【JVM详解五】JVM性能调优
示例:
配置JVM参数运行
#前台运行
java -XX:MetaspaceSize-128m -XX:MaxMetaspaceSize-128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio=8 -
XX:+UseConcMarkSweepGC -jar /jar包路径
#后台运行
nohup java -XX:MetaspaceSize-128m -XX:MaxMetaspaceSize-128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio=8
-XX:+UseConcMarkSweepGC -jar /jar包路径参数说明:
-XX:MetaspaceSize=128m (元空间默认大小)
-XX:MaxMetaspaceSize=128m (元空间最大大小)
-Xms1024m (堆最大大小)
-Xmx1024m (堆默认大小)
-Xmn256m (新生代大小)
-Xss256k (棧最大深度大小)
-XX:SurvivorRatio=8 (新生代分区比例 8:2)
-XX:+UseConcMarkSweepGC (指定使用的垃圾收集器,这里使用CMS收集器)一、JVM性能监控与故障处理工具
1.1 jps:虚拟机进程状况工具
虚拟机进程状况工具;jps主要用来输出JVM中运行的进程状态信息。语法格式如下:
jps [options] [hostid]
- 第一个参数 options :-q 不输出类名、Jar名和传入main方法的参数;-m 输出传入main方法的参数;-l 输出main类或 Jar的全限名;-v 输出传入JVM的参数。
- 第二个参数 hostid :主机或者是服务器的id,如果不指定,就默认为当前的主机或者是服务器。

- 如果是本地虚拟机进程,VMID和LVMID是一致的。
- 如果是远程虚拟机进程,那么vmid的格式应当是 :
1.2 jstat:虚拟机统计信息监视工具
虚拟机统计信息监控工具;jstat监视虚拟机各种运行状态信息,可以显示本地或者是远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。语法格式如下:
jstat [ option vmid [interval[s|ms] [count]] ]
- 第一个参数 option:代表着用户希望查询的虚拟机信息,分为类加载、垃圾收集、运行期编译状况3类。

- 参数interval和count代表查询间隔和次数,如果省略这两个参数,说明只查询一次。
假设需要每1000毫秒查询一次进程9344垃圾收集状况,一共查询2次,那命令应当是:
jstat -gcutil 9344 1000 2

- S0代表幸存者0区;
- S1代表幸存者1区;
- E代表伊甸园区;
- O代表老年代;
- M代表方法区;
- CCS代表压缩类,以上这些值都是占比情况;
- YGC代表年轻代垃圾回收的次数;
- YGCT年轻代进行垃圾回收需要的时间;
- FGC代表代表Full GC的次数;
- FGCT代表Full GC的时间;
- GCT代表垃圾回收的总时间。
- [protocol:][//]lvmid[@hostname[:port]/servername]
- 需要远程主机提供RMI支持,sun提供的jstatd可以很方便的建立远程RMI服务器。

1.3 jstack:java虚拟机栈跟踪工具
堆栈跟踪工具;jstack用于生成虚拟机当前时刻的线程快照(threaddump或javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法栈(看java虚拟机栈定义)的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等等。语法格式如下:
jstack [option] vmid
- 第一个参数:option

- 第二个参数:vmid
vmid是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID,可通过jps命令获得。
1.4 jinfo:java配置信息工具
实时地查看和调整虚拟机各项参数;命令格式:
jinfo [option] pid
- 第一个参数:option

- 第二个参数:pid 指定显示的进程id
注意:
1)、如果运行过程中,通过jinfo修改了,则修改后的值只能通过jinfo看到,jps是看不到的,jps命令只能看到启动时的jvm参数。
2)、很多运行参数是不能调整的,如果出现这种异常,说明不能调整:

1.5 jmap:java内存映像工具
生成堆转储快照(heapdump文件);jmap(Memory Map for Java,内存映像工具),用于生成堆转存的快照,一般是heapdump或者dump文件。如果不适用jmap命令,可以使用-XX:+HeapDumpOnOutOfMemoryError参数,当虚拟机发生内存溢出的时候可以产生快照。或者使用kill -3 pid也可以产生。jmap的作用并不仅仅是为了获取dump文件,它可以查询finalize执行队列,java堆和永久代的详细信息,如空间使用率,当前用的哪种收集器。命令格式如下:
jmap [option] vmid
- 第一个参数:option

- 第二个参数 vmid:可通过jps获得
1.6 jhat:jvm堆转储快照分析工具
分析内存转储快照,不推荐使用,而且慢。由于这个工具功能比较简陋,运行起来也比较耗时,所以这个工具不推荐使用,推荐使用MAT。
1.7 JConsole:java监视与管理控制台
基于JMX的可视化管理工具;这个工具相比较前面几个工具,使用率比较高,很重要。它是一个java GUI监视工具,可以以图表化的形式显示各种数据。并可通过远程连接监视远程的服务器VM。用java写的GUI程序,用来监控VM,并可监控远程的VM,非常易用,而且功能非常强。线程监控还可以检查死锁。
1.7.1 启动JConsole
命令行输入 jconsole,然后从下图选择进程(前提是在IDE工具先建立一个线程运行着)

