Redis 的缓存雪崩、缓存穿透和缓存击穿详解,并提供多种解决方案
本文是对 Redis 知识的补充,在了解了如何搭建多种类型的 Redis 集群,并清楚了 Redis 集群搭建的过程的原理和注意事项之后,就要开始了解在使用 Redis 时可能出现的突发问题和对应的解决方案。
引言:虽然 Redis 是单线程的,但它可以通过使用非阻塞 I/O 去高效地处理大量并发连接。具有事件驱动机制,可以基于事件循环机制,达到快速响应各种请求。另外,在 Redis 6.0 引入了多线程 I/O,可以利用多核 CPU 提高网络 I/O 的效率,是市面上高效的 NoSQL 缓存组件。尤其是在分布式系统中,Redis 缓存经常被用来减轻数据库的负载,提高系统的响应速度。
在具有高并发的项目环境或者秒杀环境等,前台会产生超量的请求到缓存或者数据库或者项目突然出现攻击,攻击者对某一个缓存键发起大量请求,或者缓存中不存在的数据直接命中数据库等情况。这些情况必定会导致系统性能下降,甚至完全崩溃。下面就常见的三个问题作解释。
文章目录
- 一、什么是缓存雪崩?
- 二、怎么解决缓存雪崩
- 1、缓存预热(主要)
- 2、过期时间错峰(主要)
- 3、加锁控制对某个缓存的读线程数量
- 4、设置二级缓存
- 5、设置合理的 Redis 集群
- 6、降级限流
- 三、什么是缓存穿透?
- 四、怎么解决缓存穿透
- 1、缓存空值(主要)
- 2、布隆过滤器(主要)
- 3、增强数据的合法性校验(主要)
- 4、使用分布式锁
- 5、限流和熔断
- 6、设置热点数据永不过期
- 7、二级缓存
- 五、什么是缓存击穿?
- 六、怎么解决缓存击穿
- 1、设置热点数据过期时间
- 2、使用布隆过滤器
- 3、使用互斥锁(分布式锁)
- 4、使用逻辑过期
- 5、本地缓存和Redis缓存(二级缓存)
- 七、总结
一、什么是缓存雪崩?
缓存雪崩是指大量缓存数据在同一时间段失效,导致所有请求都涌向数据库,引发数据库崩溃,或者 Redis 宕机导致缓存系统失效。
这个问题的触发是具有条件性的,这个请况的出现原因在于高并发访问时,Redis 创建缓存时每一秒接收到的数据量大,同时这批数据又设置了相同的过期时间,导致的大量缓存数据在同一时间段失效。
所造成的危害就是数据库瞬间承载大量压力,可能直接导致数据库崩溃,系统性能急剧下降,用户体验变差。

二、怎么解决缓存雪崩
那如何避免或者解决这种情况呢?上述情况通常可以分为以下几种,我们要做多种措施,保证不会出现缓存雪崩的情况。
1、缓存预热(主要)
Redis 启动时是没有缓存任何数据的,在后续的时间就可能面临大量热点数据的请求,这时没有相应缓存,会全部命中数据库,造成数据库性能出现问题。这个的解决办法一般是 缓存预热 。
缓存预热就是系统上线时提前将相关的缓存数据直接加载到缓存系统,而不是等到用户请求的时候才将查询数据缓存,这样用户可直接查询事先被预热的数据。这样部署项目一般都在不常访问的时间段,提前缓存热点数据,在后续的时间就不会面临大量访问数据库的情况。
2、过期时间错峰(主要)
缓存预热并不能根本解决问题,在 新热点数据 出现时还是会出现缓存雪崩,例如某些黑料的出现等,这时就需要探究缓存大批失效的根本能问题。
热点数据同时失效的根本原因在于创建缓存时设置的过期时间是固定的,这种方式就会造成一批生成、一批失效。同一批创建的缓存可以 在固定的过期时间加上一个时间的随机值 ,按照项目要求设置随机值范围,就可以避免同时失效。
3、加锁控制对某个缓存的读线程数量
在缓存失效后,通过加锁或者队列的方式,来控制读数据库和写缓存的线程数量,例如对于某个 Key ,只允许一个线程查询数据和写缓存,其他线程等待。
4、设置二级缓存
设置二级缓存或者双缓存策略,A1为原始缓存,A2为拷贝缓存,A1失效后可以访问A2,A1缓存失效的时间可以设置短期,A2缓存可以设置为长期。其中A2可以是热点缓存,将A1中的热点缓存记录并放入A2,应对突发情况。
5、设置合理的 Redis 集群
使用高可用架构,根据自己系统的业务能力,合理设计Redis集群,例如:
- 小型系统就是用一主一从的集群架构。
- 对实时性要求不高并且有一定并发问题的系统就使用一主多从的集群架构。
- 对于实时性要求高,存在高并发的系统使用多主多从的集群架构。
不同的集群架构会合理使用主从复制功能和哨兵模式来避免单点故障和因某个主节点崩溃而导致的系统问题。
6、降级限流
对于出现缓存雪崩后的补救措施可以使用服务降级和请求限流等机制进行补救。服务降级的最终目的就是保证核心服务可用,即使是有损的。服务降级应当提前确定好哪些服务是可降级的,不同情况下不同的服务的优先级也不同。
具体做法可以拒接服务,延迟服务和随即提供服务,或者说禁用某些功能或者禁用某些功能模块。
三、什么是缓存穿透?
缓存穿透是指客户端查询一个缓存中不存在的键,由于缓存中无数据,无法命中,所以每次查询都会直接访问数据库,并且数据库中也没有数据,这样就导致缓存一直无法生效,从而导致数据库负载增加,产生压力过大的情况。

