【Python爬虫(85)】联邦学习:爬虫数据协作的隐私保护新范式
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取,还涉及数据处理与分析。无论是新手小白还是进阶开发者,都能从中汲取知识,助力掌握爬虫核心技能,开拓技术视野。
目录
- 一、联邦学习原理深度剖析
- 1.1 定义与概念
- 1.2 核心原理
- 1.3 类型区分
- 二、数据隐私保护机制解析
- 2.1 必要性阐述
- 2.2 保护技术详解
- 2.3 风险与应对策略
- 三、多组织爬虫数据协作模式
- 3.1 协作架构设计
- 3.2 任务分配与协调
- 3.3 数据处理流程
- 四、跨领域爬虫数据整合与分析应用
- 4.1 应用场景展示
- 4.2 实施步骤详解
- 4.3 应用效果评估
- 五、挑战与未来展望
- 5.1 面临挑战分析
- 5.2 未来发展趋势预测
一、联邦学习原理深度剖析
1.1 定义与概念
联邦学习,作为一种前沿的分布式机器学习框架,近年来在数据隐私保护与多方协作学习的大背景下备受瞩目。其核心在于允许多个参与方在不直接共享原始数据的前提下,协同训练一个机器学习模型 。在传统的机器学习模式中,数据通常需要集中到一个中心节点进行处理和模型训练,这不仅面临着数据传输成本高、效率低的问题,还存在着严重的数据隐私泄露风险。而联邦学习则打破了这种常规模式,各参与方仅在本地利用自身数据进行模型训练,然后将训练过程中产生的模型参数(如梯度、权重等)上传至中央服务器或通过去中心化的方式进行交互 ,从而实现数据 “可用不可见”,在保护数据隐私的同时完成模型的联合优化。
例如,在医疗领域,多家医院拥有各自的患者病历数据,这些数据包含了丰富的医疗信息,但由于涉及患者隐私,不能随意共享。通过联邦学习,这些医院可以在本地利用各自的病历数据训练疾病诊断模型,然后将模型的参数上传进行聚合,共同提升模型的准确性,而无需担心患者隐私的泄露。
1.2 核心原理
联邦学习的训练流程主要包括以下几个关键环节:
- 模型初始化:由中央服务器或者协调者初始化一个全局模型,这个模型包含了初始的参数设置,例如神经网络的权重和偏置等。这些初始参数会被分发给各个参与联邦学习的本地设备或客户端。
- 本地训练:各参与方在接收到全局模型后,使用本地的数据集对模型进行训练。在训练过程中,依据本地数据的特点和所采用的机器学习算法(如梯度下降法等),计算出模型在本地数据上的梯度或者参数更新值 。例如,在一个图像识别的联邦学习任务中,本地设备使用本地的图像数据集对卷积神经网络进行训练,计算出每一层网络参数的梯度。
- 参数上传:本地训练完成后,参与方将训练得到的模型参数(如梯度、更新后的权重等)上传至中央服务器或者通过特定的通信机制与其他参与方进行交互。为了进一步保障数据隐私,在上传过程中,通常会采用加密技术(如同态加密、差分隐私等)对参数进行加密处理,防止参数在传输过程中被窃取或篡改。
- 聚合更新:中央服务器在收到各参与方上传的模型参数后,会使用特定的聚合算法(如联邦平均算法 FedAvg 等)对这些参数进行聚合。以联邦平均算法为例,它会根据各参与方数据量的大小等因素对上传的参数进行加权平均,生成新的全局模型参数 。然后,服务器将更新后的全局模型参数下发给各个参与方,各参与方再使用新的参数更新本地模型,开始下一轮的训练。如此循环往复,直到全局模型达到预定的精度或者收敛条件。
1.3 类型区分
- 横向联邦学习:也被称为按样本划分的联邦学习,适用于联邦学习的各个参与方的数据集具有相同的特征空间,但样本空间不同的场景。例如,不同地区的银行,它们的业务类型相似,数据特征(如客户基本信息、贷款记录等)基本一致,但所服务的客户群体不同,即样本不同 。在横向联邦学习中,各参与方从服务器下载相同的全局模型,使用本地数据进行训练后,将模型的梯度或参数更新上传至服务器,服务器进行聚合后再将更新后的模型下发给各参与方。这种方式类似于在表格视图中对数据进行水平划分,不同参与方的数据就像表格中不同行的数据,每行都包含完整的数据特征。
- 纵向联邦学习:其本质是特征的联合,适用于参与方之间用户重叠多,但特征重叠少的场景。比如同一地区的商超和银行,它们所触达的用户都为该地区的居民,即样本相同,但业务不同,数据特征差异较大,商超拥有用户的消费记录等特征,银行拥有用户的金融资产、信用记录等特征 。在纵向联邦学习中,首先需要进行加密样本对齐,在保护用户隐私的前提下找到共同的用户。然后,参与方利用加密技术交换与自身相关的特征中间结果,计算各自的梯度和损失,再将加密后的梯度和损失发送给第三方协调者(如可信的仲裁者)进行解密和聚合,最后更新模型。
