集成学习(二):从理论到实战(附代码)
接上一篇续写《集成学习(一):从理论到实战(附代码)》
五、实用算法
5.1 随机森林
随机森林在数据集的各个子样本上拟合许多决策树分类器,并使用平均来提高预测精度和控制过拟合。每一个分类器拟合了一部分随机样本,同时也拟合一部分随机特征
通过以下两个主要步骤来构建强大的预测模型:
- Bootstrap Sampling:从原始数据集中随机抽取样本(有放回抽样),创建多个不同的子集。
- Random Feature Selection:在每个子集上训练一个决策树时,在每次分裂节点时只考虑一部分特征,而不是所有特征。这样可以增加模型的多样性,并减少过拟合的风险。
最终,对于分类问题,随机森林通常使用多数投票的方式来决定最终类别;对于回归问题,则通常使用平均值的方式来决定最终预测值。
RandomForestClassifier 和 RandomForestRegressor 是基于集成学习方法中的随机森林(Random Forest)算法实现的分类和回归模型。随机森林通过构建多个决策树并将它们的结果结合起来,以提高预测的准确性和控制过拟合。
5.1.1 RandomForestClassifier
RandomForestClassifier 用于分类任务,通过构建多个决策树分类器,并将它们的预测结果进行组合来得出最终的分类决策。
工作原理
- Bootstrap Aggregating (Bagging):对原始数据集进行有放回抽样,生成多个不同的训练子集。
- Random Feature Selection:在每个节点分裂时,只考虑一个随机选择的特征子集,而不是所有特征。
- Majority Voting:每棵树都对输入数据进行分类,最终的分类结果是所有树的分类结果中出现次数最多的类别(即多数投票)。
示例代码
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split# 创建合成数据集
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)# 训练模型
rf_clf.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = rf_clf.predict(X_test)
5.1.2 RandomForestRegressor
RandomForestRegressor 用于回归任务,通过构建多个决策树回归器,并将它们的预测结果进行组合来得出最终的预测值。
工作原理
- Bootstrap Aggregating (Bagging):与分类器类似,通过对原始数据集进行有放回抽样生成多个不同的训练子集。
- Random Feature Selection:在每个节点分裂时,同样只考虑一个随机选择的特征子集。
- Average Prediction:每棵树都对输入数据进行预测,最终的预测结果是对所有树的预测结果取平均值。
示例代码
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split# 创建合成数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义随机森林回归器
rf_reg = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)# 训练模型
rf_reg.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = rf_reg.predict(X_test)
关键参数解释
n_estimators:指定要构建的决策树数量。更多的树通常能带来更好的性能,但也会增加计算成本。max_depth:设置每棵树的最大深度。限制树的深度可以帮助防止过拟合。random_state:控制随机性,确保实验结果的可重复性。
5.1.3 总结
- RandomForestClassifier 和 RandomForestRegressor 都是基于随机森林算法的模型,分别用于解决分类和回归问题。
- 随机森林通过构建大量的决策树,并结合这些树的预测结果来提高模型的稳定性和准确性。
- 在分类任务中,采用多数投票法决定最终类别;在回归任务中,则通过平均各树的预测值得到最终预测结果。
- 随机森林的一个重要特性是其对高维数据的良好适应性以及对噪声数据的鲁棒性,使其成为实际应用中非常流行的机器学习算法之一。
5.2 XGBoost
XGBoost的核心是梯度提升决策树(Gradient Boosting Decision Trees, GBDT),但其在性能优化、正则化等方面做了很多改进,使得它在速度和效果上都优于传统的GBDT实现。以下是XGBoost的一些关键特性:
-
梯度提升:从一个初始预测开始,然后迭代地添加新的树,每棵树都在尝试修正之前所有树的预测误差。具体来说,每棵新树都是根据前一棵树的残差(即预测值与真实值之间的差异)来训练的。
-
正则化:XGBoost引入了正则项到损失函数中,帮助控制模型复杂度,减少过拟合的风险。
-
列采样和行采样:类似于随机森林,XGBoost也支持特征子集(列)采样和样本子集(行)采样,增加了模型的多样性并提高了计算效率。