用户第一次请求,缓存没数据就会触发写缓存操作,第二次请求就会命中缓存。这种问题造成的危害是数据库负载增加,可能引发性能问题,恶意请求可能频繁访问数据库,导致资源浪费。例如如发起为 id 为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
四、怎么解决缓存穿透
1、缓存空值(主要)
顾名思义,就是收到一个查询后,发现缓存和数据库都没有要查询的数据,这时就将查询的数据以 null 值缓存到 Redis 中。
具体来说,当客户端访问数据时,先请求 Redis,但 Redis 中没有数据,这时会访问数据库,但是数据库中也没有数据。因此这个数据穿透了缓存,直击数据库,并且这种状态下该数据还无法生成缓存。
如果大量的请求同时访问这种不存在的数据,那么这些请求就都会访问到数据库,由于数据库能够承载的并发不如 Redis ,就会出现数据库性能出现问题。
解决方案对于数据库中不存在的数据如果被查询到了,就把这个数据存入到 Redis 缓存中去,下次用户过来访问这个不存在的数据,就能在 Redis 缓存中找到。
这种方式也会产生问题,面临大量的恶意请求,会导致缓存逐渐增加,进而影响服务性能,另外,如果该数据被写入到数据库中,缓存还是null值,会造成数据的短期不一致。
2、布隆过滤器(主要)
布隆过滤器是一种基于哈希算法的数据结构,用于快速判断一个元素是否存在于一个集合中。在请求到达缓存之前,先通过布隆过滤器判断该请求是否合法。如果布隆过滤器判断该请求不存在,则直接返回,避免查询数据库。
布隆过滤器的大致原理:布隆过滤器中存放二进制位,数据库的数据通过哈希算法计算其哈希值并存放到布隆过滤器中,后面判断该数据是否存在的时候,就是查找该数据的哈希值是 0 还是 1 。这是一种概率上的统计,能够保证该数据被判断不存在的时候就一定是不存在,被判断存在的时候不一定存在,存在一定的穿透风险。
优点是内存占用较少,适合处理大规模数据,Redis 缓存中也不会存储多余的键。但是实现相对复杂,并且存在一定的误判率,但可以通过调整布隆过滤器的参数来降低误判率。
3、增强数据的合法性校验(主要)
在请求到达缓存和数据库之前,增加对请求参数的合法性校验。例如,对于用户ID的请求,可以校验ID是否符合预期的格式或范围。如果参数不合法,则直接返回错误,避免不必要的查询。
4、使用分布式锁
在缓存穿透的场景下,当多个请求同时发现缓存中没有数据时,可以使用分布式锁(如 Redis 的 SETNX 命令)来确保只有一个请求去数据库查询数据并更新缓存,其他请求等待锁释放后直接从缓存获取数据。
5、限流和熔断
对于高频请求,可以采用限流策略,限制单位时间内对某个接口的访问次数。当请求量超过阈值时,直接返回错误或排队等待。此外,还可以结合熔断机制,在缓存穿透导致数据库压力过大时,暂时停止对数据库的访问。
6、设置热点数据永不过期
对于一些热点数据(如热门商品信息),可以设置其缓存永不过期,或者通过后台线程定期更新缓存。这样可以避免因缓存过期而导致的缓存穿透问题。
7、二级缓存
也可以采用缓存雪崩中的二级缓存解决办法,A1为原始缓存,A2为拷贝缓存,A1失效后可以访问A2,A1缓存失效的时间可以设置短期,A2缓存可以设置为长期。其中A2可以是热点缓存,将A1中的热点缓存记录并放入A2,应对突发情况。
不同的解决方案适用于不同的场景,可以根据实际需求选择合适的方法。例如,对于小规模应用,缓存空对象或增强数据校验可能足够;而对于大规模高并发系统,布隆过滤器或分布式锁可能是更好的选择。
五、什么是缓存击穿?
缓存击穿,是指一个 Key 在不停地支撑着高并发,高并发集中对这一个点进行访问,当这个 Key 在失效的瞬间,持续的高并发就穿破缓存,直接请求数据库。缓存击穿和缓存雪崩的区别在于缓存击穿是针对某一个 Key 缓存而盲,缓存雪崩则是针对很多 Key。

