【人工智能】通过python练习机器学习中的8大算法
python一系列练习在前面几节中基本练习了一遍,本篇通过机器学习的算法加强python的训练。我印象中常用的几种算法有:线性回归、逻辑回归,决策树,向量机SVM,KNN-近邻,朴素贝叶斯,K-means,神经网络tensorflow。记起来的也就这些,那么久通过python去撸一遍看看效果。
马上开搞
1、线性回归
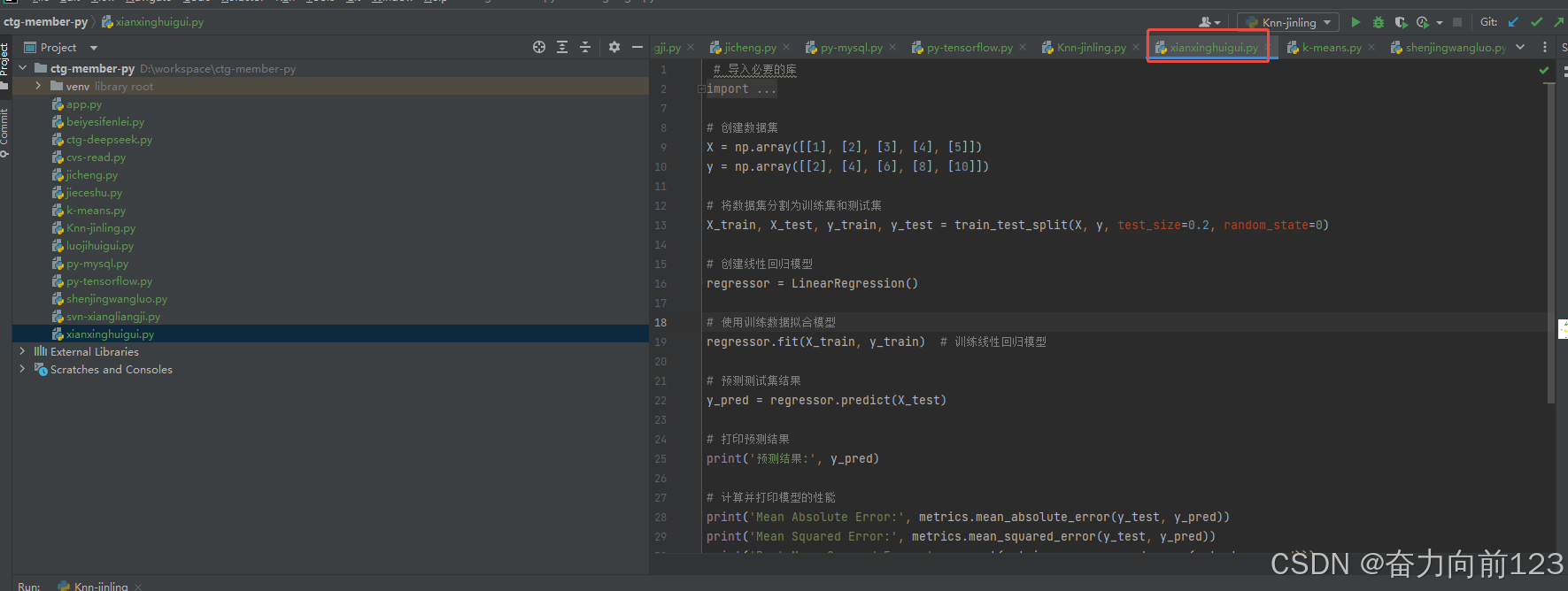
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics# 创建数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([[2], [4], [6], [8], [10]])# 将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 创建线性回归模型
regressor = LinearRegression()# 使用训练数据拟合模型
regressor.fit(X_train, y_train) # 训练线性回归模型# 预测测试集结果
y_pred = regressor.predict(X_test)# 打印预测结果
print('预测结果:', y_pred)# 计算并打印模型的性能
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))# 画出回归线
plt.scatter(X_test, y_test, color='gray')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.show()
运行代码看看
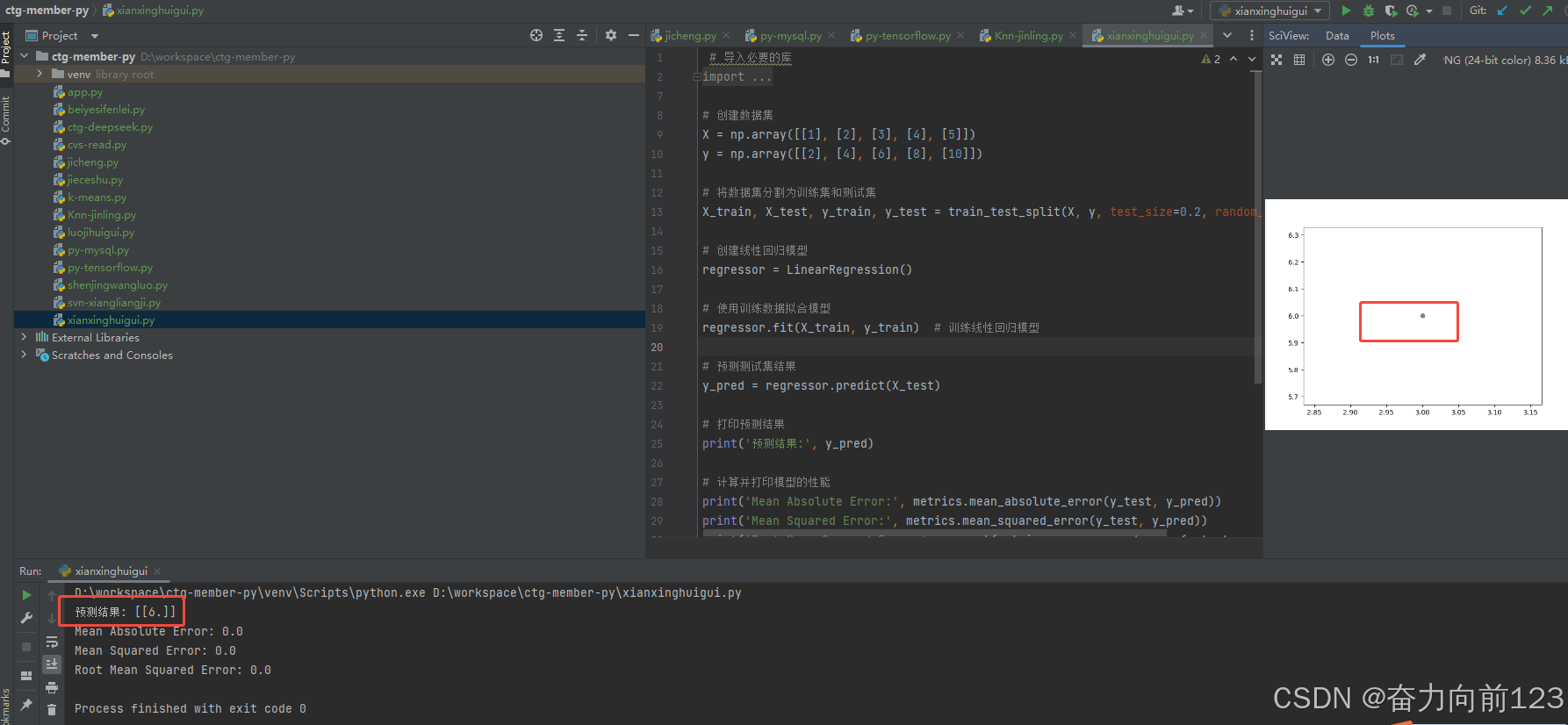
代码运行没问题
现在进行代码分析
需要的python库
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn import metrics
构造一些模拟数据
# 创建数据集 X = np.array([[1], [2], [3], [4], [5]]) y = np.array([[2], [4], [6], [8], [10]])
2、逻辑回归
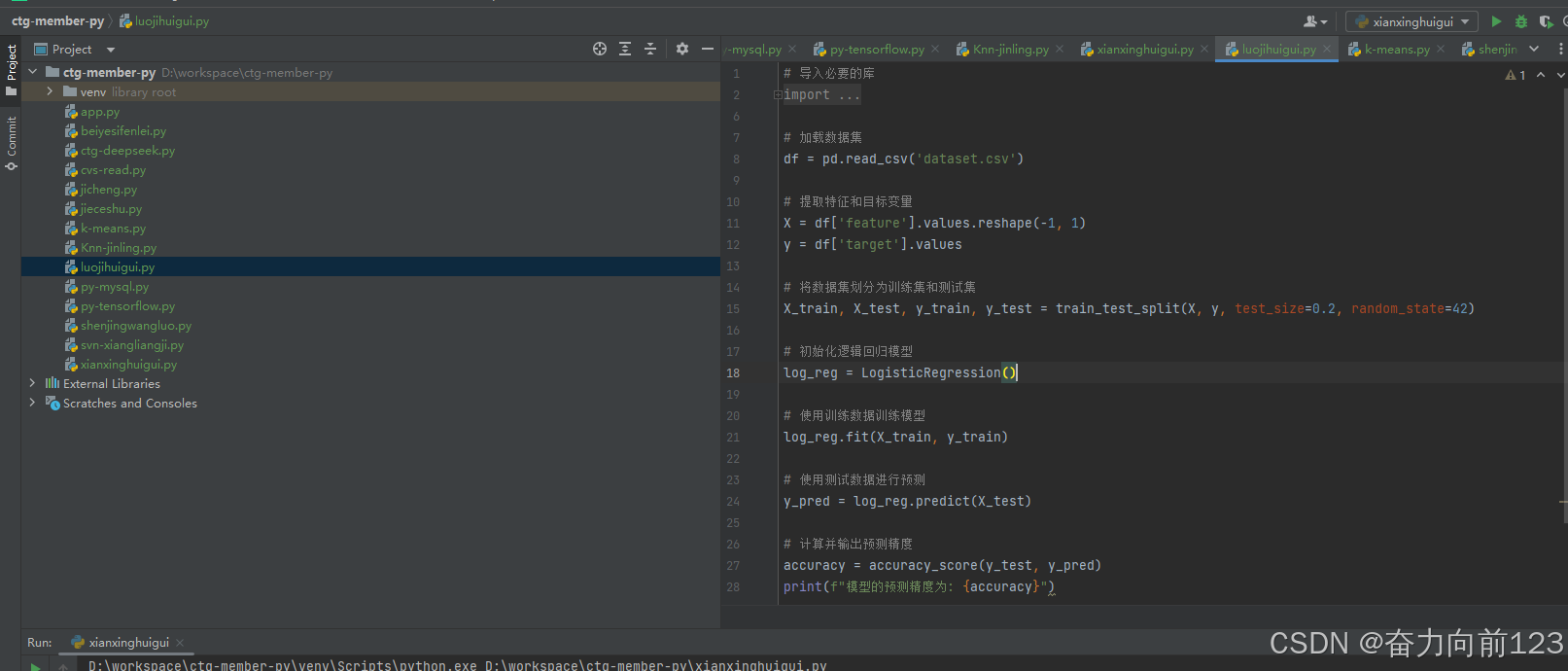
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 加载数据集
df = pd.read_csv('dataset.csv')# 提取特征和目标变量
X = df['feature'].values.reshape(-1, 1)
y = df['target'].values# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化逻辑回归模型
log_reg = LogisticRegression()# 使用训练数据训练模型
log_reg.fit(X_train, y_train)# 使用测试数据进行预测
y_pred = log_reg.predict(X_test)# 计算并输出预测精度
accuracy = accuracy_score(y_test, y_pred)
print(f"模型的预测精度为: {accuracy}")运行看看效果
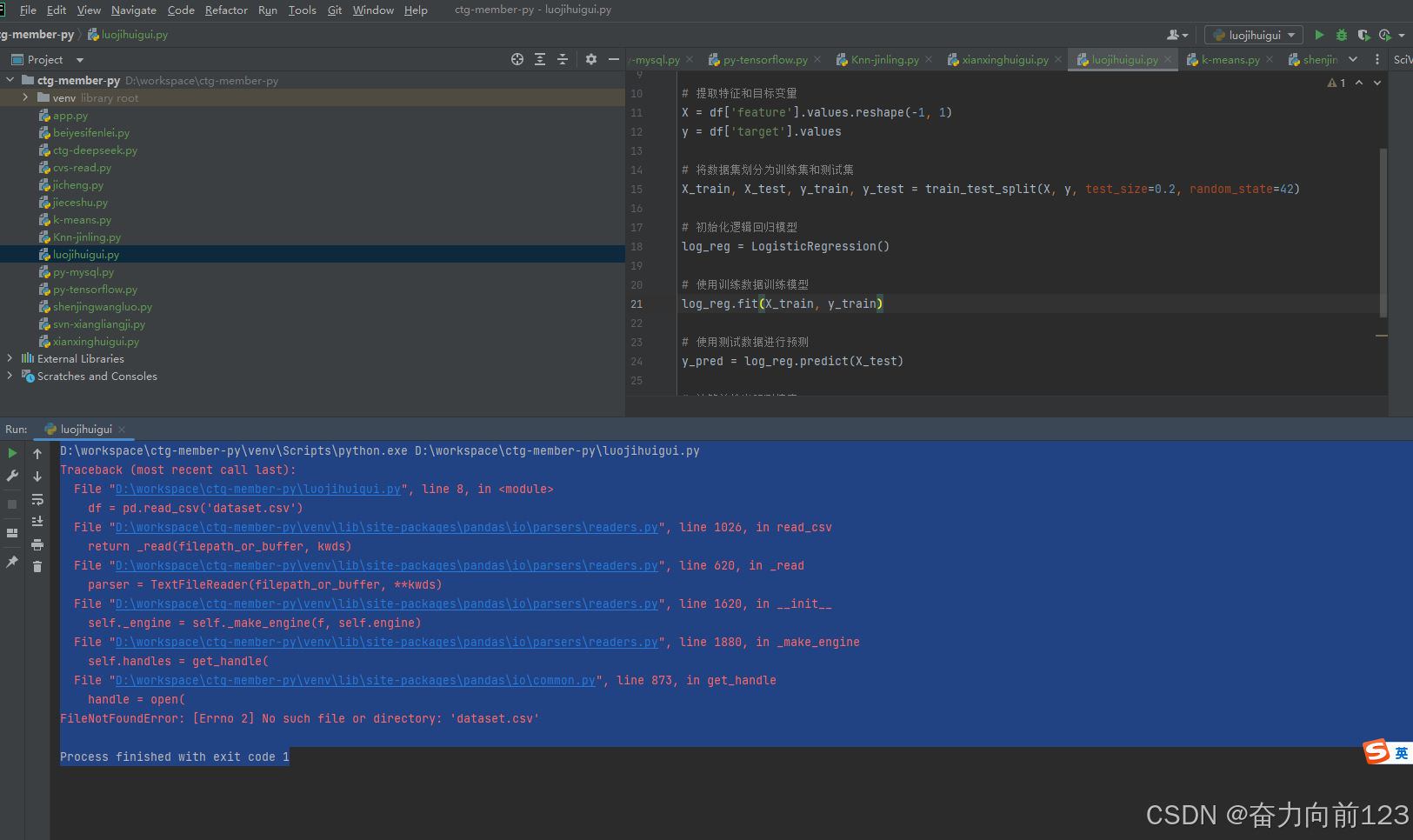
