Transformer 代码剖析2 - 模型训练 (pytorch实现)
一、模型初始化模块
参考:项目代码
1.1 参数统计函数
def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)
技术解析:
numel()方法计算张量元素总数requires_grad筛选需要梯度更新的参数- 统计结果反映模型复杂度,典型Transformer-base约65M参数
1.2 权重初始化
def initialize_weights(m):if hasattr(m, 'weight') and m.weight.dim() > 1:nn.init.kaiming_uniform_(m.weight.data)
初始化原理:
- Kaiming初始化针对ReLU族激活函数设计
- 保持前向传播时方差一致性
- 公式: W ∼ U ( − 6 / n i n , 6 / n i n ) W \sim U(-\sqrt{6/n_{in}}, \sqrt{6/n_{in}}) W∼U(−6/nin,6/nin)
1.3 模型实例化
model = Transformer(src_pad_idx=src_pad_idx,trg_pad_idx=trg_pad_idx,trg_sos_idx=trg_sos_idx,d_model=d_model,enc_voc_size=enc_voc_size,dec_voc_size=dec_voc_size,max_len=max_len,ffn_hidden=ffn_hidden,n_head=n_heads,n_layers=n_layers,drop_prob=drop_prob,device=device).to(device)
关键参数解析:
| 参数 | 典型值 | 作用 |
|---|---|---|
| d_model | 512 | 向量表征维度 |
| n_head | 8 | 注意力头数量 |
| ffn_hidden | 2048 | 前馈网络隐层维度 |
| n_layers | 6 | 编码器/解码器堆叠层数 |
| drop_prob | 0.1 | Dropout概率 |
二、训练准备模块
2.1 优化器配置
optimizer = Adam(params=model.parameters(),lr=init_lr,weight_decay=weight_decay,eps=adam_eps)
Adam优化器数学原理:
θ t + 1 = θ t − η v ^ t + ϵ m ^ t \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon}\hat{m}_t θt+1=θt−v^t+ϵηm^t
其中 m ^ t \hat{m}_t m^t和 v ^ t \hat{v}_t v^t为一阶、二阶矩估计的偏差修正项
2.2 学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,verbose=True,factor=factor,patience=patience)
调度策略:
- 监控验证集损失变化
- 当损失停滞时按factor比例(典型0.5)衰减学习率
- patience=5表示连续5次无改善触发衰减
2.3 损失函数
criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)
Padding处理机制:
- 通过ignore_index屏蔽填充符的梯度计算
- 数学表达式修正为:
L = − ∑ i = 1 n y i log p i ⋅ I ( y i ≠ pad ) \mathcal{L} = -\sum_{i=1}^{n} y_i \log p_i \cdot \mathbb{I}(y_i \neq \text{pad}) L=−i=1∑nyilogpi⋅I(yi=pad)
三、训练与评估模块
3.1 训练函数
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoptimizer.zero_grad()output = model(src, trg[:, :-1])output_reshape = output.contiguous().view(-1, output.shape[-1])trg = trg[:, 1:].contiguous().view(-1)loss = criterion(output_reshape, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()print('step :', round((i / len(iterator)) * 100, 2), '% , loss :', loss.item())return epoch_loss / len(iterator)
关键技术点:
- 教师强制(Teacher Forcing):使用真实目标序列作为解码器输入
- 序列切片
trg[:, :-1]去除终止符 - 梯度裁剪防止梯度爆炸
3.2 评估函数
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0batch_bleu = []with torch.no_grad():for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoutput = model(src, trg[:, :-1])output_reshape = output.contiguous().view(-1, output.shape[-1])trg = trg[:, 1:].contiguous().view(-1)loss = criterion(output_reshape, trg)epoch_loss += loss.item()total_bleu = []for j in range(batch_size):try:trg_words = idx_to_word(batch.trg[j], loader.target.vocab)output_words = output[j].max(dim=1)[1]output_words = idx_to_word(output_words, loader.target.vocab)bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())total_bleu.append(bleu)except:passtotal_bleu = sum(total_bleu) / len(total_bleu)batch_bleu.append(total_bleu)batch_bleu = sum(batch_bleu) / len(batch_bleu)return epoch_loss / len(iterator), batch_bleu
BLEU计算原理:
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU = BP \cdot \exp\left(\sum_{n=1}^N w_n \log p_n\right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
其中:
- BP为简洁惩罚因子
- p n p_n pn为n-gram精度
- w n w_n wn为各阶权重(通常平均加权)
四、运行控制模块
4.1 训练循环
def run(total_epoch, best_loss):train_losses, test_losses, bleus = [], [], []for step in range(total_epoch):start_time = time.time()train_loss = train(model, train_iter, optimizer, criterion, clip)valid_loss, bleu = evaluate(model, valid_iter, criterion)end_time = time.time()if step > warmup:scheduler.step(valid_loss)train_losses.append(train_loss)test_losses.append(valid_loss)bleus.append(bleu)epoch_mins, epoch_secs = epoch_time(start_time, end_time)if valid_loss < best_loss:best_loss = valid_losstorch.save(model.state_dict(), 'saved/model-{0}.pt'.format(valid_loss))f = open('result/train_loss.txt', 'w')f.write(str(train_losses))f.close()f = open('result/bleu.txt', 'w')f.write(str(bleus))f.close()f = open('result/test_loss.txt', 'w')f.write(str(test_losses))f.close()print(f'Epoch: {step + 1} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')print(f'\tVal Loss: {valid_loss:.3f} | Val PPL: {math.exp(valid_loss):7.3f}')print(f'\tBLEU Score: {bleu:.3f}')
