python量化交易——金融数据管理最佳实践——qteasy创建本地数据源
文章目录
- qteasy金融历史数据管理
- 总体介绍
- 本地数据源——DataSource对象
- 默认数据源
- 查看数据表
- 查看数据源的整体信息
- 最重要的数据表
- 其他的数据表
- 从数据表中获取数据
- 向数据表中添加数据
- 删除数据表 —— 请尽量小心,删除后无法恢复!!
- 总结
qteasy金融历史数据管理
qteasy 是一套功能全面的量化交易工具包,金融数据的获取和使用是qteasy提供的核心功能之一。
总体介绍
目前,网上有很多不同的金融数据获取渠道,可供量化交易者下载金融数据,但是直接从网上下载数据,有许多缺点:
- 数据格式不统一:同样的数据,例如交易量数据,有些渠道提供的数据单位为“手”,而另一些提供的数据为“股”
- 可提取的数据量有限:尤其是通过爬虫获取的数据,高频K线数据往往只有过去几天的数据,更久以前的数据无法提供
- 数据提取不稳定:数据提取速度和成功率不能保证,受网络连接影响很大
- 下载成本较高:收费数据渠道往往能提供更全面的数据,但是一般都有流量限制,而免费渠道提供的数据不全,也提高成本
- 信息提取不易:获得原始数据以后,还需要进一步将数据转化为需要的信息,这个过程费力且不直观
qteasy就是为了解决上面提到的这些痛点而设计的。
qteasy的金融数据管理模块提供了三个主要的功能,这三个功能的设计,着眼点都是为了
-
数据拉取:从多个不同的网络数据提供商拉取多种金融数据,满足不同用户的使用习惯:
qteasy提供的数据拉取API具备强大的多线程并行下载、数据分块下载、下载流量控制和错误延时重试功能,以适应不同数据供应商各种变态的流量限制,同时数据拉取API可以方便地定期自动运行完成数据批量下载任务,不用担心错过高频数据。 -
数据清洗和存储:标准化定义本地数据存储,将从网络拉取的数据清洗、整理后保存到本地数据库中:
qteasy定义了一个专门用于存储金融历史数据的DataSource类,并以标准化的形式预定义了大量金融历史数据存储表,不管数据的来源如何,最终存储的数据始终会被清洗后以统一的格式存储在DataSource中,避免不同时期不同来源的数据产生偏差,确保数据高质量存储。同时提供多种存储引擎,满足不同用户的使用习惯。 -
信息提取和使用:区分“数据“和”信息,“提供接口将集中在数据表中的真正有意义的信息提取出来,从而直接用于交易策略或数据分析:
我们知道”数据“并不等于”信息“,光是将数据表保存在本地不代表立即就能使用其中的信息。而
qteasy特意将数据表中的可用“信息”以标准化的方式定义为DataType对象,简化数据访问过程和策略的定义过程,统一的API使得获取信息的过程变得更加直接和友好
总体来说,qteasy的数据获取模块的结构可以用下面的示意图来表示:

