【推理llm论文精读】DeepSeek V3技术论文_精工见效果
先附上原始论文和效果对比https://arxiv.org/pdf/2412.19437

摘要 (Abstract)
DeepSeek-V3是DeepSeek-AI团队推出的最新力作,一个强大的混合专家(Mixture-of-Experts,MoE)语言模型。它拥有671B的总参数量,但每个token仅激活37B参数,实现了效率和性能的平衡。DeepSeek-V3在架构上采用了多头潜注意力(Multi-head Latent Attention, MLA)和DeepSeekMoE,并在训练策略上进行了创新,引入了无辅助损失的负载均衡和多token预测目标。经过14.8万亿token的预训练,以及监督微调和强化学习阶段,DeepSeek-V3在多项评估中超越了其他开源模型,并在某些任务上达到了与领先闭源模型相媲美的水平。更令人印象深刻的是,DeepSeek-V3的训练成本极低,整个训练过程仅需2.788M H800 GPU小时,且训练过程非常稳定。
1. 引言 (Introduction)
大型语言模型(LLMs)的发展日新月异,不断缩小与通用人工智能(AGI)的差距。DeepSeek-V3的发布,进一步推动了开源模型的发展。它不仅在性能上表现出色,而且在训练效率和成本控制方面也树立了新的标杆。
本文将深入剖析DeepSeek-V3的各个方面,包括模型结构、预训练、后训练和推理部署,揭示其创新之处和实现逻辑。
2. 模型结构 (Architecture)

