18爬虫:关于playwright相关内容的学习
1.如何在python中安装playwright
打开pycharm,进入终端,输入如下的2个命令行代码即可自动完成playwright的安装
pip install playwright ——》在python中安装playwright第三方模块
playwright install ——》安装playwright所需的工具插件和所支持的浏览器
看到这里,是否想要动手进行安装。先不要着急,playwright对安装环境也是有一定要求的。
| python版本要求 | Python 3.8 或更高版本 |
| windows系统要求 | Windows 10+、Windows Server 2016+ |
| MacOS系统版本要求 | MacOS 12 Monterey 或 MacOS 13 Ventura |
| linux系统版本要求 | Debian 11、Debian 12、Ubuntu 20.04 或 Ubuntu 22.04 |
2.playwright的录屏功能
playwright具有录屏功能,并自动生成相应的同步操作代码或者异步操作代码,这个功能是非常强大的。
打开pycharm进入终端,输入如下的命令
| 打开浏览器并启动录屏操作 | playwright codegen |
| 打开浏览器并进入指定网页同时启动录屏操作 | playwright codegen https://www.baidu.com/ |
| 查看对应的参数 | playwright codegen --help |
当我们在pycharm终端中输入:playwright codegen 后,会自动弹出浏览器和代码录屏窗口

我们在使用playwright弹出的浏览器时,需要讲该浏览器的搜索引擎变更问百度或者其他在国内可用的搜索引擎,原浏览器搜索引擎默认是google。
接下来我们进入百度页面,输入python,可以发现右侧的代码记录工具将我们在浏览器上的操作逐一映射成python代码,默认是生成同步代码,这个代码是可以直接在python编译环境中运行的。
import re
from playwright.sync_api import Playwright, sync_playwright, expectdef run(playwright: Playwright) -> None:browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://www.baidu.com/s?ie=UTF-8&wd=%E7%99%BE%E5%BA%A6")with page.expect_popup() as page1_info:page.locator("#content_left [id=\"\\31 \"]").get_by_role("link", name="百度一下,你就知道").click()page1 = page1_info.valuepage1.locator("#kw").click()page1.locator("#kw").fill("pytho")page1.locator("#kw").press("Enter")page1.locator("#kw").press("Enter")page1.get_by_role("button", name="百度一下").click()# ---------------------context.close()browser.close()with sync_playwright() as playwright:run(playwright)
3.playwright驱动浏览器的两种方式
使用with驱动浏览器,代码如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p: # 实例化一个playwright对象# headless设置有头模式启动浏览器browser = p.chromium.launch(headless=False) # 创建一盒浏览器对象,指定驱动的浏览器,用launch设置启动的模式context = browser.new_context() # 创建上下文,上下文可以理解为上下文的交互,同时会打开一个浏览器page = context.new_page() # 打开一个浏览器的标签页page.goto('url') # 访问的网址page.wait_for_timeout(10000) # 默认的单位是毫秒,作用类似于timeout,该种方法是playsright自带的# 正常关闭playwright的步骤page.close() # 关闭访问的页面context.close() # 关闭上下文管理工具browser.close() # 关闭浏览器不使用with,一般使用录屏工具生成的代码都是不使用with,代码如下:
from playwright.sync_api import sync_playwrightp = sync_playwright().start() # 实例化一个playwright对象
browser = p.chromium.launch(headless=False,slow_mo=2000) # 创建一个浏览器对象,有头的模式,slow_mo表示每执行一个步骤暂停2秒
context = browser.new_context() # 创建上下文管理器
page = context.new_page() # 创建一个网页对象
page.goto("https://www.baidu.com/") # 使用网页对象访问对应url网站
page.wait_for_timeout(10000) # 等待10秒。10000毫秒page.close() # 关闭网页对象
context.close() # 关闭上下文管理器
browser.close() # 关闭浏览器对象p.stop() # 停止playwright对象使用with驱动浏览器可以自动帮我们打开浏览器(sync_playwright().start()),也可以帮我们自动停止浏览器进程(sync_playwright().stop())。不使用with则需要我们手动开启和停止,除此以外代码逻辑没有区别。
4.playwright同时驱动两个浏览器
在同一个浏览器中使用一个context管理器管理所有的标签页,如果想要同时驱动两个浏览器或者多个浏览器,需要创建两个不同的context管理器,具体的代码如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context1 = browser.new_context()context2 = browser.new_context()page1 = context1.new_page()page2 = context2.new_page()page1.goto('https://www.baidu.com/')page2.goto('https://www.mi.com/shop')page1.wait_for_timeout(10000)page2.wait_for_timeout(10000)print(page1.title)print(page2.title)page1.close()page2.close()context1.close()context2.close()browser.close()在上述的代码中,我们分别创建两个不同context管理器对象,并创建两个不同的浏览器页面分别访问百度和小米。
5.在同一个浏览器中访问两个不同的网页
有了驱动两个不同浏览器的基础,在同一个浏览器中访问两个不同的网页,也就是打开两个标签是非常简单的。在代码中,我们使用同一个context管理器创建两个不同的page对象分别访问不同的url,具体代码如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()# 只需要一个context对象page1 = context.new_page()page2 = context.new_page()page1.goto('https://www.baidu.com/')page2.goto('https://www.mi.com/shop')page1.wait_for_timeout(10000)page2.wait_for_timeout(10000)print(page1.title)print(page2.title)page1.close()page2.close()context.close()browser.close()6.网页之间的切换操作
学习过前端的相关知识后,我们发现在网页上点击某一超链接,有的会在原标签页上打开超链接对应的网页,有的会打开一个新的标签页,有的会弹出一个新的浏览器窗口。那么如何才能让代码访问到新打开的网页,如何才能返回原网上上呢。
这里就需要使用context管理器中的pages属性,该属性是一个列表,记录我们当前代码打开的所有网页,索引0表示原网页,索引1表示第二次打开的网页,以此类推。

