强化学习裁剪函数:解锁算法稳定性的关键密码
目录
- 一、引言
- 二、裁剪函数基本原理
- (一)什么是裁剪函数
- (二)裁剪函数在强化学习中的作用
- 三、裁剪函数在常见强化学习算法中的应用
- (一)近端策略优化(PPO)算法
- (二)其他算法中的潜在应用
- 四、代码示例
- (一)PPO 算法中裁剪函数的实现(以 OpenAI Gym 环境 CartPole 为例)
- (二)DQN 中 Q 值裁剪的简单示例
- 五、案例分析
- (一)自动驾驶中的应用
- (二)工业机器人控制
- 六、总结
一、引言
在强化学习领域,为了使智能体能够高效地学习到最优策略,众多技术与方法应运而生,裁剪函数(Clipping Function)便是其中之一。裁剪函数在优化智能体的策略和价值估计过程中发挥着关键作用,通过对某些变量或计算结果进行有针对性的限制,有效提升了强化学习算法的稳定性与收敛性。本文将深入剖析强化学习中的裁剪函数,涵盖原理讲解、在常见算法中的应用分析、代码示例展示以及实际案例探讨,助力全面掌握这一重要技术。
二、裁剪函数基本原理
(一)什么是裁剪函数
裁剪函数,从字面意思理解,就是对数据进行 “裁剪” 操作的函数。在强化学习里,它主要用于对一些可能导致算法不稳定或不良影响的数值进行限制。例如,在计算过程中,某些值可能会变得过大或过小,过大的值可能导致梯度爆炸,使算法无法收敛;过小的值则可能导致梯度消失,同样阻碍算法的学习进程。裁剪函数通过设定上下限,将这些数值约束在合理范围内。
以一个简单的数学函数为例,假设有一个函数 f ( x ) f(x) f(x),我们希望将其输出值限制在 [ a , b ] [a, b] [a,b]区间内,那么使用裁剪函数 c l i p ( f ( x ) , a , b ) clip(f(x), a, b) clip(f(x),a,b)后, f ( x ) f(x) f(x) 映射如下:
- 当 f ( x ) < a f(x) < a f(x)<a时,返回值为 a a a
- 当 f ( x ) > b f(x) > b f(x)>b时,返回值为 b b b
- 当 a ≤ f ( x ) ≤ b a \leq f(x) \leq b a≤f(x)≤b时,返回值为 f ( x ) f(x) f(x)本身
(二)裁剪函数在强化学习中的作用
稳定策略更新:在策略梯度算法中,策略的更新依赖于梯度的计算。如果梯度值过大,策略更新的幅度就会过于剧烈,可能导致智能体的行为变得不稳定,甚至偏离最优策略。裁剪函数可以对梯度进行裁剪,使得策略更新更加平稳,逐步朝着最优策略的方向发展。
防止价值估计偏差:在价值估计过程中,裁剪函数可以避免由于异常奖励或估计误差导致的价值函数剧烈波动。例如,当智能体获得一个极大的奖励时,如果不进行处理,可能会大幅拉高价值估计,误导后续的决策。通过裁剪函数对奖励或价值估计进行限制,能够保持价值函数的相对稳定性,为智能体的决策提供更可靠的依据。
三、裁剪函数在常见强化学习算法中的应用
(一)近端策略优化(PPO)算法
PPO 算法是强化学习中广泛应用的算法之一,其中裁剪函数起到了关键作用。PPO 算法使用截断的优势目标函数(clipped surrogate objective)来优化策略。
PPO 的目标函数为: L C L I P ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \mathbb{E}_{t}[\min(r_{t}(\theta)\hat{A}_{t}, \text{clip}(r_{t}(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_{t})] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中, r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{old}}(a_{t}|s_{t})} rt(θ)=πθold(at∣st)πθ(at∣st) 是重要性采样比, A ^ t \hat{A}_{t} A^t 是估计的优势函数, ϵ \epsilon ϵ 是裁剪参数。
在这个公式中,通过对重要性采样比 r t ( θ ) r_{t}(\theta) rt(θ) 进行裁剪(将其限制在 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ]区间内),可以防止由于策略更新过大而导致的不稳定。如果 r t ( θ ) r_{t}(\theta) rt(θ) 超过了这个区间,就使用裁剪后的边界值来计算目标函数,从而保证策略更新在一个可控的范围内。
(二)其他算法中的潜在应用
除了 PPO 算法,在一些基于深度 Q 网络(DQN)的改进算法中,裁剪函数也有应用。例如,在处理 Q 值估计时,为了防止 Q 值的过度波动,可以对 Q 值进行裁剪。当 Q 值超过预先设定的最大或最小值时,将其调整为边界值,这样可以提高 Q 值估计的稳定性,进而提升算法的性能。
四、代码示例
(一)PPO 算法中裁剪函数的实现(以 OpenAI Gym 环境 CartPole 为例)
import gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical# 定义策略网络
class Policy(nn.Module):def __init__(self, state_size, action_size):super(Policy, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return Categorical(logits=x)# 超参数
gamma = 0.99
epsilon = 0.2
learning_rate = 3e-4
num_epochs = 10# 初始化环境和策略网络
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
policy = Policy(state_size, action_size)
