MongoDB索引介绍
索引简述
-
索引是什么
索引在数据库技术体系中占据了非常重要的位置,其主要表现为一种目录式的数据结构,用来实现快速的数据查询。通常在实现上,索引是对数据库表(集合)中的某些字段进行抽取、排列之后,形成的一种非常易于遍历读取的数据集合。目前绝大多数的数据库对于索引技术都有非常强大且稳定的支持。
索引的作用非常类似于一本书的目录。 -
索引的分类
- 按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)。
- 按照索引字段的类型,可以分为主键索引和非主键索引。
- 按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含了一个指向数据记录的指针。
- 按照索引的特性不同,又可以分为唯一索引、稀疏索引、文本索引、地理空间索引等。
单键、复合索引
在MongoDB中,我们可以对集合中的某个字段或某几个字段创建索引,以book实体为例:
{"_id" : ObjectId("67ab68cbf47317cf01307b3b"),"title" : "book-0","type" : "technology","favCount" : 93,"tags":['popular'],"author" : {"name" : "zale"}
}
-
单字段索引
如果经常使用title这个字段进行搜索,可以为它创建一个单字段的索引> db.book.bookCollection.ensureIndex({title:1}) {"createdCollectionAutomatically" : true,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1 }这里的“title:1”中的1表示所有采用的是升序排列。然而,在单字段的索引中,使用升序和降序并没有什么区别。
我们也可以对内嵌的文档字段创建索引:db.book.bookCollection.ensureIndex({auth.name:1}) -
复合索引
复合索引是多个字段组合而成的索引,其性质和单字段索引类似。但不同的是,复合索引中字段的顺序、字段的升降序对查询性能有直接的影响,因此在设计复合索引时需要考虑不同的查询场景。
例如,如果需要频繁地查询某分类下地book文档排名,可以按照分类,收藏数量创建一个复合索引,
db.book.bookCollection.ensureIndex({type:1,favCount:1})
数组索引
数组索引也被称为多值索引,当我们对数组型地字段创建索引时,这个索引就是多值的。多值索引在使用上与普通索引并没有什么不同,只是索引键上会同时产生多个值。
db.book.bookCollection.ensureIndex({tags:1})
多值索引很容易与复合索引产生混淆,复合索引时多个字段的组合,而多值索引则仅仅是在一个字段上出现了多值。而实际上,多值索引也可以出现在复合索引上,例如:db.book.bookCollection.ensureIndex({type:1,tags:1})。然而,mongodb并不支持一个复合索引中同时出现多个数组字段。
地理空间索引
在移动互联网时代,基于地理位置的检索功能几乎时所有应用系统的标配。
mongodb为地理空间检索提供了非常方便的功能。地理空间索引就是专门用于实现位置检索的一种特殊索引。
db.store.insertOne({location:{type:"Point",coordinates:[-122.158574,37.449157]}})
db.store.ensureIndex({ location: "2dsphere" });
db.store.find({location:{$near:{$geometry:{type:"Point",coordinates:[-122.158,37.449]},$maxDistance:5000}}})> { "_id" : ObjectId("67ab829c2cee149b47c1e30e"), "location" : { "type" : "Point", "coordinates" : [ -122.158574, 37.449157 ] } }
这里使用$near查询操作符,用于实现附近商家的检索,返回的数据结果会按距离排序
注意:mongodb的地理空间检索基于WGS84坐标系,在与一些地图平台集成时需要注意转换。
唯一性约束
在创建索引时,通过指定unique=true选项可以将其声明为唯一性索引,代码如下:
db.book.ensureIndex({title:1},{unique:true})
此后,如果尝试写入2个拥有相同标题的book文档,则会报错;另外,对于指定的字段已经存在重复记录的集合,如果尝试创建唯一性约束的索引,也会提示报错。
-
复合索引的唯一性
除了单字段索引,还可以为复合索引使用唯一约束。例如,如果只是希望分类下的书籍标题保持唯一性,那么可以建立复合式的唯一索引。db.book.ensureIndex({type:1,title:1},{unique:true}) -
嵌套文档的唯一性
唯一性约束同样可以用于嵌套文档的某个字段,这和普通索引没有什么区别,比如:db.book.ensureIndex({author.name:1},{unique:true})但如果希望将整个嵌套文档作为唯一性的保证,那么在使用时可能会造成困扰,比如:
db.book.ensureIndex({author:1},{unique:true})嵌套文档的唯一性约束是严格按照写入顺序进行比较的,如下代码所示,尽管写入的文档内容是一样的,但由于字段的顺序不一致,mongodb仍然认为这是不同的文档。为了避免困扰,尽量少用这种写法。
db.book.insert({author:{age:20,name:"Lwy"}}) db.book.insert({author:{name:"Lwy",age:20}}) -
数组的唯一性
