RoCBert:具有多模态对比预训练的健壮中文BERT
摘要
大规模预训练语言模型在自然语言处理(NLP)任务上取得了最新的最优结果(SOTA)。然而,这些模型容易受到对抗攻击的影响,尤其是对于表意文字语言(如中文)。 在本研究中,我们提出了 ROCBERT——一种对抗各种形式对抗攻击(如单词扰动、同义词替换、拼写错误等)具有鲁棒性的中文预训练 BERT 模型。 该模型采用对比学习目标(contrastive learning objective)进行预训练,以最大化不同合成对抗样本下的标签一致性。此外,模型输入包含多模态信息,包括:
- 语义(semantic)
- 音韵(phonetic)
- 视觉(visual)
我们发现,这些特征对于提升模型的鲁棒性至关重要,因为对抗攻击可能发生在这三种信息模态中。 在 5 个中文自然语言理解(NLU)任务上,ROCBERT 在三种黑盒对抗攻击算法下均优于强基线模型,同时不损失干净测试集(clean testset)上的性能。此外,在有害内容检测任务中,该模型在人工构造的攻击下表现最佳。
1 引言
大规模预训练模型在微调(finetuning) 充足的标注数据后,已经能够接近甚至超越人类水平(Peters et al., 2018; Radford et al.; Devlin et al., 2019; Liu et al., 2019; Brown et al., 2020)。 然而,即便这些模型在海量文本上进行了预训练,它们仍然容易受到对抗攻击(adversarial attacks)的影响,例如:
- 同义词替换(synonyms substitution)
- 单词删除/交换(word deletion/swapping)
- 拼写错误(misspelling)
这些对抗样本(adversarial examples) 在真实世界场景中频繁出现,它们可能是:
- 自然产生的(例如:拼写错误)
- 恶意制造的(例如:规避有害内容的自动检测)

缺乏鲁棒性的问题
在噪声较大的真实环境中进行测试时,这些预训练模型的鲁棒性不足,可能会导致严重的性能下降。这一问题在表意文字语言(如中文)中尤为突出,因为对抗攻击可以发生在:
- 字形(Glyph Character)
- 拼音(Pinyin,即罗马化音标表示)
- 或二者结合的方式
(Wang et al., 2020; Li et al., 2020d; Zhang et al., 2020; Nuo et al., 2020)。
表 1 展示了一些攻击示例。例如,单词“科比 (Kobe)” 可以被替换为:
- 同义词(语义攻击)
- 发音相似的词(语音攻击)
- 视觉上相似的字(视觉攻击)
攻击者甚至可以先将汉字转换为拼音,然后在字母层面继续攻击(如表中的 “keb1”)。
由于汉字的语义与语音信息相互独立,且汉字的字形字符丰富,使得攻击形式远比英语等字母语言更加多样化。
当前对抗防御方法的局限性
目前,研究人员主要采用两种方法来防御对抗攻击:
-
拼写检查(Spell Checking)
- 在文本输入预测模型之前,先进行拼写检查,以修正书写错误
- 相关研究:Pruthi et al., 2019; Li et al., 2020b; Mozes et al., 2021
- 问题:中文拼写检查本身就是一个极具挑战的任务,模型需要准确恢复原始文本,而拼写检查中的微小错误都可能导致模型无法预测或产生错误行为
-
对抗训练(Adversarial Training)
- 在训练数据中加入对抗样本,让模型适应对抗攻击
- 相关研究:Zang et al., 2020; Li et al., 2020a; Liu et al., 2020
- 问题:在微调阶段,模型难以适应所有对抗变体,尤其是在训练数据稀缺的情况下(Meng et al., 2021)
ROCBERT 方案:构建鲁棒的中文 BERT
为了解决上述挑战,我们提出ROCBERT,这是一种鲁棒的中文 BERT 预训练模型,其核心方法包括:
-
对抗对比学习目标(Contrastive Learning Objective)
- 最大化不同对抗样本下的标签一致性,提高模型鲁棒性
-
自动生成对抗样本
- 采用专门的算法,涵盖常见的攻击类型
-
组合攻击(Combinatorial Attacks)
- 多个攻击类型可叠加(这在以往研究中从未被考虑)
-
多模态信息融合
- 在编码器中融合语义、音韵和视觉信息,以全面抵御不同形式的攻击
- 其中,语音和视觉特征被插入到自注意力层(Self-Attention Layer)中,然后在后续层进行动态融合
在5 个标准 NLU 任务和1 个有害内容检测任务上,我们的预训练模型在各种对抗攻击下达到了最新 SOTA 结果。
贡献总结
- 提出了一种新的鲁棒中文 BERT 预训练方法,结合对抗对比学习,使模型在干净测试集和对抗攻击数据集上都能表现良好。
- 采用合成对抗样本,涵盖语义、音韵和视觉三种攻击类型,并融合多模态特征来防御所有级别的攻击。
- 在 5 个 NLU 任务和 1 个有害内容检测任务上,在各种对抗攻击下均超越强基线模型。
- 进行广泛的消融实验,探讨不同预训练选项的影响,并与主流对抗防御方法进行了深入比较,以促进未来研究。
2 相关工作
对抗攻击(Adversarial Attack)
大量研究表明,NLP 模型在对抗样本下极易受到攻击,即使这些样本对人类来说可理解,但会导致模型预测错误(Li et al., 2020c; Garg & Ramakrishnan, 2020; Zang et al., 2020)。
通常,对抗攻击可分为两类:
-
语义等价替换(Semantic Equivalent Replacement)
- 通过词向量相似性替换单词(Jin et al., 2020; Wang et al., 2020)
- 通过WordNet 同义词替换(Zang et al., 2020)
- 通过预训练模型的掩码预测(Masked Prediction)(Li et al., 2020c; Garg & Ramakrishnan, 2020; Li et al., 2020d)
-
噪声注入(Noise Injection)
- 添加/删除/交换单词(Li et al., 2019a; Gil et al., 2019; Sun et al., 2020a)
- 替换为发音或视觉相似的单词(Eger et al., 2019; Eger & Benz, 2020)
对于中文而言,由于汉字的字形和拼音特性,噪声可以同时作用在字形和拼音上(Zhang et al., 2020; Nuo et al., 2020)。
3 对抗样本生成(Adversarial Example Synthesis)
3.1 中文字符攻击(Attacking Chinese Characters)
由于汉字的复杂性,我们专门设计了5 种中文特定的攻击方法:
-
语音攻击(Phonetic Attack)
- 用同音字替换汉字(忽略声调)
- 对于多音字,选取最常见的 2 个拼音
-
视觉攻击(Visual Attack)
- 用视觉上相似的汉字进行替换(使用汉字相似度数据库)
-
字符拆分攻击(Character Split Attack)
- 拆分汉字为两个子部分,且每部分仍是有效汉字或视觉相似汉字
- 参考中文拆分字典(共17,803 种拆分方式)
-
同义词替换攻击(Synonym Attack)
- 分词后用同义词替换部分单词(使用Jieba 分词器)
- 同义词判定标准:相似度 > 0.75
- 仅替换名词和形容词(因为其他词的替换往往会改变语义)
-
字符转拼音攻击(Character-to-Pinyin Attack)
-
用拼音表示汉字(忽略声调)