然后我们选择了相应的选项之后,进入这个工具就会出现下面这个界面:

1.8 VisualVM:多合一故障处理工具
- Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具,基于图形化界面。
- 它集成了多个JDK命令行工具,使用Visual VM可用于显示虚拟机进程及进程的配置和环境信息(jps,jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等,甚至代替JConsole。
- 在JDK 6 Update 7以后,Visual VM便作为JDK的一部分发布(VisualVM 在JDK/bin目录下),即:它完全免费。
- 此外,Visual VM也可以作为独立的软件安装。
- 直接在命令行打入jvisualvm即可启动。
- 有一系列功能扩展插件:如visual gc 插件,可查看gc情况
- 生成/读取内存快照;
- 查看JVM参数和系统属性;
- 查看运行中的虚拟机进程;
- 生成/读取线程快照;
- 程序资源的实时监控;
- 其他功能:
- JMX代理连接
- 远程环境监控
- CPU分析和内存分析

1.9 Arthas:aliyun开源工具
前面说过的jvisualvm等要进行远程连接需要在服务端项目开启时配置很多参数,而且如果线上环境是隔离的,那么本地工具是连接不到线上环境的。
Arthas是阿里开源的性能监控神器。阿尔萨斯在远程连接时不需要进行复杂的参数配置,可以在线排除问题,无需重启应用,可以动态跟踪java代码,实时监控JVM状态。
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load(负载)、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
开发文档:Arthas Install | arthas
1.9.1 Arthas Install
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
1.9.2 通过浏览器连接 arthas
Arthas 目前支持 Web Console,用户在 attach 成功之后,可以直接访问:http://127.0.0.1:8563/。
可以填入 IP,远程连接其它机器上的 arthas。

1.9.3 使用arthas定位问题
1.9.4 退出 arthas
如果只是退出当前的连接,可以用quit或者exit命令。Attach 到目标进程上的 arthas 还会继续运行,端口会保持开放,下次连接时可以直接连接上。
如果想完全退出 arthas,可以执行stop命令。
启动arthas之后, 选择要attach的进程之后控制台报错内容如下:

上一次没有通过stop完全退出arthas,然后再次attach与上一次不同的进程之后就会出现这个错误。
1.10 GCViewer 日志分析工具
- Memory:分析Totalheap、Tenuredheap、Youngheap内存占用率及其他指标,理论上内存占用率越小越好;
- Pause:分析Gc pause、Fullgc pause、Total pause三个大项中各指标,理论上GC次数越少越好,GC时长越小越好;
git clone https://github.com/chewiebug/GCViewer.git
//或者用 IDEA打开项目后,用 maven进行打包
mvn clean pacakge
//得到一个 jar包
cd targetjava -jar gcviewer-1.36.jar-Xms60M -Xmx60M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/Users/xxx/Documents/logs/gc.log
1)图表
GCViewer 在图表(第一个选项卡)中显示多条线等,可以点击 View 按钮选择显示哪些线条,具体每个曲线的地方代表什么意思官网都讲的很清楚了。https://github.com/chewiebug/GCViewer GitHub - chewiebug/GCViewer: Fork of tagtraum industries' GCViewer. Tagtraum stopped development in 2008, I aim to improve support for Sun's / Oracle's java 1.6+ garbage collector logs (including G1 collector)
其中黑色的竖线表示 Full GC,这样的线越少越好。就像上图所示,Full GC 后老年代并没有释放多少空间,所以才会抛出 OOM 异常。
图表需要参照 这个view中的信息,其中包含full gc等相关信息,这个在本地开发的时候可以时不时拉出来看下是不是有问题,性能或者一些关键的参数都可以在图标上面一目了然:

2)数据面板
点击 Summary:

- Total heap(usage/alloc.max):占用堆的总大小及使用占比
- Max heap after full GC:Full GC 后的堆内存大小
- Freed memory :释放内存
- Total Time:GC 总耗时
- Accumulated Pauses:GC 过程中暂停总时长
- Throughput(吞吐量):上图显示是 86.8%,有些系统要求吞吐量至少为 90%,那么就说明需要进行 GC 优化。

- Accumulated Pauses:GC 过程中暂停总时长
- Number of Pauses:暂停总次数
- Avg Pause:平均暂停时间
- Avg pause interval:平均暂停的间隔时间
- Full gc Pauses :full gc 暂停信息
- Gc pauses :gc暂停信息
如果你的 Full GC 平均的暂停时间很长(大于1s),或者平均暂停间隔非常的短(小于10s),说明可能你的 GC 回收是有问题的,可能需要优化。
二、GC日志获取
- -XX:+PrintGC :输出GC日志。
- -XX:+PrintGCDetails :输出GC的详细日志。
- -XX:+PrintGCTimeStamps :输出GC的时间戳(以基准时间的形式)。
- -XX:+PrintGCDateStamps :输出GC的时间戳(以日期的形式,如 2017-09-04T21:53:59.234+0800)。
- -XX:+PrintHeapAtGC :在进行GC的前后打印出堆的信息。
- -XX:+PrintGCApplicationStoppedTime :GC造成的应用暂停的时间
- -Xloggc:../logs/gc.log :日志文件的输出路径。
在生产环境中,根据需要配置相应的参数来监控JVM运行情况。
三、gc日志分析
JVM和GC调优,总结下CMS的一些特点和要点,让我们先简单的看下整个堆年轻代和年老代的垃圾收集器组合(以下配合java8完美支持,其他版本可能稍有不同),其中标红线的则是我们要着重讲的内容:

3.1 ParNew and CMS
"Concurrent Mark and Sweep" 是CMS的全称,官方给予的名称是:“Mostly Concurrent Mark and Sweep Garbage Collector”;
年轻代:采用 stop-the-world mark-copy 算法(ParNew);
年老代:采用 Mostly Concurrent mark-sweep 算法(CMS);
设计目标:年老代收集的时候避免长时间的暂停;
- 它不会花时间整理压缩年老代,而是维护了一个叫做 free-lists 的数据结构,该数据结构用来管理那些回收再利用的内存空间。
- mark-sweep分为多个阶段,其中一大部分阶段GC的工作是和Application threads的工作同时进行的(当然,gc线程会和用户线程竞争CPU的时间),默认的GC的工作线程为你服务器物理CPU核数的1/4。

3.1.1 Minor GC

我们来分析下对象晋升问题(原文中的计算方式有问题):
开始的时候:整个堆的大小是 10885349K,年轻代大小是613404K,这说明老年代大小是 10885349-613404=10271945K,
收集完成之后:整个堆的大小是 10880154K,年轻代大小是68068K,这说明老年代大小是 10880154-68068=10812086K,
老年代的大小增加了:10812086-10271945=608209K,也就是说 年轻代到年老代promot了608209K的数据;

3.1.2 Full/Major GC

Phase 1: Initial Mark(初始标记)
这是CMS中两次stop-the-world事件中的一次。它有两个目标:一是标记老年代中所有的GC Roots;二是标记被年轻代中活着的对象引用的对象。
标记结果如下:


- 016-08-23T11:23:07.321-0200: 64.42 – GC事件开始,包括时钟时间和相对JVM启动时候的相对时间,下边所有的阶段改时间的含义相同;
- CMS Initial Mark – 收集阶段,开始收集所有的GC Roots和直接引用到的对象;
- 10812086K – 当前老年代使用情况;
- (11901376K) – 老年代可用容量;
- 10887844K – 当前整个堆的使用情况;
- (12514816K) – 整个堆的容量;
- 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] – 时间计量;
Phase 2: Concurrent Mark(并发标记)
这个阶段会遍历整个老年代并且标记所有存活的对象,从“初始化标记”阶段找到的GC Roots开始。并发标记的特点是和应用程序线程同时运行。并不是老年代的所有存活对象都会被标记,因为标记的同时应用程序会改变一些对象的引用等。

在上边的图中,一个引用的箭头已经远离了当前对象(current obj)。

- CMS-concurrent-mark – 并发收集阶段,这个阶段会遍历整个年老代并且标记活着的对象;
- 035/0.035 secs – 展示该阶段持续的时间和时钟时间;
- [Times: user=0.07 sys=0.00, real=0.03 secs] – 同上。
四、性能调优
4.1 性能调优的层次

进行jvm调优之前,我们假设项目的架构调优和代码调优已经进行过或者是针对当前项目是最优的。这两个是jvm调优的基础,并且架构调优是对系统影响最大的 ,我们不能指望一个系统架构有缺陷或者代码层次优化没有穷尽的应用,通过jvm调优令其达到一个质的飞跃,这是不可能的。其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
另外,在调优之前,必须得有明确的性能优化目标, 然后找到其性能瓶颈。之后针对瓶颈的优化,还需要对应用进行压力和基准测试,通过各种监控和统计工具,确认调优后的应用是否已经达到相关目标。
4.1.1 JVM调优前提
- Heap内存(老年代)持续上涨达到设置的最大内存值;
- Full GC 次数频繁;
- GC 停顿时间过长(超过1秒);
- 应用出现OutOfMemory 等内存异常;
- 应用中有使用本地缓存且占用大量内存空间;
- 系统吞吐量与响应性能不高或下降。
4.2 JVM调优流程(VisualVM+gc插件 / gcviewer日志分析工具)
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm的调优也不例外,jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。当然这里的最少是最优的选择,而不是越少越好。
4.2.1 性能定义
要查找和评估器性能瓶颈,首先要知道性能定义,对于jvm调优来说,我们需要知道以下三个定义属性,依作为评估基础:

这三个属性中,其中一个任何一个属性性能的提高,几乎都是以另外一个或者两个属性性能的损失作代价,不可兼得,具体某一个属性或者两个属性的性能对应用来说比较重要,要基于应用的业务需求来确定。
4.2.2 性能调优原则
在调优过程中,我们应该谨记以下3个原则,以便帮助我们更轻松的完成垃圾收集的调优,从而达到应用程序的性能要求。

