DeepSeek-R1训练时采用的GRPO算法数学原理及算法过程浅析
先来简单看下PPO和GRPO的区别:

-
PPO:通过奖励和一个“评判者”模型(critic 模型)评估每个行为的“好坏”(价值),然后小步调整策略,确保改进稳定。
-
GRPO:通过让模型自己生成一组结果(比如回答或行为),比较它们的相对质量(优势),然后优化策略。它的特点是不需要额外的“评判者”模型(critic 模型),直接用组内比较来改进。
个人理解记录,供参考。
1. GRPO目标函数的数学原理
GRPO的目标函数如下:
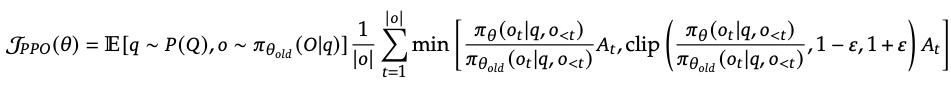
这个函数看起来复杂,但我们可以将其拆解为几个关键部分,逐一分析其作用和意义。GRPO的目标函数由两大部分组成:策略梯度更新项和KL散度正则化项。我们分别分析它们的作用。
1.1 策略梯度更新项
策略梯度部分是目标函数的主要成分,形式为:
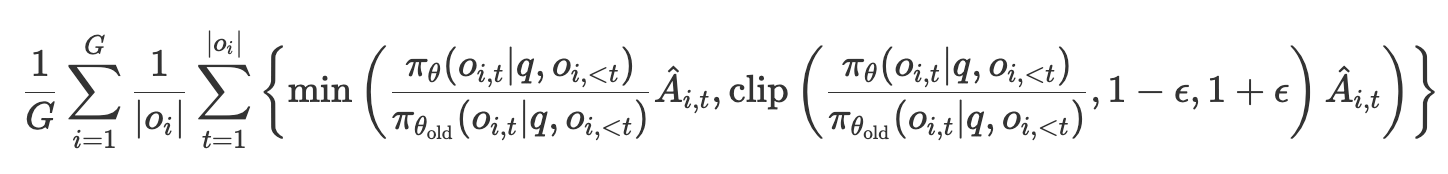
核心思想
这一部分的目标是通过策略梯度调整 θ \theta θ,使策略 π θ \pi_{\theta} πθ 在有利动作( A ^ i , t > 0 \hat{A}_{i,t} > 0 A^i,t>0)上提高概率,在不利动作( A ^ i , t < 0 \hat{A}_{i,t} < 0 A^i,t<0)上降低概率。为了避免更新过于激进,GRPO引入了剪切机制。
概率比
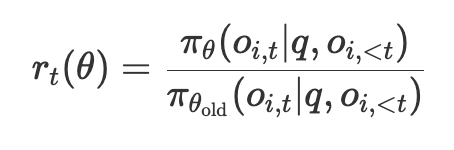
这是当前策略与旧策略在动作 o i , t o_{i,t} oi,t 上的概率比。若 r t ( θ ) > 1 r_t(\theta) > 1 rt(θ)>1,表示当前策略更倾向于选择该动作;若 r t ( θ ) < 1 r_t(\theta) < 1 rt(θ)<1,则倾向于减少该动作。
剪切操作
clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) clip(rt(θ),1−ϵ,1+ϵ)
剪切操作将 r t ( θ ) r_t(\theta) rt(θ) 限制在 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 区间内:
- 如果 r t ( θ ) < 1 − ϵ r_t(\theta) < 1 - \epsilon rt(θ)<1−ϵ,则被截断为 1 − ϵ 1 - \epsilon 1−ϵ;
- 如果 r t ( θ ) > 1 + ϵ r_t(\theta) > 1 + \epsilon rt(θ)>1+ϵ,则被截断为 1 + ϵ 1 + \epsilon 1+ϵ。
这限制了策略更新的幅度,防止单次更新偏离旧策略太远。
最小值操作
min ( r t ( θ ) A ^ i , t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min \left( r_t(\theta) \hat{A}_{i,t}, \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) \hat{A}_{i,t} \right) min(rt(θ)A^i,t,clip(rt(θ),1−ϵ,1+ϵ)A^i,t)
- 当 A ^ i , t > 0 \hat{A}_{i,t} > 0 A^i,t>0(动作有利)时, min \min min 选择较小的值,确保更新不会过于增加概率。
- 当 A ^ i , t < 0 \hat{A}_{i,t} < 0 A^i,t<0(动作不利)时, min \min min 同样选择较小的值(即较大的负值),限制概率减少的幅度。
这种设计类似于PPO算法,通过剪切和最小值操作增强训练稳定性。
平均操作
- 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} ∣oi∣1∑t=1∣oi∣: 对单个轨迹内的所有时间步取平均。
- 1 G ∑ i = 1 G \frac{1}{G} \sum_{i=1}^{G} G1∑i=1G: 对所有 G G G 个轨迹取平均。
- E q ∼ P ( Q ) , { o i } ∼ π θ old \mathbb{E}_{q \sim P(Q), \{o_i\} \sim \pi_{\theta_{\text{old}}}} Eq∼P(Q),{oi}∼πθold: 在状态和轨迹分布上取期望。
这些平均和期望操作使目标函数能够泛化到不同的状态和轨迹。
2.2 KL散度正则化项
β D KL ( π θ ∣ ∣ π ref ) \beta D_{\text{KL}}(\pi_{\theta}||\pi_{\text{ref}}) βDKL(πθ∣∣πref)
作用
KL散度(Kullback-Leibler divergence)衡量当前策略 π θ \pi_{\theta} πθ 与参考策略 π ref \pi_{\text{ref}} πref 之间的差异。负号和权重 β \beta β 表示这是一个惩罚项,目标是限制 π θ \pi_{\theta} πθ 偏离 π ref \pi_{\text{ref}} πref 过远。
意义
- 当 D KL D_{\text{KL}} DKL 较大时,惩罚增加,迫使策略更新更加保守。
- β \beta β 控制正则化强度: β \beta β 越大,策略变化越小。
2. GRPO算法的整体工作流程

