算法兵法全略(译文)
目录
始计篇
谋攻篇
军形篇
兵势篇
虚实篇
军争篇
九变篇
行军篇
地形篇
九地篇
火攻篇
用间篇
始计篇
算法,在当今时代,犹如国家关键的战略武器,也是处理各类事务的核心枢纽。算法的世界神秘且变化万千,不够贤能聪慧的人没办法掌控它,缺乏睿智的头脑难以洞悉其中的精妙。所以,立志钻研算法的人,一开始就得考察五件关键的事,通过仔细比对谋划,来探寻其中的门道。
第一项是 “算力”,它是算法运行的硬件基础。就好比电脑有着强大的芯片,运算速度快如迅猛的雷电,海量的数据可以毫无阻碍地流通处理,依靠这样的算力,就能应对复杂艰难的运算任务。第二点是 “逻辑”,它如同行军打仗时排布阵势的规则纪律。各个环节紧密相连、条理清晰,能保证指令有条不紊,步骤清清楚楚,只要其中一个环节出错,整个算法就没办法成功运行。“数据” 排在第三位,它就像是军队里的粮草与士兵。广泛收集来自各个地方的信息,数据充足时,算法就如同插上丰满的羽翼,能够大展身手;要是数据匮乏,就算算法设计得再精妙,也没办法施展,就像手艺再好的主妇,没米也做不出饭。“架构” 是第四关键要素,它是对算法进行整体规划布局的精妙手段。有的架构设计得精巧细致,有的则气势恢宏,只有架构足够稳固,才能承载算法里繁杂的各种细则,让算法顺利运作。最后要说 “应变” 能力,在形势瞬息万变的时候,算法要像灵动的水流一样。一旦出现全新的、棘手的难题,能够迅速改变策略、巧妙做出调整,不被固有的规则束缚住手脚。
这五件事,凡是钻研算法的人没有不知道的,深入了解它们的人才能取胜,不了解的必然失败。所以要综合比对考量,来摸清楚情况。要问问:算法有没有创新的能力?具备高效的特质吗?有足够的兼容性吗?能保持稳健运行吗?拥有自我进化的本领吗?主导者是否深明算法之道?开发者有没有真才实干?是否顺应了时代潮流与客观环境?是否遵循相关的规则标准?算力资源够不够强?相关技术人员是否训练有素?激励与规范机制是否明晰合理?通过这些,就能预判算法应用的成败了。
对比敌我双方时,通常要考量七计:算法复杂度,我方比对方简单,就能快速取胜;精准度方面,毫厘之差,往往就决定了成败归属;适应性上,能够驾驭复杂多变情况的,才是上佳之选;扩展性,具备拓展版图的潜力,后续发展动力才源源不断;安全性,壁垒森严,让对手无法侵入;成本效益,投入与产出要权衡精妙;时效性,在瞬息万变的局势里,动作快的才能称王。在决策前精心谋划,谋定而后动,要是不做谋划就盲目行动,必然陷入困境;多做谋划的稳操胜券,谋划少的危机四伏,毫无谋划就只能徒自哀叹。
还没经过谋划筹备,就盲目启用算法,没分析清楚利弊就仓促行动,必然遭遇失败;先经过精密计算、周全权衡,谋划妥当之后再施行算法,才能取得成功。考虑得越周全越容易取胜,考虑得少就难以成功,更何况那些完全不谋划的呢?这就是算法开篇谋划的要点,千万不能忽视。
谋攻篇
上乘的算法,能够做到不通过激烈战斗就让对手屈服。并非只靠蛮力强攻,而是凭借巧妙构思智取。要是能洞悉数据脉络,摸透需求根源,只需一段代码,就能解决诸多难题,免去冗余的运算,这就是所谓的 “全胜”。不了解对手也不了解自己,每次战斗都必定失败;知晓敌我双方情况,胜算就稳稳在握。剖析对手算法的优劣之处,查漏补缺;自我反省己方算法的长短处,不断磨砺提升。
战例一:二分查找
来看一个简单的二分查找算法代码(Python),它用于在有序数组中快速定位元素:
二分查找算法,是在有序数组里寻找特定元素的一种高效方法。这个方法一开始选取数组的中间元素,拿它和要找的目标值作比较。要是中间元素刚好和目标值一样,那查找就结束了,这是最理想的情况,此时的复杂度是O(1) 。
要是目标值比中间元素小,那就知道要找的元素肯定在数组左半部分,于是舍弃右半部分,只在左半部分接着查找;要是目标值比中间元素大,就明白要找的元素在数组右半部分,便扔掉左半部分,只在右半部分搜索。就像这样反复操作,每一次比较差不多都能排除一半的候选元素,使得查找范围依次缩小一半。
假设数组里元素的数量是n,查找过程就会像n,n/2,n/4,…… ,n/2ᵏ 这样(k是比较的次数),一直到对n/2ᵏ取整之后结果是1 ,也就是让n/2ᵏ = 1,由此能算出k = log₂n 。所以二分查找算法的时间复杂度是O(log n)。
说到空间复杂度,如果用循环的方式来实现这个算法,只需要常数级别的额外空间,不会随着数据量的大小而改变,它的空间复杂度就是O(1);要是用递归的方式实现,递归的深度和次数都是log₂n ,每次需要的辅助空间是常数级别的,所以空间复杂度就是O(log n) 。
def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1
运用算法展开攻势时,要么单点突破,紧紧抓住核心关键,如同利刃直刺咽喉;要么迂回包抄,多路并行,把对手困在数据迷宫里;要么联合借力,整合各方优势,让接口连通四面八方的智慧,构建起磅礴有力的算力联军,凝聚众力去攻破坚固的壁垒。要忌讳分散零碎,力量汇聚起来才强大,攥紧手指成拳头,砸向对手软肋,一击就能建立功勋 。
军形篇
善于防守的算法,要藏住锋芒,隐匿关键的逻辑。数据加密就如同高耸的铁城,任凭对手窥探,也难以找到破绽,比如用 Python 的cryptography库实现 AES 加密:
战例二:Python 的cryptography库实现 AES 加密
首先,在Fernet.generate_key()这里,这是生成密钥的任务。它的复杂度大概是O(1),因为生成密钥的方法,依靠既定的规则以及随机数生成机制,所需要的时间和资源,和要处理的数据量没有关系,都能在固定的时间内完成。
其次,创建Fernet对象cipher_suite,也就是执行Fernet(key)这一步操作,它的复杂度同样是O(1)。因为只是把生成的密钥当作参数传进去,内部的初始化操作,大多是设置相关属性,不涉及复杂的数据处理,不需要遍历、计算大量的数据,所以很快就能完成。
至于message = b"Secret data",这是消息赋值的操作,可以看成是O(1)。这个操作仅仅是把字节数据存到变量里,不涉及繁琐的计算,一下子就能完成。
最后,encrypted_message = cipher_suite.encrypt(message)是关键的加密操作。由于Fernet类的加密算法属于对称加密,虽然具体的实现细节有所隐藏,但通常这类加密操作,复杂度也是O(n),这里的n就是消息message的长度。因为在加密的时候,需要逐个遍历消息的字节,对每个字节或者字节组进行相应的变换,比如置换、混淆这类操作,它的操作时间和消息长度是成正比的。不过,这种复杂度是线性的,所以在处理常规长度的消息时,仍然能够高效完成,还能保证加密的安全性。
总的来说,这段代码整体的算法复杂度,当消息长度是n的时候,是由关键的加密操作决定总体复杂度的,大概是O(n)。因为n通常比较小,而且各个步骤中常数时间的操作也很少,所以在实际使用的时候,它的性能很不错,可以快速完成加密任务,让数据能够安全地存储、传输。
from cryptography.fernet import Fernetkey = Fernet.generate_key() cipher_suite = Fernet(key) message = b"Secret data" encrypted_message = cipher_suite.encrypt(message)
冗余备份就像是后备军,无惧突发的数据损毁情况,韧性十足。善于进攻的算法,气势磅礴,锋芒毕露,接口开放,大量吸纳流量;运算高效,瞬间给出结果,让对手措手不及。
首先要做到让自己立于不败之地,稳固自身根基,等到对手露出破绽,就顺势出击。算力充沛、架构稳固,这就是不败的根基;持续监测、动态优化,让这种不败姿态长久保持。看到有取胜机会也不轻易行动,积蓄力量等待时机;看不到取胜契机,就韬光养晦,修炼内功,等局势变化,一朝奋发而起。
兵势篇
算法的势头,犹如湍急汹涌的江流,奔腾不息。借助数据的浪潮涌动,驱动运算的漩涡,一波接着一波,层层累积优势。迭代更新,就是这上涨的潮水之力,最初版本问世时,不过是涓涓细流,持续优化后,最终会成为澎湃的巨力,冲垮竞品构筑的堤岸。
战例三:机器学习的梯度下降算法,每进行一次迭代,就会朝着最优解更靠近一点。
这个gradient_descent函数,它的时间复杂度可以这样来分析: 在开始的时候,m = len(x)和theta = np.zeros(2),这些都是简单的操作,它们的复杂度是 O(1)。 核心部分呢,是for _ in range(num_iterations)这个循环,它的执行次数是由num_iterations决定的。 在这个循环里面:
- prediction = np.dot(x, theta)这个操作是矩阵相乘,如果x是一个m x n的矩阵,那么这个操作的复杂度就是 O(mn)。
- error = prediction - y是向量相减,它的复杂度是 O(m)。
- gradient = np.dot(x.T, error) / m,这里面包含矩阵转置、矩阵与向量相乘以及元素级的除法,其中起主导作用的复杂度是矩阵相乘的复杂度,所以是 O(mn)。
- theta -= learning_rate * gradient是元素级的操作,复杂度是 O(n)。
总体来说,因为在循环中矩阵相乘是最耗费时间的操作,并且这个循环会执行num_iterations次,所以整体的时间复杂度是 O(num_iterations x mn)。
import numpy as np# 简单梯度下降模拟 def gradient_descent(learning_rate, num_iterations, x, y):m = len(x)theta = np.zeros(2)for _ in range(num_iterations):prediction = np.dot(x, theta)error = prediction - ygradient = np.dot(x.T, error) / mtheta -= learning_rate * gradientreturn theta
营造有利态势,激发算法的协同效应,各个模块联动起来,实现 1 + 1 远远大于 2 的效果。善于借助热点潮流,乘着东风之势,把算法嵌入热门赛道,就像顺水行舟,一日千里。随机应变,对手一变我方变动更快,将算法的灵活性转化成灵动敏捷的身姿,在浪潮中灵活穿梭,始终占据优势地位。