如图所示,qteasy的数据功能分为三层,第一层包括多种数据下载接口,用于从网络数据提供商获取数据,这个过程称为DataFetching。第二层是qteasy的核心功能之一,定义了一个本地数据库用于存储大量的数据表,并且支持多种数据引擎,这一层的核心是DataSource类,第三层是数据应用层,将数据表中有意义的信息提取出来定义为DataType对象,提取数据的过程被称为Information Extraction。而这个DataType对象在qteasy内部被广泛使用,创建交易策略,进行数据分析、可视化等后续的一切工作,都是以DataType对象为基础进行的。
正因为金融数据在量化交易过程中的重要性,从下一章节开始,我们将详细介绍qteasy数据功能的所有功能模块:
- 本地数据源——DataSource对象
- 本地数据源——内置数据表
- 拉取网络数据——从不同的渠道
- 使用本地数据——DataType对象
本地数据源——DataSource对象
本地数据源是qteasy数据管理功能的核心,所有的数据都必须首先下载并保存在本地数据源中,才能为qteasy所用。qteasy使用DataSource对象管理本地数据源,本地数据源类似于一个数据库,包含一系列预先定义的数据表,DataSource类提供了一系列API用于数据表中数据的管理,包括读取、更新、删除和查询其中的数据。
要创建一个新的DataSource对象,可以使用下面的命令:
>>> import qteasy as qt
>>> ds = qt.DataSource()
通过打印DataSource对象,可以查看其最基本的属性:
>>> print(ds)
file://csv@qt_root/data/
从DataSource的打印字符串file://csv@qt_root/data/中,可以看出它的基本属性
打印结果包含数据源对象的基本信息:
file:– 数据源的类型。qteasy支持两种类型的数据源:文件型和数据库型,file代表数据源中的所有数据表都是以文件的形式保存在磁盘上的,同样,数据也可以保存在mysql数据库中,此时数据源的类型代码为db。csv:– 数据文件保存格式。qteasy可以将数据文件以不同的格式保存在磁盘上,最基本的格式为csv文件,但是用户同样可以将数据保存为hdf文件和fth文件(feather文件),以满足不同的性能偏好。qt_root/data/:– 数据文件的保存路径。其中qt_root表示qteasy的安装根路径,默认情况下所有数据文件都保存在根目录下的/data/子路径下
同样,可以创建一个数据保存类型为数据库的数据源对象,并查看其基本属性:
不过,创建类型为数据库的数据源时,需要指定需要连接的Mysql数据库的主机名、用户名、密码、(或者)数据库名称等信息:
>>> ds_db = qt.DataSource(source_type='database', host='localhost', user='您的用户名', password='您的密码', db_name='test_db')
>>> print(ds_db)
db:mysql://localhost@3306/test_db
同样,打印结果中包含数据源的基本信息:
db:mysql– 数据源的类型为mysql数据库,所有的数据表都保存在数据库中localhost– 数据库的主机名3306– 数据库连接端口test_db– 数据库名称,如果不指定名称,默认数据库qt_db,不过这个数据库必须事先创建好
不同的数据源对象,如果它们的存储方式不同,存储路径不同,那么它们所保存的数据没有关系,互不干扰,但如果两个数据源指向同一个路径,且文件类型相同时,那么它们所保存的数据就会重复。
要查看数据源的更多基本属性,可以调用数据源对象的几个属性查看:
>>> print(ds.source_type) # 数据源的类型
file
>>> print(ds_db.source_type)
db
>>> print(ds.file_type, ds.file_path) # 数据源的文件类型和存储路径
csv /Users/jackie/Projects/qteasy/qteasy/data/
>>> print(ds.connection_type, ds_db.connection_type) # 数据源的连接类型
file://csv@qt_root/data/ db:mysql://localhost@3306/test_db
默认数据源
qteasy有一个内置默认的数据源,不需要用户手动创建,默认情况下,所有的数据都会保存到这个默认数据源,并从这个数据源读取。用户可以通过qteasy的配置文件配置该数据源的参数,确保该数据源指向正确的路径或使用正确的用户名登陆正确的数据库。通过下面的方法查看内置默认数据源的属性:
>>> print(qt.QT_DATA_SOURCE)
db:mysql://www.qteasy.online@3306/ts_db
查看数据表
了解数据源对象的基本属性后,下一步可以进一步了解数据源中保存的数据。
数据源中的数据表都是事先定义好的,每一张数据表都保存一类不同的数据,这些数据涵盖沪深股市、期货市场的股票、指数、基金、期货、期权等各种不同投资产品的基本信息、K线行情、上市公司业绩报表、宏观经济数据等等大量的数据,完整的数据表清单介绍,请参见下一章节,这里主要介绍如何查看各种数据表的基本情况和数据。
数据源中的数据表清单可以通过数据源的all_tables属性获取,它会返回一个列表对象,包含数据源中已经预定义的所有数据表。不过,这里必须厘清一个概念,数据源中虽然已经定义好了很多数据表,但这些数据表仅仅是有了基本的定义,即表头信息,数据表的字段名称、每个字段的含义以及数据类型都定义好了,但是刚刚建立的新数据源,其数据表往往都是空的,还没有任何数据。如果要查看数据源中有哪些数据表已经有了数据,需要用get_table_info()函数来获取:
>>> print('All tables in datasource:', len(ds.all_tables))
All tables in datasource: 108
>>> print('Some tables:', ds.all_tables[5:15])
Some tables: ['hk_trade_calendar', 'us_trade_calendar', 'stock_basic', 'hk_stock_basic', 'us_stock_basic', 'stock_names', 'stock_company', 'stk_managers', 'new_share', 'money_flow']
可见,目前版本的qteasy预定义了108张数据表,其中部分数据表的名称包括stock_basic等。
如果要查看当前数据源中某张数据表的详情,例如该数据表的定义,是否包含数据等信息,使用get_table_info()方法获取:
>>> info = ds.get_table_info('stock_basic')
<stock_basic>--<股票基本信息>
852KB/5K records on disc
primary keys:
----------------------------------------
1: ts_code: <5396> entriesstarts: 000001.SZ, end: 920128.BJcolumns of table:
------------------------------------columns dtypes remarks
0 ts_code varchar(9) 证券代码
1 symbol varchar(6) 股票代码
2 name varchar(20) 股票名称
3 area varchar(10) 地域
4 industry varchar(10) 所属行业
5 fullname varchar(50) 股票全称
6 enname varchar(120) 英文全称
7 cnspell varchar(40) 拼音缩写
8 market varchar(6) 市场类型
9 exchange varchar(6) 交易所代码
10 curr_type varchar(6) 交易货币
11 list_status varchar(4) 上市状态
12 list_date date 上市日期
13 delist_date date 退市日期
14 is_hs varchar(2) 是否沪深港通
打印的信息包括数据表的名称、说明、数据表的字段定义以及数据类型。
