key (or a subset of the key) is used to derive* the partition, typically by a hash function. The total number of partitions* is the same as the number of reduce tasks for the job. Hence this controls* which of the <code>m</code> reduce tasks the intermediate key (and hence the * record) is sent for reduction.</p>** <p>Note: A <code>Partitioner</code> is created only when there are multiple* reducers.</p>** <p>Note: If you require your Partitioner class to obtain the Job's* configuration object, implement the {@link Configurable} interface.</p>* * @see Reducer*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class Partitioner<KEY, VALUE> {/** * Get the partition number for a given key (hence record) given the total * number of partitions i.e. number of reduce-tasks for the job.* * <p>Typically a hash function on a all or a subset of the key.</p>** @param key the key to be partioned.* @param value the entry value.* @param numPartitions the total number of partitions.* @return the partition number for the <code>key</code>.*/public abstract int getPartition(KEY key, VALUE value, int numPartitions);}2. 成绩分组
成绩文本如下,第一列为人名,第二列为成绩。目标是将成绩分为5段,分别为 [ 0 , 20 ) [0, 20) [0,20), [ 20 , 40 ) [20, 40) [20,40), [ 40 , 60 ) [40, 60) [40,60), [ 60 , 80 ) [60, 80) [60,80), [ 80 , 100 ] [80, 100] [80,100]。
1 23
2 78
3 45
4 12
5 67
6 34
7 89
8 56
9 9
10 78
11 21
12 54
13 83
14 10
15 65
16 39
17 92
18 47
19 28
20 72
2.1 Map
假设这个MapReduce作业使用了1个Map,Map的作用是从文本获取<人名,成绩>键值对,同时保证成绩在有效范围内。

2.2 Partition
根据成绩进行分区,其中1的范围是 [ 20 , 40 ) [20, 40) [20,40),3的范围是 [ 60 , 80 ) [60, 80) [60,80),2的范围是 [ 40 , 60 ) [40, 60) [40,60),4的范围是 [ 80 , 100 ] [80, 100] [80,100],0的范围是 [ 0 , 20 ) [0, 20) [0,20)。

