【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)

目录
一、引言
二、MMoE(Multi-gate Mixture-of-Experts,多门混合专家网络)
2.1 技术原理
2.2 技术优缺点
2.3 业务代码实践
2.3.1 业务场景与建模
2.3.2 模型代码实现
2.3.3 模型训练与推理测试
2.3.4 打印模型结构
三、总结
一、引言
上一篇我们讲了MoE混合专家网络,通过引入Gate门控,针对不同的Input分布,对多个专家网络赋予不同的权重,解决多场景或多目标任务task的底层信息共享及个性化问题。但MoE网络对于不同的Expert专家网络,采用同一个Gate门控网络,仅对不同的Input分布实现了个性化,对不同目标任务task的个性化刻画能力不足,今天在MoE的基础上,引入MMoE网络,为每一个task任务构建专属的Gate门控网络,这样的改进可以针对不同的task得到不同的Experts权重,从而实现对Experts专家的选择利用,不同的任务task对应的gate门控网络可以学习到不同的Experts网络组合模式,更容易捕捉到不容task间的相关性和差异性。
二、MMoE(Multi-gate Mixture-of-Experts,多门混合专家网络)
2.1 技术原理
MMoE(Multi-gate Mixture-of-Experts)全称为多门混合专家网络,主要由多个专家网络、多个任务塔、多个门控网络构成。核心原理:样本数据分别输入num_experts个专家网络进行推理,每个专家网络实际上是一个前馈神经网络(MLP),输入维度为x,输出维度为output_experts_dim;同时,样本数据分别输入目标task对应的门控网络Gate A及Gate B,门控网络也是一个MLP(可以为多层,也可以为一层),输出为num_experts个experts专家的概率分布,维度为num_experts(采用softmax将输出归一化,各个维度加起来和为1);对于每一个Task,将各自对应专家网络的输出,基于对应gate门控网络的softmax加权平均,作为各自Task的输入,所有Task的输入统一维度均为output_experts_dim。在每次反向传播迭代时,对Gate A、Gate B和num_experts个专家参数进行更新,Gate A、Gate B和专家网络的参数受任务Task A、B共同影响。

- 专家网络:样本数据分别输入num_experts个专家网络进行推理,每个专家网络实际上是一个前馈神经网络(MLP),输入维度为x,输出维度为output_experts_dim。
- 门控网络:样本数据分别输入目标task对应的门控网络Gate A及Gate B,门控网络也是一个MLP(可以为多层,也可以为一层),输出为num_experts个experts专家的概率分布,维度为num_experts(采用softmax将输出归一化,各个维度加起来和为1)
- 任务网络:对于每一个Task,将各自对应专家网络的输出,基于对应gate门控网络的softmax加权平均,作为各自Task的输入,所有Task的输入统一维度均为output_experts_dim。
2.2 技术优缺点
相较于MoE网络,MMoE的本质是每个task自带Gate门控网络对多个专家的预估结果进行选择,相当于给每个task安排了一个个人助理,对专家的结果进行评审(而MoE对于所有task仅有一个公共助理,对task的专属需求了解不深)。相较于MoE网络:
优点:
- 对每个task安排专属的gate网络,在专家网络赋值时更加个性化
- 更容易捕捉到不容task间的相关性和差异性。
缺点:
- MMOE中所有的Expert是被所有task共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
- 不同的Expert之间没有交互,联合优化的效果有所折扣,虽然可以缓解负迁移问题,但跷跷板现象仍然存在。
2.3 业务代码实践
2.3.1 业务场景与建模
我们还是以小红书推荐场景为例,针对一个视频,用户可以点红心(互动),也可以点击视频进行播放(点击),针对互动和点击两个目标进行多目标建模

我们构建一个100维特征输入,4个experts专家网络,2个task目标,2个门控的MMoE网络,用于建模多目标学习问题,模型架构图如下:

如架构图所示,其中有几个注意的点:
- num_experts:门控gate的输出维度和专家数相同,均为num_experts,因为gate的用途是对专家网络最后一层进行加权平均,gate维度与专家数是直接对应关系。
- output_experts_dim:专家网络的输出维度和task网络的输入维度相同,task网络承接的是专家网络各维度的加权平均值,experts网络与task网络是直接对应关系。
- Softmax:Gate门控网络对最后一层采用Softmax归一化,保证专家网络加权平均后值域相同
2.3.2 模型代码实现
基于pytorch,实现上述网络架构,如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDatasetclass MMoEModel(nn.Module):def __init__(self, input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_experts):super(MMoEModel, self).__init__()# 初始化函数外使用初始化变量需要赋值,否则默认使用全局变量# 初始化函数内使用初始化变量不需要赋值 self.num_experts = num_expertsself.output_experts_dim = output_experts_dim# 初始化多个专家网络self.experts = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_experts)])# 定义任务1的输出层self.task1_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task1_dim),nn.Sigmoid()) # 定义任务2的输出层self.task2_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task2_dim),nn.Sigmoid()) # 初始化门控网络1self.gating1_network = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_experts),nn.Softmax(dim=1))# 初始化门控网络2self.gating2_network = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_experts),nn.Softmax(dim=1))def forward(self, x):# 计算输入数据通过门控网络后的权重gates1 = self.gating1_network(x)gates2 = self.gating2_network(x)#print(gates)batch_size, _ = x.shapetask1_inputs = torch.zeros(batch_size, self.output_experts_dim)task2_inputs = torch.zeros(batch_size, self.output_experts_dim)# 计算每个专家的输出并加权求和for i in range(self.num_experts):expert_output = self.experts[i](x)task1_inputs += expert_output * gates1[:, i].unsqueeze(1)task2_inputs += expert_output * gates2[:, i].unsqueeze(1)task1_outputs = self.task1_head(task1_inputs)task2_outputs = self.task2_head(task2_inputs)return task1_outputs, task2_outputs# 实例化模型对象
num_experts = 4 # 假设有4个专家
experts_hidden1_dim = 64
experts_hidden2_dim = 32
output_experts_dim = 16
gate_hidden1_dim = 16
gate_hidden2_dim = 8
task_hidden1_dim = 32
task_hidden2_dim = 16
output_task1_dim = 1
output_task2_dim = 1# 构造虚拟样本数据
torch.manual_seed(42) # 设置随机种子以保证结果可重复
input_dim = 100
num_samples = 1024
X_train = torch.randint(0, 2, (num_samples, input_dim)).float()
y_train_task1 = torch.rand(num_samples, output_task1_dim) # 假设任务1的输出维度为1
y_train_task2 = torch.rand(num_samples, output_task2_dim) # 假设任务2的输出维度为1# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train_task1, y_train_task2)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)model = MMoEModel(input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_experts)# 定义损失函数和优化器
criterion_task1 = nn.MSELoss()
criterion_task2 = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 100
for epoch in range(num_epochs):model.train()running_loss = 0.0for batch_idx, (X_batch, y_task1_batch, y_task2_batch) in enumerate(train_loader):# 前向传播: 获取预测值#print(batch_idx, X_batch )#print(f'Epoch [{epoch+1}/{num_epochs}-{batch_idx}], Loss: {running_loss/len(train_loader):.4f}')outputs_task1, outputs_task2 = model(X_batch)# 计算每个任务的损失loss_task1 = criterion_task1(outputs_task1, y_task1_batch)loss_task2 = criterion_task2(outputs_task2, y_task2_batch)total_loss = loss_task1 + loss_task2# 反向传播和优化optimizer.zero_grad()total_loss.backward()optimizer.step()running_loss += total_loss.item()if epoch % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')print(model)
#for param_tensor in model.state_dict():
# print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 模型预测
model.eval()
with torch.no_grad():test_input = torch.randint(0, 2, (1, input_dim)).float() # 构造一个测试样本pred_task1, pred_task2 = model(test_input)print(f'互动目标预测结果: {pred_task1}')print(f'点击目标预测结果: {pred_task2}')相比于上一篇MoE中的代码,MMoE初始化了gating1_network和gating2_network两个门控网络,在forward前向传播网络结构定义中,两个gate分别以input为输入,通过多层MLP后得到task相对应的加权平均权重。
2.3.3 模型训练与推理测试
运行上述代码,模型启动训练,Loss逐渐收敛,测试结果如下:

2.3.4 打印模型结构

三、总结
本文详细介绍了MMoE多任务模型的算法原理、算法优势,并以小红书业务场景为例,构建网络结构并使用pytorch代码实现对应的网络结构、训练流程。相比于MoE,MMoE可以更好的学习不同Task任务的相关性和差异性。是深度学习推荐系统中多目标或多场景类问题中必须掌握的根基模型。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)
【深度学习】多目标融合算法(三):混合专家网络MOE(Mixture-of-Experts)
【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)
相关文章:
【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)
目录 一、引言 二、MMoE(Multi-gate Mixture-of-Experts,多门混合专家网络) 2.1 技术原理 2.2 技术优缺点 2.3 业务代码实践 2.3.1 业务场景与建模 2.3.2 模型代码实现 2.3.3 模型训练与推理测试 2.3.4 打印模型结构 三、总结 一、…...

RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决
RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决 1、报错情况 下载:https://gitcode.com/yangzongzhuan/RuoYi-Vue-Oracle 用idea打开,启动: 日志有报错: 点右侧m图标,maven有以下报误 &…...

C# OpenCV机器视觉:对位贴合
在热闹非凡的手机维修街上,阿强开了一家小小的手机贴膜店。每天看着顾客们自己贴膜贴得歪歪扭扭,不是膜的边缘贴不整齐,就是里面充满了气泡,阿强心里就想:“要是我能有个自动贴膜的神器,那该多好啊…...

Baumer工业相机堡盟相机的相机传感器芯片清洁指南
Baumer工业相机堡盟相机的相机传感器芯片清洁指南 Baumer工业相机1.Baumer工业相机传感器芯片清洁工具和清洁剂2.Baumer工业相机传感器芯片清洁步骤2.1、准备步骤2.2、清洁过程1.定位清洁工具2.清洁传感器3.使用吹风装置 Baumer工业相机传感器芯片清洁的优势设计与结…...
)
SQL 大厂面试题目(由浅入深)
今天给大家带来一份大厂SQL面试覆盖:基础语法 → 复杂查询 → 性能优化 → 架构设计,大家需深入理解执行原理并熟悉实际业务场景的解决方案。 1. 基础查询与过滤 题目:查询 employees 表中所有薪资(salary)大于 10000…...

在Linux上部署Jenkins的详细指南
引言 在当今快速迭代的软件开发环境中,持续集成和持续交付(CI/CD)变得越来越重要。Jenkins作为一个开源自动化服务器,能够帮助开发者更高效地进行代码集成、测试和部署。本文将详细介绍如何在Linux系统上安装和配置Jenkins。 准…...

《我在技术交流群算命》(三):QML的Button为什么有个蓝框去不掉啊(QtQuick.Controls由Qt5升级到Qt6的异常)
有群友抛出类似以下代码和运行效果截图: import QtQuick import QtQuick.ControlsWindow {width: 640height: 480visible: truetitle: qsTr("Hello World")Button{anchors.centerIn: parentwidth: 100height: 40background: Rectangle {color: "red…...

Golang:Go 1.23 版本新特性介绍
流行的编程语言Go已经发布了1.23版本,带来了许多改进、优化和新特性。在Go 1.22发布六个月后,这次更新增强了工具链、运行时和库,同时保持了向后兼容性。 Go 1.23 的新增特性主要包括语言特性、工具链改进、标准库更新等方面,以下…...

