记忆化搜索(典型算法思想)—— OJ例题算法解析思路
目录
一、509. 斐波那契数 - 力扣(LeetCode)
算法代码:
1. 动态规划 (fib 函数)
初始化:
递推计算:
返回结果:
2. 记忆化搜索 (dfs 函数)
备忘录初始化:
递归终止条件:
递归计算:
返回结果:
3. 代码优化建议
4. 优化后的动态规划代码
5. 优化后的记忆化搜索代码
总结
二、 62. 不同路径 - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 动态规划 (uniquePaths 函数)
思路:
状态定义:
初始条件:
状态转移方程:
边界条件:
最终结果:
代码实现:
3. 记忆化搜索 (dfs 函数)
思路:
备忘录定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
4. 代码优化建议
动态规划的空间优化
记忆化搜索的边界处理
5. 总结
三、 300. 最长递增子序列 - 力扣(LeetCode)
算法代码:
1. 问题描述
示例:
2. 动态规划 (lengthOfLIS 函数)
思路:
状态定义:
初始条件:
状态转移方程:
填表顺序:
最终结果:
代码实现:
3. 记忆化搜索 (dfs 函数)
思路:
备忘录定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
4. 代码优化建议
动态规划的优化
记忆化搜索的边界处理
5. 总结
四、 375. 猜数字大小 II - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 记忆化搜索 (dfs 函数)
思路:
状态定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
3. 动态规划的思路
动态规划的状态转移方程:
动态规划的填表顺序:
动态规划的代码实现:
4. 代码优化建议
记忆化搜索的优化
动态规划的空间优化
5. 总结
五、329. 矩阵中的最长递增路径 - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 代码思路
(1)变量定义
(2)主函数 longestIncreasingPath
(3)DFS 函数 dfs
递归终止条件:
递归计算:
记录结果:
3. 代码实现
4. 代码优化建议
(1)边界检查优化
(2)空间优化
(3)方向数组优化
5. 总结
DFS + 记忆化搜索:
时间复杂度:
空间复杂度:
一、509. 斐波那契数 - 力扣(LeetCode)

算法代码:
class Solution {
public:int memo[31]; // memory 备忘录int dp[31];int fib(int n) {// 动态规划dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++)dp[i] = dp[i - 1] + dp[i - 2];return dp[n];}// 记忆化搜索int dfs(int n) {if (memo[n] != -1) {return memo[n]; // 直接去备忘录⾥⾯拿值}if (n == 0 || n == 1) {memo[n] = n; // 记录到备忘录⾥⾯return n;}memo[n] = dfs(n - 1) + dfs(n - 2); // 记录到备忘录⾥⾯return memo[n];}
}; 这段代码实现了计算斐波那契数列的第 n 项,使用了两种不同的方法:动态规划和记忆化搜索。下面是对代码的思路和实现细节的详细解释:

1. 动态规划 (fib 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算斐波那契数列的值。
-
初始化:
-
dp[0] = 0:斐波那契数列的第 0 项是 0。 -
dp[1] = 1:斐波那契数列的第 1 项是 1。
-
-
递推计算:
-
从第 2 项开始,每一项的值等于前两项的和,即
dp[i] = dp[i - 1] + dp[i - 2]。 -
通过循环从
i = 2到i = n,逐步计算每一项的值。
-
-
返回结果:
-
最终返回
dp[n],即第n项的值。
-
2. 记忆化搜索 (dfs 函数)
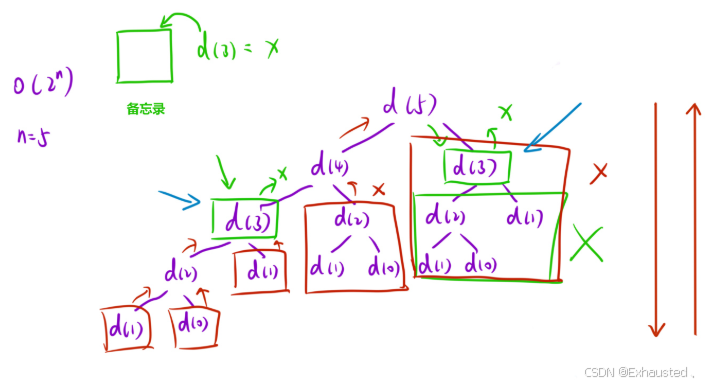
记忆化搜索是一种自顶向下的方法,通过递归计算斐波那契数列的值,并使用备忘录 (memo) 来避免重复计算。
-
备忘录初始化:
-
在调用
dfs函数之前,需要将memo数组初始化为-1,表示尚未计算过的值。
-
-
递归终止条件:
-
如果
n == 0或n == 1,直接返回n,并将结果记录到备忘录中。
-
-
递归计算:
-
如果
memo[n]不为-1,说明已经计算过,直接返回memo[n]。 -
否则,递归计算
dfs(n - 1)和dfs(n - 2),并将结果相加,记录到备忘录中。
-
-
返回结果:
-
最终返回
memo[n],即第n项的值。
-
3. 代码优化建议
-
备忘录初始化:在
dfs函数中,memo数组应该在调用dfs之前初始化为-1,否则可能会导致错误的结果。 -
空间优化:对于动态规划方法,可以只使用两个变量来存储前两项的值,而不需要维护整个
dp数组,从而将空间复杂度从O(n)降低到O(1)。
4. 优化后的动态规划代码
int fib(int n) {if (n == 0) return 0;if (n == 1) return 1;int prev2 = 0; // dp[0]int prev1 = 1; // dp[1]int result = 0;for (int i = 2; i <= n; i++) {result = prev1 + prev2;prev2 = prev1;prev1 = result;}return result;
}5. 优化后的记忆化搜索代码
int memo[31]; // 备忘录int dfs(int n) {if (memo[n] != -1) {return memo[n];}if (n == 0 || n == 1) {memo[n] = n;return n;}memo[n] = dfs(n - 1) + dfs(n - 2);return memo[n];
}int fib(int n) {memset(memo, -1, sizeof(memo)); // 初始化备忘录return dfs(n);
}总结
-
动态规划:适合自底向上的计算,空间复杂度可以优化到
O(1)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
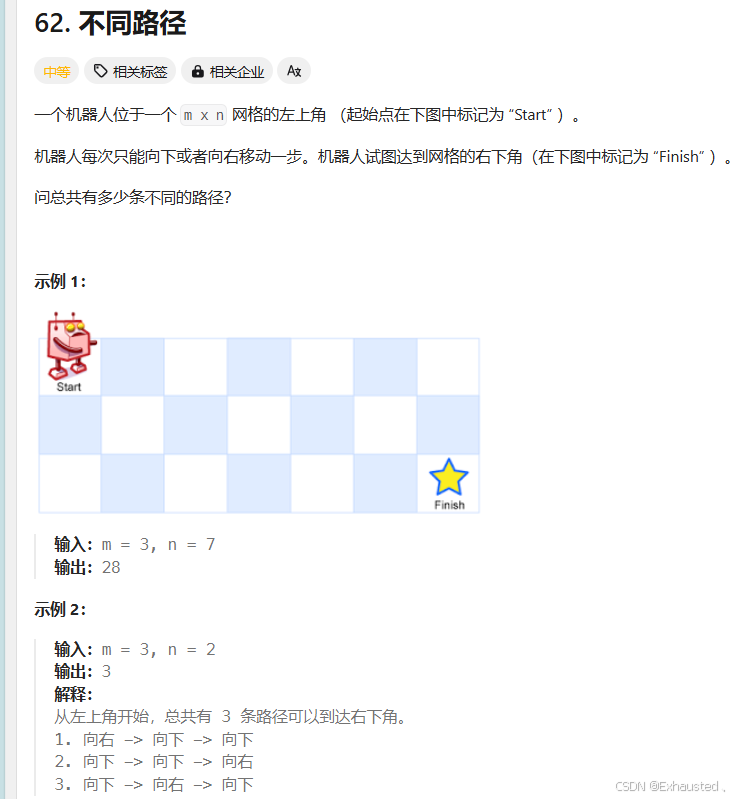
二、 62. 不同路径 - 力扣(LeetCode)

