Java数据结构_一篇文章了解常用排序_8.1
本文所有排序举例均默认为升序排列。
目录
1. 常见的排序算法
2. 常见排序算法的实现
2.1 插入排序
2.1.1 基本思想:
2.1.2 直接插入排序
2.1.3 希尔排序(缩小增量排序)
2.2 选择排序
2.2.1 基本思想:
2.2.2 直接选择排序
2.2.3 堆排序
2.3 交换排序
2.3.1 冒泡排序
2.3.2 快速排序
1. Hoare版
回答问题:
2. 挖坑法
3. 前后指针法:
2.2.3 快速排序的优化
1. 三数取中法选key
2.递归到比较小的子区间的时候,可以考虑使用插入排序
2.2.4 快速排序的非递归实现:
2.4 归并排序
2.4.1 基本思想
2.4.2 归并排序的非递归实现
2.4.3 海量数据的排序问题
3. 排序算法复杂度及其稳定性分析总结
4. 其他非基于比较排序(了解)
1. 计数排序
2. 基数排序
3. 桶排序
1. 常见的排序算法

2. 常见排序算法的实现
2.1 插入排序
2.1.1 基本思想:
直接插入排序的基本思想:
把待排序的元素,按照其关键码值的大小 逐个插入到一个已经排好序的有序序列中,知道所有的元素插入完为止,从而得到一个有序的序列,实际生活中,就像在整理扑克牌时,就利用了插入排序的思想。
2.1.2 直接插入排序
当插入第 i (i >= 1)个元素的时候,i 前面的元素已经排好序,此时用array[i]与前面的元素进行比较,找到适合的位置插入即可,原来位置上的元素则顺序向后移。
如图:
如果要将下图的数组按照直接插入排序

可定义两个索引变量 i = 1 , j = i - 1,在定义一个临时变量tmp

将下标为 i 的元素先存入tmp中
 然后再将下标为 j 的元素与tmp进行对比,如果array[j] > tmp,则要把下标为 j 的位置让出来,即 array[j + 1] = array[j],同时 j--,继续对比
然后再将下标为 j 的元素与tmp进行对比,如果array[j] > tmp,则要把下标为 j 的位置让出来,即 array[j + 1] = array[j],同时 j--,继续对比

直到 j < 0结束对比,此时 j + 1下标的位置就是最小的元素的下标,再将tmp的值赋给array[j + 1],即
array[j + 1] = tmp

然后 i 继续向后走,j 继续赋值为 i - 1

比较array[j] > tmp,则给tmp让出位置(注意,让出位置的作用的不能在排序过程中损失任何一个元素),array[j + 1] = array[j] ,j--
继续比较array[j] 仍然大于 tmp 继续让位置 array[j + 1] = array[j],j--

当 j < 0的时候,将tmp赋给索引为 j + 1的位置

如此循环,即可实现直接插入排序方法
于是有代码如下:

下面是对直接插入排序方法的分析:

可以在测试类中测试:
在测试类中,先写三个创建数组的方法

然后再main函数中分别调用orderArray,notOrderArray,notOrderArrayRandom和testInsertSort方法,来测试一下排序耗时,从而区别在不同情况下该方法的时间复杂度

也可以用普通用例来测试,是否符合预期:

2.1.3 希尔排序(缩小增量排序)
希尔排序又称缩小增量法。其基本思想是:先选定一个整数,把待排序数组中所有元素分成多个组(距离为那个整数的元素分在同一组内),并对每一组的元素进行排序,然后,再取一个整数,重复上述分组和排序的工作。当取的值达到1的时候,所有的记录在同一组内排好序。
如下图,有一组数据,其初始状态如下:

取整数gap为5,然后将互相距离为5的元素分为一组,然后进行排序

再取整数gap为2,然后再将互相距离为2的元素分为一组,即4 2 5 8 5一组,1 3 9 6 7一组,然后组内进行排序:
然后再取整数gap为1,此时距离为1,即所有的元素都在一组,然后再进行分组,组内排序

问题来了,整数gap的值是如何取的呢?此处为什么是5 2 1呢?This is a question,很多专家对此评判不一:


我们此处代码实现,就按照gap = n / 2的大小来写代码如下:

希尔排序的本质是直接插入排序的一种优化方法,再shell方法中本质上还是直接排序方法,不过是i 和 j 的运动由之前的一个一个变化为了跳跃gap。
普通测试如下:符合预期
时间复杂度测试:

2.2 选择排序
2.2.1 基本思想:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到排序的数据元素排完。
2.2.2 直接选择排序
- 初始状态:整个数组分为有序区和无序区,初始时有序区为空,无序区包含数组的所有元素。
- 第 1 轮选择:在无序区中找到最小的元素,将它与无序区的第一个元素交换位置,此时有序区包含 1 个元素,无序区包含
n - 1个元素。 - 第 2 轮选择:在剩余的无序区中找到最小的元素,将它与无序区的第一个元素交换位置,此时有序区包含 2 个元素,无序区包含
n - 2个元素。 - 重复上述步骤,直到无序区为空,此时整个数组就有序了。
如下图,如何将其以直接选择排序的方式进行排序

定义下标i , j , minIndex 
然后将 j 逐步向后加加,比较array[j] 与 array[minIndex]的大小,如果array[j] < array[minIndex],则交换对应的值一直 j 遍历完整个数组后

进行交换

i++,继续寻找下一个最小的元素。最终使得数组称为升序。





于是有代码如下:

测试符合预期:

复杂度:

选择排序方法中,还有一种优化后的方法:

让 i 向后遍历数组,如果array[i] < array[minIndex] 则把 i 赋给minIndex,如果array[i] > array[maxIndex],则把 i 赋给maxIndex,这样 i 遍历一次之后,就能知道最大和最小的值了,然后然后将对应最大和最小的值分别放在索引为right 和 left 的位置,然后left++,right--
于是有代码如下:

但是在Test测试类中,发现结果不符合预期:

是因为还存在一种逻辑错误,当最大元素的初始位置,恰好是left时候,在将最小元素交换到left位置之后,最大元素就被换到了minIndex位置,后序代码再将索引为right和索引为maxIndex(还是原来的left位置)进行交换,就会导致结果错误。
如下图,minIndex = 3,maxIndex = 0
先将left和minIndex元素交换
再将right与maxIndex的元素交换时,maxIndex索引指向的元素已经不是最大值了,出现逻辑错误。
应该进行改正:在minIndex和left进行交换后,加一个if判断条件:if(maxIndex == left) maxIndex = minIndex
完整代码如下:

测试符合预期:
2.2.3 堆排序
堆排序(Heapsort) 是指利用堆这种数据结构所设计的一种排序算法。注意的是:排升序要建大根堆,排降序要建小根堆。
在堆中已经学习,此处仅做代码复习:

测试符合预期:

时间测试:

2.3 交换排序
基本思想:根据序列中两个记录键值的比较结果来兑换两个记录在序列中的位置。
2.3.1 冒泡排序
简单,仅作代码展示

2.3.2 快速排序
Hoare于1962年提出的一种二叉树结构的交换排序方法,基本思想:任取待排序元素中的某元素作为基准值,按照该基准值将排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右序列重复该过程,知道所有元素都排列在相应位置上为止。
大致框架:

1. Hoare版
举例说明:
如下面这个数组

定义一个left,一个right

Key对应的元素是6,然后先从后面right开始,找比6小的元素,再从前面left开始,找比6大的元素

找到之后,交换其值

再继续找

找到之后,再交换值

直到left和right相遇之后

将相遇的这个索引的数值和6进行交换

换完之后,会发现,6左边的元素都是比6小的值,6右边的元素都是比6大的值
此时称6为privot(基准)
 然后再以上面的方法,分而治之,即再在6的左边,和6的右边进行上述操作
然后再以上面的方法,分而治之,即再在6的左边,和6的右边进行上述操作
例如:在左边,Key为3

再先从right开始,找比3小的元素,找到2,再从左边left出发找比3大的元素,发现会相遇

在拿相遇时候的值和3进行交换

此时3又是新的基准

再对3的左边进行操作,有新的left和right

先从right找比2小的--1,再从left找比2大的,与right相遇

相遇的值与2进行交换

此时2有序了,左侧只有一个元素,1也有序了。

再对3的右树进行操作:操作过后,4,5交换位置,这样6的左树就全部有序了

大致操作过程,也是很像二叉树的递归过程
第一次找到privot6

然后对6的左树递归
再对3的左树递归

再逐层向下递归
然后再递归3的右树,再递归6的右树等等,所以重点在于,如何确定基准privot的位置。
可以先将大致框架搭建起来,为了保持和前面排序方法参数的一致性,所以再quickSort方法中添加了quic方法。再quick中不断调用partition方法。

假设已经partition方法已经完成,在quick方法中,如何不断递归呢?
因为在后面过程中,不断进行变化的是left和right,这里start和end的位置并没有发生变化。

还要思考的是:递归结束的条件是什么呢?
可以回忆在递归二叉树的时候结束的条件:
当没有左右子树,或者只有左右子树一棵树的条件: start >= end。

如何在partition方法中找到partition呢?