《写文章-CSDN创作中心》对应的索引为0——〉原网页
《qq_37587269-CSDN博客》对应的索引为1——〉第二次打开的网页
《路飞学城-帮助有志向的年轻人》对应的索引为2——〉第三次打开的网页
'''
网页之间的切换有些网页的超链接打开之后会新开一个标签页,也有可能是弹出一个新的窗口如果要定位新页面上面的元素的话,需要进行网页切换pages = context.pages——》上下文管理器中的pages能够记录当前浏览器打开恶所有网页pages[i].bring_to_front()——》激活当前页面的句柄# 切换网页的另外两种方式context.go_to_page(pages[i])context.go_to_url(pages[i].url)
'''from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False,slow_mo=2000)context = browser.new_context()page = context.new_page()page.goto("https://blog.csdn.net/weixin_40744274/article/details/140598126") # CSDN网页page.locator('xpath=//*[@id="markdownContent"]/p[3]/a').click() # 网页上的某一个超链接,点击之后打开一个新的标签页page.locator('xpath=//*[@id="markdownContent"]/p[4]/a').click() # 网页上的某一个超链接,点击之后打开一个新的标签页page.wait_for_timeout(5000)pages = context.pages # 获取所有的打开网页'''pages的形式是所有打开的网页的url组成的列表,url的顺序是我们打开网页的顺序,整体称为网页句柄pages = [<Page url='https://blog.csdn.net/weixin_40744274/article/details/140598126'>, <Page url='https://link.csdn.net/?from_id=140598126&target=https%3A%2F%2Fedu.51cto.com%2Fvideo%2F4645.html%3Futm_platform%3Dpc%26utm_medium%3D51cto%26utm_source%3Dzhuzhan%26utm_content%3Dwzy_tl'>, <Page url='https://link.csdn.net/?from_id=140598126&target=https%3A%2F%2Fedu.51cto.com%2Fvideo%2F3832.html%3Futm_platform%3Dpc%26utm_medium%3D51cto%26utm_source%3Dzhuzhan%26utm_content%3Dwzy_tl'>]'''print(pages)# 切换到网页2上pages[1].bring_to_front() # 调整当前playwright的视角至第二个打开的网页上pages[1].locator('xpath=//*[@id="linkPage"]/div[1]/div[2]/div[2]/a').click()pages[1].wait_for_timeout(5000)# 切换到网页3上pages[2].bring_to_front() # 调整当前playwright的视角至第三个打开的网页上pages[2].locator('xpath=//*[@id="linkPage"]/div[1]/div[2]/div[2]/a').click()pages[2].wait_for_timeout(5000)# 返回初始网页,也就是网页1page.bring_to_front() # pages[0],bring_to_front()t = page.locator('xpath=/html/head/title').inner_text() # python playwright模拟鼠标右键点击-CSDN博客print(t)page.close()context.close()browser.close()不同网页之间的切换代码如上所示:利用context.pages中记录的不同网页对象,通过context.pages[i].bring_to_front()激活当前网页,也就是将playwright的视角切换至当前网页。综上所述,playwright切换网页依赖于context的pages属性与bring_to_front()方法。
| context.pages | 记录当前context管理器下所有打开的网页 |
| context.pages[i].bring_to_front() | 激活指定索引对应的网页 |
7.模拟网页中的前进与后退
当我们打开某个超链接后,有的会在原标签页上打开超链接对应的网页,此时我们不需要切换playwright的视角就可以访问新网页,这一点是非常人性化的。
当我们访问完新网页后,如何才能退回至原来的网页中呢。这时如果再使用网页切换是不可行的,在context.pages中仅仅保存了最新的url,此时需要使用page中的go_forward()与go_back()方法模拟网页中的前进与后退。具体代码如下:
'''
模拟浏览器中的前进与后退
page.go_forward()和page.go_back()方法,实现网页的前进与后退,同一网页标签上的前进与后退
'''
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://www.mi.com/?g_utm=Thirdparty.Baidu.ProductUnion.BrandZone-Baidu-PC.Brand-A-2")page.wait_for_timeout(5000)# 点击网页登录,相当于网页前进异步page.locator('xpath=//div[contains(text(),"登录")]').click()loc = page.locator('xpath=//input[@name="account"]')page.wait_for_timeout(5000)# 模拟浏览器中的前进后退page.go_back() # 网页后退page.wait_for_timeout(5000)page.go_forward() # 网页前进page.wait_for_timeout(5000)# 测试前进后退之后是否需要重新定位元素# 跳转到登录的页面loc.fill('123456')page.locator('xpath=//input[@name="password"]').fill('1234567')page.wait_for_timeout(5000)page.locator('xpath=//button[@type="submit"]').click()page.wait_for_timeout(5000)page.close()context.close()browser.close()
8.playwright中的元素定位
playwrigh中元素定位多种,这里我们仅以代码的形式演示如何使用xpath进行元素定位,代码如下:
'''