模型保存策略:
- 采用验证损失作为保存标准
- 使用
model.state_dict()保存参数快照 - 文件命名包含验证损失便于版本管理
五、工程实践要点
5.1 训练技巧
- Warm-up策略:前warmup个epoch不启动学习率衰减
- 混合精度训练:可结合
torch.cuda.amp加速训练 - 梯度累积:小批量数据累积梯度模拟大批量效果
5.2 性能优化
torch.backends.cudnn.benchmark = True # 启用cuDNN自动优化器
torch.autograd.set_detect_anomaly(False) # 禁用异常检测提升速度
5.3 扩展实现
模型并行改造示例
class ParallelTransformer(Transformer):def __init__(self, ...):super().__init__(...)self.encoder = nn.DataParallel(self.encoder)self.decoder = nn.DataParallel(self.decoder)
本节从代码实现到理论机制进行了多角度解析,完整保留原始代码结构的同时通过流程图解耦了各模块的运作机制。实际应用中可根据任务规模调整超参数,建议在8*V100 GPU环境下进行大规模预训练,结合混合精度训练提升训练效率。
源码(附):
"""
@author : Hyunwoong
@when : 2019-10-22
@homepage : https://github.com/gusdnd852
"""
import math
import timefrom torch import nn, optim
from torch.optim import Adamfrom data import *
from models.model.transformer import Transformer
from util.bleu import idx_to_word, get_bleu
from util.epoch_timer import epoch_timedef count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)def initialize_weights(m):if hasattr(m, 'weight') and m.weight.dim() > 1:nn.init.kaiming_uniform(m.weight.data)model = Transformer(src_pad_idx=src_pad_idx,trg_pad_idx=trg_pad_idx,trg_sos_idx=trg_sos_idx,d_model=d_model,enc_voc_size=enc_voc_size,dec_voc_size=dec_voc_size,max_len=max_len,ffn_hidden=ffn_hidden,n_head=n_heads,n_layers=n_layers,drop_prob=drop_prob,device=device).to(device)print(f'The model has {count_parameters(model):,} trainable parameters')
model.apply(initialize_weights)
optimizer = Adam(params=model.parameters(),lr=init_lr,weight_decay=weight_decay,eps=adam_eps)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,verbose=True,factor=factor,patience=patience)criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoptimizer.zero_grad()output = model(src, trg[:, :-1])output_reshape = output.contiguous().view(-1, output.shape[-1])trg = trg[:, 1:].contiguous().view(-1)loss = criterion(output_reshape, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()print('step :', round((i / len(iterator)) * 100, 2), '% , loss :', loss.item())return epoch_loss / len(iterator)def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0batch_bleu = []with torch.no_grad():for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoutput = model(src, trg[:, :-1])output_reshape = output.contiguous().view(-1, output.shape[-1])trg = trg[:, 1:].contiguous().view(-1)loss = criterion(output_reshape, trg)epoch_loss += loss.item()total_bleu = []for j in range(batch_size):try:trg_words = idx_to_word(batch.trg[j], loader.target.vocab)output_words = output[j].max(dim=1)[1]output_words = idx_to_word(output_words, loader.target.vocab)bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())total_bleu.append(bleu)except:passtotal_bleu = sum(total_bleu) / len(total_bleu)batch_bleu.append(total_bleu)batch_bleu = sum(batch_bleu) / len(batch_bleu)return epoch_loss / len(iterator), batch_bleudef run(total_epoch, best_loss):train_losses, test_losses, bleus = [], [], []for step in range(total_epoch):start_time = time.time()train_loss = train(model, train_iter, optimizer, criterion, clip)valid_loss, bleu = evaluate(model, valid_iter, criterion)end_time = time.time()if step > warmup:scheduler.step(valid_loss)train_losses.append(train_loss)test_losses.append(valid_loss)bleus.append(bleu)epoch_mins, epoch_secs = epoch_time(start_time, end_time)if valid_loss < best_loss:best_loss = valid_losstorch.save(model.state_dict(), 'saved/model-{0}.pt'.format(valid_loss))f = open('result/train_loss.txt', 'w')f.write(str(train_losses))f.close()f = open('result/bleu.txt', 'w')f.write(str(bleus))f.close()f = open('result/test_loss.txt', 'w')f.write(str(test_losses))f.close()print(f'Epoch: {step + 1} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')print(f'\tVal Loss: {valid_loss:.3f} | Val PPL: {math.exp(valid_loss):7.3f}')print(f'\tBLEU Score: {bleu:.3f}')if __name__ == '__main__':run(total_epoch=epoch, best_loss=inf)相关文章:
Transformer 代码剖析2 - 模型训练 (pytorch实现)
一、模型初始化模块 参考:项目代码 1.1 参数统计函数 def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)#mermaid-svg-OL9twT8AmPz3Bp0O {font-family:"trebuchet ms",verdana,arial,sans-serif;fon…...