再想一下,刚刚模拟的过程,首先明白,当left和right相遇的时候,要把第一个元素key来存起来,然后就是先从right位置找比6小的元素(为什么要先从right开始走呢?这里提出一个问题,后面解决),当从right位置找到比6小的元素之后,再从left位置找到比6大的元素,然后进行交换,然后left++,right--,直到left和right相遇,于是有代码如下:(在array[right] >= key中 为什么要加上等于呢?这里是第二个问题)

但是,注意上面的代码会出现越界的问题,在219和224中的while循环中,可能会出现越界错误,比如219中,如果right从后面开始,逐渐--的过程中,后面的元素的值都是比key大的元素,则right会一直--,会出现越界情况,224中如果left从前面开始,逐渐++的过程中,元素的值都是比key小的元素,则left会一直++,也会出现越界的情况,所以此时要再加一个条件。

上面代码一直执行217中的while循环,直到left和right相遇之后,就要交换相遇位置和最开始key值的位置了,但是有一个问题是,最开始的key位置是通过left定位的,left已经++到了后面,无法再找到6的下标索引,所以应该在最开始再定义一个遍历来存一下key的下标索引。

即定义一个 i 存储最开始的key位置的下标索引,然后当相遇跳出循环后,再交换left/right 与 i ,最后返回 left/right。
完整代码为:

测试符合预期:

分析时间复杂度和空间复杂度:
如果数组的顺序是 1 2 3 4 5 6.......等等,那此时的时间复杂度是最坏情况,因为此时right右边都是比key大的元素,一直到最左边与left相遇,这样就会称为只有一侧的单分支树,此时时间复杂度为O(N ^ 2)

最好情况,就是在partition方法中,每次分割都能分割称完全二叉树 / 满二叉树,此时的时间复杂度为O(N * logN)

同样的空间复杂度也分最好情况:O(logN) 满二叉树 / 完全二叉树
最坏情况:O(N) 单分支的树
总结:
再创建100000数据来测试时间:
却发现出现异常了,自行研究发现是栈溢出异常,则发现,当创建顺序和逆序的数组时候,空间复杂度为O(N),10000个数据导致栈溢出。后面会有优化的方法!

回答问题:
一:为什么要right先开始从后往前找比key小的元素,也就是说:为什么不可以先从left开始,找比key大的元素?可以尝试一下,如果先从left开始找,结果是什么


left继续向后走,找比6大的元素,是9,此刻正好与right相遇,则交换此时left下标索引的值与key下标索引的值
会发现,如果先left后right的话,会导致,left和right相遇的数字是比6大的数字,导致交换后,6左边的元素,并不是都比6大的元素。
二:下面框住的地方为什么是等于号
这里可以举出两种反例,来证明取等号的重要性:
一:如果数组为[3,3,1,3,4],right开始找,如果不取等号,即array[right] > key,right--,则right会在倒数第二个元素,即下标索引为3的位置停止。之后,left开始找,如果left也不取等号,即array[left] < key,left++,则left会在第一个元素,即下标索引位置为0的位置停止。然后执行swap代码,但是发现,left和right指向的元素都大小都是3,交换之后没有意义,且,代码会陷入死循环,一直交换这两个相同的3。
二:如果数组为[5,5,5,5,5],则代码更是会陷入死循环,无法跳出while(left < right) 的循环,无法返回left。
2. 挖坑法
还是这个例子:

挖坑法,顾名思义,是会挖出一个一个空的,会首先将key的值单独存起来(相当于挖了一个坑),然后从right开始找比key小的元素,找到后,把该索引的值填入给key的下标索引中
如图:先将6存起来