直接报错:
D:\workspace\ctg-member-py\venv\Scripts\python.exe D:\workspace\ctg-member-py\luojihuigui.py
Traceback (most recent call last):
File "D:\workspace\ctg-member-py\luojihuigui.py", line 8, in <module>
df = pd.read_csv('dataset.csv')
File "D:\workspace\ctg-member-py\venv\lib\site-packages\pandas\io\parsers\readers.py", line 1026, in read_csv
return _read(filepath_or_buffer, kwds)
File "D:\workspace\ctg-member-py\venv\lib\site-packages\pandas\io\parsers\readers.py", line 620, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "D:\workspace\ctg-member-py\venv\lib\site-packages\pandas\io\parsers\readers.py", line 1620, in __init__
self._engine = self._make_engine(f, self.engine)
File "D:\workspace\ctg-member-py\venv\lib\site-packages\pandas\io\parsers\readers.py", line 1880, in _make_engine
self.handles = get_handle(
File "D:\workspace\ctg-member-py\venv\lib\site-packages\pandas\io\common.py", line 873, in get_handle
handle = open(
FileNotFoundError: [Errno 2] No such file or directory: 'dataset.csv'
Process finished with exit code 1
原因是没有准备数据;dataset.csv
先分析代码
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 加载数据集
df = pd.read_csv('dataset.csv')
3、决策树
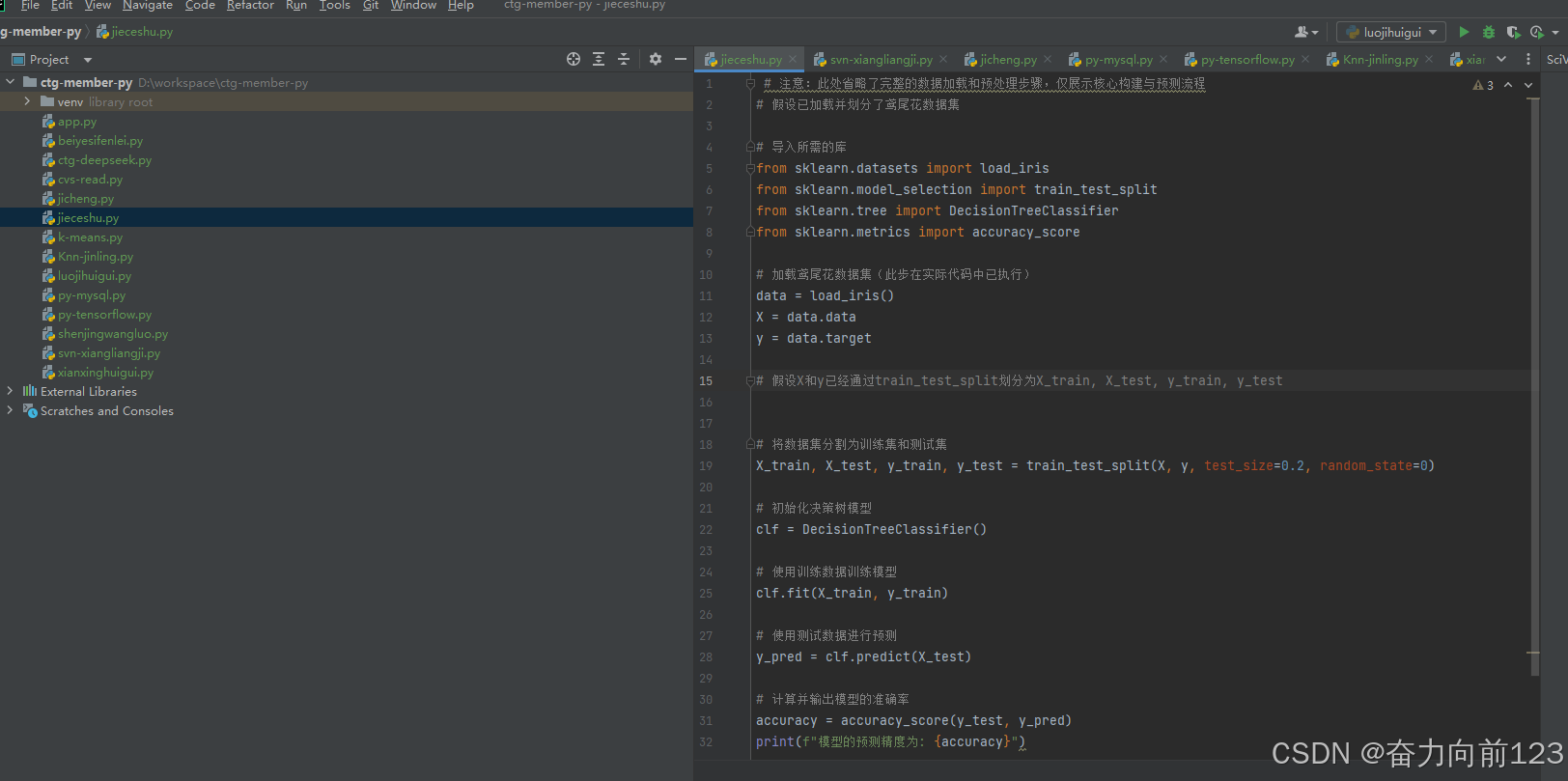
# 注意:此处省略了完整的数据加载和预处理步骤,仅展示核心构建与预测流程
# 假设已加载并划分了鸢尾花数据集# 导入所需的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集(此步在实际代码中已执行)
data = load_iris()
X = data.data
y = data.target# 假设X和y已经通过train_test_split划分为X_train, X_test, y_train, y_test# 将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 初始化决策树模型
