mysql之Innodb数据页
Innodb数据页结构
- InnoDB数据页结构
- 一、数据页基础概念
- 二、数据页核心结构
- 1. 头部控制区
- 2. 数据存储区
- 3. 尾部与目录区
- 三、关键机制详解
- 1. 记录链表与删除优化
- 2. 页目录与二分查找
- 3. 空间复用与碎片管理
- 4. 数据页的合并与分裂
- 四、应用与性能影响
- 1. 索引效率
- 2. 插入优化
- 3. 事务与恢复
- 4. 与 Buffer Pool 的关系
- 五、总结
InnoDB数据页结构

一、数据页基础概念
-
页大小:InnoDB默认页大小为16KB,是存储管理的基本单位。
-
页类型:包含索引页(数据页)、Undo页、系统页、Inode页、IBuf页等,本文聚焦 索引页(数据页) ,用于存储表记录。
-
FIL_PAGE_UNDO_LOG: Undo Log 页,用于存储事务回滚所需的信息。 -
FIL_PAGE_INODE: Inode 页,用于存储段(Segment)的元数据信息。 -
FIL_PAGE_IBUF: Insert Buffer 页,用于缓存对二级索引的插入操作。 -
FIL_PAGE_TYPE_ALLOCATED: 新分配但未使用的页。
-
二、数据页核心结构
数据页由7部分组成,按功能分为三大部分:
1. 头部控制区
- File Header(38字节)
-
功能:跨页管理,包含页号(
FIL_PAGE_OFFSET)、前后页指针(FIL_PAGE_PREV/NEXT)、页类型(FIL_PAGE_INDEX表示数据页)、LSN(FIL_PAGE_FILE_FLUSH_LSN)和校验和(FIL_PAGE_SPACE_OR_CHKSUM)。 -
字段详解:
-
FIL_PAGE_OFFSET: 页号,唯一标识一个页。 -
FIL_PAGE_PREV/NEXT: 前后页指针,形成双向链表,用于B+树的范围查询。 -
FIL_PAGE_TYPE: 页类型,标识页的用途。 -
FIL_PAGE_FILE_FLUSH_LSN: 页面最后一次刷新到磁盘时的LSN。 -
FIL_PAGE_SPACE_OR_CHKSUM: 页的校验和,使用CRC32算法计算,用于检测页的完整性。 -
应用:通过双向链表连接相邻页,支持B+树索引结构;校验和用于检测页完整性。
- Page Header(56字节)
-
功能:记录页内状态,如记录数(
PAGE_N_RECS)、空闲位置(PAGE_HEAP_TOP)、删除记录链表(PAGE_FREE)、索引层级(PAGE_LEVEL)、插入方向(PAGE_DIRECTION)、连续插入次数(PAGE_N_DIRECTION)和最后插入位置(PAGE_LAST_INSERT)。 -
字段详解:
-
PAGE_N_RECS: 页中记录的数量(不包括Infimum和Supremum)。 -
PAGE_HEAP_TOP: 指向堆中第一个可用空间的指针,也是新纪录插入位置的起点。 -
PAGE_FREE: 指向已删除记录组成的垃圾链表的头部。 -
PAGE_LEVEL: 当前页在B+树中的层级,0表示叶子节点。 -
PAGE_DIRECTION: 最近插入记录的方向(左/右)。 -
PAGE_N_DIRECTION: 最近连续往相同方向插入记录的次数。 -
PAGE_LAST_INSERT: 指向最后插入的记录。 -
应用:快速获取页填充状态,指导插入和空间重用,优化页分裂策略。
2. 数据存储区
- User Records & Free Space
-
动态分配:记录按行格式存储,新增记录从Free Space划分空间,用尽后申请新页。
-
行格式细节:InnoDB支持多种行格式 (
ROW_FORMAT),包括Compact、Redundant、Dynamic和Compressed。Compact是最常用的行格式,它具有更高的存储效率。 -
Compact 行格式结构:
-