值得说明的是,如果数据表中已经填充了数据,那么就会显示出数据表目前的大小,在上面的例子中,一些关键信息的解释如下:
852KB/5K records on disc– 表示数据表占用磁盘空间大约852K字节,且数据量大约为5000行primary keys– 显示数据的主键列,这里表示ts_code列为数据表的主键,且该列大约有5396条不同的记录。如果数据表有多个主键,那么每个主键列都分别列出,同时会列出该字段数据的范围,例如上例中ts_code列数据范围就是从000001.SZ开始一直到920128.BJ为止,让我们知道股票基本信息表里包含了代码从000001一直到920128为止的共五千多只股票的信息columns of table– 这里显示数据表的字段定义,也就是数据表的schema。列出每一列的名称columns、数据类型dtypes以及说明信息remarks
另外,get_table_info()方法返回一个dict,同样包含该数据表的信息,可以将这些信息打印出来,与上述格式化信息对照了解:
>>> print(info)
{'table': 'stock_basic', 'table_exists': True, 'table_size': '852KB', 'table_rows': '5K', 'primary_key1': 'ts_code', 'pk_records1': 5396, 'pk_min1': '000001.SZ', 'pk_max1': '920128.BJ', 'primary_key2': None, 'pk_records2': None, 'pk_min2': None, 'pk_max2': None}
查看数据源的整体信息
通过上面的方法,我们可以查看每一张数据表的具体定义和已经填充的数据信息。同样,通过overview()方法,我们可以检查所有的数据表,并汇总出整个数据源的整体信息:
>>> overview = ds.overview()
Analyzing local data source tables... depending on size of tables, it may take a few minutes
[########################################]104/104-100.0% A...zing completed!
Finished analyzing datasource:
file://csv@qt_root/data/
3 table(s) out of 104 contain local data as summary below, to view complete list, print returned DataFrame
===============================tables with local data===============================Has_data Size_on_disk Record_count Record_start Record_end
table
trade_calendar True 1.8MB 70K CFFEX SZSE
stock_basic True 852KB 5K None None
stock_daily True 98.8MB 1.3M 20211112 20241231
查看整个数据源的总体信息,可能需要花费数分钟的时间,因为需要统计每张数据表的所有信息。
在统计过程中,qteasy会显示一根进度条显示统计的进度,最终统计分析完成后,qteasy会将数据源中所有数据表的信息以DataFrame的形式返回,并打印出关键的信息。
上面的信息显示了数据源中有3张数据表已经有了数据,包括trade_calendar、stock_basic和stock_daily,并显示了这些数据表的数据量、占用磁盘空间、数据的起始日期��结束日期等信息。如果想查看所有数据表的信息,可以将返回的DataFrame打印出来:
>>> print(overview)has_data size records pk1 records1 min1 \
table
trade_calendar True 1.8MB 70K cal_date 12865 19901012
hk_trade_calendar False 0 0 cal_date unknown N/A
us_trade_calendar False 0 0 cal_date unknown N/A
stock_basic True 852KB 5K ts_code 5396 000001.SZ
hk_stock_basic False 0 0 ts_code unknown N/A
... ... ... ... ... ... ...
cn_cpi False 0 0 month unknown N/A
cn_ppi False 0 0 month unknown N/A
cn_money False 0 0 month unknown N/A
cn_sf False 0 0 month unknown N/A
cn_pmi False 0 0 month unknown N/A max1 pk2 records2 min2 max2
table
trade_calendar 20251231 exchange 7 CFFEX SZSE
hk_trade_calendar N/A None None None None
us_trade_calendar N/A None None None None
stock_basic 920128.BJ None None None None
hk_stock_basic N/A None None None None
... ... ... ... ... ...
cn_cpi N/A None None None None
cn_ppi N/A None None None None
cn_money N/A None None None None
cn_sf N/A None None None None
cn_pmi N/A None None None None [104 rows x 11 columns]
最重要的数据表
如果您是第一次使用qteasy,很可能数据源中的数据表都是空的,没有任何数据。通常这没有任何问题,因为qteasy的设计初衷就是极大地简化金融数据的获取和使用过程。
您可以非常容易地从网络数据提供商处获取最基本的数据。不过,虽然数据表中的数据可以是空的,但是有几张数据表却比其他的数据表更加重要,您应该优先将这几张数据表的数据填充完整,因为这几张数据表中的数据是很多其他数据表的基础,甚至是qteasy的运行基础:
trade_calendar– 交易日历表,包含了所有交易所的交易日历信息,包括交易日、交易所代码、交易所名称等信息。可以说这是qteasy运行的基础,如果缺了这张表,qteasy的很多功能都将无法运行或者将降低效率。qteasy使用这张表中的数据来判断交易日,如果要下载其他的数据表,通常也必须通过交易日数据表来确定下载的起止日期,因此,这是您应该绝对优先填充的数据表。stock_basic– 股票基本信息表,包含了所有上市股票的基本信息,包括股票代码、股票名称、上市日期、退市日期、所属行业、地域等信息。这张表是很多其他数据表的基础,例如股票日K线数据表、股票财务数据表等,因此,这也是您应该优先填充的数据表。index_basic– 指数基本信息表,包含了所有指数的基本信息,包括指数代码、指数名称、发布日期、退市日期等信息。这张表是很多其他数据表的基础,例如指数日K线数据表、指数成分股表等,因此,这也是您应该优先填充的数据表。fund_basic– 基金基本信息表,包含了所有基金的基本信息,包括基金代码、基金名称、基金类型、基金规模等信息。这张表是很多其他数据表的基础,例如基金日K线数据表、基金净值数据表等,因此,这也是您应该优先填充的数据表。
基本上,如果您能够填充了上面这几张数据表的数据,那么您就可以开始比较顺畅使用qteasy的大部分数据相关的功能了。
另外,qteasy还在数据源中定义了几张系统数据表,这些表一共四张,用于存储跟实盘交易相关的信息:
sys_op_live_accounts– 实盘交易账户信息表,包含了所有实盘交易账户的基本信息,包括账户ID、账户名称、账户类型、账户状态等信息。sys_op_positions– 实盘持仓信息表,包括所有实盘交易账户的持仓信息,包括账户ID、证券代码、证券名称、持仓数量、持仓成本等信息。sys_op_trade_orders– 实盘交易委托表,包括所有实盘交易账户的交易委托信息,包括账户ID、委托时间、委托类型、证券代码、委托数量、委托价格等信息。sys_op_trade_results– 实盘交易成交表,包括所有实盘交易账户的交易成交信息,包括账户ID、成交时间、证券代码、成交数量、成交价格等信息。
