深入理解并实现自定义 unordered_map 和 unordered_set
亲爱的读者朋友们😃,此文开启知识盛宴与思想碰撞🎉。
快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。

在 C++ 的标准模板库(STL)中,unordered_map和unordered_set是非常实用的容器,它们基于哈希表实现,能够提供高效的查找、插入和删除操作。在 SGI - STL30 版本中,虽然没有标准的unordered_map和unordered_set,但有类似功能的hash_map和hash_set,它们作为非标准容器存在。
本文将基于哈希表来模拟实现自定义的unordered_map和unordered_set。
目录
💯模拟实现的基础 —— 哈希表
1. HashTable 类
1.1 迭代器相关函数
Iterator Begin()
Iterator End()
ConstIterator Begin() const 和 ConstIterator End() const
1.2 插入函数 Insert
1.3 查找函数 Find
1.4 删除函数 Erase
1.5 辅助函数 __stl_next_prime
2. HTIterator 类
2.1 构造函数 HTIterator(Node* node, const HashTable * pht)
2.2 解引用操作符 operator*()
2.3 箭头操作符 operator->()
2.4 不等于操作符 operator!=
2.5 前置递增操作符 operator++()
💯基于哈希表实现 unordered_set
💯基于哈希表实现 unordered_map
operator[] 函数
💯测试代码
💯模拟实现的基础 —— 哈希表
首先,定义哈希表的节点结构HashNode。每个节点包含数据_data和指向下一个节点的指针_next,用于解决哈希冲突(链地址法)。
namespace zdf {
// 哈希表节点定义
template<class T>
struct HashNode {T _data;HashNode<T>* _next;// 构造函数,初始化数据和指针HashNode(const T& data) : _data(data), _next(nullptr) {}
};
}
- 功能:这是哈希表中节点的基本结构,用于存储数据和指向下一个节点的指针,采用链表法解决哈希冲突。
- 构造函数
HashNode(const T& data):
- 参数:
data是要存储在节点中的数据,类型为T。- 作用:初始化节点的数据成员
_data为传入的data,并将指向下一个节点的指针_next初始化为nullptr。
1. HashTable 类
接着,定义哈希表类HashTable。它包含多个成员变量和成员函数,以实现哈希表的各种功能。
namespace zdf {
template<class K, class T, class KeyOfT, class Hash>
class HashTable {// 定义节点类型typedef HashNode<T> Node;
public:// 定义迭代器类型typedef HTIterator<K, T, T*, T&, KeyOfT, Hash> Iterator;// 定义常量迭代器类型typedef HTIterator<K, T, const T*, const T&, KeyOfT, Hash> ConstIterator;// 返回哈希表起始位置的迭代器Iterator Begin() {if (_n == 0) {return End();}for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];if (cur) {return Iterator(cur, this);}}return End();}// 返回哈希表结束位置的迭代器Iterator End() {return Iterator(nullptr, this);}// 返回常量哈希表起始位置的迭代器ConstIterator Begin() const {if (_n == 0) {return End();}for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];if (cur) {return ConstIterator(cur, this);}}return End();}// 返回常量哈希表结束位置的迭代器ConstIterator End() const {return ConstIterator(nullptr, this);}// 插入数据到哈希表pair<Iterator, bool> Insert(const T& data) {KeyOfT kot;Iterator it = Find(kot(data));if (it != End()) {return make_pair(it, false);}Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子达到1时进行扩容if (_n == _tables.size()) {vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];while (cur) {Node* next = cur->_next;// 计算在新表中的位置并插入size_t newHashi = hs(kot(cur->_data)) % newtables.size();cur->_next = newtables[newHashi];newtables[newHashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}// 在当前位置插入新节点Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(Iterator(newnode, this), true);}// 在哈希表中查找数据Iterator Find(const K& key) {KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {return Iterator(cur, this);}cur = cur->_next;}return End();}// 从哈希表中删除数据bool Erase(const K& key) {KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {_tables[hashi] = cur->_next;}else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}
