Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。
本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。
1. Excel单元格批量填充
import pandas as pd # 批量填充指定列的单元格
def fill_column(file_path, column_name, value): df = pd.read_excel(file_path) df[column_name] = value # 将指定列的所有单元格填充为value df.to_excel(file_path, index=False) fill_column('example.xlsx', '备注', '已处理')
print("备注列已成功填充!")
解释
此脚本将example.xlsx中的“备注”列全部填充为“已处理”。对于普通用户来说,处理大量数据时常需要对某一列进行统一标记,这个功能就显得尤为重要。
2. 设置行高与列宽
from openpyxl import load_workbook # 设置Excel的行高与列宽
def set_row_column_size(file_path): wb = load_workbook(file_path) ws = wb.active # 设置第一行行高、第一列列宽 ws.row_dimensions[1].height = 30 # 设置行高 ws.column_dimensions['A'].width = 20 # 设置列宽 wb.save(file_path) set_row_column_size('example.xlsx')
print("行高和列宽设置成功!")
解释
这个脚本为Excel文件设置了第一行的行高和第一列的列宽。适当调整行高和列宽可以提高表格的可读性,尤其是在内容较多或较复杂时,使用此功能可以使报告更加美观易读。
3. 根据条件删除行
# 根据条件删除Excel中的行
def delete_rows_based_on_condition(file_path, column_name, condition): df = pd.read_excel(file_path) df = df[df[column_name] != condition] # 删除满足条件的行 df.to_excel(file_path, index=False) delete_rows_based_on_condition('example.xlsx', '状态', '无效')
print("符合条件的行已删除!")
解释
该脚本从Excel中删除“状态”列中值为“无效”的行。这种操作在数据清理过程中非常常见,有助于减少数据集中的噪声,提高数据分析的准确性。
4. 创建新的Excel工作表
# 在现有Excel文件中创建新的工作表
def create_new_sheet(file_path, sheet_name): wb = load_workbook(file_path) wb.create_sheet(title=sheet_name) # 创建新的工作表 wb.save(file_path) create_new_sheet('example.xlsx', '新工作表')
print("新工作表创建成功!")
解释
该脚本在已有的Excel文件中创建一个新的工作表。这对于组织数据,分开不同任务或项目的数据非常有用,保持文件结构的清晰。
5. 导入CSV文件到Excel
# 将CSV文件导入到Excel工作表
def import_csv_to_excel(csv_file, excel_file): df = pd.read_csv(csv_file) df.to_excel(excel_file, index=False) import_csv_to_excel('data.csv', 'imported_data.xlsx')
print("CSV文件成功导入到Excel!")
解释
这个脚本将CSV文件导入到Excel中。很多时候,数据是以CSV格式提供的,通过该脚本可以方便地将其转换为Excel格式,便于后续分析和处理。
6. 数据透视表生成
# 生成数据透视表并保存到新的Excel文件
def generate_pivot_table(file_path, index_column, values_column, output_file): df = pd.read_excel(file_path) pivot_table = df.pivot_table(index=index_column, values=values_column, aggfunc='sum') # 汇总 pivot_table.to_excel(output_file) generate_pivot_table('sales_data.xlsx', '地区', '销售额', 'pivot_output.xlsx')
print("透视表生成成功!")
解释
该脚本根据给定的“地区”和“销售额”列生成汇总透视表,并保存到新文件中。在进行业务分析时,透视表能快速展示不同维度下的数据总结。
7. 格式化Excel
from openpyxl.styles import Font, Color # 设置Excel单元格字体样式
def format_cells(file_path): wb = load_workbook(file_path) ws = wb.active for cell in ws['A']: # 遍历A列 cell.font = Font(bold=True, color="FF0000") # 设置字体加粗和红色 wb.save(file_path) format_cells('example.xlsx')
print("单元格格式化成功!")
解释
该脚本将example.xlsx中的A列字体设置为加粗和红色。这种格式化通常用于强调特定数据,使报告更具视觉吸引力。
8. 分析并输出描述性统计
# 输出描述性统计到Excel
def descriptive_statistics(file_path, output_file): df = pd.read_excel(file_path) stats = df.describe() # 计算描述性统计 stats.to_excel(output_file) descriptive_statistics('example.xlsx', 'statistics_output.xlsx')
print("描述性统计输出成功!")
解释