clf = DecisionTreeClassifier()# 使用训练数据训练模型
clf.fit(X_train, y_train)# 使用测试数据进行预测
y_pred = clf.predict(X_test)# 计算并输出模型的准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型的预测精度为: {accuracy}")运行代码
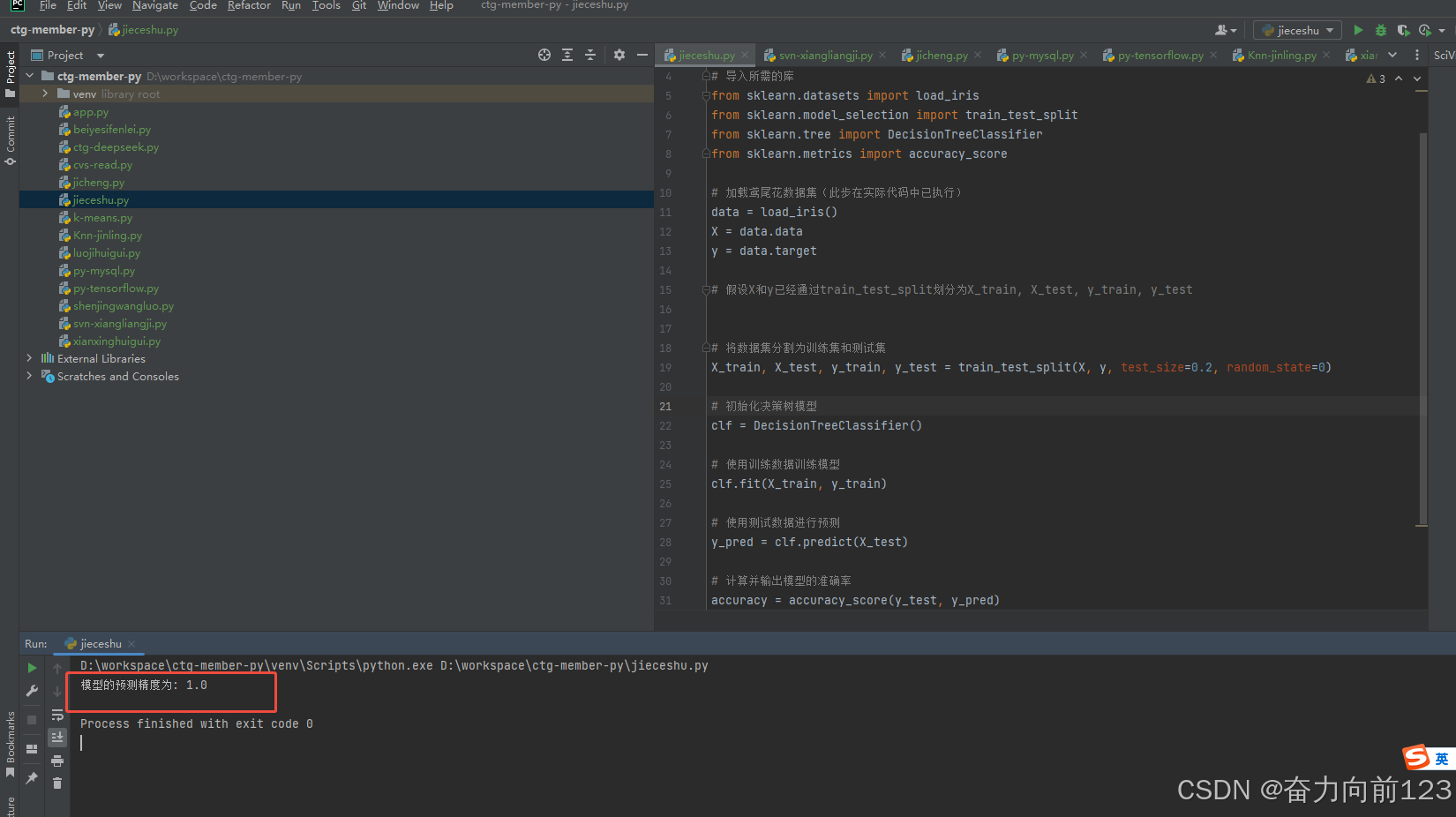
分析代码:
# 导入所需的库 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score# 加载鸢尾花数据集(此步在实际代码中已执行) data = load_iris() X = data.data y = data.target
4、向量机SVM
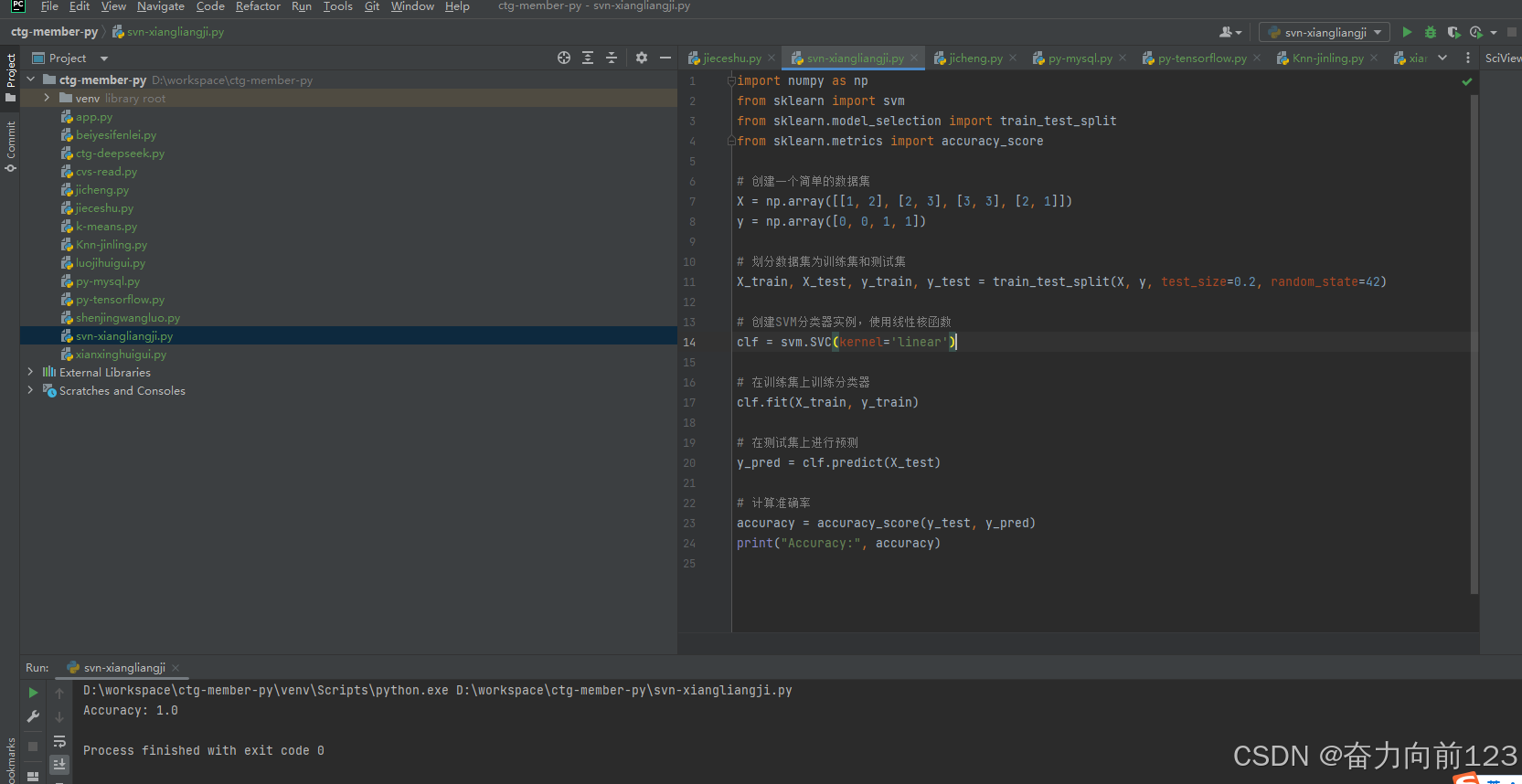
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 创建一个简单的数据集
X = np.array([[1, 2], [2, 3], [3, 3], [2, 1]])
y = np.array([0, 0, 1, 1])# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器实例,使用线性核函数
clf = svm.SVC(kernel='linear')# 在训练集上训练分类器
clf.fit(X_train, y_train)# 在测试集上进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
5、KNN-近邻
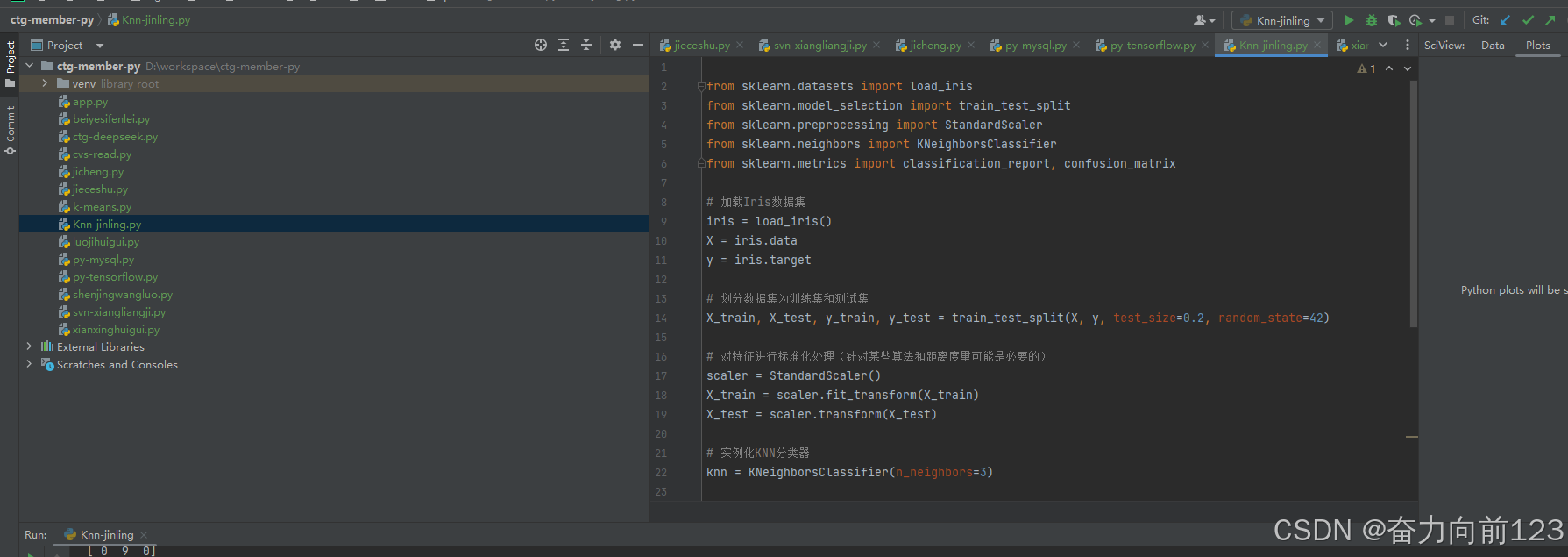
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 对特征进行标准化处理(针对某些算法和距离度量可能是必要的)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 实例化KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)# 训练分类器
knn.fit(X_train, y_train)# 在测试集上进行预测
y_pred = knn.predict(X_test)# 评估分类器性能
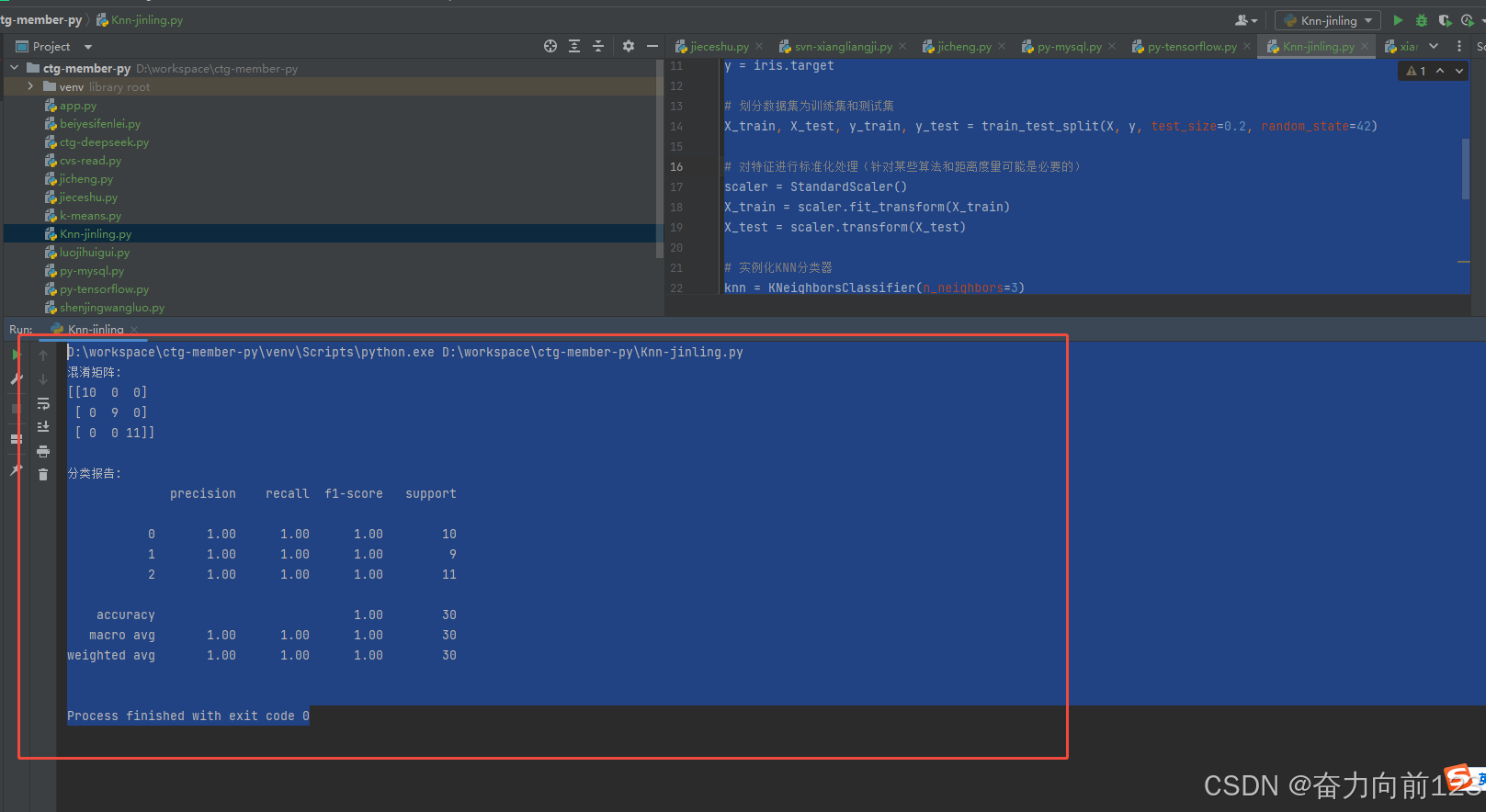
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred))输出结果:
D:\workspace\ctg-member-py\venv\Scripts\python.exe D:\workspace\ctg-member-py\Knn-jinling.py
混淆矩阵:
[[10 0 0]
[ 0 9 0]
[ 0 0 11]]
分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
Process finished with exit code 0
6、朴素贝叶斯
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score# 加载或创建数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练朴素贝叶斯分类器
