kafka生产端之架构及工作原理
文章目录
- 整体架构
- 元数据更新
整体架构
消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用,那么在此之后又会发生什么呢?下面我们来看一下生产者客户端的整体架构,如图所示。

整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator缓存的大小可以通过生产者客户端参数buffer.memory配置,默认值为33554432B,即32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer的send0方法调用要么被阻塞,要么抛出异常,这个取决于参数max.b1ock.ms的配置,此参数的默认值为60000,即60秒。
主线程中发送过来的消息都会被追加到RecordAccumulator的某个双端队列(Deque)中,在RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque。消息写入缓存时,追加到双端队列的尾部;Sender读取消息时,从双端队列的头部读取。注意ProducerBatch不是ProducerRecord,ProducerBatch中可以包含一至多个ProducerRecord。通俗地说,ProducerRecord是生产者中创建的消息,而ProducerBatch是指一个消息批次,ProducerRecord会被包含在ProducerBatch中,这样可以使字节的使用更加紧漆。与此同时,将较小的ProducerRecord拼漆成一个较大的ProducerBatch,也可以减少网络请求的次数以提升整体的吞吐量。ProducerBatch和消息的具体格式有关。如果生产者客户端需要向很多分区发送消息,则可以将buffer.memory参数适当调大以增加整体的吞吐量。
消息在网络上都是以字节(Byte)的形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。在Kafka生产者客户端中,通过java.io.ByteBuffer实现消息内存的创建和释放。不过频繁的创建和释放是比较耗费资源的,在RecordAccumulator的内部还有一个BufferPool,它主要用来实现ByteBuffer的复用,以实现缓存的高效利用。不过BufferPool只针对特定大小的ByteBuffer进行管理,而其他大小的ByteBuffer不会缓存进BufferPool中,这个特定的大小由batch.size参数来指定,默认值为16384B,即16KB。我们可以适当地调大batch.size参数以便多缓存一些消息。
ProducerBatch的大小和batch.size参数也有着密切的关系。当一条消息(ProducerRecord)流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个ProducerBatch(如果没有则新建),查看ProducerBatch中是否还可以写入这个ProducerRecord,如果可以则写入,如果不可以则需要创建一个新的ProducerBatch。在新建ProducerBatch时评估这条消息的大小是否超过batch.size参数的大小,如果不超过,那么就以batch.size参数的大小来创建ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool的管理来进行复用;如果超过,那么就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
Sender从RecordAccumulator中获取缓存的消息之后,会进一步将原本<分区,Deque>的保存形式转变成<Node,ListProducerBatch>的形式,其中Node表示Kafka集群的broker节点。对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的broker节点发送消息,而并不关心消息属于哪一个分区;而对于KafkaProducer的应用逻辑而言,我们只关注向哪个分区中发送哪些消息,所以在这单需要做一个应用逻辑层面到网络IO层面的转换。
在转换成<Node,ListProducerBatch>>的形式之后,Sender还会进一步封装成<Node,Request>的形式,这样就可以将Request请求发往各个Node了,这里的Request是指Kafka的各种协议请求,对于消息发送而言就是指具体的ProduceRequest。
请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为Map<NodeId,Deque>,它的主要作用是缓存了已经发出去但还没有收到响应的请求(NodeId是一个String类型,表示节点的id编号)。与此同时,InFlightRequests还提供了许多管理类的方法,并且通过配置参数还可以限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数。这个配置参数为max.in.flight.requests.per.connection,默认值为5,即每个连接最多只能缓存5个未响应的请求,超过该数值之后就不能再向这个连接发送更多的请求了,除非有缓存的请求收到了响应(Response)。通过比较Deque的size与这个参数的大小来判断对应的Node中是否已经堆积了很多未响应的消息,如果真是如此,那么说明这个Node节点负载较大或网络连接有问题,再继续向其发送请求会增大请求超时的可能。
元数据更新
上面提及的InFlightRequests还可以获得leastLoadedNode,即所有Node中负载最小的那一个。这里的负载最小是通过每个Node在InFlightRequests中还未确认的请求决定的,未确认的请求越多则认为负载越大。对于图中的InFlightRequests来说,图中展示了三个节点Node0、Node1和Node2,很明显Node1的负载最小。也就是说,Node1为当前的leastLoadedNodec选择leastLoadedNode发送请求可以使它能够尽快发出,避免因网络拥塞等异常而影响整体的进度。leastLoadedNode的概念可以用于多个应用场合,比如元数据请求、消费者组播协议的交互。