该脚本计算Excel文件的描述性统计信息(如均值、标准差等),并将结果保存到新的Excel文件中。这对于了解数据的基本特征非常重要,尤其在数据分析前期阶段。
9. 批量修改Excel文件名称
import os # 批量重命名指定目录下的Excel文件
def rename_excel_files(directory, prefix): for filename in os.listdir(directory): if filename.endswith('.xlsx'): new_name = f"{prefix}_{filename}" os.rename(os.path.join(directory, filename), os.path.join(directory, new_name)) print(f"已将 {filename} 重命名为 {new_name}") rename_excel_files('/path/to/excel/files', '2024')
解释
该脚本批量重命名指定目录中的所有Excel文件,在每个文件名前面添加一个前缀。对于需要处理大量Excel文件的用户来说,这种批量操作非常便利,比如根据年份或项目为文件命名,以便于管理和归档。
10. 自动发送包含Excel数据的电子邮件
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
from email.mime.text import MIMEText # 自动发送带有Excel附件的电子邮件
def send_email(to_address, subject, body, excel_file): from_address = "your_email@example.com" password = "your_password" msg = MIMEMultipart() msg['From'] = from_address msg['To'] = to_address msg['Subject'] = subject # 添加正文 msg.attach(MIMEText(body, 'plain')) # 添加Excel附件 with open(excel_file, "rb") as attachment: part = MIMEApplication(attachment.read(), Name=os.path.basename(excel_file)) part['Content-Disposition'] = f'attachment; filename="{os.path.basename(excel_file)}"' msg.attach(part) # 发送邮件 with smtplib.SMTP('smtp.example.com', 587) as server: server.starttls() server.login(from_address, password) server.send_message(msg) send_email('recipient@example.com', 'Monthly Report', 'Please find attached the monthly report.', 'report.xlsx')
print("邮件发送成功!")
解释
此脚本使用SMTP协议自动发送一封电子邮件,其中附带了一个Excel文件。这个功能在工作中尤其有用,比如每月定期发送财务报表或业绩报告给相关人员。通过自动化邮件发送,可以节省时间并减少人为错误。
11. 合并多个Excel文件
import pandas as pd
import osdef merge_excel_files(folder_path, output_file):all_data = pd.DataFrame()for filename in os.listdir(folder_path):if filename.endswith('.xlsx'):file_path = os.path.join(folder_path, filename)df = pd.read_excel(file_path)all_data = pd.concat([all_data, df], ignore_index=True)all_data.to_excel(output_file, index=False)merge_excel_files('your_folder_path', 'merged_file.xlsx')
print("多个Excel文件合并成功!")
解释
该脚本将指定文件夹下的所有Excel文件合并成一个文件。在处理分散在多个文件中的数据时,这个功能可以将数据整合在一起,方便后续的统一分析。
12. 拆分Excel文件
import pandas as pddef split_excel_file(file_path, column_name, output_folder):df = pd.read_excel(file_path)unique_values = df[column_name].unique()for value in unique_values:sub_df = df[df[column_name] == value]output_file = os.path.join(output_folder, f'{value}.xlsx')sub_df.to_excel(output_file, index=False)split_excel_file('example.xlsx', '部门', 'output_folder')
print("Excel文件拆分成功!")
解释
此脚本根据指定列的唯一值将Excel文件拆分成多个文件。例如,按照“部门”列将数据拆分成不同部门对应的文件,便于各部门独立查看和处理自己的数据。
13. 替换单元格内容
import pandas as pddef replace_cell_content(file_path, column_name, old_value, new_value):df = pd.read_excel(file_path)df[column_name] = df[column_name].replace(old_value, new_value)df.to_excel(file_path, index=False)replace_cell_content('example.xlsx', '产品名称', '旧产品', '新产品')
print("单元格内容替换成功!")
解释
该脚本将指定列中的特定内容替换为新的内容。在数据修正或更新时,这个功能可以快速修改数据中的错误或过时信息。
14. 对数据进行排序