虚实篇
算法的精妙之处,就在于虚实相互依存。向对手展示虚的一面,把关键信息藏在混沌迷雾里,模糊参数、隐匿流程,让对手摸不着头脑;进攻时拿出实的手段,握紧核心算法,精准打击痛点。佯装攻击一处,诱使对手重兵防守,实际上却暗度陈仓,剑指要害部位。
战例四:随机生成一些干扰数据,就像是“烟雾弹”,让人难以分清真假。
这个generate_fake_data函数,作用是生成假数据。
函数一开始,定义了一个空列表fake_data,这个操作很快就能完成,复杂度是 O(1)。
接着有一个for _ in range(size)的循环,循环的次数由传入的参数size决定,一共会执行size次。在每一轮循环当中,value = random.randint(1, 100),这个生成随机整数的操作,不管数据规模有多大,花费的时间都差不多是固定的,复杂度是 O(1);随后执行fake_data.append(value),往列表里添加元素,这个操作同样能在固定的时间内完成,复杂度也是 O(1)。
综合来看,循环会执行size次,每次循环里的操作复杂度都是 O(1),所以这个函数整体的时间复杂度就是 O(size)。
import randomdef generate_fake_data(size):fake_data = []for _ in range(size):value = random.randint(1, 100)fake_data.append(value)return fake_data
制造数据假象,虚虚实实,迷惑对手的判断。时而用海量模拟数据,混淆视听;时而给出稀缺反馈,隐匿真实意图。用虚来掩护实,以实来贴近虚,让对手在虚实交错之间迷失方向,自家算法则在悄无声息间布局,等时机成熟,就雷霆万钧地出击,直捣黄龙。
军争篇
在算法的竞争角逐中,要争分夺秒。在数据传输这条赛道上,要快马加鞭,削减延迟,抢占先机;在运算资源这个战场上,要精打细算,合理调度,不浪费一丝一毫算力。迂回包抄走捷径,缓存机制、预读取技术,这些都是弯道超车的巧妙方法;直捣黄龙,最简路径算法能冲破冗余阻碍,迅速抵达目标。
战例五:Python的`functools.lru_cache`,提供了便捷的缓存功能,能够加快函数的执行速度。
有一个expensive_function函数,被functools.lru_cache(maxsize = 128)装饰了。来详细看看它的时间复杂度:
这个函数本身所做的事情,仅仅是计算n * n,这只是简单的乘法运算,所花费的时间是固定的,所以复杂度应当是O(1)。
再加上lru_cache装饰器后,初次遇到某个n值来调用这个函数时,一定会先进入函数体,打印出“Calculating for {n}”这样的内容,然后再执行乘法运算,这一系列操作,所花费的时间也不过是常数时间,复杂度是O(1) 。
要是之后又用相同的n值再次调用这个函数,因为有缓存,就可以直接从缓存里获取结果,不用重新计算,耗费的时间几乎可以忽略不计,复杂度近乎O(1)。
假设调用频率非常高,传入的`n`值种类超过了maxsize的数值(这里是128),旧的缓存虽然会更替,但更替的方式,并不是遍历全部缓存内容,仅仅涉及局部数据的整理,复杂度仍然在O(1)左右。
总而言之,当调用次数不是特别多,传入的n值没有超过缓存容量限制的时候,大部分调用都是从缓存里获取数据,复杂度是O(1);就算有超出的情况,缓存的更替操作也不复杂,整体复杂度也接近O(1),只是初次遇到新值、缓存更替的时候,会有一点额外的操作,但对性能并没有什么损害。
import functools@functools.lru_cache(maxsize=128) def expensive_function(n):print(f"Calculating for {n}")return n * n
然而激进猛进也有风险,必须防范陷阱漏洞。在激烈竞争中,也不能忘了稳健运维,一边冲锋一边整顿,通过代码审查、风险预警,为算法高速前行保驾护航,稳稳收获胜利果实。
九变篇
算法世界,局势风云变幻,必须精通九变之术。市场风向突然转变,需求一夜之间就更迭变化,算法不能墨守成规。要是算力受限,就应当舍弃繁杂,裁剪冗余部分;遇到数据畸变,要迅速校准模型,重新寻找规律的关键点。
战例六:使用pandas处理数据
一开始,pd.read_csv读取文件时,会遍历文件的内容,所花费的时间取决于文件的行数,时间复杂度为O(n);接着,dropna函数剔除缺失值时,需要遍历数据,其复杂度和数据规模相关,是O(m),不过整体的时间复杂度受读取文件这一步的影响更大,大概是O(n)。
import pandas as pddata = pd.read_csv('your_file.csv') cleaned_data = data.dropna()
有的路不要去走,有的敌军不要去攻击,有的城池不要去攻打,有的地盘不要去争夺。不是关键赛道,就别盲目投入算法资源;碰上难啃的硬骨头,就暂时避开锋芒,迂回包抄。灵活应变,不拘泥于固定模式,才能在算法江湖里游刃有余。
