53倍性能提升!TiDB 全局索引如何优化分区表查询?
作者: Defined2014 原文来源: https://tidb.net/blog/7077577f
什么是 TiDB 全局索引
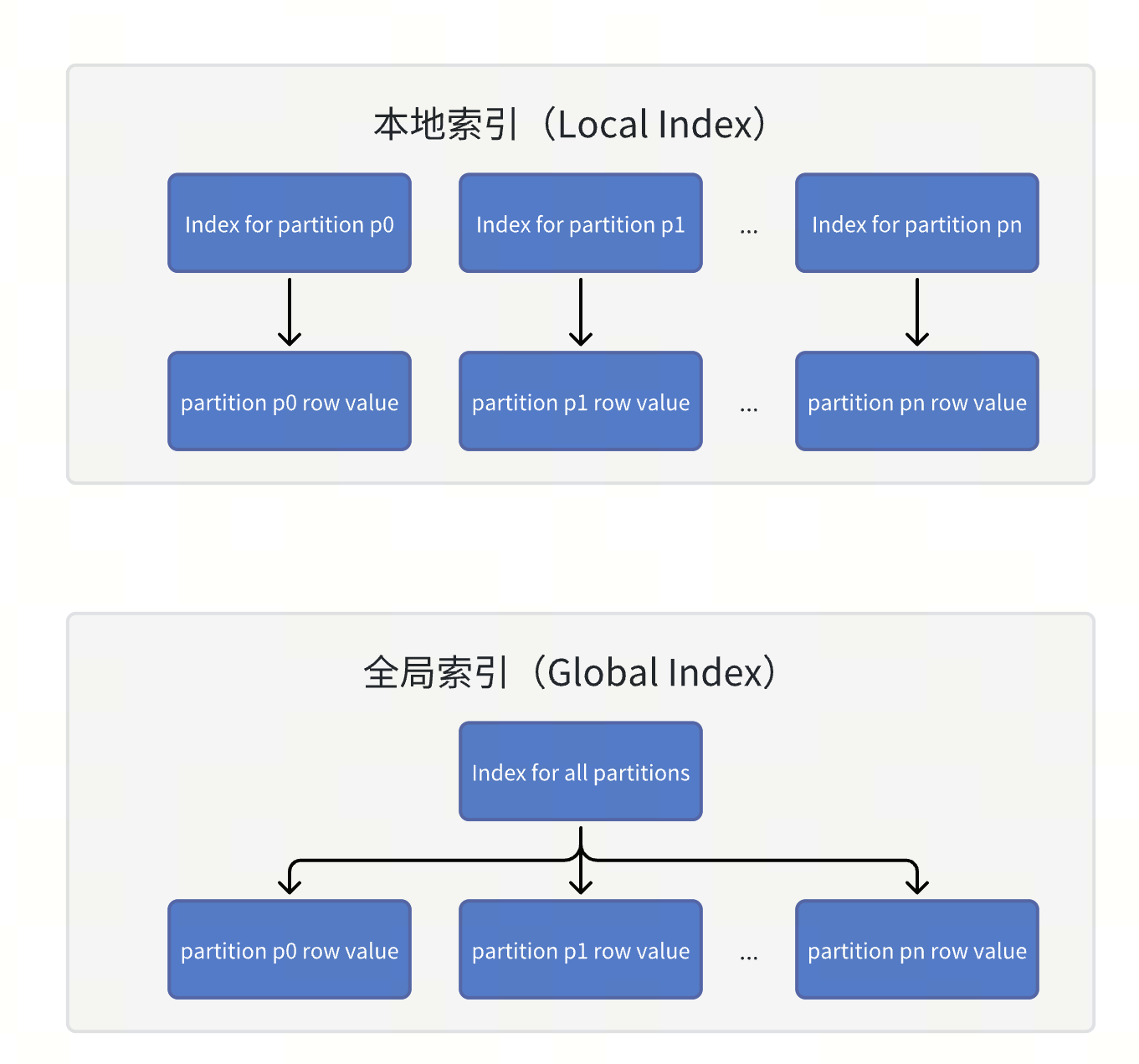
在 TiDB 中,全局索引是一种定义在分区表上的索引类型,它允许索引分区与表分区之间建立一对多的映射关系,即一个索引分区可以对应多个表分区。这与 TiDB 早期版本中的本地索引(Local Index)不同,本地索引的索引分区与表分区之间是一对一的映射关系,即一个分区对应一个局部的索引块。
全局索引能覆盖整个表的数据,使得主键和唯一键在不包含分区键的情况下仍能保持全局唯一性。此外,全局索引可以在一次操作中访问多个分区的索引数据,而无需对每个分区的本地索引逐一查找,显著提升了针对非分区键的查询性能。
下图简单展示了本地索引和全局索引的区别
TiDB 全局索引的发展历程
- v7.6.0 版本之前 :TiDB 仅支持分区表的本地索引。这意味着,对于分区表上的唯一键,必须包含表分区表达式中的所有列。如果查询条件中没有使用分区键,那么查询将不得不扫描所有分区,这会导致查询性能下降。
- v7.6.0 版本 :引入了系统变量
tidb_enable_global_index,用于开启全局索引功能。然而,当时该功能仍在开发中,不推荐用户启用。 - v8.3.0 版本 :全局索引功能作为实验性特性发布。用户可以通过在创建索引时显式使用
GLOBAL关键字来创建全局索引。 - v8.4.0 版本 :全局索引功能正式成为一般可用(GA)特性。用户可以直接使用
GLOBAL关键字创建全局索引,而无需再设置系统变量tidb_enable_global_index。从这个版本开始,该系统变量被弃用,并且始终为ON。 - v8.5.0 版本 :全局索引功能支持了包含分区表达式中的所有列。
- v9.0.0 版本 :全局索引功能支持了非唯一索引的情况。在分区表中,除聚簇索引外都可以被创建为全局索引。
TiDB 全局索引的语法
在 TiDB 中,创建全局索引(Global Index)时,可以在 CREATE INDEX 或 ALTER TABLE 语句中使用 GLOBAL 关键字,或在建表时通过 GLOBAL 关键字或 /*T![global_index] GLOBAL */ 注释指定。
创建全局索引的语法:
CREATE [UNIQUE] INDEX index_name ON table_name (column_list) [GLOBAL];
ALTER TABLE table_name ADD [UNIQUE] INDEX index_name (column_list) [GLOBAL];
示例:
- 创建全局唯一索引:
CREATE UNIQUE INDEX idx_global ON employees (email) GLOBAL;
此语句在 employees 表的 email 列上创建一个全局唯一索引,确保每个电子邮件地址在整个表中唯一。
- 添加全局索引:
ALTER TABLE orders ADD INDEX idx_global_order_date (order_date) GLOBAL;
此语句向 orders 表添加一个名为 idx_global_order_date 的全局索引,索引列为 order_date 。