playwright中的元素定位方法playwright中有内置的get_xx_xx方法,系统默认同样也有locator()方法进行定位contains关键字的使用,对应的语法结构为contains(属性,值)and关键字的使用 例如://div[@class="uesr_name" and @id="account"]在xpath中通过文本进行定位:注意开始标签和结束标签之间的文本才是元素上的文字,元素上的文字才可以使用该种定位方法<div>文本</div>对应的语法结构为: //div[text()="输入"]也可以结合contains进行文本定位: contains(text(),'登录')xpath定位中一些不常用的定位方法playwright中的文本定位,精确匹配page.locator('text="登录"'),模糊匹配page.locator('text=登录')该定位比xpath中的定位强大很多,不仅可以定位HTML标签之间的文字,也可以定位HTML标签属性内的文字元素,也就是说只要页面上存在的文字都可以拿来使用只掌握xpath定位即可
'''from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://www.mi.com/?g_utm=Thirdparty.Baidu.ProductUnion.BrandZone-Baidu-PC.Brand-A-2")# page.locator('xpath=//div[@class="user-name"]').click() # 通过xpath定位登录按钮然后进行点击登录# xpath中关键字contains使用# page.locator('//div[contains(@class,"name")]').click() # 定位div标签,其class属性值包含name# 使用xpath进行文本定位# page.locator('xpath=//div[text()="登录"]').click()# contains结合文本进行定位page.locator('xpath=//div[contains(text(),"登录")]').click()page.wait_for_timeout(5000)# 通过xpath中的文本进行定位# 跳转到登录的页面page.locator('xpath=//input[@name="account"]').fill('123456')page.locator('xpath=//input[@name="password"]').fill('1234567')page.wait_for_timeout(5000)page.locator('xpath=//button[@type="submit"]').click()page.wait_for_timeout(5000)page.close()context.close()browser.close()
9.playwright中保存cookie信息以及如何使用cookie自动登录网页
如果想要保存cookie信息,需要使用 context.storage_state(path='login_status.json')
如果想要使用本地的cookie信息,需要在创建context对象时加入本地保留的cookie信息,context = browser.new_context(storage_state='login_status.json')
playwright保留登录的cookie信息,代码如下:
'''
context.storage_state(path='login_status.json') 将cookie保存至一个json文件中
'''
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://www.mi.com/?g_utm=Thirdparty.Baidu.ProductUnion.BrandZone-Baidu-PC.Brand-A-2")page.get_by_text("登录").click()page.locator('xpath=//*[@id="rc-tabs-0-panel-login"]/form/div[1]/div[1]/div[2]/div/div/div/div/input').fill('XXXXXX')page.locator('xpath=//*[@id="rc-tabs-0-panel-login"]/form/div[1]/div[2]/div/div[1]/div/input').fill('XXXXXX')page.locator('xpath=//*[@id="rc-tabs-0-panel-login"]/form/div[1]/div[3]/label/span[1]/input').click()page.locator('xpath=//*[@id="rc-tabs-0-panel-login"]/form/div[1]/button').press('Enter')page.wait_for_timeout(5000)# 暴露cookie信息,将对应的信息保存至json文件context.storage_state(path='login_status.json')page.close()context.close()browser.close()
使用本地保留的cookie信息登录代码如下:
'''
context.storage_state(path='login_status.json') 将cookie保存至一个json文件中
context = browser.new_context(storage_state='login_status.json')使用保留的json文件
'''
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context(storage_state='login_status.json') # 在实例化上下文的时候使用cookie信息直接登录page = context.new_page()page.goto("https://www.mi.com/?g_utm=Thirdparty.Baidu.ProductUnion.BrandZone-Baidu-PC.Brand-A-2")page.wait_for_timeout(10000)page.close()context.close()browser.close()
10:实战:bili中指定关键字搜索页面中视频的标题和作者名称
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://bilibili.com")page.locator('xpath=//input[@class="nav-search-input"]').fill('python')page.locator('xpath=//*[@id="nav-searchform"]/div[2]').click()# 此时虽然打开一个新的网页,但是playwright的视角页进行了同步切换,检查context.pages只有一个url记录t3 = page.locator('xpath=//h3').all()for t in t3:print(t.get_attribute('title'))page.wait_for_timeout(10000)page.close()context.close()browser.close()相关文章:
18爬虫:关于playwright相关内容的学习
1.如何在python中安装playwright 打开pycharm,进入终端,输入如下的2个命令行代码即可自动完成playwright的安装 pip install playwright ——》在python中安装playwright第三方模块 playwright install ——》安装playwright所需的工具插件和所支持的…...

