Python简单使用MinerU
Python简单使用MinerU
1 简介
MinerU是国产的一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。目前支持图像(.jpg及.png)、PDF、Word(.doc及.docx)、以及PowerPoint(.ppt及.pptx)等。
# 官网地址
https://mineru.readthedocs.io/en/latest/index.html# Github地址
https://github.com/opendatalab/mineru# API接口地址
https://mineru.readthedocs.io/en/latest/user_guide/quick_start/convert_pdf.html# 模型下载脚本地址
# 从ModelScope下载模型:download_models.py
# 从HuggingFace下载模型: download_models_hf.py
https://github.com/opendatalab/MinerU/tree/master/scripts
2 安装MinerU
安装Python环境
# 我的版本是:magic-pdf==1.1.0
pip install -U "magic-pdf[full]" -i https://pypi.tuna.tsinghua.edu.cn/simple
下载权重
官网提供了HuggingFace和ModelScope两种方法下载,本文从ModlScope上下载,
# 官网下载方法地址
https://github.com/opendatalab/MinerU/blob/master/docs/how_to_download_models_zh_cn.md
开始下载权重
⚠️ 注意:模型下载完成后,脚本会自动生成用户目录下的magic-pdf.json文件,并自动配置默认模型路径。 您可在【用户目录】下找到magic-pdf.json文件。
# 安装modelscope
pip install modelscope# 下载文件
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py -O download_models.py
# 也可以到下面的地址,找到download_models.py下载
https://github.com/opendatalab/MinerU/tree/master/scripts# 执行下载模型
# 为了方便使用模型,我修改了download_models.py,添加了设置模型的位置。
python download_models.py
修改后的download_models.py
⚠️ 此步可以不做。
文件中的local_dir是我新加的下载模型的位置,如果不设置会下载到下面目录中:windows的用户目录为 “C:\Users\用户名”, linux用户目录为 “/home/用户名”。
import json
import osimport requests
from modelscope import snapshot_downloaddef download_json(url):# 下载JSON文件response = requests.get(url)response.raise_for_status() # 检查请求是否成功return response.json()def download_and_modify_json(url, local_filename, modifications):if os.path.exists(local_filename):data = json.load(open(local_filename))config_version = data.get('config_version', '0.0.0')if config_version < '1.1.1':data = download_json(url)else:data = download_json(url)# 修改内容for key, value in modifications.items():data[key] = value# 保存修改后的内容with open(local_filename, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)if __name__ == '__main__':mineru_patterns = ["models/Layout/LayoutLMv3/*","models/Layout/YOLO/*","models/MFD/YOLO/*","models/MFR/unimernet_small_2501/*","models/TabRec/TableMaster/*","models/TabRec/StructEqTable/*",]# 设置模型下载的位置local_dir="E:/mineru"# 下载模型model_dir = snapshot_download('opendatalab/PDF-Extract-Kit-1.0', allow_patterns=mineru_patterns, local_dir=local_dir)layoutreader_model_dir = snapshot_download('ppaanngggg/layoutreader', local_dir=local_dir)model_dir = model_dir + '/models'print(f'model_dir is: {model_dir}')print(f'layoutreader_model_dir is: {layoutreader_model_dir}')json_url = 'https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/magic-pdf.template.json'config_file_name = 'magic-pdf.json'home_dir = os.path.expanduser('~')config_file = os.path.join(home_dir, config_file_name)json_mods = {'models-dir': model_dir,'layoutreader-model-dir': layoutreader_model_dir,}download_and_modify_json(json_url, config_file, json_mods)print(f'The configuration file has been configured successfully, the path is: {config_file}')
3 Python使用MinerU
Python安装完MinerU后,可以直接执行下面的代码,首次执行时会自动下载PaddleOCR模型的权重和参数,PaddleOCR模型会自动下载到用户目录下的.paddleocr目录下。
解析PDF文件的Python代码如下:
import osfrom magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod# pdf文件路径
pdf_file_path = "E:/hello/test-5-2.pdf"
# 获取没有后缀的pdf文件名称
pdf_file_path_without_suff = pdf_file_path.split(".")[0]
print(pdf_file_path_without_suff)# 文件所在的目录
pdf_file_path_parent_dir = os.path.dirname(pdf_file_path)
image_dir = os.path.join(pdf_file_path_parent_dir, "images")
print(image_dir)# Markdown的写入实例
# markdown_dir = "./output/markdown"
# writer_markdown = FileBasedDataWriter(markdown_dir)
writer_markdown = FileBasedDataWriter()
# 读取图片
writer_image = FileBasedDataWriter(image_dir)# 读取文件流
reader_pdf = FileBasedDataReader("")
bytes_pdf = reader_pdf.read(pdf_file_path)# 处理数据
dataset_pdf = PymuDocDataset(bytes_pdf)# 判断是否支持ocr
if dataset_pdf.classify() == SupportedPdfParseMethod.OCR:# 支持OCRinfer_result = dataset_pdf.apply(doc_analyze, ocr=True)pipe_result = infer_result.pipe_ocr_mode(writer_image)
else:# 不支持OCRinfer_result = dataset_pdf.apply(doc_analyze, ocr=False)pipe_result = infer_result.pipe_txt_mode(writer_image)# 在每一页上都使用模型解析文本
infer_result.draw_model(pdf_file_path)# 获取模型处理后的结果
model_inference_result = infer_result.get_infer_res()
print(model_inference_result)# 为pdf生成含有颜色标注布局的pdf文件
pipe_result.draw_layout(f"{pdf_file_path_without_suff}_layout.pdf")# 为pdf生成含有颜色标注文本行的pdf文件
pipe_result.draw_span(f"{pdf_file_path_without_suff}_spans.pdf")# 获取markdown的内容
markdown_content = pipe_result.get_markdown(image_dir)
print(markdown_content)# 保存markdown文件
# pipe_result.dump_md(writer_markdown, f"{pdf_file_path_without_suff}.md", image_dir)
pipe_result.dump_md(writer_markdown, f"{pdf_file_path_without_suff}.md", image_dir)# json文本列表
# 数据类型包括type、text、text_level、page_idx、img_path等
content_list_content = pipe_result.get_content_list(image_dir)
print(content_list_content)# 保存json文本列表
pipe_result.dump_content_list(writer_markdown, f"{pdf_file_path_without_suff}_content_list.json", image_dir)# 获取含有位置信息的json文本
middle_json_content = pipe_result.get_middle_json()# 保存含有位置信息的json文本
pipe_result.dump_middle_json(writer_markdown, f'{pdf_file_path_without_suff}_middle.json')
相关文章:

Python简单使用MinerU
Python简单使用MinerU 1 简介 MinerU是国产的一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。目前支持图像(.jpg及.png)、PDF、Word(.doc及.docx)、以及P…...

使用AI创建流程图和图表的 3 种简单方法
你可能已经尝试过使用 LLMs 生成图像,但你有没有想过用它们来创建 流程图和图表?这些可视化工具对于展示流程、工作流和系统架构至关重要。 通常,在在线工具上手动绘制图表可能会耗费大量时间。但你知道吗?你可以使用 LLMs 通过简…...

ImportError: cannot import name ‘FixtureDef‘ from ‘pytest‘
错误信息表明 pytest 在尝试导入 FixtureDef 时出现了问题。通常是由于 pytest 版本不兼容 或 插件版本冲突 引起的。以下是详细的排查步骤和解决方案: 1. 检查 pytest 版本 首先,确认当前安装的 pytest 版本。某些插件可能需要特定版本的 pytest 才能…...

机器学习实战(7):聚类算法——发现数据中的隐藏模式
第7集:聚类算法——发现数据中的隐藏模式 在机器学习中,聚类(Clustering) 是一种无监督学习方法,用于发现数据中的隐藏模式或分组。与分类任务不同,聚类不需要标签,而是根据数据的相似性将其划…...

z-score算法
z-score算法原理参考网址 https://blog.csdn.net/m0_59596937/article/details/128378641 具体实现代码如下: import numpy as npclass ZScoreOutlierDetector:def __init__(self, threshold3):"""构造函数"""self.threshold thre…...

企业级RAG开源项目分享:Quivr、MaxKB、Dify、FastGPT、RagFlow
企业级 RAG GitHub 开源项目深度分享:Quivr、MaxKB、Dify、FastGPT、RagFlow 及私有化 LLM 部署建议 随着生成式 AI 技术的成熟,检索增强生成(RAG)已成为企业构建智能应用的关键技术。RAG 技术能够有效地将大型语言模型ÿ…...

open webui 部署 以及解决,首屏加载缓慢,nginx反向代理访问404,WebSocket后端服务器链接失败等问题
项目地址:GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 选择了docker部署 如果 Ollama 在您的计算机上,请使用以下命令 docker run -d -p 3000:8080 --add-hosthost.docker.internal:host-gatewa…...