Record Header (5 字节): 存储记录的元数据信息。
-
变长字段长度列表: 逆序存储变长字段的实际长度,每个长度占用1字节或2字节。
-
NULL值标志位: 如果记录中存在NULL值,则使用该标志位标识哪些字段为NULL。
-
实际数据: 存储记录的实际数据。
-
Record Header 详解:
-
delete_mask (1 bit): 标记记录是否被删除。 -
record_type (3 bits): 记录类型,0表示普通记录,1表示B+树非叶子节点记录,2表示Infimum记录,3表示Supremum记录。 -
next_record (16 bits): 指向下一条记录的偏移量,形成单向链表。 -
heap_no (13 bits): 记录在堆中的位置编号。 -
n_owned (4 bits): 页目录槽拥有的记录数。 -
min_rec_mask (1 bit): B+树的每个非叶子节点都必须包含两条记录,分别是最小记录和最大记录。通过设置min_rec_mask标记,保证非叶子节点中最小记录的min_rec_mask值为1。 -
Dynamic/Compressed 行格式: 当记录中的某些列(如TEXT或BLOB类型)的内容过大时,会使用
Dynamic或Compressed行格式,将这些列的数据存储在单独的溢出页中。Compressed行格式还会对数据进行压缩。 -
删除处理:
delete_mask标记删除记录加入垃圾链表(PAGE_FREE指向),空间可重用,减少碎片。 实际上被删除的记录仍然保存在页中,只是通过delete_mask标记为已删除,并且链入到垃圾链表中。 当有新的记录需要插入时,会优先使用这些被删除记录的空间。PAGE_GARBAGE统计已删除空间总量,辅助空间分配决策。 -
Free Space 管理: InnoDB 使用链表或者位图来管理 Free Space。 当需要分配空间时,会从 Free Space 链表中找到合适的空闲块进行分配。
- Infimum + Supremum(26字节)
-
虚拟记录:作为逻辑边界,Infimum为最小记录,Supremum为最大记录,初始化时即存在。
-
作用:简化范围查询,维护记录链表的起点和终点。
3. 尾部与目录区
- Page Directory(页目录)
-
槽(Slot)结构:将记录分组,每组最后一条记录(槽)保存地址偏移量,槽按主键排序。 每个槽指向组内最大记录的地址偏移量,通过这个偏移量可以找到组内的记录。
-
分组规则:初始组(Infimum)1条,最大记录组1-8条,其他组4-8条。插入触发动态分裂。
-
n_owned: 每个槽拥有n_owned个记录,这个值表示该槽指向的记录是其所在组的最后一条记录,且该槽拥有该组内的所有记录。 当插入一条新记录时,会找到与该记录主键值最接近的槽,然后将该槽的n_owned值加1。 如果n_owned值超过8,则会触发槽的分裂。 -
二分查找:通过槽快速定位记录,时间复杂度从O(n)降至O(log n)。
-
查找流程:
-
二分法确定目标槽。
-
遍历槽内记录(组内最多8条),避免全页扫描。
- File Trailer(8字节)
-
校验机制:包含页尾校验和与LSN(日志序列号),与File Header校验和对比,确保页写入完整性。
-
LSN (Log Sequence Number): LSN 是一个单调递增的数值,用于表示事务日志的写入顺序。 File Trailer 中存储的 LSN 表示该页最后一次被修改时的 LSN。 LSN 不仅用于崩溃恢复,还用于支持 MVCC (Multi-Version Concurrency Control)。
-
页尾校验和与页头的校验和用于确保数据页在写入磁盘时没有发生损坏。
三、关键机制详解
1. 记录链表与删除优化
-
单链表结构:记录按主键排序,通过
next_record串联,支持高效顺序访问。 -
删除优化:
delete_mask标记删除,空间暂不释放,链入垃圾链表供后续重用,避免频繁整理。 当有新记录插入时,优先使用垃圾链表中的空间。
2. 页目录与二分查找
-
槽管理:
-
每个槽指向组内最大记录,初始槽数为2(Infimum和Supremum)。
-
插入记录时,定位到差值最小的槽,增加
n_owned值,超过阈值则分裂组。 槽实际上存储的是组内最大的记录的地址偏移量,通过这个偏移量可以找到组内的记录。
-
-
查找流程:
-
二分法确定目标槽。
-
遍历槽内记录(组内最多8条),避免全页扫描。
-
3. 空间复用与碎片管理
-
Free Space重用:删除记录的空间优先分配给新插入,减少空间扩张。 InnoDB 使用链表或者位图来管理 Free Space。
-
PAGE_GARBAGE统计:跟踪已删除空间总量,辅助空间分配决策。
4. 数据页的合并与分裂
-
页分裂: 当一个数据页的空间被用完,需要插入新的记录时,就会发生页分裂。 页分裂会将当前页的数据复制到新的页中,并将当前页分成两个部分,分别指向新的页。
-
页合并: 当一个数据页中的数据被删除到一定程度,导致空间利用率过低时,就会发生页合并。 页合并会将相邻的两个页合并成一个页,从而提高空间利用率。
四、应用与性能影响
1. 索引效率
-
B+树结构:数据页作为叶子节点,通过File Header中的前后页指针形成双向链表,支持范围查询。
-
非叶子节点: B+树的非叶子节点存储的是索引键值和指向子节点的指针。 非叶子节点用于快速定位到叶子节点。
-
页目录加速:槽的二分查找大幅减少索引定位时间,尤其适合大范围扫描。
2. 插入优化
-
顺序插入:通过
PAGE_DIRECTION和PAGE_N_DIRECTION统计插入方向,优化页分裂策略。 -
紧凑存储:变长字段逆序存储(如NULL值列表),提升缓存命中率。
-
innodb_fill_factor** 参数:** 这个参数影响数据页的填充程度,从而影响空间利用率和查询性能。 较高的填充因子可以提高空间利用率,但可能会导致更频繁的页分裂。
3. 事务与恢复
-
LSN机制:File Trailer中的LSN与日志系统协作,确保崩溃恢复时页状态的正确性。 LSN 也用于支持 MVCC。
-
Redo Log: Redo Log 记录了数据页的变更操作,用于在崩溃恢复时重做这些操作,保证数据的一致性。
-
Undo日志:虽未展开,但数据页与Undo页协作支持事务回滚和多版本控制(MVCC)。 Undo Log 记录了数据页的旧版本数据,用于支持事务回滚和 MVCC。
4. 与 Buffer Pool 的关系
-
Buffer Pool 是 InnoDB 存储引擎用于缓存数据页的内存区域。 当需要访问某个数据页时,会先从 Buffer Pool 中查找,如果找到则直接使用,否则需要从磁盘读取到 Buffer Pool 中。
-
Buffer Pool 的大小直接影响数据库的性能。 较大的 Buffer Pool 可以缓存更多的数据页,从而减少磁盘 I/O。
五、总结
InnoDB数据页通过精细的结构设计,实现了高效存储管理、快速数据访问和强一致性保障:
-
存储管理:动态空间分配与碎片重用,平衡空间利用率与性能。
-
查询优化:页目录和有序链表结构,支持高效点查与范围扫描。
-
可靠性:校验和与LSN机制确保数据完整性,应对意外中断。
理解数据页结构对数据库调优(如合理选择行格式、监控页分裂、调整 innodb_fill_factor 参数)、故障排查(如空间碎片分析)和性能优化具有重要指导意义。
相关文章:
mysql之Innodb数据页
Innodb数据页结构 InnoDB数据页结构一、数据页基础概念二、数据页核心结构1. 头部控制区2. 数据存储区3. 尾部与目录区 三、关键机制详解1. 记录链表与删除优化2. 页目录与二分查找3. 空间复用与碎片管理4. 数据页的合并与分裂 四、应用与性能影响1. 索引效率2. 插入优化3. 事务…...