docker Error response from daemon: Get “https://registry-1.docker.io/v2/ 的问题处理
docker Error response from daemon: Get "https://registry-1.docker.io/v2/ 的问题处理 最近pull 数据 发现 docker 有如下错误 文章目录 docker Error response from daemon: Get "https://registry-1.docker.io/v2/ 的问题处理报错问题检查网络连接解决方案&…...

拉取本地的 Docker 镜像的三种方法
方法 1:通过 docker save 和 docker load 导出和导入镜像 在本地服务器上导出镜像: 使用 docker save 将镜像保存为一个 .tar 文件: docker save -o mysql-5.7.tar mysql:5.7 将镜像文件传输到其他服务器: 你可以通过 scp 或其他…...

【Linux系统】线程:线程的优点 / 缺点 / 超线程技术 / 异常 / 用途
1、线程的优点 创建和删除线程代价较小 创建一个新线程的代价要比创建一个新进程小得多,删除代价也小。这种说法主要基于以下几个方面: (1)资源共享 内存空间:每个进程都有自己独立的内存空间,包括代码段…...

老榕树的Java专题:Redis 从入门到实践
一、引言 在当今的软件开发领域,数据的高效存储和快速访问是至关重要的。Redis(Remote Dictionary Server)作为一个开源的、基于内存的数据结构存储系统,因其高性能、丰富的数据类型和广泛的应用场景,成为了众多开发者…...