private:// 计算下一个素数,用于扩容inline unsigned long __stl_next_prime(unsigned long n) {static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last? *(last - 1) : *pos;}// 哈希表存储数据的桶,是一个指针数组vector<Node*> _tables;// 哈希表中存储数据的个数size_t _n = 0;
};
}
1.1 迭代器相关函数
Iterator Begin()
Iterator Begin() {if (_n == 0) {return End();}for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];if (cur) {return Iterator(cur, this);}}return End();
}
- 功能:返回哈希表起始位置的迭代器。
- 步骤:
- 检查哈希表中元素数量
_n是否为 0,如果是则直接返回表示结束位置的迭代器。- 遍历哈希表的每个桶(
_tables),找到第一个不为空的桶。- 如果找到不为空的桶,返回指向该桶第一个节点的迭代器。
- 如果遍历完所有桶都没有找到非空桶,则返回表示结束位置的迭代器。
Iterator End()
Iterator End() {return Iterator(nullptr, this);
}
- 功能:返回哈希表结束位置的迭代器,通常用一个指向
nullptr的迭代器表示。- 步骤:创建一个指向
nullptr的迭代器并返回。
ConstIterator Begin() const 和 ConstIterator End() const
- 功能:与上述
Begin()和End()类似,但用于常量哈希表,返回常量迭代器。- 实现细节:实现逻辑与非常量版本相同,只是返回的是常量迭代器。
1.2 插入函数 Insert
pair<Iterator, bool> Insert(const T& data) {KeyOfT kot;Iterator it = Find(kot(data));if (it != End()) {return make_pair(it, false);}Hash hs;size_t hashi = hs(kot(data)) % _tables.size();if (_n == _tables.size()) {vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];while (cur) {Node* next = cur->_next;size_t newHashi = hs(kot(cur->_data)) % newtables.size();cur->_next = newtables[newHashi];newtables[newHashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(Iterator(newnode, this), true);
}
- 功能:向哈希表中插入一个新的数据项。
- 步骤:
- 使用
Find函数检查数据是否已经存在于哈希表中,如果存在则返回该元素的迭代器和false。- 计算数据的哈希值,确定其在哈希表中的桶位置
hashi。- 检查负载因子(元素数量
_n与桶数量_tables.size()相等),如果达到阈值则进行扩容操作:
- 创建一个新的更大的哈希表
newtables,桶的数量为下一个素数。- 遍历原哈希表的每个桶,将每个节点重新计算哈希值并插入到新的哈希表中。
- 交换原哈希表和新哈希表的指针。
- 创建一个新的节点
newnode,将其插入到对应桶的头部。- 元素数量
_n加 1。- 返回新插入节点的迭代器和
true。
1.3 查找函数 Find
Iterator Find(const K& key) {KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {return Iterator(cur, this);}cur = cur->_next;}return End();
}
- 功能:在哈希表中查找指定键
key对应的数据项。- 步骤:
- 计算键的哈希值,确定其在哈希表中的桶位置
hashi。- 遍历该桶对应的链表,检查每个节点的数据是否与键匹配。
- 如果找到匹配的节点,则返回指向该节点的迭代器。
- 如果遍历完链表都没有找到匹配的节点,则返回表示结束位置的迭代器。
1.4 删除函数 Erase
bool Erase(const K& key) {KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {_tables[hashi] = cur->_next;}else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;
}
- 功能:从哈希表中删除指定键
key对应的数据项。- 步骤:
- 计算键的哈希值,确定其在哈希表中的桶位置
hashi。- 遍历该桶对应的链表,查找键匹配的节点。
- 如果找到匹配的节点:
- 如果该节点是链表的第一个节点,则将桶的头指针指向该节点的下一个节点。
- 否则,将前一个节点的
_next指针指向该节点的下一个节点。- 删除该节点,并将元素数量
_n减 1。- 返回
true表示删除成功。- 如果遍历完链表都没有找到匹配的节点,则返回
false表示删除失败。
1.5 辅助函数 __stl_next_prime