PE文件结构详解(DOS头/NT头/节表/导入表)使用010 Editor手动解析notepad++.exe的PE结构
一:DOS部分 DOS部分分为DOS MZ文件头和DOS块,其中DOS MZ头实际是一个64位的IMAGE_DOS——HEADER结构体。 DOS MZ头部结构体的内容如下,我们所需要关注的是前面两个字节(e_magic)和后面四个字节(e_lfanew&a…...
[含文档+PPT+源码等]精品基于Python实现的vue3+Django计算机课程资源平台
基于Python实现的Vue3Django计算机课程资源平台的背景,可以从以下几个方面进行阐述: 一、教育行业发展背景 1. 教育资源数字化趋势 随着信息技术的快速发展,教育资源的数字化已成为不可逆转的趋势。计算机课程资源作为教育领域的重要组成部…...

vue3中ref和reactive响应式数据、ref模板引用(组合式和选项式区别)、组件ref的使用
目录 Ⅰ.ref 1.基本用法:ref响应式数据 2.ref模板引用 3.ref在v-for中的模板引用 4.ref在组件上使用 5.TS中ref数据标注类型 Ⅱ.reactive 1.基本用法:reactive响应式数据 2.TS中reactive标注类型 Ⅲ.ref和reactive的使用场景和区别 Ⅳ.小结…...

Oracle VM VirtualBox 7.1 安装与虚拟机创建全流程指南(Windows平台)
一、软件定位与核心功能 Oracle VM VirtualBox 是开源跨平台虚拟化工具,支持在 Windows、Linux、macOS 系统上创建和管理虚拟机(VM),其核心功能包括: 多系统兼容:可安装 Windows、Ubuntu、CentOS 等 50 操…...

细说 Java GC 垃圾收集器
一、GC目标 业务角度,我们需要追求2个指标: 低延迟(Latency):请求必须多少毫秒内完成响应;高吞吐(Throughput):每秒完成多少次事务。 两者通常存在权衡关系࿰…...

云原生网络篇——万级节点服务网格与智能流量治理
引言:网络即神经系统 2023年双十一期间,某电商平台的支付网关因瞬时流量激增导致服务网格控制面崩溃,造成2.7亿元交易失败。而另一家跨国流媒体公司通过智能流量治理系统,在跨三大洲的云环境中实现了200万QPS的稳定传输。这两个案…...