- 在建表时创建全局索引:
CREATE TABLE `sbtest` (`id` int NOT NULL,`k` int NOT NULL DEFAULT '0',`c` char NOT NULL DEFAULT '',KEY `idx1` (`k`) GLOBAL,KEY `idx2` (`k`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY HASH (`id`) PARTITIONS 5;
此语句在创建 sbtest 表时同时创建了两个名为 idx1 和 idx2 的全局索引,两个索引的索引列都为 k 。
TiDB 全局索引的优势
提升查询性能
全局索引能够有效提高检索非分区列的效率。当查询涉及非分区列时,全局索引可以快速定位相关数据,避免了对所有分区的全表扫描,可以显著降低 cop task 的数量,这对于分区数量庞大的场景尤为有效。
经过测试,在分区数量为 100 的情况下,sysbench select_random_points 场景得到了 53 倍 的性能提升。
增强应用灵活性
全局索引的引入,消除了分区表上唯一键必须包含所有分区列的限制。这使得用户在设计索引时更加灵活,可以根据实际的查询需求和业务逻辑来创建索引,而不再受限于表的分区方案。这种灵活性有助于更好地优化查询性能,满足多样化的业务需求。
减少应用修改工作量
在数据迁移和应用修改过程中,全局索引可以减少对应用的修改工作量。如果没有全局索引,在迁移数据或修改应用时,可能需要调整分区方案或重写查询语句以适应索引的限制。有了全局索引之后,这些修改可以被避免,从而降低了开发和维护成本。
如在将 Oracle 数据库中的某张表迁移到 TiDB 时,因为 Oracle 支持全局索引,可能在某些表上存在一些不包含分区列的唯一索引,在迁移过程需要对表结构进行调整,以适应 TiDB 的分区表限制。然而,随着 TiDB 对全局索引的支持,用户只需简单地修改索引定义,将其设置为全局索引,即可与 Oracle 保持一致,从而显著降低迁移成本。
TiDB 全局索引的工作原理
基本思想
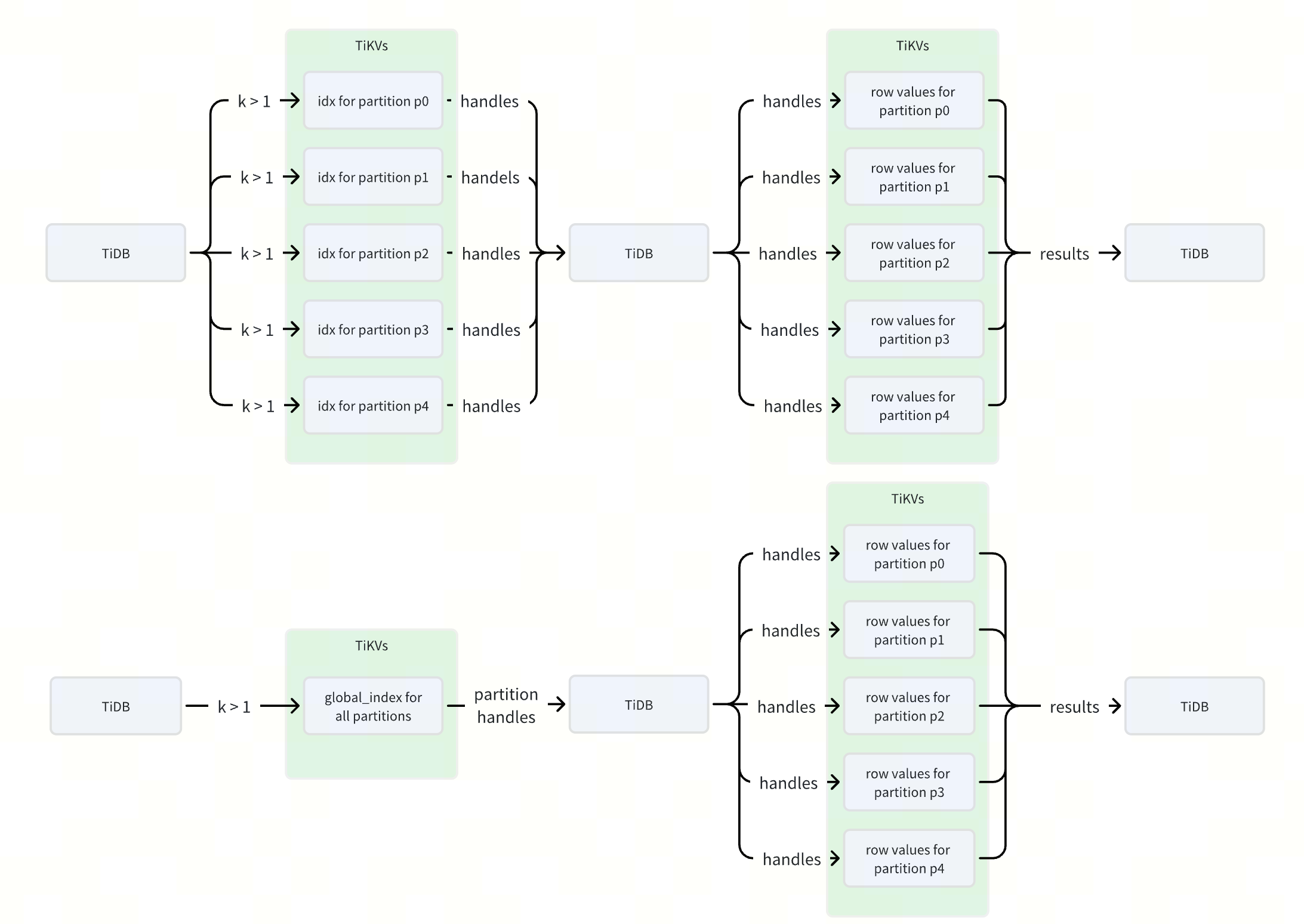
在 TiDB 的分区表中,本地索引的键值前缀是分区表的 ID 而全局索引的前缀是表的 ID。这样的改动确保了全局索引的数据在 TiKV 上分布是连续的,降低了查询索引时 RPC 的数量。
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',KEY idx(k),KEY global_idx(k) GLOBAL
) partition by hash(id) partitions 5;
以上面的表结构为例, idx 为普通索引, global_idx 为全局索引。索引 idx 的数据会分布在 5 个不同的 ranges 中,如 PartitionID1_i_xxx , PartitionID2_i_xxx 等,而索引 global_idx 的数据则会集中在一个 range ( TableID_i_xxx ) 内。