算法代码:
class Solution {
public:int uniquePaths(int m, int n) {// 动态规划vector<vector<int>> dp(m + 1, vector<int>(n + 1));dp[1][1] = 1;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++) {if (i == 1 && j == 1)continue;dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}return dp[m][n];// 记忆化搜索// vector<vector<int>> memo(m + 1, vector<int>(n + 1));// return dfs(m, n, memo);}int dfs(int i, int j, vector<vector<int>>& memo) {if (memo[i][j] != 0) {return memo[i][j];}if (i == 0 || j == 0)return 0;if (i == 1 && j == 1) {memo[i][j] = 1;return 1;}memo[i][j] = dfs(i - 1, j, memo) + dfs(i, j - 1, memo);return memo[i][j];}
};这段代码解决了机器人从网格左上角到右下角的唯一路径数问题,使用了两种方法:动态规划和记忆化搜索。以下是代码的思路和实现细节的详细解释:
1. 问题描述
在一个 m x n 的网格中,机器人从左上角 (1, 1) 出发,每次只能向右或向下移动,问到达右下角 (m, n) 有多少条唯一的路径。

2. 动态规划 (uniquePaths 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算每个位置的路径数。
思路:
-
状态定义:
-
dp[i][j]表示从起点(1, 1)到达位置(i, j)的唯一路径数。
-
-
初始条件:
-
起点
(1, 1)的路径数为 1,即dp[1][1] = 1。
-
-
状态转移方程:
-
对于位置
(i, j),机器人只能从上方(i-1, j)或左方(i, j-1)到达。 -
因此,
dp[i][j] = dp[i-1][j] + dp[i][j-1]。
-
-
边界条件:
-
如果
i == 1 && j == 1,跳过计算,因为初始值已经设置为 1。 -
如果
i == 0或j == 0,表示越界,路径数为 0。
-
-
最终结果:
-
返回
dp[m][n],即从(1, 1)到(m, n)的唯一路径数。
-
代码实现:
int uniquePaths(int m, int n) {vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0)); // 初始化 dp 数组dp[1][1] = 1; // 起点路径数为 1for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (i == 1 && j == 1) continue; // 跳过起点dp[i][j] = dp[i - 1][j] + dp[i][j - 1]; // 状态转移}}return dp[m][n]; // 返回结果
}3. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算每个位置的路径数,并使用备忘录 (memo) 来避免重复计算。
思路:
-
备忘录定义:
-
memo[i][j]表示从位置(i, j)到终点(m, n)的唯一路径数。
-
-
递归终止条件:
-
如果
i == 1 && j == 1,表示到达起点,路径数为 1。 -
如果
i == 0或j == 0,表示越界,路径数为 0。
-
-
递归计算:
-
如果
memo[i][j]已经计算过,直接返回memo[i][j]。 -
否则,递归计算从上方
(i-1, j)和左方(i, j-1)的路径数,并相加。
-
-
记录结果:
-
将计算结果记录到
memo[i][j]中,避免重复计算。
-
代码实现:
int dfs(int i, int j, vector<vector<int>>& memo) {if (memo[i][j] != 0) {return memo[i][j]; // 如果已经计算过,直接返回}if (i == 0 || j == 0) {return 0; // 越界,路径数为 0}if (i == 1 && j == 1) {memo[i][j] = 1; // 起点,路径数为 1return 1;}memo[i][j] = dfs(i - 1, j, memo) + dfs(i, j - 1, memo); // 递归计算return memo[i][j];
}int uniquePaths(int m, int n) {vector<vector<int>> memo(m + 1, vector<int>(n + 1, 0)); // 初始化备忘录return dfs(m, n, memo); // 调用记忆化搜索
}4. 代码优化建议
动态规划的空间优化
-
当前动态规划的空间复杂度为
O(m * n),可以优化为O(n)。 -
使用一维数组
dp,每次更新时覆盖旧值。
优化后的代码:
int uniquePaths(int m, int n) {vector<int> dp(n + 1, 0);dp[1] = 1; // 起点路径数为 1for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (i == 1 && j == 1) continue; // 跳过起点dp[j] += dp[j - 1]; // 状态转移}}return dp[n]; // 返回结果
}记忆化搜索的边界处理
-
在
dfs函数中,可以提前判断i和j是否越界,避免无效递归。
5. 总结
-
动态规划:适合自底向上的计算,空间复杂度可以优化到
O(n)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
三、 300. 最长递增子序列 - 力扣(LeetCode)