请解释 React 中的 Hooks,何时使用 Hooks 更合适?
一、Hooks 核心理解 1. 什么是 Hooks? Hooks 是 React 16.8 引入的函数式编程范式,允许在函数组件中使用状态管理和生命周期能力。就像给函数组件装上了"智能芯片",让原本只能做简单展示的组件具备了处理复杂逻辑的能力。 2. 类…...

《国密算法开发实战:从合规落地到性能优化》
前言 随着信息技术的飞速发展,信息安全已成为全球关注的焦点。在数字化时代,数据的保密性、完整性和可用性直接关系到国家、企业和个人的利益。为了保障信息安全,密码技术作为核心支撑,发挥着至关重要的作用。国密算法,即国家密码算法,是我国自主设计和推广的一系列密码…...

第2章 windows故障排除(网络安全防御实战--蓝军武器库)
网络安全防御实战--蓝军武器库是2020年出版的,已经过去3年时间了,最近利用闲暇时间,抓紧吸收,总的来说,第2章开始带你入门了,这里给出了几个windows重要的工具,说实话,好多我也是第一…...
を利用する設定手順)
DifyでOracle Base Database Service(23ai)を利用する設定手順
[TOC](DifyでOracle Base Database Service(23ai)を利用する設定手順) はじめに 本記事では、DifyプラットフォームとOracle Base Database Service(23aiエディション)を連携させる方法を解説します。クラウド環境における大規模データ処理を想定した設…...

量子关联特性的多维度探索:五量子比特星型系统与两量子比特系统的对比分析
模拟一个五量子比特系统,其中四个量子比特(编号为1, 2, 3, 4)分别与第五个量子比特(编号为5)耦合,形成一个星型结构。分析量子比特1和2的纠缠熵随时间的变化。 系统的哈密顿量H描述了量子比特间的相互作用…...
)
初识C语言之操作符详解(上)
一.操作符分类 1.算数操作符: - * / % 2.移位操作符:<< >> 3.位操作符:& | ʌ 4.赋值操作符: - * / % << >> & | ʌ 5.单目操作符࿱…...

HarmonyOS学习第12天:解锁表格布局的奥秘
表格布局初相识 不知不觉,我们在 HarmonyOS 的学习旅程中已经走到了第 12 天。在之前的学习里,我们逐步掌握了 HarmonyOS 开发的各种基础与核心技能,比如组件的基本使用、布局的初步搭建等,这些知识就像一块块基石,为我…...

【心得】一文梳理高频面试题 HTTP 1.0/HTTP 1.1/HTTP 2.0/HTTP 3.0的区别并附加记忆方法
面试时很容易遇到的一个问题—— HTTP 1.0/HTTP 1.1/HTTP 2.0/HTTP 3.0的区别,其实这四个版本的发展实际上是一环扣一环的,是逐步完善的,本文希望帮助读者梳理清楚各个版本之间的区别,并且给出当前各个版本的应用情况,…...

《Python实战进阶》No 11:微服务架构设计与 Python 实现
第11集:微服务架构设计与 Python 实现 2025年3月3日更新了代码和微服务运行后的系统返回信息截图,所有代码在 python3.11.5虚拟环境下运行通过。 微服务架构通过将复杂应用拆分为独立部署的小型服务,显著提升了系统的可扩展性和维护性。本集…...
)
电商平台项目需求文档(精简版)
以下是电商平台项目需求文档样例(精简版),包含核心功能模块和技术实现要求: 电商平台项目需求文档 一、项目概述 项目名称:ECP-全栈电商平台(ECP - E-Commerce Platform) 技术定位:…...

Android15 Camera HAL Android.bp中引用Android.mk编译的libB.so
背景描述 Android15 Camera HAL使用Android.bp脚本来构建系统。假设Camera HAL中引用了另外一个HAL实现的so (例如VPU HAL), 恰巧被引用的这个VPU HAL so是用Android.mk构建的,那Camera HAL Android.bp在直接引用这个Android.mk编…...
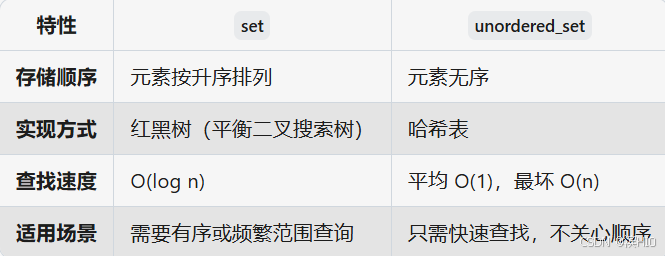
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair 题目 分析一、pair1.1pair与vector的区别1.2 两者使用场景两者组合使用 二、set2.1核心特点2.2set的基本操作2.3 set vs unordered_set示例:统计唯一单词数代码 题目 分析 大佬写的很明白,看这儿 我讲讲…...