DeepSeek-V3的架构设计有两大核心目标:
- 高效推理 (Efficient Inference): 通过多头潜注意力(MLA)实现。
- 经济训练 (Economical Training): 通过DeepSeekMoE实现。
此外,DeepSeek-V3还引入了多token预测 (Multi-Token Prediction, MTP) 训练目标,进一步提升模型性能。
2.1 多头潜注意力 (Multi-Head Latent Attention, MLA)
MLA是DeepSeek-V2中首次提出的注意力机制,旨在减少推理过程中的KV缓存大小。其核心思想是对Key和Value进行低秩联合压缩。
MLA的计算过程如下:
-
Key和Value的压缩:
- 计算潜向量:
cKV = WDKV * ht(WDKV是降维矩阵,ht是输入) - 计算压缩后的Key:
[k1; k2; ...; knh] = k = WUK * cKV - 计算解耦Key (用于RoPE):
k = ROPE(WKR * ht) - 将压缩后的Key和解耦Key拼接:
kt,i = [k; k] - 计算压缩后的Value:
[v1; v2; ...; vnh] = v = WUV * cKV
- 计算潜向量:
-
Query的压缩(训练时):
- 计算潜向量:
c = WDQ * ht - 计算压缩后的Query:
[q1; q2; ...; qnh] = q = WUQ * c - 计算解耦Query (用于RoPE):
q = ROPE(WQR * c) - 将解耦Query进行切分:
qt,i = [q; q]
- 计算潜向量:
-
注意力计算:
ot,i = Softmax( (qt,i * kTi) / sqrt(dh + d) ) * vut = W0 * [ot,1; ot,2; ...; ot,nh]
MLA的优势:
- 减少KV缓存: 推理时只需缓存压缩后的潜向量
cKV和解耦Keyk,大大减少了KV缓存的大小。 - 保持性能: 在减少KV缓存的同时,MLA能够保持与标准多头注意力(MHA)相当的性能。
2.2 DeepSeekMoE
DeepSeekMoE是DeepSeek团队提出的一种MoE架构,相比于传统的MoE架构(如GShard),它具有以下特点:
- 更细粒度的专家 (Finer-grained Experts): 每个专家负责处理更小的计算量。
- 共享专家 (Shared Experts): 部分专家被所有token共享,处理通用知识。
- 无辅助损失的负载均衡 (Auxiliary-Loss-Free Load Balancing): 避免了辅助损失对模型性能的负面影响。
DeepSeekMoE的计算过程如下:
-
FFN输出:
h = ut + Σ FFN(s)(ut) + Σ git * FFN(r)(ut)
这里,FFN(s)表示共享专家,FFN(r)表示路由专家(routed experts),git表示路由权重。 -
路由权重计算:
git = { sit , sit ∈ Topk({sj,t | 1 ≤ j ≤ Nr}, Kr); 0, otherwise
sit = Sigmoid( ut * ei )
其中:
* `Ns`: 共享专家数量
* `Nr`: 路由专家数量
* `Kr`: 每个token激活的路由专家数量
* `ei`: 第i个路由专家的中心向量
* `Topk`函数选择亲和度(affinity)最高的K个专家。
-
无辅助损失负载均衡: DeepSeek-V3使用了一种创新的无辅助损失负载均衡策略。它为每个专家引入一个偏置项