这样当我们进行 k 相关的查询时,如 select * from sbtest where k > 1 ,通过索引 idx 会构造 5 个不同的 ranges,而通过全局索引 global_idx 则只会构造 1 个 range,每个 range 在 TiDB 中对应一个或多个 RPC 请求,这样使用全局索引可以降低数倍的 RPC 请求数,从而提升查询索引的性能。
下图更加直观地展示了在使用 idx 和 global_idx 两个不同索引执行 select * from sbtest where k > 1 查询语句在 RPC 请求和数据流转过程中的差异。
编码方式
在 TiDB 中,索引项被编码为键值对。对于分区表,每个分区在 TiKV 层被视为一个独立的物理表,拥有自己的 partitionID 。因此,分区表的索引项也被编码为:
唯一键
Key:
- PartitionID_indexID_ColumnValuesValue:
- IntHandle- TailLen_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle非唯一键
Key:
- PartitionID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_Padding- CommonHandle- TailLen_IndexVersion
在全局索引中,索引项的编码方式有所不同。为了使全局索引的键布局与当前索引键编码保持兼容,新的索引编码布局为:
唯一键
Key:
- TableID_indexID_ColumnValuesValue:
- IntHandle- TailLen_PartitionID_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle_PartitionID非唯一键
Key:
- TableID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_PartitionID- CommonHandle- TailLen_IndexVersion_PartitionID
这种编码方式使得全局索引的键以 TableID 开头,而 PartitionID 被放置在 Value 中。这样设计的优点是,它与现有的索引键编码方式兼容,但同时也带来了一些挑战,例如在执行 DROP PARTITION, TRUNCATE PARTITION 等 DDL 操作时,由于索引项不连续,需要进行额外的处理。
TiDB 全局索引的限制与注意事项
影响部分 DDL 性能
当分区表中存在全局索引时,执行诸如 DROP PARTITION(删除分区)、TRUNCATE PARTITION(清空分区)、REORG PARTITION(重组分区)等部分 DDL 操作时,需要同步更新全局索引的值,这会显著增加 DDL 操作的执行时间。
在 v8.5.0 默认参数下,测试显示对包含全局索引的 sysbench 表执行 DROP PARTITION 或 TRUNCATE PARTITION 操作时, oltp_read_write 负载的性能会下降 15% 至 20%。
聚簇索引 (Clustered Index)
聚簇索引不能成为全局索引,是因为如果聚簇索引是全局索引,则表将不再分区。这是因为聚簇索引的键是分区级别的行数据的键,但全局索引是表级别的,这就造成了冲突。如果需要将主键设置为全局索引,则需要显式设置该主键为非聚簇索引,如 PRIMARY KEY(col1, col2) NONCLUSTERED GLOBAL 。