在 PyTorch 中理解词向量,将单词转换为有用的向量表示
你要是想构建一个大型语言模型,首先得掌握词向量的概念。幸运的是,这个概念很简单,也是本系列文章的一个完美起点。 那么,假设你有一堆单词,它可以只是一个简单的字符串数组。 animals ["cat", "dog…...

deepseek API 调用-python
【1】创建 API keys 【2】安装openai SDK pip3 install openai 【3】代码: https://download.csdn.net/download/notfindjob/90343352...

PHP中的魔术方法
在 PHP 中,以两个下划线 __ 开头的方法被称为魔术方法,它们在特定场景下会自动被调用,以下是一些常见的魔术方法: 1.__construct():类的构造函数,在对象创建完成后第一个自动调用,用于执行初始…...

Git、Github和Gitee完整讲解:丛基础到进阶功能
第一部分:Git 是什么? 比喻:Git就像是一本“时光机日记本” 每一段代码的改动,Git都会帮你记录下来,像是在写日记。如果出现问题或者想查看之前的版本,Git可以带你“穿越回过去”,找到任意时间…...

相对收益-固定收益组合归因-加权久期归因模型
固定收益组合归因-加权久期归因模型和Campisi模型 1 加权久期归因模型--推导方式11.1 债券策略组合收益率的分解1.1.2 加权久期归因(1)总久期贡献(2)债券类属配置贡献 1.1.3 如何应用加权久期归因 2 加权久期归因模型--推导方式22…...

原生鸿蒙版小艺APP接入DeepSeek-R1,为HarmonyOS应用开发注入新活力
原生鸿蒙版小艺APP接入DeepSeek-R1,为HarmonyOS应用开发注入新活力 在科技飞速发展的当下,人工智能与操作系统的融合正深刻改变着我们的数字生活。近日,原生鸿蒙版小艺APP成功接入DeepSeek-R1,这一突破性进展不仅为用户带来了更智…...

RabbitMQ 从入门到精通:从工作模式到集群部署实战(三)
文章目录 使用CLI管理RabbitMQrabbitmqctlrabbitmq-queuesrabbitmq-diagnosticsrabbitmq-pluginsrabbitmq-streamsrabbitmq-upgraderabbitmqadmin 使用CLI管理RabbitMQ RabbitMQ CLI 工具需要安装兼容的 Erlang/OTP版本。 这些工具假定系统区域设置为 UTF-8(例如en…...

AI-学习路线图-PyTorch-我是土堆
1 需求 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili PyTorch 深度学习快速入门教程 配套资源 链接 视频教程 https://www.bilibili.com/video/BV1hE411t7RN/ 文字教程 https://blog.csdn.net/xiaotudui…...

2.1 Mockito核心API详解
Mockito核心API详解 1. 创建Mock对象 Mockito提供两种方式创建模拟对象: 1.1 手动创建(传统方式) // 创建接口/类的Mock对象 UserDao userDao Mockito.mock(UserDao.class);1.2 注解驱动(推荐方式) 结合JUnit 5的…...

傅里叶单像素成像技术研究进展
摘要:计算光学成像,通过光学系统和信号处理的有机结合与联合优化实现特定成像特性的成像系统,摆脱了传统成像系统的限制,为光学成像技术添加了浓墨重彩的一笔,并逐步向简单化与智能化的方向发展。单像素成像(Single-Pi…...

可视化工作流编排参数配置完整方案设计文档
一、背景及需求分析 1. 背景 在复杂的工作流程中,后续程序需要动态构造输入参数,这些参数源自多个前序程序的 JSON 数据输出。为了增强系统的灵活性和可扩展性,配置文件需要支持以下功能: 灵活映射前序程序的 JSON 数据。…...

镜头放大倍率和像素之间的关系
相互独立的特性 镜头放大倍率:主要取决于镜头的光学设计和结构,决定了镜头对物体成像时的缩放程度,与镜头的焦距等因素密切相关。比如,微距镜头具有较高的放大倍率,能将微小物体如昆虫、花朵细节等放大成像࿰…...