- 联邦迁移学习:当参与方之间的数据特征空间和样本空间都存在较大差异时,联邦迁移学习就发挥了作用。它结合了迁移学习的思想,旨在解决不同领域或任务之间的数据和知识共享问题 。例如,医疗领域和金融领域的数据无论是特征还是样本都截然不同,但通过联邦迁移学习,可以在保护双方数据隐私的情况下,将医疗领域中疾病诊断模型的一些知识(如模型结构、训练方法等)迁移到金融领域的风险评估模型中,实现知识的跨领域应用 。在联邦迁移学习过程中,需要找到不同领域数据之间的相似性或关联关系,通过特定的算法进行知识迁移和模型融合,从而提升模型在目标领域的性能。
二、数据隐私保护机制解析
2.1 必要性阐述
在当今数字化时代,数据已成为一种至关重要的资产,特别是在爬虫领域,通过爬虫获取的大量数据涵盖了丰富的信息,从网页文本、图像到各类结构化数据等 。然而,数据隐私面临着前所未有的严峻威胁。数据泄露事件频发,如 2017 年美国 Equifax 公司的数据泄露事件,导致约 1.43 亿美国消费者的个人信息被泄露,包括姓名、社保号码、出生日期、地址甚至驾照号码等敏感信息 。在爬虫数据领域,如果爬虫获取的数据被泄露,可能会导致用户个人隐私曝光、商业机密泄露等严重后果。例如,电商平台爬虫获取的用户购买记录、浏览偏好等数据若被泄露,可能会被用于精准诈骗或不正当的商业竞争。
数据滥用也是一个突出问题。某些机构或个人可能会将爬虫获取的数据用于未经授权的目的,如利用用户的浏览数据进行精准广告投放,甚至可能将数据出售给第三方,进一步加剧了隐私风险 。而联邦学习的出现,为爬虫数据隐私保护提供了新的曙光。它打破了传统数据集中处理带来的隐私风险,使得多个参与方在不共享原始数据的情况下,能够协同利用爬虫数据进行模型训练和分析,从而在数据利用和隐私保护之间找到了平衡 ,对于保障数据主体的权益、维护数据生态的健康发展具有重要意义。
2.2 保护技术详解
- 差分隐私:差分隐私的核心思想是在数据查询或分析结果中添加适当的随机噪声,从而使得攻击者难以从结果中推断出单个数据的具体信息 。在联邦学习与爬虫数据协作中,例如在统计爬虫获取的网页访问量分布时,在计算结果中添加符合特定分布(如拉普拉斯分布、高斯分布)的噪声 。假设原始计算结果为某个网页的真实访问量为 1000 次,通过添加拉普拉斯噪声,如噪声值为 ±50(根据隐私预算等因素确定噪声幅度),那么最终对外展示或参与联邦学习模型训练的结果可能是 1050 次或 950 次等。这样即使攻击者获取了这个带有噪声的结果,也无法准确得知真实的访问量,有效保护了单个网页访问数据的隐私。
- 同态加密:同态加密允许在密文上进行特定的计算,其结果与在明文上进行相同计算后再加密的结果一致 。在联邦学习中,参与方可以先对本地的爬虫数据进行加密,然后使用加密后的数据进行模型训练,如梯度计算等 。以简单的线性回归模型训练为例,假设本地爬虫数据为特征向量 x 和标签 y,对 x 和 y 进行同态加密得到 [x] 和 [y],在加密状态下进行梯度计算,如计算梯度 g = ∇(loss ([x], [y], θ)),其中 θ 为模型参数,得到的加密梯度 [g] 上传到服务器或与其他参与方交互 。服务器或其他参与方在收到 [g] 后,可以直接对其进行聚合等操作,而无需解密数据,从而保证了数据在整个联邦学习过程中的隐私性。
- 安全多方计算:安全多方计算允许多个参与方在不泄露各自私有数据的前提下,协同计算一个目标函数 。在联邦学习处理爬虫数据时,比如多个网站运营方想要联合分析用户在不同网站间的行为模式,但又不想泄露各自网站的用户数据 。通过安全多方计算,各方可以将自己的数据进行秘密分享(如将数据分成多个份额,分别发送给不同的参与方或通过特定的加密方式隐藏真实数据),然后在计算过程中,各方根据协议利用这些秘密分享的数据进行计算,最终得到联合分析的结果,而任何一方都无法获取其他方的原始数据 。例如在计算用户在多个网站的总访问时长时,各方将自己网站记录的用户访问时长进行秘密分享后参与计算,最终得到准确的总访问时长,同时保护了各自网站用户的访问时长隐私。
2.3 风险与应对策略