上面四张表是qteasy实盘交易功能的基础,这几张表中的数据不需要人为填充,而是系统自动生成,您不需要查看、填充或删除这些表
其他的数据表
除了上面提到的几张重要的数据表之外,数据源中还定义了大量的数据表,这些数据表包含了各种各样的金融数据,包括股票、指数、基金、期货、期权等各种金融产品的基本信息、日K线数据、财务数据、分红数据、业绩报表、宏观经济数据等等,主要分类如下:
- 行情数据表 – 这类数据表包含了股票、基金、指数各个不同频率的K线行情数据
- 基本信息表 – 这类数据表包含了股票、基金、指数、期货、期权等各种金融产品的基本信息
- 指标信息表 – 这类数据表包含了各种指标的信息,例如技术指标、基本面指标、宏观经济指标等
- 财务数据表 – 这类数据表包含了上市公司的财务报表数据,包括资产负债表、利润表、现金流量表等
- 业绩报表表 – 这类数据表包含了上市公司的业绩报表数据,包括业绩快报、业绩预告、业绩预测等
- 分红交易数据表 – 这类数据表包含了上市公司的分红数据,以及股票大宗交易、股东交易等信息表
- 参考数据表 – 这类数据表包含了各种参考数据,例如宏观经济数据、行业数据、交易所数据等
这些数据表的具体定义和数据类型,可以通过get_table_info()方法查看,或者通过本文档的下一章节查询。
从数据表中获取数据
如果数据表中已经填充了数据,那么现在就可以从中读取数据了。DataSource提供了read_table_data()方法,从数据源中直接读取某个数据表中的数据,同时,用户可以筛选数据的起止日期以及证券代码,同时不用考虑数据表的具体结构、存储方式、存储位置等具体的实现方式。
为了避免读取的数据量过大,建议在读取数据时一定要同时给出某些筛选条件。对于read_table_data()方法来说,用户总是可以通过证券代码和起止日期来筛选数据:
shares: 给出一个证券代码或者逗号分隔的多个证券代码,如果数据表的主键中含有证券代码,那么根据该证券代码筛选输出的数据start: 给出一个日期,格式为“YYYYMMDD”,如果数据表的主键包含时间或日期,那么根据筛选start与end之间的数据,start/end必须成对给出end: 给出一个日期,格式为“YYYYMMDD”,如果数据表的主键包含时间或日期,那么根据筛选start与end之间的数据,start/end必须成对给出
DataSource对象会根据输入的筛选条件自动筛选数据,例如:
从stock_daily表中读取一只股票(000651.SZ)从2024年1月1日到2024年1月15日之间的股票日K线数据:
>>> ds.read_table_data(table='stock_daily', shares='000651.SZ', start='20240101', end='20240115')open high low ... pct_chg vol amount
ts_code trade_date ...
000651.SZ 2024-01-03 32.00 32.08 31.70 ... -0.7181 254468.92 810315.0132024-01-04 31.90 32.01 31.45 ... 0.4717 333398.05 1057458.4112024-01-08 33.12 33.21 32.85 ... -0.2426 415911.34 1372722.0502024-01-02 32.17 32.20 31.96 ... -0.4352 253797.30 814257.1752024-01-15 33.45 33.95 33.42 ... 0.6544 295681.34 996815.7252024-01-11 33.66 33.82 33.42 ... -0.2376 284088.74 955075.1002024-01-09 32.81 33.55 32.65 ... 1.7933 438207.66 1454959.6372024-01-10 33.35 33.84 33.28 ... 0.5375 366485.52 1233441.5722024-01-12 33.50 33.83 33.42 ... 0.0893 224012.73 753931.8212024-01-05 32.05 33.29 31.62 ... 3.2238 832156.75 2738167.636[10 rows x 9 columns]
DataSource对象会自动根据数据表的定义来进行正确的筛选,并忽略掉不必要的参数。例如,我们可以筛选出某两支股票的基本信息。对于股票基本信息来说,交易日期是个不必要的参数,此时qteasy会自动忽略掉start/end参数并给出提示信息。同样,shares参数也不一定只能匹配股票代码,对于基金、指数、甚至期货、期权,都可以同样匹配:
>>> ds.read_table_data(table='stock_basic', shares='000651.SZ,000700.SZ', start='20240101', end='20240131')
/Users/jackie/Projects/qteasy/qteasy/database.py:1314: RuntimeWarning: list index out of range
can not find date-like primary key in the table stock_basic!
passed start(2024-01-01) and end(2024-01-31) arguments will be ignored!warnings.warn(msg, RuntimeWarning)symbol name area industry ... list_status list_date delist_date is_hs
ts_code ...
000651.SZ 651 格力电器 广东 家用电器 ... L 19961118 NaN S
000700.SZ 700 模塑科技 江苏 汽车配件 ... L 19970228 NaN S[2 rows x 14 columns]
关于read_table_data()方法的更多信息,请参阅DataSource对象的参考信息。
向数据表中添加数据
如果数据表中尚未填充数据,或者数据表中填充的数据不足以满足我们的需求,那么读取数据就会不成功。为了避免这种情况,我们需要向数据表中填充数据。
向数据表中填充数据可以使用数据源的update_table_data()方法。使用这个API,用户可以将保存在一个DataFrame中的数据写入到相应的数据表中。这个API只需要给出三个参数:
table: 一个数据表的名称,需要写入数据的数据表df: 一个DataFrame,保存了需要写入数据表中的数据merge_type: 如果是update则更新数据表中已经存在的数据,如果是ignore则忽略重复的数据.
使用update_table_data()方法,用户不需要保证写入的数据格式与数据表完全一致,只要数据格式与数据表大致一致,qteasy就会自动整理数据格式、删除重复数据,确保写入数据表中的数据符合要求。
下面将一些示例数据写入数据源(写入的数据仅为演示效果)
>>> import pandas as pd
>>> df = pd.DataFrame({
... 'ts_code': ['000001.SZ', '000002.SZ', '000003.SZ', '000004.SZ', '000005.SZ',
... '000001.SZ', '000002.SZ', '000003.SZ', '000004.SZ', '000005.SZ'],
... 'trade_date': ['20211112', '20211112', '20211112', '20211112', '20211112',
... '20211113', '20211113', '20211113', '20211113', '20211113'],
... 'open': [1., 2., 3., 4., 5., 6., 7., 8., 9., 10.],
... 'high': [2., 3., 4., 5., 6., 7., 8., 9., 10., 1.],