-
3.2 其他字符的攻击方式
除了中文字符,中文语料库中还包含拼音、数字、标点符号和外文单词。我们设计了以下 4 种攻击方法,适用于所有字符类型:
-
Unicode 攻击(Unicode Attack)
- 随机选取一个视觉相似的 Unicode 字符进行替换
-
随机插入(Random Insertion)
- 从词汇表中随机抽取一个字符
- 随机插入到目标字符的左侧或右侧
-
交换字符(Swap)
- 交换目标字符与其相邻字符的位置
-
删除字符(Deletion)
- 直接删除目标字符
表 1 展示了所有攻击类型的示例。
3.3 对抗样本的生成过程(Synthesis Process)
对抗样本的生成流程如下:
- 给定一个句子,我们首先选择多个字符作为攻击目标。
- 针对每个被选中的字符,我们结合上述字符级攻击算法,生成被攻击后的字符形式。
攻击比例(Attack Ratio) 攻击比例( γ γ γ)决定了一个句子中有多少字符会被攻击。
设句子中的总字符数为 n c n_c nc,我们定义 γ γ γ 为:
γ = min ( max ( int ( ϵ ) , 1 ) , n c ) ( 1 ) ϵ ∼ N ( max ( 1 , 0.15 n c ) , 1 ) \begin{aligned} & \gamma=\operatorname*{min}(\operatorname*{max}(\operatorname{int}(\epsilon),1),n_{c}) \\ & & \mathrm{(1)} \\ & \epsilon\sim\mathcal{N}(\max(1,0.15n_{c}),1) \end{aligned} γ=min(max(int(ϵ),1),nc)ϵ∼N(max(1,0.15nc),1)(1)
其中,int 函数将四舍五入为最接近的整数。这样做的直观原因是,我们希望平均攻击 15% 的字符。如果句子较短,我们将确保至少攻击一个字符。我们在平均比例的基础上添加了正态高斯噪声,以增加一定的随机性。
字符选择:许多研究表明,攻击信息量大的词比随机选择词更有效(Li et al., 2019a; Sun et al., 2020a)。因此,我们根据字符在句子中的信息量来决定其被选中的概率。设 w ( c i ) w(c_i) w(ci) 表示字符 c i c_i ci 所属的词, c i c_i ci 的信息量得分通过删除 w ( c i ) w(c_i) w(ci) 后语言模型损失的变化来计算(记为 L ( ▽ w ( c i ) ) \mathcal{L}(\triangledown w(c_{i})) L(▽w(ci)),参考 Li et al., 2016)。字符 c i c_i ci 被选中攻击的概率为:
p ( c i ) = e L ( ∇ w ( c i ) ) ∣ w ( c i ) ∣ ∑ j = 1 n w e L ( ∇ w j ) ( 2 ) p(c_i)=\frac{e^{\mathcal{L}(\nabla w(c_i))}}{|w(c_i)|\sum_{j=1}^{n_w}e^{\mathcal{L}(\nabla w_j)}}\qquad{(2)} p(ci)=∣w(ci)∣∑j=1nweL(∇wj)eL(∇w(ci))(2)
其中, n w n_{w} nw 是句子中的词数。 ∣ w ( c i ) ∣ |w(c_i)| ∣w(ci)∣ 表示 w ( c i ) w(c_i) w(ci) 中的字符数,因此同一词中的字符被选中的概率相等。
攻击组合:一个字符可能会受到多种攻击的组合。例如,我们可以将一个中文字符转换为其拼音,然后继续在字母级别对其进行攻击(如表1中的“to pinyin + unicode”)。我们将其定义为一个顺序过程,每一步都可以在之前的基础上添加新的攻击。具体来说,所有攻击组合应用于字符 c c c 后得到的新字符 c ~ \tilde{c} c~ 为:
c ~ = A S ( c ) ∘ ⋯ ∘ A 2 ∘ A 1 ( c ) ( 3 ) \tilde{c}=A_{S(c)}\circ\cdots\circ A_2\circ A_1(c) \qquad{(3)} c~=AS(c)∘⋯∘A2∘A1(c)(3)
p ( S ( c ) = k ) = q ( 1 − q ) k − 1 p(S(c)=k)=q(1-q)^{k-1} p(S(c)=k)=q(1−q)k−1
其中,“o” 表示将新的攻击算法 A A A 应用于上一步的输出。在每一步 i i i,攻击算法 A i A_i Ai 都是从所有适用于上一步输出的算法中随机选择的。 S ( c ) S(c) S(c) 表示应用于字符 c c c 的攻击步骤数,它服从指数衰减函数。我们在实验中将超参数设定为 q = 0.7 q=0.7 q=0.7。对抗样本生成的完整流程如图 1 所示。
4. 多模态对比学习预训练(Multimodal Contrastive Pretraining)
借助上述对抗样本生成算法,我们可以通过多模态对比学习目标来预训练模型。
4.1 多模态特征(Multimodal Features)
我们采用标准 BERT 结构(Devlin et al., 2019)作为基础,并在此基础上**将语音(Phonetic)和视觉(Visual)特征融合到输入文本中。
特征表示(Feature Representation)
对于词汇表中的每个字符 c c c,除了标准的语义嵌入(Semantic Embedding) S e ( c ) Se(c) Se(c),我们还包括两个额外的向量:
- P h ( c ) Ph(c) Ph(c) —— 编码字符的语音(拼音)信息
- V i ( c ) Vi(c) Vi(c) —— 编码字符的视觉信息
如果 c c c 不是一个汉字,它会有自己的语音向量。否则,其语音向量 P h ( c ) Ph(c) Ph(c) 定义如下:
P h ( c ) = ∑ k ∈ p i n y i n ( c ) P h ( k ) Ph(c)=∑k∈pinyin(c)Ph(k) Ph(c)=∑k∈pinyin(c)Ph(k)
其中, p i n y i n ( c ) pinyin(c) pinyin(c) 是字符 c c c 的拼音序列。字符的视觉向量 V i ( c ) Vi(c) Vi(c) 是从其 32×32 图像 I ( c ) I(c) I(c) 中提取的。对于汉字,该图像采用宋体(Simsun);对于其他字符,则采用Arial字体,这些是大多数在线文本的默认字体。
V i ( c ) Vi(c) Vi(c) 的计算方式如下:
V i ( c ) = L a y e r N o r m ( M T R e s N e t 18 ( I ( c ) ) ) ( 4 ) Vi(c)=LayerNorm(M^TResNet18(I(c)))\qquad{(4)} Vi(c)=LayerNorm(MTResNet18(I(c)))(4)
M M M 是一个可学习矩阵,我们利用 ResNet18 (He et al., 2016)将 字符图像 I ( c ) I(c) I(c) 映射为一维向量(该映射在训练过程中被冻结,即不会更新)。
视觉表征预训练(Visual Representation Pretrain)
为了获得合理的初始化,我们增加了一个仅针对视觉表征的预训练阶段。
- 语音表征(Phonetic representations)在训练开始时随机初始化。
- 视觉表征的变换矩阵 M M M(公式 4 中)使用与公式 5 相同的对比损失进行预训练。
在该阶段,字符 c c c 的正样本(positive sample)是其视觉对抗形式 c ~ \tilde{c} c~,定义如下:
c ~ = A ( c ) \tilde{c}=\mathcal{A}(c) c~=A(c) ,其中, A ∼ U ( visual, character split, unicode ) \mathcal{A} \sim \mathbb{U}(\text{visual, character split, unicode}) A∼U(visual, character split, unicode),表示从 §3 提到的三种视觉攻击方法**(**视觉替换、字符拆分、Unicode 替换)中均匀采样。 如果 c c c 被拆分为两个字符 c 1 c_1 c1 和 c 2 c_2 c2,则其视觉表征计算方式如下:
V i ( c ~ ) = V i ( c 1 ) + V i ( c 2 ) Vi(\tilde{c})=Vi(c_1)+Vi(c_2) Vi(c~)=Vi(c1)+Vi(c2)
负样本(negative samples) 是同一批次(batch)中的所有其他字符。 经过该训练后,视觉相似的字符将在表征空间中彼此靠近。
特征融合(Feature Integration)
一个直接的多模态特征融合方法是在送入编码器(encoder)之前进行融合(Sun et al., 2021; Liu et al., 2021)。
然而,这种方法会对三种特征(语义、语音、视觉)赋予相等的权重**,使模型无法动态关注最有用的特征。
另一种方法是两步编码(two-step encoding),先确定各特征的权重,然后用选择性注意力进行编码(Xu et al., 2021)。