如果对数组索引使用唯一性约束,那么可以保证所有的文档之间不会存在重叠的数组元素,代码如下:db.book.ensureIndex({tags:1},{unique:true}) db.book.insert({tags:["t1","t2"]}) db.book.insert({tags:["t1","t3","t3"]})//插入失败但是,数组索引上的唯一性约束并无法保证同一个文档中包含重复的元素,如下面的语句是可以写入成功的:
db.book.insert({tags:['t1','t3','t1']})注意:如果数组中的元素是嵌套的文档,那么同样会遇到字段次序的问题。
-
使用约束
- 唯一性索引对于文档中缺失的字段,会使用null值代替,因此不允许存在多个文档缺失索引字段的情况。
- 对于分片的集合,唯一性约束必须匹配分片规则。换句话说,为了保证全局的唯一性,分片键必须作为唯一性索引的前缀字段。
TTL索引
在一般的应用系统中,并非所有的数据都需要永久存储。例如一些系统事件、用户消息等,这些数据随着事件的推移,其重要程度逐渐降低。更重要的是,储存这些大量的历史数据需要花费较高的成本,因此项目中通常会对过期且不再使用的数据进行老化处理。
通常的做法如下:
- 为每一个数据记录一个时间戳,应用侧开启一个定时器,按时间戳定期删除过期的数据。
- 数据按日期进行分表,同一天的数据归档到同一张表,同样使用定时器删除过期的表。
对于数据老化,mongodb提供了一种更加便捷的做法:TTL索引。TTL索引需要声明在一个日期类型的字段中,假定写入的文档数据如下:
db.systemlog.insert({createdDate:new Date(),type:"warning"})
db.systemlog.ensureIndex({createdDate:1},{expireAfterSeconds:3600})//1小时后过期
对于集合创建TTL索引之后,mongodb会在周期性运行的后台线程中对该集合进行检查以及数据清理工作。除了数据老化功能,TTL索引具有普通索引的功能,同样可以用于加速数据的查询。
-
可变的过期时间
TTL索引在创建之后,仍然可以对过期时间进行修改。db.runCommand({collMod:"systemlog",index:{KeyPattern:{createdDate:1},expireAfterSeconds:7200}})另一种情形也比较常见,如每个文档可能拥有各自的存活时长,即老化策略不同。
比如,在systemlog集合中,不同的事件类型的老化周期是不一样的,对于此类场景的解决方法是可以使用一个单独的字段expiredDate,用于表示每个文档的过期时间点,那么TTL索引创建的规则为:db.systemlog.ensureIndex({expiredDate:1},{expireAfterSeconds:0}) -
使用约束
TTL索引的确可以减少开发量,而且通过数据库自动清理的方式会更加高效、可靠,但是在使用TTL索引时需要注意以下的限制:- TTL索引只能支持单个字段,并且必须是非_id字段。
- TTL索引不能用于固定集合。
- TTL索引无法保证及时的数据老化,mongodb会通过后台的TTL Monitor定时器来清理老化数据,如果在数据库负载过高的情况下,TTL的行为则会进一步收到影响。
- TTL索引对于数据的清理仅仅使用了remove命令,这种方式并不是很高效。因此TTL Monitor在运行期间对系统CPU、磁盘都会造成一定的压力。相比之下,按日期分表的方式操作会更加高效。
条件索引
条件索引允许对部分文档建立索引。例如,仅对业务上最常用于查询的数据集创建索引,可以节省一些空间。
db.store.createIndex({cuisine:1,name:1},{partialFilterExpression:{rating:{$gt:5}}})
只对评分高于5分的餐馆信息进行索引。
稀疏索引
对于某个索引字段来说,可能某些文档中并不存在该字段,但是mongodb索引会将不存在字段的情况等同于null值处理。稀疏索引则具备这样的特性:只对存在字段的文档进行索引(包括字段值为null的文档)。
> db.test.insert({x:1})
WriteResult({ "nInserted" : 1 })
> db.test.insert({x:2,z:null})
WriteResult({ "nInserted" : 1 })
> db.test.find({z:null})
{ "_id" : ObjectId("63fedb6ae658b76ec2b3d9f1"), "name" : "test" }
{ "_id" : ObjectId("63fee0eab09131f29d9a4ace"), "sdsd" : 12 }
{ "_id" : ObjectId("63fee0f7b09131f29d9a4acf"), "sdsd" : 12 }
{ "_id" : ObjectId("63fee113b09131f29d9a4ad0"), "sdsd" : 12 }
{ "_id" : ObjectId("63fee118b09131f29d9a4ad1"), "sdsd" : 12 }
{ "_id" : ObjectId("63fee241b09131f29d9a4ad2"), "name" : undefined }
{ "_id" : ObjectId("63fee281b09131f29d9a4ad3"), "name" : undefined }
{ "_id" : ObjectId("63fee2d0b09131f29d9a4ad4"), "name" : undefined }
{ "_id" : ObjectId("67af62c2cebb0af2ca2a680e"), "x" : 1 }
{ "_id" : ObjectId("67af62cecebb0af2ca2a680f"), "x" : 2, "z" : null }
> db.test.createIndex({z:1},{sparse:true})
> db.test.find({z:null}).hint({"z":1})