... 'low': [3., 4., 5., 6., 7., 8., 9., 10., 1., 2.],
... 'close': [4., 5., 6., 7., 8., 9., 10., 1., 2., 3.]
... })
>>> print(df)ts_code trade_date open high low close
0 000001.SZ 20211112 1.0 2.0 3.0 4.0
1 000002.SZ 20211112 2.0 3.0 4.0 5.0
2 000003.SZ 20211112 3.0 4.0 5.0 6.0
3 000004.SZ 20211112 4.0 5.0 6.0 7.0
4 000005.SZ 20211112 5.0 6.0 7.0 8.0
5 000001.SZ 20211113 6.0 7.0 8.0 9.0
6 000002.SZ 20211113 7.0 8.0 9.0 10.0
7 000003.SZ 20211113 8.0 9.0 10.0 1.0
8 000004.SZ 20211113 9.0 10.0 1.0 2.0
9 000005.SZ 20211113 10.0 1.0 2.0 3.0
上面的DataFrame中保存了一些示例数据,我们下面将把这个DataFrame的数据写入数据源中的index_daily数据表。
目前我们可以看到,index_daily数据表是空的,而且这个数据表的schema与上面的DataFrame并不完全相同:
index_daily数据表的数据定义中包含11列,而上面的数据只有6列,不过DataFrame中的所有列都包含在index_daily数据表的schema中index_daily数据表目前是空的,没有填充任何数据
>>> info = ds.get_table_info('index_daily')
<index_daily>--<指数日线行情>
0 MB/0 records on disc
primary keys:
----------------------------------------
1: ts_code: <unknown> entriesstarts: N/A, end: N/A
2: trade_date: <unknown> entriesstarts: N/A, end: N/Acolumns of table:
------------------------------------columns dtypes remarks
0 ts_code varchar(20) 证券代码
1 trade_date date 交易日期
2 open float 开盘价
3 high float 最高价
4 low float 最低价
5 close float 收盘价
6 pre_close float 昨收价
7 change float 涨跌额
8 pct_chg float 涨跌幅
9 vol double 成交量(手)
10 amount double 成交额(千元)
接下来我们可以将数据写入数据表,如果方法执行正确,它将返回写入数据表中的数据的行数,如下所示:
>>> ds.update_table_data(table='index_daily', df=df)
10
将数据写入数据表之后,我们可以尝试一下从数据表中读取数据,现在我们已经可以读出刚才写入的数据了。
请注意,读出来的数据有许多列都是NaN值,这表明这些列没有写入数据,原因就是我们写入的df并不包含这些数据,因此读出的数据为NaN值。
>>> df = ds.read_table_data('index_daily', shares='000001.SZ, 000002.SZ')
>>> print(df)open high low close pre_close change pct_chg vol \
ts_code trade_date
000001.SZ 2021-11-12 1.0 2.0 3.0 4.0 NaN NaN NaN NaN
000002.SZ 2021-11-12 2.0 3.0 4.0 5.0 NaN NaN NaN NaN
000001.SZ 2021-11-13 6.0 7.0 8.0 9.0 NaN NaN NaN NaN
000002.SZ 2021-11-13 7.0 8.0 9.0 10.0 NaN NaN NaN NaN amount
ts_code trade_date
000001.SZ 2021-11-12 NaN
000002.SZ 2021-11-12 NaN
000001.SZ 2021-11-13 NaN
000002.SZ 2021-11-13 NaN
删除数据表 —— 请尽量小心,删除后无法恢复!!
我们除了可以向数据表中写入数据,从数据表中读取数据之外,当然也可以删除数据,不过请注意,在qteasy中操作DataSource删除数据时,您务必非常小心:因为qteasy不支持从数据表中删除部分数据,您只能删除整张数据表。
这是因为qteasy的数据源被设计为高效地存储和读取数据,但它并不是一个通常的数据库,我们并不需要经常操作其中的数据,这个数据仓库的作用是为了存储巨量的数据,因此,它的重点在于保存和提取数据,而不是删除操作。
qteasy的DataSource对象提供了一个删除数据表的方法: drop_table_data(),这个方法将删除整个数据表,而且删除后无法恢复!
为了避免在代码中误删除数据表,默认情况下drop_table_data()会导致错误,例如我们想删除之前写入临时数据的index_daily表:
>>> ds.drop_table_data('index_daily')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[19], line 1
----> 1 ds.drop_table_data('index_daily')File ~/Projects/qteasy/qteasy/database.py:1587, in DataSource.drop_table_data(self, table)1584 if not self.allow_drop_table:1585 err = RuntimeError('Can\'t drop table from current datasource according to setting, please check: '1586 'datasource.allow_drop_table')
-> 1587 raise err1589 if self.source_type == 'db':1590 self._drop_db_table(db_table=table)RuntimeError: Can't drop table from current datasource according to setting, please check: datasource.allow_drop_table
这时候我们需要修改数据源的allow_drop_table属性,将其修改为True,这样就可以删除数据表了,请记住删除后将allow_drop_table改为False。
下面代码删除了index_daily表,然后就会发现,无法从该表读取数据了:
>>> ds.allow_drop_table = True
>>> ds.drop_table_data('index_daily')
>>> ds.allow_drop_table = False
>>> df = ds.read_table_data(table='index_daily')
>>> print(df)Empty DataFrame
Columns: []
Index: []
总结
至此,我们已经了解了DataSource对象,qteasy中金融历史数据管理的最重要的核心类的基本工作方式,了解了下面内容:
- 什么是
DataSource,如何创建一个数据源 - 如何从数据源中提取数据
- 如何操作数据源
在后面的章节中,您将会了解更多的内容:
- 数据源中有哪些有用的金融数据?
- 如何批量下载数据并填充到数据源中?
- 如何从数据源中更有效地提取信息?
相关文章:
python量化交易——金融数据管理最佳实践——qteasy创建本地数据源
文章目录 qteasy金融历史数据管理总体介绍本地数据源——DataSource对象默认数据源查看数据表查看数据源的整体信息最重要的数据表其他的数据表 从数据表中获取数据向数据表中添加数据删除数据表 —— 请尽量小心,删除后无法恢复!!总结 qteas…...