算法代码:
class Solution {
public:int lengthOfLIS(vector<int>& nums) {// 动态规划int n = nums.size();vector<int> dp(n, 1);int ret = 0;// 填表顺序:从后往前for (int i = n - 1; i >= 0; i--) {for (int j = i + 1; j < n; j++) {if (nums[j] > nums[i]) {dp[i] = max(dp[i], dp[j] + 1);}}ret = max(ret, dp[i]);}return ret;// 记忆化搜索//// vector<int> memo(n);// int ret = 0;// for(int i = 0; i < n; i++)// ret = max(ret, dfs(i, nums, memo));// return ret;}int dfs(int pos, vector<int>& nums, vector<int>& memo) {if (memo[pos] != 0)return memo[pos];int ret = 1;for (int i = pos + 1; i < nums.size(); i++) {if (nums[i] > nums[pos]) {ret = max(ret, dfs(i, nums, memo) + 1);}}memo[pos] = ret;return ret;}
};这段代码解决了最长递增子序列(Longest Increasing Subsequence, LIS)问题,使用了两种方法:动态规划和记忆化搜索。以下是代码的思路和实现细节的详细解释:
1. 问题描述
给定一个整数数组 nums,找到其中最长的严格递增子序列的长度。
示例:
-
输入:
nums = [10, 9, 2, 5, 3, 7, 101, 18] -
输出:
4 -
解释:最长的递增子序列是
[2, 3, 7, 101],长度为 4。
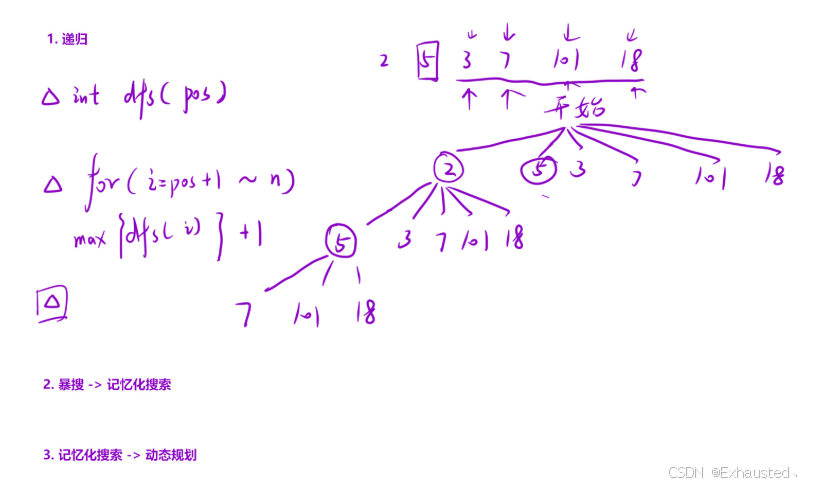
2. 动态规划 (lengthOfLIS 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算以每个位置结尾的最长递增子序列的长度。
思路:
-
状态定义:
-
dp[i]表示以nums[i]结尾的最长递增子序列的长度。
-
-
初始条件:
-
每个元素本身就是一个长度为 1 的递增子序列,因此
dp[i] = 1。
-
-
状态转移方程:
-
对于每个位置
i,遍历其后面的所有位置j(j > i)。 -
如果
nums[j] > nums[i],说明nums[j]可以接在nums[i]后面,形成一个更长的递增子序列。 -
因此,
dp[i] = max(dp[i], dp[j] + 1)。
-
-
填表顺序:
-
从后往前填表,确保在计算
dp[i]时,dp[j]已经计算过。
-
-
最终结果:
-
遍历
dp数组,找到最大值,即为最长递增子序列的长度。
-
代码实现:
int lengthOfLIS(vector<int>& nums) {int n = nums.size();vector<int> dp(n, 1); // 初始化 dp 数组,每个元素至少是一个长度为 1 的递增子序列int ret = 0; // 记录最终结果for (int i = n - 1; i >= 0; i--) { // 从后往前填表for (int j = i + 1; j < n; j++) { // 遍历后面的元素if (nums[j] > nums[i]) {dp[i] = max(dp[i], dp[j] + 1); // 状态转移}}ret = max(ret, dp[i]); // 更新最大值}return ret; // 返回结果
