NLP 八股 DAY1:BERT
BERT全称:Pre-training of deep bidirectional transformers for language understanding,即深度双向Transformer。

模型训练时的两个任务是预测句⼦中被掩盖的词以及判断输⼊的两个句⼦是不是上下句。在预训练 好的BERT模型后⾯根据特定任务加上相应的⽹络,可以完成NLP的下游任务,⽐如⽂本分类、机器 翻译等。Masked LM和Next Sentence Prediction。
只使⽤了transformer的encoder部分,它的整体框架是由多层transformer的encoder堆叠⽽成的。 每⼀层的encoder则是由⼀层muti-head-attention和⼀层feed-forword组成,⼤的模型有24层, 每层16个attention heads,⼩的模型12层,每层12个attention heads。feed-forward的维度是4 * d_model也就是4 * 768 = 3072。
在BERT中,输⼊的向量是由三种不同的embedding求和⽽成,分别是: a. wordpiece embedding:词嵌⼊,WordPiece是指将单词划分成⼀组有限的公共⼦词单元,能在单词的有效性和字符的灵活性之间取得⼀个折中的平衡; b. position embedding:不是三⻆函数⽽是⼀个跟着训练学出来的向量,也就是nn.Embedding; c. segment embedding:⽤于区分两个句⼦的向量表示。这个在问答等⾮对称句⼦中是⽤区别的。
BERT常⻅⾯试问题:bert的具体⽹络结构,以及训练过程,bert为什么⽕,它在什么的基础上改进 了些什么?
答:bert是⽤了transformer的encoder侧的⽹络,作为⼀个⽂本编码器,使⽤⼤规模数据进⾏预训练,预训练使⽤两个loss,⼀个是mask LM,遮蔽掉源端的⼀些字,然后根据上下⽂去预测这些字;⼀个是next sentence,判断两个句⼦是否在⽂章中互为上下句,然后使⽤了⼤规模的语料去预训练。在它之前是GPT,GPT是⼀个单向语⾔模型的预训练过程(它和gpt的区别就是bert为啥叫双向bi-directional),更适⽤于⽂本⽣成。
mask的具体做法:Masked LM 即掩码语⾔模型,它和⼀般的语⾔模型如N元语⾔模型不同。 a. N元语⾔模型第 i 个字的概率和它前 i-1 个字有关,也就是要预测第 i 个字,那么模型就得先从头到尾依次预测出第1个到第 i-1 个字,再来预测第 i 个字;这样的模型⼀般称为⾃回归模型 (Autoregressive LM)。 b. ⽽Masked LM 通过随机将句⼦中的某些字MASK掉,然后通过该MASK掉的字的上下⽂来预测 该字,我们称这样的语⾔模型为⾃编码语⾔模型(Autoencoder LM)。Bert 的 MASK 机制是 这样的:它以token为单位随机选择句⼦中 15%的 token,然后将其中 80% 的 token 使⽤ [MASK] 符号进⾏替换,将 10% 使⽤随机的其他 token 进⾏替换,剩下的10%保持不变。
更细节的阐述:在⼀个句⼦中,随机选中⼀定百分⽐(实际是15%)的token,将这些token⽤" [MASK]"替换。然后⽤分类模型预测"[MASK]"实际上是什么词。作者发现,在pre-training阶段, ⼀句话中有15%的token被选中,然后将这些token⽤"[MASK]"替换。⽽在fine-tuning阶段,给 BERT模型的输⼊并没有token被"[MASK]"替换。为了减少pre-training与fine-tuning阶段的差异, 在pre-training阶段,对MLM任务进⾏改进:在被选中的15%的token中,有80%被替换为" [MASK]",有10%被替换为⼀个随机token,有10%保持不变。如下所示:
 具体怎么做分类:输⼊[CLS]我 mask 中 mask 天 安 ⻔[SEP],预测句⼦的mask,多分类问题。
具体怎么做分类:输⼊[CLS]我 mask 中 mask 天 安 ⻔[SEP],预测句⼦的mask,多分类问题。
NSP任务:下⼀个句⼦预测,⽤于判断两个句⼦是否互为上下⽂。输⼊[CLS]a[SEP]b[SEP],预测b 是否为a的下⼀句,即⼆分类问题。
具体实现:因为与⽂本中已有的其它词相⽐,CLS这个⽆明显语义信息的符号会更“公平”地融合⽂ 本中各个词的语义信息,从⽽更好的表示整句话的语义。
 11. BERT和transformer
11. BERT和transformer
a. 相同点:
- ⅰ. 基础架构相同,BERT使⽤Transformer作为编码器;
- ⅱ. 都使⽤了位置编码;