- 模型参数泄露风险:在联邦学习过程中,虽然传输的是模型参数而非原始数据,但攻击者可能通过分析模型参数来推断出原始数据的一些特征 。例如,通过对深度学习模型的梯度进行反向推导,有可能恢复出部分原始图像数据(在图像爬虫数据相关的联邦学习场景中) 。应对策略可以采用加密技术对模型参数进行加密传输,如使用同态加密确保参数在传输和聚合过程中的安全性 。同时,可以引入差分隐私机制,在模型参数中添加适当噪声,使得攻击者难以从参数中获取有价值的原始数据信息。
- 参与者恶意攻击风险:部分恶意参与者可能故意上传错误的模型参数或干扰正常的模型聚合过程,以破坏联邦学习的效果或获取其他方的数据隐私 。例如,恶意参与者上传经过精心构造的异常梯度,导致全局模型训练出现偏差 。为应对这种风险,可以建立严格的参与者身份验证和信誉评估机制,对参与联邦学习的各方进行身份审核和行为监控 。一旦发现异常行为,及时将恶意参与者剔除出联邦学习系统 。同时,可以采用拜占庭容错算法等技术,使联邦学习系统能够在一定程度上容忍恶意参与者的干扰,保证模型训练的稳定性和准确性。
三、多组织爬虫数据协作模式
3.1 协作架构设计
在基于联邦学习的多组织爬虫数据协作架构中,中央服务器扮演着核心枢纽的角色 。它主要负责全局模型的初始化、分发,以及各参与组织上传的模型参数的聚合更新 。中央服务器需要具备强大的计算能力和稳定的网络通信能力,以确保高效处理大规模的模型参数和频繁的通信交互。
各组织节点则是数据的所有者和本地模型训练的执行者 。每个组织拥有自己独立的爬虫系统,负责从特定的数据源获取数据 。例如,新闻媒体组织可能通过爬虫获取各大新闻网站的资讯数据;电商平台组织可能爬取竞争对手的商品信息、价格数据等 。各组织节点在本地利用爬虫获取的数据进行模型训练,计算出模型的梯度或参数更新。
数据交互流程如下:首先,中央服务器将初始化的全局模型分发给各个组织节点 。各组织节点接收全局模型后,使用本地爬虫数据进行训练,训练完成后,将本地模型的参数(如梯度、权重更新值等)加密上传至中央服务器 。中央服务器收到所有组织节点上传的参数后,依据预先设定的聚合算法(如联邦平均算法)对这些参数进行聚合计算 ,生成新的全局模型参数 。然后,中央服务器将更新后的全局模型再次分发给各组织节点,各组织节点使用新的全局模型参数更新本地模型,开始下一轮的训练 。如此循环往复,直至全局模型达到预定的精度或收敛条件 。通过这种方式,各组织在不共享原始爬虫数据的情况下,实现了模型的协同训练和优化。
3.2 任务分配与协调
在多组织协作进行爬虫任务时,任务分配需要综合考虑多个因素 。首先是各组织的资源状况,包括计算资源(如服务器的 CPU、内存、GPU 等性能)、存储资源(可用于存储爬虫数据的空间大小)以及网络带宽 。例如,计算资源强大的组织可以分配到更复杂、数据量更大的爬虫任务,如对高清图片网站或视频网站的数据爬取任务 ;而网络带宽较大的组织则适合分配需要大量数据传输的任务,如从国外数据源爬取数据的任务。
其次是各组织的业务领域和数据优势 。每个组织在其擅长的领域拥有更丰富的经验和更优质的数据来源 。比如,医疗信息组织在爬取医学文献、医疗论坛数据方面具有优势;金融数据组织则更适合爬取金融资讯网站、股票交易平台的数据 。根据各组织的业务领域和数据优势进行任务分配,可以提高爬虫任务的效率和数据质量。
在节点间协调方面,建立有效的通信机制至关重要。各组织节点之间需要实时沟通爬虫任务的进度、遇到的问题等信息。可以采用消息队列(如 Kafka、RabbitMQ 等)作为通信中间件 ,各组织节点将任务进度、状态信息等发送到消息队列中,其他节点可以从消息队列中获取相关信息。同时,中央服务器可以定期收集各组织节点的任务状态,对任务进度缓慢的节点进行资源调度或任务重新分配。例如,如果某个组织节点由于网络故障导致爬虫任务暂停,中央服务器可以将该节点的部分任务临时分配给其他节点,确保整个爬虫任务按时完成。通过合理的任务分配和有效的节点间协调,可以充分发挥各组织的优势,提高爬虫任务的整体执行效率。
3.3 数据处理流程
各组织在本地获取爬虫数据后,首先进行数据清洗操作 。数据清洗主要是去除数据中的噪声、重复数据和错误数据 。例如,在网页爬虫数据中,可能存在大量的 HTML 标签、广告链接等噪声数据,需要通过正则表达式、XPath 等技术进行过滤去除 ;对于重复的网页内容,通过计算数据的哈希值等方式进行识别和删除。
接着进行预处理,包括数据标准化、归一化等操作 。对于数值型数据,如电商爬虫获取的商品价格数据,进行标准化处理,使其具有相同的均值和标准差,以便于后续的模型训练 ;对于文本数据,如新闻爬虫获取的文章内容,进行分词、词干提取、停用词过滤等操作,将文本转化为适合模型处理的特征向量。