}3. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算以每个位置结尾的最长递增子序列的长度,并使用备忘录 (memo) 来避免重复计算。
思路:
-
备忘录定义:
-
memo[pos]表示以nums[pos]结尾的最长递增子序列的长度。
-
-
递归终止条件:
-
如果
memo[pos]已经计算过,直接返回memo[pos]。
-
-
递归计算:
-
对于当前位置
pos,遍历其后面的所有位置i(i > pos)。 -
如果
nums[i] > nums[pos],说明nums[i]可以接在nums[pos]后面,形成一个更长的递增子序列。 -
因此,递归计算
dfs(i, nums, memo),并更新当前结果。
-
-
记录结果:
-
将计算结果记录到
memo[pos]中,避免重复计算。
-
代码实现:
int dfs(int pos, vector<int>& nums, vector<int>& memo) {if (memo[pos] != 0) {return memo[pos]; // 如果已经计算过,直接返回}int ret = 1; // 至少是一个长度为 1 的递增子序列for (int i = pos + 1; i < nums.size(); i++) { // 遍历后面的元素if (nums[i] > nums[pos]) {ret = max(ret, dfs(i, nums, memo) + 1); // 递归计算}}memo[pos] = ret; // 记录结果return ret;
}int lengthOfLIS(vector<int>& nums) {int n = nums.size();vector<int> memo(n, 0); // 初始化备忘录int ret = 0;for (int i = 0; i < n; i++) {ret = max(ret, dfs(i, nums, memo)); // 计算以每个位置结尾的最长递增子序列}return ret; // 返回结果
}4. 代码优化建议
动态规划的优化
-
当前动态规划的时间复杂度为
O(n^2),可以使用二分查找将时间复杂度优化到O(n log n)。 -
使用一个辅助数组
tails,其中tails[i]表示长度为i+1的递增子序列的最小末尾元素。
优化后的代码:
int lengthOfLIS(vector<int>& nums) {vector<int> tails;for (int num : nums) {auto it = lower_bound(tails.begin(), tails.end(), num); // 二分查找if (it == tails.end()) {tails.push_back(num); // 如果 num 比所有元素都大,直接添加到末尾} else {*it = num; // 否则替换第一个大于等于 num 的元素}}return tails.size(); // tails 的长度即为最长递增子序列的长度
}记忆化搜索的边界处理
-
在
dfs函数中,可以提前判断pos是否越界,避免无效递归。
5. 总结
-
动态规划:适合自底向上的计算,时间复杂度为
O(n^2),可以通过二分查找优化到O(n log n)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
四、 375. 猜数字大小 II - 力扣(LeetCode)
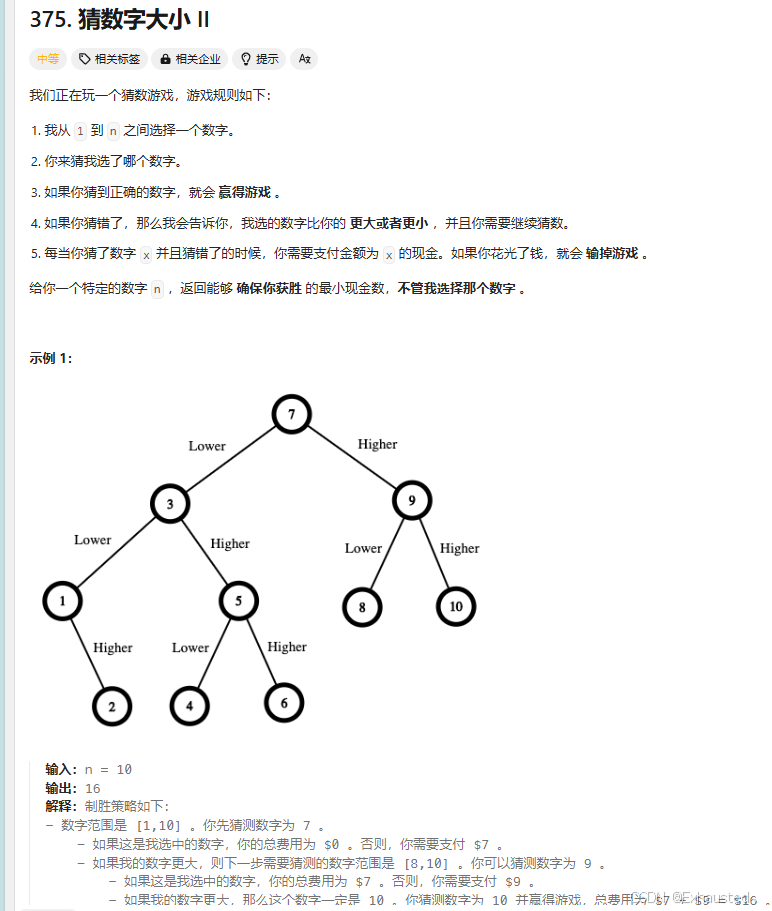