GRPO是一种基于组奖励的策略优化算法,其工作流程可以分为以下几个步骤:
-
采样响应(Sample G responses)
对于每个输入问题 $ q_i $,从旧策略 $ \pi_{\theta_{\text{old}}} $ 中采样 $ G $ 个响应 $ {o_i}_{i=1}^{G} $。这些响应可以看作是对问题的多种可能回答,图示中用粉色方块表示“prompts”(输入问题),绿色方块表示“completions”(生成响应)。 -
分配奖励(Assign rewards based on rules)
根据预定义的规则为每个响应分配奖励 $ R_i $。奖励可能基于回答的质量(如准确性、流畅性等),图示中用蓝色方块表示“rewards”。 -
计算优势(Compute advantages)
通过比较每个响应的奖励与组内统计值,计算优势值 $ A_i $。具体公式为:
A i = R i − mean ( group ) std ( group ) A_i = \frac{R_i - \text{mean}(\text{group})}{\text{std}(\text{group})} Ai=std(group)Ri−mean(group)
其中,$ \text{mean}(\text{group}) $ 是组内奖励的平均值,$ \text{std}(\text{group}) $ 是标准差。优势值 $ A_i $ 反映了每个响应相对于组内平均表现的优劣,图示中用紫色方块表示“advantages”。 -
更新策略(Update the policy)
通过最大化目标函数 $ J_{\text{GRPO}}(\theta) $,调整策略参数 $ \theta ,以提高高优势值( ,以提高高优势值( ,以提高高优势值( A_i > 0 )响应的生成概率,同时降低低优势值( )响应的生成概率,同时降低低优势值( )响应的生成概率,同时降低低优势值( A_i < 0 $)响应的概率。 -
KL散度惩罚(KL Divergence penalty)
为避免新策略 π θ \pi_{\theta} πθ 过于偏离参考模型 π ref \pi_{\text{ref}} πref,引入KL散度惩罚项 − β D KL ( π θ ∣ ∣ π ref ) -\beta D_{\text{KL}}(\pi_{\theta}||\pi_{\text{ref}}) −βDKL(πθ∣∣πref)。这一正则化措施确保策略更新的稳定性并保留通用推理能力,图示中用橙色方块表示“$ D_{\text{KL}} $”。
整个流程通过迭代优化实现:从输入问题到生成响应,再到奖励分配和优势计算,最后更新策略,形成一个闭环。
3. 为什么GRPO算法有效?
- GRPO通过消除传统强化学习算法(如PPO)中需要的一个单独价值函数模型,显著提高了效率。这个模型通常需要额外的内存和计算资源,而GRPO的做法降低了这些需求,使其更适合处理大型语言模型。
稳健的优势估计 - GRPO采用基于群体的优势估计方法。它为每个提示生成多个响应,并使用群体的平均奖励作为基准。这种方法无需依赖另一个模型的预测,提供了一种更稳健的政策评估方式,有助于减少方差并确保学习稳定性。
- GRPO直接将Kullback-Leibler(KL)散度纳入损失函数中。这有助于控制策略更新,防止策略与参考策略偏离过多,从而保持训练的稳定性。
4. 几个GRPO复现deepseek-R1-zero的流程代码repo
- https://github.com/Jiayi-Pan/TinyZero
- https://github.com/Unakar/Logic-RL
关于作者:余俊晖,主要研究方向为自然语言处理、大语言模型、文档智能。曾获CCF、Kaggle、ICPR、CCL、CAIL等国内外近二十项AI算法竞赛/评测冠亚季军。发表SCI、顶会等文章多篇,专利数项。
相关文章:
DeepSeek-R1训练时采用的GRPO算法数学原理及算法过程浅析
先来简单看下PPO和GRPO的区别: PPO:通过奖励和一个“评判者”模型(critic 模型)评估每个行为的“好坏”(价值),然后小步调整策略,确保改进稳定。 GRPO:通过让模型自己生…...