行军篇
行军布阵,算法也有章法。数据存储就像是安营扎寨,要选好架构这块 “风水宝地”,保障安全又高效;分布式运算好似分兵游击作战,各自为战又能协同配合,掌控全局。监测代码运行,就如同斥候巡逻,隐患刚一露头,就能立刻察觉;调试纠错,便是整饬军纪,做到令行禁止,让算法回归正轨。
战例七:使用Python的logging模块记录代码的运行状态。
这段代码中的some_algorithm函数,其时间复杂度值得探究。首先,logging.info("Algorithm started")这个操作是将信息记录到日志中,花费的时间非常短,不涉及复杂的运算,时间复杂度为O(1)。
至于其中的“主算法逻辑”,由于没有详细展示,所以很难确定它的时间复杂度,有可能是O(1),比如只进行简单的操作,像是赋值、比较等;也可能是O(n),要是存在遍历相关的操作;还可能是O(n²),倘若包含嵌套循环;其他复杂度也有可能,都取决于具体的算法。
最后,logging.info("Algorithm finished")这个操作和前面一样,时间复杂度为O(1)。 该函数的整体时间复杂度由“主算法逻辑”主导,然而因为这部分不明确,所以很难确切知晓,只知道前后记录信息的操作都是常数复杂度,如果“主算法逻辑”的复杂度是C,那么这个函数整体的时间复杂度就是O(C),而C会因具体算法而异。
import logginglogging.basicConfig(level = logging.INFO) def some_algorithm():logging.info("Algorithm started")# 主算法逻辑logging.info("Algorithm finished")
依据不同环境调适算法,面对不同硬件平台、使用场景,算法都能精准适配,就像变色龙融入背景一样,无缝对接,稳定又高效运行,这才是行军不败的方法。
地形篇
算法落地实施,必须审视所处地形。商业场景如同山地,高低起伏,竞争激烈的地方就是陡峭高峰,细分赛道则是隐蔽山谷,选准山谷深耕细作,避开高峰的锋芒;科研领域好似旷野,广阔无垠,适合大开脑洞,铺展算法宏伟蓝图,探索未知边界。
战例八:假定要依据不同场景来选择推荐算法:
这个select_recommendation_algorithm函数,把scenario当作参数。进入函数体后,首先进行条件判断。
要是scenario的值是“ecommerce”,就会立刻返回“Collaborative Filtering Algorithm”,这种判断与返回操作瞬间就能完成,时间复杂度是O(1)。
要是scenario的值是“research_paper”,同样会迅速返回“Content-based Recommendation Algorithm”,它的时间复杂度也是O(1)。
要是以上情况都不匹配,就返回“Default Algorithm”,这个操作也能快速完成,复杂度为O(1)。 这个函数仅仅做条件判断,不管输入什么值,耗费的时间都是固定的,所以整个函数的时间复杂度是O(1)。
def select_recommendation_algorithm(scenario):if scenario == "ecommerce":return "Collaborative Filtering Algorithm"elif scenario == "research_paper":return "Content-based Recommendation Algorithm"return "Default Algorithm"
要知晓难易程度,清楚危险与平易之处,复杂的数据结构就是荆棘丛生的沼泽,简易任务则是平坦大道。因地制宜部署算法,在沼泽地里就用轻量敏捷的方法,在大道上就施展磅礴宏伟之术,算法自然能畅行无阻,建立功勋。
九地篇
生地、死地、绝地…… 在算法的征程里,会涉足各类不同 “九地”。刚进入新兴领域,这是生地,要大胆开拓,抢占先机;深陷竞品的围剿,就是进入死地,需背水一战,激发自身潜能;面临技术瓶颈,便处于绝地,要破釜沉舟,创新突围。
战例九:在遇到技术瓶颈的时候,应当尝试引入新的技术框架。下面所讲的,就是一个导入新框架的简单示例。
这段代码的时间复杂度值得探究一番。一开始,在try语句块里的import new_tech_framework,这一导入模块的操作,它所耗费的时间取决于框架的加载方式。要是框架已经妥善安装,并且没有复杂的初始化流程,加载过程近乎瞬间就能完成,时间复杂度为O(1);要是需要大量调配资源、读取多个文件,那复杂度或许会上升,暂时用O(t)来表示,这里的t与框架的复杂程度、体量大小相关。
后续使用新框架的逻辑,由于没有详细说明,假设其复杂度为O(u),这取决于具体的算法。 到了except部分,print语句仅仅输出一条信息,操作很简单,能够在固定时间内完成,时间复杂度是O(1) 。
综合来看,如果导入成功,复杂度主要受新框架使用逻辑的影响,大约是O(u);要是导入失败,那也不过就是执行print语句的O(1)。因为导入是否成功并不明确,不过导入操作通常能快速完成,所以整体复杂度通常接近O(1),只有在导入流程极为繁杂的时候,才依据实际耗费的时间来确定。