C++ 智能指针 unique_ptr shared_ptr weak_ptr小练习
智能指针是 C11 引入的一项重要特性,它可以帮助我们管理动态分配的内存,自动释放内存,避免内存泄漏和悬空指针的问题。智能指针有三种常用类型:std::unique_ptr、std::shared_ptr 和 std::weak_ptr。 为了帮助你熟悉智能指针的使…...
网络工具介绍)
Netstat(Network Statistics)网络工具介绍
Netstat 工具详细介绍及常见指令应用 Netstat(Network Statistics)是一个常用的命令行工具,用于显示网络连接、路由表、接口统计信息、伪装连接等信息。它可以帮助用户监控计算机的网络状态,尤其在诊断网络问题时非常有用。Netst…...

内容中台架构下智能推荐系统的算法优化与分发策略
内容概要 在数字化内容生态中,智能推荐系统作为内容中台的核心引擎,承担着用户需求与内容资源精准匹配的关键任务。其算法架构的优化路径围绕动态特征建模与多模态数据融合展开,通过深度强化学习技术实现用户行为特征的实时捕捉与动态更新&a…...

React 高阶组件的优缺点
React 高阶组件的优缺点 优点 1. 代码复用性高 公共逻辑封装:当多个组件需要实现相同的功能或逻辑时,高阶组件可以将这些逻辑封装起来,避免代码重复。例如,多个组件都需要在挂载时进行数据获取操作,就可以创建一个数…...

最新版IDEA下载安装教程
一、下载IDEA 点击前往官网下载 或者去网盘下载 点击前往百度网盘下载 点击前往夸克网盘下载 进去后点击IDEA 然后点击Download 选择自己电脑对应的系统 点击下载 等待下载即可 二、安装IDEA 下载好后双击应用程序 点击下一步 选择好安装目录后点击下一步 勾选这两项后点击…...

DeepSeek最新开源动态:核心技术公布
2月21日午间,DeepSeek在社交平台X发文称,从下周开始,他们将开源5个代码库,以完全透明的方式与全球开发者社区分享他们的研究进展。并将这一计划定义为“Open Source Week”。 DeepSeek表示,即将开源的代码库是他们在线…...

《炒股养家心法.pdf》 kimi总结
《炒股养家心法.pdf》这篇文章详细阐述了一位超级游资炒股养家的心得与技巧,展示了其从40万到10亿的股市传奇。以下是文章中炒股技巧和心得的详细总结: 1.核心理念 市场情绪的理解:炒股养家强调,股市的本质是群体博弈,…...

运维脚本——8.证书自动化管理
场景:自动化SSL/TLS证书的申请、续期和部署,避免证书过期导致服务中断。 示例:使用Shell脚本配合Lets Encrypt的Certbot工具自动续期证书。 #!/bin/bash # 自动续期Lets Encrypt证书并重启服务 certbot renew --quiet --post-hook "syst…...

RDMA ibverbs_API功能说明
设备管理 获取当前活动网卡 返回当前rdma设备列表 struct ibv_device **ibv_get_device_list(int *num_devices);//使用 struct ibv_device **dev_list ibv_get_device_list(NULL);获取网卡名 返回网卡名字字符串:如"mlx5_0",一般通过网卡…...

第15届 蓝桥杯 C++编程青少组中/高级选拔赛 202401 真题答案及解析
第 1 题 【 单选题 】 表达式117 % 16 的结果是( )。 A:0 B:5 C:7 D:10 解析: % 是取模运算符,用于计算两个数相除后的余数。 计算 117 / 16,结果是 7,余数是 5。因此,117 % 16 = 5。答案: B 第 2 题 【 单选题 】 下列选项中,字符数组定义正确的是( …...

【R语言】绘图
一、散点图 散点图也叫X-Y图,它将所有的数据以点的形式展现在坐标系上,用来显示变量之间的相互影响程度。 ggplot2包中用来绘制散点图的函数是geom_point(),但在绘制前需要先用ggplot()函数指定数据集和变量。 下面用mtcars数据集做演示&a…...
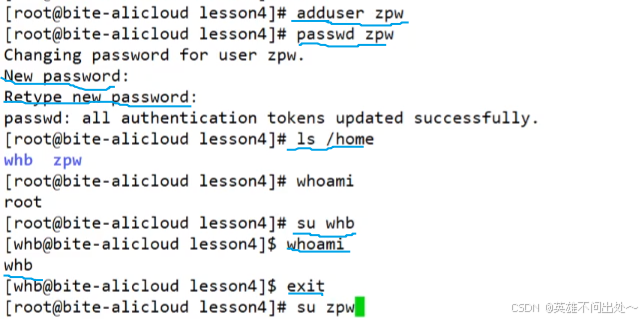
Linux基本指令(三)+ 权限
文章目录 基本指令grep打包和压缩zip/unzipLinux和windows压缩包互传tar(重要)Linux和Linux压缩包互传 bcuname -r常用的热键关机外壳程序 知识点打包和压缩 Linux中的权限用户权限 基本指令 grep 1. grep可以过滤文本行 done用于标记循环的结束&#x…...