MariaDB *MaxScale*实现mysql8读写分离
1.MaxScale 是干什么的? MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换,对多个从服务器能实现负载均衡。 2.MaxScale 实验环境 中间件192.168.12…...

计算机毕业设计Spark+大模型知网文献论文推荐系统 知识图谱 知网爬虫 知网数据分析 知网大数据 知网可视化 预测系统 大数据毕业设计 机器学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

MySQL的事务实现原理和隔离级别?
目录 MySQL 事务实现原理 1. 事务的基本概念 2. 实现原理 日志系统 锁机制 MySQL 隔离级别 1. 隔离级别概述 2. 各隔离级别详解 读未提交(Read Uncommitted) 读已提交(Read Committed) 可重复读(Repeatable Read) 串行化(Serializable) 3. 设置隔离级别 My…...

JVM做GC垃圾回收时需要多久,都由哪些因素决定的
JVM进行垃圾回收(GC)的时间长短受多种因素影响,主要包括以下几个方面: 1. 堆内存大小 堆内存越大,GC需要扫描和回收的对象越多,耗时越长。堆内存较小时,GC频率增加,但每次回收的时…...

padding: 20rpx 0rpx 20rpx 20rpx(上、右、下、左的填充(顺时针方向))
CSS样式 padding: 20rpx 0rpx 20rpx 20rpx; 用于设置元素的填充区域。以下是对每个值的详细解释: 20rpx(上边距):设置元素顶部的填充为20rpx。0rpx(右边距):设置元素右侧的填充为0rpx。20rpx&a…...
)
2025-2-10-4.4 双指针(基础题1)
文章目录 4.4 双指针(基础题)**344. 反转字符串****125. 验证回文串****1750. 删除字符串两端相同字符后的最短长度****167.两数之和 II - 输入有序数组****2105. 给植物浇水 II****977. 有序数组的平方****658. 找到K个最接近的元素****1471. 数组中的k…...
)
Qt - 地图相关 —— 2、Qt调用百度在线地图功能示例全集,包含线路规划、地铁线路查询等(附源码)
效果:由于录制软件导致exe显示不正常,实际运行没有任何问题。 说明:exe试用下载(提取码: 4d8y )...

微信小程序如何使用decimal计算金额
第三方库地址:GitHub - MikeMcl/decimal.js: An arbitrary-precision Decimal type for JavaScript 之前都是api接口走后端计算,偶尔发现这个库也不错,计算简单,目前发现比较准确 上代码 导入js import Decimal from ../../uti…...

【AI学习】关于 DeepSeek-R1的几个流程图
遇见关于DeepSeek-R1的几个流程图,清晰易懂形象直观,记录于此。 流程图一 来自文章《Understanding Reasoning LLMs》, 文章链接:https://magazine.sebastianraschka.com/p/understanding-reasoning-llms?continueFlagaf07b1a0…...
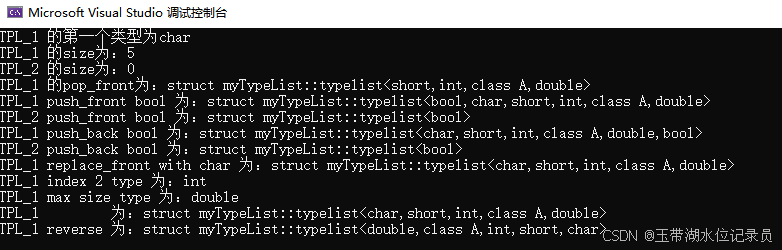
C++模板编程——typelist的实现
文章最后给出了汇总的代码,可直接运行 1. typelist是什么 typelist是一种用来操作类型的容器。和我们所熟知的vector、list、deque类似,只不过typelist存储的不是变量,而是类型。 typelist简单来说就是一个类型容器,能够提供一…...