【Elasticsearch】文本分析Text analysis概述
文本分析概述
文本分析使 Elasticsearch 能够执行全文搜索,搜索结果会返回所有相关的结果,而不仅仅是完全匹配的结果。
如果你搜索“Quick fox jumps”,你可能希望找到包含“A quick brown fox jumps over the lazy dog”的文档,你也可能希望找到包含相关词汇(如“fast fox”或“foxes leap”)的文档。
分析通过分词实现全文搜索:将文本分解成更小的单元,称为词元。在大多数情况下,这些词元是单独的单词。
如果你将短语“the quick brown fox jumps”作为一个单一字符串进行索引,而用户搜索“quick fox”,那么它不会被视为匹配。然而,如果你对短语进行分词并将每个单词分别索引,查询字符串中的术语就可以单独查找。这意味着它们可以通过搜索“quick fox”“fox brown”或其他变体来匹配。
分词使得能够对单个术语进行匹配,但每个词元仍然会逐字匹配。这意味着:
• 搜索“Quick”不会匹配“quick”,尽管你可能希望这两个词能够相互匹配。
• 尽管“fox”和“foxes”有相同的词根,但搜索“foxes”不会匹配“fox”,反之亦然。
• 搜索“jumps”不会匹配“leaps”。尽管它们没有相同的词根,但它们是同义词,意思相近。
为了解决这些问题,文本分析可以将这些词元规范化为标准格式。这使得你可以匹配那些与搜索词不完全相同,但仍然足够相关的词元。例如:
• “Quick”可以转换为小写:“quick”。
• “foxes”可以进行词干提取,即还原为词根:“fox”。
• “jump”和“leap”是同义词,可以索引为同一个词:“jump”。
为了确保搜索词能够按预期匹配这些词,你可以对查询字符串应用相同的分词和规范化规则。例如,搜索“Foxes leap”可以被规范化为搜索“fox jump”。
自定义文本分析
文本分析是由分析器执行的,它是一组规则,控制整个分析过程。
Elasticsearch 包含一个默认的分析器,称为标准分析器,它在大多数情况下都能很好地工作。
如果你想定制搜索体验,你可以选择不同的内置分析器,甚至可以配置一个自定义的分析器。自定义分析器让你能够控制分析过程的每一步,包括:
• 在分词之前对文本进行更改。
• 文本如何转换为词元。
• 在索引或搜索之前对词元进行的规范化更改。
索引和搜索分析
文本分析发生在两个时间点:
索引时间
当文档被索引时,任何`text`字段的值都会被分析。
搜索时间
在对`text`字段执行全文搜索时,用户正在搜索的查询字符串(即用户输入的文本)会被分析。搜索时间也被称为查询时间。
在每个时间点使用的分析器(或分析规则集)分别被称为索引分析器或搜索分析器。
索引分析器和搜索分析器如何协同工作
在大多数情况下,索引和搜索时应该使用相同的分析器。这可以确保字段的值和查询字符串被转换成相同形式的标记(tokens)。反过来,这可以确保在搜索期间标记能够按预期匹配。
示例
一个文档在`text`字段中索引了以下值:
```
The QUICK brown foxes jumped over the dog!
```
字段的索引分析器将值转换为标记并对其进行规范化。在这个例子中,每个标记代表一个单词:
```
[ quick, brown, fox, jump, over, dog ]
```
然后这些标记被索引。
稍后,用户在同一个`text`字段中搜索以下内容:
用户期望这个搜索能够匹配之前索引的句子`The QUICK brown foxes jumped over the dog!`。
然而,查询字符串并不包含文档原始文本中使用的精确单词:
• `Quick`vs`QUICK`
• `fox`vs`foxes`
为了应对这种情况,查询字符串使用相同的分析器进行分析。这个分析器产生了以下标记:
为了执行搜索,Elasticsearch将这些查询字符串标记与`text`字段中索引的标记进行比较。
标记 查询字符串 `text`字段
`quick` X X
`brown` X
`fox` X X
`jump` X
`over` X
`dog` X
由于字段值和查询字符串以相同的方式进行了分析,它们产生了类似的标记。标记`quick`和`fox`是精确匹配的。这意味着搜索匹配了包含`"The QUICK brown foxes jumped over the dog!"`的文档,正如用户所期望的那样。
何时使用不同的搜索分析器
虽然不太常见,但在某些情况下,使用不同的索引和搜索分析器是有意义的。为此,Elasticsearch允许你为查询字符串指定一个单独的搜索分析器。
通常,只有在使用相同形式的标记对字段值和查询字符串进行匹配时会创建意外或不相关的搜索结果时,才应该指定一个单独的搜索分析器。
示例
Elasticsearch被用于创建一个搜索引擎,该引擎只匹配以提供的前缀开头的单词。例如,搜索`tr`应该返回`tram`或`trope`,但永远不会返回`taxi`或`bat`。
一个文档被添加到搜索引擎的索引中;该文档在`text`字段中包含一个这样的单词:
字段的索引分析器将值转换为标记并对其进行规范化。在这个例子中,每个标记代表一个可能的单词前缀:
```
[ a, ap, app, appl, apple]
```
然后这些标记被索引。
稍后,用户在同一个`text`字段中搜索以下内容:
用户期望这个搜索只匹配以`appli`开头的单词,例如`appliance`或`application`。搜索不应该匹配`apple`。
然而,如果使用字段的索引分析器来分析这个查询字符串,它会产生以下标记:
```
[ a, ap, app, appl, appli ]
```
当Elasticsearch将这些查询字符串标记与`apple`索引的标记进行比较时,它会找到多个匹配项。
标记 `appli` `apple`
`a` X X
`ap` X X
`app` X X
`appl` X X
`appli` X
这意味着搜索会错误地匹配`apple`。不仅如此,它还会匹配任何以`a`开头的单词。
为了解决这个问题,你可以为`text`字段的查询字符串指定一个不同的搜索分析器。
在这种情况下,你可以指定一个产生单个标记而不是一组前缀的搜索分析器:
这个查询字符串标记只会匹配以`appli`开头的单词的标记,这更符合用户的搜索期望。
相关文章:

【Elasticsearch】文本分析Text analysis概述
文本分析概述 文本分析使 Elasticsearch 能够执行全文搜索,搜索结果会返回所有相关的结果,而不仅仅是完全匹配的结果。 如果你搜索“Quick fox jumps”,你可能希望找到包含“A quick brown fox jumps over the lazy dog”的文档,…...

23页PDF | 国标《GB/T 44109-2024 信息技术 大数据 数据治理实施指南 》发布
一、前言 《信息技术 大数据 数据治理实施指南》是中国国家标准化管理委员会发布的关于大数据环境下数据治理实施的指导性文件,旨在为组织开展数据治理工作提供系统性的方法和框架。报告详细阐述了数据治理的实施过程,包括规划、执行、评价和改进四个阶…...

AI代码生成器如何重塑前端开发的工作环境
近年来,人工智能(AI)技术迅猛发展,深刻地改变着各行各业的工作方式。在软件开发领域,AI写代码工具的出现更是掀起了一场革命,尤其对前端开发工程师的工作环境和协作方式产生了深远的影响。本文将深入探讨AI…...

kafka的架构和工作原理
目录 Kafka 架构 Kafka 工作原理 Kafka 数据流 Kafka 核心特性 总结 Kafka 架构 1. 生产者(Producer) 2. 消费者(Consumer) 3. 主题(Topic) 4. 分区(Partition) 5. 副本(Replica) 6. 代理(Broker) 7. ZooKeeper(旧版本)/KRaft(新版本) Kafka 工作…...

Xcode证书密钥导入
证书干嘛用 渠道定期会给xcode证书,用来给ios打包用,证书里面有记录哪些设备可以打包进去。 怎么换证书 先更新密钥 在钥匙串访问中,选择系统。(选登录也行,反正两个都要导入就是了)。 mac中双击所有 .p12 后缀的密钥ÿ…...

索引的详细介绍
数据库索引是一种用于加速数据检索的数据结构,类似于书籍的目录。通过索引,数据库可以快速定位数据,而无需扫描整个表。以下是关于数据库索引的详细介绍: 1. 索引的基本概念 定义:索引是数据库表中一列或多列的值及其…...

Python 基于 OpenCV 的人脸识别上课考勤系统(附源码,部署教程)
博主介绍:✌2013crazy、10年大厂程序员经历。全网粉丝12W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&a…...