-
近似树分裂:为了提高处理大规模数据集的能力,XGBoost使用了一种近似算法来寻找最佳分裂点,而不是精确搜索,这大大加快了训练过程。
-
并行处理:尽管每棵树的构建过程本质上是顺序的,XGBoost通过并行化计算每个节点的最佳分裂点来加速训练。
XGBClassifier 和 XGBRegressor 是基于XGBoost(eXtreme Gradient Boosting)算法的实现,专门用于分类和回归任务。XGBoost是一种高效的梯度提升框架,它通过构建一系列决策树并将它们组合起来以形成一个强大的预测模型。
5.2.1 XGBClassifier
XGBClassifier 适用于分类问题。它通过构建一系列决策树,并使用梯度下降的方法来最小化损失函数(如对数损失),从而逐步改善模型的预测能力。
示例代码
from xgboost import XGBClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 创建合成数据集
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义XGB分类器
xgb_clf = XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')# 训练模型
xgb_clf.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = xgb_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print(f"XGB Classifier Accuracy: {accuracy:.4f}")
use_label_encoder=False:避免警告信息,因为从某些版本开始,默认情况下会使用标签编码器转换标签。eval_metric='mlogloss':指定评估指标为多类对数损失。
5.2.2 XGBRegressor
XGBRegressor 适用于回归问题。它的工作方式与XGBClassifier类似,但目标是最小化回归任务中的损失函数(如均方误差)。
示例代码
from xgboost import XGBRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 创建合成数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义XGB回归器
xgb_reg = XGBRegressor()# 训练模型
xgb_reg.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = xgb_reg.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, predictions)
print(f"XGB Regressor MSE: {mse:.4f}")
关键参数解释
n_estimators:要构建的树的数量。更多的树通常可以带来更好的性能,但也可能增加过拟合的风险。max_depth:每棵树的最大深度。限制树的深度可以帮助防止过拟合。learning_rate:每次迭代时对新增加的树的重要性进行缩放的比例。较小的学习率通常需要更多的树来达到同样的效果,但它有助于提高模型的泛化能力。subsample:用于训练每棵树的数据比例。设置小于1.0的值可以减少过拟合。colsample_bytree:用于训练每棵树的特征比例。同样,设置小于1.0的值可以增加模型的多样性,减少过拟合。
5.2.3 总结
- XGBClassifier 和 XGBRegressor 基于XGBoost算法,分别用于解决分类和回归问题。
- XGBoost通过梯度提升方法构建一系列决策树,并通过多种技术如正则化、列采样和行采样等手段来提高模型的稳定性和泛化能力。
- 这些模型因其高效性和良好的性能,在实际应用中非常受欢迎,特别是在处理大型数据集时表现出色。
5.3 LightGBM
由微软维护,特别适合处理大数据集的机器学习算法。
终极推荐:
- 训练速度
- 推理速度
- 处理数据量
- 结果层面
- 综合来看,最优!!!!!!
LightGBM 的核心原理
-
基于梯度的单边采样 (GOSS):在传统的 GBDT 中,每次迭代都会使用全部的数据进行训练。而在 LightGBM 中,GOSS 通过保留具有较大梯度的实例,并对剩余的小梯度实例进行随机抽样来减少数据量。这种方法能够在不严重损害模型精度的情况下大幅减少数据量,从而加快训练速度。
-
互斥特征捆绑 (EFB):许多实际应用中的特征是稀疏的,且某些特征之间很少或几乎不会同时非零(即它们是互斥的)。EFB 技术利用这一点,将这些互斥特征捆绑在一起作为一个新特征,减少了特征维度,进而提高了训练速度和降低了内存消耗。
-
直方图算法:不同于传统的精确分割方法,LightGBM 使用直方图算法来寻找最佳分裂点。这意味着它不是直接计算每个可能分裂点的信息增益,而是将连续的特征值离散化为若干个区间(桶),然后基于这些区间的统计信息来决定分裂点。这种方法不仅加快了分裂点的选择过程,还支持并行处理。
-