4.2.3 性能调优流程

以上就是对应用程序进行jvm调优的基本流程,我们可以看到,jvm调优是根据性能测试结果不断优化配置而多次迭代的过程。在达到每一个系统需求指标之前,之前的每个步骤都有可能经历多次迭代。有时候为了达到某一方面的指标,有可能需要对之前的参数进行多次调整,进而需要把之前的所有步骤重新测试一遍。
另外调优一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。以下我们针对每个步骤进行详细的示例讲解。
在JVM的运行模式方面,我们直接选择server模式,这也是jdk1.6以后官方推荐的模式。
在垃圾收集器方面,我们直接采用了jdk1.6-1.8 中默认的parallel收集器(新生代采用parallelGC,老生代采用parallelOldGC)。
4.2.3.1 确定内存占用
- 应用程序的运行阶段
- jvm内存分配
1)运行阶段
应用程序的运行阶段,我可以划分为以下三个阶段:

确定内存占用以及活跃数据的大小,我们应该是在程序的稳定阶段来进行确定,而不是在项目起初阶段来进行确定,如何确定,我们先看以下jvm的内存分配。

jvm堆中主要的空间,就是以上新生代、老生代、永久代组成,整个堆大小=新生代大小 + 老生代大小 + 永久代大小。 具体的对象提升方式,这里不再过多介绍了,我们看下一些jvm命令参数,对堆大小的指定。如果不采用以下参数进行指定的话,虚拟机会自动选择合适的值,同时也会基于系统的开销自动调整。

在设置的时候,如果关注性能开销的话,应尽量把永久代的初始值与最大值设置为同一值,因为永久代的大小调整需要进行FullGC 才能实现。

如前所述,活跃数据应该是基于应用程序稳定阶段时,观察长期存活与对象在java堆中占用的空间大小。
- 测试时,启动参数采用jvm默认参数,不人为设置。
- 确保Full GC 发生时,应用程序正处于稳定阶段。
采用jvm默认参数启动,是为了观察应用程序在稳定阶段的所需要的内存使用。
如何才算稳定阶段?
一定得需要产生足够的压力,找到应用程序和生产环境高峰符合状态类似的负荷,在此之后达到峰值之后,保持一个稳定的状态,才算是一个稳定阶段。所以要达到稳定阶段,压力测试是必不可少的。
在确定了应用出于稳定阶段的时候,要注意观察应用的GC日志,特别是Full GC 日志。

-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -Xloggc:/Users/wangjiafu/logs/gc.log必须得有FullGC 日志,如果没有的话,可以采用监控工具强制调用一次,或者采用以下命令,亦可以触发:jmap -histo:live pid
在稳定阶段触发了FullGC我们一般会拿到如下 GC 日志信息:
10.080: 2[GC 3(Allocation Failure) 0.080: 4[DefNew: 56815K->280K(9216K),6 0.0043690 secs] 76815K->6424K(19456K), 80.0044111 secs]9 [Times: user=0.00 sys=0.01, real=0.01 secs]
以上是发生 Minor GC 的 GC 是日志,如果发生 Full GC 呢,格式如下:
10.088: 2[Full GC 3(Allocation Failure) 0.088: 4[Tenured: 50K->210K(10240K), 60.0009420 secs] 74603K->210K(19456K), [Metaspace: 2630K->2630K(1056768K)], 80.0009700 secs]9 [Times: user=0.01 sys=0.00, real=0.02 secs]
- 开头的 0.080,0.088 代表了 GC 发生的时间,这个数字的含义是从 Java 虚拟机启动以来经过的秒数;
- [GC 或者 [Full GC 说明了这次垃圾收集的停顿类型,注意不是用来区分新生代 GC 还是老年化 GC 的,如果有 Full,说明这次 GC 是发生了 Stop The World 的,如果是调用 System.gc() 所触发的收集,这里会显示 [Full GC(System);
- 之后的 Allocation Failure 代表了触发 GC 的原因,在这个程序中我们设置了新生代的大小为 10M(-Xmn10M),Eden:S0:S1 = 8:1:1(-XX:SurvivorRatio=8),也就是说 Eden 区占了 8M, 当分配 allocation4 时,由于将要分配的总大小为 10M,超过了 Eden 区,所以此时会发生 GC;
- 接下来的 [DefNew,[Tenured,[Metaspace 表示 GC 发生的区域,这里显示的区域名与使用的 GC 收集器是密切相关的,在此例中由于新生代我们使用了 Serial 收集器,此收集器新生代名为「Default New Generation」,所以显示的是 [DefNew,如果是 ParNew 收集器,新生代名称就会变为 [ParNew`,意为 「Parallel New Generation」,如果采用 「Parallel Scavenge」收集器,则配套的新生代名称为「PSYoungGen」,老年代与新生代一样,名称也是由收集器决定的;
- 再往后 6815K->280K(9216K) 表示 「GC 前该内存区域已使用容量 -> GC 后该内存区域已使用容量(该内存区域总容量)」;
- 0.0043690 secs 表示该块内存区域 GC 所占用的时间,单位是秒;
- 6815K->6424K(19456K) 表示「GC 前 Java 堆已使用容量 -> GC 后 Java 堆已使用容易(java 堆总容量)」。
- 0.0044111 secs 表示整个 GC 执行时间,注意和 6 中 0.0043690 secs 的区别,后者专指相关区域所花的 GC 时间,而前者指的 GC 的整体堆内存变化所花时间(新生代与老生代的的内存整理),所以前者是肯定大于后者的!
- 最后一个 [Times: user=0.01 sys=0.00, real=0.02 secs] 这里的 user, sys 和 real 与Linux 的 time 命令所输出的时间一致,分别代表用户态消耗的 CPU 时间,内核态消耗的 CPU 时间,和操作从开始到结束所经过的墙钟时间,墙钟时间包括各种非运算的等待耗时,例如等待磁盘 I/O,等待线程阻塞,而 CPU 时间不包括这些耗时,但当系统有多 CPU 或者多核的话,多线程操作会叠加这些 CPU 时间,所以 user 或 sys 时间是可能超过 real 时间的。
知道了 GC 日志怎么看,我们就可以根据 GC 日志有效定位问题了,如我们发现 Full GC 发生时间过长,则结合我们上文应用中打印的 OOM 日志可能可以快速定位到问题。