Python标准库【os】5 文件和目录操作2
文章目录 8 文件和目录操作8.7 浏览目录下的内容8.8 查看文件或目录的信息8.9 文件状态修改文件标志位文件权限文件所属用户和组其它 8.10 浏览Windows的驱动器、卷、挂载点8.11 系统配置信息 os模块提供了各种操作系统接口。包括环境变量、进程管理、进程调度、文件操作等方面…...

⭐算法OJ⭐矩阵的相关操作【动态规划 + 组合数学】(C++ 实现)Unique Paths 系列
文章目录 62. Unique Paths动态规划思路实现代码复杂度分析 组合数学思路实现代码复杂度分析 63. Unique Paths II动态规划定义状态状态转移方程初始化复杂度分析 优化空间复杂度状态转移方程 62. Unique Paths There is a robot on an m x n grid. The robot is initially lo…...

【Java基础】Java中new一个对象时,JVM到底做了什么?
Java中new一个对象时,JVM到底做了什么? 在Java编程中,new关键字是我们创建对象的最常用方式。但你是否想过,当你写下new MyClass()时,Java虚拟机(JVM)到底在背后做了哪些工作?今天&…...

Baklib云内容中台的核心架构是什么?
云内容中台分层架构解析 现代企业内容管理系统的核心在于构建动态聚合与智能分发的云端中枢。以Baklib为代表的云内容中台采用三层架构设计,其基础层为数据汇聚工具集,通过标准化接口实现多源异构数据的实时采集与清洗,支持从CRM、ERP等业务…...

