【知识】PyTorch中不同优化器的特点和使用
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
1. SGD(随机梯度下降)
2. Adam(自适应矩估计)
3. AdamW
4. Adagrad
5. Adadelta
6. Adafactor
7. SparseAdam
8. Adamax
9. LBFGS
10. RMSprop
11. Rprop(弹性反向传播)
12. ASGD(平均随机梯度下降)
13. NAdam(Nesterov 加速自适应矩估计)
14. RAdam(修正 Adam)
15. Adafactor(自适应因子化梯度)
16. AMSGrad
性能考虑
总结
torch.optim — PyTorch 2.6 documentation
1. SGD(随机梯度下降)
-
用途:适用于小型到中型模型的基本优化。
-
特点:
-
通过负梯度方向更新参数。
-
可以包含动量(momentum)以加速学习并减少震荡。
-
简单且广泛使用,但需要仔细调整学习率。
-
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的模型
model = nn.Linear(10, 1) # 一个线性模型
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-4)# 训练循环
for input, target in dataloader:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()2. Adam(自适应矩估计)
-
用途:深度学习模型,尤其是需要 L2 正则化时。
-
特点:
-
根据一阶和二阶矩估计为每个参数计算自适应学习率。
-
支持学习率衰减的无偏估计。
-
通常在适当设置下比 SGD 收敛更快。
-
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.0, amsgrad=False)3. AdamW
-
用途:迁移学习、视觉任务,以及权重衰减关键的场景。
-
特点:
-
将权重衰减与梯度解耦,使其更有效。
-
在某些场景下性能超过 Adam 和 SGD。
-
optimizer = optim.AdamW(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01)4. Adagrad
-
用途:处理稀疏数据,例如自然语言处理或图像识别。
-
特点:
-
累积之前的平方梯度以调整学习率。
-
随着训练的进行,学习率单调递减,有助于收敛。
-
optimizer = optim.Adagrad(model.parameters(), lr=0.01, lr_decay=0.0, weight_decay=0.0, initial_accumulator_value=0.0, eps=1e-10)5. Adadelta
-
用途:文本数据处理和图像分类。
-
特点:
-
通过使用窗口和解决 Adagrad 的学习率递减问题。
-
维护平方梯度和平方参数更新的运行平均值。
-
optimizer = optim.Adadelta(model.parameters(), lr=1.0, rho=0.9, eps=1e-06, weight_decay=0.0)6. Adafactor
-
用途:大规模模型、大批量或长序列(例如深度学习在网页文本语料库上的应用)。
-
特点:
-
通过使用近似值替换二阶矩来减少计算开销。
-
专为非常大的模型设计,不会增加训练时间。
-
optimizer = optim.Adafactor(model.parameters(), lr=0.05, eps=(1e-30, 1e-3), clip_threshold=1.0, decay_rate=-0.8, beta1=None, weight_decay=0.0, scale_parameter=True, relative_step=True, warmup_init=False)7. SparseAdam
-
用途:具有稀疏梯度数据的模型,例如 NLP 中的嵌入层。
-
特点:
-
优化稀疏张量更新;结合 SparseAdam 用于密集张量和 Adagrad 用于稀疏更新。
-
专为具有许多零值的参数设计。
-
optimizer = optim.SparseAdam(model.sparse_parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08)8. Adamax
-
用途:类似于 Adam,但基于无穷范数,某些问题上更稳定。
-
特点:
-
使用过去梯度的最大值而不是平均值。
-
optimizer = optim.Adamax(model.parameters(), lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.0)9. LBFGS
