机器学习:监督学习、无监督学习和强化学习
机器学习(Machine Learning, ML)是人工智能(AI)的一个分支,它使计算机能够从数据中学习,并在没有明确编程的情况下执行任务。机器学习的核心思想是使用算法分析数据,识别模式,并做出预测或决策。
1. 机器学习的主要类别
监督学习、无监督学习和强化学习:算法与应用场景
机器学习主要分为 监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)。它们在不同任务中有各自适用的算法和应用场景。
1. 监督学习(Supervised Learning)
概念
监督学习是一种基于带标签数据进行训练的机器学习方法。数据集由输入特征(X)和对应的输出标签(Y) 组成,模型通过学习输入到输出的映射关系,在遇到新数据时能够进行预测。
常见算法
| 算法 | 任务类型 | 适用场景 |
|---|---|---|
| 线性回归(Linear Regression) | 回归 | 房价预测、股票价格预测 |
| 逻辑回归(Logistic Regression) | 分类 | 垃圾邮件分类、信用卡欺诈检测 |
| 支持向量机(SVM) | 分类 | 文本分类、人脸识别 |
| K 近邻(KNN) | 分类/回归 | 推荐系统、疾病预测 |
| 决策树(Decision Tree) | 分类/回归 | 客户流失预测、信用评估 |
| 随机森林(Random Forest) | 分类/回归 | 广告点击预测、风险评估 |
| 梯度提升树(GBDT, XGBoost, LightGBM) | 分类/回归 | Kaggle 竞赛、搜索排名 |
| 神经网络(Neural Networks) | 分类/回归 | 图像识别、语音识别 |
应用场景
-
计算机视觉:
- 图像分类(如猫狗识别)
- 物体检测(如自动驾驶)
-
自然语言处理(NLP):
- 语音识别(如 Siri、语音转文字)
- 情感分析(如微博情绪分析)
-
金融风控:
- 信用评分(预测用户是否违约)
- 交易欺诈检测(检测是否存在异常交易)
-
医疗健康:
- 疾病预测(如糖尿病预测)
- 癌症检测(基于医学影像)
-
电子商务:
- 用户购买预测(预测用户是否会购买某件商品)
- 推荐系统(基于用户历史数据推荐商品)
2. 无监督学习(Unsupervised Learning)
概念
无监督学习用于没有标签的数据,主要用于数据模式发现,如数据分类、降维、异常检测等。
常见算法
| 算法 | 任务类型 | 适用场景 |
|---|---|---|
| K-means 聚类 | 聚类 | 客户分群、图像分割 |
| DBSCAN | 聚类 | 异常检测、地理位置分析 |
| 层次聚类 | 聚类 | 社交网络分析、基因分析 |
| 主成分分析(PCA) | 降维 | 高维数据可视化、特征降维 |
| t-SNE | 降维 | 图像处理、文本分析 |
| 自编码器(Autoencoder) | 特征学习 | 异常检测、数据压缩 |
| 关联规则学习(Apriori, FP-Growth) | 规则挖掘 | 购物篮分析、推荐系统 |
应用场景
-
客户分群
- 电子商务网站根据用户行为对用户进行分群(K-means)
- 银行对客户进行信用分级(层次聚类)
-
异常检测
- 信用卡欺诈检测(基于 Autoencoder)
- 服务器异常流量检测(DBSCAN)
-
推荐系统
- 商品关联推荐(如 Apriori 规则学习)
- 电影推荐(基于用户兴趣聚类)
-
文本分析
- 文本主题建模(LDA 主题模型)
- 新闻分类(基于 K-means 进行文本聚类)
-
数据降维
- PCA 用于降维高维图像数据
- t-SNE 进行数据可视化(如 MNIST 手写数字可视化)
3. 强化学习(Reinforcement Learning, RL)
概念
强化学习是一种基于奖励信号的学习方法,智能体(Agent)在与环境交互时,通过获得奖励或惩罚来优化其策略,以最大化长期回报。
常见算法
| 算法 | 任务类型 | 适用场景 |
|---|---|---|
| Q-learning | 值迭代 | 机器人导航、游戏 AI |
| SARSA | 值迭代 | 自适应控制 |
| 深度 Q 网络(DQN) | 值迭代 + 神经网络 | 视频游戏 AI(AlphaGo) |
| 策略梯度(Policy Gradient) | 策略优化 | 自动驾驶、对话系统 |
| 近端策略优化(PPO) | 策略优化 | 机器人控制 |
| 软 Actor-Critic(SAC) | 连续控制 | 机械臂操作 |
| A3C | 并行训练 | 复杂环境下的智能体决策 |
应用场景
-
自动驾驶
- 强化学习用于模拟自动驾驶环境,提高无人车决策能力。
-
游戏 AI
- AlphaGo 通过强化学习击败人类围棋选手。
- 强化学习用于训练 AI 玩 Dota 2、星际争霸等游戏。
-
机器人控制
- 机器人通过强化学习学习行走。
- 机械臂通过强化学习优化抓取物体的策略。
-
智能推荐