{ "_id" : ObjectId("67af62cecebb0af2ca2a680f"), "x" : 2, "z" : null }
文本索引
mongodb支持文本检索功能,可通过建立文本索引来实现简易的分词检索。不过该功能目前支持英文分词,并未提供中文分词的功能。
> db.systemlog.insert({title:"the monkey's hair",summary:"the story about monkey"})
WriteResult({ "nInserted" : 1 })
> db.systemlog.insert({title:"two stars",summary:"long long hair in the sky"})
WriteResult({ "nInserted" : 1 })
> db.store.find()
{ "_id" : ObjectId("67ab829c2cee149b47c1e30e"), "location" : { "type" : "Point", "coordinates" : [ -122.158574, 37.449157 ] } }
> db.systemlog.find()
{ "_id" : ObjectId("67af661ccebb0af2ca2a6810"), "title" : "the monkey's hair", "summary" : "the story about monkey" }
{ "_id" : ObjectId("67af663dcebb0af2ca2a6811"), "title" : "two stars", "summary" : "long long hair in the sky" }
> db.systemlog.createIndex({title:"text",summary:"text"})
{"createdCollectionAutomatically" : false,"numIndexesBefore" : 2,"numIndexesAfter" : 3,"ok" : 1
}
> db.systemlog.find({$text:{$search:"monkey sky"}})//会检索出含有monkey或sky关键词的文档
{ "_id" : ObjectId("67af661ccebb0af2ca2a6810"), "title" : "the monkey's hair", "summary" : "the story about monkey" }
{ "_id" : ObjectId("67af663dcebb0af2ca2a6811"), "title" : "two stars", "summary" : "long long hair in the sky" }
> db.systemlog.find({$text:{$search:"sky"}})
{ "_id" : ObjectId("67af663dcebb0af2ca2a6811"), "title" : "two stars", "summary" : "long long hair in the sky" }
> db.systemlog.find({$text:{$search:"stars"}})
{ "_id" : ObjectId("67af663dcebb0af2ca2a6811"), "title" : "two stars", "summary" : "long long hair in the sky" }
>
$text操作符会将search文本进行分词再检索。
模糊索引
模糊索引可以建立再一些不可预知的字段上,一次实现查询的加速。该功能是mongodb4.2版本才推出的新特性。
db.goods.insert({name:"wallet",attributes:{color:"red"}})
db.good.insert({name:"chair",attributes:{height:120}})
其中,attributes作为嵌套文档存放了商品的多个属性,而不同商品所具有的属性可能是不一样的。接下来创建一个模糊索引:
db.goods.createIndex({"attributes.$**":1})
attributes.$**表示该索引将匹配以attributes字段作为开始路径的任何一个字段。
使用explain命令验证优化(查询计划)
db.systemlog.find({$text:{$search:"monkey sky"}}).explain("executionStats")
通过该命令我们可以验证下加了索引前后的查询差异。
如果有多个索引可以同时匹配当前的查询条件,那么mongodb就会在它们之中做出选择。又或者,整个查询过程并没有索引的介入而执行了全表扫描。
一个查询具体如何被执行的过程称为查询计划。通过explain命令我们可以清楚地看到查询计划地许多细节。这包括我们关心地一些问题:
- 查询是否使用了索引。
- 索引命中地情况是不是最佳的。
- 查询是否需要扫描大量的记录。
explain命令除提供查询计划的信息外,还可以模拟计划的执行并提供更多的过程信息。总的来说,explain有3种执行模式。
- queryPlanner:默认的模式,仅进行查询计划分析,输出计划种的阶段信息。
- executionStats:执行模式,在查询计划分析后,将按照winningPlan执行查询并统计过程信息。
- allPlansExecution:全计划执行模式,将执行所有计划(包括winningPlan和rejectPlans),并返回全部的过程统计信息。
合理使用索引
通过上面的知识,我们知道了mongodb所支持的各种索引分类以及基本操作。然而,仅有这些可能还不够,在日常开发中,或许经常会遇到这样的问题:
- 什么时候应该使用索引
- 怎么创建索引才是最高效的,有没有可遵循的一些原则
- 索引是怎么提升性能的,是不是索引越多越好呢
索引检索原理
-
全表扫描带来的问题