但这种方法会显著降低系统的运行速度。 我们提出了一种轻量级融合方法——“层插入”(layer-insert) ,即仅在编码器的一个层中插入多模态特征。令 H k ( i ) H_k(i) Hk(i) 表示第 k k k 层中第 i i i 个词的表征,我们的插入方式如下:
W 1 = K 1 T H k ( i ) H k ( i ) V 1 W 2 = K 2 T H k ( i ) P h ( i ) V 2 W 3 = K 3 T H k ( i ) V i ( i ) V 3 H k ( i ) = W 1 H k ( i ) + W 2 P h ( i ) + W 3 V i ( i ) W 1 + W 2 + W 3 \begin{aligned} W_{1} & =K_{1}^{T}H^{k}(i)H^{k}(i)V_{1} \\ W_{2} & =K_{2}^{T}H^{k}(i)Ph(i)V_{2} \\ W_{3} & =K_3^TH^k(i)Vi(i)V_3 \\ H^{k}(i) & =\frac{W_{1}H^{k}(i)+W_{2}Ph(i)+W_{3}Vi(i)}{W_{1}+W_{2}+W_{3}} \end{aligned} W1W2W3Hk(i)=K1THk(i)Hk(i)V1=K2THk(i)Ph(i)V2=K3THk(i)Vi(i)V3=W1+W2+W3W1Hk(i)+W2Ph(i)+W3Vi(i)
其中, P h ( i ) Ph(i) Ph(i)和 V i ( i ) Vi(i) Vi(i)分别是语音和视觉表示, K j / V j K_j / V_j Kj/Vj是可学习的矩阵。直观上,我们可以使用第 0 层到第 ( k-1 ) 层来决定三种多模态表示的权重,并使用其余层进行句子表示学习。这使得模型能够根据句子上下文动态融合多模态信息,同时仅增加少量复杂性。
4.2 模型损失
模型损失由两部分组成:对比学习损失和标准的掩码语言模型(MLM)损失。
对比学习:对比学习(Chen et al., 2020; Kim et al., 2021)的核心思想是,表示空间应使相似(正)样本更接近,而使不相似(负)样本更远离。对于每个句子,我们将其对抗形式(通过第 3 节中的算法获得)视为正样本,并将同一批次中的所有其他句子视为负样本。给定一个包含 ( N ) 个句子的批次,第 ( i ) 个句子 ( s i s_i si ) 的损失为:
L c ( i ) = − log e s i m ( s i , s ~ i ) / τ ∑ j = 1 N e s i m ( s i , s j ) / τ , ( 5 ) \mathcal{L}_{c}(i)=-\log\frac{e^{sim(s_{i},\tilde{s}_{i})/\tau}}{\sum_{j=1}^{N}e^{sim(s_{i},s_{j})/\tau}},\qquad{(5)} Lc(i)=−log∑j=1Nesim(si,sj)/τesim(si,s~i)/τ,(5)
其中, τ \tau τ 是温度超参数(temperature hyperparameter), s i s_i^{~} si 是从 s i s_i si 生成的对抗样本。我们在初步实验的基础上设定 τ = 0.01 \tau = 0.01 τ=0.01,并定义相似度计算公式如下: sim ( s i , s ~ i ) = h i ⃗ T h i ⃗ ∥ h i ⃗ ∥ ⋅ ∥ h i ⃗ ∥ \text{sim}(s_i, \tilde{s}_i) = \frac{\vec{h_i}^T\vec{h_i}}{\|\vec{h_i}\| \cdot \|\vec{h_i}\|} sim(si,s~i)=∥hi∥⋅∥hi∥hiThi ,即在表示空间 h i h_i hi 和 h i ~ \tilde{h_i} hi~ 中的余弦相似度(cosine similarity)。
混合 MLM 训练(Mix with MLM)
我们将**对比学习损失(contrastive learning loss)与标准的掩码语言模型(MLM)损失(Devlin et al., 2019)混合,以实现句子级和词级的表示学习。 我们采用基于字符(character-based)的分词器,原因如下:
- 中文字符本身可作为独立的语义单元(Li et al., 2019b)。
- 基于字符的模型在嘈杂(noisy)或对抗性(adversarial)场景下更具鲁棒性**(El Boukkouri et al., 2020)。
对于中文字符,我们采用两种掩码策略:
- 整词掩码(Whole Word Masking, WM)
- 字符掩码(Char Masking, CM)
因为大量中文词汇由多个字符组成(Cui et al., 2019; Sun et al., 2021)。 最终,对比学习损失和 MLM 损失具有相同的权重**(equally weighted)。
5 实验(Experiments)
5.1 实验设置(Experiment Setup)
模型细节(Model Details)
我们使用16224个词汇(vocabulary size),其中14642个是中文字符。我们提供两种版本的 ROCBERT:
- Base 版本:12 层/头,隐藏神经元数为 768。训练 600k 步,batch size 为 4k,学习率 1e-4,warmup 25k 步。
- Large 版本:48 层,24 个注意力头(attention heads),隐藏神经元数为 1024。训练 500k 步,学习率 3e-4,warmup 70k 步,batch size 8k。
预训练细节(Pretraining Details)
按照通用做法,我们在 2TB 文本数据上进行预训练,该数据来源于 THUCTC 12、中文维基百科(Chinese Wikipedia)和 Common Crawl。
- 训练设备:64 块 NVIDIA V100 (32GB) GPU,使用 FP16 和 ZERO-stage-1 优化(Rasley et al., 2020)。
- 内存优化:
- 采用 PatricStar(Fang et al., 2021)以动态内存调度,结合基于块(chunk-based)的内存管理。
- 该方法会将除当前计算部分外的所有内容卸载到 CPU,从而在相同硬件条件下训练更大的模型。
- 基于块的内存管理利用了Transformer 结构的线性特性,可以提前预加载即将计算的层到 GPU,提高计算效率。
基线模型(Baseline Models)
我们将 ROCBERT 与以下 最先进(SOTA)的中文预训练模型进行对比:
- MBert-Chinese(Devlin et al., 2019)
- Bert-wwm(Cui et al., 2019):在 MBert-Chinese 基础上继续预训练,并采用 Whole Word Masking(WWM)策略。
- MacBERT(Cui et al., 2020):采用 MLM-As-Correlation(MAC) 预训练策略,并加入句子顺序预测(Sentence-Order Prediction, SOP)任务。
- ERNIE-gram(Sun et al., 2019, 2020b):采用多种掩码策略(token 级、短语级、实体级),在大规模异构数据上进行预训练。
- ChineseBERT(Sun et al., 2021):在预训练过程中加入了字形(glyph)和音韵(phonetic)特征。
评测任务(Tasks)
我们在 5 个标准中文自然语言理解(NLU)任务和 1 个有害内容检测(toxic detection)任务上测试模型:
- ChnSentiCorp(2k 训练数据):中文情感分类任务(Xu et al., 2020)。
- TNEWS(50k 训练数据):新闻标题分类任务。
- AFQMC(34k 训练数据):问题匹配(question matching)任务。
- CSL(20k 训练数据):从论文摘要中识别关键词(keyword recognition)。
- CMNLI(390k 训练数据):中文多领域自然语言推理(Chinese Multi-Genre NLI)(Conneau et al., 2018)。
- 有害内容检测(Toxic Detection):
- 该任务用于对抗人类制造的攻击(human-made attacks),与合成攻击(synthesized attacks)形成对比。
- 数据来源于用户在某在线对话平台上的输入,其中用户会刻意使用各种攻击手段来规避系统的自动过滤(如垃圾广告、色情、辱骂等)。
- 我们手动标注了50k 条用户输入,其中2k 条为有害内容(positive),且 90% 具有对抗性特征。
- 负例(negative)随机采样2k 条非有害文本,最终数据集按 8:1:1 划分为 训练/验证/测试集。
攻击方法(Attacker)
我们在 三种不同的攻击方法下测试模型表现(均为无目标攻击,即不对目标类别施加限制):
- ADV(我们的自定义攻击算法)
- TextFooler(Jin et al., 2020):
- 黑盒(black-box)攻击算法,通过用语义相似的词替换关键字来欺骗模型。
- 原生为英文算法,我们重新实现(reimplement)了对应的中文版本。
- Argot(Zhang et al., 2020):
- 黑盒攻击算法,专门针对中文特征进行攻击。
所有三种攻击方法的最大攻击比率(attack ratio)均设为 20%。