算法代码:
class Solution {int memo[201][201];public:int getMoneyAmount(int n) { return dfs(1, n); }int dfs(int left, int right) {if (left >= right)return 0;if (memo[left][right] != 0)return memo[left][right];int ret = INT_MAX;for (int head = left; head <= right; head++) // 选择头结点{int x = dfs(left, head - 1);int y = dfs(head + 1, right);ret = min(ret, head + max(x, y));}memo[left][right] = ret;return ret;}
};这段代码解决了猜数字游戏的最小代价问题,使用了记忆化搜索的方法。以下是代码的思路和实现细节的详细解释:
1. 问题描述
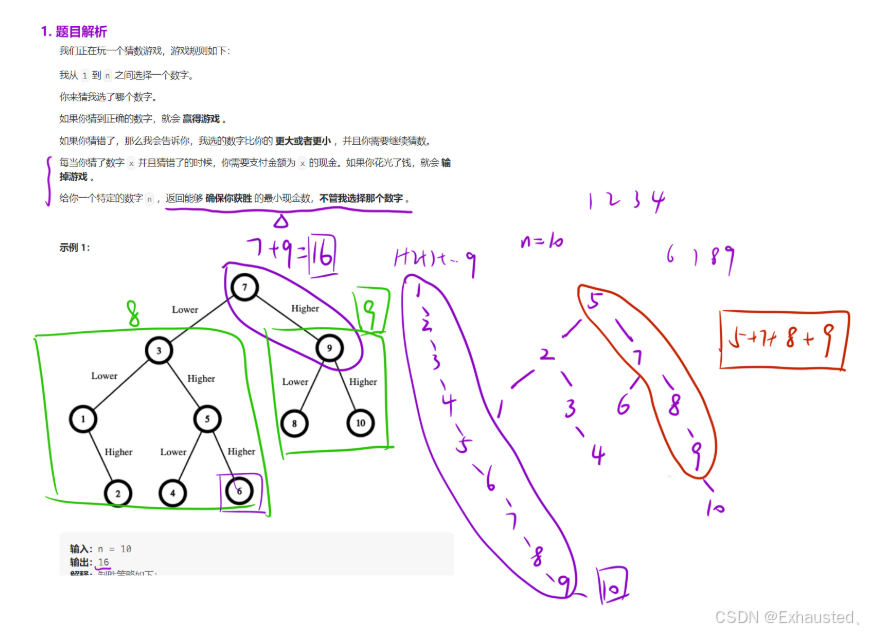
-
给定一个范围
[1, n],你需要猜一个目标数字。 -
每次猜错后,会被告知猜的数字是大于还是小于目标数字。
-
每次猜测的代价是猜测的数字本身。
-
目标是找到一种策略,使得最坏情况下的总代价最小。
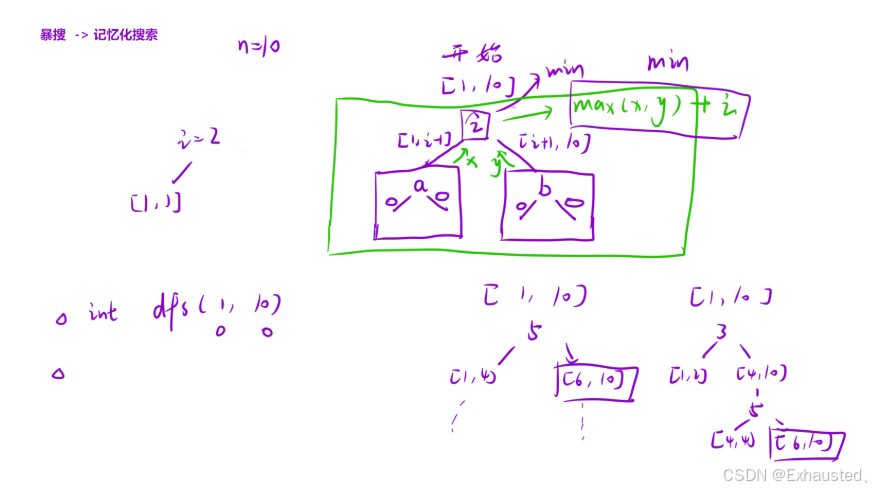
2. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算每个子问题的最小代价,并使用备忘录 (memo) 来避免重复计算。
思路:
-
状态定义:
-
dfs(left, right)表示在范围[left, right]内猜数字的最小代价。
-
-
递归终止条件:
-
如果
left >= right,说明范围内没有数字或只有一个数字,不需要猜测,代价为 0。
-
-
递归计算:
-
遍历范围内的每个数字
head,作为猜测的起点。 -
将问题分为两部分:
-
左部分:
[left, head - 1]。 -
右部分:
[head + 1, right]。
-
-
计算左部分和右部分的最小代价,并取最大值(因为是最坏情况)。
-
当前猜测的代价为
head + max(左部分代价, 右部分代价)。 -
选择所有猜测中代价最小的一个。
-
-
记录结果:
-
将计算结果记录到
memo[left][right]中,避免重复计算。
-
代码实现:
int memo[201][201]; // 备忘录int dfs(int left, int right) {if (left >= right) {return 0; // 范围内没有数字或只有一个数字,代价为 0}if (memo[left][right] != 0) {return memo[left][right]; // 如果已经计算过,直接返回}int ret = INT_MAX; // 初始化最小代价为最大值for (int head = left; head <= right; head++) { // 遍历范围内的每个数字int x = dfs(left, head - 1); // 左部分代价int y = dfs(head + 1, right); // 右部分代价ret = min(ret, head + max(x, y)); // 更新最小代价}memo[left][right] = ret; // 记录结果return ret;
}int getMoneyAmount(int n) {return dfs(1, n); // 调用记忆化搜索
}3. 动态规划的思路
虽然代码中使用了记忆化搜索,但这个问题也可以用动态规划来解决。动态规划是一种自底向上的方法,通过填表逐步计算每个子问题的最小代价。
动态规划的状态转移方程:
-
定义
dp[i][j]表示在范围[i, j]内猜数字的最小代价。 -
状态转移方程:
dp[i][j] = min(dp[i][j], head + max(dp[i][head - 1], dp[head + 1][j]));其中
head是当前猜测的数字。
动态规划的填表顺序:
-
从小到大枚举范围的长度
len。 -
对于每个长度
len,枚举起点i,计算j = i + len - 1。
动态规划的代码实现:
int getMoneyAmount(int n) {vector<vector<int>> dp(n + 2, vector<int>(n + 2, 0)); // 初始化 dp 数组for (int len = 2; len <= n; len++) { // 枚举范围的长度for (int i = 1; i + len - 1 <= n; i++) { // 枚举起点int j = i + len - 1; // 终点dp[i][j] = INT_MAX; // 初始化最小代价为最大值for (int head = i; head <= j; head++) { // 遍历范围内的每个数字int cost = head + max(dp[i][head - 1], dp[head + 1][j]); // 当前猜测的代价dp[i][j] = min(dp[i][j], cost); // 更新最小代价}}}return dp[1][n]; // 返回结果
}4. 代码优化建议
记忆化搜索的优化
-
在
dfs函数中,可以提前判断left和right是否越界,避免无效递归。
动态规划的空间优化
-
当前动态规划的空间复杂度为
O(n^2),无法进一步优化。
5. 总结
-
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
-
动态规划:适合自底向上的计算,通过填表逐步计算每个子问题的最小代价。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
五、329. 矩阵中的最长递增路径 - 力扣(LeetCode)