try:import new_tech_framework# 使用新框架的代码逻辑 except ImportError:print("Failed to import new framework, fallback plan activated")
算法团队协同配合,攻坚时能齐心协力汇聚一处,分散时又能各自探索。深入用户场景这块 “重地”,珍视用户反馈,依据这些重塑算法灵魂,不管处于何种境地,都能绝地逢生,所向披靡。
火攻篇
火攻,就是借助外力助力算法发起凌厉攻势。舆论热点好似烈火,算法贴合热点进行优化,趁着热度飙升,收获滚滚流量;跨界合作仿若借风,引入外部算法模块、数据资源,燃起创新大火,烧穿行业隔阂,拓展业务版图。
战例十:借助社交媒体的API来抓取热点话题数据,以此辅助算法的优化。
现有一段程序,引入了tweepy库,其目的在于借助社交媒体推特(Twitter)的API,获取热点话题数据,助力算法优化相关事宜。
首先要配置Twitter API,于是设定多个参数:consumer_key、consumer_secret、access_token以及access_token_secret,分别赋予专属的字符值,这些参数是连通推特API的关键密钥。
接着,使用OAuthHandler构建认证对象auth,把consumer_key与consumer_secret传入其中,以此奠定认证的基础;再运用`set_access_token`方法,补充完整权限信息,让认证更加周全。
最后得到API对象api,通过调用api.trends_place(1),向推特API请求热门话题数据。这是因为trends_place函数能够依据传入的地域代码(此处代码为1,通常代表特定的默认地区),抓取该地区当下的热门趋势。获取到的数据,后续可以应用到算法当中,依据数据特性,既能够为训练集补充素材,也能作为策略调整的依据,促使算法贴合舆情热点,达到更优的性能表现。
import tweepy# 配置Twitter API consumer_key = "your_key" consumer_secret = "your_secret" access_token = "your_token" access_token_secret = "your_secret_token"auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth)trends = api.trends_place(1) # 获取热门话题
然而火不能随意放,一旦失控反噬,必然酿成大祸。要把控好伦理边界,不涉及隐私侵权问题;防范数据滥用,避免算法失控。善于用火攻,能为算法霸业添砖加瓦,谨慎用猛火,才能保住算法的良好声誉,长治久安。
用间篇
在算法的江湖里,谍影重重。安插 “数据间谍”,收集竞品情报,窥探对手的更新迭代、参数奥秘;启用 “用户暗探”,深挖需求痛点,为算法优化找准靶点。逆向工程则是巧妙的反间手段,剖析对手代码,学习对方长处,化为己用。
战例十一:模拟一个简单的网页爬虫,用来获取竞品的公开数据。
首先,引入requests与BeautifulSoup库,它们是获取和解析网页数据的重要工具。 其次,将url设定为竞品网页的地址,称作competitor_url。
接着,使用requests.get(url)发起请求,该操作会向设定好的url发送HTTP请求,获取网页的响应。这一操作花费的时间和网页大小有关,如果把网页大小设为n,那么它的复杂度大约是O(n) 。
获取响应之后,提取response.content,这个操作能够在固定时间内完成,复杂度是O(1)。 再用BeautifulSoup(response.content, 'html.parser')创建BeautifulSoup对象soup,并使用html.parser来解析响应内容。这个解析过程,需要遍历网页内容,拆解其结构,它的复杂度与网页大小以及复杂程度相关,假设网页结构复杂度是m,那么这部分的复杂度大约是O(m)。
最后,可以凭借BeautifulSoup对象的各种方法,解析网页并提取关键信息,其复杂度依据所提取信息的多少以及网页结构来定,是O(k),这里的k与所提取信息的数量以及网页结构相关。
总体而言,这段代码的整体复杂度,受网页大小与结构的制约,因为需要发起请求、解析内容以及提取信息,大致是O(n + m + k),不过在实际情况中,网络状况和服务器响应速度也会对其性能产生影响。
import requests from bs4 import BeautifulSoupurl = "competitor_url" response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 解析网页提取关键信息
不过间谍很难用好,稍有不慎,反而会被对手迷惑。要甄别情报真假,不被虚假数据误导;严守己方机密,防范间谍泄密,让自家算法核心坚如磐石,在无声的暗战中胜出,最终成就算法霸业。
(完)
相关文章:

算法兵法全略(译文)
目录 始计篇 谋攻篇 军形篇 兵势篇 虚实篇 军争篇 九变篇 行军篇 地形篇 九地篇 火攻篇 用间篇 始计篇 算法,在当今时代,犹如国家关键的战略武器,也是处理各类事务的核心枢纽。算法的世界神秘且变化万千,不够贤能聪慧…...

react传递函数与回调函数原理
为什么 React 允许直接传递函数? 回调函数核心逻辑 例子:父组件控制 Modal 的显示与隐藏 // 父组件 (ParentComponent.tsx) import React, { useState } from react; import { Modal, Button } from antd; import ModalContent from ./ModalContent;co…...

多媒体术语扫盲备忘录
DRM DRM: Digital Rights Management, 数字版权保护。 广义上讲,能够保护数字版权(不单单是音视频)都可以叫做DRM。 国外主要分为三大类, Google的Widevine, MicroSoft的 PlayReady, 以及 Apple的 FairPlay. 更多细节请参考此文章. Google Widevine: …...

Node.js 调用 DeepSeek API 完整指南
简介 本文将介绍如何使用 Node.js 调用 DeepSeek API,实现流式对话并保存对话记录。Node.js 版本使用现代异步编程方式实现,支持流式处理和错误处理。 1. 环境准备 1.1 系统要求 Node.js 14.0 或更高版本npm 包管理器 1.2 项目结构 deepseek-proje…...
盛铂科技 SMF106 低相位噪声贴片式频率综合器模块
在现代通信和电子设备领域,频率综合器作为关键组件,其性能优劣直接影响系统的整体表现。盛铂科技的 SMF106 低相位噪声贴片式频率综合器,以其卓越的性能和独特设计,成为众多高性能系统的选择。 一、频率覆盖范围广,步进…...
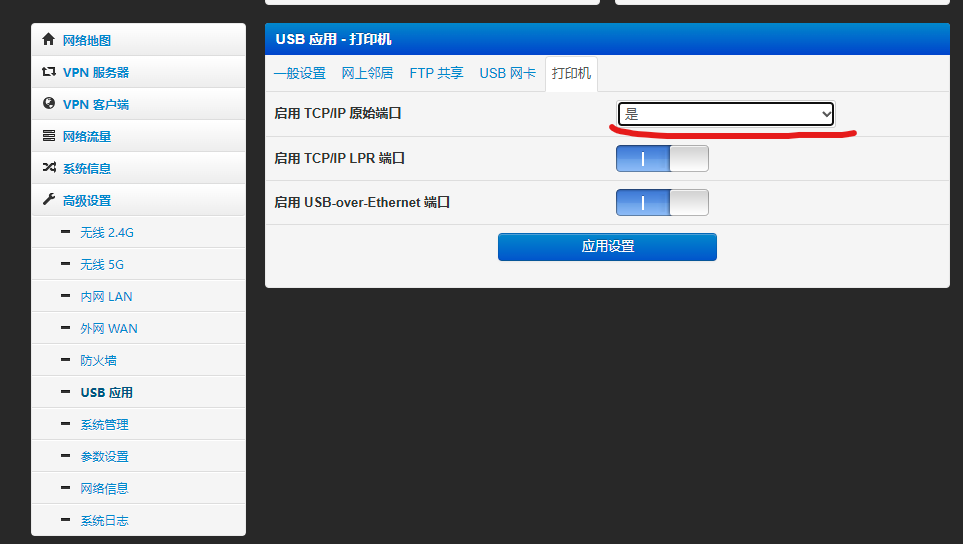
小米 R3G 路由器(Pandavan)实现网络打印机功能
小米 R3G 路由器(Pandavan)实现网络打印机功能 一、前言 家中有多台 PC 设备需要打印服务,但苦于家中的 Epson L380 打印机没有网络打印功能,并且配置 Windows 共享打印机实在是过于繁琐且需要共享机保持唤醒状态过于费电。想到…...