TikTok网页版访问受限?一文解析解决方案
TikTok网页版是许多用户用来浏览视频、管理账号和发布内容的重要工具。然而,部分用户可能会遇到无法打开TikTok网页版的问题,如页面加载失败、显示网络错误或提示访问受限。本文将帮助你快速排查问题,并提供解决方案,让你顺利访问…...
+openwebui/docker+openwebui)
本地部署【LLM-deepseek】大模型 ollama+deepseek/conda(python)+openwebui/docker+openwebui
通过ollama本地部署deepseek 总共两步 1.模型部署 2.[web页面] 参考官网 ollama:模型部署 https://ollama.com/ open-webui:web页面 https://github.com/open-webui/open-webui 设备参考 Mac M 芯片 windows未知 蒸馏模型版本:deepseek-r1:14b 运行情况macminim2 24256 本地…...

【vs2022配置cursor】
Cursor搭配cmake实现C程序的编译、运行和调试的参考地址 cursor下载地址 第一步: 电脑上按爪cmake 第二步:cursor 配置 安装中文 第三步环境变量: D:\Program Files\Microsoft Visual Studio\2022\Professional\VC\Tools\MSVC\14.35.322…...

Redis 的缓存雪崩、缓存穿透和缓存击穿详解,并提供多种解决方案
本文是对 Redis 知识的补充,在了解了如何搭建多种类型的 Redis 集群,并清楚了 Redis 集群搭建的过程的原理和注意事项之后,就要开始了解在使用 Redis 时可能出现的突发问题和对应的解决方案。 引言:虽然 Redis 是单线程的…...

Docker使用指南与Dockerfile文件详解:从入门到实战
Docker使用指南与Dockerfile文件详解:从入门到实战 文章目录 **Docker使用指南与Dockerfile文件详解:从入门到实战****引言****第一部分:Docker 核心概念速览****1. Docker 基础架构****2. Docker 核心命令****第二部分:Dockerfile 文件深度解析****1. Dockerfile 是什么?…...

如何在个人电脑本地化部署Deepseek-R1大模型
文章目录 Deepseek概述公司简介DeepSeek模型优势DeepSeek模型发展历史Ollama安装Deepseek版本选择Deepseek支持的客户端工具编程语言客户端库桌面客户端插件类其他工具客户端工具配置cherryStudio配置测试如何使用DeepSeek满血版什么是 DeepSeek R1 满血版?deepseek官方第三方…...

DeepSeek-R1复现方案梳理
open-r1 项目地址:https://github.com/huggingface/open-r1 由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deepseek的指标,可以在open-r1/open-r1-eval-leaderboard查看指标的…...

【Redis】 - Redis的Bitmap实现用户签到
Redis的Bitmap实现用户签到 使用Redis的Bitmap数据结构来记录用户的每日签到状态是一种高效且节省空间的方法。通过将用户ID和日期结合生成动态Key,可以轻松管理不同用户在不同日期的签到情况。下面详细介绍如何设计这一方案。 设计思路 动态Key生成:根…...

用php tp6对接钉钉审批流的 table 表格 明细控件 旧版sdk
核心代码 foreach ($flows[product_list] as $k>$gift) {$items_list[] [[name > 商品名称, value > $gift[product_name] ?? ],[name > 规格, value > $gift[product_name] ?? ],[name > 数量, value > $gift[quantity] ?? ],[name > 单位, v…...

使用DeepSeek建立一个智能聊天机器人0.07
进一步完善获取API密钥和DeepSeek的API端点,我们可以添加更多的错误处理和默认值设置,确保程序在各种情况下都能正常运行。同时,我们还可以提供一个更友好的用户界面,以便用户可以轻松地设置和查看配置信息。 以下是进一步完善的…...

PySpark查找Dataframe中的非ASCII字符并导出Excel文件
from pyspark.sql import SparkSession from pyspark.sql.types import StringType from pyspark.sql.functions import udf, col from pyspark.sql.types import BooleanType import pandas as pd# 初始化Spark会话 spark SparkSession.builder.appName("StringFilter&q…...

大模型RLHF:PPO原理与源码解读
大模型RLHF:PPO原理与源码解读 原文链接:图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 本文直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训…...