inline unsigned long __stl_next_prime(unsigned long n) {static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last? *(last - 1) : *pos;
}
- 功能:计算大于等于
n的下一个素数,用于哈希表扩容时确定新的桶数量。- 步骤:
- 定义一个素数列表
__stl_prime_list。- 使用
lower_bound函数在素数列表中查找第一个大于等于n的素数。- 如果找到则返回该素数,否则返回素数列表中的最后一个素数。
为了实现哈希表的迭代器功能,定义迭代器类HTIterator。
2. HTIterator 类
namespace zdf {
template<class K, class T, class Ptr, class Ref, class KeyOfT, class Hash>
struct HTIterator {// 定义节点类型typedef HashNode<T> Node;// 定义自身类型typedef HTIterator<K, T, Ptr, Ref, KeyOfT, Hash> Self;Node* _node;const HashTable<K, T, KeyOfT, Hash>* _pht;// 构造函数,初始化节点指针和哈希表指针HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht) : _node(node), _pht(pht) {}// 解引用操作符重载,返回节点数据的引用Ref operator*() {return _node->_data;}// 箭头操作符重载,返回节点数据的指针Ptr operator->() {return &_node->_data;}// 不等于操作符重载,用于比较两个迭代器bool operator!=(const Self& s) {return _node != s._node;}// 前置递增操作符重载,移动到下一个节点Self& operator++() {if (_node->_next) {_node = _node->_next;}else {KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();++hashi;while (hashi < _pht->_tables.size()) {if (_pht->_tables[hashi]) {break;}++hashi;}if (hashi == _pht->_tables.size()) {_node = nullptr;}else {_node = _pht->_tables[hashi];}}return *this;}
};
}
2.1 构造函数 HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht)
HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht) : _node(node), _pht(pht) {}
- 功能:初始化迭代器,将节点指针
node和哈希表指针pht赋值给成员变量。- 参数:
node:指向当前节点的指针。pht:指向哈希表的指针。
2.2 解引用操作符 operator*()
Ref operator*() {return _node->_data;
}
- 功能:返回当前迭代器指向节点的数据的引用。
- 步骤:直接返回节点的数据成员
_data。
2.3 箭头操作符 operator->()
Ptr operator->() {return &_node->_data;
}
- 功能:返回当前迭代器指向节点的数据的指针。
- 步骤:返回节点数据成员
_data的地址。
2.4 不等于操作符 operator!=
bool operator!=(const Self& s) {return _node != s._node;
}
- 功能:比较两个迭代器是否不相等。
- 步骤:比较两个迭代器指向的节点指针是否不同。
2.5 前置递增操作符 operator++()
Self& operator++() {if (_node->_next) {_node = _node->_next;}else {KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();++hashi;while (hashi < _pht->_tables.size()) {if (_pht->_tables[hashi]) {break;}++hashi;}if (hashi == _pht->_tables.size()) {_node = nullptr;}else {_node = _pht->_tables[hashi];}}return *this;
}
- 功能:将迭代器移动到下一个节点。
- 步骤:
- 如果当前节点有下一个节点,则直接将迭代器指向该下一个节点。
- 如果当前节点没有下一个节点,则需要找到下一个非空的桶:
- 计算当前节点所在的桶位置
hashi。- 从下一个桶开始查找,直到找到一个非空的桶。
- 如果遍历完所有桶都没有找到非空桶,则将迭代器指向
nullptr。- 否则,将迭代器指向该非空桶的第一个节点。
- 返回迭代器自身的引用。
💯基于哈希表实现 unordered_set
unordered_set是一个无序的集合容器,它存储唯一的键值。通过复用前面实现的哈希表,定义unordered_set类。
namespace zdf {
template<class K, class Hash = HashFunc<K>>
class unordered_set {// 仿函数,用于从键值中提取键struct SetKeyOfT {const K& operator()(const K& key) {return key;}};