gnb = GaussianNB()
gnb.fit(X_train, y_train)# 评估分类器性能
y_pred = gnb.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
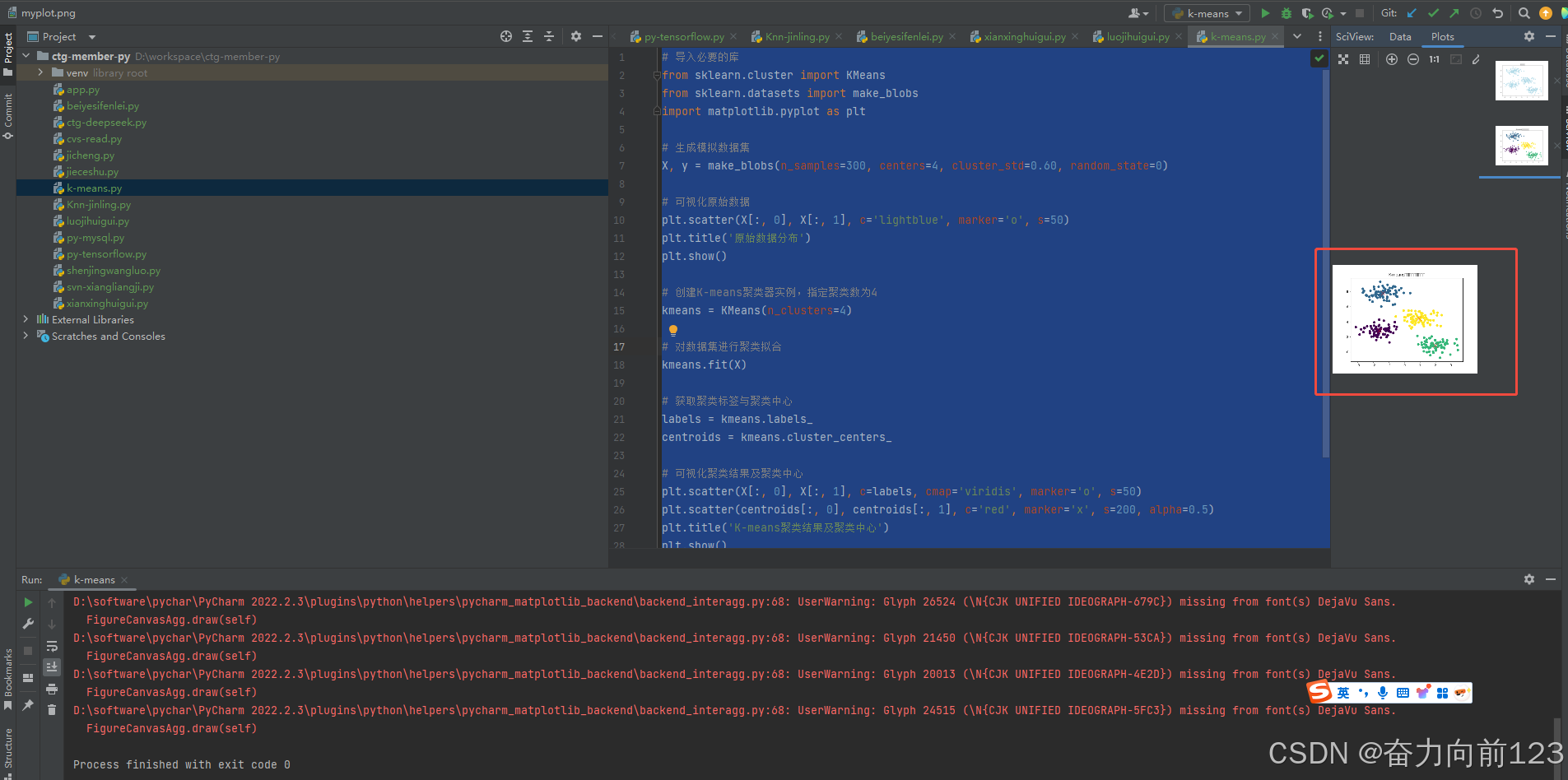
print("Accuracy:", accuracy)7、K-means(重点记住这个是无监督机器学习)
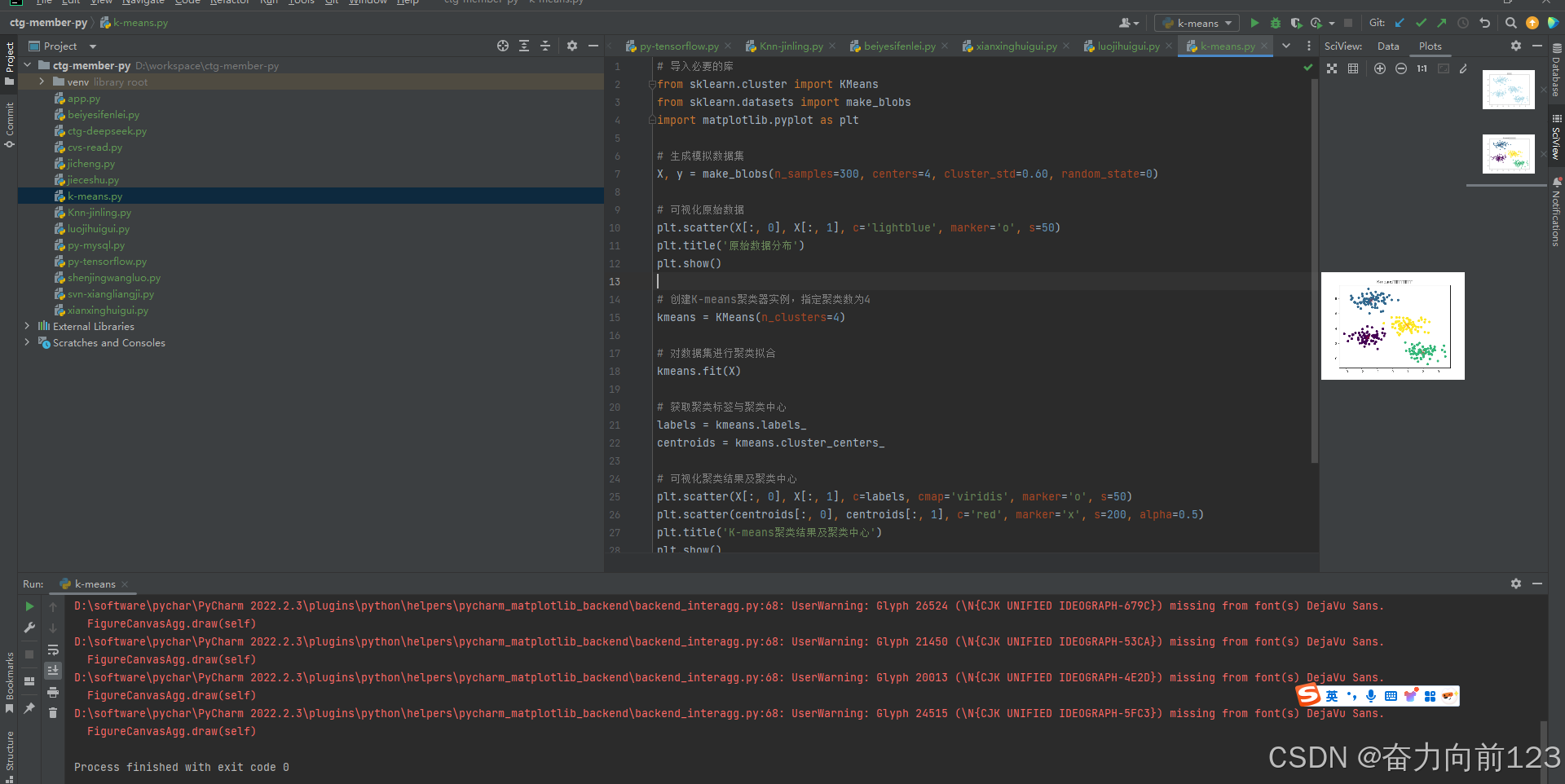
# 导入必要的库
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt# 生成模拟数据集
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 可视化原始数据
plt.scatter(X[:, 0], X[:, 1], c='lightblue', marker='o', s=50)
plt.title('原始数据分布')
plt.show()# 创建K-means聚类器实例,指定聚类数为4
kmeans = KMeans(n_clusters=4)# 对数据集进行聚类拟合
kmeans.fit(X)# 获取聚类标签与聚类中心
labels = kmeans.labels_
centroids = kmeans.cluster_centers_# 可视化聚类结果及聚类中心
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', marker='o', s=50)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', marker='x', s=200, alpha=0.5)
plt.title('K-means聚类结果及聚类中心')
plt.show()
运行结果:
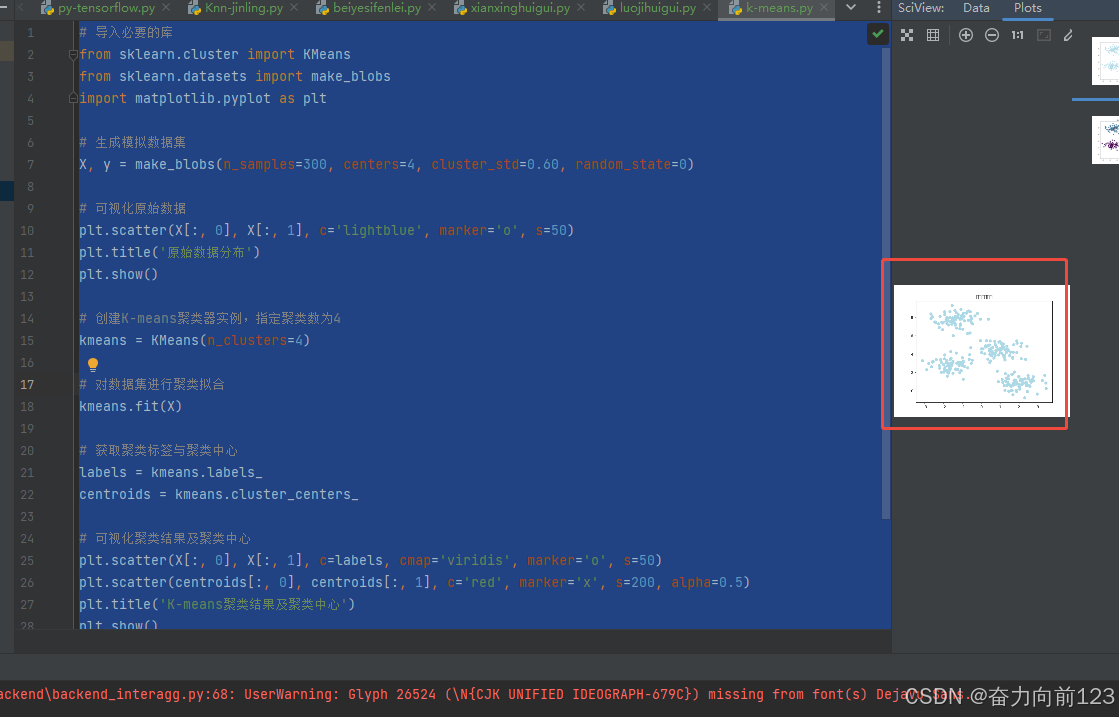
8.神经网络tensorflow
代码报错,没法安装tensorflow,搜索说是python的版本不兼容 需要在3.6到3.9之间,我的python版本是3.13.6 版本过高
#导入tensorflow库
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 归一化处理(将像素值从0-255缩放到0-1)
train_images, test_images = train_images / 255.0, test_images / 255.0#一个简单的卷积神经网络(CNN)来处理MNIST数据集
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10)
])#在训练模型之前,我们需要编译模型,指定优化器、损失函数和评估指标
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
#使用训练数据训练模型。
model.fit(train_images[..., np.newaxis], train_labels, epochs=5)
#评估模型在测试数据上的表现。
test_loss, test_acc = model.evaluate(test_images[..., np.newaxis], test_labels, verbose=2)