2.3 Reduce
reduce不进行任何操作,直接将分区结果排序后写入5个文件中。

3. 代码和结果
3.1 pom.xml中依赖配置
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.6</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.3.6</version><type>pom</type></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>3.3.6</version></dependency></dependencies>
3.2 工具类util
import java.net.URI;
import java.util.regex.Matcher;
import java.util.regex.Pattern;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class util {public static FileSystem getFileSystem(String uri, Configuration conf) throws Exception {URI add = new URI(uri);return FileSystem.get(add, conf);}public static void removeALL(String uri, Configuration conf, String path) throws Exception {FileSystem fs = getFileSystem(uri, conf);if (fs.exists(new Path(path))) {boolean isDeleted = fs.delete(new Path(path), true);System.out.println("Delete Output Folder? " + isDeleted);}}public static void showResult(String uri, Configuration conf, String path) throws Exception {FileSystem fs = getFileSystem(uri, conf);String regex = "part-r-";Pattern pattern = Pattern.compile(regex);if (fs.exists(new Path(path))) {FileStatus[] files = fs.listStatus(new Path(path));for (FileStatus file : files) {Matcher matcher = pattern.matcher(file.getPath().toString());if (matcher.find()) {System.out.println(file.getPath() + ":");FSDataInputStream openStream = fs.open(file.getPath());IOUtils.copyBytes(openStream, System.out, 1024);openStream.close();}}}}
}
3.3 GroupScores
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class App {public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String[] splitStr = value.toString().split(" ");Text keyOut = new Text(splitStr[0]);int grade = Integer.parseInt(splitStr[1]);if (grade >= 0 && grade <= 100) {IntWritable valueOut = new IntWritable(grade);context.write(keyOut, valueOut);}}}public static class MyPartitioner extends Partitioner<Text, IntWritable> {@Overridepublic int getPartition(Text key, IntWritable value, int numPartitions) {if (value.get() >= 80) {return 0;} else if (value.get() >= 60) {return 1;} else if (value.get() >= 40) {return 2;} else if (value.get() >= 20) {return 3;} else {return 4;}}}public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable value : values) {context.write(key, value);}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] myArgs = {"file:///home/developer/CodeArtsProjects/mapreduce-partitioner/values.txt","hdfs://localhost:9000/user/developer/GroupScores/output"};util.removeALL("hdfs://localhost:9000", conf, myArgs[myArgs.length - 1]);Job job = Job.getInstance(conf, "GroupScores");job.setMapperClass(MyMapper.class);job.setPartitionerClass(MyPartitioner.class);job.setReducerClass(MyReducer.class);job.setNumReduceTasks(5);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < myArgs.length - 1; i++) {FileInputFormat.setInputPaths(job, new Path(myArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(myArgs[myArgs.length - 1]));int res = job.waitForCompletion(true) ? 0 : 1;if (res == 0) {System.out.println("GroupScores结果为:");util.showResult("hdfs://localhost:9000", conf, myArgs[myArgs.length - 1]);}System.exit(res);}
}3.4 结果
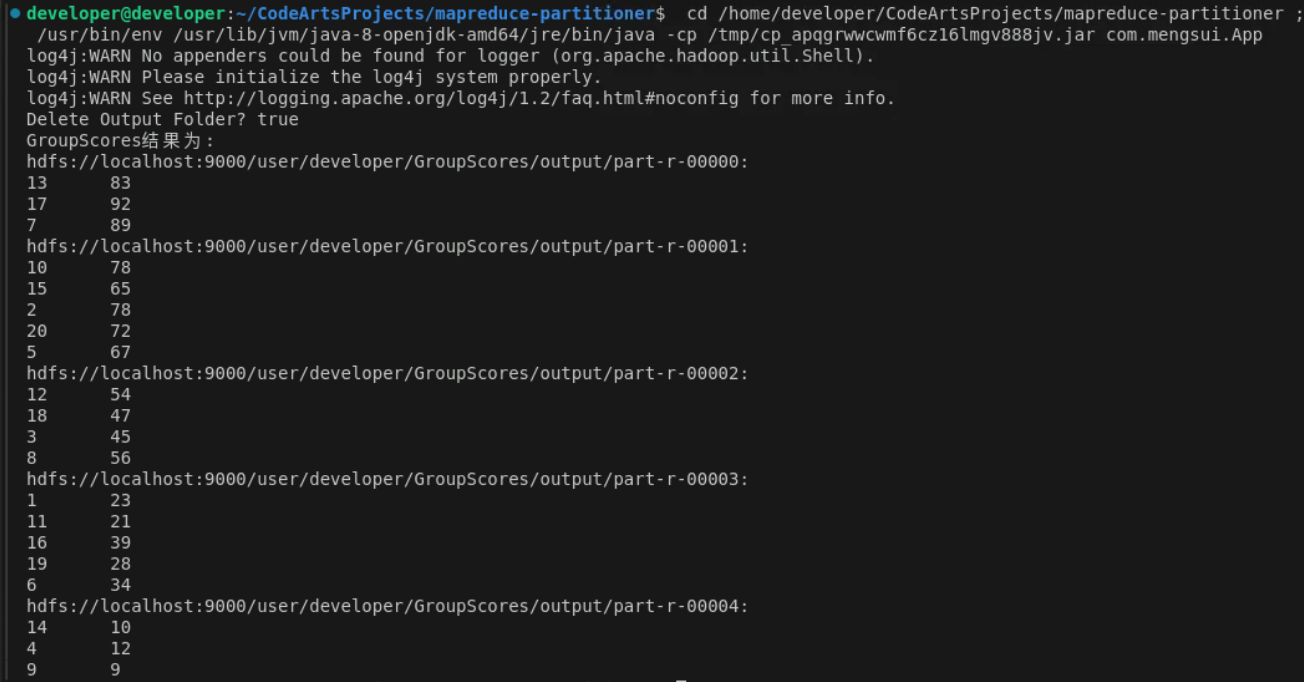
参考
吴章勇 杨强著 大数据Hadoop3.X分布式处理实战
相关文章:
MapReduce分区
目录 1. MapReduce分区1.1 哈希分区1.2 自定义分区 2. 成绩分组2.1 Map2.2 Partition2.3 Reduce 3. 代码和结果3.1 pom.xml中依赖配置3.2 工具类util3.3 GroupScores3.4 结果 参考 本文引用的Apache Hadoop源代码基于Apache许可证 2.0,详情请参阅 Apache许可证2.0。…...

【Spring】Spring Cloud Alibaba 版本选择及项目搭建笔记
文章目录 前言1. 版本选择2. 集成 Nacos3. 服务间调用4. 集成 Sentinel5. 测试后记 前言 最近重新接触了 Spring Cloud 项目,为此参考多篇官方文档重新搭建一次项目,主要实践: 版本选择,包括 Spring Cloud Alibaba、Spring Clou…...