叶子生长策略:大多数 GBDT 实现采用深度优先(Depth-wise)的增长策略,而 LightGBM 使用叶子导向(Leaf-wise)的增长策略。这意味着它会优先选择分裂那些能带来最大收益的叶子节点,而不是简单地逐层增长树。这种策略有助于生成更少但更深的树,从而可能达到更高的准确性。
LGBMClassifier 和 LGBMRegressor 是基于 LightGBM(Light Gradient Boosting Machine)框架的分类和回归模型。LightGBM 是一种梯度提升框架,它被设计用于提高传统梯度提升决策树(GBDT)的速度和效率,同时保持高准确率。LightGBM 通过引入一些创新技术,如基于梯度的单边采样(GOSS, Gradient-based One-Side Sampling)和互斥特征捆绑(EFB, Exclusive Feature Bundling),显著提高了计算效率和内存使用效率。
5.3.1 LGBMClassifier
LGBMClassifier 是专门用于解决分类问题的 LightGBM 模型。它通过上述技术构建一系列决策树,并结合这些树的结果来进行最终的分类预测。
示例代码
from lightgbm import LGBMClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 创建合成数据集
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义LGBM分类器
lgbm_clf = LGBMClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)# 训练模型
lgbm_clf.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = lgbm_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print(f"LGBM Classifier Accuracy: {accuracy:.4f}")
5.3.2 LGBMRegressor
LGBMRegressor 是用于回归任务的 LightGBM 模型。其工作方式与 LGBMClassifier 类似,但目标是最小化回归损失函数(如均方误差)。
示例代码
from lightgbm import LGBMRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 创建合成数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义LGBM回归器
lgbm_reg = LGBMRegressor(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)# 训练模型
lgbm_reg.fit(X_train, y_train)# 使用训练好的模型进行预测
predictions = lgbm_reg.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, predictions)
print(f"LGBM Regressor MSE: {mse:.4f}")
关键参数解释
n_estimators:要构建的树的数量。更多的树通常可以带来更好的性能,但也可能增加过拟合的风险。learning_rate:每次迭代时对新增加的树的重要性进行缩放的比例。较小的学习率通常需要更多的树来达到同样的效果,但它有助于提高模型的泛化能力。max_depth:每棵树的最大深度。限制树的深度可以帮助防止过拟合。num_leaves:控制树的复杂度的一个重要参数,指定了每棵树的叶子节点数。适当调整这个参数可以帮助找到平衡点,在不过度拟合的同时获得较好的模型表现。
5.3.3 总结
- LGBMClassifier 和 LGBMRegressor 基于 LightGBM 框架,分别用于解决分类和回归问题。
- LightGBM 通过多种技术创新,如 GOSS、EFB 和直方图算法,显著提高了训练速度和效率,同时保持了高准确率。
- 这些模型因其高效性和良好的性能,在处理大规模数据集时特别有用,并广泛应用于各种机器学习竞赛和实际项目中。
六、实战建议
使用 GridSearchCV 来进行超参数调优,以找到最佳的模型配置。举个例子,使用 XGBoost 的分类器 XGBClassifier 作为基础模型,并通过网格搜索来寻找最优的超参数组合。
# 自动化建模流程示例
from sklearn.model_selection import GridSearchCV# 参数网格
param_grid = {'n_estimators': [100, 200],'max_depth': [3, 5],'learning_rate': [0.1, 0.05]
}# 网格搜索
grid_search = GridSearchCV(estimator=XGBClassifier(),param_grid=param_grid,scoring='accuracy',cv=5,n_jobs=-1
)