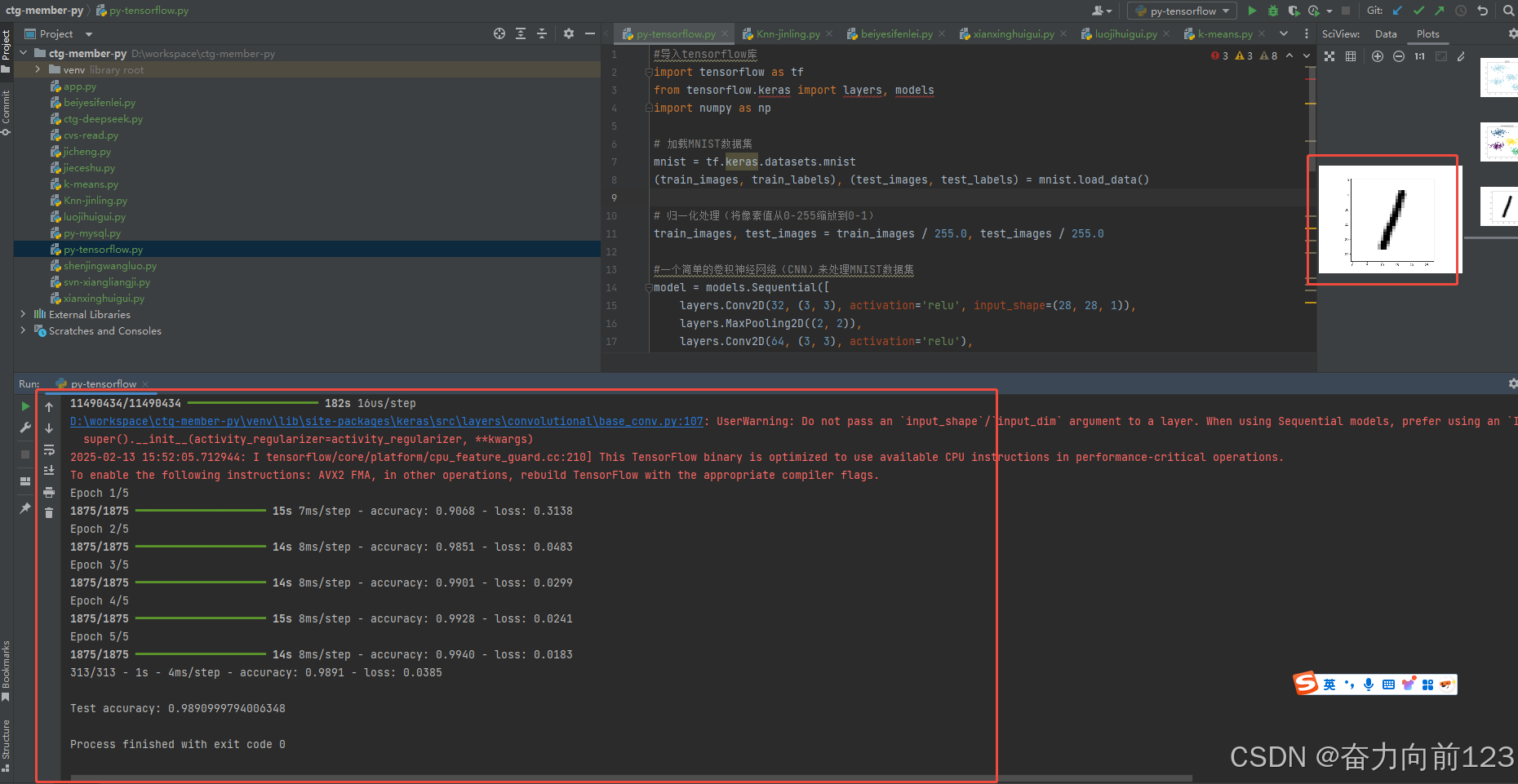
print('\nTest accuracy:', test_acc)#模型可视化
import matplotlib.pyplot as plt
import random
i = random.randint(0, len(test_images)) # 选择一个随机图像进行展示
plt.imshow(test_images[i], cmap=plt.cm.binary)
plt.show()
运行看看
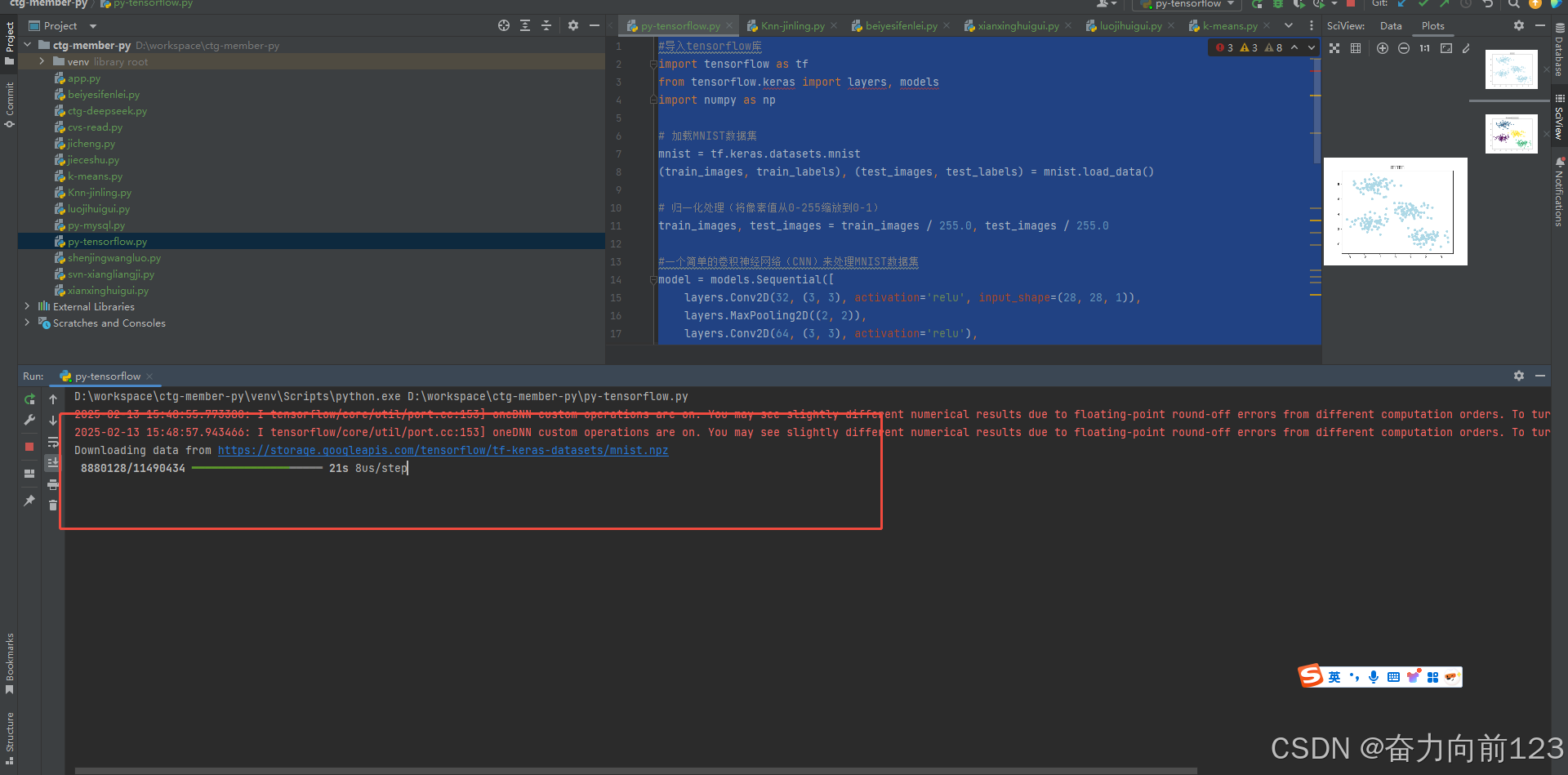
运行成功:
D:\workspace\ctg-member-py\venv\Scripts\python.exe D:\workspace\ctg-member-py\py-tensorflow.py
2025-02-13 15:48:55.773380: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-02-13 15:48:57.943466: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 182s 16us/step
D:\workspace\ctg-member-py\venv\lib\site-packages\keras\src\layers\convolutional\base_conv.py:107: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
2025-02-13 15:52:05.712944: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 15s 7ms/step - accuracy: 0.9068 - loss: 0.3138
Epoch 2/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 14s 8ms/step - accuracy: 0.9851 - loss: 0.0483
Epoch 3/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 14s 8ms/step - accuracy: 0.9901 - loss: 0.0299
Epoch 4/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - accuracy: 0.9928 - loss: 0.0241
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 14s 8ms/step - accuracy: 0.9940 - loss: 0.0183
313/313 - 1s - 4ms/step - accuracy: 0.9891 - loss: 0.0385
Test accuracy: 0.9890999794006348
Process finished with exit code 0
相关文章:
【人工智能】通过python练习机器学习中的8大算法
python一系列练习在前面几节中基本练习了一遍,本篇通过机器学习的算法加强python的训练。我印象中常用的几种算法有:线性回归、逻辑回归,决策树,向量机SVM,KNN-近邻,朴素贝叶斯,K-means…...