SQLite 数据库:优点、语法与快速入门指南
文章目录 一、引言二、SQLite 的优点 💯三、SQLite 的基本语法3.1 创建数据库3.2 创建表3.3 插入数据3.4 查询数据3.5 更新数据3.6 删除数据3.7 删除表 四、快速入门指南4.1 安装 SQLite4.2 创建数据库4.3 创建表4.4 插入数据4.5 查询数据4.6 更新数据4.7 删除数据4…...

pytorch笔记:mm VS bmm
1 bmm (batch matrix multiplication) 批量矩阵乘法,用于同时处理多个矩阵的乘法bmm 的输入是两个 3D 张量(batch of matrices),形状分别为 (batch_size, n, m) 和 (batch_size, m, p)bmm 输出的形状是 (batch_size, n, p) 2 mm…...
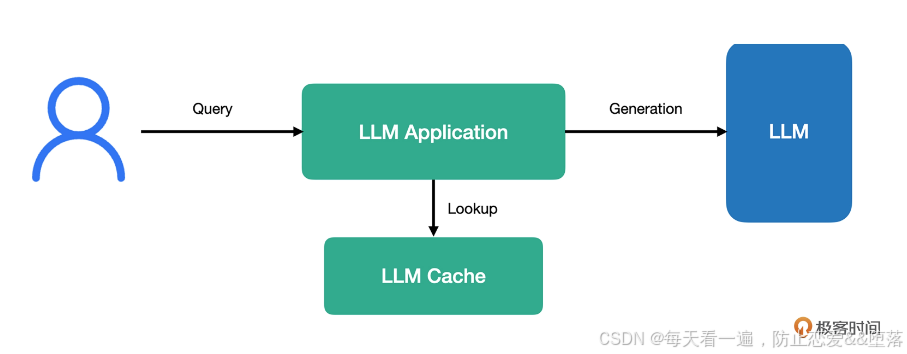
5、大模型的记忆与缓存
文章目录 本节内容介绍记忆Mem0使用 mem0 实现长期记忆 缓存LangChain 中的缓存语义缓存 本节内容介绍 本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义…...

LangChain系列:LangChain基础入门教程
LangChain 是一个开源框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。它为链提供了标准接口,与许多其他工具进行了集成,并为常见应用提供了端到端的链。 LangChain 让 AI 开发人员能够基于大型语言模型&#…...

修改docker内容器中的某配置文件的命令
先找到配置文件config.php find / -name "config.php" 2>/dev/null 然后用vi编辑器修改配置文件 vi /var/www/config.php 最后就是vi的基本操作,根据具体需求使用: vi 有两种主要模式: 命令模式:进入 vi 后的默认…...

无人机遥感图像拼接及处理实践技术:生态环境监测、农业、林业等领域,结合图像拼接与处理技术,能够帮助我们更高效地进行地表空间要素的动态监测与分析
近年来,无人机技术在遥感领域的应用越来越广泛,尤其是在生态环境监测、农业、林业等领域,无人机遥感图像的处理与分析成为了科研和业务化工作中的重要环节。通过无人机获取的高分辨率影像数据,结合图像拼接与处理技术,…...

基于Springmvc+MyBatis+Spring+Bootstrap+EasyUI+Mysql的个人博客系统
基于SpringmvcMyBatisSpringBootstrapEasyUIMysql的个人博客系统 1.项目介绍 使用Maven3Spring4SpringmvcMybatis3架构;数据库使用Mysql,数据库连接池使用阿里巴巴的Druid;使用Bootstrap3 UI框架实现博客的分页显示,博客分类&am…...

Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式
目录 引言 一、ViT模型的起源和历史 二、什么是ViT? 图像处理流程 图像切分 展平与线性映射 位置编码 Transformer编码器 分类头(Classification Head) 自注意力机制 注意力图 三、Coovally AI模型训练与应用平台 四、ViT与图像…...

Tailwind CSS 的核心理念
实用优先(Utility-First) Tailwind CSS 的最核心理念是"实用优先"。这种方法颠覆了传统的 CSS 开发方式,不再编写自定义的类名和样式规则,而是通过组合预定义的工具类来构建界面。这种方式带来了以下优势: …...

软考高级《系统架构设计师》知识点(二)
操作系统知识 操作系统概述 操作系统定义:能有效地组织和管理系统中的各种软/硬件资源,合理地组织计算机系统工作流程,控制程序的执行,并且向用户提供一个良好的工作环境和友好的接口。操作系统有三个重要的作用: 管理…...

DeepSeek的魔法:如何让复杂概念变得通俗易懂?
日常生活中,常常会被复杂的概念所困扰。怎么样将这些晦涩难懂的概念变得通俗易懂?当然是利用大模型帮我们解答,不过让大模型解答也需要有好的沟通提示词。 我收集整理了 2 套提示词,大家一起学习一下。 一、用推理模型解释概…...