5.2 实验结果(Experiment Results)
中文 NLU 任务结果(Chinese NLU Results)
我们在 5 个中文 NLU 任务上的结果见表 2 至表 6。对于每个任务,我们报告模型在干净测试集(clean test set)和三种对抗测试集(adversarial test sets)(即 ADV、TextFooler 和 Argot 生成的对抗数据集)上的准确率(accuracy)。
为了公平比较,我们报告了所有 base 版本模型的性能。然后,我们选择表现最好的 base 版本模型,测试其 large 版本性能,并将其与 ROCBERT 进行比较。
从实验结果可以看出:
- TNEWS、AFQMC 和 CSL 受 ADV 攻击的影响较小,因为这些任务更依赖全局句子结构,而非个别单词。
- 在情感分类(sentiment classification)和自然语言推理(NLI)等任务中,单个词汇对模型决策的影响较大,因此攻击会导致显著的性能下降。
- Argot 和 TextFooler 导致的性能下降比 ADV 更大,因为:
- TextFooler 和 Argot 专门选择最能影响模型决策的单词进行攻击,而 ADV 仅基于语言模型分数选择攻击单词。
- Argot 比 TextFooler 更有效,因为它在替换字符时考虑了中文的特定特征(Chinese-specific features)。
- 总体而言,ROCBERT 在所有攻击算法和所有 5 个任务上都优于其他模型。即使在干净数据集(clean dataset)上,它在 5 个任务中 4 个任务表现最佳。
- ChineseBERT 在各种攻击下排名第二,因为它在预训练时也考虑了多模态特征(multimodal features),这进一步证明了多模态特征在中文语言预训练中的重要性。
有害内容检测结果(Toxic Content Detection Results)
我们在有害内容检测任务(toxic content detection task)上训练所有模型,结果见表 7。
-
ROCBERT 在 4 个评测指标上都优于所有其他模型,这验证了其能够捕捉真实语义,而不受对抗攻击形式的影响。
-
不同模型之间的性能差异较小,因为它们都在该任务上进行了微调(finetuning)。
-
所有模型在训练过程中都能适应不同形式的攻击,而表 2 至表 6 则测试了它们对未知攻击(unknown attacks)的零样本泛化能力(zeroshot generalization)。