bi,并将其添加到亲和度得分sit中,以确定top-K路由:s'i,t = { si,t + bi, si,t + bi ∈ Topk({sj,t + bj | 1 ≤ j ≤ Nr}, Kr); 0, otherwise }在训练过程,会动态调整每个专家偏置
b,过载则减小,负载不足则增加。 -
补充序列级辅助损失: 为了防止单个序列内的极端不平衡,DeepSeek-V3还引入了一个非常小的序列级辅助损失。
DeepSeekMoE的优势:
- 高效训练: 更细粒度的专家和共享专家机制使得计算更高效。
- 更好的负载均衡: 无辅助损失的负载均衡策略避免了性能损失,同时实现了更好的负载均衡。
2.3 多token预测 (Multi-Token Prediction, MTP)
DeepSeek-V3采用了MTP训练目标,这受到Gloeckle等人(2024)工作的启发。MTP扩展了预测范围,在每个位置预测多个未来的token。
MTP的实现:
-
MTP模块: DeepSeek-V3使用了D个串行的MTP模块来预测D个额外的token。每个MTP模块包含:
- 共享的嵌入层(Shared Embedding Layer)
- 共享的输出头(Shared Output Head)
- Transformer块
- 投影矩阵
-
计算过程: 对于第i个输入token ti,在第k个预测深度:
- 组合表示:
h = Mk * [RMSNorm(h-1); RMSNorm(Emb(ti+k))] - Transformer块:
h:T-k = TRMk(h) - 预测概率:
P = OutHead(h)
- 组合表示:
-
MTP训练目标: 对于每个预测深度,计算交叉熵损失
LMTP,最终的MTP损失是所有深度损失的加权平均。
MTP的优势:
- 增强信号: MTP提供了更密集的训练信号,有助于模型学习。
- 预规划: MTP可能使模型能够预先规划其表示,以更好地预测未来的token。
- 推理加速: MTP可用于推测解码,以提升推理速度。
3. 预训练 (Pre-Training)
DeepSeek-V3的预训练过程有以下几个关键点:
- 数据 (Data): 使用了14.8T高质量、多样化的token,并优化了数学和编程样本的比例,扩展了多语言覆盖。
- FIM (Fill-in-Middle): 采用了FIM策略,提高了模型处理上下文的能力。
- 超参数 (Hyper-Parameters): 采用了AdamW优化器,并使用了学习率调度和批大小调度策略。
- 稳定性 (Stability): 预训练过程非常稳定,没有出现不可恢复的损失峰值或回滚。
- 长上下文扩展: 采用两阶段上下文长度扩展,最终支持128K的上下文长度。
4. 后训练 (Post-Training)
DeepSeek-V3的后训练包括两个阶段:
-
监督微调 (Supervised Fine-Tuning, SFT):
- 数据: 使用了1.5M实例的多领域指令数据集。
- 推理数据生成: 采用了从DeepSeek-R1模型中蒸馏推理能力的方法。
- 非推理数据生成: 使用DeepSeek-V2.5生成响应,并由人工标注者进行验证。
-
强化学习 (Reinforcement Learning, RL):
- 奖励模型 (Reward Model, RM): 使用了基于规则的RM和基于模型的RM。
- 优化算法: 采用了Group Relative Policy Optimization (GRPO)算法。
5. 推理部署 (Inference and Deployment)
DeepSeek-V3的推理部署策略旨在同时保证在线服务的服务水平目标(SLO)和高吞吐量。