然后right找到比6小的元素5

把5覆盖到6的位置,同时之前5的位置相当于又留了一个坑

left向前走,找到比6大的元素的下标索引
把7填到刚刚5留下的坑的位置,同时7也留下了新的坑
right继续向前找到比6小的元素

把4填到刚刚7留下的坑,同时4也留下了新的坑

left继续向后找到比6大的元素,9把刚刚4留下的坑填入,留下新的坑

right继续向前找到比6小的元素,3把刚刚9留下的坑填入,留下新的坑

left向后走,和right相遇,相遇位置是空的坑,将最开始记录下的6填入
完成一次排序,返回基准值,然后进行递归,挖坑法的大致流程和Hoare法相同,但在细节和每一次的排序结果中有所不同。
于是代码实现为:
3. 前后指针法:
这个直接用代码来理解思想即可:

起始时,prev指针指向序列的开头,cur指针指向prev指针的后一个位置

示例与代码结合,示例满足286行循环,进入循环,287行中array[cur] <= array[left],示例中array[cur] 等于1,array[left] 等于6, 满足条件,再看array[++prev] != array[cur] array[++prev]等于1,array[cur] 等于1,两个值相等,不满足if条件,不进入循环,cur直接++

cur++后,cur仍小于等于right,继续进入循环,仍不满足if的第二个条件,直接cur++
继续进入循环,此时情况不满足if的第一个条件,直接cur++,注意此时因为不满足第一个if条件,就不会进入if的第二个条件,所以prev不会执行前置++
继续进入循环,此时情况不满足if的第一个条件,直接cur++,prev仍然不会执行前置++ 此时进入循环,if的两个条件都满足,且在第二个条件的时候,prev是的位置也进行了变化
此时进入循环,if的两个条件都满足,且在第二个条件的时候,prev是的位置也进行了变化

进入if循环,交换cur和prev的值
然后cur++

继续向后推进,if的两个条件都满足,在满足第二个条件的时候,prev的位置继续进行变化
进入if条件,进行swap交换
cur++

进入循环,满足if的两个条件,prev先前置++

再swap交换

cur++
再进入循环,不满足if的第一个条件,prev不前置++,不交换,cur++

此时cur 等于 right 还可以进入循环,不满足if的第一个条件,prev不前置++,不交换

此时cur > right 无法进入循环,再交换left和prev的值
prev的位置作为基准进行返回,这就是一次前后指针的过程
前后指针方法的特点是:使用单指针进行扫描:cur指针从左到右扫描数组,同时利用prev指针标记小于基准元素区域的边界,通过条件判断和交换操作完成分区。
2.2.3 快速排序的优化
在刚刚的方法中,无论是Hoare法,挖坑法,或者前后指针法,都会出现最坏情况,使得在排序的时候出现“单分支树”的情况,导致栈溢出的异常,如何进行优化呢?
栈溢出,就是因为树的高度太多了,想办法优化,就是降低需要的空间,就是要降低树的高度
即尽量使得单分支树 变为 满 / 完全二叉树

1. 三数取中法选key
如下图数据:

如果直接进行快速排序,则会形成单分支树。
可以对下标索引进行操作,找到位于 left 和 right 的中间位置索引mid

对比left mid right 三个下标索引对应的元素值 5 7 9, 比较这三个值的大小,判断哪一个的大小位于这三个值的中间位置,即7是5 7 9 三个元素的中间,然后7的位置和left进行交换
这样7就称为了新的key值,在每次递归前,先进行上面操作,这样进行快速排序的时候,不会出现单分支树的情况了。
代码实现:
这是在三个下标对应的元素取出元素值为中间值的下标的方法
然后在quick方法中应用:

如果将数据量减少未1 0000 个,未优化时候,的耗时是如下

优化后的耗时为

优化之后,耗时是减少了,但如果数据量是10_0000,仍然会像未优化一样,出现栈溢出的异常,这其实是因为IDEA集成开发环境导致的,IDEA的默认运行栈的大小是比较小的,所以优化后也会溢出,可以手动设置一下。
教程:(不同IDEA版本的教程有所不同,我使用的是2024.1版本,比较新,CSDN可以找到略旧版本的设置)