optimizer = optim.Adam(policy.parameters(), lr=learning_rate)for epoch in range(num_epochs):states, actions, rewards = [], [], []state = env.reset()state = torch.FloatTensor(state)done = Falsewhile not done:states.append(state)dist = policy(state)action = dist.sample()actions.append(action)state, reward, done, _ = env.step(action.item())state = torch.FloatTensor(state)rewards.append(reward)returns = []R = 0for r in rewards[::-1]:R = r + gamma * Rreturns.insert(0, R)returns = torch.FloatTensor(returns)states = torch.stack(states)actions = torch.tensor(actions)old_log_probs = policy(states).log_prob(actions)for _ in range(3):dist = policy(states)log_probs = dist.log_prob(actions)ratios = torch.exp(log_probs - old_log_probs.detach())advantages = returns - policy(states).value# 应用裁剪函数surr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1 - epsilon, 1 + epsilon) * advantagesloss = -torch.min(surr1, surr2).mean()optimizer.zero_grad()loss.backward()optimizer.step()env.close()在这段代码中,torch.clamp(ratios, 1 - epsilon, 1 + epsilon) 就是对重要性采样比 ratios 应用裁剪函数,将其限制在 [1 - epsilon, 1 + epsilon] 区间内,以实现 PPO 算法中对策略更新的稳定控制。
(二)DQN 中 Q 值裁剪的简单示例
import gym
import torch
import torch.nn as nn
import torch.optim as optim# 定义Q网络
class QNetwork(nn.Module):def __init__(self, state_size, action_size):super(QNetwork, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 超参数
gamma = 0.99
learning_rate = 3e-4
q_value_clip = 10 # 设定Q值裁剪的上下限为[-10, 10]# 初始化环境和Q网络
env = gym.make('FrozenLake-v1', is_slippery=False)
state_size = env.observation_space.n
action_size = env.action_space.n
q_network = QNetwork(state_size, action_size)
optimizer = optim.Adam(q_network.parameters(), lr=learning_rate)for episode in range(100):state = env.reset()done = Falsewhile not done:state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0)q_values = q_network(state_tensor)action = torch.argmax(q_values).item()next_state, reward, done, _ = env.step(action)# 计算目标Q值next_state_tensor = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)next_q_values = q_network(next_state_tensor)max_next_q_value = torch.max(next_q_values).item()target_q_value = reward + gamma * max_next_q_value if not done else reward# 应用Q值裁剪target_q_value = torch.clamp(torch.tensor(target_q_value), -q_value_clip, q_value_clip)# 计算损失并更新Q网络q_value = q_values[0][action]loss = nn.functional.mse_loss(q_value, target_q_value)optimizer.zero_grad()loss.backward()optimizer.step()state = next_stateenv.close()在这个 DQN 示例中,torch.clamp(torch.tensor(target_q_value), -q_value_clip, q_value_clip) 实现了对目标 Q 值的裁剪,将其限制在 [-q_value_clip, q_value_clip] 范围内,有助于稳定 Q 值的估计。
五、案例分析
(一)自动驾驶中的应用
在自动驾驶场景中,智能驾驶系统可看作一个强化学习智能体。在训练过程中,车辆的行驶决策(如加速、减速、转向等动作)依赖于对环境状态(如车速、路况、周围车辆位置等)的评估和策略选择。
以 PPO 算法为例,在计算策略更新时,使用裁剪函数可以防止由于某些极端路况下的决策偏差导致策略更新过度。比如,当车辆突然遇到紧急情况(如前方车辆急刹车)时,可能会产生较大的奖励或惩罚信号,如果不使用裁剪函数对相关梯度进行处理,可能会使策略更新过于剧烈,导致车辆在后续行驶中行为不稳定。通过裁剪函数对梯度进行限制,能使车辆的行驶策略更加平稳地调整,提高自动驾驶的安全性和稳定性。
(二)工业机器人控制
在工业机器人的任务执行中,机器人需要根据不同的任务需求(如搬运物体、装配零件等)选择合适的动作序列。在这个过程中,价值估计的准确性至关重要。
假设使用基于 DQN 的算法来控制机器人,在估计 Q 值时,裁剪函数可以避免由于机器人在某些复杂操作中获得异常奖励(如成功完成一个高难度装配动作获得过高奖励)而导致 Q 值估计偏差。通过对 Q 值进行裁剪,能够保证机器人在不同任务阶段的决策更加稳定和合理,提高工业生产的效率和质量。
六、总结
裁剪函数作为强化学习中的重要技术,通过对关键数值的限制,有效提升了算法的稳定性和收敛性。无论是在策略优化还是价值估计过程中,裁剪函数都发挥着不可或缺的作用。在实际应用中,根据不同的强化学习任务和场景,合理选择和调整裁剪函数的参数,将有助于开发出更高效、更可靠的强化学习算法。
相关文章:

强化学习裁剪函数:解锁算法稳定性的关键密码
目录 一、引言二、裁剪函数基本原理(一)什么是裁剪函数(二)裁剪函数在强化学习中的作用 三、裁剪函数在常见强化学习算法中的应用(一)近端策略优化(PPO)算法(二ÿ…...

网络安全威胁是什么
1.网络安全威胁的概念 网络安全威胁指网络中对存在缺陷的潜在利用,这些缺陷可能导致信息泄露、系统资源耗尽、非法访问、资源被盗、系统或数据被破坏等。 2.网络安全威胁的类型 物理威胁系统漏洞威胁身份鉴别威胁线缆连接威胁有害程序危险 (1&#x…...

iOS主要知识点梳理回顾-3-运行时消息机制
运行时(runtime) 运行时是OC的重要特性,也是OC动态性的根本支撑。动态,如果利用好了,扩展性就很强。当然了,OC的动态性只能算是一个一般水平。与swift、java这种强类型校验的语言相比,OC动态性很…...

驱动开发、移植(最后的说法有误,以后会修正)
一、任务明确:把创龙MX8的驱动 按照我们的要求 然后移植到 我们的板子 1.Linux系统启动卡制作, sd卡 先按照 《用户手册—3-2-Linux系统启动卡制作及系统固化》 把创龙的Linux系统刷进去。 2. 把TLIMX8-EVM的板子过一遍 把刚刚烧好系统的sd卡插入 创…...

归并排序(C# C++)
目录 1 归并排序的基本概念 2 算法步骤 2-1 分解阶段 2-2 合并阶段 3 代码实现 3-1 C#代码示例(该代码在unity环境下) 3-2 C代码示例 1 归并排序的基本概念 归并排序(Merge Sort)是一种经典的分治算法,由约翰…...

【逆向工程】破解unity的安卓apk包
先了解一下普通apk包的逆向方法(无加密或加壳) 开发环境: 操作系统:windows 解apk包 下载工具:apktool【Install Guide | Apktool】按照文档说的操作就行,先安装java运行时环境【我安装的是jre-8u441-wind…...

如何使用智能化RFID管控系统,对涉密物品进行安全有效的管理?
载体主要包括纸质文件、笔记本电脑、优盘、光盘、移动硬盘、打印机、复印机、录音设备等,载体(特别是涉密载体)是各保密、机要单位保证涉密信息安全、防止涉密信息泄露的重要信息载体。载体管控系统主要采用RFID射频识别及物联网技术…...

Oracle ORA-00054
ORA-00054: resource busy and acquire with NOWAlT specified or timeout expire 错误 ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired 是 Oracle 数据库中常见的一个错误,通常发生在尝试获取一个已经被其他会话占用的资源时。这…...

华为云kubernetes基于keda自动伸缩deployment副本(监听redis队列长度)
1 概述 KEDA(Kubernetes-based Event-Driven Autoscaler,网址是https://keda.sh)是在 Kubernetes 中事件驱动的弹性伸缩器,功能非常强大。不仅支持根据基础的CPU和内存指标进行伸缩,还支持根据各种消息队列中的长度、…...