ThinkORM模型静态方法create好像对MongoDB不支持
软件版本 think-orm:3.0PHP:8.4.1MongoDB:8.0.4 (本地单数据 非集群)注:我是在 webman 框架下使用think-orm,并非在 thinkphp框架下使用 使用场景 定义的模型如下: <?php na…...

nginx配置:nginx.conf配置文件
nginx.conf配置文件说明 基本结构 全局块:位于最外层,定义影响整个Nginx服务器的设置。事件块:配置网络连接相关的设置。HTTP块:定义HTTP服务器以及反向代理、负载均衡等特性。Server块:定义虚拟主机,即响…...

基于 PyQt5 的聊天机器人程序(AI)
这是一个基于 PyQt5 的聊天机器人程序,通过 API 接入硅基流动(Silicon Flow)或其他的聊天服务,支持用户与聊天机器人进行交互。 API 设置:通过菜单栏的“设置”选项,用户可以修改 API 地址和 API 密钥。 设…...

[实现Rpc] 服务端 | RpcRouter实现 | Builder模式
目录 项目服务端独用类的实现 1. RpcRouter类的实现 ServiceDescribe SDescribeFactory ⭕ Builder模式 1. 动机 2. 模式定义 3. 要点总结 4. 代码感受 ServiceManager RpcRouter 4. 代码感受 ServiceManager RpcRouter 前文我们就将 Rpc 通用类都实现完啦&#…...

红外人体传感器选型和电路解析
红外人体传感器选型和电路解析 背景:想要制作一套IoT系统,基于HA构建上层管理,蓝牙和蓝牙MESH构建无线网络,以及多种传感器和控制器作为底层,其中人体红外传感器作为一个重要的选项,需要考虑好。 红外人体传…...

rtthread的串口框架、485框架
一、串口接收超时中断的实现。 1. rtthread中定义的串口超时结构体 定义串口接收超时的结构体 CM_TMR0_TypeDef 为TM0的实例(实际有CM_TMR0_1 CM_TMR0_2 对应华大460的两个TMR0单元 ) channel 每个timer0有两个通道(TMR0_CHA、TMR0_CHB) clock 为FCG2_PERIPH_TMR0_1、FCG…...

Embedding模型
检索的方式有那些 关键字搜索:通过用户输入的关键字来查找文本数据。 语义搜索:它的目标是理解用户查询的真实意图,不仅考虑关键词的匹配,还考虑词汇之间的语义 (文字,语音,语调...࿰…...

如何使用Spring Boot实现商品的管理系统
1. 项目初始化 1.1 使用 Spring Initializr 创建项目 访问 Spring Initializr,进行如下配置: Project:选择 Maven Project。Language:选择 Java。Spring Boot:选择合适的版本,如 3.1.x。Group:填写项目的组织名,例如 com.example。Artifact:填写项目名称,如 general…...

最新扣子(Coze)案例教程:全自动DeepSeek 写影评+批量生成 + 发布飞书,提效10 倍!手把手教学,完全免费教程
👨💻群里有同学是做影视赛道的博主,听说最近DeepSeek这么火,咨询能不能用DeepSeek写影评,并整理电影数据资料,自动发布到飞书文档,把每天的工作做成一个自动化的流程。 那今天斜杠君就为大家…...