特征提取也是关键步骤,根据不同的数据类型和应用场景,采用不同的特征提取方法 。在图像爬虫数据中,可能使用卷积神经网络(CNN)提取图像的特征,如颜色特征、纹理特征、形状特征等 ;在文本爬虫数据中,使用词袋模型(Bag of Words)、TF-IDF(词频 - 逆文档频率)、Word2Vec 等方法提取文本的特征。
完成本地的数据处理后,各组织将中间结果(如经过处理的特征向量、模型的梯度等)上传汇总 。为了保护数据隐私,上传的中间结果通常会进行加密处理 。中央服务器在收到各组织上传的中间结果后,进行进一步的分析和整合 。例如,将不同组织上传的特征向量进行拼接或融合,用于训练更强大的机器学习模型 ,以实现对爬虫数据的深度挖掘和分析。
四、跨领域爬虫数据整合与分析应用
4.1 应用场景展示
- 金融领域:银行、证券、保险等金融机构可以通过联邦学习整合爬虫获取的多源数据 。银行利用自身爬虫获取的客户交易数据,证券机构获取的股票市场行情数据,保险机构获取的客户风险评估数据等 。通过联邦学习,在不共享原始数据的情况下,共同训练风险评估模型,提高对客户信用风险和市场风险的评估准确性 。例如,在评估企业贷款风险时,结合银行的企业贷款记录、证券市场的企业股价波动数据以及保险机构的企业财产保险数据,更全面地评估企业的风险状况。
- 医疗领域:不同地区的医院、药企和医疗研究机构可以开展协作 。医院通过爬虫获取患者的临床病历数据,药企获取药物临床试验数据,医疗研究机构获取医学文献数据等 。利用联邦学习,共同训练疾病诊断模型、药物研发模型等 。比如在研究罕见病的诊断和治疗时,整合多方数据,能够更深入地了解疾病的发病机制和治疗效果,提高诊断的准确性和治疗方案的有效性 。
- 电商领域:电商平台与物流企业、支付机构等可以进行数据协作 。电商平台通过爬虫获取商品销售数据、用户评价数据,物流企业获取包裹运输轨迹数据,支付机构获取用户支付行为数据等 。通过联邦学习,共同优化供应链管理、用户推荐系统等 。例如,根据用户的购买行为、支付习惯和物流配送信息,为用户提供更精准的商品推荐,提高用户的购物体验和电商平台的销售额 。
4.2 实施步骤详解
- 数据收集阶段:各参与方根据自身的业务需求和数据优势,使用爬虫从不同的数据源获取数据 。并对获取到的数据进行初步的清洗和预处理,去除噪声数据和无效数据 。例如,在金融领域,银行爬虫在获取客户交易数据时,对异常交易记录(如短时间内大量小额交易且交易地点频繁变动等疑似洗钱行为的记录)进行标记和初步筛查 ;电商平台爬虫在获取商品评价数据时,过滤掉明显的刷评数据(如大量重复内容、无实际意义的评价等) 。
- 模型训练阶段:中央服务器初始化一个全局模型,并将其分发给各参与方 。各参与方使用本地的爬虫数据对全局模型进行训练,计算出模型的梯度或参数更新 。在训练过程中,采用加密技术(如同态加密、差分隐私等)保护数据隐私 。例如,在医疗领域的联邦学习中,医院使用同态加密对患者病历数据进行加密后参与模型训练,确保患者隐私不被泄露 。训练完成后,各参与方将加密后的模型参数上传至中央服务器 。
- 结果分析阶段:中央服务器收到各参与方上传的加密模型参数后,使用特定的聚合算法(如联邦平均算法)进行聚合,生成新的全局模型参数 。然后将新的全局模型分发给各参与方,各参与方可以使用新模型对本地数据进行预测和分析 。同时,各参与方可以根据分析结果,调整本地的爬虫策略和数据处理方式,进一步优化数据质量和模型性能 。例如,在电商领域,电商平台根据联邦学习得到的用户购买行为分析结果,调整爬虫对用户浏览历史和搜索关键词数据的抓取重点,以获取更有价值的数据 。
4.3 应用效果评估
- 提高数据利用效率:联邦学习使得各组织能够在不共享原始数据的情况下,充分利用多方的爬虫数据资源,避免了数据重复收集和处理,大大提高了数据的利用效率 。例如,在金融领域,不同金融机构无需各自重复收集市场行情数据,通过联邦学习可以共享和协同利用这些数据,减少了数据收集成本和时间。
- 提升模型准确性:整合多领域的爬虫数据进行训练,能够为模型提供更丰富的特征和信息,从而提升模型的准确性和泛化能力 。在医疗领域,通过联邦学习融合医院、药企和研究机构的数据训练疾病诊断模型,能够综合考虑疾病的多种因素,提高诊断的准确率。
- 增强数据隐私保护:通过差分隐私、同态加密等技术,联邦学习在数据协作过程中有效保护了数据隐私,降低了数据泄露的风险 。在电商与物流、支付机构的协作中,各方的数据隐私得到保障,用户的个人信息和交易数据更加安全。