# 执行网格搜索:调用 `fit` 方法开始训练模型。
# `GridSearchCV` 会对 `param_grid` 中所有可能的超参数组合进行训练和评估。
# 最终,它会选择在交叉验证中表现最好的一组超参数。
grid_search.fit(X_train, y_train)
# `best_params_` 属性存储了在交叉验证中得分最高的那组超参数。
# 通过打印 `grid_search.best_params_` 可以查看这些最佳参数。
print(f"最佳参数: {grid_search.best_params_}")
代码解释
GridSearchCV 是一个用于自动化超参数调整的强大工具,它通过交叉验证(Cross-Validation)来评估不同超参数设置下的模型性能。
# 参数网格
param_grid = {'n_estimators': [100, 200],'max_depth': [3, 5],'learning_rate': [0.1, 0.05]
}
定义参数网格:这里定义了一个字典 param_grid,其中键是模型的超参数名称,值是一个列表,包含了该超参数可能取的所有值。
'n_estimators':表示要构建的树的数量。在这里尝试了[100, 200]。'max_depth':每棵树的最大深度。在这里尝试了[3, 5]。'learning_rate':每次迭代时对新增加的树的重要性进行缩放的比例。在这里尝试了[0.1, 0.05]。
# 网格搜索
grid_search = GridSearchCV(estimator=XGBClassifier(),param_grid=param_grid,scoring='accuracy',cv=5,n_jobs=-1
)
初始化 GridSearchCV 对象:
estimator=XGBClassifier():指定使用的模型为XGBClassifier。param_grid=param_grid:传入之前定义的参数网格。scoring='accuracy':指定模型评估指标为准确率(适用于分类问题)。对于回归问题,可以使用如'neg_mean_squared_error'等其他评分标准。cv=5:指定使用 5 折交叉验证。这意味着数据集将被分成 5 份,模型会训练 5 次,每次使用不同的 4/5 数据作为训练集,剩余的 1/5 数据作为验证集。n_jobs=-1:利用所有可用的 CPU 核心并行计算,加快搜索速度。
总结:上面这段代码的主要目的是通过网格搜索和交叉验证自动找到 XGBClassifier 模型的最佳超参数组合。这样做有助于提高模型的性能,并避免手动逐一尝试每个超参数组合的繁琐过程。
通过设置不同的参数值范围,GridSearchCV 可以系统地探索所有可能的组合,并基于指定的评分标准(此处为准确率)选择最佳模型配置。这种方法尤其适合于寻找最优超参数设置,特别是在处理复杂或大规模数据集时。
调优策略:
- 优先调节学习率和树数量(n_estimators)
- 控制单棵树复杂度(max_depth, min_child_weight)
- 采样策略(subsample, colsample_bytree)
- 正则化参数(lambda, alpha)
- 早停法防止过拟合
七、结论与推荐
对于结构化数据或表格类数据,集成学习通常是最有效的选择。尽管深度学习在某些领域表现出色,但在处理这类数据时,集成学习往往能提供更好的结果。
- 训练速度:集成学习算法如随机森林、XGBoost和LightGBM在大多数情况下都能快速训练。
- 推理速度:这些算法也具有较快的推理速度,非常适合实时应用。
- 处理数据量:特别是LightGBM,在处理大规模数据集方面表现出色。
- 结果层面:集成学习方法通常能够提供高准确度和鲁棒性的预测结果。
算法选型指南
| 指标 | 随机森林 | XGBoost | LightGBM |
|---|---|---|---|
| 训练速度 | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| 预测速度 | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| 内存消耗 | ★★☆☆☆ | ★★★☆☆ | ★★★★★ |
| 处理类别特征 | 需要编码 | 需要编码 | 原生支持 |
| 可解释性 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| 大数据支持 | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
终极建议:
- 中小数据集:XGBoost(精度优先)
- 大数据集:LightGBM(效率优先)
- 快速原型:随机森林(易用性好)
- 类别特征多:CatBoost
- 需要可解释性:随机森林特征重要性
相关文章:
:从理论到实战(附代码))
集成学习(二):从理论到实战(附代码)
接上一篇续写《集成学习(一):从理论到实战(附代码)》 五、实用算法 5.1 随机森林 随机森林在数据集的各个子样本上拟合许多决策树分类器,并使用平均来提高预测精度和控制过拟合。每一个分类器拟合了一部分随机样本,…...