性能测试数据
-
select_random_pointsin sysbench
示例表结构
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',`pad` char(60) NOT NULL DEFAULT '',PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,KEY `k_1` (`k`)/* Key `k_1` (`k`, `c`) GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
/* Partition by hash(`id`) partitions 100 */
/* Partition by range(`id`) xxxx */
负载 SQL
SELECT id, k, c, pad
FROM sbtest1
WHERE k IN (xx, xx, xx)
| Range Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 225 | 19,999 | 30,293 | 7.92 |
| Clustered table range partitioned by PK | 68 | 480 | 511 | 114.87 |
Clustered table range partitioned by PK, with Global Index on k, c columns | 207 | 17,798 | 27,707 | 11.73 |
| Hash Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 166 | 20361 | 28922 | 7.86 |
| Clustered table hash partitioned by PK | 60 | 244 | 283 | 119.73 |
Clustered table hash partitioned by PK, with Global Index on k, c columns | 156 | 18233 | 15581 | 10.77 |
- 通过上述测试可以看出,在高并发环境下,全局索引能够显著提升分区表查询性能,提升幅度可达 50 倍。同时,全局索引还能够显著降低资源(RU)消耗。随着分区数量的增加,这种性能提升的效果将愈加明显。
最佳实践
全局索引和本地索引
全局索引适用场景 :
- 数据归档不频繁 :例如,医疗行业的部分业务数据需要保存 30 年,通常按月分区,然后一次性创建 360 个分区,且很少进行
DROP或TRUNCATE操作。在这种情况下,使用全局索引更为合适,因为它能提供跨分区的一致性和查询性能。 - 查询需要跨分区的数据 :当查询需要访问多个分区的数据时,全局索引可以避免跨分区扫描,提高查询效率。
本地索引适用场景 :
- 数据归档需求 :如果数据归档操作很频繁,且主要查询集中在单个分区内,本地索引可以提供更好的性能。
- 需要使用分区交换功能 :在银行等行业,可能会将处理后的数据先写入普通表,确认无误后再交换到分区表,以减少对分区表性能的影响。此时,本地索引更为适用,因为在使用了全局索引之后,分区表将不再支持分区交换功能。