public:// 定义迭代器类型typedef typename HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;// 定义常量迭代器类型typedef typename HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;// 返回容器起始位置的迭代器iterator begin() {return _ht.Begin();}// 返回容器结束位置的迭代器iterator end() {return _ht.End();}// 返回常量容器起始位置的迭代器const_iterator begin() const {return _ht.Begin();}// 返回常量容器结束位置的迭代器const_iterator end() const {return _ht.End();}// 插入键值到unordered_setpair<iterator, bool> insert(const K& key) {return _ht.Insert(key);}// 在unordered_set中查找键值iterator Find(const K& key) {return _ht.Find(key);}// 从unordered_set中删除键值bool Erase(const K& key) {return _ht.Erase(key);}
private:// 使用哈希表存储数据HashTable<K, const K, SetKeyOfT, Hash> _ht;
};
}
💯基于哈希表实现 unordered_map
unordered_map是一个无序的键值对容器,它允许通过键快速查找对应的值。同样复用哈希表来实现unordered_map类。
namespace zdf {
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map {// 仿函数,用于从键值对中提取键struct MapKeyOfT {const K& operator()(const pair<K, V>& kv) {return kv.first;}};
public:// 定义迭代器类型typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;// 定义常量迭代器类型typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;// 返回容器起始位置的迭代器iterator begin() {return _ht.Begin();}// 返回容器结束位置的迭代器iterator end() {return _ht.End();}// 返回常量容器起始位置的迭代器const_iterator begin() const {return _ht.Begin();}// 返回常量容器结束位置的迭代器const_iterator end() const {return _ht.End();}// 插入键值对到unordered_mappair<iterator, bool> insert(const pair<K, V>& kv) {return _ht.Insert(kv);}// 通过键访问对应的值,若键不存在则插入默认值V& operator[](const K& key) {pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}// 在unordered_map中查找键值对iterator Find(const K& key) {return _ht.Find(key);}// 从unordered_map中删除键值对bool Erase(const K& key) {return _ht.Erase(key);}
private:// 使用哈希表存储数据HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
};
}
operator[] 函数
V& operator[](const K& key) {pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;
}
- 功能:通过键访问对应的值,如果键不存在则插入一个默认值。
- 步骤:
- 调用底层哈希表的
Insert函数插入键值对(如果键不存在)。- 返回插入或已存在的键值对的值的引用。
💯测试代码
为了验证自定义的unordered_map和unordered_set的功能正确性,编写测试函数。
using namespace std;
// 测试unordered_set的功能
void test_set() {zdf::unordered_set<int> s;int a[] = { 4,2,6,1,3,5,15,7,16,14,3,3,15 };for (auto e : a) {s.insert(e);}for (auto e : s) {cout << e << " ";}cout << endl;zdf::unordered_set<int>::iterator it = s.begin();while (it != s.end()) {cout << *it << " ";++it;}cout << endl;
}// 测试unordered_map的功能
void test_map() {zdf::unordered_map<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "Left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];zdf::unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()) {it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}int main() {test_set();test_map();return 0;
}
通过上述代码,我们基于哈希表成功模拟实现了自定义的unordered_map和unordered_set,并对其功能进行了测试验证。这不仅有助于深入理解哈希表的工作原理以及 STL 容器的实现机制,也为在实际开发中根据特定需求进行容器的定制化提供了思路和参考。
如果文章对你有帮助,欢迎关注我👉【A charmer】