- 通过强化学习优化推荐系统,例如新闻推荐、视频推荐。
-
金融交易
- 量化交易中强化学习用于优化买卖决策,最大化收益。
对比总结
| 特性 | 监督学习 | 无监督学习 | 强化学习 |
|---|---|---|---|
| 是否有标签数据 | 是 | 否 | 通过奖励信号学习 |
| 目标 | 预测或分类 | 发现数据结构 | 通过试错优化策略 |
| 数据需求 | 大量标注数据 | 未标注数据 | 交互式数据 |
| 应用场景 | 图像识别、语音识别 | 聚类、异常检测 | 游戏 AI、机器人 |
如何选择适合的机器学习方法?
- 如果有标注数据,并且需要预测具体的值或类别 → 监督学习
- 如果没有标签数据,希望找到数据的结构或模式 → 无监督学习
- 如果任务涉及交互式环境,并且需要通过试错优化策略 → 强化学习
2. 机器学习的核心流程
无论是哪种机器学习方法,一般都遵循以下步骤:
-
数据收集(Data Collection):
- 从数据库、传感器、互联网等收集数据。
-
数据预处理(Data Preprocessing):
- 缺失值处理:填充或删除缺失数据。
- 数据清理:去除异常值,转换数据格式。
- 特征工程:提取关键特征,如标准化、归一化、降维。
-
选择合适的模型(Model Selection):
- 线性回归、决策树、神经网络等,根据问题选择合适的模型。
-
训练模型(Model Training):
- 使用训练数据调整模型参数,使其尽可能拟合数据。
-
模型评估(Model Evaluation):
- 使用测试数据评估模型性能,常见评估指标:
- 回归任务:均方误差(MSE)、R²
- 分类任务:准确率(Accuracy)、F1 分数、ROC 曲线
- 使用测试数据评估模型性能,常见评估指标:
-
模型优化(Model Optimization):
- 超参数调优,如调整学习率、选择不同优化算法(如 Adam、SGD)。
- 交叉验证(Cross Validation)以避免过拟合。
-
部署和预测(Deployment & Prediction):
- 训练好的模型用于新数据预测,如推荐系统、自动驾驶、语音识别等。
3. 机器学习的一些关键概念
(1) 过拟合(Overfitting)和欠拟合(Underfitting)
- 过拟合:模型过度学习训练数据的细节,导致泛化能力差,在新数据上表现不好。
- 欠拟合:模型过于简单,无法学习训练数据中的模式,表现不佳。
解决方案:
- 交叉验证(Cross Validation)
- 正则化(L1/L2 正则)
- 数据增强(Data Augmentation)
- 增加训练数据量
(2) 特征工程(Feature Engineering)
特征工程是提升机器学习模型性能的重要步骤,包括:
- 特征选择(Feature Selection):选择最相关的特征,减少数据维度。
- 特征提取(Feature Extraction):例如从文本中提取关键词。
- 数据变换(Feature Scaling):归一化或标准化数据,如 Min-Max 归一化。
(3) 评价指标
不同任务使用不同的评估指标:
-
回归任务
- 均方误差(MSE)
- 平均绝对误差(MAE)
- R² 评分
-
分类任务
- 准确率(Accuracy):正确分类的样本比例。
- 精确率(Precision):预测为正样本中真正为正的比例。
- 召回率(Recall):真正为正的样本中被正确预测的比例。
- F1 分数(F1-score):Precision 和 Recall 的调和平均数。
- ROC 曲线 & AUC:衡量模型的分类能力。
4. 机器学习的应用
机器学习在许多领域都得到了广泛应用:
(1) 计算机视觉(Computer Vision)
- 目标检测、人脸识别(如 iPhone 的 Face ID)
- 自动驾驶(特斯拉自动驾驶)
(2) 自然语言处理(NLP)
- 机器翻译(Google Translate)
- 语音识别(Siri, Google Assistant)
- 生成式 AI(ChatGPT)
(3) 推荐系统
- 视频推荐(Netflix, YouTube)
- 购物推荐(淘宝、京东)
- 音乐推荐(Spotify)
(4) 金融与医疗
- 诈骗检测(银行信用卡欺诈检测)
- 股票市场预测
- 疾病预测(癌症检测)
5. 机器学习工具与框架
- Python 语言(最常用):Scikit-learn、TensorFlow、PyTorch、XGBoost
- 数据处理工具:Pandas、NumPy
- 可视化工具:Matplotlib、Seaborn
- 深度学习:TensorFlow(Google)、PyTorch(Facebook)
6. 机器学习 vs 深度学习
机器学习和深度学习的区别:
- 机器学习:需要手工设计特征(如特征工程),然后输入模型(如决策树、SVM)。
- 深度学习(Deep Learning):使用神经网络(如 CNN、RNN),能够自动学习特征,特别适用于图像、语音、文本数据。