- ⅲ. 都是多层堆叠的层级结构。
b. 不同点:
- ⅰ. 训练⽅式不同,Transformer在训练时,输⼊序列从左到右进⾏处理,逐步⽣成输出。这意 味着在⽣成每个位置的隐藏表示时,只能依赖于已经⽣成的左侧部分;BERT: 使⽤了双 向(双向上下⽂)的训练⽅式。它通过遮蔽输⼊⽂本中的⼀些词,然后预测这些词的上下 ⽂,从⽽使模型能够考虑到每个词的上下⽂信息。
- ⅱ. 此外还有输出层的差异:Transformer通常在输出层使⽤Softmax函数进⾏概率分布的计 算,适⽤于分类任务,BERT常⽤于⽣成上下⽂相关的词嵌⼊,⽽不是直接在输出层进⾏分 类。
BERT采⽤LayerNorm结构,和BatchNorm的区别主要是做规范化的维度不同
- a. BatchNorm针对⼀个batch⾥⾯的数据进⾏规范化,针对单个神经元进⾏,⽐如batch⾥⾯有64 个样本,那么规范化输⼊的这64个样本各⾃经过这个神经元后的值(64维)。图像领域⽤BN⽐ 较多的原因是因为每⼀个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被⼀起规范化。
- b. LayerNorm则是针对单个样本,不依赖于其他数据,常被⽤于⼩mini-batch场景、动态⽹络场 景和 RNN,特别是⾃然语⾔处理领域,就BERT来说就是对每层输出的隐层向量(768维)做规范化。
Attention时为啥要除以根号下dk:作者在论⽂中的解释是点积后的结果⼤⼩是跟维度成正⽐的,所以经过softmax以后,梯度就会变很⼩,除以根号下dk后可以让attention的权重分布⽅差为1,⽽不是dk。
NLP中构造词表
- a. 传统构造词表的⽅法,是先对各个句⼦进⾏分词,然后再统计并选出频数最⾼的前N个词组成词表。
- b. 存在问题: ⅰ. 模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将 ⽆法处理及⽣成; ⅱ. 词表中的低频词/稀疏词在模型训练过程中⽆法得到充分训练,进⽽模型不能充分理解这些 词的语义; ⅲ. ⼀个单词因为不同的形态会产⽣不同的词,但是在词表中这些词会被当作不同的词处理, ⼀⽅⾯增加了训练冗余,另⼀⽅⾯也造成了⼤词汇量问题。
上述问题的⼀种解决思路是使⽤字符粒度来表示词表,虽然能够解决OOV问题,但单词被拆分成字 符后,⼀⽅⾯丢失了词的语义信息,另⼀⽅⾯,模型输⼊会变得很⻓,这使得模型的训练更加复杂 难以收敛。针对上述问题,Subword(⼦词)模型⽅法被提出。它的划分粒度介于词与字符之间,⽐如 可以将”looking”划分为”look”和”ing”两个⼦词,⽽划分出来的"look",”ing”⼜能够⽤来构造其它 词,如"look"和"ed"⼦词可组成单词"looked",因⽽Subword⽅法能够⼤⼤降低词典的⼤⼩,同时对 相近词能更好地处理。
⽬前有三种主流的Subword算法,它们分别是:Byte Pair Encoding (BPE), WordPiece和Unigram Language Model。
理解BERT中的三部分输⼊:(1)wordpiece embedding:词嵌⼊,使⽤wordpiece⽅法对语料进 ⾏分词并编码;(2)position embedding:不是三⻆函数⽽是⼀个跟着训练学出来的向量,也就是 nn.Embedding;(3)segment embedding⽤于处理句⼦对任务,对输⼊序列中的每个单词标记其 所属句⼦,通常使⽤ 0 和 1 表示两个句⼦,然后通过嵌⼊层将每个句⼦标记转换为⼀个向量表示。
当⼀个batch的数据输⼊模型的时候,⼤⼩为(batch_size, max_len, embedding),其中batch_size 为batch的批数,max_len为每⼀批数据的序列最⼤⻓度,embedding则为每⼀个单词或者字的 embedding维度⼤⼩。⽽Batch Normalization是在batch间选择同⼀个位置的值做归⼀化,相当于 是对batch⾥相同位置的字或者单词embedding做归⼀化,Layer Normalization是在⼀个Batch⾥⾯ 的每⼀⾏做normalization,相当于是对每句话的embedding做归⼀化。显然,LN更加符合处理⽂本 的直觉。
相关文章:
NLP 八股 DAY1:BERT
BERT全称:Pre-training of deep bidirectional transformers for language understanding,即深度双向Transformer。 模型训练时的两个任务是预测句⼦中被掩盖的词以及判断输⼊的两个句⼦是不是上下句。在预训练 好的BERT模型后⾯根据特定任务加上相应的⽹…...