相关文章:
深入理解并实现自定义 unordered_map 和 unordered_set
亲爱的读者朋友们😃,此文开启知识盛宴与思想碰撞🎉。 快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。 在 C 的标准模板库(STL)中,unorder…...

228页PPT丨制造业核心业务流程优化咨询全案(战略营销计划生产研发质量),附核心系统集成架构技术支撑体系,2月26日资料已更新
一、订单全生命周期管理优化 1. 智能订单承诺(CTP)系统 ●集成ERP/APS/MES数据,实时计算产能可视性 ●应用蒙特卡洛模拟评估订单交付风险 ●建立动态插单评估模型(基于边际贡献与产能占用系数) 2. 跨部门协同机制…...

6.6.5 SQL访问控制
文章目录 GRANT授予权限REVOKE回收权限 GRANT授予权限 GRANT语句可以给用户授予权限,基本格式是GRANT 权限 TO 用户。在授权时,WITH GRANT OPTION是可选项,有此句话,被授予权限的用户还能把权限赋给其他用户。 REVOKE回收权限 RE…...

PhyloSuite v1.2.3安装与使用-生信工具049
PhyloSuite 一个好用的win集成建树平台,官方相关文档视频等做的可好了PhyloSuite (jushengwu.com) 官网 https://github.com/dongzhang0725/PhyloSuite/releases #官网 http://phylosuite.jushengwu.com/dongzhang0725.github.io/installation/ #官方说明文档…...

【语法】C++中string类中的两个问题及解答
贴主在学习string类时遇到过两个困扰我的问题,今天拿出来给大家分享一下我是如何解决的 一、扩容时capacity的增长问题 在string的capacity()接口中,调用的是这个string对象的容量(可以存多少个有效字符),而size()是调用的string对象现在有…...

智慧校园平台在学生学习与生活中的应用
随着科技的发展,教育领域也在不断探索新的模式与方法。智慧校园平台作为教育信息化的重要组成部分,正逐渐成为推动教育改革、提高教学质量的关键工具。 一.智慧校园平台概述 智慧校园平台是一种集成了教学管理、资源服务、数据分析等多功能于一体的数字…...

AtCoder Beginner Contest 001(A - 積雪深差、B - 視程の通報、C - 風力観測、D - 感雨時刻の整理)题解
由于我发现网上很少有人会发很久之前AtCoder Beginner Contes的题,所以我打算从AtCoder Beginner Contest 001开始写。大约两周一更,需要的可以订阅专栏,感谢支持Thanks♪(・ω・)ノ →题目翻译 A - 積雪深差…...
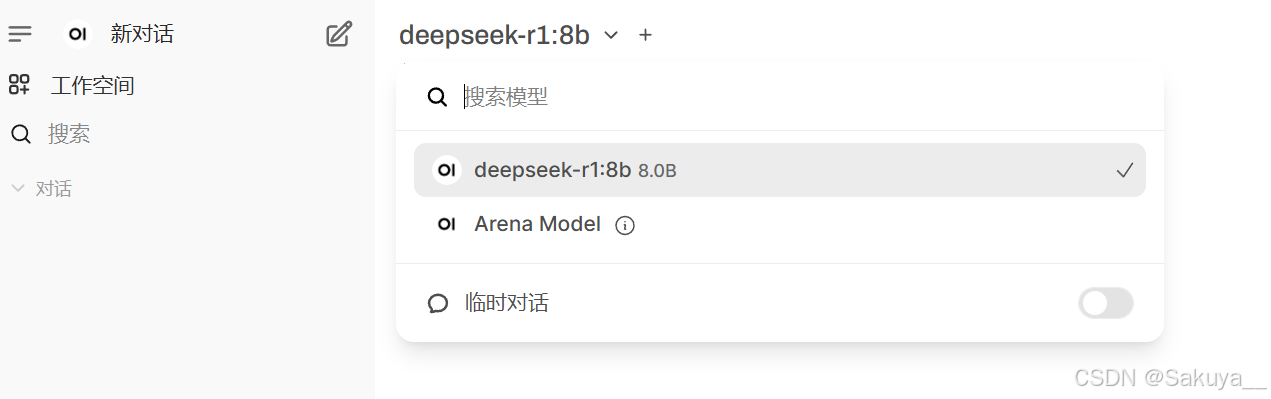
Windows本地Docker+Open-WebUI部署DeepSeek
最近想在自己的电脑本地部署一下DeepSeek试试,由于不希望污染电脑的Windows环境,所以在wsl中安装了ollama,使用ollama拉取DeepSeek模型。然后在Windows中安装了Docker Desktop,在Docker中部署了Open-WebUI,最后再在Ope…...