在没有任何索引辅助的情况下,数据库查找数据只能通过遍历所有文档,并逐一过滤,直到数据查找完成。全表扫描是线性查找的方式,其时间复杂度为O(n)。尤其是遇到数据量大的时候,一个查询可能要花费几十秒甚至几分钟的时间,除此之外,在其整个扫描过程中,还会加载大量的磁盘数据到内存中,导致mongodb用于提供快速查询的“热数据缓存”被大量换出,进而又影响整体的性能以及稳定性。 -
B+树索引
既然全表扫描的问题在于扫描的条目太多,那么索引的优化就在于如何缩短检索数据所需要经历的路径。从mongodb3.2版本开始,其采用了wiredTiger作为默认的引擎,在索引和集合的检索上则借鉴了B+树的结构。B+树索引是一个m阶平衡树的结构,其查询复杂度是O(logm n),其中,m是节点最大的分支数量,n是总体的节点数。以1亿的表为例,转换为平衡树结构(m阶)之后,假设m=10,那么整个树只有8层,一次检索只需经过8次节点扫描就可以完成。 -
二级索引
二级索引也叫非聚簇索引,另一个相对的概念叫做聚簇索引,这两者的区别如下:- 聚簇索引的叶子节点存储了正真的数据记录。
- 二级索引的叶子节点仅仅存放了索引值以及指向数据记录的指针或主键。
因此,二级索引在检索数据的过程中往往需要更多的查找次数,其中第二次查找真正数据记录的过程中常常被称为“回表”。在mongodb集合中,除了_id外的其他索引都是二级索引。
覆盖索引
覆盖索引指的是一种查询优化的行为。在一棵二级索引的B+树上,索引的值存在于叶子节点。因此,如果希望查询的字段被包含在索引中,则直接查找二级索引树就可以获得,而不需要再次通过_id索引查找出原始的文档。相比“非覆盖式”的查找,覆盖索引的这种行为可以减少一次对最终文档数据的检索操作(回表)。大部分情况下,二级索引树常驻在内存中,覆盖式的查询可以保证一次检索行为仅仅发生在内存中,既避免了对磁盘的I/O的操作。
> db.test.find({name:/as/},{name:1,_id:0})
{ "name" : "as9238Ji" }
> db.test.find({name:/as/},{name:1,_id:0}).explain()//_id:0是必须提供的,否则数据库会将_id字段也一起返回,这样会导致使用覆盖索引行为失效。
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test.test","indexFilterSet" : false,"parsedQuery" : {"name" : {"$regex" : "as"}},"winningPlan" : {"stage" : "PROJECTION","transformBy" : {"name" : 1,"_id" : 0},"inputStage" : {"stage" : "IXSCAN","filter" : {"name" : {"$regex" : "as"}},"keyPattern" : {"name" : 1},"indexName" : "name_1","isMultiKey" : false,"multiKeyPaths" : {"name" : [ ]},"isUnique" : false,"isSparse" : true,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"name" : ["[\"\", {})","[/as/, /as/]"]}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "DESKTOP-5433197","port" : 27017,"version" : "4.0.14-rc1","gitVersion" : "1622021384533dade8b3c89ed3ecd80e1142c132"},"ok" : 1
}
> db.test.find({name:/as/},{name:1}).explain()
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test.test","indexFilterSet" : false,"parsedQuery" : {"name" : {"$regex" : "as"}},"winningPlan" : {"stage" : "PROJECTION","transformBy" : {"name" : 1},"inputStage" : {"stage" : "FETCH","inputStage" : {"stage" : "IXSCAN","filter" : {"name" : {"$regex" : "as"}},"keyPattern" : {"name" : 1},"indexName" : "name_1","isMultiKey" : false,"multiKeyPaths" : {"name" : [ ]},"isUnique" : false,"isSparse" : true,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"name" : ["[\"\", {})","[/as/, /as/]"]}}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "DESKTOP-5433197","port" : 27017,"version" : "4.0.14-rc1","gitVersion" : "1622021384533dade8b3c89ed3ecd80e1142c132"},"ok" : 1
}
>
我们可以对比二者查询的查询计划,使用覆盖索引并不存在FETCH阶段。
最终,在使用覆盖索引是需要记住下面两点:
- 覆盖索引的前提是二级索引,并且检索条件,返回字段都必须严格被索引覆盖到
- 对于嵌套的数组字段,无法使用覆盖索引查询。
强制命中
-
使用hint方法
hint方法实现了对查询计划机制的干预,在查询计划中使用hint语句可以让mongodb忽略查询优化器的结果,从而直接使用指定的索引。