我们只知道主题的名称,对于其他一些必要的信息却一无所知。KafkaProducer要将此消息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定)目标分区,之后KafkaProducer需要知道目标分区的leader副本所在的broker节点的地址、端口等信息才能建立连接,最终才能将消息发送到Kafka,在这一过程中所需要的信息都属于元数据信息。
在上面的讲解中我们了解了bootstrap.servers参数只需要配置部分broker节点的地址即可,不需要配置所有broker节点的地址,因为客户端可以自己发现其他broker节点的地址,这一过程也属于元数据相关的更新操作。与此同时,分区数量及leader副本的分布都会动态地变化,客户端也需要动态地捕捉这些变化。
元数据是指Kafka集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在哪个节点上,follower副本分配在哪些节点上,哪些副本在AR、ISR等集合中,集群中有哪些节点,控制器节点又是哪一个等信息。
当客户端中没有需要使用的元数据信息时,比如没有指定的主题信息,或者超过metadata.max.age.ms时间没有更新元数据都会引起元数据的更新操作。客户端参数metadata.max.age.ms的默认值为300000,即5分钟。元数据的更新操作是在客户端内部进行的,对客户端的外部使用者不可见。当需要更新元数据时,会先挑选出leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具体的元数据信息。这个更新操作是由Sender线程发起的,在创建完MetadataRequest之后同样会存入InFlightRequests,之后的步骤就和发送消息时的类似。元数据虽然由Sender线程负责更新,但是主线程也需要读取这些信息,这里的数据同步通过synchronized和final关键字来保障。
相关文章:
kafka生产端之架构及工作原理
文章目录 整体架构元数据更新 整体架构 消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用,那么在此之后又会…...

在 Windows 上使用 ZIP 包安装 MySQL 的详细步骤
以下是使用官方 ZIP 包在 Windows 上安装 MySQL 的详细步骤,确保能通过 mysql -uroot -p 成功连接。 步骤 1:下载 MySQL ZIP 包 访问 MySQL 官方下载页面: https://dev.mysql.com/downloads/mysql/选择 Windows (x86, 64-bit), ZIP Archive&…...

【web自动化】指定chromedriver以及chrome路径
selenium自动化,指定chromedriver,以及chrome路径 对应这篇文章,可以点击查看,详情 from selenium import webdriverdef get_driver():# 获取配置对象option webdriver.ChromeOptions()option.add_experimental_option("de…...

记录 | WPF创建和基本的页面布局
目录 前言一、创建新项目注意注意点1注意点2 解决方案名称和项目名称 二、布局2.1 Grid2.1.1 RowDefinitions 行分割2.1.2 Row & Column 行列定位区分 2.1.3 ColumnDefinitions 列分割 2.2 StackPanel2.2.1 Orientation 修改方向 三、模板水平布局【Grid中套StackPanel】中…...

mysql 存储过程和自定义函数 详解
首先创建存储过程或者自定义函数时,都要使用use database 切换到目标数据库,因为存储过程和自定义函数都是属于某个数据库的。 存储过程是一种预编译的 SQL 代码集合,封装在数据库对象中。以下是一些常见的存储过程的关键字: 存…...

Maven 中常用的 scope 类型及其解析
在 Maven 中,scope 属性用于指定依赖项的可见性及其在构建生命周期中的用途。不同的 scope 类型能够影响依赖项的编译和运行阶段。以下是 Maven 中常用的 scope 类型及其解析: compile(默认值): 这是默认的作用域。如果…...

SpringCloud - Nacos注册/配置中心
前言 该博客为Nacos学习笔记,主要目的是为了帮助后期快速复习使用 学习视频:7小快速通关SpringCloud 辅助文档:SpringCloud快速通关 源码地址:cloud-demo 一、简介 Nacos官网:https://nacos.io/docs/next/quickstar…...

C++ 继承(1)
1.继承概念 我们平时有时候在写多个有内容重复的类的时候会很麻烦 比如我要写Student Teacher Staff 这三个类 里面都要包含 sex name age成员变量 唯一不同的可能有一个成员变量 但是这三个成员变量我要写三遍 太麻烦了 有没有好的方式呢? 有的 就是继承…...