Qt基于信号量QSemaphore实现的生产者消费者模型
在 Qt 中,信号量(QSemaphore)是一种用于控制对共享资源访问的同步工具。它允许一定数量的线程同时访问共享资源,适合用于生产者-消费者模型。 代码实现 #include <QCoreApplication> #include <QThread> #include &…...

七星棋牌 6 端 200 子游戏全开源修复版源码(乐豆 + 防沉迷 + 比赛场 + 控制)
七星棋牌源码 是一款运营级的棋牌产品,覆盖 湖南、湖北、山西、江苏、贵州 等 6 大省区,支持 安卓、iOS 双端,并且 全开源。这个版本是 修复优化后的二开版本,新增了 乐豆系统、比赛场模式、防沉迷机制、AI 智能控制 等功能&#…...

CSDN博客导出设置介绍
在CSDN编辑博客时,如果想导出保存到本地,可以选择导出为Markdown或者HTML格式。其中导出为HTML时有这几种选项:jekyll site,plain html,plain text,styled html,styled html with toc。分别是什…...

_ 为什么在python中可以当变量名
在 Python 中,_(下划线)是一个有效的变量名,这主要源于 Python 的命名规则和一些特殊的使用场景。以下是为什么 _ 可以作为变量名的原因和常见用途: --- ### 1. **Python 的命名规则** Python 允许使用字母ÿ…...

使用haproxy实现MySQL服务器负载均衡
一、环境准备 主机名IP地址备注openEuler-1192.168.121.11mysql-server-1openEuler-2192.168.121.12mysql-server-2openEuler-3192.168.121.13clientRocky-1192.168.121.51haproxy 二、mysql-server配置 [rootopenEuler-1 ~]# yum install -y mariadb-server [rootopenEuler…...

音视频-WAV格式
1. WAV格式说明: 2. 格式说明: chunkId:通常是 “RIFF” 四个字节,用于标识文件类型。(wav文件格式表示)chunkSize:表示整个文件除了chunkId和chunkSize这 8 个字节外的其余部分的大小。Forma…...

apload-lab打靶场
1.提示显示所以关闭js 上传<?php phpinfo(); ?>的png形式 抓包,将png改为php 然后放包上传成功 2.提示说检查数据类型 抓包 将数据类型改成 image/jpeg 上传成功 3.提示 可以用phtml,php5,php3 4.先上传.htaccess文件࿰…...

通用查询类接口数据更新的另类实现
文章目录 一、简要概述二、java工程实现1. 定义main方法2. 测试运行3. 源码放送 一、简要概述 我们在通用查询类接口开发的另类思路中,关于接口数据的更新,提出了两种方案: 文件监听 #mermaid-svg-oJQjD6jQ8T19XlHA {font-family:"tre…...

sentinel详细使用教学
sentinel源码地址: https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D sentinel官方文档: https://sentinelguard.io/zh-cn/docs/introduction.html Sprong Cloud alibaba Sentinel文档【小例子】 : https://github.com/alibaba/spring-cl…...

python django
官网地址 https://www.djangoproject.com/ 安装 控制台输入命令 pip install django 或者可以指定版本号 pip install django3.2.4 创建项目 在控制台找个目录存放生成好的项目,输入命令 django-admin startproject demo_django 然后用pycharm打开项目可以…...