C语言实现统计字符串中不同ASCII字符个数
在C语言编程中,经常会遇到一些对字符串进行处理的需求,今天我们就来探讨如何统计给定字符串中ASCII码在0 - 127范围内不同字符的个数。这不仅是一个常见的算法问题,也有助于我们更好地理解C语言中数组和字符操作的相关知识。 问题描述 对于给…...

保姆级教程Docker部署Zookeeper官方镜像
目录 1、安装Docker及可视化工具 2、创建挂载目录 3、运行Zookeeper容器 4、Compose运行Zookeeper容器 5、查看Zookeeper运行状态 6、验证Zookeeper是否正常运行 1、安装Docker及可视化工具 Docker及可视化工具的安装可参考:Ubuntu上安装 Docker及可视化管理…...

DeepSeek R1 简易指南:架构、本地部署和硬件要求
DeepSeek 团队近期发布的DeepSeek-R1技术论文展示了其在增强大语言模型推理能力方面的创新实践。该研究突破性地采用强化学习(Reinforcement Learning)作为核心训练范式,在不依赖大规模监督微调的前提下显著提升了模型的复杂问题求解能力。 技…...

Ollama教程:轻松上手本地大语言模型部署
Ollama教程:轻松上手本地大语言模型部署 在大语言模型(LLM)飞速发展的今天,越来越多的开发者希望能够在本地部署和使用这些模型,以便更好地控制数据隐私和计算资源。Ollama作为一个开源工具,旨在简化大语言…...
)
并行计算、分布式计算与云计算:概念剖析与对比研究(表格对比)
什么是并行计算?什么是分布计算?什么是云计算?我们如何更好理解这3个概念,我们采用概念之间的区别和联系的方式来理解,做到切实理解,深刻体会。 1、并行计算与分布式计算 并行计算、分布式计算都属于高性…...

Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写
Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写 基于springboot(可改ssm)htmlvue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库&…...

【Linux系统】信号:再谈OS与内核区、信号捕捉、重入函数与 volatile
再谈操作系统与内核区 1、浅谈虚拟机和操作系统映射于地址空间的作用 我们调用任何函数(无论是库函数还是系统调用),都是在各自进程的地址空间中执行的。无论操作系统如何切换进程,它都能确保访问同一个操作系统实例。换句话说&am…...

自定义数据集 使用paddlepaddle框架实现逻辑回归
导入必要的库 import numpy as np import paddle import paddle.nn as nn 数据准备: seed1 paddle.seed(seed)# 1.散点输入 定义输入数据 data [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6…...

LabVIEW图片识别逆向建模系统
本文介绍了一个基于LabVIEW的图片识别逆向建模系统的开发过程。系统利用LabVIEW的强大视觉处理功能,通过二维图片快速生成对应的三维模型,不仅降低了逆向建模的技术门槛,还大幅提升了建模效率。 项目背景 在传统的逆向建模过程中…...

MySQL(高级特性篇) 13 章——事务基础知识
一、数据库事务概述 事务是数据库区别于文件系统的重要特性之一 (1)存储引擎支持情况 SHOW ENGINES命令来查看当前MySQL支持的存储引擎都有哪些,以及这些存储引擎是否支持事务能看出在MySQL中,只有InnoDB是支持事务的 &#x…...

前端进阶:深度剖析预解析机制
一、预解析是什么? 在前端开发中,我们常常会遇到一些看似不符合常规逻辑的代码执行现象,比如为什么在变量声明之前访问它,得到的结果是undefined,而不是报错?为什么函数在声明之前就可以被调用?…...

C++实现一款功能丰富的通讯录管理系统
在学习编程的过程中,如何设计一个实用的项目是许多同学头疼的问题。如果你是一位正在学习C的同学,想通过实际项目巩固知识,那么这个通讯录管理系统绝对是一个理想的练手项目。在本文中,我将详细拆解代码逻辑,帮助你理解…...

Selenium 使用指南:从入门到精通
Selenium 使用指南:从入门到精通 Selenium 是一个用于自动化 Web 浏览器操作的强大工具,广泛应用于自动化测试和 Web 数据爬取中。本文将带你从入门到精通地掌握 Selenium,涵盖其基本操作、常用用法以及一个完整的图片爬取示例。 1. 环境配…...

【力扣】53.最大子数组和
AC截图 题目 思路 这道题主要考虑的就是要排除负数带来的负面影响。如果遍历数组,那么应该有如下关系式: currentAns max(prenums[i],nums[i]) pre是之前记录的最大和,如果prenums[i]小于nums[i],就要考虑舍弃pre,从…...