六、怎么解决缓存击穿
首先要知道缓存击穿出现的场景,才好使用对应的解决方案,缓存击穿是指一个 Key 在不停地支撑着高并发,高并发集中对这一个点进行访问,当这个 Key 在失效的瞬间,持续的高并发就穿破缓存,直接请求数据库。
对一般的网站而言,很难有一个 Key 能达到缓存击穿的级别,一般是热门网站的秒杀或爆款商品,才有可能发生这种情况。当发生缓存击穿时,在这个 Key 没有被重新加载到缓存之前,或者过期时间超过抢购时段时是一种很好的避免发生缓存击穿的方法,这时这种可以不需要考虑数据一致性的问题的话。
1、设置热点数据过期时间
首先在秒杀环境中,设置 Key 的过期时间超过秒杀的时间是最好的一种办法,或者对于热点数据,可以设置其缓存永不过期,通过后台线程定期更新缓存。这就不会出现缓存击穿的情况,但是可能会出现数据不一致问题。
// 设置热点数据永不过期
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(data));// 后台线程定期更新缓存
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
scheduler.scheduleAtFixedRate(() -> {Object newData = queryDatabase(key);setCache(key, newData);
}, 0, 10, TimeUnit.MINUTES);
2、使用布隆过滤器
布隆过滤器是用于快速判断一个元素是否存在于一个集合中。首先初始化布隆过滤器,将所有可能的Key加入布隆过滤器,在请求到达缓存之前,先通过布隆过滤器判断该请求是否合法。如果布隆过滤器判断该请求不存在,则直接返回,避免查询数据库。在缓存穿透的解决方案中也推荐过这种方法。
// 初始化布隆过滤器
BloomFilter<String> bloomFilter = new BloomFilter<>(100000, 0.01);
bloomFilter.add("hotKey1");
bloomFilter.add("hotKey2");// 查询缓存
if (!bloomFilter.contains(key)) {return null; // Key不存在,直接返回
}
String json = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(json)) {return JSONUtil.toBean(json, type);
}
3、使用互斥锁(分布式锁)
在查询缓存时,如果发现缓存失效,尝试获取分布式锁。通过分布式锁(如Redis的SETNX命令)确保只有一个线程去查询数据库并更新缓存,其他线程等待锁释放后直接从缓存获取数据。如果获取锁成功,则查询数据库并更新缓存。如果获取锁失败,则等待锁释放后再次查询缓存。
String lockKey = "lock:" + key;
boolean isLock = tryLock(lockKey);
if (isLock) {// 查询数据库并更新缓存Object data = queryDatabase(key);setCache(key, data);
} else {// 等待锁释放后再次查询缓存Thread.sleep(50);return queryCache(key);
}
4、使用逻辑过期
逻辑过期是指在缓存中存储数据时,将数据和过期时间一起存储。当查询缓存时,先检查数据是否过期,如果未过期,直接返回数据,如果已过期,启动独立线程去更新缓存,同时返回旧数据。这样做的优点在于即使缓存已过期,也可以先返回旧数据。
@Data
public class RedisData {private LocalDateTime expireTime;private Object data;
}// 查询缓存
String json = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(json)) {RedisData redisData = JSONUtil.toBean(json, RedisData.class);if (redisData.getExpireTime().isAfter(LocalDateTime.now())) {return redisData.getData();} else {// 启动独立线程更新缓存CACHE_REBUILD_EXECUTOR.submit(() -> {try {Object newData = queryDatabase(key);setCacheWithLogicalExpire(key, newData, expireTime);} catch (Exception e) {throw new RuntimeException(e);}});return redisData.getData(); // 返回旧数据}
}
5、本地缓存和Redis缓存(二级缓存)
采用多级缓存架构,在本地缓存中存储热点数据,先查询本地缓存,如果本地缓存失效,则查询Redis缓存。
// 查询本地缓存
Object data = localCache.get(key);
if (data == null) {// 查询Redis缓存String json = stringRedisTemplate.opsForValue().get(key);if (StrUtil.isNotBlank(json)) {data = JSONUtil.toBean(json, type);localCache.put(key, data); // 更新本地缓存}
}
return data;
不同的解决方案适用于不同的场景,可以根据实际需求选择合适的方法。
- 互斥锁适用于缓存失效时需要保护数据库的场景。
- 逻辑过期适用于需要快速返回数据且对数据实时性要求不高的场景。
- 热点数据永不过期适用于热点数据频繁访问的场景。
- 布隆过滤器适用于数据量大且需要快速判断Key是否存在的场景。
- 多级缓存适用于需要进一步减轻数据库压力的场景。
七、总结
看到最后的读者也明白了,缓存雪崩、缓存穿透和缓存击穿出现的场景各有不同,但是解决办法都是存在一定的共同点,相似的解决方案基本都是辅助解决问题,而对于不同场景独特的解决方案才是解决该问题的核心。在各种解决方案中,大家一定要注意数据的实时性和一致性,在保障了这两个前提下才能更好的解决问题,实现高可用的系统。
相关文章:
Redis 的缓存雪崩、缓存穿透和缓存击穿详解,并提供多种解决方案
本文是对 Redis 知识的补充,在了解了如何搭建多种类型的 Redis 集群,并清楚了 Redis 集群搭建的过程的原理和注意事项之后,就要开始了解在使用 Redis 时可能出现的突发问题和对应的解决方案。 引言:虽然 Redis 是单线程的…...