- 分离阶段: 将推理过程分为预填充(Prefilling)和解码(Decoding)两个阶段。
- 预填充:
- 采用4路张量并行(TP4)和8路数据并行(DP8)。
- MoE部分采用32路专家并行(EP32)。
- 使用冗余专家策略实现负载均衡。
- 同时处理两个微批次,以提高吞吐量。
- 解码:
- 采用TP4和DP80。
- MoE部分采用EP320。
- 使用直接点对点传输和IBGDA技术来减少延迟。
- 也采用冗余专家策略。
6. 创新点总结
DeepSeek-V3的创新点可以归纳为以下几点:
- 架构创新:
- MLA: 减少推理时的KV缓存。
- DeepSeekMoE: 更细粒度的专家、共享专家和无辅助损失的负载均衡。
- MTP: 多token预测目标,增强训练信号。
- 训练创新:
- FP8训练: 首次在超大规模模型上验证了FP8训练的可行性和有效性。
- DualPipe: 高效的流水线并行算法,实现了计算和通信的高度重叠。
- 跨节点All-to-All通信优化: 充分利用IB和NVLink带宽,减少通信开销。
- 内存优化: 通过重计算、CPU中的EMA、共享嵌入和输出头等技术,减少内存占用。
- 知识蒸馏: 从DeepSeek-R1中蒸馏长CoT(Chain-of-Thought)推理能力。
- 推理创新:
- 冗余专家: 动态调整专家部署,实现负载均衡。
- 分离阶段: 将预填充和解码分离,优化吞吐量和延迟。
7. 实验结果 (Evaluation Results)
DeepSeek-V3在多个基准测试中都取得了优异的成绩,包括:
- 知识: 在MMLU、MMLU-Pro、GPQA等教育基准测试中,DeepSeek-V3超越了所有其他开源模型,并接近领先的闭源模型。
- 代码、数学和推理: 在数学和编码基准测试中,DeepSeek-V3取得了SOTA性能。
- 长上下文: 在长上下文理解任务中,DeepSeek-V3表现出色。
- 中文能力: 在中文基准测试中,DeepSeek-V3表现出强大的竞争力。
- 开放式评估: 在Arena-Hard和AlpacaEval 2.0等开放式评估中,DeepSeek-V3也取得了优异的成绩。
8. 局限性与未来方向
论文中承认DeepSeek-V3存在一些局限性,主要是在部署方面:
- 部署资源要求高: 为了保证高效推理,DeepSeek-V3的推荐部署单元较大。
- 推理速度仍有提升空间: 虽然推理速度已经比DeepSeek-V2快两倍以上,但仍有优化潜力。
未来的研究方向包括:
- 进一步优化模型架构: 探索更高效的注意力机制和MoE架构。
- 数据扩展: 持续迭代训练数据,并探索更多样的训练信号来源。
- 深度思考能力: 增强模型的推理能力和问题解决能力。
- 更全面的评估方法: 探索更全面、多维度的模型评估方法。
相关文章:
【推理llm论文精读】DeepSeek V3技术论文_精工见效果
先附上原始论文和效果对比https://arxiv.org/pdf/2412.19437 摘要 (Abstract) DeepSeek-V3是DeepSeek-AI团队推出的最新力作,一个强大的混合专家(Mixture-of-Experts,MoE)语言模型。它拥有671B的总参数量,但每个tok…...
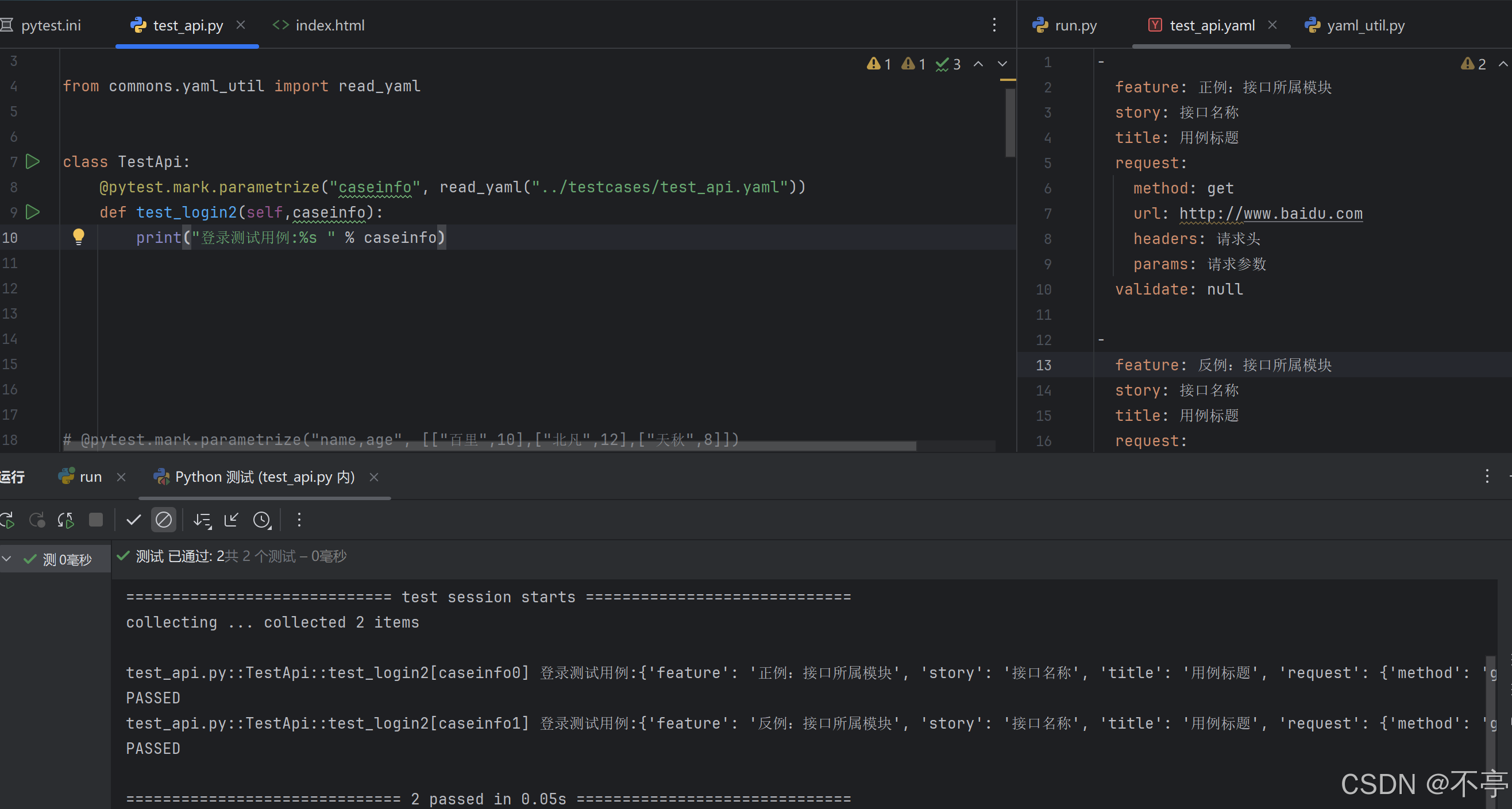
python自动化测试之Pytest框架之YAML详解以及Parametrize数据驱动!
一、YAML详解 YAML是一种数据类型,它能够和JSON数据相互转化,它本身也是有很多数据类型可以满足我们接口 的参数类型,扩展名可以是.yml或.yaml 作用: 1.全局配置文件 基础路径,数据库信息,账号信息&…...