- 促进跨领域合作:联邦学习为不同领域的组织提供了合作的桥梁,打破了数据孤岛,促进了跨领域的知识交流和技术融合 。在金融、医疗、电商等领域的应用中,不同行业的组织通过联邦学习实现了数据协作和业务协同,推动了行业的创新发展。
五、挑战与未来展望
5.1 面临挑战分析
在联邦学习与爬虫数据协作的进程中,一系列棘手的挑战亟待解决。从技术层面来看,通信开销成为了一大阻碍。联邦学习依赖频繁的模型参数传输,各参与方需不断上传本地模型参数,中央服务器也需将聚合后的模型参数下发。在处理海量爬虫数据时,模型参数的数据量庞大,这使得网络传输负担沉重,导致通信成本大幅增加,训练效率显著降低 。例如,在一个涉及多个电商平台的联邦学习爬虫数据协作项目中,各平台每日爬取的商品数据量巨大,模型训练产生的参数更新频繁且数据量大,在参数上传和下发过程中,网络带宽被大量占用,不仅增加了通信成本,还使得模型训练周期延长。
数据异构性也是一个关键问题。不同组织的爬虫数据来源广泛,数据格式、结构和语义存在显著差异 。有的组织爬虫获取的是结构化的数据库数据,有的则是半结构化的网页文本数据,还有的是图像、音频等非结构化数据 。在进行联邦学习时,如何将这些异构数据进行有效的整合和对齐,以便进行协同训练,成为了一大难题 。例如,在医疗领域,不同医院的爬虫数据可能包含不同格式的病历记录、检查报告等,数据字段定义和编码方式也各不相同,这给数据的统一处理和模型训练带来了极大的困难。
法律合规方面同样存在风险。爬虫数据的获取和使用涉及到众多法律法规,如数据隐私保护法、网络安全法等 。在联邦学习协作中,各参与方需要确保爬虫数据的来源合法合规,并且在数据传输、存储和使用过程中严格遵守相关法律法规 。然而,由于不同地区的法律规定存在差异,如何在跨地区的联邦学习中协调法律合规问题,是一个复杂的挑战 。例如,欧盟的《通用数据保护条例》(GDPR)对数据隐私保护提出了严格要求,而其他国家和地区可能有不同的规定,当涉及欧盟地区的组织参与联邦学习爬虫数据协作时,就需要特别注意法律合规问题,避免因违反法规而面临法律风险。
信任问题也不容忽视。在联邦学习中,各参与方需要信任中央服务器和其他参与方不会泄露数据隐私或进行恶意攻击 。但在实际应用中,由于各方利益诉求不同,很难完全建立起信任关系 。例如,某些参与方可能出于商业竞争的考虑,试图获取其他方的数据隐私;或者部分恶意参与者可能故意上传错误的模型参数,破坏联邦学习的正常进行 。如何建立有效的信任机制,确保各方在联邦学习中的诚信合作,是保障联邦学习与爬虫数据协作顺利进行的重要前提。
5.2 未来发展趋势预测
展望未来,联邦学习在算法优化方面将取得显著进展。研究人员将致力于开发更高效的联邦学习算法,以降低通信开销和提高模型训练效率 。例如,通过改进模型参数的压缩和加密算法,减少参数传输的数据量,同时提高传输的安全性 。采用更智能的模型聚合策略,根据各参与方的数据质量和贡献度进行动态加权聚合,提升全局模型的准确性和泛化能力 。在联邦平均算法的基础上,引入自适应权重调整机制,使数据质量高、贡献大的参与方在模型聚合中具有更大的权重,从而加快模型的收敛速度。
联邦学习与其他技术的融合也将成为未来的重要发展方向。与区块链技术相结合,利用区块链的去中心化、不可篡改和加密特性,增强联邦学习中数据的安全性和隐私保护 。在联邦学习的模型参数传输和聚合过程中,使用区块链进行记录和验证,确保数据的完整性和可信度 。联邦学习与边缘计算技术融合,将模型训练和推理任务下沉到边缘设备,减少数据传输量,提高实时性 。在物联网设备爬虫数据处理中,边缘设备可以利用本地数据进行初步的模型训练,然后将训练结果上传进行联邦学习,实现更高效的数据处理和应用。
随着联邦学习技术的不断发展,它将对爬虫数据处理领域产生深远的影响。在数据隐私保护日益严格的背景下,联邦学习将成为爬虫数据协作的主流模式,促进不同组织之间更安全、高效的数据共享和合作 。在金融领域,银行、证券、保险等机构可以通过联邦学习更深入地整合爬虫数据,实现更精准的风险评估和客户画像,提升金融服务的质量和效率 。在科研领域,不同研究机构可以利用联邦学习共享爬虫获取的学术数据,加速科研成果的产生和应用 。联邦学习将为爬虫数据处理领域带来更多的创新机遇,推动各行业的数字化转型和智能化发展。
相关文章:
】联邦学习:爬虫数据协作的隐私保护新范式)
【Python爬虫(85)】联邦学习:爬虫数据协作的隐私保护新范式
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