-
用途:无约束优化问题、回归以及需要二阶信息的问题。
-
特点:
-
使用梯度评估近似海森矩阵的拟牛顿方法。
-
比 SGD 或 Adam 需要更多内存和计算资源。
-
optimizer = optim.LBFGS(model.parameters(), lr=1.0, max_iter=20, max_eval=None, tolerance_grad=1e-07, tolerance_change=1e-09, history_size=100, line_search_fn=None)# 使用 LBFGS 需要提供一个闭包(closure)来重新评价模型
def closure():optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()return lossoptimizer.step(closure)10. RMSprop
-
用途:卷积神经网络和递归神经网络。
-
特点:
-
维护平方梯度的运行平均值,并对参数更新进行归一化。
-
解决 Adagrad 学习率单调递减的问题。
-
optimizer = optim.RMSprop(model.parameters(), lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0.0, momentum=0.0, centered=False)11. Rprop(弹性反向传播)
-
用途:神经网络中梯度大小不重要的场景。
-
特点:
-
仅使用梯度的符号来更新参数,根据梯度符号变化调整学习率。
-
optimizer = optim.Rprop(model.parameters(), lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50.0))12. ASGD(平均随机梯度下降)
-
用途:促进某些模型的泛化。
-
特点:
-
维护优化过程中遇到的参数的运行平均值。
-
optimizer = optim.ASGD(model.parameters(), lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0.0)13. NAdam(Nesterov 加速自适应矩估计)
-
用途:结合 Nesterov 动量和 Adam。
-
特点:
-
结合 Nesterov 加速梯度(NAG)以提供更稳定的收敛。
-
optimizer = optim.NAdam(model.parameters(), lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.0, momentum_decay=0.004)14. RAdam(修正 Adam)
-
用途:需要自适应学习率但希望减少方差的场景。
-
特点:
-
根据梯度方差动态调整学习率。
-
optimizer = optim.RAdam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.0)15. Adafactor(自适应因子化梯度)
-
用途:大规模模型的内存高效优化。
-
特点:
-
通过将大梯度分解为小成分来减少内存使用。
-
optimizer = optim.Adafactor(model.parameters(), lr=0.3, eps=(1e-30, 1e-3), clip_threshold=1.0, decay_rate=-0.8, beta1=None, weight_decay=0.0, scale_parameter=True, relative_step=True, warmup_init=False)16. AMSGrad
- 用途: Adam 优化器的一种改进版本,旨在解决 Adam 在某些情况下可能不收敛的问题。它通过保留梯度的历史信息来防止学习率过早下降,从而提高训练的稳定性和收敛性。
- 特点
-
自适应学习率:AMSGrad 自适应地调整学习率,以便更好地训练神经网络。
-
防止震荡:它可以防止 Adam 算法中的震荡现象,从而提高训练效果。
-
改进收敛性:通过优化二阶动量,避免了 Adam 算法可能遭遇的收敛问题,特别适合长时间训练或解决深层网络难题。
-
# 初始化 AMSGrad 优化器,通过amsgrad参数设置
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=True)性能考虑
-
这些优化器的性能可能因硬件和问题的性质而异。PyTorch 将优化器分为以下几类:
-
For-loop:基本实现,但由于内核调用较慢。
-
Foreach:使用多张量操作以加快处理速度。
-
Fused:将步骤合并为单个内核以实现最大速度。
-
总结
-
选择优化器取决于问题的复杂性、数据的稀疏性和硬件的可用性。像 Adam 或 AdamW 这样的自适应算法因其通用有效性而被广泛使用,而像 SGD 这样的简单方法在适当调整超参数时是最优的。
相关文章:

【知识】PyTorch中不同优化器的特点和使用
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 1. SGD(随机梯度下降) 2. Adam(自适应矩估计) 3. AdamW 4. Adagrad 5. Adadelta 6. Adafact…...

ubuntu windows双系统踩坑
我有个台式机,先安装的ubuntu,本来想专门用来做开发,后面儿子长大了,给他看了一下星际争霸、魔兽争霸,立马就迷上了。还有一台windows的笔记本,想着可以和他联局域网一起玩,在ubuntu上用wine跑魔…...

AI智算-k8s+SGLang实战:DeepSeek-r1:671b满血版多机多卡私有化部署全攻略
k8sSGLang实战:DeepSeek-r1:671b满血版多机多卡私有化部署全攻略 前言环境准备1. 模型下载2.软硬件环境介绍 正式部署1. 部署LWS API2. 通过 LWS 部署DeepSeek-r1模型3. 查看显存占用情况4. 服务对外暴露5. 测试部署效果5.1 通过 curl5.2 通过 OpenWebUIa. 部署 Ope…...

zlib编译https://www.cnblogs.com/MrOuqs/p/5751485.html
vs2015零基础编译zlib从失败到成功 vs2015零基础编译zlib从失败到成功_zlib vs2015-CSDN博客 c如何将文件夹打包成zip...

【蓝桥杯单片机】第十三届省赛第二场
一、真题 二、模块构建 1.编写初始化函数(init.c) void Cls_Peripheral(void); 关闭led led对应的锁存器由Y4C控制关闭蜂鸣器和继电器 2.编写LED函数(led.c) void Led_Disp(unsigned char ucLed); 将ucLed取反的值赋给P0 开启锁存器 关闭锁存…...

【安装及调试旧版Chrome + 多版本环境测试全攻略】
👨💻 安装及调试旧版Chrome 多版本环境测试全攻略 🌐 (新手友好版 | 覆盖安装/运行/调试全流程) 🕰️ 【背景篇】为什么我们需要旧版浏览器测试? 🌍 🌐 浏览器世界的“…...

从零开始玩转TensorFlow:小明的机器学习故事 5
图像识别的挑战 1 故事引入:小明的“图像识别”大赛 小明从学校里听说了一个有趣的比赛:“美食图像识别”。参赛者需要训练计算机,看一张食物照片(例如披萨、苹果、汉堡等),就能猜出这是什么食物。听起来…...

sql的索引与性能优化相关
之前面试的时候,由于在简历上提到优化sql代码,老是会被问到sql索引和性能优化问题,用这个帖子学习记录一下。 1.为什么要用索引 ------------------------------------------------------------------------------------------------------…...

Snapshot Compressed Imaging:打破传统成像的新视界
在我们的日常生活中,拍照、拍视频已经成为记录生活的常规操作。无论是用手机捕捉美丽的风景,还是用相机拍摄珍贵的瞬间,传统的成像方式似乎已经满足了我们大部分的需求。但你是否想过,在某些特殊的场景下,传统成像技术可能会遇到一些难题,而一种名为 Snapshot Compressed…...

git 命令 设置别名
在 Git 中,你可以通过配置别名来简化常用的命令。这样,你可以使用更短或更易记的命令来完成相同的操作。要设置 Git 命令的别名,你可以使用 git config 命令。 全局设置 如果你想为所有 Git 仓库设置别名,可以使用 --global 选项…...

在Spark中如何配置Executor内存以优化性能
在Spark中,配置Executor内存以优化性能是一个关键步骤。以下是一些具体的配置方法和建议: 一、Executor内存配置参数 在Spark中,Executor的内存配置主要通过以下几个参数进行: --executor-memory 或 spark.executor.memory&…...