基于Spring Security 6的OAuth2 系列之七 - 授权服务器--自定义数据库客户端信息
之所以想写这一系列,是因为之前工作过程中使用Spring Security OAuth2搭建了网关和授权服务器,但当时基于spring-boot 2.3.x,其默认的Spring Security是5.3.x。之后新项目升级到了spring-boot 3.3.0,结果一看Spring Security也升级…...

vim-plug的自动安装与基本使用介绍
vim-plug介绍 Vim-plug 是一个轻量级的 Vim 插件管理器,它允许你轻松地管理 Vim 插件的安装、更新和卸载。相较于其他插件管理器,vim-plug 的优点是简单易用,速度较快,而且支持懒加载插件(即按需加载) 自动…...

Deep Crossing:深度交叉网络在推荐系统中的应用
实验和完整代码 完整代码实现和jupyter运行:https://github.com/Myolive-Lin/RecSys--deep-learning-recommendation-system/tree/main 引言 在机器学习和深度学习领域,特征工程一直是一个关键步骤,尤其是对于大规模的推荐系统和广告点击率预…...
想品客老师的第十天:类
类是一个优化js面向对象的工具 类的声明 //1、class User{}console.log(typeof User)//function//2、let Hdclass{}//其实跟1差不多class Stu{show(){}//注意这里不用加逗号,对象才加逗号get(){console.log(后盾人)}}let hdnew Stu()hd.get()//后盾人 类的原理 类…...
:AJAX技术(前端发送请求))
4 前端前置技术(上):AJAX技术(前端发送请求)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 前言...

MyBatis-Plus速成指南:条件构造器和常用接口
Wrapper 介绍 Wrapper:条件构造抽象类,最顶端父类 AbstractWrapper:用于查询条件封装,生成 SQL 的 where 条件QueryWrapper:查询条件封装UpdateWrapper:Update 条件封装AbstractLambdaWrapper:使…...
空间复杂度-一次遍历双指针)
LeetCode 0922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针
【LetMeFly】922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针 力扣题目链接:https://leetcode.cn/problems/sort-array-by-parity-ii/ 给定一个非负整数数组 nums, nums 中一半整数是 奇数 ,一半整数是 偶数 。 对数组进…...

windows环境下如何在PyCharm中安装软件包
windows环境下如何在pyCharm中安装wxPython软件包 在windows环境中,安装软件包可以使用 终端 的方式,在IDE下方的终端中执行pip install wxPython进行安装,安装完毕之后,使用pip show wxPython检查也符合预期。 但是在代码文件中导…...

(脚本学习)BUU18 [CISCN2019 华北赛区 Day2 Web1]Hack World1
自用 题目 考虑是不是布尔盲注,如何测试:用"1^1^11 1^0^10,就像是真真真等于真,真假真等于假"这个测试 SQL布尔盲注脚本1 import requestsurl "http://8e4a9bf2-c055-4680-91fd-5b969ebc209e.node5.buuoj.cn…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.25 多线程并行:GIL绕过与真正并发
2.25 多线程并行:GIL绕过与真正并发 目录 #mermaid-svg-JO4lsTIyjOweVkos {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-JO4lsTIyjOweVkos .error-icon{fill:#552222;}#mermaid-svg-JO4lsTIyjOweVkos …...

Java 大视界 -- Java 大数据在智能医疗影像诊断中的应用(72)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!💖 一、…...

【Leetcode刷题记录】1456. 定长子串中元音的最大数目---定长滑动窗口即解题思路总结
1456. 定长子串中元音的最大数目 给你字符串 s 和整数 k 。请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。 英文中的 元音字母 为(a, e, i, o, u)。 这道题的暴力求解的思路是通过遍历字符串 s 的每一个长度为 k 的子串…...

upload-labs安装与配置
前言 作者进行upload-labs靶场练习时,在环境上出了很多问题,吃了很多苦头,甚至改了很多配置也没有成功。 upload-labs很多操作都是旧时代的产物了,配置普遍都比较老,比如PHP版本用5.2.17(还有中间件等&am…...

从Transformer到世界模型:AGI核心架构演进
文章目录 引言:架构革命推动AGI进化一、Transformer:重新定义序列建模1.1 注意力机制的革命性突破1.2 从NLP到跨模态演进1.3 规模扩展的黄金定律二、通向世界模型的关键跃迁2.1 从语言模型到认知架构2.2 世界模型的核心特征2.3 混合架构的突破三、构建世界模型的技术路径3.1 …...