然后再多出来的框中设置即可 -Xss + 想要修改的大小 再调整栈大小为3m之后,在将三数取中法屏蔽后,仍然会出现栈溢出的异常:
再调整栈大小为3m之后,在将三数取中法屏蔽后,仍然会出现栈溢出的异常:
但如果使用了三数取中法之后,就发现可以正常运行10_0000个数据量了
的确证明我们的三数取中法是可以对快速排序法的时间和空间复杂度进行优化的。
2.递归到比较小的子区间的时候,可以考虑使用插入排序
什么叫递归到比较小的子区间呢?
对于一棵满 / 完全二叉树来说,最后两层的结点的总数,一般是较多的,占了整棵树的 2 / 3

但是在递归创建的时候,最后两层所占用的空间也是最多的。在快速排序中,是利用树的递归思想不断在进行排序,越递归到后面,即递归到比较小的子区间的时候,其实是到最后已经大致有序了,我们又直到,直接插入排序方法在对大致有序的数组进行排序时候,其效率较高。
所以,我们可以在进行快速排序的过程中,当递归到比较小的子区间的时候,使用插入排序。
代码如下:end - start + 1 <= 15 代表 当前子数组中包含的元素总数,当子数组中包含的元素总数小于15的时候,就可以使用直接插入排序方法,减少递归的次数

区间进行快速排序代码:

2.2.4 快速排序的非递归实现:
理解思想即可:

在新的基准操作的时候,入栈的时候先入left再入right,操作的时候,仍然先操作右边,再操作左边



代码实现:

解释:


-
调用
partition方法对整个数组进行分区,得到基准元素的最终位置piovt。 -
如果基准元素左边的子数组元素个数大于 1(即
piovt - 1 > left),将该子数组的左右边界(left和piovt - 1)依次压入栈中。 -
如果基准元素右边的子数组元素个数大于 1(即
piovt + 1 < right),将该子数组的左右边界(piovt + 1和right)依次压入栈中。 -

2.4 归并排序
2.4.1 基本思想
归并排序 是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个典型应用。将
已有的子序列合并,得到完全有序的序列:即先使每个子序列有序,再使子序列之间有序。
若将两个有序表合并成一个有序表,称为二路归并。步骤如下:

分步详解:
有如下数组:
对其先进行分解(先分解左边 再 分解右边 最后合并)
第一次分解 以中间的m的索引 作为新的数组的r进行分解

再向下进行分解

继续分解,直到r == l的时候分解完毕

分解完毕后,再进行合并
分解很简单,就一直向下递归即可
如何将两个序列段进行合并呢?
以如下图的两个有序段(6,10 和 1, 7)举例,对两个序列段分别定义s 和 e,来表示第一个和第二个序列端的开始和合并

因为要合并到一个新的数组,所以应该计算两个序列段的元素个数,即 3 - 0 + 1 = 4,申请一个长度为4的数组来存放合并后的序列。然后每次让s1和s2进行比较,谁小,谁放入数组中,对应的s++,e是一个结束的位置,如果有一个数组的s逐渐向后递归,直到其有一个数组没有元素了,则说明另一个数组的值都大于另一个数组的最大的值,直接将剩下的数组全部按顺序放入即可。
代码如下:
首先为了同一参数为int [] 则提供一个接口mergeSort,然后再mergeSortFunc方法中进行递归的操作,再有一个merge方法进行合并的操作

合并方法的代码如下:

上面的归并排序是严格的二分法,时间复杂度为O(N * logN),空间复杂度为O(N)
稳定性分析:按照上述的合并代码

当array[s2] == array[s1]的时候,就会将s2索引的值插入,会破坏稳定性,但如果不取等号的话,就不会提前将s2的索引值插入,就是稳定的了。所以归并排序是稳定的排序。
测试符合预期:

2.4.2 归并排序的非递归实现
归并排序的核心思想是分治法,将一个大问题分解为多个小问题,分别解决小问题后再将结果合并。非递归的归并排序通过迭代的方式,从最小的子数组开始逐步合并,直到整个数组有序。具体步骤是先将数组看作多个长度为 1 的子数组,两两合并成长度为 2 的子数组,再将长度为 2 的子数组合并成长度为 4 的子数组,以此类推,直到合并成一个完整的有序数组。

代码实现如下图:

为什么可能会出现mid和right越界的情况呢?
当 i 走到1下标索引的位置,此时mid 如果继续等于 left + gap - 1就会越界,此时mid应该修正位置为array.length - 1

right呢?当最后剩的元素不够一组的长度的时候,此时right = mid + gap会越界,也需要修正位置为array.length - 1
2.4.3 海量数据的排序问题
外部排序:排序过程需要在磁盘等等外部存储的排序
前提:内容比较小,例如只有1G,但需要排序的数据远远大于内存,比如有100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,归并排序是最常用的外部排序
- 先把文件分成200份,每一份512M
- 分别对512M进行排序,此时内存以及可以放的下,任意排序方式都可以
- 进行2路归并,同时对200分有序文件做归并过程,最终得到有序的结果
大致过程如下图:

3. 排序算法复杂度及其稳定性分析总结


4. 其他非基于比较排序(了解)
1. 计数排序
思想:计数排序又称为鸽巢原理,操作步骤:
- 统计相同元素出现的次数
- 根据统计的结果将序列回收到原来的序列中
举例如下图:
技术排序要先申请一个计数数组
然后对序列段进行遍历,把对应出现的数据 出现的次数 再计数数组当中进行记录

然后 i 向后走,重复上面的操作
最终计数数组的状态为:

然后遍历计数数组,如果在计数数组中值为0 说明未出现数据 重新写回数据
即索引为1的值为2,说明有需要排序的序列段中有两个1,最终结果为:1 1 2 2 3 3 4 4 4 6 7 7 8 9
那如何实现呢?在实现前,需要解决问题:第一步中,申请一个计数数组,那数组的长度该如何确定呢?如果10个数据的大小集中在 90 - 100 之间,总不可能为10个数据申请一个大小为100的数组,可以用序列段中的最大值max - 最小值min + 1 来确定数组的长度,注意:申请的计数数组值是用来统计数据出现的个数。
于是有代码如下:

对 - minVal 和 + minVal的解释:
效率研究如下:

计数排序的使用场景十分有限,适用于序列段的范围较为集中的情况。
2. 基数排序
1.10 基数排序 | 菜鸟教程
此处仅进行思想理解:
举例如下图:

要利用基数排序对其进行排序,因为上面序列段均是十进制的数据,由 0 - 9 是个数字组成,创建 0 - 9 十个数组

然后将按照序列段中数据的个位的值来分别进入十个数组,如下图:

再按照顺序出各个数组:如果有两个数据在同一个数组,遵循先进先出原则

这样一趟排序,数据都个位有序了
然后将按照上面出来的顺序中数据的十位的值来分别进入十个数组

再按照顺序出数组,同样的,如果一个数组中有多个数据,按照先进先出的原则,下面的数据就个位和十位都是有序的了

然后将按照上面出来的顺序中数据的百位的值来分别进入十个数组
然后再出数组得到的结果是 :96 101 109 200 336 457 517 883,这样就把十个数据排列好了,数据一共进出了数组三次(最大数据的位数是3位)。0 - 9 这十个数组进出是根据先进先出原则,是一个队列数组...
3. 桶排序
【排序】图解桶排序-CSDN博客

完...
相关文章:
Java数据结构_一篇文章了解常用排序_8.1
本文所有排序举例均默认为升序排列。 目录 1. 常见的排序算法 2. 常见排序算法的实现 2.1 插入排序 2.1.1 基本思想: 2.1.2 直接插入排序 2.1.3 希尔排序(缩小增量排序) 2.2 选择排序 2.2.1 基本思想: 2.2.2 直接选择排…...

(南京观海微电子)——倍压设计与应用
在电路设计过程中,当后级需要的电压比前级高出数倍而所需要的电流并不是很大时,就可以使用倍压整流电路。倍压整流:可以将较低的交流电压,用耐压较高的整流二极管和电容器,“整”出一个较高的直流电压。 01 倍压整流电…...

AtCoder Beginner Contest AT_abc395_d ABC395D Pigeon Swap 题解
前言 在谎言中迷茫,试图躲避瓶颈。 可惜细节太多,浪费五发罚时。 一个绿名用户,被出题人卡住。 八十六分钟多,才看见一抹绿。 本题解 LaTeX \LaTeX LATEX 格式可能不太美观,以内容为主。 题目大意 有一群鸽子和它…...

网络安全-使用DeepSeek来获取sqlmap的攻击payload
文章目录 概述DeepSeek使用创建示例数据库创建API测试sqlmap部分日志参考 概述 今天来使用DeepSeek做安全测试,看看在有思路的情况下实现的快不快。 DeepSeek使用 我有一个思路,想要测试sqlmap工具如何dump数据库的: 连接mysql数据库&#…...