ASP.NET Core WebSocket、SignalR
目录 WebSocket SignalR SignalR的基本使用 WebSocket WebSocket基于TCP协议,支持二进制通信,双工通信。性能和并发能力更强。WebSocket独立于HTTP协议,不过我们一般仍然把WebSocket服务器端部署到Web服务器上,因为可以借助HT…...

【学术投稿】第五届计算机网络安全与软件工程(CNSSE 2025)
重要信息 官网:www.cnsse.org 时间:2025年2月21-23日 地点:中国-青岛 简介 第五届计算机网络安全与软件工程(CNSSE 2025)将于2025年2月21-23日在中国-青岛举行。CNSSE 2025专注于计算机网络安全、软件工程、信号处…...

26~31.ppt
目录 26.北京主要的景点 题目 解析 27.创新产品展示及说明会 题目 解析 28.《小企业会计准则》 题目 解析 29.学习型社会的学习理念 题目 解析 30.小王-产品展示信息 题目 解析 31.小王-办公理念-信息工作者的每一天 题目 解析 26.北京主要的景点…...

缓存实战:Redis 与本地缓存
引言 在现代互联网应用中,缓存是提升系统性能和用户体验的关键技术之一。通过将频繁访问的数据存储在快速访问的存储介质中,可以显著减少对数据库的直接访问压力,从而提高系统的响应速度和吞吐量。 本文将从实战的角度出发,详细…...

网络工程师 (28)IEEE802标准
前言 IEEE 802标准是由电气和电子工程师协会(IEEE)制定的一组局域网(LAN)和城域网(MAN)标准,定义了网络中的物理层和数据链路层。 一、起源与背景 IEEE 802又称为LMSC(LAN/MAN Stand…...

背包问题1
核心: // f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值是多少 //res maxx(f[n][]0-v] //f[i][j]: //1 不选第i个物品 f[i][j] f[i-1][j] //2 选第i个物品 f[i][j] f[i-1][j-v[i]] w[i]...

Spring 中的设计模式详解
控制反转(IoC)和依赖注入(DI) IoC(Inversion of Control,控制反转) 是 Spring 中一个非常非常重要的概念,它不是什么技术,而是一种解耦的设计思想。IoC 的主要目的是借助于“第三方”(Spring 中的 IoC 容器) 实现具有依赖关系的对象之间的解耦(IOC 容器…...

OpenAI 实战进阶教程 - 第十一节 : 文档搜索与摘要生成
读者群体:面向哪类从业人员? 软件工程师 / 后端开发人员:需要在系统中集成对文档的搜索和问答功能。技术支持 / 运维人员:需要快速查询、提炼大批量文档以提供高效支持。项目经理 / 产品经理:想要更好地理解并利用已有…...

scss混合优化媒体查询书写
采用scss的混合和继承优化css的媒体查询代码书写 原写法 .header {width: 100%; } media (min-width: 320px) and (max-width: 480px) {.header {height: 50px;} } media (min-width: 481px) and (max-width: 768px) {.header {height: 60px;} } media (min-width: 769px) an…...

人类的算计与机器的算计
近日,国外一视频网站博主通过设定,使DeepSeek和ChatGPT开展了一场国际象棋对弈。前十分钟双方在正常对弈,互有输赢,且ChatGPT逐渐占优。随后DeepSeek突然以对话方式告诉ChatGPT,国际象棋官方刚刚更新了比赛规则&#x…...

android的ViewBinding的使用
参考: 安卓开发中的ViewBinding使用...

rockmq配置出现的问题
环境注意事项 java要配置javahome-- java8,并且rockmq配置 根目录 解决方法: https://blog.csdn.net/weixin_46661658/article/details/133753627 如果执行第二步报错jar的路径 命令: start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTop…...