【C语言】传值调用与传址调用详解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯传值调用1. 什么是传值调用?2. 示例代码:传值调用失败的情况执行结果: 3. 为什么传值调用无法修改外部变量? Ǵ…...

蓝桥杯C语言组:图论问题
蓝桥杯C语言组图论问题研究 摘要 图论是计算机科学中的一个重要分支,在蓝桥杯C语言组竞赛中,图论问题频繁出现,对参赛选手的算法设计和编程能力提出了较高要求。本文系统地介绍了图论的基本概念、常见算法及其在蓝桥杯C语言组中的应用&#…...

windows通过网络向Ubuntu发送文件/目录
由于最近要使用树莓派进行一些代码练习,但是好多东西都在windows里或虚拟机上,就想将文件传输到树莓派上,但试了发现u盘不能简单传送,就在网络上找到了通过windows 的scp命令传送 前提是树莓派先开启ssh服务,且Window…...

Unity抖音云启动测试:如何用cmd命令行启动exe
相关资料:弹幕云启动(原“玩法云启动能力”)_直播小玩法_抖音开放平台 1,操作方法 在做云启动的时候,接完发现需要命令行模拟云环境测试启动,所以研究了下。 首先进入cmd命令,CD进入对应包的文件…...
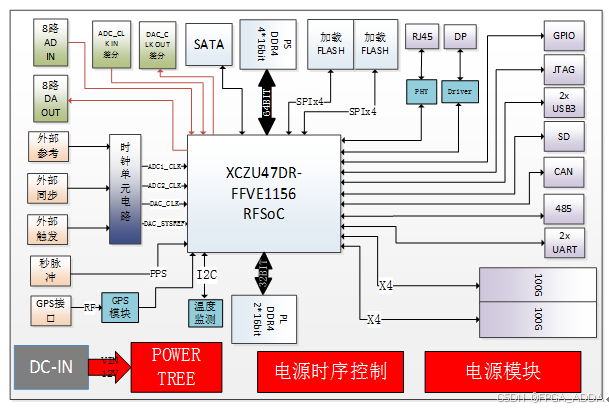
ZU47DR 100G光纤 高性能板卡
简介 2347DR是一款最大可提供8路ADC接收和8路DAC发射通道的高性能板卡。板卡选用高性价比的Xilinx的Zynq UltraScale RFSoC系列中XCZU47DR-FFVE1156作为处理芯片(管脚可以兼容XCZU48DR-FFVE1156,主要差别在有无FEC(信道纠错编解码࿰…...

【算法】动态规划专题⑥ —— 完全背包问题 python
目录 前置知识进入正题模板 前置知识 【算法】动态规划专题⑤ —— 0-1背包问题 滚动数组优化 完全背包问题是动态规划中的一种经典问题,它与0-1背包问题相似,但有一个关键的区别:在完全背包问题中,每种物品都有无限的数量可用。…...

MySQL——表操作及查询
一.表操作 MySQL的操作中,一些专用的词无论是大写还是小写都是可以通过的。 1.插入数据 INSERT [INTO] table_name (列名称…)VALUES (列数据…), (列数据…); "[]"表示可有可无,插入时,如果不指定要插入的列,则表示默…...

SAP-ABAP:ROLLBACK WORK使用详解
在SAP ABAP 中,ROLLBACK WORK 语句用于回滚当前事务(LUW,Logical Unit of Work),撤销自上次提交或回滚以来的所有数据库更改。它通常与 COMMIT WORK 配合使用,确保数据一致性。 关键点: 回滚作…...

C#中深度解析BinaryFormatter序列化生成的二进制文件
C#中深度解析BinaryFormatter序列化生成的二进制文件 BinaryFormatter序列化时,对象必须有 可序列化特性[Serializable] 一.新建窗体测试程序BinaryDeepAnalysisDemo,将默认的Form1重命名为FormBinaryDeepAnalysis 二.新建测试类Test Test.cs源程序如下: using System; us…...

Git提交错误解决:missing Change-Id in message footer
问题现象: 提交的commit中没有插入change id导致push代码失败。 问题解决: 针对该错误,Git已经给出了解决方案: 1、to automatically insert a Change-Id, install the hook: gitdir$(git rev-parse --git-dir); scp -p -P 2…...