Docker使用指南与Dockerfile文件详解:从入门到实战
Docker使用指南与Dockerfile文件详解:从入门到实战 文章目录 **Docker使用指南与Dockerfile文件详解:从入门到实战****引言****第一部分:Docker 核心概念速览****1. Docker 基础架构****2. Docker 核心命令****第二部分:Dockerfile 文件深度解析****1. Dockerfile 是什么?…...

如何在个人电脑本地化部署Deepseek-R1大模型
文章目录 Deepseek概述公司简介DeepSeek模型优势DeepSeek模型发展历史Ollama安装Deepseek版本选择Deepseek支持的客户端工具编程语言客户端库桌面客户端插件类其他工具客户端工具配置cherryStudio配置测试如何使用DeepSeek满血版什么是 DeepSeek R1 满血版?deepseek官方第三方…...

DeepSeek-R1复现方案梳理
open-r1 项目地址:https://github.com/huggingface/open-r1 由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deepseek的指标,可以在open-r1/open-r1-eval-leaderboard查看指标的…...

【Redis】 - Redis的Bitmap实现用户签到
Redis的Bitmap实现用户签到 使用Redis的Bitmap数据结构来记录用户的每日签到状态是一种高效且节省空间的方法。通过将用户ID和日期结合生成动态Key,可以轻松管理不同用户在不同日期的签到情况。下面详细介绍如何设计这一方案。 设计思路 动态Key生成:根…...

用php tp6对接钉钉审批流的 table 表格 明细控件 旧版sdk
核心代码 foreach ($flows[product_list] as $k>$gift) {$items_list[] [[name > 商品名称, value > $gift[product_name] ?? ],[name > 规格, value > $gift[product_name] ?? ],[name > 数量, value > $gift[quantity] ?? ],[name > 单位, v…...

使用DeepSeek建立一个智能聊天机器人0.07
进一步完善获取API密钥和DeepSeek的API端点,我们可以添加更多的错误处理和默认值设置,确保程序在各种情况下都能正常运行。同时,我们还可以提供一个更友好的用户界面,以便用户可以轻松地设置和查看配置信息。 以下是进一步完善的…...

PySpark查找Dataframe中的非ASCII字符并导出Excel文件
from pyspark.sql import SparkSession from pyspark.sql.types import StringType from pyspark.sql.functions import udf, col from pyspark.sql.types import BooleanType import pandas as pd# 初始化Spark会话 spark SparkSession.builder.appName("StringFilter&q…...