全局索引和聚簇索引
由于聚簇索引和全局索引的原理限制,一个索引不能同时作为聚簇索引和全局索引。然而,这两种索引在不同查询场景中能提供不同的性能优化。在遇到需要同时兼顾两者的需求时,我们可以将分区列添加到聚簇索引中,同时创建一个不包含分区列的全局索引。
假设我们有如下表结构:
CREATE TABLE `t` (`id` int DEFAULT NULL,`ts` timestamp NULL DEFAULT NULL,`data` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800)PARTITION `p1` VALUES LESS THAN (1738339200)...)
在上面的 t 表中, id 列的值是唯一的。为了优化点查和范围查询的性能,我们可以选择在建表语句中定义一个聚簇索引 PRIMARY KEY(id, ts) 和一个不包含分区列的全局索引 UNIQUE KEY id(id) 。这样在进行基于 id 的点查询时,会走全局索引 id ,选择 PointGet 的执行计划;而在进行范围查询时,聚簇索引则会被选中,因为聚簇索引相比全局索引少了一次回表操作,从而提升查询效率。
修改后的表结构如下所示:
CREATE TABLE `t` (`id` int NOT NULL,`ts` timestamp NOT NULL,`data` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`, `ts`) /*T![clustered_index] CLUSTERED */,UNIQUE KEY `id` (`id`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800),PARTITION `p1` VALUES LESS THAN (1738339200)...)
通过这种方式,我们既能优化基于 id 的点查询,又能提升范围查询的性能,同时确保表的分区列在基于时间戳的查询中能得到有效的利用。
总结
TiDB 全局索引是 TiDB 在分区表索引方面的重要特性,它通过允许索引分区与表分区之间提供一对多的映射关系,提供了更灵活的索引设计和更高效的查询性能。全局索引的引入,不仅提升了 TiDB 分区表在处理复杂查询和大数据量场景下的能力,还为用户在数据库设计和优化方面提供了更多的选择。
然而,全局索引也带来了一些挑战,如维护成本的增加。在使用全局索引时,需要根据具体的业务需求和数据特点,合理设计索引,权衡查询性能和数据修改性能,以达到最佳的数据库性能。
总之,TiDB 全局索引是一个强大且灵活的特性,能够帮助用户更好地优化数据库性能,满足多样化的业务需求。在实际应用中,合理使用全局索引,可以显著提升查询性能,提高数据库的整体效率。
相关文章:
53倍性能提升!TiDB 全局索引如何优化分区表查询?
作者: Defined2014 原文来源: https://tidb.net/blog/7077577f 什么是 TiDB 全局索引 在 TiDB 中,全局索引是一种定义在分区表上的索引类型,它允许索引分区与表分区之间建立一对多的映射关系,即一个索引分区可以对…...