postgresql源码学习(60)—— VFD的作用及机制
首先VFD是Virtual File Descriptor,即虚拟文件描述符,既然是虚拟的,一定先有物理的。 一、 物理文件描述符(File Descriptor, FD) 1. 什么是 FD 它是操作系统提供给用户程序访问和操作文件或其他 I/O 资源的抽象接口…...

【CSS—前端快速入门】CSS 选择器
CSS 1. CSS介绍 1.1 什么是CSS? CSS(Cascading Style Sheet),层叠样式表,用于控制页面的样式; CSS 能够对网页中元素位置的排版进行像素级精确控制,实现美化页面的效果;能够做到页面的样式和 结构分离; 1…...

Linux安装jdk,node,mysql,redis
准备工作: 1.安装VMware软件,下载CentOs7镜像文件,在VMware安装CentOs7 2.宿主机安装Xshell用来操作linux 3. .宿主机安装Xftp用来在宿主机和虚拟机的linux传输文件 案例1:在 /home/soft文件夹解压缩jdk17,并配置环…...
深度求索(DeepSeek)的AI革命:NLP、CV与智能应用的技术跃迁
Deepseek官网:DeepSeek 引言:AI技术浪潮中的深度求索 近年来,人工智能技术以指数级速度重塑全球产业格局。在这场技术革命中,深度求索(DeepSeek)凭借其前沿的算法研究、高效的工程化能力以及对垂直场景的…...

Minio搭建并在SpringBoot中使用完成用户头像的上传
Minio使用搭建并上传用户头像到服务器操作,学习笔记 Minio介绍 minio官网 MinIO是一个开源的分布式对象存储服务器,支持S3协议并且可以在多节点上实现数据的高可用和容错。它采用Go语言开发,拥有轻量级、高性能、易部署等特点,并且可以自由…...

【鸿蒙Next】 测试包 签名、打包、安装 整体过程记录
签名打包记录: HarmonyOS应用签名、打Hap包、Hap调试包真机安装步骤 https://blog.csdn.net/qq_34462735/article/details/135226332 测试包真机安装方式二 DevEco Testing 鸿蒙应用示例:DevEco Testing 工具的常用功能及使用场景 https://blog.csd…...

阿里云 | 快速在网站上增加一个AI助手
创建智能体应用 如上所示,登录阿里云百炼人工智能业务控制台,创建智能体应用,智能体应用是一个agent,即提供个人或者企业的代理或中间件组件应用,对接阿里云大模型公共平台,为个人或者企业用户提供大模型应…...

Raspberry Pi边缘计算网关设计与LoRa通信实现
Raspberry Pi边缘计算网关设计与LoRa通信实现 摘要第一章 绪论1.1 研究背景1.2 研究现状1.3 论文结构 第二章 相关技术理论2.1 边缘计算体系架构2.2 LoRa通信技术2.3 Raspberry Pi硬件生态 第三章 系统架构设计3.1 硬件架构设计3.2 软件架构设计3.3 混合通信协议设计 第四章 硬…...

原型链与继承
#搞懂还是得自己动手# 原型链 function Person(name) { this.name name; } Person.prototype.sayName function() { console.log(this.name); };const p new Person("Alice"); 原型链关系图: 原型链:person->Person.prototype->O…...

动态规划 ─── 算法5
动态规划(Dynamic Programming,简称 DP)是一种用于解决复杂问题的算法设计技术,特别适用于具有重叠子问题和最优子结构性质的问题。动态规划通过将问题分解为更小的子问题,并存储子问题的解来避免重复计算,…...

博客系统--测试报告
博客系统--测试报告 项目背景项目功能功能测试①登录功能测试②发布博客功能测试③删除文章功能测试④功能测试总结: 自动化测试自动化脚本执行界面: 性能测试 本博文主要针对个人实现的项目《博客系统》去进行功能测试、自动化测试、性能测试࿰…...