蓝桥与力扣刷题(230 二叉搜索树中第k小的元素)
题目:给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。 示例 1: 输入:root [3,1,4,null,2], k 1 输出:1示例 2ÿ…...

半遮挡检测算法 Detecting Binocular Half-Occlusions
【1. 背景】: 本文分析【Detecting Binocular Half-Occlusions:Empirical Comparisons of Five Approaches】Geoffrey Egnal和Richard P. Wildes于2002年发表在IEEE Transactions on Pattern Analysis and Machine Intelligence上,这是1篇中…...

PHP培训机构教务管理系统小程序
🔑 培训机构教务管理系统——智慧教育,高效管理新典范 🚀 这款教务管理系统,是基于前沿的ThinkPHP框架与Uniapp技术深度融合,匠心打造的培训机构管理神器。它犹如一把开启高效运营与精细管理的金钥匙,专为…...

《LeetCode 763. 划分字母区间 | 高效分割字符串》
内容: 问题描述: 给定一个字符串 S,将字符串分割成若干个子串,使得每个子串中的字符都不重复,并且返回每个子串的长度。 解题思路: 找到每个字符最后一次出现的位置:我们首先遍历一遍字符串&a…...

无人机不等同轴旋翼架构设计应用探究
“结果显示,对于不等组合,用户应将较小的螺旋桨置于上游以提高能效,但若追求最大推力,则两个相等的螺旋桨更为理想。” 在近期的研究《不等同轴旋翼性能特性探究》中,Max Miles和Stephen D. Prior博士深入探讨了不同螺…...

什么是 大语言模型中Kernel优化
什么是 大语言模型中Kernel优化 目录 什么是 大语言模型中Kernel优化Kernel优化操作系统内核优化深度学习计算内核优化手工优化原理举例Flash Attention,Faster TransformerKernel优化 大语言模型存在访存密集操作(如注意力机制、LayerNorm等),这些操作使得GPU计算性能无法…...

DeepSeek与ChatGPT:AI语言模型的全面对决
DeepSeek与ChatGPT:AI语言模型的全面对决 引言:AI 语言模型的时代浪潮一、认识 DeepSeek 与 ChatGPT(一)DeepSeek:国产新星的崛起(二)ChatGPT:AI 界的开拓者 二、DeepSeek 与 ChatGP…...