vue字符串的常用方法,截取字符串,获取字符串长度,检索字符串
1.使用substr方法截取字符串 let str "12345"; let part str.substr(0, 3); // 截取从索引0开始到索引3的子字符串 console.log(part); // "123" 2.获取字符串长度 JavaScript中的字符串有一个 length属性,该属性可以用在VUE获取字符串的长度…...

Neo4j集群学习
文章目录 官方指导文档Neo4j因果集群核心服务器只读副本因果一致性 Neo4j集群搭建Neo4j企业版下载集群简介虚拟机准备jdk安装实施搭建访问neo4j Web服务 集群添加Core节点 官方指导文档 Neo4j 5 ClusterNeo4j 5 Basic Cluster Neo4j因果集群 集群是Neo4企业版中所提供的功能…...

【人工智能】深度学习中的梯度检查:原理详解与Python实现
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 梯度检查是深度学习模型开发中至关重要的一步,它能够验证反向传播的梯度计算是否正确,从而确保模型训练的稳定性和准确性。在本文中,我们…...
接口)
Kotlin 2.1.0 入门教程(十七)接口
接口 接口可以包含抽象方法的声明,也可以包含方法的实现。 接口与抽象类的不同之处在于,接口无法存储状态。接口可以拥有属性,但这些属性要么必须是抽象的,要么就得提供访问器的实现。 接口使用 interface 关键字来定义&#x…...
)
了解i2c_check_functionality()
i2c_check_functionality()用来检查设备适配器支持的标志是否要求。 打开“include/linux/i2c.h” /* Return the functionality mask */ static inline u32 i2c_get_functionality(struct i2c_adapter *adap) { return adap->algo->functionality(adap); //返回该…...