一个基于vue3的图片瀑布流组件
演示 介绍 基于vue3的瀑布流组件 演示地址: https://wanning-zhou.github.io/vue3-waterfall/ 安装 npm npm install wq-waterfall-vue3yarn yarn add wq-waterfall-vue3pnpm pnpm add wq-waterfall-vue3使用 <template><Waterfall :images"imageList&qu…...

内存中的缓存区
在 Java 的 I/O 流设计中,BufferedInputStream 和 BufferedOutputStream 的“缓冲区”是 内存中的缓存区(具体是 JVM 堆内存的一部分),但它们的作用是优化数据的传输效率,并不是直接操作硬盘和内存之间的缓存。以下是详…...

【pytest框架源码分析一】pluggy源码分析之hook常用方法
简单看一下pytest的源码,其实很多地方是依赖pluggy来实现的。这里我们先看一下pluggy的源码。 pluggy的目录结构如下: 这里主要介绍下_callers.py, _hooks.py, _manager.py,其中_callers.py主要是提供具体调用的功能,_hooks.py提…...

《Kafka 理解: Broker、Topic 和 Partition》
Kafka 核心架构解析:从概念到实践 Kafka 是一个分布式流处理平台,广泛应用于日志收集、实时数据分析和事件驱动架构。本文将从 Kafka 的核心组件、工作原理、实际应用场景等方面进行详细解析,帮助读者深入理解 Kafka 的架构设计及其在大数据领域的重要性。 1. Kafka 的背…...

【AHK】资源管理器自动化办公实例/自动连点设置
此处为一个自动连续点击打开检查的自动化操作案例,没有quicker的鼠键录制,不常用了,做个备份 #MaxThreadsPerHotkey 2 ; 这个是核心!!!!确保可以同时运行多个热键或标签global isRunning : tru…...

在docker容器中运行vllm部署deepseek-r1大模型
# 在本地部署python环境 cd /app/ python -m venv myenv # 激活虚拟环境 source /app/myenv/activate # 要撤销激活一个虚拟环境,请输入: deactivate# 进入虚拟环境安装modelscope pip install modelscope# 下载大模型(7B为例) modelscope do…...
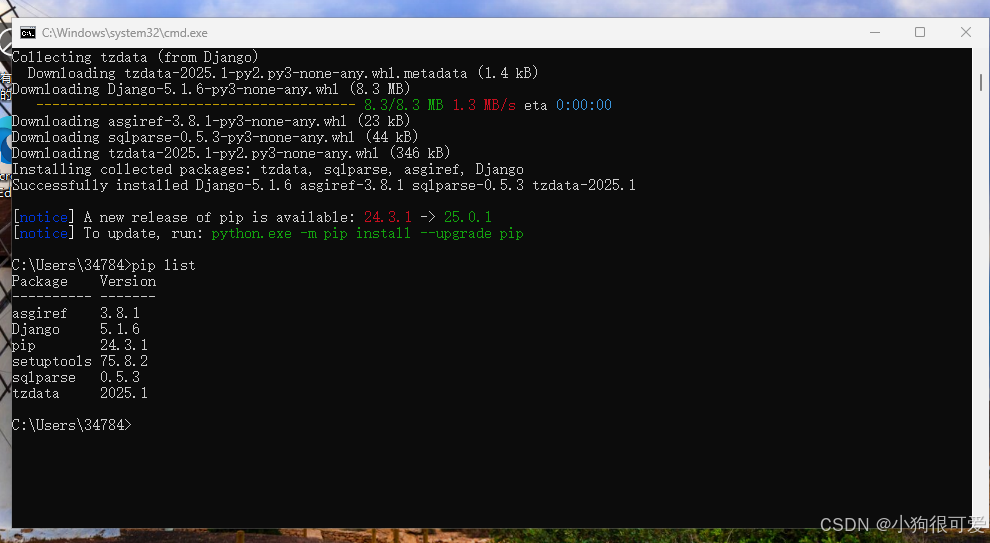
Django基础环境准备
Django基础环境准备 文章目录 Django基础环境准备1.准备的环境 win11系统(运用虚拟环境搭建)1.1详见我的资源win11环境搭建 2.准备python环境2.1 winr 打开命令提示符 输入cmd 进入控制台2.2 输入python --version 查看是否有python环境2.3在pyhton官网下…...

使用DeepSeek实现自动化编程:类的自动生成
目录 简述 1. 通过注释生成C类 1.1 模糊生成 1.2 把控细节,让结果更精准 1.3 让DeepSeek自动生成代码 2. 验证DeepSeek自动生成的代码 2.1 安装SQLite命令行工具 2.2 验证DeepSeek代码 3. 测试代码下载 简述 在现代软件开发中,自动化编程工具如…...

nio使用
NIO : new Input/Output,,在java1.4中引入的一套新的IO操作API,,,旨在替代传统的IO(即BIO:Blocking IO),,,nio提供了更高效的 文件和网络IO的 操作…...