CTFHub技能树-密码口令wp
目录 引言弱口令默认口令 引言 仅开放如下关卡 弱口令 通常认为容易被别人(他们有可能对你很了解)猜测到或被破解工具破解的口令均为弱口令。 打开环境,是如下界面,尝试一些弱口令密码无果 利用burpsuite抓包,然后爆…...

Deepseek R1模型本地化部署与API实战指南:释放企业级AI生产力
摘要 本文深入解析Deepseek R1开源大模型的本地化部署流程与API集成方案,涵盖从硬件选型、Docker环境搭建到模型微调及RESTful接口封装的完整企业级解决方案。通过电商评论分析和智能客服搭建等案例,展示如何将前沿AI技术转化为实际生产力。教程支持Lin…...

MISP从入门到实战:威胁情报共享平台搭建与使用详解
MISP从入门到实战:威胁情报共享平台搭建与使用详解 目录 MISP核心作用与价值MISP安装与部署 2.1 Docker快速部署2.2 手动安装(Ubuntu) MISP基础使用教程 3.1 创建事件与属性3.2 数据共享与同步3.3 威胁情报分析实战 MISP高级功能 4.1 Galaxy…...

【NLP251】BertTokenizer 的全部 API 及 使用案例
BertTokenizer 是 Hugging Face 的 transformers 库中用于处理 BERT 模型输入的分词器类。它基于 WordPiece 分词算法,能够将文本分割成词汇单元(tokens),并将其转换为 BERT 模型可以理解的格式。BertTokenizer 是 BERT 模型的核心…...

【MySQL常见疑难杂症】常见文件及其所存储的信息
1、MySQL配置文件的读取顺序 (非Win)/etc/my.cnf、/etc/mysql/my.cnf、/usr/local/mysql/etc/my.cnf、~/.my.cnf 可以通过命令查看MySQL读取配置文件的顺序 [roothadoop01 ~]# mysql --help |grep /etc/my.cnf /etc/my.cnf /etc/mysql/my.c…...

InnoDB如何解决幻读?深入解析MySQL的并发控制机制
--- ## 一、什么是幻读(Phantom Read)? **幻读**是数据库事务隔离性中的一个典型问题,具体表现为: 在同一个事务中,多次执行相同的范围查询(Range Query)时,**后一次…...

栈的深度解析:从基础实现到高级算法应用——C++实现与实战指南
一、栈的核心算法与应用场景 栈的先进后出特性使其在以下算法中表现优异: 括号匹配:校验表达式合法性。表达式求值:中缀转后缀,逆波兰表达式求值。深度优先搜索(DFS):模拟递归调用。单调栈&am…...

IDEA集成DeepSeek
引言 随着数据量的爆炸式增长,传统搜索技术已无法满足用户对精准、高效搜索的需求。 DeepSeek作为新一代智能搜索技术,凭借其强大的语义理解与深度学习能力,正在改变搜索领域的游戏规则。 对于 Java 开发者而言,将 DeepSeek 集成…...

Oracle Trace文件突然增长很多的原因分析及解决办法
Oracle Trace文件突然增长很多可能是由多种原因引起的,例如SQL语句的长时间跟踪、错误的跟踪设置、大量的错误和警告信息等。 一、以下是一些解决Trace文件增长过快的方法: 1.清理旧的Trace文件 可以通过以下命令删除超过一定天数的Trace文件,例如删除3天前的Trace文件: …...

leetcode:627. 变更性别(SQL解法)
难度:简单 SQL Schema > Pandas Schema > Salary 表: ----------------------- | Column Name | Type | ----------------------- | id | int | | name | varchar | | sex | ENUM | | salary | int …...

SQLMesh系列教程-3:SQLMesh模型属性详解
SQLMesh 的 MODEL 提供了丰富的属性,用于定义模型的行为、存储、调度、依赖关系等。通过合理配置这些属性,可以构建高效、可维护的数据管道。在 SQLMesh 中,MODEL 是定义数据模型的核心结构,初学SQLMesh,定义模型看到属…...