Retrieval-Augmented Generation for LargeLanguage Models: A Survey
标题:Retrieval-Augmented Generation for Large Language Models: A Survey 作者:Yunfan Gaoa , Yun Xiongb , Xinyu Gaob , Kangxiang Jiab , Jinliu Panb , Yuxi Bic , Yi Daia , Jiawei Suna , Meng Wangc , and Haofen Wang 1. By referencing ext…...

C#多线程异步连接MySQL与SQLserver数据库
C#多线程异步连接MySQL与SQLserver数据库 一、前言二、多线程异步连接数据库代码2.1代码块2.2代码说明 参考文档 一、前言 当编写代码连接多台设备上的数据库时,如果采用同步逐个连接的方式,在网络畅通的情况下连接速度尚可,但当其中一台设备…...

try learning-git-branching
文章目录 mergerebase分离 HEAD相对引用利用父节点branch -f 撤销变更cherry-pick交互式 rebase只取一个提交记录提交的技巧rebase 在上一次提交上amendcherry-pick 在上一次提交上 amend tag多分支 rebase两个parent节点纠缠不清的分支偏离的提交历史锁定的Main learning git …...

代码随想录算法【Day46】
Day46 647. 回文子串 class Solution { public:int countSubstrings(string s) {vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));int result 0;for (int i s.size() - 1; i > 0; i--) { // 注意遍历顺序for (int j i; j < s…...

flutter本地推送 flutter_local_notifications的使用记录
flutter_local_notifications 效果 安卓配置(AndroidManifest.xml) <uses-permission android:name"com.android.alarm.permission.SET_ALARM"/> <uses-permission android:name"android.permission.SCHEDULE_EXACT_ALARM" /> <us…...
Springboot 中如何使用Sentinel
在 Spring Boot 中使用 Sentinel 非常方便,Spring Cloud Alibaba 提供了 spring-cloud-starter-alibaba-sentinel 组件,可以快速将 Sentinel 集成到你的 Spring Boot 应用中,并利用其强大的流量控制和容错能力。 下面是一个详细的步骤指南 …...

AI Agent 有哪些痛点问题
AI Agent 有哪些痛点问题 目录 AI Agent 有哪些痛点问题身份安全问题数据安全问题模型安全问题可靠性问题伦理和合规问题身份安全问题 身份界定模糊:AI代理既非完全意义上的人类,也不同于传统的机器,现有的身份管理工具难以准确对其进行定位和管理,导致在权限分配、责任追溯…...

一个让Stable Diffusion更稳定、更易用的Github开源项目
2023除了ChatGPT大火,Stable Diffusion同样也是非常火热,Stable Diffusion是一个Github开源项目,很多爱好者都会本地安装,但面对一些初学者来说,在安装、配置和使用过程中还是会经常出现很多问题,特别不了解…...

Docker+Jenkins自动化部署SpringBoot项目【详解git,jdk,maven,ssh配置等各种配置,附有示例+代码】
文章目录 DockerJenkins部署SpringBoot项目一.准备工作1.1安装jdk111.2安装Maven 二.Docker安装Jenkins2.1安装Docker2.2 安装Jenkins2.3进入jenkins 三.Jenkins设置3.1安装jenkins插件3.2全局工具配置全局配置jdk全局配置maven全局配置git 3.3 系统配置安装 Publish Over SSH …...

.NET SixLabors.ImageSharp v1.0 图像实用程序控制台示例
使用 C# 控制台应用程序示例在 Windows、Linux 和 MacOS 机器上处理图像,包括创建散点图和直方图,以及根据需要旋转图像以便正确显示。 这个小型实用程序库需要将 NuGet SixLabors.ImageSharp包(版本 1.0.4)添加到.NET Core 3.1/ …...

【机器学习】线性回归与一元线性回归
线性回归与一元线性回归 V1.1线性回归问题线性方程的最优解一元线性回归一元线性回归的方程一元线性回归距离衡量方法一元线性回归的最优化求解一元线性回归的最小二乘法解法 V1.1 线性回归问题 线性回归问题就是找一条线或超平面,并使用线或超平面来描述数据分布…...

soular基础教程-使用指南
soular是TikLab DevOps工具链的统一帐号中心,今天来介绍如何使用 soular 配置你的组织、工作台,快速入门上手。  1. 账号管理 可以对账号信息进行多方面管理,包括分配不同的部门、用户组等,从而确保账号权限和职责…...