算法代码:
class Solution {int m, n;int dx[4] = {0, 0, 1, -1};int dy[4] = {1, -1, 0, 0};int memo[201][201];public:int longestIncreasingPath(vector<vector<int>>& matrix) {int ret = 0;m = matrix.size(), n = matrix[0].size();for (int i = 0; i < m; i++)for (int j = 0; j < n; j++) {ret = max(ret, dfs(matrix, i, j));}return ret;}int dfs(vector<vector<int>>& matrix, int i, int j) {if (memo[i][j] != 0)return memo[i][j];int ret = 1;for (int k = 0; k < 4; k++) {int x = i + dx[k], y = j + dy[k];if (x >= 0 && x < m && y >= 0 && y < n &&matrix[x][y] > matrix[i][j]) {ret = max(ret, dfs(matrix, x, y) + 1);}}memo[i][j] = ret;return ret;}
};这段代码解决了矩阵中的最长递增路径问题,使用了深度优先搜索(DFS)和记忆化搜索的方法。以下是代码的思路和实现细节的详细解释:
1. 问题描述
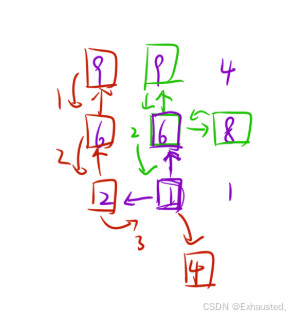
-
给定一个
m x n的整数矩阵matrix,找到其中最长的递增路径的长度。 -
对于每个单元格,你可以向上下左右四个方向移动,但不能移动到边界外或移动到值小于等于当前单元格的单元格。
2. 代码思路
(1)变量定义
-
m和n:矩阵的行数和列数。 -
dx和dy:表示四个方向的偏移量(右、左、下、上)。 -
memo[i][j]:记录从单元格(i, j)出发的最长递增路径的长度。
(2)主函数 longestIncreasingPath
-
遍历矩阵中的每个单元格
(i, j),调用dfs函数计算从该单元格出发的最长递增路径。 -
更新全局最大值
ret。
(3)DFS 函数 dfs
-
递归终止条件:
-
如果
memo[i][j]已经计算过,直接返回memo[i][j]。
-
-
递归计算:
-
初始化当前单元格的最长路径长度为 1。
-
遍历四个方向,检查是否可以移动到相邻单元格
(x, y):-
如果
(x, y)在矩阵范围内,并且matrix[x][y] > matrix[i][j],则递归计算dfs(matrix, x, y)。 -
更新当前单元格的最长路径长度
ret = max(ret, dfs(matrix, x, y) + 1)。
-
-
-
记录结果:
-
将计算结果
ret记录到memo[i][j]中。 -
返回
ret。
-
3. 代码实现
class Solution {int m, n; // 矩阵的行数和列数int dx[4] = {0, 0, 1, -1}; // 四个方向的 x 偏移量int dy[4] = {1, -1, 0, 0}; // 四个方向的 y 偏移量int memo[201][201]; // 备忘录,记录从每个单元格出发的最长递增路径长度public:int longestIncreasingPath(vector<vector<int>>& matrix) {int ret = 0; // 记录全局最大值m = matrix.size(), n = matrix[0].size(); // 初始化矩阵的行数和列数for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {ret = max(ret, dfs(matrix, i, j)); // 计算从每个单元格出发的最长递增路径}}return ret; // 返回全局最大值}int dfs(vector<vector<int>>& matrix, int i, int j) {if (memo[i][j] != 0) {return memo[i][j]; // 如果已经计算过,直接返回}int ret = 1; // 初始化当前单元格的最长路径长度为 1for (int k = 0; k < 4; k++) { // 遍历四个方向int x = i + dx[k], y = j + dy[k]; // 计算相邻单元格的坐标if (x >= 0 && x < m && y >= 0 && y < n && matrix[x][y] > matrix[i][j]) {ret = max(ret, dfs(matrix, x, y) + 1); // 递归计算并更新最长路径长度}}memo[i][j] = ret; // 记录结果return ret; // 返回当前单元格的最长路径长度}
};4. 代码优化建议
(1)边界检查优化
-
在
dfs函数中,可以提前判断(x, y)是否在矩阵范围内,避免无效递归。
(2)空间优化
-
当前备忘录
memo的大小为201 x 201,可以动态分配内存,避免空间浪费。
(3)方向数组优化
-
方向数组
dx和dy可以定义为静态常量,避免重复初始化。
5. 总结
-
DFS + 记忆化搜索:
-
通过深度优先搜索遍历矩阵中的每个单元格。
-
使用备忘录
memo记录每个单元格的最长递增路径长度,避免重复计算。
-
-
时间复杂度:
-
每个单元格最多计算一次,时间复杂度为
O(m * n)。
-
-
空间复杂度:
-
备忘录
memo的空间复杂度为O(m * n)。
-
通过 DFS 和记忆化搜索的结合,可以高效地解决矩阵中的最长递增路径问题。
相关文章:
记忆化搜索(典型算法思想)—— OJ例题算法解析思路
目录 一、509. 斐波那契数 - 力扣(LeetCode) 算法代码: 1. 动态规划 (fib 函数) 初始化: 递推计算: 返回结果: 2. 记忆化搜索 (dfs 函数) 备忘录初始化: 递归终止条件: 递…...