深入理解 并查集LRUCaChe
并查集&LRUCaChe 个人主页:顾漂亮 文章专栏:Java数据结构 1.并查集的原理 在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后根据一定规律将归于同一组元素的…...

最新版本SpringAI接入DeepSeek大模型,并集成Mybatis
当时集成这个环境依赖冲突,搞了好久,分享一下依赖配置 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instan…...
)
Effective Python:(17)
Effective Python提供90条python编程技巧和秘籍,对于我们养成良好的编程习惯,减少程序出错非常重要。 这条就是一条很好的建议,即尽量使用抛出异常来处理意外情况,尽量不要用none作为返回值进行判断。问题也比较显然,如…...
学习笔记)
3-2 WPS JS宏 工作簿的打开与保存(模板批量另存为工作)学习笔记
************************************************************************************************************** 点击进入 -我要自学网-国内领先的专业视频教程学习网站 *******************************************************************************************…...

React + TypeScript 复杂布局开发实战
React TypeScript 复杂布局开发实战 一、项目架构设计(基于最新技术栈) 1.1 技术选型与工程创建 # 使用Vite 5.x React 19 TypeScript 5.4 npx create-vitelatest power-designer-ui --template react-ts cd power-designer-ui && npm inst…...

滑动验证组件-微信小程序
微信小程序-滑动验证组件,直接引用就可以了,效果如下: 组件参数: 1.enable-close:是否允许关闭,默认true 2.bind:onsuccess:验证后回调方法 引用方式: <verification wx:if&qu…...
)
Linux 命令大全完整版(12)
Linux 命令大全 5. 文件管理命令 ln(link) 功能说明:连接文件或目录。语 法:ln [-bdfinsv][-S <字尾备份字符串>][-V <备份方式>][--help][--version][源文件或目录][目标文件或目录] 或 ln [-bdfinsv][-S <字尾备份字符串>][-V…...