《Spring实战》(第6版)第1章 Spring起步
第1部分 Spring基础 第1章 Spring起步 1.1 什么是Spring Spring的核心是提供一个容器(container)。 称为Spring应用上下文(Spring application context)。 创建和管理应用的组件(bean),与上下文装配在一起。 Bean装配通过依赖注入(Dependency Injection,DI)。…...

PAT乙级真题 — 1084 外观数列(java)
外观数列是指具有以下特点的整数序列: d, d1, d111, d113, d11231, d112213111, ...它从不等于 1 的数字 d 开始,序列的第 n1 项是对第 n 项的描述。比如第 2 项表示第 1 项有 1 个 d,所以就是 d1;第 2 项是 1 个 d(对…...

I.MX6ull 看门狗
一、看门狗介绍 WatchDog是为了能够防止程序跑飞而使用的一种硬件模块。如果你的程序没有跑飞,那么你的程序会 定时的去喂看门狗;如果你的程序跑飞了,那么就不会再去喂狗了,如果超过了喂狗的时间,那么狗就会 自己生成一个信号来重…...

鲸鱼算法优化Transformer+KAN网络并应用于时序预测任务
😊😊😊欢迎来到本博客😊😊😊 本次博客内容将聚焦于深度学习的相关知识与实践 🎉作者简介:⭐️⭐️⭐️主要研究方向涵盖深度学习、计算机视觉等方向。 📝目前更新&#x…...

一维差分算法篇:高效处理区间加减
那么在正式介绍我们的一维差分的原理前,我们先来看一下一维差分所应用的一个场景,那么假设我们现在有一个区间为[L,R]的一个数组,那么我要在这个数组中的某个子区间比如[i,m] (L<i<m<R)进行一个加k值或者减去k值的一个操作ÿ…...

export关键字
注意点: 使用 export 和 import 时,确保你的JavaScript环境支持ES6模块 在JavaScript中,export 关键字主要用于模块化编程,允许你将代码的不同部分导出,使得其他模块可以通过 import 关键字来引入这些部分。这是ES6&a…...

【C++】基础入门(详解)
🌟 Hello,我是egoist2023! 🌍 种一棵树最好是十年前,其次是现在! 目录 输入&输出 缺省参数(默认参数) 函数重载 引用 概念及定义 特性及使用 const引用 与指针的关系 内联inline和nullptr in…...

【快速入门】Unity 常用组件(功能块)
欢迎关注 、订阅专栏 【unity 新手教程】谢谢你的支持!💜💜 文章目录 Unity 常用组件(功能块):Transform - 变换:坐标、朝向、大小Mesh Filter - 加载网格数据Mesh Renderer- 渲染网格Camera - …...

Nessus 工具使用全攻略
目录 一、Nessus:网络安全的坚固防线 二、Nessus 安装指南 (一)获取安装包 (二)安装流程 三、初次配置:开启 Nessus 的第一步 (一)账号注册 (二)激活 …...

1441. 用栈操作构建数组 中等
1441. 用栈操作构建数组 给你一个数组 target 和一个整数 n。每次迭代,需要从 list { 1 , 2 , 3 ..., n } 中依次读取一个数字。 请使用下述操作来构建目标数组 target : "Push":从 list 中读取一个新元素, 并将其推入…...

【Springboot知识】从零开始配置springfox
文章目录 配置过程1. 添加依赖2. 创建Swagger配置类3. 配置Swagger UI4. 自定义Swagger配置(可选)4.1 添加全局请求参数4.2 配置响应消息 5. 运行项目并访问Swagger UI6. 其他注意事项7. 使用Springfox 3.x(可选)总结 忽略登录验证…...

PHP代驾系统小程序
🚗 代驾系统 —— 安全、便捷、智能的出行新选择 🔧 一款基于先进ThinkPHPUniapp技术架构,匠心独运的代驾软件横空出世,微信小程序端率先登场,为您的出行之旅增添前所未有的便捷与安全。它不仅是您贴心的出行助手&…...