Qt程序退出相关资源释放问题
目录 问题背景: aboutToQuit 代码举例 资源释放函数注意事项 closeEvent事件 代码举例 程序退出方式 quit() exit(int returnCode 0) close() 问题背景: 实际项目中程序退出前往往需要及进行一些资源释放、配置保存、线程中断等操作,…...
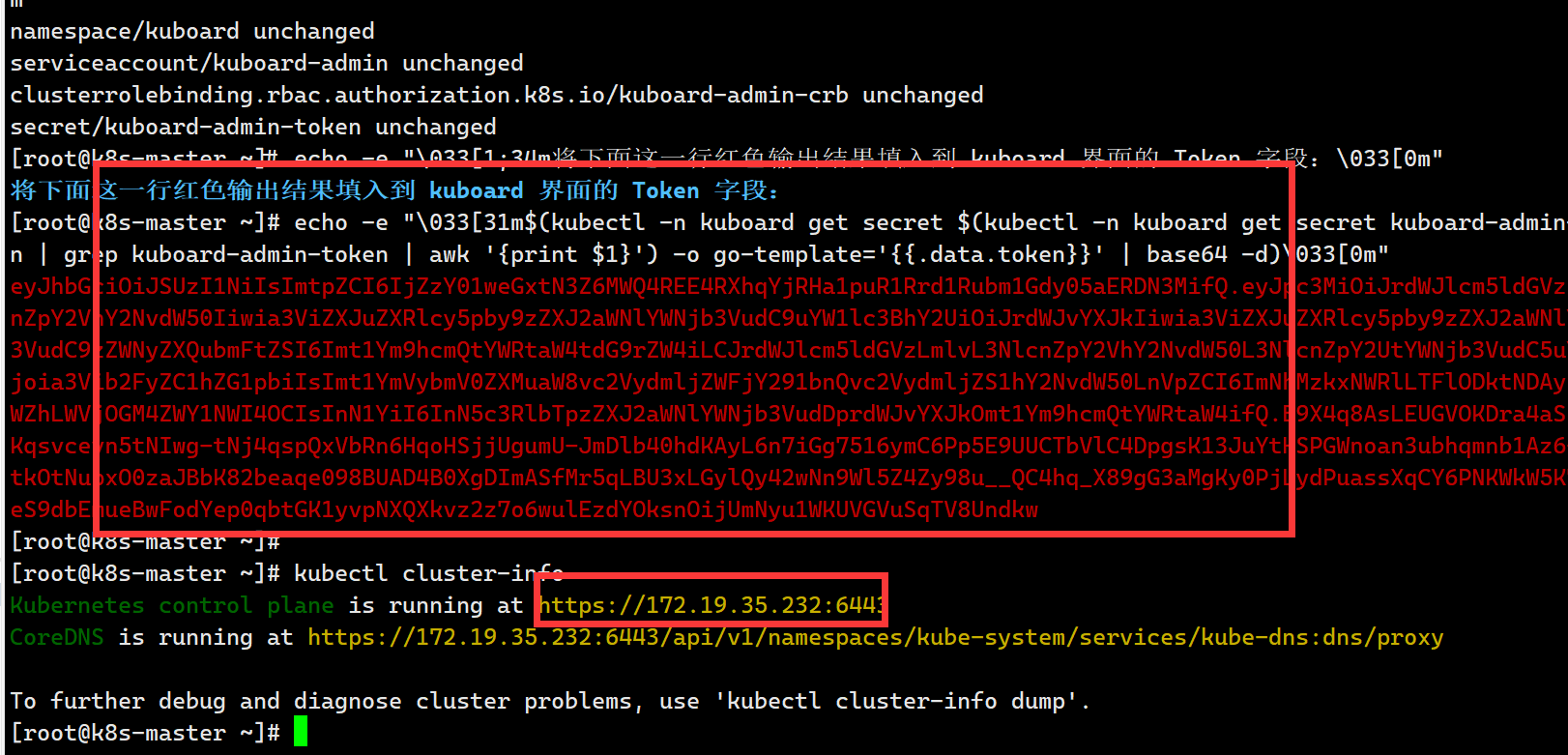
Ubuntu 22.04安装K8S集群
以下是Ubuntu 22.04安装Kubernetes集群的步骤概要 一、设置主机名与hosts解析 # Master节点执行 sudo hostnamectl set-hostname "k8smaster" # Worker节点执行 sudo hostnamectl set-hostname "k8sworker1"# 所有节点的/etc/hosts中添加: ca…...

Kubernetes的Ingress 资源是什么?
在Kubernetes中,Ingress资源是一种用于管理集群外部对内部服务访问的API对象,主要用于将不同的外部请求路由到集群内的不同服务,以下是关于它的详细介绍: 定义与作用 Ingress资源定义了从集群外部到内部服务的HTTP和HTTPS路由规…...

Apifox 增强 AI 接口调试功能:自动合并 SSE 响应、展示DeepSeek思考过程
在现代的API接口调试中,效率和精确性对于开发者和测试人员来说至关重要。Apifox,作为一款功能强大的API管理和调试工具,近年来不断提升其用户体验和智能化功能。最近,Apifox 推出了增强版的AI接口调试功能,其中包括自动…...
MATLAB基础学习相关知识
MATLAB安装参考:抖音-记录美好生活 MATLAB基础知识学习参考:【1小时Matlab速成教程-哔哩哔哩】 https://b23.tv/CnvHtO3 第1部分:变量定义和基本运算 生成矩阵: % 生成矩阵% 直接法% ,表示行 ;表示列 a [1,2,3;4,5,6;7,8,9];%…...

DeepSeek赋能智慧文旅:新一代解决方案,重构文旅发展的底层逻辑
DeepSeek作为一款前沿的人工智能大模型,凭借其强大的多模态理解、知识推理和内容生成能力,正在重构文旅产业的发展逻辑,推动行业从传统的经验驱动向数据驱动、从人力密集型向智能协同型转变。 一、智能服务重构:打造全域感知的智…...

蓝桥与力扣刷题(蓝桥 交换瓶子)
题目:有 N 个瓶子,编号 1 ~ N,放在架子上。 比如有 5 个瓶子: 2 1 3 5 4 要求每次拿起 2 个瓶子,交换它们的位置。 经过若干次后,使得瓶子的序号为: 1 2 3 4 5 对于这么简单的情况&#x…...