入选TPAMI2025!傅里叶变换+目标检测新突破!
今天给大家推荐一个目标检测,好发不卷的新思路:与傅里叶变换结合! 一方面,不仅能提升检测的准确性和可靠性,还能增强模型的通用性和适应性,灵活应对复杂场景。比如TPAMI25的FSD模型,便通过该方…...

物联网智能语音控制灯光系统设计与实现
背景 随着物联网技术的蓬勃发展,智能家居逐渐成为现代生活的一部分。在众多智能家居应用中,智能灯光控制系统尤为重要。通过语音控制和自动调节灯光,用户可以更便捷地操作家中的照明设备,提高生活的舒适度与便利性。本文将介绍一…...

fastjson2学习大纲
一、基础篇 - JSON与fastjson2核心概念 JSON基础 JSON语法规范(RFC 8259)JSON数据类型与Java类型对应关系序列化/反序列化核心概念 fastjson2入门 与fastjson1的主要区别核心优势: 性能提升(JSONB二进制协议)更完善的…...

等级保护2.0|网络安全服务
等级保护2.0|网络安全服务 定义 对于国家秘密信息、法人和其他组织及公民专有信息以及公开信息的存储、传输、处理这些信息系统分等级实行安全保护,对信息系统中发生的信息安全时间分等级响应、处置。 思想 对信息安全实行等级化保护和等级化管理 目标 突出重…...

告别硬编码:用 load_dotenv 高效管理你的环境变量
前言 环境变量是开发中常见的配置工具,特别是用于存储敏感信息,如数据库连接字符串、API 密钥等。直接将这些数据写进代码,除了不安全外,还让人感到一团乱麻。为了避免这种情况,dotenv 库应运而生,它能帮我们轻松从 .env 文件中加载环境变量,避免将这些敏感信息硬编码到…...

安科瑞光伏发电防逆流解决方案——守护电网安全,提升能源效率
安科瑞 华楠 18706163979 在当今大力发展清洁能源的时代背景下,光伏发电作为一种可持续的能源解决方案, 正得到越来越广泛的应用。然而,光伏发电过程中出现的逆流问题,给电网的安全稳定 运行带来了诸多挑战。若不能有效解决&…...

Unity使用iTextSharp导出PDF-02基础结构及设置中文字体
基础结构 1.创建一个Document对象 2.使用PdfWriter创建PDF文档 3.打开文档 4.添加内容,调用文档Add方法添加内容时,内容写入到输出流中 5.关闭文档 using UnityEngine; using iTextSharp.text; using System.IO; using iTextSharp.text.pdf; using Sys…...

Web第二次作业_补充完小鹅通首页(静态)
目录 题目 index css style 解题 技术优势 html css 运营服务 html css 小鹅通 html css 咨询 html css 友情链接、公司信息 html css 效果展示 技术优势 运营服务 小鹅通 咨询 友情链接、公司信息 题目 index <!DOCTYPE html> <html lang…...

碳纤维复合材料制造的六西格玛管理实践:破解高端制造良率困局的实战密码
碳纤维复合材料制造的六西格玛管理实践:破解高端制造良率困局的实战密码 在全球碳中和与高端制造升级的双重驱动下,碳纤维复合材料行业正经历前爆发式增长。航空航天、新能源汽车、风电叶片等领域对碳纤维产品的性能稳定性提出近乎苛刻的要求࿰…...

在 Mac ARM 架构上使用 nvm 安装 Node.js 版本 16.20.2
文章目录 1. 安装 nvm(如果还没有安装的话)2. 加载 nvm 配置3. 列出特定系列的 Node.js 版本(远程):4. 安装 Node.js 16.20.25. 使用指定版本的 Node.js6. 验证安装 在 Mac ARM 架构上使用 nvm 安装 Node.js 版本 16.…...

tenda路由器WriteFacMac存在远程命令执行漏洞(CVE-2024-10697)
一、漏洞简介 tenda路由器WriteFacMac存在远程命令执行漏洞 二、漏洞影响 tenda路由器三、网络测绘: fofa: title"Tenda | LOGIN"四、复现过程 POC 1 GET /goform/WriteFacMac?macls%20%3E/webroot/1.txt HTTP/1.1 Accept: text/html,application/…...