51单片机之引脚图(详解)
8051单片机引脚分类与功能笔记 1. 电源引脚 VCC(第40脚):接入5V电源,为单片机提供工作电压。GND(第20脚):接地端,确保电路的电位参考点。 2.时钟引脚 XTAL1(第19脚&a…...

jupyterLab插件开发
jupyter lab安装、配置: jupyter lab安装、配置教程_容器里装jupyterlab-CSDN博客 『Linux笔记』服务器搭建神器JupyterLab_linux_布衣小张-腾讯云开发者社区 Jupyter Lab | 安装、配置、插件推荐、多用户使用教程-腾讯云开发者社区-腾讯云 jupyterLab插件开发教…...

配置#include “nlohmann/json.hpp“,用于处理json文件
#include “nlohmann/json.hpp” // 需要安装 nlohmann/json.hpp 头文件 using json = nlohmann::json; 下载链接:https://github.com/nlohmann/json/tree/develop 1.下载并解压:首先,需要从nlohmann/json的GitHub仓库下载源代码,并解压得到的文件。 地址: nlohmann/json…...

MATLAB | 基于Theil-Sen斜率和Mann-Kendall检验的栅格数据趋势分析
最近看到一些博主分享关于 SenMK 检验的代码,对于新手来说可能有点复杂。我们编写了一段 MATLAB 代码,能够一次性解决这些问题,简化操作流程。我们还准备了几个关于趋势检验的空间分布图,供大家参考。 一、Sens Slope和Mann-Kenda…...

python连点器
要实现一个用于抖音点赞的鼠标连点工具,可以通过编程或现有软件实现。以下是两种常见方法(但请注意:频繁自动化操作可能违反平台规则,需谨慎使用): 方法 1:使用现成工具(如 AutoClic…...

C#程式状态机及其Godot实践
前言 今天是周日,马上就要迎来新的一周了,前几周都没干什么事,为了减缓偷懒症状,立个Flag从今往后每周至少更新两次文章。内容虽然无法保证优质,但重在坚持,全当写周记了。希望不要三分钟热度吧。 今天记录…...

Windows 系统下使用 Ollama 离线部署 DeepSeek - R1 模型指南
引言 随着人工智能技术的飞速发展,各类大语言模型层出不穷。DeepSeek - R1 凭借其出色的语言理解和生成能力,受到了广泛关注。而 Ollama 作为一款便捷的模型管理和部署工具,能够帮助我们轻松地在本地环境中部署和使用模型。本文将详细介绍如…...

Docker、Ollama、Dify 及 DeepSeek 安装配置与搭建企业级本地私有化知识库实践
在现代企业中,管理和快速访问知识库是提升工作效率、促进创新的关键。为了满足这些需求,企业越来越倾向于构建本地私有化的知识库系统,这样可以更好地保护企业数据的安全性和隐私性。本文将介绍如何利用 **Docker**、**Ollama**、**Dify** 和…...
【漫话机器学习系列】087.常见的神经网络最优化算法(Common Optimizers Of Neural Nets)
常见的神经网络优化算法 1. 引言 在深度学习中,优化算法(Optimizers)用于更新神经网络的权重,以最小化损失函数(Loss Function)。一个高效的优化算法可以加速训练过程,并提高模型的性能和稳定…...

react-native fetch在具有http远程服务器后端的Android设备上抛出“Network request failed“错误
问题描述: 在具有http远程服务器后端的Android设备上,使用react-native fetch时抛出"Network request failed"错误。 回答: "Network request failed"错误通常表示在进行网络请求时出现了问题。可能的原因包括网络连接…...

【JVM详解四】执行引擎
一、概述 Java程序运行时,JVM会加载.class字节码文件,但是字节码并不能直接运行在操作系统之上,而JVM中的执行引擎就是负责将字节码转化为对应平台的机器码让CPU运行的组件。 执行引擎是JVM核心的组成部分之一。可以把JVM架构分成三部分&am…...

route 与 router 之间的差别
简述: router:主要用于处理一些动作, route:主要获得或处理一些数据,比如地址、参数等 例: videoInfo1.vue: <template><div class"video-info"><h3>二级组件…...