【考试大纲】中级网络工程师考试大纲(最新版与旧版对比)
目录 引言考试科目1:网络工程师基础知识考试科目2:网络工程师应用技术引言 最新的网络工程师考试大纲出版于 2024 年 10 月,本考试大纲基于此版本整理。 考试科目1:网络工程师基础知识 计算机系统知识1.1 计算机硬件知识 1.2 操作系统知识 1.3 系统管理 系统开发和运行…...

Spring的下载与配置
1. 下载spring开发包 下载地址:https://repo.spring.io/webapp/#/artifacts/browse/simple/General/libs-release-local/org/springframework/spring 打开之后可以看到有很多版本供选择,因为视频教程用的是4.2.4版本,于是我也选择这个 右键…...

解决IDEA使用Ctrl + / 注释不规范问题
问题描述: ctrl/ 时,注释缩进和代码规范不一致问题 解决方式 设置->编辑器->代码样式->java->代码生成->注释代码...
学术小助手智能体
学术小助手:开学季的学术领航员 文心智能体平台AgentBuilder | 想象即现实 文心智能体平台AgentBuilder,是百度推出的基于文心大模型的智能体平台,支持广大开发者根据自身行业领域、应用场景,选取不同类型的开发方式,…...

kafka-leader -1问题解决
一. 问题: 在 Kafka 中,leader -1 通常表示分区的领导者副本尚未被选举出来,或者在获取领导者信息时出现了问题。以下是可能导致出现 kafka leader -1 的一些常见原因及相关分析: 1. 副本同步问题: 在 Kafka 集群中&…...

【开源-鸿蒙土拨鼠大理石系统】鸿蒙 HarmonyOS Next App+微信小程序+云平台
✨本人自己开发的开源项目:土拨鼠充电系统 ✨踩坑不易,还希望各位大佬支持一下,在GitHub给我点个 Start ⭐⭐👍👍 ✍GitHub开源项目地址👉:https://github.com/lusson-luo/HarmonyOS-groundhog-…...

HBuilder X中,uni-app、js的延时操作及定时器
完整源码下载 https://download.csdn.net/download/luckyext/90430165 在HBuilder X中,uni-app、js的延时操作及定时器可以用setTimeout和setInterval这两个函数来实现。 1.setTimeout函数用于在指定的毫秒数后执行一次函数。 例如, 2秒后弹出一个提…...

下载pyenv
安装 1、git clone https://gitclone.com/github.com/pyenv/pyenv.git ~/.pyenv 备用:git clone https://hub.fgit.ml/pyenv/pyenv.git ~/.pyenv 配置环境变量 export PYENV_ROOT"$HOME/.pyenv" export PATH"$PYENV_ROOT/bin:$PATH"然后&…...

升级TTSDK抖音小游戏banner广告接入
升级TTSDK抖音小游戏banner广告接入 介绍修改总结 介绍 我们原来使用的是unity2021,这次为了抖音新出的TTSDK中的新的API升级我们将项目升级为了unity2022,这次抖音官方剔除了原来StartSDKUnityTools和Start Asset Analyser(startmini&#x…...

vue 项目部署到nginx 服务器
一 vue 项目打包 1 本地环境 npm run build 2 打包完成生成一个dist 文件夹,将其放到服务器指定的文件夹,此文件夹可以在nginx 配置文件中配置 二 nginx 1 根据对应的系统搜索安装命令 sudo yum install nginx 2 查看conf位置 如果不知道的话 ng…...

ubuntu终端指令集 shell编程基础(一)
磁盘指令 连接与查看:磁盘与 Ubuntu 有两种连接方式;使用ls /dev/sd*查看是否连接成功,通过df系列指令查看磁盘使用信息。若 U 盘已挂载,相关操作可能失败,需用umount取消挂载。磁盘操作:使用sudo fdisk 磁…...

win11编译pytorch cuda128版本流程
Geforce 50xx系显卡最低支持cuda128,torch cu128 release版本目前还没有释放,所以自己基于2.6.0源码自己编译wheel包。 1. 前置条件 1. 使用visual studio installer 安装visual studio 2022,工作负荷选择【使用c的桌面开发】,安装完成后将…...

STM32G431RBT6——(1)芯片命名规则
相信很多新手入门STM学的芯片,是STM32F103C8T6,假如刷到个项目换个芯片类型,就会感到好难啊,看不懂,就无从下手,不知所云。其实没什么难的,对于一个个不同的芯片的区别,就像是学习包…...

mac Homebrew安装、更新失败
我这边使用brew安装git-lfs 一直报这个错: curl: (35) LibreSSL SSL_connect: SSL_ERROR_SYSCALL更新brew update也是报这个错误。最后使用使用大佬提供的脚本进行操作: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/mast…...

Ecode前后端传值
说明 在泛微 E9 系统开发过程中,使用 Ecode 调用后端接口并进行传值是极为常见且关键的操作。在上一篇文章中,我们探讨了 Ecode 调用后端代码的相关内容,本文将深入剖析在 Ecode 中如何向后端传值,以及后端又该如何处理接收这些值…...

Wireshark:自定义类型帧解析
文章目录 1. 前言2. 背景3. 开发 Lua 插件 1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。 2. 背景 Wireshark 不认识用 tcpdump 抓取的数据帧,仔细分析相关代码和数据帧后,…...