比如下面这种做法:db.test.find().hint({name:1}) //强制使用{name:1}这个索引。 db.test.find().hint("name_1") //可以传入索引的定义对象,也可以是索引的名称。 -
使用IndexFilter方法
db.runCommand({planCacheSetFilter:"test",query:{a:3,b:4},indexs:[{b:1}]})执行planCacheSetFilter命令会在test集合中增加了一个IndexFilter对象,该对象将会自动关联到同时包含a字段和b字段的等值查询,并引导查询优化器使用{b:1}这个索引。
其中,查询模型会忽略查询条件中具体的数值,因此下面的查询时适用的:db.test.find({a:99,b:-1})但是,如果使用了非等值查询(如ge、lt),或者排序(sort)、投射(projection)发生了变化,就会导致匹配失效。
indexFilter时内存台的,如果重启了mongodb,则会自动失效。另外,可以使用planCacheClearFilters进行擦除,代码如下:db.runCommand({planCacheClearFilters:"test"})
indexFilter方法优先级高于hint,如果查询优化器发现了关联的indexFilter,则一定会忽略hint语句。但是,indexFilter并不能保证查询优化器最终一定会选择对应的索引,事实上优化器会将这些索引于全表扫描一并进行评估,再抉择出最终的结果。在最坏的情况下,如果我们指定了不存在的索引,就会导致全表扫描。
注意:mongodb的查询优化器已经足够强大,无论是hint方法还是indexfilter,都会改变默认的查询优化行为,尽量少用。
优化原则
-
在适当的时机使用索引
索引的作用在于提高查询效率。当返回结果集只是全部文档的一小部分时,增加合适的索引才能获得不错的性价比。 -
使用前缀匹配
对于模糊匹配的查询,尽量使用前缀匹配。比如搜索名称时使用/^keyword/要明显优于/keyword/。后者很可能需要对整个索引树进行遍历。 -
避免低效的操作符
nin、ne、not不利于索引命中。相反,这些操作符会导致大范围扫描,建议避免这些操作。除此之外,where、exist也无法利用索引优化,同样需要避免。 -
使用覆盖索引优化
建议只返回需要的字段,同时,利用覆盖索引来提升性能。 -
高基数优先原则
基数(card inality)是指某个字段拥有的唯一值的数量。以用户信息为例,基数高的字段为用户身份证号、手机号等,基数低的字段为性别等。一个字段的基数越高,越有利于快速检索。这是因为高基数的索引能迅速将检索范围圈定到一个比较小的结果集上,如果基数太小则会产生许多排除性的工作。比如想要查询“1990年10月13日出生的女性”,如果使用性别(gender)这个索引进行查找,将只能将结果集范围缩小50%左右。
一般来说,唯一索引的数量是最高的(基数等同于文档的数量),建议优先为基数高的字段建立索引,另外,组合索引上也应尽量将基数高的字段放在前面。 -
控制索引的数量
索引并不是越多越好,相反,过多的索引会带来一些问题:- 多余索引会抢占内存空间,导致常用的索引被挤兑,影响查询性能。
- 写操作性能降低,一次文档写入会触发多个索引的更新,增加了系统I/O开销。需要谨慎地对整个文档进行保存。如果使用了SpringDataMongo这样的ORM框架,开发者往往会使用save命令保存整个文档,此时将会触发集合中所有索引的更新。如果能在update操作中明确指定需要更新的字段,那么影响则会减少一些。也就是说,只有当索引中的字段被update指定时才会触发更新。
- 不利于查询计划优化,太多的索引会增加查询计划评估的难度,在极端情况下可能会产生“索引跳变”。
-
避免设计过长的数组索引
数组索引是多值的,在存储时需要使用更多的空间。如果索引的数组长度特别长,或者数组的增长不受控制,则可能导致索引空间急剧膨胀。 -
避免创建重复的索引
组合索引具有“前缀覆盖”的特点,应避免存在已经被覆盖的索引。例如:>ab.test.ensure Tndex((x:1,y:1,z:1}) >db.test.ensureIndex({x:1,y:1 )) >db.test.ensureIndex({x:1}){xl,y:1,z1}同时具备{x1}索引和{x1,y:1}索引的功能,因此后面两个索引可以去掉。如果使用了哈希分片,则可能会获得该分片键上的一个哈希索引。如果应用上只需要对该字段进行单个查询,那么该索引已经完全可以满足。不要对分片键创建重复的索引。
-
删除无用的索引
对环境中的数据库例行检查,及时删除不使用的索引。 -
避免深度分页
避免使用skip命令实现超大集合的分页,该命令会消耗CPU资源,当跳转到深度页面时响应会非常缓慢。 -
避免一次性返回大量结果集
对于较大的集合,应避免直接使用find命令进行全表查询;当返回的结果集很大时,使用limit方法限制合理的返回条目数,比如一次批量查询不超过1000条。这个约束还要考虑结合当前系统所能承受的性能压力,一般在高并发、高实时性的场景下,这个值通常要设置得更小。无论何时,都应该对结果集的大小保持警惕。如果对此不加控制,则很可能导致应用程序出现OOM错误。 -
谨防内存排序
对于存在排序需求的查询,在缺失索引,或者组合索引的排序方向不匹配的情况下,会产生内存排序。内存排序需要更多的临时内存,影响资源占用。此外,MongoDB对于排序的内存使用有32MB的限制,超过该阈值会产生失败。 -
避免大量的扫描
避免全表扫描或大范围的记录扫描,通过exp lain结果中的totalKeysExamined、totalDocsExamined可获知当前的扫描次数。避免涉及大范围扫描的计算操作。 -
为索引预留足够的内存
为了保证性能,最好保证索引能被装入内存中。当内存不足时,索引需要从磁盘中加载,这会导致昂贵的I/O操作。一种例外的情况是递增式的索引,即索引的值呈现出递增的特点,而且应用上也只关心最近产生的一部分数据。例如,系统日志可以按照日期建立索引,而通常我们也只关心最近几天产生的日志,此时内存中则可以仅保留“被关心”的部分数据。
相关文章:

MongoDB索引介绍
索引简述 索引是什么 索引在数据库技术体系中占据了非常重要的位置,其主要表现为一种目录式的数据结构,用来实现快速的数据查询。通常在实现上,索引是对数据库表(集合)中的某些字段进行抽取、排列之后,形成的一种非常易于遍历读取…...

【一文读懂】WebRTC协议
WebRTC(Web Real-Time Communication)协议 WebRTC(Web Real-Time Communication)是一种支持浏览器和移动应用程序之间进行 实时音频、视频和数据通信 的协议。它使得开发者能够在浏览器中实现高质量的 P2P(点对点&…...

【弹性计算】容器、裸金属
容器、裸金属 1.容器和云原生1.1 容器服务1.2 弹性容器实例1.3 函数计算 2.裸金属2.1 弹性裸金属服务器2.2 超级计算集群 1.容器和云原生 容器技术 起源于虚拟化技术,Docker 和虚拟机和谐共存,用户也找到了适合两者的应用场景,二者对比如下图…...

【个人开发】deepspeed+Llama-factory 本地数据多卡Lora微调
文章目录 1.背景2.微调方式2.1 关键环境版本信息2.2 步骤2.2.1 下载llama-factory2.2.2 准备数据集2.2.3 微调模式2.2.3.1 zero-3微调2.2.3.2 zero-2微调2.2.3.3 单卡Lora微调 2.3 踩坑经验2.3.1 问题一:ValueError: Undefined dataset xxxx in dataset_info.json.2…...