Java 中的 HashSet 和 HashMap 有什么区别?
一、核心概念与用途 特性HashSetHashMap接口实现实现 Set 接口(存储唯一元素)实现 Map 接口(存储键值对)数据存储存储单个对象(元素唯一)存储键值对(键唯一,值可重复)典…...

Kubernetes-master 组件
以下是Kubernetes Master Machine的组件。 etcd 它存储集群中每个节点可以使用的配置信息。它是一个高可用性键值存储,可以在多个节点之间分布。只有Kubernetes API服务器可以访问它,因为它可能具有一些敏感信息。这是一个分布式键值存储,所…...

【Leetcode 952】按公因数计算最大组件大小
题干 给定一个由不同正整数的组成的非空数组 nums ,考虑下面的图: 有 nums.length 个节点,按从 nums[0] 到 nums[nums.length - 1] 标记;只有当 nums[i] 和 nums[j] 共用一个大于 1 的公因数时,nums[i] 和 nums[j]之…...

js考核第三题
题三:随机点名 要求: 分为上下两个部分,上方为显示区域,下方为控制区域。显示区域显示五十位群成员的学号和姓名,控制区域由开始和结束两个按钮 组成。点击开始按钮,显示区域里的内容开始滚动,…...

【第4章:循环神经网络(RNN)与长短时记忆网络(LSTM)— 4.6 RNN与LSTM的变体与发展趋势】
引言:时间序列的魔法钥匙 在时间的长河中,信息如同涓涓细流,绵延不绝。而如何在这无尽的数据流中捕捉、理解和预测,正是循环神经网络(RNN)及其变体长短时记忆网络(LSTM)所擅长的。今天,我们就来一场深度探索,揭开RNN与LSTM的神秘面纱,看看它们如何在时间序列的海洋…...

简单几个步骤完成 Oracle 到金仓数据库(KingbaseES)的迁移目标
作为国产数据库的领军选手,金仓数据库(KingbaseES)凭借其成熟的技术架构和广泛的市场覆盖,在国内众多领域中扮演着至关重要的角色。无论是国家电网、金融行业,还是铁路、医疗等关键领域,金仓数据库都以其卓…...

Java和JavaScript当中的json对象和json字符串分别讲解
Java和JavaScript当中的json对象和json字符串分别讲解 一、Java当中的json对象和json字符串 在 Java 中,JSON 对象和 JSON 字符串有不同的表示和操作方式。 1. JSON 对象: 如果你使用的是 org.json 库,创建 JSON 对象的代码如下࿱…...

【第11章:生成式AI与创意应用—11.2 音频与音乐生成的探索与实践】
凌晨三点的录音棚里,制作人小林对着空荡荡的混音台抓狂——广告方临时要求将电子舞曲改编成巴洛克风格,还要保留"赛博朋克"元素。当他在AI音乐平台输入"维瓦尔弟遇见霓虹灯"的瞬间,一段融合羽管键琴与合成器的奇妙旋律喷涌而出,这场人与机器的音乐狂想…...