DeepSeek 本地部署指南
在人工智能飞速发展的今天,大语言模型的应用越来越广泛。DeepSeek 作为一款强大的大语言模型,具备出色的语言理解和生成能力。然而,许多用户希望能够在本地部署 DeepSeek,以实现更高的隐私性、更低的延迟和更好的定制化。本文将为…...

[LeetCode]day21 15.三数之和
题目链接 题目描述 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复…...

Unity学习part1
课程为b站【Unity教程】零基础带你从小白到超神 1、脚本执行顺序 unity的脚本执行顺序不像blender的修改器那样按顺序执行,而是系统默认给配置一个值,值越小,执行顺序越靠前(注意,这个顺序是全局生效的) …...
)
【AI知识点】Adversarial Validation(对抗验证)
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】【读书与思考】【AI应用】 Adversarial Validation(对抗验证) 是一种用于检查 训练集(Train Set)和测试集(Test Set)是否同分布 的方法。它…...

力扣 15.三数之和
题目: 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的…...

Spring boot中实现字典管理
数据库脚本 CREATE TABLE data_dict (id bigint NOT NULL COMMENT 主键,dict_code varchar(32) DEFAULT NULL COMMENT 字典编码,dict_name varchar(64) DEFAULT NULL COMMENT 字典名称,dict_description varchar(255) DEFAULT NULL COMMENT 字典描述,dict_status tinyint DEFA…...
)
唯一值校验的实现思路(续)
本文接着上一篇文章《唯一值校验的实现思路》,在后端实现唯一值校验。用代码实现。 /*** checkUniqueException[唯一值校验]** param entity 新增或编辑的学生实体* param insert 是否新增,如果是传入true;反之传入false* return void* date…...

【AI论文】10亿参数大语言模型能超越405亿参数大语言模型吗?重新思考测试时计算最优缩放
摘要:测试时缩放(Test-Time Scaling,TTS)是一种通过在推理阶段使用额外计算来提高大语言模型(LLMs)性能的重要方法。然而,目前的研究并未系统地分析策略模型、过程奖励模型(Process …...

Ubuntu20.04上搭建nginx正向代理提供上网服务
背景:公司很多电脑因软件管控问题不得不禁止设备上网,现需搭建上网代理服务器提供给这些用户使用。 操作系统:ubuntu20.04 工具:nginx-1.25.4 1、下载nginx安装包及依赖 由于nginx默认只持支持转发http协议,所以如…...

web前端布局--使用element中的Container布局容器
前端页面,跟Qt中一样,都是有布局设置的。 先布局,然后再在各布局中添加显示的内容。 Element网站布局容器:https://element.eleme.cn/#/zh-CN/componet/container 1.将element相应的布局容器代码layout,粘贴到vue项…...

使用 PDF SDK 通过页面分割和数据提取对建筑图纸进行分类
一家专门从事设计和建设的建筑公司对大量多页建筑 PDF 图纸进行分类,从而提高协作和运营效率。 这类公司通常承担多个建筑设计项目,每个项目包含多个设计图纸,如详细的结构计划、电气与水管计划、机械计划等。如果项目图纸可以在上传后自动分…...

Linux命名管道与共享内存
命名管道与共享内存 命名管道介绍和基本使用 理解了匿名管道后,命名管道的理解就会变得容易。在前面使用匿名管道时可以发现,之所以可以匿名是因为由父进程创建,子进程拷贝所以子进程和父进程都可以看到这个管道。但是如果对于任意两个进程…...

maven web项目如何定义filter
在 Maven Web 项目中定义一个 Servlet 过滤器(Filter),需要遵循 Java Servlet 规范,并利用 Maven 来管理项目结构和依赖。下面是如何在 Maven Web 项目中定义和配置一个过滤器的基本步骤: 1. 创建过滤器类 首先&…...

使用 Notepad++ 编辑显示 MarkDown
Notepad 是一款免费的开源文本编辑器,专为 Windows 用户设计。它是替代记事本(Notepad)的最佳选择之一,因为它功能强大且轻量级。Notepad 支持多种编程语言和文件格式,并可以通过插件扩展其功能。 Notepad 是一款功能…...

@synchronized的使用
synchronized 介绍 synchronized 是 Objective-C 提供的一种 互斥锁(Mutex),它用于确保一段代码在同一时间只有一个线程能执行,避免多线程访问共享资源时出现数据竞争。 基本语法 synchronized (lockObject) {// 需要加锁的代码…...

解锁Rust:融合多语言特性的编程利器
如果你曾为理解Rust的特性或它们之间的协同工作原理而苦恼,那么这篇文章正是为你准备的。 Rust拥有许多令人惊叹的特性,但这些特性并非Rust所独有。实际上,Rust巧妙地借鉴了众多其他语言的优秀特性,并将它们融合成了一个完美的整体。深入了解Rust这些重要特性的来源以及它是…...

zyNo.23
SQL注入漏洞 1.SQL语句基础知识 一个数据库由多个表空间组成,sql注入关系到关系型数据库,常见的关系型数据库有MySQL,Postgres,SQLServer,Oracle等 以Mysql为例,输入 mysql-u用户名-p密码 即可登录到MySQL交互式命令行界面。 既然是…...

visual studio 在kylin v10上跨平台编译时c++标准库提示缺少无法打开的问题解决
情况1:提示无法打开 源文件 "string"之类导致无法编译 情况2:能编译,但无法打开这些库文件或标准库使用提示下划红色问题 解决方案: 一、通过工具->选项->跨平台里,在“远程标头IntelliSense管理器”更新下载一下…...