123,【7】 buuctf web [极客大挑战 2019]Secret File
进入靶场 太熟悉了,有种回家的感觉 查看源代码,发现一个紫色文件 点下看看 点secret 信息被隐藏了 要么源代码,要么抓包 源代码没有,抓包 自己点击时只能看到1和3处的文件,点击1后直接跳转3,根本不出…...

微服务知识——微服务拆分规范
文章目录 一、微服务拆分规范1、高内聚、低耦合2、服务拆分正交性原则3、服务拆分层级最多三层4、服务粒度适中、演进式拆分5、避免环形依赖、双向依赖6、通用化接口设计,减少定制化设计7、接口设计需要严格保证兼容性8、将串行调用改为并行调用,或者异步…...

docker数据持久化的意义
Docker 数据持久化是指在 Docker 容器中保存的数据不会因为容器的停止、删除或重启而丢失。Docker 容器本身是临时性的,默认情况下,容器内的文件系统是临时的,容器停止或删除后,其中的数据也会随之丢失。为了确保重要数据…...

双目标定与生成深度图
基于C#联合Halcon实现双目标定整体效果 一,标定 1,标定前准备工作 (获取描述文件与获取相机参数) 针对标准标定板可以直接调用官方提供描述文件,也可以自己生成描述文件后用PS文件打印 2,相机标定 &…...
、count() 与 count(列名) 的区别)
【SQL】count(1)、count() 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释: 1. COUNT(1) 定义: COUNT(1) 计算查询结果集中的行数。 实现: 在执…...

使用bucardo实现postgresql数据库双主同步
使用bucardo实现postgresql数据库双主同步 方案优缺点 优点 pg数据库只支持单向数据复制,双机部署一般只能使用主(读写)备(只读)模式。而使用bucardo能实现pg数据库双机的双主模式,支持同时双写…...

在 Navicat 17 中扩展 PostgreSQL 数据类型 | 创建自定义域
定义域 以适当的格式存储数据可以确保数据完整性,防止错误,优化性能,并通过实施验证规则和支持高效数据管理来维护系统间的一致性。基于这些原因,顶级关系数据库(如PostgreSQL)提供了多种数据类型。此外&a…...

【Apache Paimon】-- 15 -- 利用 paimon-flink-action 同步 postgresql 表数据
利用 Paimon Schema Evolution 核心特性同步变更的 postgresql 表结构和数据 1、背景信息 在Paimon 诞生以前,若 mysql/pg 等数据源的表结构发生变化时,我们有几种处理方式 (1)人工消息通知,然后手动同步到数据仓库中(2)使用 flink 消费 DDL binlog ,然后自动更新 Hi…...

获取 ARM Cortex - M 系列处理器中 PRIMASK 寄存器的值
第一种实现(纯汇编形式) __ASM uint32_t __get_PRIMASK(void) {mrs r0, primaskbx lr }代码分析 __ASM 关键字:这通常是特定编译器(如 ARM GCC 等)用于嵌入汇编代码的指示符。它告诉编译器下面的代码是汇编代码。mrs …...

Linux+Docer 容器化部署之 Shell 语法入门篇 【Shell 替代】
🎀🎀Shell语法入门篇 系列篇 🎀🎀 LinuxDocer 容器化部署之 Shell 语法入门篇 【准备阶段】LinuxDocer 容器化部署之 Shell 语法入门篇 【Shell变量】LinuxDocer 容器化部署之 Shell 语法入门篇 【Shell数组与函数】LinuxDocer 容…...

如何处理网络连接错误导致的fetch失败?
处理由于网络连接错误导致的 fetch 失败通常涉及捕获网络错误并提供适当的用户反馈。以下是如何在 Vue 3 中实现这一点的步骤和示例。 一、更新 useFetch 函数 在 useFetch 函数中,需要捕获网络错误,并设置相应的错误信息。网络错误通常会抛出一个 TypeError,可以根据这个…...

PHP PDO 教程
PHP PDO 教程 概述 PHP PDO(PHP Data Objects)扩展为PHP提供了数据访问抽象层。PDO可以让你使用相同的接口访问多种数据库系统,这大大简化了数据库操作。本文将详细介绍PHP PDO的基本用法、优势以及在实际开发中的应用。 ##PDO 简介 PDO是…...