大模型RLHF:PPO原理与源码解读
大模型RLHF:PPO原理与源码解读 原文链接:图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 本文直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训…...

SQLite 数据库:优点、语法与快速入门指南
文章目录 一、引言二、SQLite 的优点 💯三、SQLite 的基本语法3.1 创建数据库3.2 创建表3.3 插入数据3.4 查询数据3.5 更新数据3.6 删除数据3.7 删除表 四、快速入门指南4.1 安装 SQLite4.2 创建数据库4.3 创建表4.4 插入数据4.5 查询数据4.6 更新数据4.7 删除数据4…...

pytorch笔记:mm VS bmm
1 bmm (batch matrix multiplication) 批量矩阵乘法,用于同时处理多个矩阵的乘法bmm 的输入是两个 3D 张量(batch of matrices),形状分别为 (batch_size, n, m) 和 (batch_size, m, p)bmm 输出的形状是 (batch_size, n, p) 2 mm…...
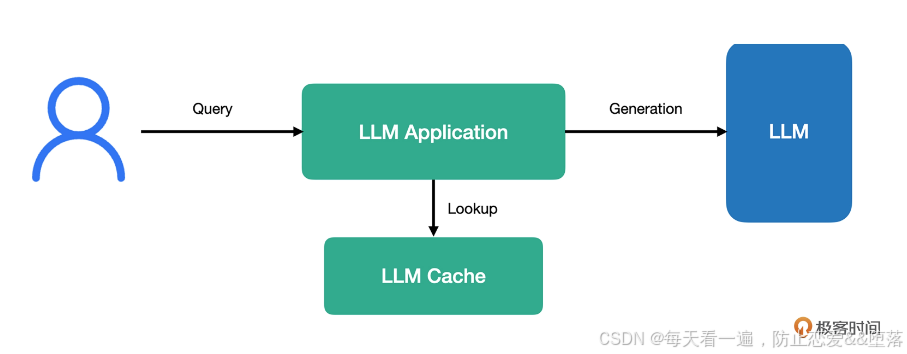
5、大模型的记忆与缓存
文章目录 本节内容介绍记忆Mem0使用 mem0 实现长期记忆 缓存LangChain 中的缓存语义缓存 本节内容介绍 本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义…...

LangChain系列:LangChain基础入门教程
LangChain 是一个开源框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。它为链提供了标准接口,与许多其他工具进行了集成,并为常见应用提供了端到端的链。 LangChain 让 AI 开发人员能够基于大型语言模型&#…...

修改docker内容器中的某配置文件的命令
先找到配置文件config.php find / -name "config.php" 2>/dev/null 然后用vi编辑器修改配置文件 vi /var/www/config.php 最后就是vi的基本操作,根据具体需求使用: vi 有两种主要模式: 命令模式:进入 vi 后的默认…...

无人机遥感图像拼接及处理实践技术:生态环境监测、农业、林业等领域,结合图像拼接与处理技术,能够帮助我们更高效地进行地表空间要素的动态监测与分析
近年来,无人机技术在遥感领域的应用越来越广泛,尤其是在生态环境监测、农业、林业等领域,无人机遥感图像的处理与分析成为了科研和业务化工作中的重要环节。通过无人机获取的高分辨率影像数据,结合图像拼接与处理技术,…...

基于Springmvc+MyBatis+Spring+Bootstrap+EasyUI+Mysql的个人博客系统
基于SpringmvcMyBatisSpringBootstrapEasyUIMysql的个人博客系统 1.项目介绍 使用Maven3Spring4SpringmvcMybatis3架构;数据库使用Mysql,数据库连接池使用阿里巴巴的Druid;使用Bootstrap3 UI框架实现博客的分页显示,博客分类&am…...

Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式
目录 引言 一、ViT模型的起源和历史 二、什么是ViT? 图像处理流程 图像切分 展平与线性映射 位置编码 Transformer编码器 分类头(Classification Head) 自注意力机制 注意力图 三、Coovally AI模型训练与应用平台 四、ViT与图像…...

Tailwind CSS 的核心理念
实用优先(Utility-First) Tailwind CSS 的最核心理念是"实用优先"。这种方法颠覆了传统的 CSS 开发方式,不再编写自定义的类名和样式规则,而是通过组合预定义的工具类来构建界面。这种方式带来了以下优势: …...