机器学习数学基础:21.特征值与特征向量
一、引言 在现代科学与工程的众多领域中,线性代数扮演着举足轻重的角色。其中,特征值、特征向量以及相似对角化的概念和方法,不仅是线性代数理论体系的核心部分,更是解决实际问题的有力工具。无论是在物理学中描述系统的振动模式…...
Android Studio2024版本安装环境SDK、Gradle配置
一、软件版本,安装包附上 👉android-studio-2024.1.2.12-windows.exe👈 👉百度网盘Android Studio安装包👈 (若下载连链接失效可去百度网盘链接下载) 二、软件安装过程 三、准备运行…...

RabbitMQ学习—day2—安装
目录 普通Linux安装 安装RabbitMQ 1、下载 2、安装 3. Web管理界面及授权操作 Docker 安装 强力推荐学docker,使用docker安装 普通Linux安装 安装RabbitMQ 1、下载 官网下载地址:https://www.rabbitmq.com/download.html(opens new window) 这…...

Jenkins 新建配置Pipeline任务 三
Jenkins 新建配置Pipeline任务 三 一. 登录 Jenkins 网页输入 http://localhost:8080 输入账号、密码登录 一个没有创建任务的空 Jenkins 二. 创建 任务 图 NewItem 界面左上角 New Item 图NewItemSelect 1.Enter an item name:输入任务名 2.Select an ite…...