离线统信系统的python第三方库批量安装流程
一、关于UOS本机 操作系统:UOS(基于Debian的Linux发行版) CPU:海光x86 二、具体步骤 1、在联网的电脑上用控制台的pip命令批量下载指定版本的第三方库 方法A cd <目标位置的绝对路径> pip download -d . --platform many…...
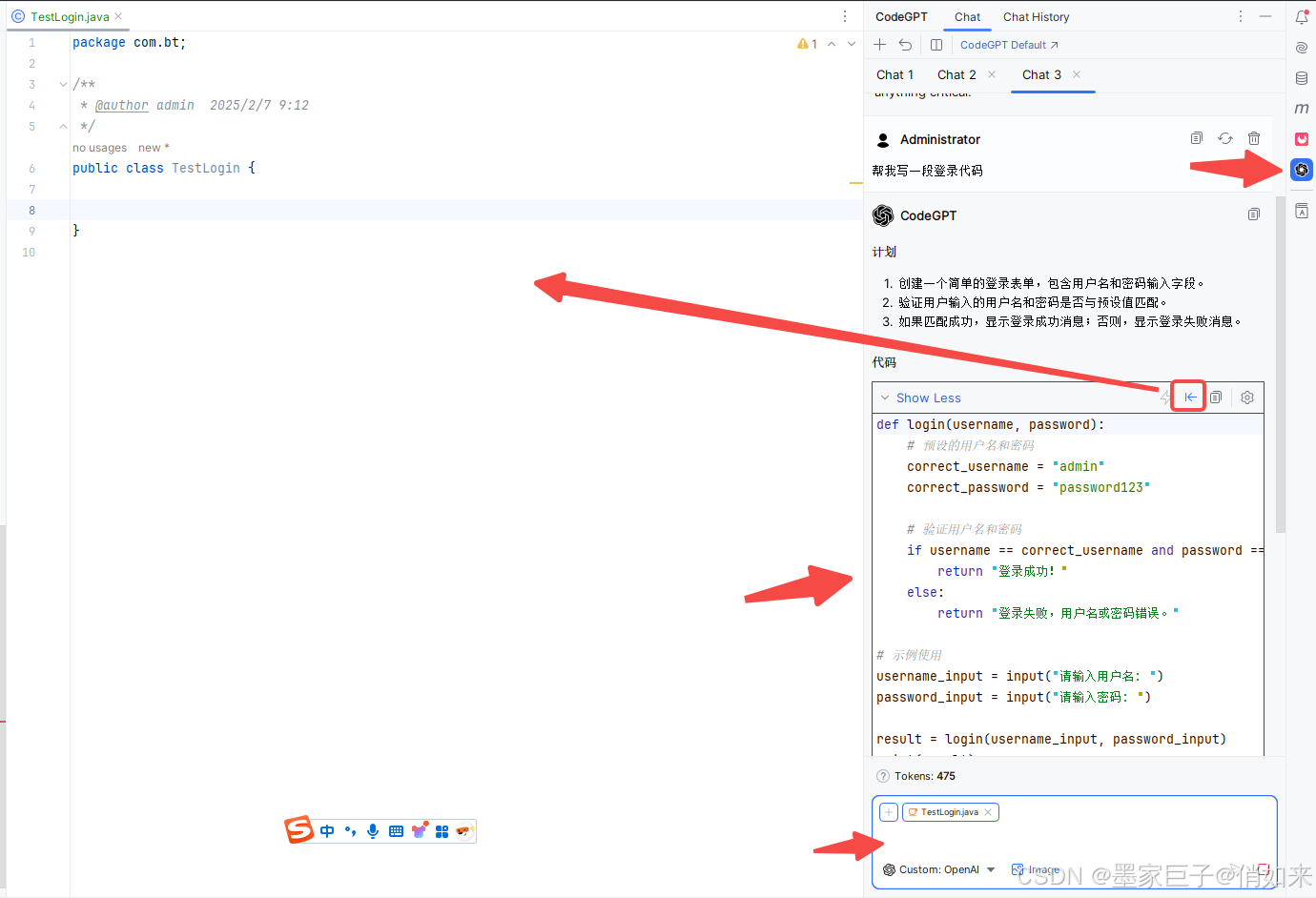
IDEA+DeepSeek让Java开发起飞
1.获取DeepSeek秘钥 登录DeepSeek官网 : https://www.deepseek.com/ 进入API开放平台,第一次需要注册一个账号 进去之后需要创建一个API KEY,然后把APIkey记录保存下来 接着我们获取DeepSeek的API对话接口地址,点击左边的:接口…...