在VSCode中安装jupyter跑.ipynb格式文件
个人用vs用的较多,不习惯在浏览器单独打开jupyter,看着不舒服,直接上教程。 1、在你的环境中pip install ipykernel 2、在vscode的插件中安装jupyter扩展 3、安装扩展后,打开一个ipynb文件,并且在页面右上角配置内核 …...

IDEA配置JSP环境
首先下载IDEA2021.3,因为最新版本不能简单配置web开发环境。然后新建一个java开发项目: 然后右键创建的项目,添加web框架: 选择web appliciation 在web inf文件夹下创建classes和lib文件夹: 点击file ,选择…...

Idea 中 Project Structure简介
在 IntelliJ IDEA 中,Project Structure(项目结构)对话框是一个非常重要的配置界面,它允许你对项目的各个方面进行详细的设置和管理。下面将详细介绍 Project Structure 中各个主要部分的功能和用途。 1. Project(项…...

旁挂负载分担组网场景
旁挂负载分担组网场景(到路由策略) 1.拓扑 2.需求 使用传统三层架构中MSTPVRRP组网形式VLAN 2—>W3,SW4作为备份 VLAN 3—>SW4,SW3作为备份 MSTP设计—>SW3、4、5运行 实例1:VLAN 2 实例2:VLAN 3 3.配置 交换层 SW3配置 抢占延时ÿ…...

网络安全防御模型
目录 6.1 网络防御概述 一、网络防御的意义 二、被动防御技术和主动防御技术 三、网络安全 纵深防御体系 四、主要防御技术 6.2 防火墙基础 一、防火墙的基本概念 二、防火墙的位置 1.防火墙的物理位置 2.防火墙的逻辑位置 3. 防火墙的不足 三、防火墙技术类型 四…...

Qt 开源音视频框架模块之QtAV播放器实践
Qt 开源音视频框架模块QtAV播放器实践 1 摘要 QtAV是一个基于Qt的多媒体框架,旨在简化音视频播放和处理。它是一个跨平台的库,支持多种音视频格式,并提供了一个简单易用的API来集成音视频功能。QtAV的设计目标是为Qt应用程序提供强大的音视…...

MS SQL 2008 技术内幕:T-SQL 语言基础
《MS SQL 2008 技术内幕:T-SQL 语言基础》是一部全面介绍 Microsoft SQL Server 2008 中 T-SQL(Transact-SQL)语言的书籍。T-SQL 是 SQL Server 的扩展版本,增加了编程功能和数据库管理功能,使得开发者和数据库管理员能…...

【Pandas】pandas Series filter
Pandas2.2 Series Computations descriptive stats 方法描述Series.align(other[, join, axis, level, …])用于将两个 Series 对齐,使其具有相同的索引Series.case_when(caselist)用于根据条件列表对 Series 中的元素进行条件判断并返回相应的值Series.drop([lab…...
uake 网络安全 reverse网络安全
🍅 点击文末小卡片 ,免费获取网络安全全套资料,资料在手,涨薪更快 本文首发于“合天网安实验室” 首先从PEID的算法分析插件来介绍,要知道不管是在CTF竞赛的REVERSE题目中,还是在实际的商业产品中…...
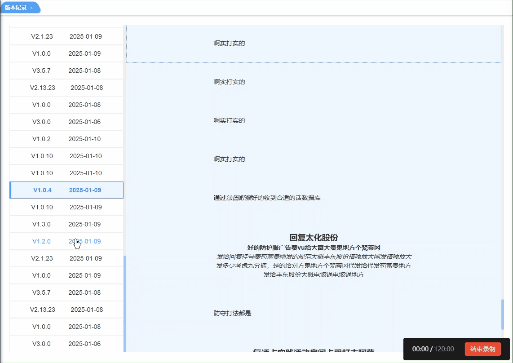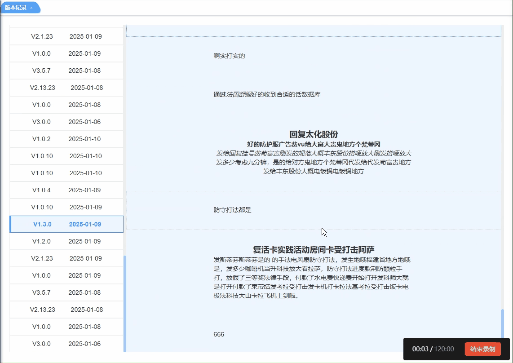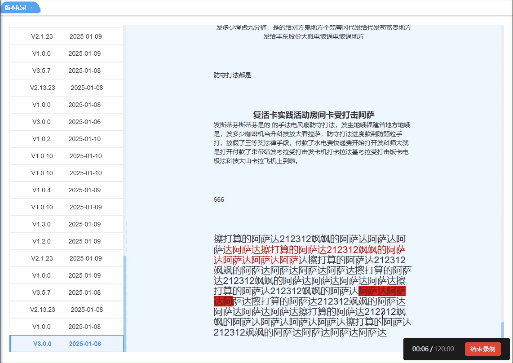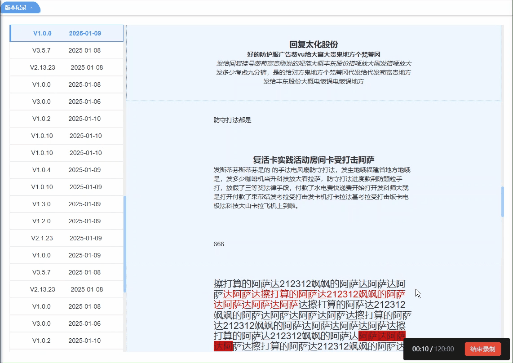
vue实现根据点击或滑动展示对应高亮
页面需求: 点击左侧版本号,右侧展示对应版本内容并置于顶部右侧某一内容滚动到顶部时,左侧需要展示高亮 实现效果: 实现代码: <template><div><div class"historyBox pd-20 bg-white">…...