Day11,Hot100(贪心算法)
贪心 (1)121. 买卖股票的最佳时机 第 i 天卖出的最大利润,即在前面最低价的时候买入 class Solution:def maxProfit(self, prices: List[int]) -> int:min_price prices[0]ans 0for price in prices:ans max(ans, price - min_price…...

翻译: 深入分析LLMs like ChatGPT 一
大家好,我想做这个视频已经有一段时间了。这是一个全面但面向普通观众的介绍,介绍像ChatGPT这样的大型语言模型。我希望通过这个视频让大家对这种工具的工作原理有一些概念性的理解。 首先,我们来谈谈你在这个文本框里输入内容并点击回车后背…...

《白帽子讲 Web 安全》之移动 Web 安全
目录 摘要 一、WebView 简介 二、WebView 对外暴露 WebView 对外暴露的接口风险 三、通用型 XSS - Universal XSS 介绍 四、WebView 跨域访问 五、与本地代码交互 js 5.1接口暴露风险: 5.2漏洞利用: 5.3JavaScript 与 Native 代码通信 六、Chr…...

解锁 indexOf、substring 和 JSON.stringify:从小程序图片上传看字符串魔法 ✨
🌟 解锁 indexOf、substring 和 JSON.stringify:从小程序图片上传看字符串魔法 ✨ 在 JavaScript 中,字符串操作和数据序列化是开发中不可或缺的技能。indexOf、substring 和 JSON.stringify 是三个简单却强大的工具,分别用于定位…...
常用的AI文本大语言模型汇总
AI文本【大语言模型】 1、文心一言https://yiyan.baidu.com/ 2、海螺问问https://hailuoai.com/ 3、通义千问https://tongyi.aliyun.com/qianwen/ 4、KimiChat https://kimi.moonshot.cn/ 5、ChatGPThttps://chatgpt.com/ 6、魔塔GPT https://www.modelscope.cn/studios/iic…...
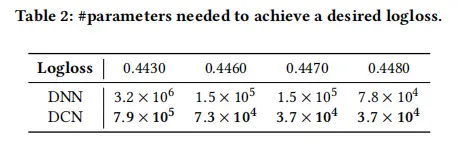
DCN讲解
DCN是DeepFM的升级版,后者是只能做二阶交叉特征,随着阶数上升,模型复杂度大幅提高,且FM网络层较浅,表达能力有限。google团队通过构建深度交叉网络来自动进行特征的高阶交叉,且时空复杂度均为线性增长&…...

前端开发常用的加密算法
以下是前端开发中常用的加密方式及其适用场景的详细说明: 一、核心加密方案 加密类型常用算法特点适用场景对称加密AES、DES、3DES加密解密使用相同密钥,速度快本地存储加密、HTTP Body加密非对称加密RSA、ECC公钥加密私钥解密,安全性高传输…...

5. Nginx 负载均衡配置案例(附有详细截图说明++)
5. Nginx 负载均衡配置案例(附有详细截图说明) 文章目录 5. Nginx 负载均衡配置案例(附有详细截图说明)1. Nginx 负载均衡 配置实例3. 注意事项和避免的坑4. 文档: Nginx 的 upstream 配置技巧5. 最后: 1. Nginx 负载均衡 配置实例 需求说明/图解 windows 浏览器输…...

C++之再识模板template
目录 1.非类型模板参数 2.函数/类模板的特化 3.模板的分离编译 4.总结:模板的优缺点 1. 代码复用性高 2. 类型安全 3. 性能优化 2. 错误信息难以理解 3. 代码膨胀 易错易忽略的语法点: 1. 模板声明和定义分离问题 2. 模板参数推导问题 1.非类…...

【文献阅读】Collective Decision for Open Set Recognition
基本信息 文献名称:Collective Decision for Open Set Recognition 出版期刊:IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 发表日期:04 March 2020 作者:Chuanxing Geng and Songcan Chen 摘要 在开集识别࿰…...

力扣刷题DAY2(链表/简单)
一、回文链表 回文链表 方法一:双指针 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, L…...

golang 内存对齐和填充规则
内存对齐和填充规则 对齐要求:每个数据类型的起始地址必须是其大小的倍数。 int8(1字节):不需要对齐。int16(2字节):起始地址必须是2的倍数。int32(4字节):起…...

ansible自动化运维工具学习笔记
目录 ansible环境部署 控制端准备 被控制端准备 ansible批量管理主机的方式主要有两种 配置准备: ssh密码认证方式管理机器 密码登录,需要各主机密码相同 配置免密登录 ssh密钥方式批量管理主机 ansible实现批量化主机管理的模式 ansible-doc命令 comman…...