mysql的原理及经验
1. 存储引擎 存储引擎是MySQL的核心组件之一,它负责数据的存储和检索。MySQL支持多种存储引擎,每种引擎都有其独特的特点和适用场景。 InnoDB:这是MySQL的默认存储引擎,支持事务处理(ACID特性)、行级锁定和…...

苹果公司宣布正式开源 Xcode 引擎 Swift Build145
2025 年 2 月 1 日,苹果公司宣布正式开源 Xcode 引擎 Swift Build145。 Swift 是苹果公司于 2014 年推出的一种开源编程语言,用于开发 iOS、iPadOS、macOS、watchOS 和 tvOS 等平台的应用程序。 发展历程 诞生:2014 年,苹果在全球…...

怀旧经典:1200+款红白机游戏合集,Windows版一键畅玩
沉浸在怀旧的海洋中,体验经典红白机游戏的魅力!我们为您精心准备了超过1200款经典游戏的合集,每一款都是时代的印记,每一场都是回忆的旅程。这个合集不仅包含了丰富的游戏资源,还内置了多个Windows版的NES模拟器&…...

《解锁GANs黑科技:打造影视游戏的逼真3D模型》
在游戏与影视制作领域,逼真的3D模型是构建沉浸式虚拟世界的关键要素。从游戏中栩栩如生的角色形象,到影视里震撼人心的宏大场景,高品质3D模型的重要性不言而喻。随着人工智能技术的飞速发展,生成对抗网络(GANs…...

【漫话机器学习系列】083.安斯库姆四重奏(Anscombe‘s Quartet)
安斯库姆四重奏(Anscombes Quartet) 1. 什么是安斯库姆四重奏? 安斯库姆四重奏(Anscombes Quartet)是一组由统计学家弗朗西斯安斯库姆(Francis Anscombe) 在 1973 年 提出的 四组数据集。它们…...

kafka消费端之分区分配策略
文章目录 概述分区分配策略RangeAssignor分配策略RoundRobinAssignor分配策略StickyAssignor自定义分区分配策略 总结 概述 我们知道kafka的topic可以被分成多个分区,消费者在集群模式下消费时一个消费组内的每个消费者实例只能消费到一个分区的消息,那…...

e2studio开发RA2E1(9)----定时器GPT配置输入捕获
e2studio开发RA2E1.9--定时器GPT配置输入捕获 概述视频教学样品申请硬件准备参考程序源码下载选择计时器时钟源UART配置UART属性配置设置e2studio堆栈e2studio的重定向printf设置R_SCI_UART_Open()函数原型回调函数user_uart_callback ()printf输出重定向到串口定时器输入捕获配…...

【Elasticsearch】分桶聚合功能概述
这些聚合功能可以根据它们的作用和应用场景分为几大类,以下是分类后的结果: 1.基础聚合(Basic Aggregations) • Terms(字段聚合) 根据字段值对数据进行分组并统计。 例子:按产品类别统计销…...

开源安全一站式构建!开启企业开源治理新篇章
在如今信息技术日新月异、飞速发展的数字化时代,开源技术如同一股强劲的东风,为企业创新注入了源源不断的活力,然而,正如一枚硬币有正反两面,开源技术的广泛应用亦伴随着不容忽视的挑战。安全风险如影随形,…...

功能架构元模型
功能架构的元模型是对功能架构进行描述和建模的基础框架,它有助于统一不同团队对系统的理解,并为系统的设计和开发提供一致的标准和规范。虽然具体的元模型可能因不同的应用领域和特定需求而有所差异,但一般来说,功能架构的元模型可以涵盖以下几个方面: 组件/模块元模型:…...

Node.js 与 npm 版本兼容性问题详解:如何避免版本冲突
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...