社区版IDEA中配置TomCat(详细版)
文章目录 1、下载Smart TomCat2、配置TomCat3、运行代码 1、下载Smart TomCat 由于小编的是社区版,没有自带的tomcat server,所以在设置的插件里面搜索,安装第一个(注意:安装时一定要关闭外网,小编因为这个…...

FFmpeg Audio options
ffmpeg音频命令选项: 1. -aframes number (output) 设置输出音频帧的数量。这是一个已经过时的别名,应该使用 -frames:a 参数来代替。 示例: ffmpeg -i input.mp4 -frames:a 300 output.mp4 表示输出300帧音频 2. -ar[:stream_specifier] freq (in…...

MATLAB 生成脉冲序列 pulstran函数使用详解
MATLAB 生成脉冲序列 pulstran函数使用详解 目录 前言 一、参数说明 二、示例一 三、示例二 总结 前言 MATLAB中的pulstran函数用于生成脉冲序列,支持连续或离散脉冲。该函数通过将原型脉冲延迟并相加,生成脉冲序列,适用于信号处理和系统…...
概率论、组合数学知识点汇总
1、概率论知识点 全概率公式:如果事件B1,B2,…,Bn是样本空间的一个划分,则:贝叶斯定理:协方差:协方差用来衡量两个变量之间的变化趋势是否一致,公式为相关系数(Pearson):…...