Okay, But Please Don’t Stop Talking
Okay, But Please Don’t Stop Talking 研发背景 现有问题:像ChatGPT的高级语音模式这类先进的语音对语音系统,容易被“我明白”“嗯哼”等在人类对话中常见的插入语打断。这表明现有语音交互系统在处理自然对话中的语音重叠情况时存在不足。 新的尝试&…...

Python的那些事第二十一篇:Python Web开发的“秘密武器”Flask
基于 Flask 框架的 Python Web 开发研究 摘要 在 Web 开发的江湖里,Python 是一位武林高手,而 Flask 则是它手中那把小巧却锋利的匕首。本文以 Flask 框架为核心,深入探讨了它在 Python Web 开发中的应用。通过幽默风趣的笔触,结合实例和表格,分析了 Flask 的特性、优势以…...

欧拉函数杂记
定义 φ ( n ) \varphi (n) φ(n)表示 [ 1 , n ] [1,n] [1,n]中与 n n n互质的数的个数。 性质 φ ( p ) p − 1 , p ∈ P \varphi (p)p-1,\ p\in \mathbb {P} φ(p)p−1, p∈P φ ( n ) n ∏ i 1 m p i − 1 p i \varphi (n)n\prod_{i1}^{m} \frac{p_i-1}{p_i} φ(n)ni1∏…...

基于IOS实现各种倒计时功能
ZJJTimeCountDown 效果图 特点: 1、已封装,支持自定义 2、支持文本各种对齐模式 3、各种效果都可以通过设置 ZJJTimeCountDownLabel 类属性来实现 4、支持背景图片设置 5、分文本显示时间时,支持设置文字大小,来动态设置每个文本…...
命令详解:head)
Linux(Centos 7.6)命令详解:head
1.命令作用 将每个文件的前10行打印到标准输出(Print the first 10 lines of each FILE to standard output) 2.命令语法 Usage: head [OPTION]... [FILE]... 3.参数详解 OPTION: -c, --bytes[-]K,打印每个文件的前K字节-n, --lines[-],打印前K行而…...

微软 Microsoft Windows Office Professional LTSC 2024 专业增强版
Office 链接:https://pan.xunlei.com/s/VOIyE3ALg0hDvQfj47cLf3MdA1?pwdvzuz#...

【愚公系列】《Python网络爬虫从入门到精通》009-使用match()进行匹配
标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度…...

Spring Boot 3 集成Xxl-job 3.0.0 单机
下载Xxl-job项目 https://gitee.com/xuxueli0323/xxl-jobhttps://github.com/xuxueli/xxl-job 创建相关数据库 数据库文件再/xxl-job/doc/db/tables_xxl_job.sql直接在数据库中运行SQL文件即可创建相关数据库 配置调度中心 打开项目找到 xxl-job-admin模块找到/xxl-job/xx…...

DeepSeek自动批量写作的AI软件
DeepSeek作为一款专注于数据处理与分析的AI软件,凭借其强大的功能和精准的分析能力,正在帮助企业实现智能化升级。无论是数据分析、市场预测还是内容创作,DeepSeek都能提供高效的解决方案。 无法使用Deepseek批量创作文案的,可在1…...

NLLB 与 ChatGPT 双向优化:探索翻译模型与语言模型在小语种应用的融合策略
作者:来自 vivo 互联网算法团队- Huang Minghui 本文探讨了 NLLB 翻译模型与 ChatGPT 在小语种应用中的双向优化策略。首先介绍了 NLLB-200 的背景、数据、分词器和模型,以及其与 LLM(Large Language Model)的异同和协同关系。接着…...
k-近邻算法(k-Nearest Neighbors, KNN)cv::ml::KNearest类)
OpenCV机器学习(4)k-近邻算法(k-Nearest Neighbors, KNN)cv::ml::KNearest类
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::ml::KNearest 是 OpenCV 机器学习模块中的一部分,它提供了实现 k-近邻算法(k-Nearest Neighbors, KNN)的…...
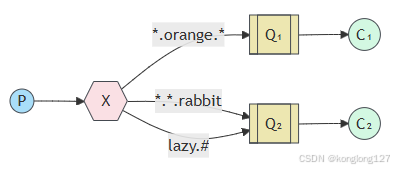
在nodejs中使用RabbitMQ(三)Routing、Topics、Headers
示例一、Routing exchange类型direct,根据消息的routekey将消息直接转发到指定队列。producer.ts 生产者主要发送消息,consumer.ts负责接收消息,同时也都可以创建exchange交换机,创建队列,为队列绑定exchangeÿ…...