腿足机器人之十一- 深度强化学习
腿足机器人之十一- 深度强化学习 机器人能力腿足机器人RL问题建模强化学习解决方案 强化学习算法库选择建议 深度学习技术已经在语音、图像、视频、文本等领域应用广泛,其和强化学习的结合使得基于深度学习的大模型能力更是上升一个台阶。因而用在腿足机器人的运动中…...

纠错检索增广生成论文
一、摘要 动机:RAG严重依赖于检索文档的相关性,如果检索出错,那么LLM的输出结果也会出现问题 解决方案:提出纠正性检索增强生成(CRAG)即设计一个轻量级的检索评估器,用来评估针对某个查询检索…...

多源 BFS 算法详解:从原理到实现,高效解决多源最短路问题
多源 BFS 是一种解决 边权为 1 的多源最短路问题 的高效算法。其核心思想是将所有源点视为一个“超级源点”,通过一次 BFS 遍历即可计算所有节点到最近源点的最短距离。以下从原理、实现和代码示例三个方面深入讲解: 目录 一、原理分析 1. 单源 BFS vs…...

Jenkins 构建 Unity 打包 .apk 同时生成 .aab
Jenkins 构建 Unity 打包 .apk 同时生成 .aab Android App Bundle简称 AAB,想了解更多关于 AAB 的知识,请看官网 https://developer.android.google.cn/guide/app-bundle/faq?hlzh-cn APK 打包部分在复用上一篇 Jenkins 构建 Unity打包APK 一、新建一…...

LTO优化详解
嵌入式开发过程中的LTO优化是什么意思?能够用来解决什么问题?它都优化了哪些?仅开启LTO真的可以优化SIZE的问题吗? 请分别回答我刚才提到的问题? 嗯,用户问关于嵌入式开发中的LTO优化,我需要详细解释这个概…...

嵌入式之条件编译
在C编程中,条件编译是一种在编译时根据特定条件选择性地包含或排除代码的技术。它通过预处理器指令来实现,允许程序员根据不同的编译环境、平台或配置来控制哪些代码被编译。条件编译在跨平台开发、调试、功能开关场景中非常有用。 1. 预处理器指令 条…...

清华大学第五弹:《DeepSeek与AI幻觉》
作者:清华大学新闻与传播学院新媒体研究中心、人工智能学院(新媒沈阳团队) 时间:2025年2月 完整版下载地址:夸克网盘分享 一、AI幻觉的定义与分类 定义 学术定义:模型生成与事实不符、逻辑断裂或脱离上下…...

理解构件的3种分类方法
对于Java程序员来说,理解“构件分类方法”是非常重要的,因为这直接关系到如何高效地管理和复用软件组件。以下是针对三种常见分类方法的具体解释: 构件的3种分类方法 1. 关键字分类法 (Keyword Classification Method) 关键字分类法是最直…...

分布式数据库解析
title: 分布式数据库解析 date: 2025/2/20 updated: 2025/2/20 author: cmdragon excerpt: 通过金融交易、社交平台、物联网等9大真实场景,结合Google Spanner跨洲事务、DynamoDB毫秒级扩展等38个生产级案例,揭示分布式数据库的核心原理与工程实践。内容涵盖CAP定理的动态…...

Zotero 快速参考文献导出(特定期刊引用)
目录 一、添加样式 每次投期刊时每种期刊的引用方式不一样,就很麻烦。发现zeotero添加期刊模板再导入很方便 一、添加样式 然后就能导出自己想要的期刊格式的引用了...

库的制作与原理(一)
1.库的概念 库是写好的,现成的可以复用的代码。本质上库是一种可执行的二进制形式,可以被操作系统载入内存执行。库有俩种:静态库 .a[Linux] .lib[windows] 动态库 .so[Linux] .dll[windows] 就是把.c文件变成.o文件,把…...

go 日志框架
内置log import ("log""os" )func main() {// 设置loglog.SetFlags(log.Llongfile | log.Lmicroseconds | log.Ldate)// 自定义日志前缀log.SetPrefix("[pprof]")log.Println("main ..")// 如果用format就用PrintF,而不是…...

JavaScript 最佳实践
我只选取了我还没完全贯彻的条目罗列如下. 1.函数命名 函数名由动词开头,如getName(); 2.布尔类型命名 若函数返回布尔值,则函数名以is/can等开头. 3.常量命名约定 常量名全大写并以下划线""连接. 4.变量类型透明化 定义变量时,应将其立即初使化为一个与其同类型…...