从以上gc日志中,我们大概可以分析到,在发生fullGC之时,整个应用的堆占用以及GC时间,当然了,为了更加精确,应该多收集几次,获取一个平均值。或者是采用耗时最长的一次FullGC来进行估算。在上图中,fullGC之后,老年代空间占用在93168kb(约93MB),我们以此定为老年代空间的活跃数据。
其他堆空间的分配,基于以下规则来进行:

- java 堆空间: 373Mb (=老年代空间93168kb*4)
- 新生代空间:140Mb(=老年代空间93168kb*1.5)
- 永久代空间:5Mb(=永久代空间3135kb*1.5)
- 老年代空间: 233Mb=堆空间-新生代看空间=373Mb-140Mb
java -Xms373m -Xmx373m -Xmn140m -XX:PermSize=5m -XX:MaxPermSize=5m
4.2.3.2 延时调优
在确定了应用程序的活跃数据大小之后,我们需要再进行延迟性调优,因为对于此时堆内存大小,延迟性需求无法达到应用的需要,需要基于应用的情况来进行调试。
在这一步进行期间,我们可能会再次优化堆大小的配置,评估GC的持续时间和频率、以及是否需要切换到不同的垃圾收集器上。
1)系统延时需求
在调优之前,我们需要知道系统的延迟需求是那些,以及对应的延迟可调优指标是那些。

以上中,平均停滞时间和最大停顿时间,对用户体验最为重要,可以多关注。
基于以上的要求,我们需要统计以下数据:

2)优化新生代的大小

比如如上的gc日志中,我们可以看到Minor GC的平均持续时间=0.069秒,MinorGC 的频率为(3.113-0.388)/7=0.389秒一次。

为了降低改变新生代的大小对其他区域的最小影响。在改变新生代空间大小的时候,尽量保持老年代空间的大小。比如此次减少了新生代空间10%的大小,应该保持老年代和永久代的大小不变化,第一步调优后的参数如下变化:

3)优化老年代的大小
同上一步一样,在优化之前,也需要采集gc日志的数据。此次我们关注的是FullGC的持续时间和频率。

上图中,我们可以看到:

没有FullGC日志时,可以通过 对象提升率 计算FullGC的持续时间和频率:比如上述中启动参数中,我们的老年代大小=233Mb。那么需要多久才能填满老年代中这233Mb的空闲空间取决于新生代到老年代的提升率。
每次提升老年代占用量=每次MinorGC 之后 java堆占用情况 减去 MinorGC后新生代的空间占用
对象提升率=平均值(每次提升老年代占用量) / 老年代空间
有了对象提升率,我们就可以算出填充满老年代空间需要多少次minorGC,大概一次fullGC的时间就可以计算出来了。
比如:

- 第一次minor GC 之后,老年代空间:13740kb - 13732kb =8kb
- 第二次minor GC 之后,老年代空间:22394kb - 17905kb =4489kb
- 第三次minor GC 之后,老年代空间:34739kb - 17917kb =16822kb
- 第四次minor GC 之后,老年代空间:48143kb - 17913kb =30230kb
- 第五次minor GC 之后,老年代空间:62112kb - 17917kb =44195kb
- 4481kb 第二次和第一次minorGC之间
- 12333kb 第3次和第2次minorGC之间
- 13408kb 第4次和第3次minorGC之间
- 13965kb 第5次和第4次minorGC之间
- 每次minorGC 的平均提升为12211kb,约为12Mb
- 上图中,平均minorGC的频率为 213ms/次
- 提升率=12211kb/213ms=57kb/ms
- 老年代空间233Mb ,占满大概需要233*1024/57=4185ms 约为4.185s。
FullGC的预期最差频率时长可以通过以上两种方式估算出来,可以调整老年代的大小来调整FullGC的频率,当然了,如果FullGC持续时间过长,无法达到应用程序的最差延迟要求,就需要切换垃圾处理器了。具体如何切换,下篇再讲,比如切换为CMS,针对CMS的调优方式又有会细微的差别。
4.2.3.3 吞吐量调优
吞吐量=运行用户代码时间 / (运行用户代码时间+垃圾收集时间);虚拟机总共运行100分钟,其中gc花掉1分钟,则吞吐量就是 99% 。
经过上述漫长 调优过程,最终来到了调优的最后一步,这一步对上述的结果进行吞吐量测试,并进行微调。
吞吐量调优主要是基于应用程序的吞吐量要求而来的,应用程序应该有一个综合的吞吐指标,这个指标基于真个应用的需求和测试而衍生出来的。当有应用程序的吞吐量达到或者超过预期的吞吐目标,整个调优过程就可以圆满结束了。
如果出现调优后依然无法达到应用程序的吞吐目标,需要重新回顾吞吐要求,评估当前吞吐量和目标差距是否巨大,如果在20%左右,可以修改参数,加大内存,再次从头调试,如果巨大就需要从整个应用层面来考虑,设计以及目标是否一致了,重新评估吞吐目标。
对于垃圾收集器来说,提升吞吐量的性能调优的目标就是就是尽可能避免或者很少发生FullGC 或者Stop-The-World压缩式垃圾收集(CMS),因为这两种方式都会造成应用程序吞吐降低。尽量在MinorGC 阶段回收更多的对象,避免对象提升过快到老年代。
五、JVM常用设置参数
5.1 栈、堆设置的常用参数
5.2 收集器设置
5.3 垃圾回收统计信息
5.4 并行收集器设置
5.5 并发收集器设置
相关文章:
【JVM详解五】JVM性能调优
示例: 配置JVM参数运行 #前台运行 java -XX:MetaspaceSize-128m -XX:MaxMetaspaceSize-128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio8 - XX:UseConcMarkSweepGC -jar /jar包路径 #后台运行 nohup java -XX:MetaspaceSize-128m -XX:MaxMetaspaceS…...

基于 STM32 平台的音频特征提取与歌曲风格智能识别系统
标题:基于 STM32 平台的音频特征提取与歌曲风格智能识别系统 内容:1.摘要 摘要:本文介绍了一种基于 STM32 平台的音频特征提取与歌曲风格智能识别系统。该系统通过对音频信号进行特征提取和分析,实现了对歌曲风格的自动识别。在特征提取方面,…...

DeepSeek:搅动人工智能产业风云的鲶鱼效应深度解读
我的个人主页 我的专栏:人工智能领域,希望能帮助到大家!!!点赞❤ 收藏❤ 引言 在当今科技飞速发展的时代,人工智能(AI)无疑是最为耀眼的领域之一。众多技术与平台如繁星般涌现&a…...

一觉醒来全球编码能力下降100000倍,新手小白的我决定科普C语言——三子棋游戏实现
硬控我一上午,小编还是太菜了,大家可以自行升级电脑难度,也可以升级游戏到五子棋 1.game.h #pragma once #include<stdio.h> #include<stdlib.h> #include<time.h> #define ROW 3 #define COL 3//初始化棋盘 void InitBoa…...

学习 URL 传参中哪些字符是支持的,哪些是不支持的
URL 的结构 URL 由多个部分组成,包括协议、域名、路径、查询参数和片段标识符,其中,查询参数部分就是问号后面的内容,这部分使用键值对,中间用 & 分隔。比如,http://example.com/path?key1value1&…...

bingAI生成的易语言编程基础
易语言编程基础 易语言(EPL)是一种基于中文的编程语言,旨在简化编程学习过程,特别适合初学者和有一定编程基础的开发者。它通过中文关键词和语法,降低了编程的门槛,使得代码更加直观易懂。 示例ÿ…...

HTML应用指南:利用POST请求获取接入比亚迪业态的充电桩位置信息
在新能源汽车快速发展的今天,充电桩的分布和可用性成为了影响用户体验的关键因素之一。比亚迪作为全球领先的新能源汽车制造商,不仅在车辆制造方面取得了卓越成就,也在充电基础设施建设上投入了大量资源。为了帮助用户更方便地找到比亚迪充电桩的位置,本篇文章,我们将探究…...

高斯消元法及其C++实现
深入浅出高斯消元法及其C实现 本文章代码由博主编写但是文章由ChatGPT-o1-mini生成 博客食用更佳 在计算机算法竞赛中,线性方程组的求解是一个常见且基础的问题。高斯消元法作为一种经典的算法,因其高效和直观的特性,广泛应用于各种编程竞赛和…...