八、SPI读写XT25数据
8.1 SPI 简介 SPI(Serial Peripheral Interface,串行外设接口)是一种同步串行通信协议,广泛用于嵌入式系统中连接微控制器与外围设备,如传感器、存储器、显示屏等。 主要特点 1. 全双工通信:支持同时发送…...
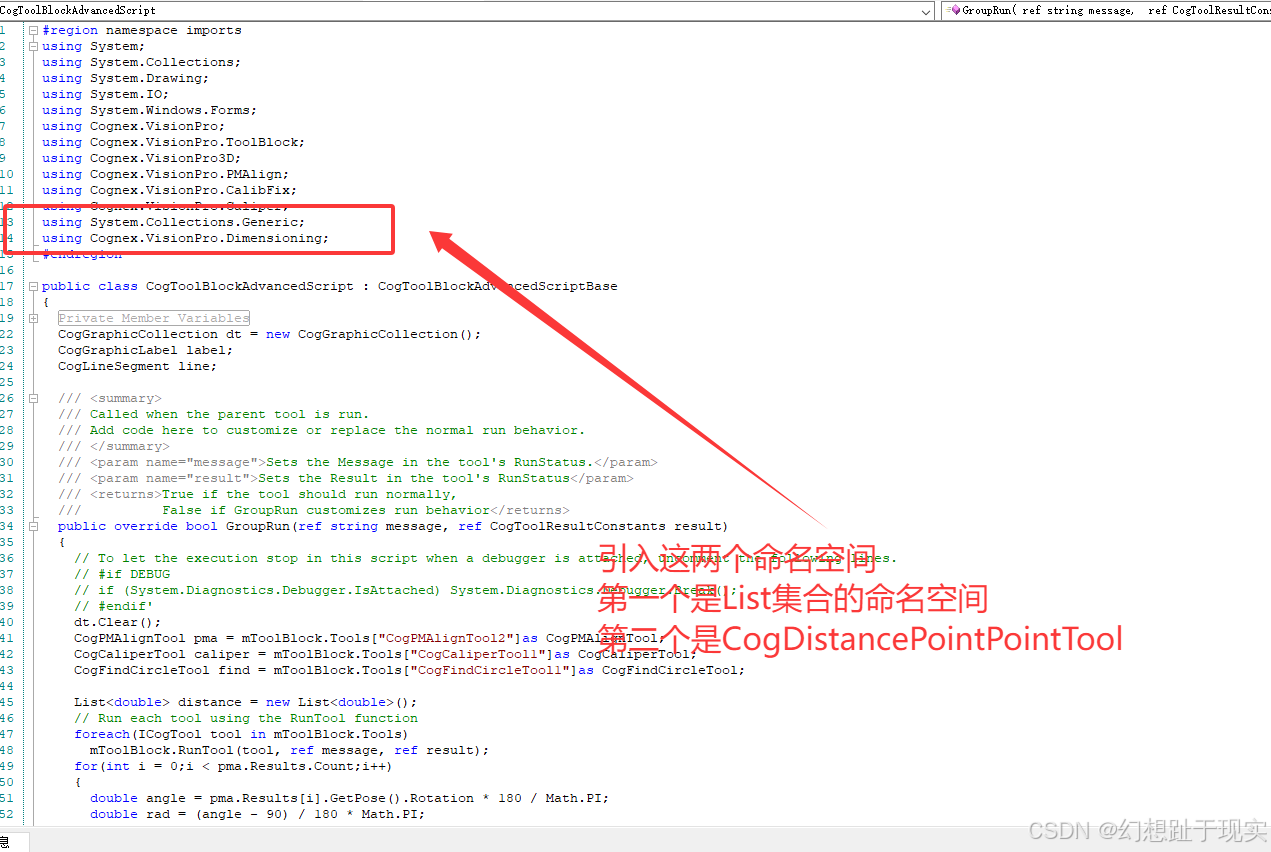
Visionpro 齿轮测量
效果展示 一、题目要求 求出最大值,最小值,平均值 二、分析 1.首先要进行模板匹配 2.划清匹配范围 3.匹配小三角的模板匹配 4.卡尺 5.用找圆工具 工具 1.CogPMAlignTool 2.CogCaliperTool 3.CogFindCircleTool 4.CogFixtureTool 三、模板匹…...

Ubuntu20.04部署stable-diffusion-webui环境小记
Ubuntu20.04部署stable-diffusion-webui环境小记 文章目录 前言后视镜视角查看安装文档聊聊我踩的那些坑python3.11的安装执行sudo apt update报错显卡驱动内存优化网络问题无法打开系统设置和网络设置查询GPU使用情况 总结 Stable Diffusion web UI A web interface for Stabl…...