【人工智能】deepseek R1模型在蓝耘智算平台的搭建与机器学习的探索
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 蓝耘智算平台 deepseek R1简介与优点蓝耘智算平台蓝耘智算平台简介蓝耘智算平台优势deepseek R1模型在蓝耘智算平台的搭建模型使用与机器学习…...

tomcat html乱码
web tomcat html中文乱码 将html文件改成jsp <% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8"%>添加 <meta charset"UTF-8">...

蓝桥杯算法日记|2.11二分算法
二分法是一种在有序数组中查找某一特定元素的搜索算法。二分法的基本思想是:每次将区间缩小一半,重复这个过程,直到找到目标值或者确定目标值不存在于该区间内。 整数二分、浮点二分、二分答案 退出条件:l、r相邻时候退出 #inclu…...

基于单片机的智能奶茶机(论文+源码+图纸)
1总体架构设计 本课题为基于单片机的智能奶茶机设计,其系统架构上设计如图2.1所示,整个系统包括了DS18B20温度传感器、继电器模块、LCD液晶、蜂鸣器、按键、STC89C52单片机等器件,在功能上用户可以通过按键键控制选择甜度和添加物以及设置温度…...

Centos7系统安装redis
Centos7系统安装redis 下载编译配置配置环境变量服务脚本安装使用远程连接 下载 下载地址:https://download.redis.io/releases/,选择版本6.2.7 具体下载链接:https://download.redis.io/releases/redis-6.2.7.tar.gz 操作:在ro…...

图数据库neo4j进阶(一):csv文件导入节点及关系
CSV 一、load csv二、neo4j-admin import<一>、导入入口<二>、文件准备<三>、命令详解 一、load csv 在neo4j Browser中使用Cypher语句LOAD CSV,对于数据量比较大的情况,建议先运行create constraint语句来生成约束 create constraint for (s:Student) req…...

langchain学习笔记之小样本提示词Few-shot Prompt Template
langchain学习笔记之小样本提示词 引言 Few-shot Prompt Templates \text{Few-shot Prompt Templates} Few-shot Prompt Templates简单介绍示例集创建创建 ExamplePrompt \text{ExamplePrompt} ExamplePrompt与 ExampleSelector \text{ExampleSelector} ExampleSelector创建 Fe…...

【认证授权FAQ】HP Anyware LLS服务器常用命令
pcoip-set-password //lls上设置管理员密码 export HISTIGNORE“export” export TERADICI_LICENSE_SERVER_PASSWORD‘Your Password’ sudo pcoip-configure-proxy -v //检查是否使用了代理 pcoip-activate-online-license -a -c //在线激活 pcoip-return-online-license -a …...

深度剖析责任链模式
一、责任链模式的本质:灵活可扩展的流水线处理 责任链模式(Chain of Responsibility Pattern)是行为型设计模式的代表,其核心思想是将请求的发送者与接收者解耦,允许多个对象都有机会处理请求。这种模式完美解决了以下…...

Windows中指定路径安装DockerDesktop
Widnows中直接安装docker desktop,默认会被安装到C:/Program Files/Docker路径下,可以通过下面方式来设置安装到指定的目录下 1. 先卸载干净(如果已安装过的话) 如果未卸载干净,重装会提示 Exising installation is up to date 卸载Docker…...
)
Java LinkedList(单列集合)
LinkedList 是 Java 中实现了 List 接口的一个类,它属于 java.util 包。与 ArrayList 不同,LinkedList 是基于双向链表实现的,适合于频繁进行插入和删除操作的场景。 1. LinkedList 的基本特性 基于链表实现:LinkedList 使用双向…...

海外服务器都有什么作用?
海外服务器具体就是指部署在中国大陆以外地区的服务器,企业选择租用海外服务器能够显著提高不同国家和地区用户的访问速度,当网站的服务器部署在目标用户所在地附近时,数据信息所传输的距离就会缩短,大大降低了网络访问的延迟度&a…...

floodfill算法系列一>岛屿的最大面积
题解 整体思路:代码设计:代码呈现: 整体思路: 代码设计: 代码呈现: class Solution {int ret,m,n,count;boolean[][] vis;public int maxAreaOfIsland(int[][] grid) {m grid.length;n grid[0].length;v…...

手机用流量怎样设置代理ip?
互联网各领域资料分享专区(不定期更新): Sheet...

2025年2月13日笔记
——自定义函数: #include<iostream> #include<bits/stdc.h> using namespace std; int a(int x,int y); int a(int x,int y){ return x*y; } int main(){ int c5; int d3; int resulta(c,d); cout<<"两数的乘积是:"&…...

游戏引擎学习第100天
仓库:https://gitee.com/mrxiao_com/2d_game_2 昨天的回顾 今天的工作重点是继续进行反射计算的实现。昨天,我们开始了反射和环境贴图的工作,成功地根据法线显示了反射效果。然而,我们还没有实现反射向量的计算,导致反射交点的代…...

Leetcode:学习记录
一、滑动窗口 1. 找出数组中元素和大于给定值的子数组的最小长度 右指针从左到右遍历,在每个右指针下,如果去掉左边元素的元素和大于等于给定值则左指针右移一次,直到小于给定值,右指针右移一个。 2.找到乘积小于给定值的子数组…...

AT32系列微控制器低压电机控制开发板
参考:《UM0014_AT32_LV_Motor_Control_EVB_V20_User_Manual_V1.0.1_ZH.pdf》 开发板介绍 此电机开发板是一个泛用型的低压三相电机驱动器,应用雅特力科技AT32系列微控制器搭配雅特力电机函数库,可驱动直流无刷电机、交流同步电机࿰…...

如何保持 mysql 和 redis 中数据的一致性?PegaDB 给出答案
MySQL 与 Redis 数据保持一致性是一个常见且复杂的问题,一般来说需要结合多种策略来平衡性能与一致性。 传统的解决策略是先读缓存,未命中则读数据库并回填缓存,但方式这种维护成本较高。 随着云数据库技术的发展,目前国内云厂商…...

Vue3(3)
一.具体业务功能实现 (1)登录注册页面 [element-plus 表单 & 表单校验] 功能需求说明: 1.注册登录 静态结构 & 基本切换 2.注册功能 (校验 注册) 3.登录功能 (校验 登录 存token) import request from /utils/request// 注册接…...

2025 西湖论剑wp
web Rank-l 打开题目环境: 发现一个输入框,看一下他是用上面语言写的 发现是python,很容易想到ssti 密码随便输,发现没有回显 但是输入其他字符会报错 确定为ssti注入 开始构造payload, {{(lipsum|attr(‘global…...