黑马Mistral Le chat逆转deepseek
法国人工智能聊天机器人出来了。 Mistral AI比deepseek 性能快很多,准确率更高,非常好用。 全新的发现! 站在老美已经出来的方法&理论上,感觉有0.2亿美金和有gpu算力,感觉搞一个超越国内deepseek难道其实…...

Spring Cloud — 深入了解Eureka、Ribbon及Feign
Eureka 负责服务注册与发现;Ribbon负责负载均衡;Feign简化了Web服务客户端调用方式。这三个组件可以协同工作,共同构建稳定、高效的微服务架构。 1 Eureka 分布式系统的CAP定理: 一致性(Consistency)&am…...
压力测试)
Web项目测试专题(六)压力测试
概述: 压力测试检验Web应用在高并发、高负载情况下的表现,帮助预估系统承载能力和发现瓶颈 步骤: 并发用户测试:增加虚拟用户数测试系统在多人同时使用时的表现 负载测试:模拟高负载情况测试系统的稳定性和响应时间…...

2.5 使用注解进行单元测试详解
Mockito 使用注解进行单元测试详解 Mockito 提供了一系列注解来简化测试代码的编写,减少手动创建和管理 Mock 对象的样板代码。结合 JUnit 5,可以更高效地构建清晰、易维护的单元测试。 1. 核心注解概览 注解作用Mock创建并注入一个 Mock 对象…...

2025年SEO工具有哪些?老品牌SEO工具有哪些
随着2025年互联网的发展和企业线上营销的日益重要,SEO(搜索引擎优化)逐渐成为了提高网站曝光率和流量的重要手段。SEO的工作不仅仅是简单地通过关键词优化和内容发布就能够实现的,它需要依赖一系列专业的SEO工具来帮助分析、监测和…...

使用 React 16+Webpack 和 pdfjs-dist 或 react-pdf 实现 PDF 文件显示、定位和高亮
写在前面 在本文中,我们将探讨如何使用 React 16Webpack 和 pdfjs-dist 或 react-pdf 库来实现 PDF 文件的显示、定位和高亮功能。这些库提供了强大的工具和 API,使得在 Web 应用中处理 PDF 文件变得更加容易。 项目设置 首先,我们需要创建…...

LabVIEW显微镜成像偏差校准
在高精度显微镜成像中,用户常常需要通过点击图像的不同位置,让电机驱动探针移动到指定点进行观察。然而,在实际操作中,经常会遇到一个问题:当点击位于图像中心附近的点时,探针能够相对准确地定位࿱…...

【Elasticsearch】文本分析Text analysis概述
文本分析概述 文本分析使 Elasticsearch 能够执行全文搜索,搜索结果会返回所有相关的结果,而不仅仅是完全匹配的结果。 如果你搜索“Quick fox jumps”,你可能希望找到包含“A quick brown fox jumps over the lazy dog”的文档,…...

23页PDF | 国标《GB/T 44109-2024 信息技术 大数据 数据治理实施指南 》发布
一、前言 《信息技术 大数据 数据治理实施指南》是中国国家标准化管理委员会发布的关于大数据环境下数据治理实施的指导性文件,旨在为组织开展数据治理工作提供系统性的方法和框架。报告详细阐述了数据治理的实施过程,包括规划、执行、评价和改进四个阶…...

AI代码生成器如何重塑前端开发的工作环境
近年来,人工智能(AI)技术迅猛发展,深刻地改变着各行各业的工作方式。在软件开发领域,AI写代码工具的出现更是掀起了一场革命,尤其对前端开发工程师的工作环境和协作方式产生了深远的影响。本文将深入探讨AI…...