import pandas as pddef sort_excel_data(file_path, column_name, ascending=True):df = pd.read_excel(file_path)df = df.sort_values(by=column_name, ascending=ascending)df.to_excel(file_path, index=False)sort_excel_data('example.xlsx', '销售额', ascending=False)
print("数据排序成功!")
解释
这个脚本的主要功能是对 Excel 文件中的数据根据指定列进行排序操作,并且可以选择升序或降序排列,最后将排序后的数据保存回原 Excel 文件。排序操作在数据处理和分析中非常常见,例如按照销售额对销售数据进行降序排序,能快速找出销售额高的记录。
15. 统计特定列的唯一值数量
import pandas as pddef count_unique_values(file_path, column_name):df = pd.read_excel(file_path)unique_count = df[column_name].nunique()print(f"{column_name}列的唯一值数量为: {unique_count}")count_unique_values('example.xlsx', '客户编号')
解释
该脚本用于统计Excel文件中指定列的唯一值数量。在数据分析中,了解某列有多少不同的值可以帮助我们快速掌握数据的分布情况,例如统计客户编号的唯一值数量可以知道有多少不同的客户。
16. 提取指定列到新的Excel文件
import pandas as pddef extract_columns(file_path, columns, output_file):df = pd.read_excel(file_path)new_df = df[columns]new_df.to_excel(output_file, index=False)extract_columns('example.xlsx', ['姓名', '年龄'], 'extracted_columns.xlsx')
print("指定列提取成功!")
解释
此脚本可以从一个Excel文件中提取指定的列,并保存到一个新的Excel文件中。当我们只需要数据中的部分信息时,使用这个脚本可以快速筛选出所需的数据,避免处理大量无关信息。
17. 为Excel表格添加边框
from openpyxl import load_workbook
from openpyxl.styles import Border, Sidedef add_border_to_excel(file_path):wb = load_workbook(file_path)ws = wb.activethin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))for row in ws.iter_rows():for cell in row:cell.border = thin_borderwb.save(file_path)add_border_to_excel('example.xlsx')
print("表格边框添加成功!")
解释
该脚本为Excel表格中的每个单元格添加了细边框。添加边框可以使表格更加清晰易读,特别是在打印或展示数据时,能够提升表格的美观度和专业性。
18. 检查Excel文件中是否存在空行并删除
import pandas as pddef remove_empty_rows(file_path):df = pd.read_excel(file_path)df = df.dropna(how='all')df.to_excel(file_path, index=False)remove_empty_rows('example.xlsx')
print("空行删除成功!")
解释
此脚本用于检查Excel文件中是否存在所有列都为空的行,并将这些空行删除。空行可能会影响数据处理和分析的结果,通过删除空行可以保证数据的完整性和准确性。
19. 根据多列条件筛选数据
import pandas as pddef filter_data_by_multiple_conditions(file_path, conditions, output_file):df = pd.read_excel(file_path)query_str = ' & '.join([f'{col} {op} {val}' for col, op, val in conditions])filtered_df = df.query(query_str)filtered_df.to_excel(output_file, index=False)# 示例条件:年龄大于25且性别为女
conditions = [('年龄', '>', 25), ('性别', '==', "'女'")]
filter_data_by_multiple_conditions('example.xlsx', conditions, 'filtered_data.xlsx')
print("多条件筛选数据成功!")
解释
该脚本可以根据多个列的条件对Excel数据进行筛选,并将筛选结果保存到新的文件中。在实际数据分析中,我们常常需要根据多个条件来筛选出符合要求的数据,使用这个脚本可以方便地实现多条件筛选。
20. 对Excel中的日期列进行格式化
import pandas as pddef format_date_column(file_path, column_name, date_format):df = pd.read_excel(file_path)df[column_name] = pd.to_datetime(df[column_name]).dt.strftime(date_format)df.to_excel(file_path, index=False)format_date_column('example.xlsx', '日期', '%Y-%m-%d')
print("日期列格式化成功!")
解释
此脚本用于对Excel文件中指定的日期列进行格式化。在处理日期数据时,不同的业务需求可能需要不同的日期格式,通过这个脚本可以将日期列转换为我们需要的格式,方便后续的数据分析和展示。
希望这些Excel自动化脚本能够进一步帮助你提高工作效率,更好地掌握Python在Excel数据处理方面的应用!如果你在实践过程中有任何疑问,欢迎随时交流。
相关文章:

Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。 本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。 1. Excel单…...

nodejs - vue 视频切片上传,本地正常,线上环境导致磁盘爆满bug
nodejs 视频切片上传,本地正常,线上环境导致磁盘爆满bug 原因: 然后在每隔一分钟执行du -sh ls ,发现文件变得越来越大,即文件下的mp4文件越来越大 最后导致磁盘直接爆满 排查原因 1、尝试将m3u8文件夹下的所有视…...

瑞友天翼应用虚拟化系统 GetPwdPolicy SQL注入漏洞复现
免责声明 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在使…...

【MySQL — 数据库基础】深入解析MySQL的聚合查询
1. 聚合查询 1.1 聚合函数 函数说明COUNT ( [DISTINCT] expr)返回查询到的数据的数量( 行数 )SUM ( [DISTINCT] expr)返回查询到的数据的总和,不是数字没有意义AVG ( [DISTINCT] expr)返回查询到的数据的平均值,不是数字没有意义MAX( [DISTINCT] expr)…...

22.3、IIS安全分析与增强
目录 IIS安全威胁分析iis安全机制iis安全增强 IIS安全威胁分析 iis是微软公司的Web服务软件,主要提供网页服务,除此之外还可以提供其他服务,第一个最主要的是网页服务,第二个是SMTP邮件服务,第三个是FTP文件传输服务。…...

windows平台本地部署DeepSeek大模型+Open WebUI网页界面(可以离线使用)
环境准备: 确定部署方案请参考:DeepSeek-R1系列(1.5b/7b/8b/32b/70b/761b)大模型部署需要什么硬件条件-CSDN博客 根据本人电脑配置:windows11 + i9-13900HX+RTX4060+DDR5 5600 32G内存 确定部署方案:DeepSeek-R1:7b + Ollama + Open WebUI 1. 安装 Ollama Ollama 是一…...

港中文腾讯提出可穿戴3D资产生成方法BAG,可自动生成服装和配饰等3D资产如,并适应特定的人体模型。
今天给大家介绍一种名为BAG(Body-Aligned 3D Wearable Asset Generation)的新方法,可以自动生成可穿戴的3D资产,如服装和配饰,以适应特定的人体模型。BAG方法通过构建一个多视图图像扩散模型,生成与人体对齐…...
模型:实现机器翻译)
【人工智能】Python中的序列到序列(Seq2Seq)模型:实现机器翻译
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 序列到序列(Seq2Seq)模型是自然语言处理(NLP)中一项核心技术,广泛应用于机器翻译、语音识别、文本摘要等任务。本文深入探讨Seq2Seq模…...

34.日常算法
1.合并区间 题目来源 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入&#x…...
架构设计指南)
DeepSeek深度思考:客户端(Android/iOS)架构设计指南
目标读者:中高级开发者、架构师 适用场景:大型复杂应用开发、跨团队协作、长期维护迭代 一、架构设计核心原则 1.模块化(Modularization) 横向拆分:按功能边界划分(如登录、支付、消息模块)纵向…...

2025 年前端开发现状分析:卷疯了还是卷麻了?
一、前端现状:框架狂飙,开发者崩溃 如果你是个前端开发者,那么你大概率经历过这些场景: 早上打开 CSDN(或者掘金,随便),发现又有新框架发布了,名字可能是 VueXNext.js 之…...

数据库 绪论
目录 数据库基本概念 一.基本概念 1.信息 2.数据 3.数据库(DB) 4.数据库管理系统(DBMS) 5.数据库系统(DBS) 二.数据管理技术的发展 1.人工管理阶段 2.文件系统阶段 3.数据库系统阶段 4.数据库管…...

【AIGC魔童】DeepSeek v3提示词Prompt书写技巧
【AIGC魔童】DeepSeek v3提示词Prompt书写技巧 (1)基础通用公式(适用80%场景)(2)问题解决公式(决策支持)(3)创意生成公式(4)学习提升公…...

Docker 部署 RabbitMQ | 自带延时队列
一、获取镜像 docker pull farerboy/rabbitmq:3.9.9 二、运行镜像 docker run -d --name rabbitmq \n --hostname rabbitmq \n -p 15672:15672/tcp \n -p 5672:5672/tcp \n -v /wwwroot/opt/docker/rabbitmq:/var/lib/rabbitmq \n farerboy/rabbitmq:3.9.9 备注:…...

【Unity】Unity中物体的static属性作用
Unity中物体的static属性主要用于优化游戏性能和简化渲染过程。 Unity中物体的static属性的作用 优化渲染性能:当物体被标记为static时,Unity会在游戏运行时将其视为静止的物体,这意味着这些物体的渲染信息不会随着每一帧的更新而变化…...

网络编程基础1
七层协议模型和四层协议模型 七层协议模型:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 四层协议模型:链路层、网络层、传输层、应用层 TCP通信流程 服务器端 (1)创建socket(socket) (2)绑定自己的IP(bind) (3)监听客户端连接(liste…...

跨越边界,大模型如何助推科技与社会的完美结合?
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 概述 2024年,大模型技术已成为人工智能领域的焦点。这不仅仅是一项技术进步,更是一次可能深刻影响社会发展方方面面的变革。大模型的交叉能否推动技术与社会的真正融合?2025年…...

kafka生产端之架构及工作原理
文章目录 整体架构元数据更新 整体架构 消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用,那么在此之后又会…...

在 Windows 上使用 ZIP 包安装 MySQL 的详细步骤
以下是使用官方 ZIP 包在 Windows 上安装 MySQL 的详细步骤,确保能通过 mysql -uroot -p 成功连接。 步骤 1:下载 MySQL ZIP 包 访问 MySQL 官方下载页面: https://dev.mysql.com/downloads/mysql/选择 Windows (x86, 64-bit), ZIP Archive&…...