Go语言--语法基础2--下载安装
2、下载安装 1、下载源码包: go1.18.4.linux-amd64.tar.gz。 官方地址:https://golang.google.cn/dl/ 云盘地址:链接: https://pan.baidu.com/s/1N2jrRHaPibvmmNFep3VYag 提 取码: zkc3 2、将下载的源码包解压…...
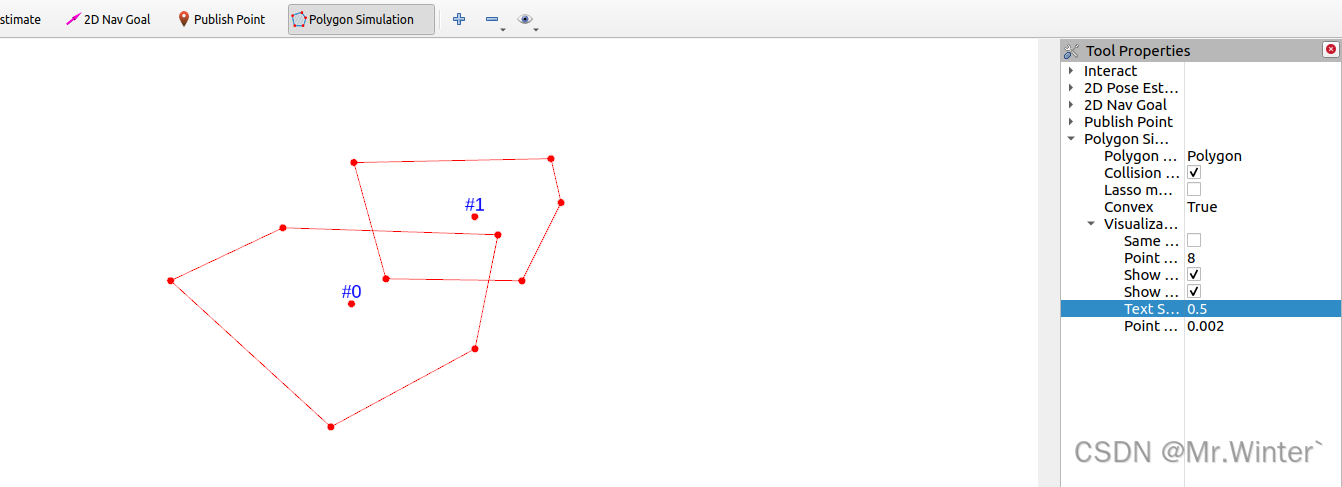
碰撞检测 | 图解凸多边形分离轴定理(附ROS C++可视化)
目录 0 专栏介绍1 凸多边形碰撞检测2 多边形判凸算法3 分离轴定理(SAT)4 算法仿真与可视化4.1 核心算法4.2 仿真实验 0 专栏介绍 🔥课设、毕设、创新竞赛必备!🔥本专栏涉及更高阶的运动规划算法轨迹优化实战,包括:曲线…...

计算机网络真题练习(高软29)
系列文章目录 计算机网络阶段练习 文章目录 系列文章目录前言一、真题练习总结 前言 计算机网络的阶段练习题,带解析答案。 一、真题练习 总结 就是高软笔记,大佬请略过!...

DPVS-1:编译安装DPVS (ubuntu22.04)
操作系统 rootubuntu22:~# lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 22.04.3 LTS Release: 22.04 Codename: jammy rootubuntu22:~# 前置软件准备 apt install git apt install meson apt install gcc ap…...

将 SELinux 永久设置为 Permissive
要将 SELinux 永久设置为 Permissive 模式,可以按照以下步骤操作: 1. 检查当前 SELinux 状态 首先,确认当前 SELinux 的状态: sestatus输出示例: SELinux status: enabled SELinuxfs mount: …...

EasyRTC:全平台支持与自研算法驱动的智能音视频通讯解决方案
在智能硬件的浪潮中,设备之间的互联互通已成为提升用户体验的核心需求。无论是智能家居、智能办公,还是工业物联网,高效的音视频通讯和交互能力是实现智能化的关键。然而,传统音视频解决方案往往面临平台兼容性差、交互体验不佳以…...

Elasticsearch 自动补全搜索 - autocomplete
作者:来自 Elastic Amit Khandelwal 探索处理自动完成的不同方法,从基础到高级,包括输入时搜索、查询时间、完成建议器和索引时间。 在本文中,我们将介绍如何避免严重的性能错误、Elasticsearch 默认解决方案为何不适用以及重要的…...

快速入门Springboot+vue——MybatisPlus多表查询及分页查询
学习自哔哩哔哩上的“刘老师教编程”,具体学习的网站为:7.MybatisPlus多表查询及分页查询_哔哩哔哩_bilibili,以下是看课后做的笔记,仅供参考。 多表查询 多表查询[Mybatis中的]:实现复杂关系映射,可以使…...