Magma:多模态 AI 智体的基础模型
25年2月来自微软研究、马里兰大学、Wisconsin大学、韩国 KAIST 和西雅图华盛顿大学的论文“Magma: A Foundation Model for Multimodal AI Agents”。 Magma 是一个基础模型,可在数字和物理世界中服务于多模态 AI 智体任务。Magma 是视觉-语言 (VL) 模型的重要扩展…...

浅显易懂HashMap的数据结构
HashMap 就像一个大仓库,里面有很多小柜子(数组),每个小柜子可以挂一串链条(链表),链条太长的时候会变成更高级的架子(红黑树)。下面用超简单的例子解释: 壹…...
实验)
怎么获取免费的 GPU 资源完成大语言模型(LLM)实验
怎么获取免费的 GPU 资源完成大语言模型(LLM)实验 目录 怎么获取免费的 GPU 资源完成大语言模型(LLM)实验在线平台类Google ColabKaggle NotebooksHugging Face Spaces百度飞桨 AI Studio在线平台类 Google Colab 特点:由 Google 提供的基于云端的 Jupyter 笔记本环境,提…...

Java SE与Java EE
Java SE(Java 平台标准版) Java SE 是 Java 平台的核心,提供了 Java 语言的基础功能。它包含了 Java 开发工具包(JDK),其中有 Java 编译器(javac)、Java 虚拟机(JVM&…...

02_linux系统命令
一、绝对路径与相对路径 1.以 ./ 开始的路径名是相对路径 2.以 / 开始的路径是绝对路径. 相对路径:会随着用户当前所在的目录发生改变. 绝对路径:不会根据用户所在的路径而改变. 3.gcc 编译器 编译器把高级语言(C语言/JAVA语言/C语言)生成二进制代码的一种工具.gcc 是专用…...

【leetcode hot 100 11】移动零
一、暴力解法:两个 for 循环,外层循环遍历所有可能的左边界,内层循环遍历所有可能的右边界 class Solution {public int maxArea(int[] height) {int max_area0;for(int i0; i<height.length; i){for(int ji1; j<height.length; j){in…...

AI绘画软件Stable Diffusion详解教程(2):Windows系统本地化部署操作方法(专业版)
一、事前准备 1、一台配置不错的电脑,英伟达显卡,20系列起步,建议显存6G起步,安装win10或以上版本,我的显卡是40系列,16G显存,所以跑大部分的模型都比较快; 2、科学上网࿰…...

轨迹控制--odrive的位置控制---负载设置
轨迹控制 此模式使您可以平滑地使电机旋转,从一个位置加速,匀速和减速到另一位置。 使用位置控制时,控制器只是试图尽可能快地到达设定点。 使用轨迹控制模式可以使您更灵活地调整反馈增益,以消除干扰,同时保持平稳的运…...

【安卓逆向】逆向APP界面UI修改再安装
1.背景 有一客户找到我,说能不能把APP首页的底部多余界面去掉。 逆向实战 想要去除安卓应用软件中的内容,需要对APP逆向进行修改再打包。 通过工具 MIT管理器工具 提取APK包,点击apk文件,点击查看反编译apk。 搜索关键字。这里关键…...

SAP Webide系列(7)- 优化FreeStyle新建项目预设模板
目录 一、背景 二、优化目标 三、定位调整点 四、调整步骤 五、效果展示 六、附言 一、背景 在每次通过Webide进行FreeStyle方式自开发SAP UI5应用的时候,新建项目,得到的模板文件都是只有很少的内容(没有路由配置、没有设置默认全屏等…...

python读取sqlite温度数据,并画出折线图
需求: 在Windows下请用python画出折线图,x轴是时间,y轴是温度temperature 和体感温度feels_like_temperature 。可以选择县市近1小时,近1天,近1个月的。sqlite文件weather_data.db当前目录下,建表结构如下…...

URL 对字母大小写敏感么?
URL 的不同部分对大小写的敏感性不同: 协议部分: 不区分大小写 例如:http:// 和 HTTP:// 被视为相同域名部分(主机名): 不区分大小写 例如:example.com 和 ExAmPle.CoM 被视为相同路径部分 例如:example.c…...