SuperMap iClient3D for WebGL 影像数据可视范围控制
在共享同一影像底图的服务场景中,如何基于用户权限体系实现差异化的数据可视范围控制?SuperMap iClient3D for WebGL提供了自定义区域影像裁剪的方法。让我们一起看看吧! 一、数据制作 对于上述视频中的地图制作,此处不做讲述&am…...

HTML元素,标签到底指的哪块部分?单双标签何时使用?
1. 标签(Tag) vs 元素(Element) 标签(Tag) 标签是 HTML 中用于定义元素的符号,用尖括号 < > 包裹。例如 <img> 是标签。元素(Element) 元素是由 标签 内容…...

OpenHarmony4.1-轻量与小型系统ubuntu开发环境
因OpenHarmony官网提供包含轻量、小型与标准系统的全量代码非常宠大,解包后大概需要70G以上硬盘空间,如要编译标准系统则需要140G以上空间。 如硬盘空间有限与只使用轻量/小型OpenHarmony系统,则可以下载并直接使用本人裁剪源码过的ubuntu硬盘…...

秒杀系统的常用架构是什么?怎么设计?
架构 秒杀系统需要单独部署,如果说放在订单服务里面,秒杀的系统压力太大了就会影响正常的用户下单。 常用架构: Redis 数据倾斜问题 第一步扣减库存时 假设现在有 10 个商品需要秒杀,正常情况下,这 10 个商品应该均…...

LabVIEW中三种PSD分析VI的区别与应用
在LabVIEW的声音与振动分析工具包中,SVFA Power Spectral Density VI、SVFA Power Spectral Density Subset VI 和 SVFA Zoom Power Spectral Density VI 均用于信号频域分析,但它们在功能、适用场景和操作逻辑上存在显著差异。以下从区别、应用场合、注…...

Python 如何实现 Markdown 记账记录转 Excel 存储
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

蓝桥杯备考:动态规划入门题目之下楼梯问题
按照动态规划解题顺序,首先,我们要定义状态表示,这里根据题意f[i]就应该表示有i个台阶方案总数 第二步就是 确认状态转移方程,画图分析 所以实际上f[i] 也就是说i个台阶的方案数实际上就是第i-1个格子的方案数第i-2个格子的方案数…...

【树莓派学习】树莓派3B+的安装和环境配置
【树莓派学习】树莓派3B的安装和环境配置 文章目录 【树莓派学习】树莓派3B的安装和环境配置一、搭建Raspberry Pi树莓派运行环境1、下载树莓派镜像下载器2、配置wifi及ssh3、SSH访问树莓派1)命令行登录2)远程桌面登录3)VNC登录(推…...
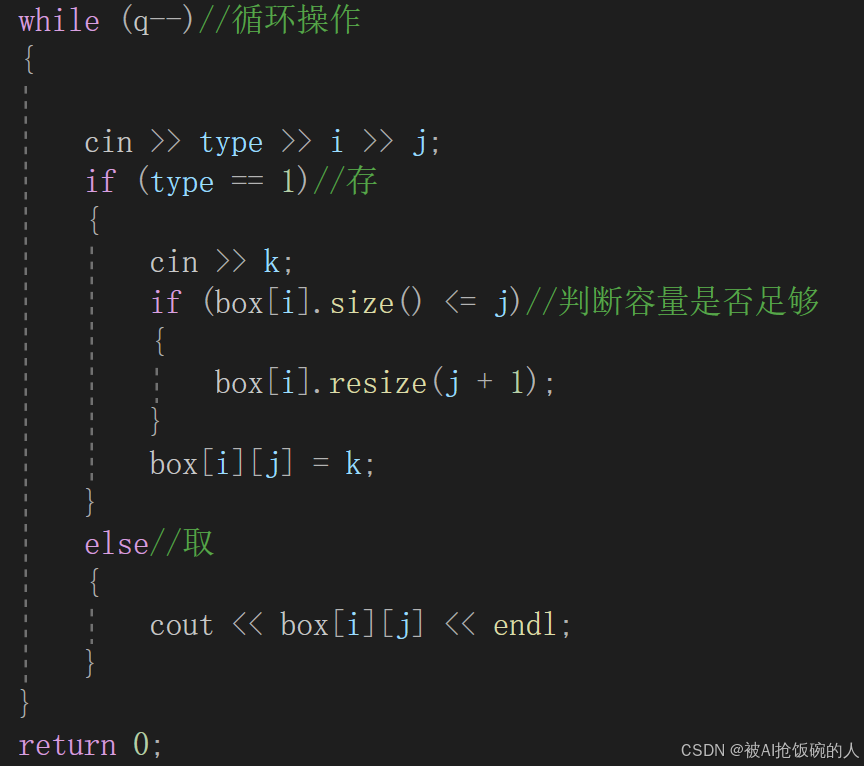
算法题(83):寄包柜
审题: 需要我们对模拟柜子的数组进行插入数据和打印数据的操作 思路: 首先我们观察题目,发现可以用一个数组表示一个柜子,而数组中每个索引的位置可以看成是一个个格子。但是柜子的数据量是1e5,且格子的数据量是1e5.如…...