防御方法比较(Defending Method Comparison)
我们进一步将 ROCBERT 与 两种流行的对抗攻击防御方法进行比较:
- 拼写检查(Spell Checker):在输入模型之前运行拼写检查器。
- 对抗训练(Adversarial Training, AdvTrain):通过添加对抗样本来增强训练数据。
我们在不同任务中,将这两种防御方法添加到在干净测试集上表现最好的 base 版本模型之上进行对比:

- TNEWS 任务:使用 ChineseBert 作为基线模型。
- AFQMC、CSL 和 CMNLI 任务:使用 Ernie-gram 作为基线模型。
- ChnSentiCorp 任务:使用 MacBert 作为基线模型。
我们采用 Cheng et al. (2020) 提出的拼写检查器。结果如图 2 所示。 从实验结果可以看出:
-
拼写检查(Spell Checking)对模型性能的提升非常有限,甚至在某些情况下反而降低性能(例如,在 ChnSentiCorp 任务下,使用 ADV 攻击时,拼写检查的效果最差)。
- 这可能是因为 拼写检查器对领域外(out-of-domain)的对抗样本效果较差,错误的拼写修正会导致错误传播,从而降低整体性能。
-
对抗训练(AdvTrain)能显著提升模型的鲁棒性(robustness),但它的缺点是它“窥探”(peeps)了测试集中的对抗攻击算法,即它在训练时已经知道测试中使用的攻击类型。
-
ROCBERT 在不知晓测试集攻击算法的情况下,依然能与 AdvTrain 相媲美,甚至在某些情况下超越 AdvTrain,说明它在 面对未知攻击时具有更强的泛化能力。
-
ROCBERT 和 AdvTrain 结合使用时,模型的鲁棒性可以进一步提升。
5.3 消融实验(Ablation Study)
我们进行了一系列 消融实验(Ablation Study),以理解ROCBERT不同组件的选择对模型性能的影响。
在本节中,所有模型均采用相同的 base 结构和超参数,并在100 万个采样训练文本上预训练1轮(epoch),然后在TNEWS 任务上进行测试。实验结果如表 8 所示。