【含文档+PPT+源码】基于SpringBoot+Vue医药知识学习与分享平台的设计与实现
项目介绍 本课程演示的是一款 基于SpringBootVue医药知识学习与分享平台的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署…...

coze生成的工作流,发布后,利用cmd命令行执行。可以定时发日报,周报等。让他总结你飞书里面的表格。都可以
coze生成的工作流,发布后,利用cmd命令行执行。可以定时发日报,周报等。让他总结你飞书里面的表格。都可以。 很简单。 准备工作,先发布你的工作流,和发布应用。 然后,点击扣子API 。 申请一个࿰…...

iOS for...in 循环
0x00 循环遍历一 输出结果是什么? NSMutableArray *marr [1, 2, 3].mutableCopy; for (NSNumber *number in marr) {NSLog("%", number);marr [4, 5, 6].mutableCopy; } NSLog("%", marr);0x01 循环遍历二 输出结果是什么? NS…...

《操作系统 - 清华大学》 9 -1:进程调度:背景
进程调度:基础概念与调度策略详解 在进程调度这部分,我们会涉及以下内容:背景介绍、各种各样的调度算法(包括通用操作系统的调度算法以及针对实时系统的算法),还会额外介绍一种调度算法。 一、CPU调度的背…...

NumPy的介绍
第四章:NumPy 基础 一 NumPy是什么 NumPy 数字集装箱 超级计算器。 NumPy 就像一台超级计算器,但它的计算对象不是简单的数字,而是成百上千个数字组成的「数字表格」。 假设你要统计全班 50 个同学的身高、体重、成绩,手动计算…...

【Python】基础语法三
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解Python的函数、列表和数组。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! > 专栏选自ÿ…...

使用 Spring Boot 和 Keycloak 的 OAuth2 快速指南
1. 概述 本教程是关于使用 Spring Boot 和 Keycloak 通过 OAuth2 配置后端的。 我们将使用 Keycloak 作为 OpenID 提供程序。我们可以将其视为负责身份验证和用户数据(角色、配置文件、联系信息等)的用户服务。它是最完整的 OpenID Connect ࿰…...

第三十六:6.6. 【$refs、$parent】
概述: $refs用于 :父→子。 $parent用于:子→父。 // 向外部提供数据 defineExpose({house}) 原理如下: 属性说明$refs值为对象,包含所有被ref属性标识的DOM元素或组件实例。$parent值为对象,当前组件…...

【源码】【Java并发】【线程池】邀请您从0-1阅读ThreadPoolExecutor源码
👋hi,我不是一名外包公司的员工,也不会偷吃茶水间的零食,我的梦想是能写高端CRUD 🔥 2025本人正在沉淀中… 博客更新速度 👍 欢迎点赞、收藏、关注,跟上我的更新节奏 📚欢迎订阅专栏…...

【开源免费】基于SpringBoot+Vue.JS网络海鲜市场系统(JAVA毕业设计)
本文项目编号 T 222 ,文末自助获取源码 \color{red}{T222,文末自助获取源码} T222,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

抽象工厂模式:思考与解读
原文地址:抽象工厂模式:思考与解读 更多内容请关注: 引言 你是否曾经在开发系统时,需要创建一系列相关的对象,而这些对象需要共同协作并保持一致性?假设你有多个不同的产品类型,但它们需要在系统中一起工…...

【综合项目】api系统——基于Node.js、express、mysql等技术
目录 0 前言 1 初始化 2 注册登录 2.1 注册 2.1.1 功能:密码加密(2.3.3) 2.1.1.1 操作 2.1.1.2 bcryptjs详解 2.1.2 插入新用户(2.3.4) 2.1.3 优化:表单数据验证(2.5) …...

Go中slice和map引用传递误区
背景 关于slice和map是指传递还是引用传递,很多文章都分析得模棱两可,其实在Go中只有值传递,但是很多情况下是因为分不清slice和map的底层实现,所以导致很多人在这一块产生疑惑,下面通过代码案例分析slice和map到底是…...

C++ ++++++++++
初始C 注释 变量 常量 关键字 标识符命名规则 数据类型 C规定在创建一个变量或者常量时,必须要指定出相应的数据类型,否则无法给变量分配内存 整型 sizeof关键字 浮点型(实型) 有效位数保留七位,带小数点。 这个是保…...