DeepSeek AI R1推理大模型API集成文档
DeepSeek AI R1推理大模型API集成文档 引言 随着自然语言处理技术的飞速发展,大语言模型在各行各业的应用日益广泛。DeepSeek R1作为一款高性能、开源的大语言模型,凭借其强大的文本生成能力、高效的推理性能和灵活的接口设计,吸引了大量开发…...

【算法-动态规划】、魔法卷轴: 两次清零机会整个数组最大累加和
【算法-动态规划】、魔法卷轴: 两次清零机会整个数组最大累加和 文章目录 一、dp1.1 题意理解1.2 整体思路1.3 具体思路1.4 代码 二、多语言解法 一、dp 1.1 题意理解 nums 数组, 有正负0, 使用最多两次魔法卷轴, 希望使数组整体的累加和尽可能大. 求尽可能大的累加和 其实就…...

【R】Dijkstra算法求最短路径
使用R语言实现Dijkstra算法求最短路径 求点2、3、4、5、6、7到点1的最短距离和路径 1.设置data,存放有向图信息 data中每个点所在的行序号为起始点序号,列为终点序号。 比如:值4的坐标为(1,2)即点1到点2距离为4;值8的坐标为(6,7)…...

深入浅出:探索 DeepSeek 的强大功能与应用
深入浅出:探索 DeepSeek 的强大功能与应用 在人工智能技术飞速发展的今天,自然语言处理(NLP)作为其重要分支,正逐渐渗透到我们生活的方方面面。DeepSeek 作为一款功能强大的 NLP 工具,凭借其易用性和高效性…...

西门子S7-200 PLC串口PPI转以太网通讯的模块链接方式
项目背景 某汽车零部件生产车间有30台自动化生产设备,控制系统采用西门子S7-200系列的CPU226。此前,设备的一个通讯端口用于和变频器进行自由口通讯,另一个通讯端口连接着一台昆仑通态触摸屏作为人机界面。车间计划进行智能化升级ÿ…...

win10向windows server服务器传输文件
win10向windows server服务器传输文件 遇到无法直接拖动文件进行传输时 解决方案: 1.点击显示选项 2.点击本地资源-详细信息 3.在窗口中选择你需要共享的磁盘 4.然后远程连接到Windows server服务器 5.登录Windows server服务器后,在此电脑下就能看…...

git服务器搭建,gitea服务搭建,使用systemclt管理服务
文章目录 页面展示使用二进制文件安装git服务下载选择架构使用wget下载安装 验证 GPG 签名服务器设置准备环境创建systemctl文件 备份与恢复备份命令 (dump)恢复命令 (restore) 页面展示 使用二进制文件安装git服务 所有打包的二进制程序均包含 SQLite,MySQL 和 Po…...
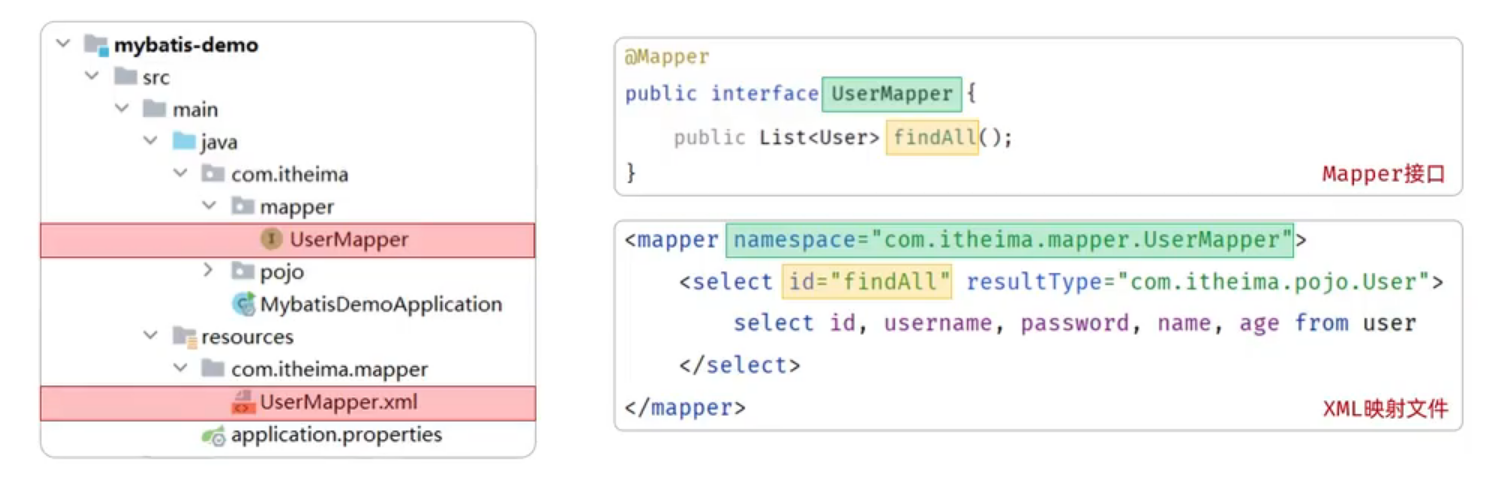
Mybatis快速入门与核心知识总结
Mybatis 1. 实体类(Entity Class)1.1 实体类的定义1.2 简化编写1.2.1 Data1.2.2 AllArgsConstructor1.2.3 NoArgsConstructor 2. 创建 Mapper 接口2.1 Param2.2 #{} 占位符2.3 SQL 预编译 3. 配置 MyBatis XML 映射文件(可选)3.1 …...