软考高级《系统架构设计师》知识点(二)
操作系统知识 操作系统概述 操作系统定义:能有效地组织和管理系统中的各种软/硬件资源,合理地组织计算机系统工作流程,控制程序的执行,并且向用户提供一个良好的工作环境和友好的接口。操作系统有三个重要的作用: 管理…...

DeepSeek的魔法:如何让复杂概念变得通俗易懂?
日常生活中,常常会被复杂的概念所困扰。怎么样将这些晦涩难懂的概念变得通俗易懂?当然是利用大模型帮我们解答,不过让大模型解答也需要有好的沟通提示词。 我收集整理了 2 套提示词,大家一起学习一下。 一、用推理模型解释概…...

地弹噪声【信号完整性】
地弹、振铃、串扰、信号反射 地弹,就是地噪声! 低频时,地噪声主要是因为构成地线的导体有“电阻”,电路系统的电流都要流经地线而产生的电势差波动。 高频时,地噪声主要是因为构成地线的导体有“电感”,电路系统的电流快速变化地经过这个“电感”时,“电感”两端激发…...

【大模型】阿里云百炼平台对接DeepSeek-R1大模型使用详解
目录 一、前言 二、DeepSeek简介 2.1 DeepSeek 是什么 2.2 DeepSeek R1特点 2.2.1 DeepSeek-R1创新点 2.3 DeepSeek R1应用场景 2.4 与其他大模型对比 三、阿里云百炼大平台介绍 3.1 阿里云百炼大平台是什么 3.2 阿里云百炼平台主要功能 3.2.1 应用场景 3.3 为什么选…...

如何在 React 中使用 CSS Modules?
在 React 中使用 CSS Modules 是一种模块化 CSS 的方式,可以避免类名冲突,并为每个组件提供独立的样式。以下是如何在 React 项目中使用 CSS Modules 的步骤: 1. 创建 React 应用 如果你还没有创建一个 React 应用,可以使用 Create React App: npx create-react-app my…...

技术革新让生活更便捷
量子通信是一种利用量子力学原理进行信息传递的技术。它的基本原理是量子纠缠和量子密钥分发。量子纠缠指两个粒子即使相隔很远,一个粒子的状态改变会立刻引起另一个粒子状态的相应变化。量子密钥分发则是通过量子态传输实现加密密钥的安全交换。 在信息安全领域&a…...

但书条款与格式条款
但书条款与格式条款 一、定义 但书条款: 但书条款是指在法律条文中,对一般规定作出例外或补充说明的条款。通常以“但”字开头,表示在特定情况下不适用一般规定。例如,《民法典》第465条第二款规定:“依法成立的合同…...

相似性图相关性重构网络用于无监督跨模态哈希
《Similarity Graph-correlation Reconstruction Network for unsupervised cross-modal hashing》 摘要1. 引言2. 相关工作2.1. 监督跨模态哈希方法2.2. 无监督跨模态哈希方法 3. 方法论3.1 问题定义3.2 特征提取3.3 模态内关系图构建3.4. 局部关系图重置3.5. 跨模态关系图构建…...

问卷数据分析|SPSS实操之单因素方差分析
适用条件: 检验分类变量和定量变量之间的差异 分类变量数量要大于等于三 具体操作: 1.选择分析--比较平均值--单因素ANOVA检验 2. 下方填分类变量,上方为各个量表数据Z1-Y2 3. 点击选项,选择描述和方差齐性检验 4.此处为结果数…...

并发编程---多线程不安全示例以及解决,多线程创建方式
文章目录 并发并行多线程为什么需要多线程线程不安全示例并发出现问题的根源: 并发三要素可见性: CPU 缓存引起原子性:分时复用引起有序性: 重排序引起 线程不安全示例的解决方法使用AtomicLong类使用synchronized 关键字 改进代码避免不必要的延迟join()方法为什么…...

多模态模型详解
多模态模型是什么 多模态模型是一种能够处理和理解多种数据类型(如文本、图像、音频、视频等)的机器学习模型,通过融合不同模态的信息来提升任务的性能。其核心在于利用不同模态之间的互补性,增强模型的鲁棒性和准确性。 如何融合…...

从零到一:开发并上线一款极简记账本小程序的完整流程
从零到一:开发并上线一款极简记账本小程序的完整流程 目录 前言需求分析与功能设计 2.1 目标用户分析2.2 核心功能设计2.3 技术栈选择 开发环境搭建 3.1 微信开发者工具安装与配置3.2 项目初始化3.3 版本控制与协作工具 前端开发 4.1 页面结构与布局4.2 组件化开发…...