容器化部署tomcat
容器化部署tomcat 需求在docker容器中部署tomcat,并通过外部机器访问tomcat部署的项目 容器化部署要先装好docker容器(docker安装配置) 实现步骤: 拉取tomcat docker pull tomcat用于列出本地Docker主机上存储的所有镜像 docker images在root目录里面创建tomc…...
vscode软件中引入vant组件
一、vant简介 Vant 是一个轻量、可靠的移动端组件库,于 2017 年开源。 目前 Vant 官方提供了 Vue 2 版本、Vue 3 版本和微信小程序版本,并由社区团队维护 React 版本和支付宝小程序版本。 官网:介绍 - Vant Weapp 里面的快速上手的教程&a…...

DeepSeek vs ChatGPT:AI 领域的华山论剑,谁主沉浮?
一、引言 在当今科技飞速发展的时代,人工智能(AI)已然成为推动各领域变革的核心力量。而在人工智能的众多分支中,自然语言处理(NLP)因其与人类日常交流和信息处理的紧密联系,成为了最受瞩目的领…...

Ubuntu 22.04 Install deepseek
前言 deepseekAI助手。它具有聊天机器人功能,可以与用户进行自然语言交互,回答问题、提供建议和帮助解决问题。DeepSeek 的特点包括: 强大的语言理解能力:能够理解和生成自然语言,与用户进行流畅的对话。多领域知识&…...

如何将公钥正确添加到服务器的 authorized_keys 文件中以实现免密码 SSH 登录
1. 下载密钥文件 2. RSA 解析 将 id_ed25519 类型的私钥转换为 RSA 类型,要将 ED25519 私钥转换为 RSA 私钥,需要重新生成一个新的 RSA 密钥对。 步骤: 生成新的 RSA 密钥对 使用 ssh-keygen 来生成一个新的 RSA 密钥对。比如,执…...

深入理解设计模式之解释器模式
深入理解设计模式之解释器模式 在软件开发的复杂世界中,我们常常会遇到需要处理特定领域语言的情况。比如在开发一个计算器程序时,需要解析和计算数学表达式;在实现正则表达式功能时,要解析用户输入的正则表达式来匹配文本。这些场景都涉及到对特定语言的解释和执行,而解…...

【WebGL】attribute方式实例化绘制
背景 一般有attribute和uniform两种方式进行实例化绘制 attribute方式实例化 这里需要注意 bufferData和bufferSubData方式的用法顺序和参数 gl.bufferData(target, sizeOrData, usage); sizeOrData(实例化配合bufferSubData 更新数据一般使用这种先)…...
)
线代[8]|北大丘维声教授《怎样学习线性代数?》(红色字体为博主注释)
文章目录 说明一、线性代数的内容简介二、学习线性代数的用处三、线性代数的特点四、学习线性代数的方法五、更新时间记录 说明 文章中红色字体为博主敲录完丘教授这篇文章后所加,刷到这篇文章的读者在首次阅读应当跳过红色字体,先通读一读文章全文&…...

光明谷推出AT指令版本的蓝牙音箱SOC 开启便捷智能音频开发新体验
前言 在蓝牙音箱市场竞争日益激烈的当下,开发一款性能卓越且易于上手的蓝牙音箱,成为众多厂商追求的目标。而光明谷科技有限公司推出的 AT 指令版本的蓝牙音箱 SOC,无疑为行业带来了全新的解决方案,以其诸多独特卖点,迅…...
—如何防止winform程序被同时打开多次)
C#从入门到精通(34)—如何防止winform程序被同时打开多次
前言: 大家好,我是上位机马工,硕士毕业4年年入40万,目前在一家自动化公司担任软件经理,从事C#上位机软件开发8年以上!我们在开发上位机软件的过程中,评判一个人软件写的好不好,有一…...

TIP: Flex-DLD
Article: Flex-DLD: Deep Low-Rank Decomposition Model With Flexible Priors for Hyperspectral Image Denoising and Restoration, 2024 TIP. 文章的主要思想是用network来学low-rank decomposition的两个matrix(input是random input). 文章的framew…...