6.1. 深度学习(Deep Learning, DL)
概念
深度学习是一种基于**人工神经网络(ANN)**的机器学习方法,能够自动学习数据中的特征,并进行分类、回归或生成任务。
特点
- 数据驱动:需要大量数据进行训练
- 静态映射:模型学习的是输入 → 输出的映射关系
- 无交互:训练过程不依赖环境反馈
- 依赖梯度下降:通常使用反向传播 + 梯度下降来优化神经网络参数
常见网络架构
| 网络类型 | 主要应用 | 例子 |
|---|---|---|
| 卷积神经网络(CNN) | 图像处理 | 人脸识别、目标检测 |
| 循环神经网络(RNN) | 序列数据 | 语音识别、文本生成 |
| 长短时记忆网络(LSTM) | 依赖长期上下文的序列数据 | 机器翻译、语音合成 |
| 变换器(Transformer) | NLP、时间序列 | GPT、BERT、T5 |
| 生成对抗网络(GAN) | 生成模型 | DeepFake、图像生成 |
| 自编码器(Autoencoder) | 无监督学习 | 异常检测、数据降维 |
应用场景
- 计算机视觉:图像分类(ResNet)、目标检测(YOLO)
- 自然语言处理:机器翻译(Google Translate)、文本摘要(ChatGPT)
- 语音处理:语音识别(Siri)、语音合成(WaveNet)
- 医学影像:疾病检测(如 CT、X-ray 诊断)
- 金融:股票价格预测、信用风险评估
2. 强化学习(Reinforcement Learning, RL)
概念
强化学习是一种基于奖励反馈的学习方法,智能体(Agent)在环境(Environment)中采取行动(Action),根据获得的奖励(Reward)调整策略(Policy),以最大化长期收益(Cumulative Reward)。
特点
- 探索与试错:智能体通过不断尝试优化策略
- 动态决策:学习的是状态 → 动作的映射关系
- 交互式学习:智能体在环境中不断学习和调整
- 非监督学习:没有明确的标签,而是基于奖励信号进行优化
强化学习核心要素
| 组件 | 作用 |
|---|---|
| 环境(Environment) | 任务所在的世界,智能体在其中行动 |
| 智能体(Agent) | 需要学习最佳策略的主体 |
| 状态(State, s) | 环境的当前状态 |
| 动作(Action, a) | 智能体可采取的行为 |
| 奖励(Reward, r) | 反馈,告诉智能体某个动作的好坏 |
| 策略(Policy, π) | 智能体在不同状态下选择动作的规则 |
| 值函数(Value Function, V) | 评估某个状态的长期收益 |
| Q 函数(Q-value, Q(s,a)) | 评估某个状态下采取特定动作的价值 |
常见强化学习算法
| 算法 | 主要特点 | 适用场景 |
|---|---|---|
| Q-learning | 基于值迭代的离线学习 | 游戏、推荐系统 |
| SARSA | 基于值迭代的在线学习 | 动态环境控制 |
| DQN(深度 Q 网络) | 用 CNN 近似 Q 值函数 | 复杂游戏(如 AlphaGo) |
| Policy Gradient | 直接优化策略 | 连续控制(机器人) |
| PPO(近端策略优化) | 训练稳定,广泛应用 | 机器人控制、自动驾驶 |
| A3C(Actor-Critic) | 并行训练加速 | 复杂环境决策 |
| SAC(Soft Actor-Critic) | 适用于连续控制 | 机械臂、无人机 |
应用场景
- 游戏 AI:AlphaGo、Dota 2 AI
- 自动驾驶:学习如何安全驾驶
- 机器人控制:机械臂操作、自动导航
- 金融投资:量化交易、动态资产管理
- 工业优化:智能制造、供应链优化
6.3. 深度学习 vs. 强化学习
| 维度 | 深度学习(DL) | 强化学习(RL) |
|---|---|---|
| 数据需求 | 需要大量标注数据 | 通过交互生成数据 |
| 学习方式 | 监督学习/无监督学习 | 试错学习(探索+利用) |
| 目标 | 学习输入到输出的映射 | 通过环境交互学习最优策略 |
| 训练方式 | 反向传播 + 梯度下降 | 价值迭代 / 策略优化 |
| 应用领域 | 计算机视觉、NLP | 游戏 AI、机器人、自适应控制 |
| 交互性 | 无交互,单次推理 | 需要环境反馈 |
6.4. 深度强化学习(Deep Reinforcement Learning, DRL)
深度学习和强化学习可以结合,形成深度强化学习(DRL),用于更复杂的决策问题。例如:
-
DQN(Deep Q-Network):用 CNN 近似 Q 值函数,玩 Atari 游戏
-
AlphaGo:用神经网络 + 强化学习训练围棋 AI
-
自动驾驶:用深度强化学习优化驾驶策略
-
如果有大量标注数据,任务是预测或分类 → 深度学习
-
如果任务需要交互式学习、优化决策策略 → 强化学习
-
如果任务是智能体在复杂环境中决策 → 深度强化学习
相关文章:

机器学习:监督学习、无监督学习和强化学习
机器学习(Machine Learning, ML)是人工智能(AI)的一个分支,它使计算机能够从数据中学习,并在没有明确编程的情况下执行任务。机器学习的核心思想是使用算法分析数据,识别模式,并做出…...

SpringBoot项目注入 traceId 来追踪整个请求的日志链路
SpringBoot项目注入 traceId 来追踪整个请求的日志链路,有了 traceId, 我们在排查问题的时候,可以迅速根据 traceId 查找到相关请求的日志,特别是在生产环境的时候,用户可能只提供一个错误截图,我们作为开发…...

苹果廉价机型 iPhone 16e 影像系统深度解析
【人像拍摄差异】 尽管iPhone 16e支持后期焦点调整功能,但用户无法像iPhone 16系列那样通过点击屏幕实时切换拍摄主体。前置摄像头同样缺失人像深度控制功能,不过TrueTone原彩闪光灯系统在前后摄均有保留。 很多人都高估了 iPhone 的安全性,查…...

视觉图像坐标转换
1. 透镜成像 相机的镜头系统将三维场景中的光线聚焦到一个平面(即传感器)。这个过程可以用小孔成像模型来近似描述,尽管实际相机使用复杂的透镜系统来减少畸变和提高成像质量。 小孔成像模型: 假设有一个理想的小孔,…...

汽车电子电控软件开发中因复杂度提升导致的架构恶化问题
针对汽车电子电控软件开发中因复杂度提升导致的架构恶化问题,建议从以下方向进行架构优化和开发流程升级,以提升灵活性、可维护性和扩展性: 一、架构设计与模块化优化 分层架构与模块解耦 采用AUTOSAR标准的分层架构(应用层、运行…...

2024年第十五届蓝桥杯大赛软件赛省赛Python大学A组真题解析《更新中》
文章目录 试题A: 拼正方形(本题总分:5 分)解析答案试题B: 召唤数学精灵(本题总分:5 分)解析答案试题C: 数字诗意解析答案试题D:回文数组试题A: 拼正方形(本题总分:5 分) 【问题描述】 小蓝正在玩拼图游戏,他有7385137888721 个2 2 的方块和10470245 个1 1 的方块,他需…...

脚本无法获取响应主体(原因:CORS Missing Allow Credentials)
背景: 前端的端口号8080,后端8000。需在前端向后端传一个参数,让后端访问数据库去检测此参数是否出现过。涉及跨域请求,一直有这个bug是404文件找不到。 在修改过程当中不小心删除了一段代码,出现了这个bug࿰…...

leetcode第39题组合总和
原题出于leetcode第39题https://leetcode.cn/problems/combination-sum/description/题目如下: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以…...

在 macOS 系统上安装 kubectl
在 macOS 系统上安装 kubectl 官网:https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-macos/ 用 Homebrew 在 macOS 系统上安装 如果你是 macOS 系统,且用的是 Homebrew 包管理工具, 则可以用 Homebrew 安装 kubectl。 运行…...