两步在 Vite 中配置 Tailwindcss
第一步:安装依赖 npm i -D tailwindcss tailwindcss/vite第二步:引入 tailwindcss 更改配置 // src/main.js import tailwindcss/index// vite.config.js import vue from vitejs/plugin-vue import tailwindcss from tailwindcss/viteexport default …...

使用 HTML CSS 和 JAVASCRIPT 的黑洞动画
使用 HTML CSS 和 JAVASCRIPT 的黑洞动画 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Black Ho…...

计算机视觉-尺度不变区域
一、尺度不变性 1.1 尺度不变性 找到一个函数,实现尺度的选择特性。 1.2 高斯偏导模版求边缘 1.3 高斯二阶导 用二阶过零点检测边缘 高斯二阶导有两个参数:方差和窗宽(给定方差可以算出窗宽) 当图像与二阶导高斯滤波核能匹配…...

SNARKs 和 UTXO链的未来
1. 引言 SNARKs 经常被视为“解决”扩容问题的灵丹妙药。虽然 SNARKs 可以提供令人难以置信的好处,但也需要承认其局限性——SNARKs 无法解决区块链目前面临的现有带宽限制。 本文旨在通过对 SNARKs 对比特币能做什么和不能做什么进行(相对)…...
DeepSeek 通过 API 对接第三方客户端 告别“服务器繁忙”
本文首发于只抄博客,欢迎点击原文链接了解更多内容。 前言 上一期分享了如何在本地部署 DeepSeek R1 模型,但通过命令行运行的本地模型,问答的交互也要使用命令行,体验并不是很好。这期分享几个第三方客户端,涵盖了桌…...

性格测评小程序07用户登录
目录 1 创建登录页2 在首页检查登录状态3 搭建登录功能最终效果总结 小程序注册功能开发好了之后,就需要考虑登录的问题。首先要考虑谁作为首页,如果把登录页作为首页,比较简单,每次访问的时候都需要登录。 如果把功能页作为首页&…...

红队视角出发的k8s敏感信息收集——日志与监控系统
针对 Kubernetes 日志与监控系统 的详细攻击视角分析,聚焦 集群审计日志 和 Prometheus/Grafana 暴露 的潜在风险及利用方法 攻击链示例 1. 攻击者通过容器逃逸进入 Pod → 2. 发现未认证的 Prometheus 服务 → 3. 查询环境变量标签获取数据库密码 → 4. 通过审…...

deepseek多列数据对比,联想到excel的高级筛选功能
目录 1 业务背景 2 deepseek提示词输入 3 联想分析 4 EXCEL高级搜索 1 业务背景 系统上线的时候经常会遇到一个问题,系统导入的数据和线下的EXCEL数据是否一致,如果不一致,如何快速找到差异值,原来脑海第一反应就是使用公…...

国产编辑器EverEdit - “切换文件类型”的使用场景
1 “切换文件类型”的使用场景 1.1 应用背景 一般的编辑器都是通过扩展名映射到对应的语法高亮规则的,比如:文件test.xml中的扩展名“xml"对应XML的语法高亮,在编辑器中打开test.xml就会给不同标识符显示不同的颜色。 但有时一些应用程…...

VSCode 接入DeepSeek V3大模型,附使用说明
VSCode 接入DeepSeek V3大模型,附使用说明 由于近期 DeepSeek 使用人数激增,服务器压力较大,官网已 暂停充值入口 ,且接口响应也开始不稳定,建议使用第三方部署的 DeepSeek,如 硅基流动 或者使用其他模型/插件,如 豆包免费AI插件 MarsCode、阿里免费AI插件 TONGYI Lin…...

JavaScript 内置对象-数组对象
在JavaScript中,数组(Array)是一种非常重要的数据结构,它允许我们以列表的形式存储多个值,并提供了丰富的内置方法来操作这些值。无论是处理简单的数值集合还是复杂的对象数组,数组对象都能提供强大的支持。…...

在linux系统中安装Anaconda,并使用conda
系统 : ubuntu20.04 显卡:NVIDIA GTX1650 目录 安装Anaconda第一步:下载合适版本的Anconda1. 查看自己Linux的操作系统及架构命令:uname -a2. 下载合适版本的Anconda 第二步:安装Aanconda1. 为.sh文件设置权限2. 执行.sh文件2.1 .…...

机械学习基础-5.分类-数据建模与机械智能课程自留
data modeling and machine intelligence - CLASSIFICATION 为什么我们不将回归技术用于分类?贝叶斯分类器(The Bayes Classifier)逻辑回归(Logistic Regression)对逻辑回归的更多直观理解逻辑 /sigmoid 函数的导数我们…...