7 使用 Pydantic 验证 FastAPI 的请求数据
FastAPI 是一个快速、现代的 Web 框架,它提供了自动生成 OpenAPI 文档的功能,支持 Pydantic 模型进行请求和响应数据的验证。Pydantic 提供了强大的数据验证功能,可以帮助你确保请求的有效性,自动进行数据转换,并生成详…...

U3D支持webgpu阅读
https://docs.unity3d.com/6000.1/Documentation/Manual/WebGPU-features.html 这里看到已经该有的差不多都有了 WOW VFX更是好东西 https://unity.com/cn/features/visual-effect-graph 这玩意儿化简了纯手搓一个特效的流程 如果按原理说就是compute shader刷position&#…...

【10.10】队列-设计自助结算系统
一、题目 请设计一个自助结账系统,该系统需要通过一个队列来模拟顾客通过购物车的结算过程,需要实现的功能有: get_max():获取结算商品中的最高价格,如果队列为空,则返回 -1add(value):将价格为…...

Mac安装配置使用nginx的一系列问题
brew安装nginx https://juejin.cn/post/6986190222241464350 使用brew安装nginx,如下命令所示: brew install nginx 如下图所示: 2.查看nginx的配置信息,如下命令: brew info nginxFrom:xxx 这样的,是n…...
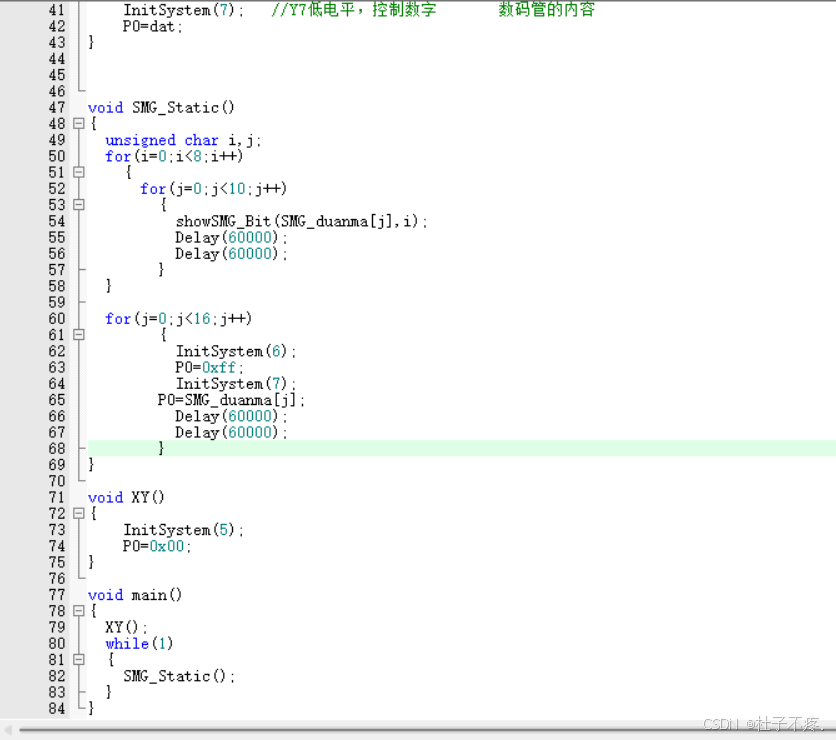
在CT107D单片机综合训练平台上,8个数码管分别单独依次显示0~9的值,然后所有数码管一起同时显示0~F的值,如此往复。
题目:在CT107D单片机综合训练平台上,8个数码管分别单独依次显示0~9的值,然后所有数码管一起同时显示0~F的值,如此往复。 延时函数分析LED首先实现8个数码管单独依次显示0~9的数字所有数码管一起同时显示0~F的值,如此往…...

00_Machine Vision_基础介绍
基础概念 由于计算机只能处理离散的数据,所以需要将连续的图片转化为离散的数据。主要包含:空间离散以及灰度值离散 空间离散:将图片的像素点离散化,即将图片的像素点转化为一个个的小方块,即为图片的分辨率。分辨率…...