【北京迅为】iTOP-RK3568OpenHarmony系统南向驱动开发-第1章 GPIO基础知识
瑞芯微RK3568芯片是一款定位中高端的通用型SOC,采用22nm制程工艺,搭载一颗四核Cortex-A55处理器和Mali G52 2EE 图形处理器。RK3568 支持4K 解码和 1080P 编码,支持SATA/PCIE/USB3.0 外围接口。RK3568内置独立NPU,可用于轻量级人工…...

linux在vim中查找和替换
在Linux中使用Vim编辑器查找文本的方法非常直观和强大。Vim是一个高度可配置的文本编辑器,支持多种查找和替换的命令。下面是一些基本的查找命令: 1. 向前查找 要向前查找文本,可以使用以下命令: /text_to_find 例如,…...

AWS中使用CloudFront分发API Gateway
首先需要准备一个Lambda function(Lambda->Functions) 还要准备一个证书,要覆盖子域名(AWS Certificate Manager->Certificates)。 1、API Gateway->Create API->REST API->Build->API endpoint type( Edge-optimized )-…...

探秘《矩阵之美》:解锁矩阵的无限魅力
在这个数据驱动的时代,矩阵作为数学中的瑰宝,不仅在理论研究中占据核心地位,更在工程技术、计算机科学、物理学、经济学等众多领域发挥着不可替代的作用。今天,让我们通过中科院大学耿修瑞老师(中科院空天信息研究院研…...

进行性核上性麻痹患者的生活护理指南
进行性核上性麻痹是一种神经系统退行性疾病,合理的生活护理能有效改善症状,提高生活质量。 居家环境要安全。移除地面杂物,铺设防滑垫,安装扶手,降低跌倒风险。在浴室、厨房等湿滑区域要特别加强防护措施。建议在床边、…...

JVM--虚拟机
JVM,即虚拟机,可以简单理解为将字节码文件翻译成机器码的机器。 .class文件-->机器码文件 JVM整体组成部分 1.类加载器 负责从磁盘中加载字节码文件到JVM中 2.运行时数据区 按照不同的数据分区进行存储(方法区,堆,栈,本地方…...

pyside6学习专栏(八):在PySide6中使用matplotlib库绘制三维图形
本代码原来是PySide6官网的一个示例程序,我对其进行的详细的注释,同时增加了一个功能:加载显示cass的地形图坐标数据示例,示例可显示以下几种三维图形 程序运行界面如下: 代码如下: # -*- coding: utf-8 -…...

松灵机器人地盘 安装 ros 驱动 并且 发布ros 指令进行控制
安装驱动 $ cd ~/catkin_ws/src $ git clone https://github.com/agilexrobotics/ugv_sdk.git $ git clone https://github.com/agilexrobotics/scout_ros.git $ cd .. $ catkin_make安装 ● 使能 gs_usb 内核模块 ● 设置 500k 波特率和使能 can-to-usb 适配器 sudo modp…...

Highcharts 配置语法详解
Highcharts 配置语法详解 引言 Highcharts 是一个功能强大的图表库,广泛应用于数据可视化领域。本文将详细介绍 Highcharts 的配置语法,帮助您快速上手并制作出精美、实用的图表。 高级配置结构 Highcharts 的配置对象通常包含以下几部分:…...

python力扣2:两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都不会以 0 开…...
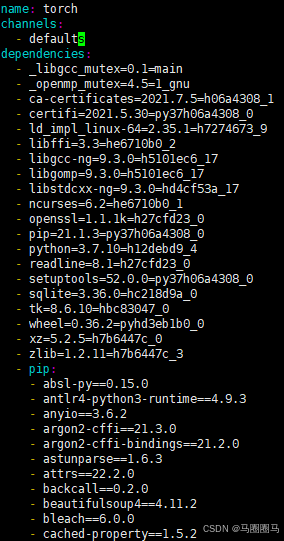
服务器间迁移conda环境
注意:可使用迁移miniconda文件 or 迁移yaml文件两种方式,推荐前者,基本无bug! 一、迁移miniconda文件: 拷贝旧机器的miniconda文件文件到新机器: 内网拷贝:scp -r mazhf192.168.1.233:~/miniconda3 ~/ 外…...

LeetCode第58题_最后一个单词的长度
LeetCode 第58题:最后一个单词的长度 题目描述 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中最后一个单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 难度 简单 题目链接 点…...