损失函数(Loss)
为了研究 预训练阶段损失函数的影响,我们尝试了两种不同的设置:
- 仅对比学习(Contrastive Only):模型仅使用 公式 5 中的 对比学习损失 进行预训练。
- 仅 MLM(MLM-Only):模型仅使用 MLM(掩码语言模型)目标 进行预训练(即标准 Bert 预训练方式)。
实验结果表明,这两种单一的损失函数都会降低模型的性能。
结合两种损失函数 可以提高模型的 对抗攻击鲁棒性,同时不会影响模型在 干净数据(Clean Data) 上的表现。
分词方法(Tokenization)
字符级分词(char-based tokenization) 在中文处理任务中已被广泛证明是最优选择(Li et al., 2019b)。
但对于拼音(pinyin)和非中文词汇,最佳的分词方法尚不明确。因此,我们尝试了以下几种不同的分词方法:
-
BPE(Byte Pair Encoding):
- 设定词汇表大小为 20K,在 训练数据 上进行训练(所有 中文字符 先转换为 拼音)。
-
Char-CNN(Zhang et al., 2015):
- 逐个字符处理,并使用 Char-CNN 获取拼音嵌入(embedding)。
-
Char-Sum(ROCBERT 最终采用的方法):
- 逐个字符处理,并将拼音嵌入表示为 其字符嵌入的总和(sum)。

实验结果表明:
- BPE 分词方法会降低模型的性能,可能是因为 BPE 分词仅在 干净数据(Clean Data) 上进行训练。
- 对于 对抗样本(Adversarial Examples),拼音中的字母更容易受到干扰,从而破坏其词汇表结构。
- 字符级(Char-Based)分词方法在对抗攻击下更具鲁棒性。
- Char-CNN 方法没有带来明显提升,可能是因为 拼音字符组合数量有限(约 400 种),每个拼音通常可以通过 字符袋(Bag of Characters) 唯一确定,无需考虑顺序信息。
** 多模态特征(Multimodal Feature)**
我们尝试移除 视觉特征(Visual Feature) 预训练,并观察模型性能的变化:
- 移除视觉特征预训练(-vis-pretrain):
- 结果表明:模型性能下降 甚至比完全移除视觉特征(-vis)更糟糕,
- 这说明 视觉特征预训练是必要的,否则模型难以学习到有意义的视觉特征。
- 移除视觉特征(-vis):
- 结果表明:视觉特征比拼音特征更为重要。
- 移除拼音特征(-pho):
- 结果表明:拼音特征也能带来一定的性能提升,但不如视觉特征重要。
- 添加拼音特征预训练(+pho-pretrain):
- 结果表明:拼音特征预训练的提升幅度很小,可能是因为拼音特征本身 基于字符嵌入(Character Embedding),
- 这使得 模型可以在训练过程中自动学习拼音特征,无需额外的预训练。
多模态融合(Multimodal Integration)
我们将 ROCBERT 提出的层插入(Layer-Insert) 方法与 三种主流的多模态特征融合方法 进行了比较:
- 加和(Sum, Liu et al., 2021):
- 直接对不同模态的嵌入进行加和。
- 拼接(Concatenation, Sun et al., 2021):
- 先 拼接 多模态嵌入,然后使用 MLP 层进行融合。
- 两步融合(Two-Step, Xu et al., 2021):
- 先计算不同模态嵌入的权重,然后再融合到 编码器(Encoder) 中。
实验结果表明:
- ROCBERT 采用的层插入(Layer-Insert)方法效果最佳,且计算开销 极小,
- 这是因为它仅通过 更新编码器的一层表征 来完成多模态信息的融合。
插入层(Insert Layer)
我们进一步分析了 插入层的位置 对模型性能的影响。
- 最佳插入层:
- 基础模型(Base Model) 在 第 1 层插入 多模态特征,
- 大模型(Large Model) 在 第 3 层插入 多模态特征。
- 插入层位置对性能的影响(见表 8):
- 当插入层提升到更高层(如第 4、7 和 10 层),模型性能逐渐下降,
- 这表明 较早插入(Early Insert) 可以 更深入地融合多模态信息,
- 但如果 直接插入到第 0 层,效果反而变差,
- 可能原因是:模型在第 0 层只能从词袋(Bag of Words)层面学习模态特征的权重,而无法进行深入表征学习。
攻击算法(Attacking Algorithm)
我们改变 攻击算法的设置,并在 图 3 中展示了其影响。
- 攻击比例(Attacking Ratio):
- 不能 过小或过大,
- 15% 是对抗预训练的最佳比例(Sweet Spot)。
- 高斯噪声(Gaussian Noise, 公式 1):
- 持续带来 正面效果,
- 这表明 不应在预训练阶段使用固定的攻击比例,而应动态调整。
- 字符选择(Character Selection):
- 该机制至关重要,
- 去掉字符选择后,模型性能大幅下降。
- 攻击算法的复杂性:
- 为了验证是否有必要采用复杂的攻击算法,
- 我们 用 SimCSE(Gao et al., 2021)进行对比(SimCSE 采用 Dropout 作为噪声,而非对抗样本)。
- 实验结果表明:SimCSE 在不同攻击方式下几乎没有帮助,
- 这说明:
- 制定基于规则的攻击算法 以更好地模拟 真实世界攻击 是必要的。
- 通用的 Dropout 正则化 无法有效适应 复杂的真实世界攻击。
6 结论(Conclusion)
我们提出了 ROCBERT:
- 第一个鲁棒的中文预训练语言模型,
- 能够抵御多种形式的对抗攻击。
关键特性:
- 基于多模态对比学习目标(Multimodal Contrastive Learning Objective)进行预训练,
- 在 5 项中文 NLU 任务上取得最佳表现,
- 能在 3 种不同的攻击算法下保持强大的鲁棒性,且不会影响干净测试集的性能,
- 在有害内容检测任务(Toxic Content Detection)上显著超越其他模型,
- 提供了大量消融实验(Ablation Studies),为未来研究提供参考。
相关文章:
RoCBert:具有多模态对比预训练的健壮中文BERT
摘要 大规模预训练语言模型在自然语言处理(NLP)任务上取得了最新的最优结果(SOTA)。然而,这些模型容易受到对抗攻击的影响,尤其是对于表意文字语言(如中文)。 在本研究中࿰…...