组件库选择:ElementUI 还是 Ant Design
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

【Kubernetes的SpringCloud最佳实践】有Service是否还需要Eureka?
在 Kubernetes 中部署 Spring Cloud 微服务时,是否还需要 Eureka 取决于具体场景和架构设计。以下是详细的实践建议和结论: 1. Kubernetes 原生服务发现 vs Eureka Kubernetes 自身提供了完善的服务发现机制(通过 Service 资源)&…...
面试题及参考答案)
顺丰数据分析(数据挖掘)面试题及参考答案
你觉得数据分析人员必备的技能有哪些? 数据分析人员需具备多方面技能,以应对复杂的数据处理与解读工作。 数据处理能力:这是基础且关键的技能。数据常以杂乱、不完整的形式存在,需通过清洗,去除重复、错误及缺失值数据,确保数据质量。例如,在电商销售数据中,可能存在价…...

从运输到植保:DeepSeek大模型探索无人机智能作业技术详解
DeepSeek,作为一家专注于深度学习与人工智能技术研究的企业,近年来在AI领域取得了显著成果,尤其在无人机智能作业技术方面展现了其大模型的强大能力。以下是从运输到植保领域,DeepSeek大模型探索无人机智能作业技术的详解…...

超越LSTM!TCN模型如何精准预测股市波动(附代码)
作者:老余捞鱼 原创不易,转载请标明出处及原作者。 写在前面的话:最近我用TCN时间卷积网络预测了标普500指数(SPX)的每日回报率,发现效果远超传统方法。TCN通过因果卷积和膨胀卷积捕捉时间序列的长期依赖关…...

[每周一更]-(第133期):Go中MapReduce架构思想的使用场景
文章目录 **MapReduce 工作流程**Go 中使用 MapReduce 的实现方式:**Go MapReduce 的特点****哪些场景适合使用 MapReduce?**使用场景1. 数据聚合2. 数据过滤3. 数据排序4. 数据转换5. 数据去重6. 数据分组7. 数据统计8.**统计文本中单词出现次数****代码…...

QML初识
目录 一、关于QML 二、布局定位和锚点 1.布局定位 2.锚点详解 三、数据绑定 1.基本概念 2.绑定方法 3.数据模型绑定 四、附加属性及信号 1.附加属性 2.信号 一、关于QML QML是Qt框架中的一种声明式编程语言,用于描述用户界面的外观和行为;Qu…...

查询已经运行的 Docker 容器启动命令
一、导语 使用 get_command_4_run_container 查询 docker 容器的启动命令 获取镜像 docker pull cucker/get_command_4_run_container 查看容器命令 docker run --rm -v /var/run/docker.sock:/var/run/docker.sock cucker/get_command_4_run_container 容器id或容器名 …...

项目管理中的13个数据分析思维
01 信度与效度思维 信度:是指一个数据或指标自身的可靠程度,包括准确性和稳定性。 效度:是指一个数据或指标的生成,需贴合它所要衡量的事物,即指标的变化能够代表该事物的变化。 在项目管理中,信度和效度的…...

快速查看ROS节点的CPU和内存占用情况
他们可能是在排查资源泄漏的问题,所以需要监控节点的CPU和内存使用情况。可能他们遇到了节点占用过多资源导致服务器崩溃的情况,需要快速定位问题节点。现有的Linux命令方面,top和htop可以实时查看进程资源使用,但用户想要的是针对ROS节点的,可能需要更针对性的工具。ROS本…...

Centos Stream 10 根目录下的文件夹结构
/ ├── bin -> usr/bin ├── boot ├── dev ├── etc ├── home ├── lib -> usr/lib ├── lib64 -> usr/lib64 ├── lostfound ├── media ├── mnt ├── opt ├── proc ├── root ├── run ├── sbin -> usr/sbin ├── srv ├─…...