浏览器扩展实现网址自动替换
作为一个开发爱好者,不能顺畅访问github是很痛苦的,这种状况不知道何时能彻底解决。 目前也有很多方案可以对应这种囧况,我此前知道有一个网站kkgithub,基本上把github的静态内容都搬了过来,我们如果需要访问某个githu…...

《open3d qt 网格泊松采样成点云》
open3d qt 网格泊松采样成点云 效果展示二、流程三、代码效果展示 效果好一点,速度慢一点。 二、流程 创建动作,链接到槽函数,并把动作放置菜单栏 参照前文 三、代码 1、槽函数实现 void on_actionMeshPossionSample_triggered()//泊松采样 void MainWindow::...

从算法到落地:DeepSeek如何突破AI工具的同质化竞争困局
🎁个人主页:我们的五年 🔍系列专栏:Linux网络编程 🌷追光的人,终会万丈光芒 🎉欢迎大家点赞👍评论📝收藏⭐文章 Linux网络编程笔记: https://blog.cs…...

阿里云一键部署DeepSeek-V3、DeepSeek-R1模型
目录 支持的模型列表 模型部署 模型调用 WebUI使用 在线调试 API调用 关于成本 FAQ 点击部署后服务长时间等待 服务部署成功后,调用API返回404 请求太长导致EAS网关超时 部署完成后,如何在EAS的在线调试页面调试 模型部署之后没有“联网搜索…...

python学opencv|读取图像(六十六)使用cv2.minEnclosingCircle函数实现图像轮廓圆形标注
【1】引言 前序学习过程中,已经掌握了使用cv2.boundingRect()函数实现图像轮廓矩形标注,相关文章链接为:python学opencv|读取图像(六十五)使用cv2.boundingRect()函数实现图像轮廓矩形标注-CSDN博客 这篇文章成功在图…...

嵌入式经常用到串口,如何判断串口数据接收完成?
说起通信,首先想到的肯定是串口,日常中232和485的使用比比皆是,数据的发送、接收是串口通信最基础的内容。这篇文章主要讨论串口接收数据的断帧操作。 空闲中断断帧 一些mcu(如:stm32f103)在出厂时就已经在…...

面试真题 | B站C++渲染引擎
一、基础与语法 自我介绍 请简要介绍自己的背景、专业技能和工作经验。实习介绍 详细描述你在实习期间参与的项目、职责和成果。二、智能指针相关问题回答 unique_ptr 是如何实现的?它有哪些特点和优势? unique_ptr 是C++11引入的一种智能指针,用于管理动态分配的内存资源…...

系统不是基于UEFI的win11,硬盘格式MBR,我如何更改为GPT模式添加UEFI启动?
我的系统不是基于UEFI的win11,硬盘格式MBR,我如何更改为GPT模式添加UEFI启动? 相当于你的Windows 11系统从MBR转换为GPT,并添加UEFI启动支持,你需要执行以下步骤: 备份数据 首先,强烈建议你备份…...

Vue2/Vue3分别如何使用computed
computed 是 Vue 中用于定义计算属性的功能,它会根据依赖的数据动态计算并缓存结果。Vue 2 和 Vue 3 中的 computed 使用方式有所不同,以下是详细说明: Vue2中的computed 在 Vue 2 中,computed 是通过选项式 API 实现的ÿ…...

操作系统知识速记:实现线程同步的方式
操作系统知识速记:实现线程同步的方式 在当今的多核和多线程世界里,线程同步是确保数据一致性和提高系统性能的关键。 互斥锁(Mutex) 互斥锁是实现线程安全的基础。它通过确保同一时间只有一个线程能访问共享资源来防止数据竞争。…...

用vue3写一个好看的wiki前端页面
以下是一个使用 Vue 3 Element Plus 实现的 Wiki 风格前端页面示例,包含现代设计、响应式布局和常用功能: <template><div class"wiki-container"><!-- 头部导航 --><el-header class"wiki-header"><d…...

从图像中提取的每行数字作为一张完整的图片,而不是每个数字单独成为一张图片
具体实现思路: 提取行区域:先通过轮廓或空白区域分割出每行数字。确保每行是一个整体:在提取每行时,确保提取区域的宽度包含该行所有的数字(即避免单独分割每个数字)。保存每一行作为一张图片:…...