静态页面在安卓端可以正常显示,但是在ios打开这个页面就需要刷新才能显示全图片
这个问题可能有几个原因导致,我来分析一下并给出解决方案: 首要问题是懒加载实现方式的兼容性问题。当前的懒加载实现可能在 iOS 上不够稳定。建议修改图片懒加载的实现方式: // 使用 Intersection Observer API 实现懒加载 function initLazyLoading() {const imageObserver…...

代码随想录刷题攻略---动态规划---子序列问题1---子序列
子序列(不连续)和子序列(连续)的问题 例题1: 最长递增子序列 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列是由数组派生而来的序列,删除(或不删除)数组中的…...

八股取士--dockerk8s
一、Docker 基础 Docker 和虚拟机的区别是什么? 答案: 虚拟机(VM):虚拟化硬件,每个 VM 有独立操作系统,资源占用高,启动慢。Docker:容器化应用,共享宿主机内核…...
)
ubuntu系统下KVM设置桥接网络(失败)
20250216 - 概述 因实验需求,需要设置KVM下的虚拟机采用桥接模式进行通信,这种方式将使虚拟机与主机类似使用同一网段的IP。实际上,为了实现这个功能,我已经在自己mac上VMware使用过,虚拟机获得了自己独立的IP。 但…...
测试用例CAPL代码全解析④】)
【ISO 14229-1:2023 UDS诊断(会话控制0x10服务)测试用例CAPL代码全解析④】
ISO 14229-1:2023 UDS诊断【会话控制0x10服务】_TestCase04 作者:车端域控测试工程师 更新日期:2025年02月15日 关键词:UDS诊断、0x10服务、诊断会话控制、ECU测试、ISO 14229-1:2023 TC10-004测试用例 用例ID测试场景验证要点参考条款预期…...

OpenAI 放王炸,将发布整合多项技术的 GPT-5,并免费无限使用,该模型有哪些技术亮点
对于 ChatGPT 的免费用户,将可以无限制地访问 GPT-5,但仅限于标准的智能级别。该级别会设定滥用限制,以防止不当使用(意思就是你得付费嘛)。 OpenAI CEO Sam Altman 今天在 X 上透露了 GPT-4.5 和 GPT-5 的最新发展计划。 OpenAI 将发布代…...
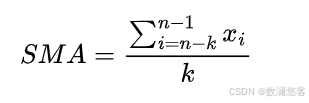
C 语言版--销售预测项目案例分享
以下是一个 C 语言销售预测项目案例,该项目模拟根据历史销售数据使用简单的移动平均法来预测未来的销售额。移动平均法是一种常见且基础的时间序列预测方法,它通过计算一定时间段内数据的平均值来预测未来的值。 项目需求 给定一系列历史销售数据,使用简单移动平均法预测下…...

用deepseek学大模型05-线性回归
deepseek.com:多元线性回归的目标函数,损失函数,梯度下降 标量和矩阵形式的数学推导,pytorch真实能跑的代码案例以及模型,数据,预测结果的可视化展示, 模型应用场景和优缺点,及如何改进解决及改进方法数据推…...

DC-7靶机渗透测试全过程
目录 前期准备 一、渗透测试 1.IP地址查询 2.端口地址收集 3.网页信息收集 社工收集信息 Drush直接修改账户密码 下载PHP插件 反弹shell 二、总结 前期准备 攻击机 : kali windows11 靶机: DC-7(调至NAT模式) 一、渗透测试 1.IP地址查询 …...

什么是服务的雪崩、熔断、降级的解释以及Hystrix和Sentinel服务熔断器的解释、比较
1.什么是服务雪崩? 定义:在微服务中,假如一个或者多个服务出现故障,如果这时候,依赖的服务还在不断发起请求,或者重试,那么这些请求的压力会不断在下游堆积,导致下游服务的负载急剧…...

解决IDEA报错:java 找不到符号
问题:IIDEA编译项目一直报 例如 java: 找不到符号 符号: 方法 getUserId()异常 的错误 解决方法: 1、刷新maven 2、clean package...

基于SpringBoot的医院药房管理系统【源码+答辩PPT++项目部署】高质量论文1-1.5W字
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

Ubuntu22.04通过Docker部署Jeecgboot
程序发布环境包括docker、mysql、redis、maven、nodejs、npm等。 一、安装docker 1、用如下命令卸载旧Docker: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done 2、安装APT环境依赖包…...