SQLark 数据迁移|断点续迁已上线(Oracle-达梦)
数据迁移是 SQLark 最受企业和个人用户欢迎的功能之一,截止目前已帮助政府、金融、能源、通信等 50 家单位完成从 Oracle、MySQL 到达梦的全量迁移,自动化迁移成功率达 96% 以上。 在 Oracle 到达梦数据库迁移过程中,SQLark V3.3 新增 断点续…...

Element Plus中el-tree点击的节点字体变色加粗
el-tree标签设置 <el-tree class"tree":data"treeData":default-expand-all"true":highlight-current"true"node-click"onTreeNodeClick"><!-- 自定义节点内容,点击的节点字体变色加粗 --><!-- 动…...

vmware安装firepower ftd和fmc
在vmware虚拟机中安装cisco firepower下一代防火墙firepower threat defence(ftd)和管理中心firepower management center(fmc)。 由于没有cisco官网下载账号,无法下载其中镜像。使用eveng模拟器中的ftd和fmc虚拟镜像…...

计算机毕业设计SpringBoot+Vue.js医院资源管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

[含文档+PPT+源码等]精品基于Python实现的微信小程序的乡村医疗咨询系统
基于Python实现的微信小程序的乡村医疗咨询系统背景,可以从以下几个方面进行阐述: 一、社会背景 医疗资源分布不均:在我国,城乡医疗资源分布不均是一个长期存在的问题。乡村地区由于地理位置偏远、经济条件有限,往往…...

Python实现GO鹅优化算法优化BP神经网络回归模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后关注获取。 1.项目背景 传统BP神经网络的局限性:BP(Back Propagation)神经网络作为一种…...
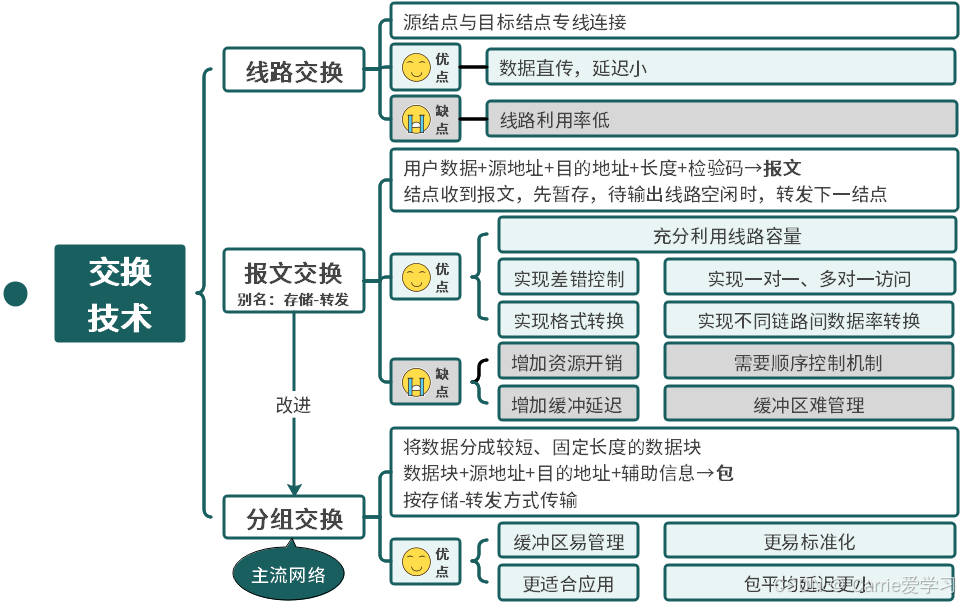
7.1.2 计算机网络的分类
文章目录 分布范围交换方式 分布范围 计算机网络按照分布范围可分为局域网、广域网、城域网。局域网的范围在10m~1km,例如校园网,网速高,主要用于共享网络资源,拓扑结构简单,约束少。广域网的范围在100km,例…...

千峰React:Hooks(上)
什么是Hooks ref引用值 普通变量的改变一般是不好触发函数组件的渲染的,如果想让一般的数据也可以得到状态的保存,可以使用ref import { useState ,useRef} from reactfunction App() {const [count, setCount] useState(0)let num useRef(0)const h…...

设置同一个局域网内远程桌面Ubuntu
1、安装xrdp: 打开终端,运行以下命令来安装xrdp: sudo apt update sudo apt install xrdp 2、启动 XRDP 并设置开机自启 sudo systemctl start xrdp sudo systemctl enable xrdp 3、验证 XRDP 运行状态 sudo systemctl status xrdp 如果显示 active (ru…...