Dockerfile 中的 COPY 语句:作用与使用详解
在 Docker 的构建过程中,Dockerfile 是一个核心文件,它定义了镜像的构建步骤和内容。其中,COPY 语句是一个非常重要的指令,用于将文件或目录从构建上下文(通常是 Dockerfile 所在的目录及其子目录)复制到容…...

DeepSeek开源周Day2:DeepEP - 专为 MoE 模型设计的超高效 GPU 通信库
项目地址:https://github.com/deepseek-ai/DeepEP 开源日历:2025-02-24起 每日9AM(北京时间)更新,持续五天 (2/5)! 引言 在大模型训练中,混合专家模型(Mixture-of-Experts, MoE)因其动…...

六十天前端强化训练之第二天CSS选择器与盒模型深度解析
欢迎来到编程星辰海的博客讲解 目录 一、CSS 核心概念 1. 三种引入方式 2. CSS 注释 3. 常见单位系统 二、CSS选择器核心知识 1. 基础选择器类型 2. 组合选择器 3. 伪类选择器(部分示例) 4. 优先级计算规则 三、盒模型深度解析 1. 标准盒模型图…...

分享httprunner 结合django实现平台接口自动化方案
说明,可以直接在某个视图集定义自定义接口来验证。 调试1:前端界面直接编写yaml文件. 新增要实现存数据到mysql,同时存文件到testcase下, 如test.yaml 更新yaml数据,同时做到更新 testcase下的文件,如test.yaml acti…...

本地大模型编程实战(22)用langchain实现基于SQL数据构建问答系统(1)
使 LLM(大语言模型) 系统能够查询结构化数据与非结构化文本数据在性质上可能不同。后者通常生成可在向量数据库中搜索的文本,而结构化数据的方法通常是让 LLM 编写和执行 DSL(例如 SQL)中的查询。 我们将演练在使用基于 langchain 链 &#x…...
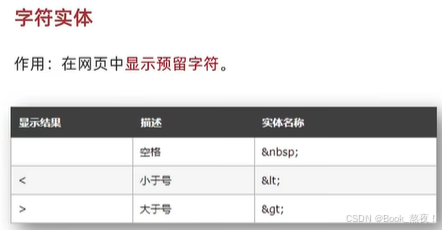
速通HTML
目录 HTML基础 1.快捷键 2.标签 HTML进阶 1.列表 a.无序列表 b.有序列表 c.定义列表 2.表格 a.内容 b.合并单元格 3.表单 a.input标签 b.单选框 c.上传文件 4.下拉菜单 5.文本域标签 6.label标签 7.按钮标签 8.无语义的布局标签div与span 9.字符实体 HTML…...
——动态规划)
算法(四)——动态规划
文章目录 基本思想适用条件最优子结构子问题重叠状态转移方程 解题步骤应用斐波那契数列背包问题最大子数组和 基本思想 动态规划的核心思想在于将一个复杂的问题分解为一系列相互关联的子问题,通过求解子问题并保存其解,避免对相同子问题的重复计算&am…...

博客系统完整开发流程
前言 通过前⾯课程的学习, 我们掌握了Spring框架和MyBatis的基本使用, 并完成了图书管理系统的常规功能开发, 接下来我们系统的从0到1完成⼀个项⽬的开发. 企业开发的流程 1. 需求评审(产品经理(PM)会和运营(想口号),UI,测试,开发等沟通) ,会涉及到背景/目标/怎么做,可能会有多…...

【C语言】指针笔试题
前言:上期我们介绍了sizeof与strlen的辨析以及sizeof,strlen相关的一些笔试题,这期我们主要来讲指针运算相关的一些笔试题,以此来巩固我们之前所学的指针运算! 文章目录 一,指针笔试题1,题目一…...

大数据开发平台的框架
根据你的需求,以下是从 GitHub 推荐的 10 个可以实现大数据开发平台的项目: 1. Apache Spark Apache Spark 是一个开源的分布式计算框架,适用于大规模数据处理和分析。它提供了强大的数据处理能力,支持实时数据处理、机器学习和…...
】从入门到精通:Scrapy Spider开发全攻略)
【Python爬虫(53)】从入门到精通:Scrapy Spider开发全攻略
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

《Keras 3 : 使用迁移学习进行关键点检测》:此文为AI自动翻译
《Keras 3 :使用迁移学习进行关键点检测》 作者:Sayak Paul,由 Muhammad Anas Raza 转换为 Keras 3 创建日期:2021/05/02 最后修改时间:2023/07/19 描述:使用数据增强和迁移学习训练关键点检测器。 (i) 此示例使用 Keras 3 在 Colab 中查看 GitHub 源 关键点检测包…...