gmock和cppfreemock原理学习
1.gmock用法 gmock(Google Mock)是 Google Test 的一个扩展库,专门用于 C 单元测试中的模拟(mocking)。它的核心原理是通过 继承和方法重载/覆盖 来模拟 C 中的虚函数,从而在测试中隔离依赖对象࿰…...

WSBDF レクチア 定义2 引理3 wsbdf的乘子
定义2 引理3 wsbdf的乘子 ここまで 寝みます❓...

AI日记app
一、需求分析与竞品调研 1. 核心功能需求 多媒体日记记录:支持语音、视频、图片的实时录制或上传。语音/视频转文字:自动将音频、视频内容转为可编辑的文字。文字编辑与排版:富文本编辑(字体、颜色、标签)、Markdown…...
)
单一职责原则(设计模式)
目录 问题: 定义: 解决: 方式 1:使用策略模式 示例:用户管理 方式 2:使用装饰者模式 示例:用户操作 方式 3:使用责任链模式 示例:用户操作链 总结 推荐 问题&a…...

Odoo免费开源CRM技术实战:从商机线索关联转化为售后工单的应用
文 / 开源智造 Odoo金牌服务 Odoo:功能强大且免费开源的CRM Odoo 引入了一种高效的客户支持管理方式,即将 CRM 线索转换为服务台工单。此功能确保销售和支持团队能够无缝协作,从而提升客户满意度并缩短问题解决时间。通过整合 CRM 模块与服…...

ChatGPT与DeepSeek:开源与闭源的AI模型之争
目录 一、模型架构与技术原理 二、性能能力与应用场景 三、用户体验与部署灵活性 四、成本与商业模式 五、未来展望与市场影响 六、总结 随着人工智能技术的飞速发展,ChatGPT和DeepSeek作为两大领先的AI语言模型,成为了行业内外关注的焦点。它们在…...

C语言(3)—循环、数组、函数的详解
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、函数二、循环与数组 1.循环2.数组 总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、函数 在C语言中,函数…...

架构师论文《论面向对象设计的应用与实现》
软考论文-系统架构设计师 摘要 我所在的公司是国内一家专注于智慧城市建设的科技企业,为适应城市数字化转型中对于高内聚、低耦合、可扩展性的技术需求,2021年3月,公司立项开发“智慧社区综合管理平台”,旨在整合物业管理、安防监…...
Deepseek函数调用流程图、Python代码示例)
Deepseek Api Function Calling解析(tools、tool_calls)Deepseek函数调用流程图、Python代码示例
文章目录 Function Calling介绍**核心原理**1. **动态扩展模型能力**2. **JSON结构化交互** **实现步骤**(以支持Function Calling的模型为例)1. **定义可用函数**2. **模型匹配与生成**3. **开发者执行函数**4. **结果反馈给模型** **DeepSeek R1的当前…...

现代未来派品牌海报设计液体装饰英文字体安装包 Booster – Liquid Font
CS Booster – 具有动态流的液体显示字体 具有液体美感的现代显示字体 CS Booster 是一种未来主义的显示字体,采用流畅和有机的形式设计,赋予其流畅、灵活和不断移动的外观。独特的液体灵感形状和非刚性边缘使这款字体脱颖而出,提供一种既俏…...

python流水线自动化项目教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1. 项目环境准备Python安装选择Python开发环境安装必要库 2. 数据获取与理解4. 模型训练流水线6. 模型保存7. 模型部署(简单 Web 服务)8…...