【web自动化】指定chromedriver以及chrome路径
selenium自动化,指定chromedriver,以及chrome路径 对应这篇文章,可以点击查看,详情 from selenium import webdriverdef get_driver():# 获取配置对象option webdriver.ChromeOptions()option.add_experimental_option("de…...

记录 | WPF创建和基本的页面布局
目录 前言一、创建新项目注意注意点1注意点2 解决方案名称和项目名称 二、布局2.1 Grid2.1.1 RowDefinitions 行分割2.1.2 Row & Column 行列定位区分 2.1.3 ColumnDefinitions 列分割 2.2 StackPanel2.2.1 Orientation 修改方向 三、模板水平布局【Grid中套StackPanel】中…...

mysql 存储过程和自定义函数 详解
首先创建存储过程或者自定义函数时,都要使用use database 切换到目标数据库,因为存储过程和自定义函数都是属于某个数据库的。 存储过程是一种预编译的 SQL 代码集合,封装在数据库对象中。以下是一些常见的存储过程的关键字: 存…...

Maven 中常用的 scope 类型及其解析
在 Maven 中,scope 属性用于指定依赖项的可见性及其在构建生命周期中的用途。不同的 scope 类型能够影响依赖项的编译和运行阶段。以下是 Maven 中常用的 scope 类型及其解析: compile(默认值): 这是默认的作用域。如果…...

SpringCloud - Nacos注册/配置中心
前言 该博客为Nacos学习笔记,主要目的是为了帮助后期快速复习使用 学习视频:7小快速通关SpringCloud 辅助文档:SpringCloud快速通关 源码地址:cloud-demo 一、简介 Nacos官网:https://nacos.io/docs/next/quickstar…...

C++ 继承(1)
1.继承概念 我们平时有时候在写多个有内容重复的类的时候会很麻烦 比如我要写Student Teacher Staff 这三个类 里面都要包含 sex name age成员变量 唯一不同的可能有一个成员变量 但是这三个成员变量我要写三遍 太麻烦了 有没有好的方式呢? 有的 就是继承…...

【C语言】传值调用与传址调用详解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯传值调用1. 什么是传值调用?2. 示例代码:传值调用失败的情况执行结果: 3. 为什么传值调用无法修改外部变量? Ǵ…...

蓝桥杯C语言组:图论问题
蓝桥杯C语言组图论问题研究 摘要 图论是计算机科学中的一个重要分支,在蓝桥杯C语言组竞赛中,图论问题频繁出现,对参赛选手的算法设计和编程能力提出了较高要求。本文系统地介绍了图论的基本概念、常见算法及其在蓝桥杯C语言组中的应用&#…...

windows通过网络向Ubuntu发送文件/目录
由于最近要使用树莓派进行一些代码练习,但是好多东西都在windows里或虚拟机上,就想将文件传输到树莓派上,但试了发现u盘不能简单传送,就在网络上找到了通过windows 的scp命令传送 前提是树莓派先开启ssh服务,且Window…...

Unity抖音云启动测试:如何用cmd命令行启动exe
相关资料:弹幕云启动(原“玩法云启动能力”)_直播小玩法_抖音开放平台 1,操作方法 在做云启动的时候,接完发现需要命令行模拟云环境测试启动,所以研究了下。 首先进入cmd命令,CD进入对应包的文件…...
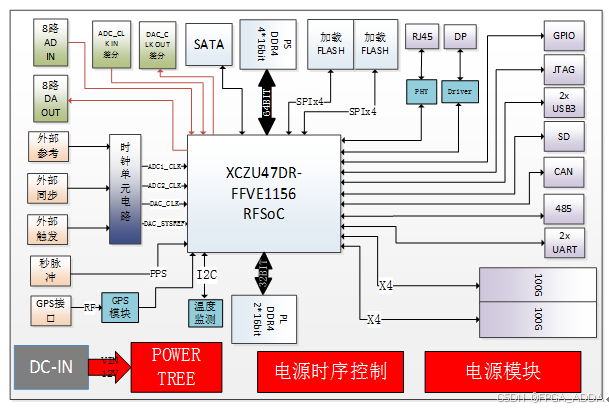
ZU47DR 100G光纤 高性能板卡
简介 2347DR是一款最大可提供8路ADC接收和8路DAC发射通道的高性能板卡。板卡选用高性价比的Xilinx的Zynq UltraScale RFSoC系列中XCZU47DR-FFVE1156作为处理芯片(管脚可以兼容XCZU48DR-FFVE1156,主要差别在有无FEC(信道纠错编解码࿰…...