CentOS停服后的替代选择:openEuler、Rocky Linux及其他系统的未来展望
CentOS停服后的替代选择:openEuler、Rocky Linux及其他系统的未来展望 引言CentOS停服的背景华为openEuler:面向未来的开源操作系统1. 简介2. 特点3. 发展趋势 Rocky Linux:CentOS的精神继承者1. 简介2. 特点3. 发展趋势 其他可选的替代系统1…...
【Qt】桌面应用开发 ------ 绘图事件和绘图设备 文件操作
文章目录 9、绘图事件和绘图设备9.1 QPainter9.2 手动触发绘图事件9.3 绘图设备9.3.1 QPixmap9.3.2 QImage9.3.3 QImage与QPixmap的区别9.3.4 QPicture 10、文件操作10.1 文件读写10.2 二进制文件读写10.3 文本文件读写10.4 综合案例 9、绘图事件和绘图设备 什么时候画&#x…...

python与C系列语言的差异总结(3)
与其他大部分编程语言不一样,Python使用空白符(whitespace)和缩进来标识代码块。也就是说,循环体、else条件从句之类的构成,都是由空白符加上冒号(:)来确定的。大部分编程语言都是使用某种大括号来标识代码块的。下面的…...

OpenCV(9):视频处理
1 介绍 视频是由一系列连续的图像帧组成的,每一帧都是一幅静态图像。视频处理的核心就是对这些图像帧进行处理。常见的视频处理任务包括视频读取、视频播放、视频保存、视频帧处理等。 视频分析: 通过视频处理技术,可以分析视频中的运动、目标、事件等。…...

【C++设计模式】观察者模式(1/2):从基础到优化实现
1. 引言 在 C++ 软件与设计系列课程中,观察者模式是一个重要的设计模式。本系列课程旨在深入探讨该模式的实现与优化。在之前的课程里,我们已对观察者模式有了初步认识,本次将在前两次课程的基础上,进一步深入研究,着重解决观察者生命周期问题,提升代码的安全性、灵活性…...

2025年华为手机解锁BL的方法
注:本文是我用老机型测试的,新机型可能不适用 背景 华为官方已经在2018年关闭了申请BL解锁码的通道,所以华为手机已经无法通过官方获取解锁码。最近翻出了一部家里的老手机华为畅玩5X,想着能不能刷个系统玩玩,但是卡…...

在 CentOS 7.9上部署 Oracle 11.2.0.4.0 数据库
目录 在 CentOS 7.9上部署 Oracle 11.2.0.4.0 数据库引言安装常见问题vim粘贴问题 环境情况环境信息安装包下载 初始环境准备关闭 SELinux关闭 firewalld 安装前初始化工作配置主机名安装依赖优化内核参数限制 Oracle 用户的 Shell 权限配置 PAM 模块配置swap创建用户组与用户,…...

idea里的插件spring boot helper 如何使用,有哪些强大的功能,该如何去习惯性的运用这些功能
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

Docker 搭建 Redis 数据库
Docker 搭建 Redis 数据库 前言一、准备工作二、创建 Redis 容器的目录结构三、启动 Redis 容器1. 通过 redis.conf 配置文件设置密码2. 通过 Docker 命令中的 requirepass 参数设置密码 四、Host 网络模式与 Port 映射模式五、检查 Redis 容器状态六、访问 Redis 服务总结 前言…...

JAVAweb之过滤器,监听器
文章目录 过滤器认识生命周期FilterConfigFilterChain过滤器执行顺序应用场景代码 监听器认识ServletContextListenerHttpSessionListenerServletRequestListener代码 过滤器 认识 Java web三大组件之一,与Servlet相似。过滤器是用来拦截请求的,而非处…...

计算机毕业设计SpringBoot+Vue.js足球青训俱乐部管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...
基于 DeepSeek LLM 本地知识库搭建开源方案(AnythingLLM、Cherry、Ragflow、Dify)认知
写在前面 博文内容涉及 基于 Deepseek LLM 的本地知识库搭建使用 ollama 部署 Deepseek-R1 LLM知识库能力通过 Ragflow、Dify 、AnythingLLM、Cherry 提供理解不足小伙伴帮忙指正 😃,生活加油 我站在人潮中央,思考这日日重复的生活。我突然想,…...

QSplashScreen --软件启动前的交互
目录 QSplashScreen 类介绍 使用方式 项目中使用 THPrinterSplashScreen头文件 THPrinterSplashScreen实现代码 使用代码 使用效果 QSplashScreen 类介绍 QSplashScreen 是 Qt 中的一个类,用于显示启动画面。它通常在应用程序启动时显示,以向用户显…...

「软件设计模式」责任链模式(Chain of Responsibility)
深入解析责任链模式:用C打造灵活的请求处理链 引言:当审批流程遇上设计模式 在软件系统中,我们经常会遇到这样的场景:一个请求需要经过多个处理节点的判断,每个节点都有权决定是否处理或传递请求。就像企业的请假审批…...

蓝桥杯嵌入式客观题以及解释
第十一届省赛(大学组) 1.稳压二极管时利用PN节的反向击穿特性制作而成 2.STM32嵌套向量终端控制器NVIC具有可编程的优先等级 16 个 3.一个功能简单但是需要频繁调用的函数,比较适用内联函数 4.模拟/数字转换器的分辨率可以通过输出二进制…...

你对WebAssembly的看法是什么?
WebAssembly(Wasm)是一种新兴的技术,旨在通过提供一种新的低级字节码格式来提高 Web 应用程序的性能和效率。它与 JavaScript 互补,使得开发者可以将其他编程语言(如 C、C、Rust 等)编译为高效的字节码&…...

Qt在Linux嵌入式开发过程中复杂界面滑动时卡顿掉帧问题分析及解决方案
Qt在Linux嵌入式设备开发过程中,由于配置较低,加上没有GPU,我们有时候会遇到有些组件比较多的复杂界面,在滑动时会出现掉帧或卡顿的问题。要讲明白这个问题还得从CPU和GPU的分工说起。 一、硬件层面核心问题根源剖析 CPU&#x…...