用docker在本地用open-webui部署网页版deepseek
前置条件 用Ollama在本地CMD窗口运行deepseek大模型-CSDN博客文章浏览阅读109次,点赞5次,收藏2次。首次运行需要下载deepseek的大模型包(大约5GB,根据本地网速的不同在半个小时到几个小时之间下载完成) ,并…...

2025.2.8——一、[护网杯 2018]easy_tornado tornado模板注入
题目来源:BUUCTF [护网杯 2018]easy_tornado 目录 一、打开靶机,整理信息 二、解题思路 step 1:分析已知信息 step 2:目标——找到cookie_secret step 3:构造payload 三、小结 一、打开靶机,整理信…...

前端实现在PDF上添加标注(1)
前段时间接到一个需求,用户希望网页上预览PDF,同时能在PDF上添加文字,划线,箭头和用矩形框选的标注,另外还需要对已有的标注进行修改,删除。 期初在互联网上一通搜索,对这个需求来讲发现了两个问…...

【CXX-Qt】1.1 Rust中的QObjects
本文涉及到了使用CXX-Qt将Rust、C和QML集成到Qt应用程序中的各个方面。下面,我将提供一个简单的示例,演示如何使用CXX-Qt来创建一个Rust结构体并将其作为QObject子类暴露给C和QML。 一、设置CXX-Qt环境 首先,确保您已经安装了Rust、CXX和CX…...

操作系统中的任务调度算法
一、引言 在操作系统中,任务调度算法是核心组件之一,它负责合理分配有限的 CPU 资源,以确保系统的高效运行和良好的用户体验。任务调度的目标是实现公平性、最小化等待时间、提高系统吞吐量,并最大化 CPU 的利用率。不同的任务调…...

GitCode 助力 Easy-Es,革新 Elasticsearch 开发体验
项目仓库(点击阅读原文链接可直达) https://gitcode.com/dromara/easy-es 项目背景:填补 Elasticsearch ORM 框架空白 在 Java 开发领域,Excel 和 Elasticsearch 的代码编写难度一直名列前茅,尤其是 Elasticsearch&a…...
)
线程同步(互斥锁与条件变量)
文章目录 1、为什么要用互斥锁2、互斥锁怎么用3、为什么要用条件变量4、互斥锁和条件变量如何配合使用5、互斥锁和条件变量的常见用法 参考资料:https://blog.csdn.net/m0_53539646/article/details/115509348 1、为什么要用互斥锁 为了使各线程能够有序地访问公共…...

EF Core中实现值对象
目录 值对象优点 值对象的需求 值类型的实现 值类型GEO的实现 值类型MultilingualString的实现 案例:构建表达式树,简化值对象的比较 值对象优点 把有紧密关系的属性打包为一个类型把领域知识放到类的定义中 class shangjia {long id;string nam…...

《从入门到精通:蓝桥杯编程大赛知识点全攻略》(十一)-回文日期、移动距离、日期问题
前言 在这篇博客中,我们将通过模拟的方法来解决三道经典的算法题:回文日期、移动距离和日期问题。这些题目不仅考察了我们的基础编程能力,还挑战了我们对日期处理和数学推理的理解。通过模拟算法,我们能够深入探索每个问题的核心…...

Kubernetes 最佳实践:Top 10 常见 DevOps/SRE 面试问题及答案
1. 如何在 Kubernetes 中设置资源请求和限制? 资源请求确保容器有最小资源量(CPU/内存),而限制则强制容器消耗的最大资源量。这有助于高效资源分配并防止资源争用。 示例: resources:requests:memory: "256Mi&…...

Docker Compose介绍及安装使用MongoDB数据库详解
在现代容器化应用部署中,Docker Compose是一种非常实用的工具,它允许我们通过一个docker-compose.yml文件来定义和运行多容器应用程序。然而,除了Docker之外,Podman也提供了类似的工具——Podman Compose,它允许我们在…...

科普:数据仓库中的“指标”和“维度”
在数据仓库中,指标和维度是两个核心概念,它们对于数据分析和业务决策至关重要。以下是对这两个概念的分析及举例说明: 一、指标 定义: 指标是用于衡量业务绩效的关键数据点,通常用于监控、分析和优化企业的运营状况。…...

11.swagger使用
菜单位置 未登录接口会返回401 登录的token存储的位置 配置文件swagger配置中将/dev-api修改/...

java高级知识之集合
前言 集合是java开发中的重点内容,需要掌握的东西很多,面试中可问的东西很多,无论是深度还是广度。集合框架中Collection对应的实现类如下所示,这些都是要完全掌握,一个可以分为三大类List集合、Set‘集合以及Map集合…...