深入 Python:变量与数据类型的奥秘
在 Python 编程的世界里,变量和数据类型是构建程序大厦的基石。它们看似简单,却蕴含着无尽的奥秘和强大的功能。今天,就让我们一起深入探索 Python 中变量与数据类型的奇妙世界。 常量和表达式:数学世界的 Python 映射 在 Pytho…...

LeetCode 718 - 最长重复子数组
LeetCode 718 - 最长重复子数组 是一个典型的数组和字符串问题,适合考察动态规划、滑动窗口和二分查找等多种编程能力。掌握其多种解法及变体能够有效提高处理字符串和数组算法的能力。 题目描述 输入: 两个整数数组 nums1 和 nums2。输出: 两个数组中存在的最长的…...

什么是预训练语言模型下游任务?
问题:Word2Vec模型是预训练模型吗? 由于训练的特性,word2Vec模型一定是与训练模型。给定一个词先使用独热编码然后使用预训练好的Q矩阵得到这个词的词向量。这里指的是词向量本身就是预训练的语言模型。 什么是下游任务? 在自然…...

jvm内存模型,类加载机制,GC算法,垃圾回收器,jvm线上调优等常见的面试题及答案
JVM内存模型 JVM内存模型包括哪些区域 答案:JVM内存模型主要包括以下区域: 程序计数器:是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器,用于记录正在执行的虚拟机字节码指令的地址。Java虚拟机…...

[Windows] 免费电脑控制手机软件 极限投屏_正式版_3.0.1 (QtScrcpy作者开发)
[Windows] 极限投屏_正式版 链接:https://pan.xunlei.com/s/VOKJf8Z1u5z-cHcTsRpSd89tA1?pwdu5ub# 新增功能(Future): 支持安卓14(Supports Android 14)提高投屏成功率(Improve the success rate of mirror)加快投屏速度(Accelerate screen mirrorin…...

C++初阶—list类
第一章:list的介绍及使用 1.1 list的介绍 list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指…...

【子网掩码计算器:Python + Tkinter 实现】
子网掩码计算器:Python Tkinter 实现 引言代码功能概述代码实现思路1. 界面设计2. 功能实现3. 事件处理 子网掩码计算器实现步骤1. 导入必要的库2. 定义主窗口类 SubnetCalculatorApp3. 创建菜单栏4. 创建界面组件5. 判断 IP 地址类别6. 计算子网信息7. 其他功能函…...

入门基础项目(SpringBoot+Vue)
文章目录 1. css布局相关2. JS3. Vue 脚手架搭建4. ElementUI4.1 引入ElementUI4.2 首页4.2.1 整体框架4.2.2 Aside-logo4.2.3 Aside-菜单4.2.4 Header-左侧4.2.5 Header-右侧4.2.6 iconfont 自定义图标4.2.7 完整代码 4.3 封装前后端交互工具 axios4.3.1 安装 axios4.3.2 /src…...

Nginx+PHP+MYSQL-Ubuntu在线安装
在 Ubuntu 上配置 Nginx、PHP 和 MySQL 的步骤如下: 1. 更新系统包 首先,确保系统包是最新的: sudo apt update sudo apt upgrade2. 安装 Nginx 安装 Nginx: sudo apt install nginx启动并启用 Nginx 服务: sudo…...

车载以太网-基于linux的ICMP协议
对于车载以太网-ICMP的技术要求: /** ICMP报文格式解析* -----------------* ICMP协议用于网络诊断和错误报告,常见应用包括Ping测试。* ICMP报文结构包括:IP头部、ICMP头部和ICMP数据部分。* 下面详细介绍每个部分的结构、字段的作用以及如何解析它们。* * ICMP头部结构:*…...

虚拟机快照与linux的目录结构
虚拟机快照是对虚拟机某一时刻状态的完整捕获,包括内存、磁盘、配置及虚拟硬件状态等,保存为独立文件。 其作用主要有数据备份恢复、方便系统测试实验、用于灾难恢复以及数据对比分析。具有快速创建和恢复、占用空间小、可多个快照并存的特点。在管理维…...

Unity小功能实现:鼠标点击移动物体
1、功能描述 当玩家点击鼠标时,场景中的物体会移动到鼠标点击的位置。这个功能可以用于控制角色移动、放置物体等场景。 2、实现步骤 创建Unity项目:首先,打开Unity并创建一个新的3D项目。 添加3D物体:在场景中创建一个3D物体&am…...