零基础deep seek+剪映,如何制作高品质的视频短片
以下是专为零基础学习者设计的 剪映专业版详细教程+Deep seek配合制 ,包含从入门到精通的系统化教学,配合具体操作步骤与实用技巧: 基于DeepSeek与剪映协同制作高品质视频短片的专业流程指南(2025年最新实践版&#x…...

网络空间安全(4)web应用程序安全要点
前言 Web应用程序安全是确保Web应用程序、服务和服务器免受网络攻击和威胁的关键环节。 一、编写安全的代码 输入验证与过滤:确保所有的用户输入都被正确验证和过滤,以防止注入攻击等安全漏洞。开发者应对URL、查询关键字、HTTP头、POST数据等进行严格的…...

【word】保存重开题注/交叉引用消失,全局更新域问题
目录 一、更新域是什么二、更新域常见问题及解决方法(一)更新域后内容未变化(二)域代码显示异常(三)交叉引用无法更新(四)全选更新域出现错误 三、交叉引用与题注的关系及操作&#…...

大语言模型中的 Token:它们是什么,如何工作?
引言 如果你使用过 ChatGPT 这样的 AI 工具,你可能会好奇:它是如何理解并生成文字的?大语言模型(LLM,Large Language Model)并不是直接处理整个句子或文章,而是拆分成一个个 Token(…...

DeepSeek的无限可能
DeepSeek的无限可能 DeepSeek简介DeepSeek定义DeepSeek的发展历程DeepSeek的核心功能 如何使用DeepSeek注册与安装模型使用原则提示语的使用 人机共生 DeepSeek简介 DeepSeek定义 DeepSeek(中文名:深度求索)是一款由杭州深度求索人工智能基…...

【wordpress】服务器已有LNMP环境(已运行WordPress),如何配置文档访问功能?
效果如图步骤确定文件存放目录404.html修改配置文件重启nginx服务 接下来是从win向linux云服务器上传文件使用Samba服务(没成功)使用xshell上传文件(大文件上传一堆乱码)winscp(好用) 效果如图 如果url不对…...

Ollama 的庐山真面目
Ollama 运行方式分析 本地推理条件(GPU/CPU/RAM):Ollama 支持在本地电脑进行大模型推理,但需要满足一定的硬件条件。一般来说,GPU 有助于加速推理,特别是显存较大的 GPU 能够加载更大的模型;如果…...
)
行为型模式 - 观察者模式 (Publish/Subscribe)
行为型模式 - 观察者模式 (Publish/Subscribe) 又称作为订阅发布模式(Publish-Subscribe Pattern)是一种消息传递模式,在该模式中,发送者(发布者)不会直接将消息发送给特定的接收者(订阅者&…...

C++编程指南21 - 线程detach后其注意变量的生命周期
一:概述 如果一个线程被 detach() 了,那么它的生命周期将独立于创建它的作用域。因此,该线程只能安全地访问: 全局变量(global/static objects)堆上分配的对象(free-store allocated objects&a…...

Hadoop之01:HDFS分布式文件系统
HDFS分布式文件系统 1.目标 理解分布式思想学会使用HDFS的常用命令掌握如何使用java api操作HDFS能独立描述HDFS三大组件namenode、secondarynamenode、datanode的作用理解并独立描述HDFS读写流程HDFS如何解决大量小文件存储问题 2. HDFS 2.1 HDFS是什么 HDFS是Hadoop中的一…...

Redis学习笔记系列(一)——Redis简介及安装
1. Redis介绍 Redis是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。 Redis与其他key-value缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行…...

【考试大纲】初级信息处理技术员考试大纲
目录 引言一、考试说明1.考试要求2.考试目标二、考试范围科目一:信息处理基础知识科目二:信息处理应用技术引言 最新的信息处理技术员考试大纲出版于 2018 年 6 月,本考试大纲基于此版本整理。 一、考试说明 1.考试要求 (1)了解信息技术的基本概念; (2)熟悉计…...

LabVIEW正弦信号处理:FFT与最小二乘拟合的参数提取
问题一:LabVIEW能否对采集的正弦力信号进行快速傅里叶变换(FFT),并得到幅值和相位结果? 答案: 可以。LabVIEW通过内置信号处理工具包提供完整的FFT分析功能,具体实现如下: FFT分析流…...

【计算机网络入门】初学计算机网络(五)
目录 1.编码&解码、调制&解调 2.常用编码方法 2.1 不归零编码(NRZ) 2.2 归零编码(RZ) 2.3 反向非归零编码(NRZI) 2.4 曼彻斯特编码 2.5 差分曼彻斯特编码 3. 各种编码的特点 4.调制 5.有线传输介质 5.1 双绞线 5.2 同轴电缆 5.3 光…...

YOLO在PiscTrace上检测到数据分析
在现代计算机视觉领域,实时视频数据的检测与分析对于安全监控、交通管理以及智能制造等领域具有重要意义。YOLO(You Only Look Once)作为一种高效的目标检测算法,能够在保持高精度的同时实现实时检测。而PiscTrace作为一款集成了O…...
【漫话机器学习系列】112.逻辑回归(Logistic Regression)
逻辑回归(Logistic Regression)详解 1. 逻辑回归简介 逻辑回归(Logistic Regression)是一种广泛用于二分类任务的统计和机器学习方法,尽管它的名字中带有“回归”,但它实际上是一种分类算法。 在逻辑回归…...