(十 四)趣学设计模式 之 策略模式!
目录 一、 啥是策略模式?二、 为什么要用策略模式?三、 策略模式的实现方式四、 策略模式的优缺点五、 策略模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支…...

EMO模型详解及代码复现
EMO定义 EMO(Efficient Mobile Networks)是一种 面向移动端的轻量化网络模型 ,旨在 在参数、FLOPs和性能之间实现平衡 ,特别适用于 密集预测任务 。EMO的设计理念源于对CNN和Transformer架构的深入理解,通过整合两者的优势,实现了高效的模型性能。 EMO的核心是 反向残差…...

kkfileview部署
kkfileview部署 链接: 官方文档 链接: gitee 链接: github 首先打开官网如下: OK,我们从官方文档的教程中看到,部署步骤如下: 是不是很简单,没错,于是我们按照步骤从码云上下载,然后解压,然…...

leetcode_34 在排序数组中查找元素的第一个和最后一个位置
1. 题意 给定一个非递减的数组,找出给定元素的开始位置和 结束位置。 2. 题解 题目要求复杂度为 log ( n ) \log (n) log(n), 因此不能用双指针了。 这个题目练习二分挺好的。 2.1 双指针 还是把双指针的写下来吧。 class Solution { public:vector<i…...

网络编程——UDP
UDP编程使用套接字(Socket)进行通信。下面是基于UDP协议进行网络编程的基本步骤。 1. 创建套接字 首先,客户端和服务器都需要通过 socket() 系统调用创建一个UDP套接字。 2. 配置地址和端口 UDP是无连接的,因此你不需要像TCP一…...

文件描述符(File Descriptor)
一、介绍 内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。 二、功能 文件…...

【3天快速入门WPF】12-MVVM
目录 1. 什么是MVVM2. 实现简单MVVM2.1. Part 12.2. Part 21. 什么是MVVM MVVM 是 Model-View-ViewModel 的缩写,是一种用于构建用户界面的设计模式,是一种简化用户界面的事件驱动编程方式。 MVVM 的目标是实现用户界面和业务逻辑之间的彻底分离,以便更好地管理和维护应用…...

钉钉MAKE AI生态大会思考
1. 核心特性 1.1 底层模型开放 除原有模型通义千问外,新接入猎户星空、智普、MinMax、月之暗面、百川智能、零一万物。 1.2 AI搜索 AI搜索贯通企业和个人散落在各地的知识(聊天记录、文档、会议、日程、知识库、项目等),通过大模型对知识逻辑化,直接生成搜索的答案,并…...

[操作系统] 文件的软链接和硬链接
文章目录 引言硬链接(Hard Link)什么是硬链接?硬链接的特性硬链接的用途 软链接(Symbolic Link)什么是软链接?软链接的特性软链接的用途 软硬链接对比文件的时间戳实际应用示例使用硬链接节省备份空间用软链…...

【TI毫米波雷达】DCA1000的ADC原始数据C语言解析及FMCW的Python解析2D-FFT图像
【TI毫米波雷达】DCA1000的ADC原始数据C语言解析及FMCW的Python解析2D-FFT图像 文章目录 ADC原始数据C语言解析Python的2D-FFT图像附录:结构框架雷达基本原理叙述雷达天线排列位置芯片框架Demo工程功能CCS工程导入工程叙述Software TasksData PathOutput informati…...

基于ai技术的视频生成工具
一、通用型AI视频生成工具 腾讯智影 特点:支持数字人播报、文字转视频,提供免费模板和素材库,登录即送5分钟免费时长,每日签到可兑换额外额度。 限制:免费版分辨率较低,部分高级功能需付费。 LunaAI.vid…...