深入浅出MySQL:概述与体系结构解析
目录 1. 初识MySQL 1.1. 数据库 1.1.1. OLTP(联机事务处理)1.1.2. OLAP(联机分析处理) 2. SQL 2.1. 定义2.2. DQL(数据查询语言)2.3. DML(数据操纵语言)2.4. DDL(数据定…...

tin这个单词怎么记
英语单词 tin,一般用作名词,意为“罐头;锡”: tin n.锡;罐头;罐;罐头盒;(盛涂料、胶水等的)马口铁罐,白铁桶;罐装物;金属食品盒;烘焙…...

【0005】Python变量详解
如果你觉得我的文章写的不错,请关注我哟,请点赞、评论,收藏此文章,谢谢! 本文内容体系结构如下: 任何一个语言编写的程序或者项目,都需要数据的支持,没有数据的项目不能称之为一个…...

yolov8_pose模型,使用rknn在安卓RK3568上使用
最近在使用rknn的一些功能,看了看文档以及自己做的一些jni,使用上yolov8_pose的模型. 1.我们先下载一下rknn的模型功能代码,rk有自己做的一套demo 地址:GitHub - airockchip/rknn_model_zooContribute to airockchip/rknn_model_zoo development by creating an account on G…...

HTTP 协议的发展历程:从 HTTP/1.0 到 HTTP/2.0
HTTP 协议的发展历程:从 HTTP/1.0 到 HTTP/2.0 HTTP(HyperText Transfer Protocol,超文本传输协议)是 Web 的基础协议,用于客户端和服务器之间的通信。从 HTTP/1.0 到 HTTP/2.0,HTTP 协议经历了多次重大改…...

PartitionFinder2 安装与使用-bioinfomatics tools 051
1. 引言 PartitionFinder2 是目前针对大中型数据集(核苷酸、氨基酸、形态数据)最理想的分区检测和进化模型选择工具。其推演的最优进化模型结果与 jModelTest2(核苷酸)和 ProTest3(氨基酸)的结果较为接近。…...

MCP与RAG:增强大型语言模型的两种路径
引言 近年来,大型语言模型(LLM)在自然语言处理任务中展现了令人印象深刻的能力。然而,这些模型的局限性,如知识过时、生成幻觉(hallucination)等问题,促使研究人员开发了多种增强技…...

ARM 架构下 cache 一致性问题整理
本篇文章主要整理 ARM 架构下,和 Cache 一致性相关的一些知识。 本文假设读者具备一定的计算机体系结构和 Cache 相关基础知识,适合有相关背景的读者阅读 1、引言 简单介绍一下 Cache 和内存之间的关系 在使能 Cache 的情况下,CPU 每次获取数…...

GB28181未来发展趋势,如何借助于EasyGBS国标GB28181平台+EasyGBD国标GB28181设备端抓住大机会
GB28181规范目前已经迎来了2022版,随着规范行业影响力和应用范围越来越大,相信还会有类似2028、2030等迭代版本出来,我们预测的GB28181发展趋势可能会是以下几个方面,感兴趣的也可以跟我单独探讨: 技术标准持续优化&a…...

代数结构—笔记
线性空间 如果满足以下性质,则域 K K K上定义了二元运算(加法)与二元函数(数乘)的非空集合 X X X称为线性空间。 1、加法封闭性:对任意 u , v ∈ X u, v \in X u,v∈X,存在 u v ∈ X uv\in X …...