工程师 - VSCode的AI编码插件介绍: MarsCode
豆包 MarsCode MarsCode AI: Coding Assistant Code and Innovate Faster with AI 豆包 MarsCode - 编程助手 安装完成并使能后,会在下方状态栏上显示MarsCode AI。 安装完并重启VSCode后,要使用这个插件,需要注册一下账号。然后授权VSCod…...

VOS3000线路对接、路由配置与路由分析操作教程
一、VOS3000简介 VOS3000是一款常用的VoIP运营平台,支持多种线路对接和路由配置,适合新手快速上手。本教程将带你了解如何对接线路、配置路由以及进行路由分析。 二、线路对接 准备工作 获取线路信息:从供应商处获取线路的IP地址、端口、用…...

学习Linux准备2
使用win10系统带的wsl配置ubuntu系统,通过wsl功能我们可以更简单更轻松的获得Linux系统环境。 首先开启Windows自带的wsl功能 打开控制面板,选中启用或关闭Windows功能 这里我们点击进入 将上图红√点击上,点击确定,然后重新启动…...

Java IO 和 NIO 的基本概念和 API
一、 Java IO (Blocking IO) 基本概念: Java IO 是 Java 平台提供的用于进行输入和输出操作的 API。Java IO 基于 流 (Stream) 的模型,数据像水流一样从一个地方流向另一个地方。Java IO 主要是 阻塞式 I/O (Blocking I/O),即线程在执行 I/O …...

【数据结构】快指针和慢指针
一、 给你单链表的头结点 head ,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。 要求:只遍历一遍链表 可以使用快慢指针:fast 一次走两步,slow 一次走一步。当 fast NULL(偶数个结点)或…...

四、综合案例(Unity2D)
一、2D渲染 1、2D相机基本设置 上面是透视,下面是正交 2、图片资源 在Unity中,常规图片导入之后,一般不在Unity中直接使用,而是转为精灵图Sprite 将图片更改为即可使用Unity内置的图片切割功能 无论精灵图片是单个的还是多个的…...
)
全面汇总windows进程通信(三)
在Windows操作系统下,实现进程间通信(IPC, Inter-Process Communication)有几种常见的方法,包括使用管道(Pipe)、共享内存(Shared Memory)、消息队列(Message Queue)、命名管道(Named Pipe)、套接字(Socket)等。本文介绍如下几种: RPC(远程过程调用,Remote Pr…...

Caffeine:高性能的Java本地缓存库
文章目录 引言什么是Caffeine?Caffeine的主要特点Caffeine的使用方法Caffeine与Google Guava Cache的对比Caffeine与Ehcache的对比总结 引言 在现代软件开发中,缓存是提高应用性能的重要手段之一。通过缓存,可以减少对数据库或其他外部系统的…...

Codes 开源免费研发项目管理平台 2025年第一个大版本3.0.0 版本发布及创新的轻IPD实现
Codes 简介 Codes 是国内首款重新定义 SaaS 模式的开源项目管理平台,支持云端认证、本地部署、全部功能开放,并且对 30 人以下团队免费。它通过创新的方式简化研发协同工作,使敏捷开发更易于实施。并提供低成本的敏捷开发解决方案࿰…...

flowable 全生命周期涉及到的api及mysql表
要了解Flowable从流程创建到审批过程中涉及的API和MySQL表。之前对工作流引擎有一些基础了解,但具体到Flowable的细节可能不太熟悉。需要先回忆一下Flowable的基本概念,比如流程定义、流程实例、任务、执行实例等,然后逐步思考每个步骤会用到…...

Golang | 每日一练 (3)
💢欢迎来到张胤尘的技术站 💥技术如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 Golang | 每日一练 (3)题目参考答案map 实现原理hmapb…...