【NLP 21、实践 ③ 全切分函数切分句子】
当无数个自己离去,我便日益坦然 —— 25.2.9 一、jieba分词器 Jieba 是一款优秀的 Python 中文分词库,它支持多种分词模式,其中全切分方式会将句子中所有可能的词语都扫描出来。 1.原理 全切分方式会找出句子中所有可能的词语组合。对于一…...
晶闸管主要参数分析与损耗计算
1. 主要参数 断态正向可重复峰值电压 :是晶闸管在不损坏的情况下能够承受的正向最大阻断电压。断态正向不可重复峰值电压 :是晶闸管只有一次可以超过的正向最大阻断电压,一旦晶闸管超过此值就会损坏,一般情况下 反向可重复峰值电压 :是指晶闸管在不损坏的情况下能够承受的…...

【Stable Diffusion部署至Google Colab】
Google Colab 中快速搭建带 GPU 加速的 Stable Diffusion WebUI from google.colab import drive drive.mount(/content/drive) !mkdir /content/drive/MyDrive/sd-webui-files !pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index…...

mongoTemplate获取某列最大值
首先,MongoDB中获取某列的最大值通常是通过聚合框架中的$group和$max操作符来完成的。那在Spring Data中,应该怎么构建这个聚合查询呢? 首先,可能需要创建一个Aggregation对象,里面包含分组和求最大值的步骤。比如&…...

基于Java的分布式系统架构设计与实现
Java在大数据处理中的应用:基于Java的分布式系统架构设计与实现 随着大数据时代的到来,数据处理的规模和复杂性不断增加。为了高效处理海量数据,分布式系统成为了必不可少的架构之一。而Java,凭借其平台独立性、丰富的生态系统以…...

独立开发日报:从AI到本地服务,5个新颖项目的启发
今天在Hacker News上看到几个特别有意思的项目,它们都找到了不同的切入点:有的用AI解决创意问题,有的深耕本地服务,有的则回归技术本质。一起来看看这些项目背后的思路。 1. AI涂色页面生成器 - 创意与AI的完美结合 这是一个基于…...

找单独的数
问题描述 在一个班级中,每位同学都拿到了一张卡片,上面有一个整数。有趣的是,除了一个数字之外,所有的数字都恰好出现了两次。现在需要你帮助班长小C快速找到那个拿了独特数字卡片的同学手上的数字是什么。 要求: 设…...
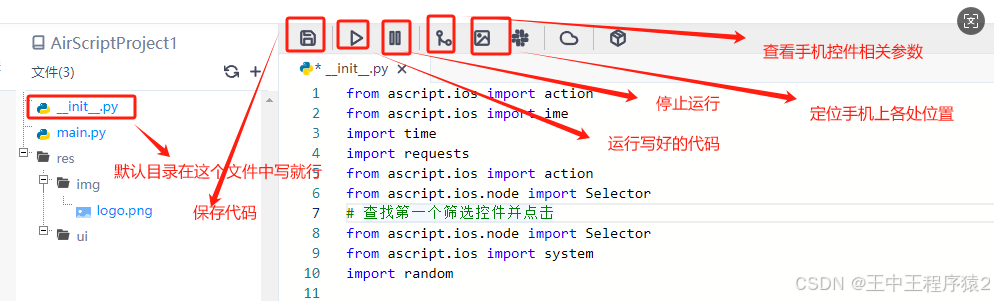
记使用AScript自动化操作ios苹果手机
公司业务需要自动化操作手机,本来以为很困难,没想到使用AScript工具出乎意料的简单,但是还有很多坑存在,写个博客记录一下。 工具信息: 手机:iphone7 系统版本:ios15 AScript官方文档链接&a…...

Android Studio集成讯飞SDK过程中在配置Project的时候有感
在配置讯飞的语音识别SDK(流式版)时候,跟着写了两个Demo,一个是YuYinTestDemo01,另一个是02,demo01比较简单,实现功能图象也比较简陋,没用讯飞SDK提供的图片,也就是没用到…...

[LLM面试题] 指示微调(Prompt-tuning)与 Prefix-tuning区别
一、提示调整(Prompt Tuning) Prompt Tuning是一种通过改变输入提示语(input prompt)以获得更优模型效果的技术。举个例子,如果我们想将一条英语句子翻译成德语,可以采用多种不同的方式向模型提问,如下图所示…...