Transformer架构
-
核心原理
-
自注意力机制
通过计算输入序列中每个位置与其他位置的关联权重(Query-Key匹配),动态聚合全局信息,解决了传统RNN/CNN的长距离依赖问题。
- 实现公式:Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(dkQKT)V,其中QQ、KK、VV分别由输入向量通过线性变换得到。
-
多头注意力
并行执行多组注意力计算,增强模型捕捉不同子空间特征的能力。
- 位置编码:引入绝对位置编码(如正弦函数)或相对位置编码(如旋转位置编码RoPE),为序列中的位置信息建模。
-
架构设计
-
编码器-解码器结构:
- 编码器:通过自注意力层和前馈网络提取输入特征,适用于分类、语义理解等任务(如BERT)。
- 解码器:结合自注意力和交叉注意力(关注编码器输出),用于生成式任务(如GPT系列)。
-
优化技术:
- FlashAttention:通过分块计算和内存优化,降低注意力矩阵的计算复杂度。
- KV缓存:在推理阶段缓存历史Key-Value向量,减少重复计算。
-
-
优缺点
- 优势:全局建模能力强、并行度高,适合大规模训练7。
- 局限性:计算复杂度与序列长度平方成正比,内存占用高7。
总结与适用场景
- Transformer:通用性强,适合需要全局建模的任务(如文本生成、翻译)。
- MoE:适合超大规模模型(如多模态、专业领域模型),兼顾性能与推理效率。
- 技术趋势:架构设计逐渐向稀疏化、动态化发展(如MoE与Transformer的深度结合),同时优化训练稳定性与硬件适配性。
Transformer开源代码详解(PyTorch框架)
一、模型整体结构
Transformer由编码器层(Encoder Layers)和解码器层(Decoder Layers)构成,核心模块通过nn.Module类封装实现。
class Transformer(nn.Module):def __init__(self, n_layers=6, d_model=512, n_heads=8):super().__init__()self.encoder = Encoder(n_layers, d_model, n_heads)self.decoder = Decoder(n_layers, d_model, n_heads)self.projection = nn.Linear(d_model, vocab_size) # 输出层映射到词表:ml-citation{ref="5" data="citationList"}
二、核心模块实现
-
多头自注意力(Multi-Head Attention)
- 计算流程:
class MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):super().__init__()self.W_q = nn.Linear(d_model, d_model) # Query矩阵self.W_k = nn.Linear(d_model, d_model) # Key矩阵self.W_v = nn.Linear(d_model, d_model) # Value矩阵self.W_o = nn.Linear(d_model, d_model) # 输出投影:ml-citation{ref="3,6" data="citationList"}def forward(self, Q, K, V, mask=None):# 拆分多头(reshape+transpose实现)Q = self.split_heads(Q) # [batch, n_heads, seq_len, d_k]K = self.split_heads(K)V = self.split_heads(V)# Scaled Dot-Product计算scores = torch.matmul(Q, K.transpose(-2, -1)) / np.sqrt(d_k)if mask is not None: # 应用掩码(训练时防止信息泄露):ml-citation{ref="8" data="citationList"}scores = scores.masked_fill(mask == 0, -1e9)attn = F.softmax(scores, dim=-1)output = torch.matmul(attn, V) # 聚合Value向量return self.W_o(output) # 合并多头输出:ml-citation{ref="1,3" data="citationList"}
位置编码(Positional Encoding)
- 实现方法:
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置正弦编码pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置余弦编码:ml-citation{ref="1,4" data="citationList"}
前馈网络(Feed Forward Network)
- 结构说明:
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff=2048):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(0.1)def forward(self, x):return self.linear2(self.dropout(F.relu(self.linear1(x)))) # ReLU激活+残差连接:ml-citation{ref="4,5" data="citationList"}
三、关键数据处理机制
-
掩码生成(Mask Generation)
- Padding Mask:
-
def get_pad_mask(seq, pad_idx):return (seq != pad_idx).unsqueeze(-2) # 过滤填充符:ml-citation{ref="8" data="citationList"}Sequence Mask:
-
def get_subsequent_mask(seq):sz_b, len_s = seq.size()subsequent_mask = (1 - torch.triu(torch.ones(1, len_s, len_s), diagonal=1)).bool()return subsequent_mask # 防止解码时看到未来信息:ml-citation{ref="8" data="citationList"}残差连接与层归一化
- 实现方式:
-
class SublayerConnection(nn.Module):def __init__(self, d_model):super().__init__()self.norm = nn.LayerNorm(d_model)self.dropout = nn.Dropout(0.1)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x))) # 先归一化再执行子层计算:ml-citation{ref="3,5" data="citationList"}四、训练与推理优化
-
并行计算加速
- 输入序列整体矩阵运算(非循环处理),利用GPU并行计算提升效率6。
- 使用
nn.Transformer类内置并行化接口(如batch_first=True参数)2。
-
学习率调度策略
- Warmup机制:初始阶段线性增加学习率,避免梯度不稳定5。
-
lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda step: min((step+1)==‌**-0.5, (step+1)*warmup**‌==-1.5) )五、开源代码实践建议
-
快速上手方案
- 使用Hugging Face库加载预训练模型:
-
from transformers import AutoModel model = AutoModel.from_pretrained("bert-base-uncased") # 直接调用Transformer变体:ml-citation{ref="2" data="citationList"} -
自定义任务适配
- 修改输出层维度:调整
projection层适配分类/生成任务5。 - 扩展位置编码:替换为旋转位置编码(RoPE)提升长文本处理能力。
- 修改输出层维度:调整
-
总结
Transformer的开源代码通过模块化设计(如多头注意力、位置编码)和高效计算优化(矩阵并行、残差连接)实现灵活性与性能平衡。开发者可通过PyTorch官方接口快速搭建模型,或基于社区优化版本(如Hugging Face、DeepSeek)进行二次开发。
相关文章:
Transformer架构
核心原理 自注意力机制 通过计算输入序列中每个位置与其他位置的关联权重(Query-Key匹配),动态聚合全局信息,解决了传统RNN/CNN的长距离依赖问题。 实现公式:Attention(Q,K,V)softmax(QKTdk)VAttention(…...
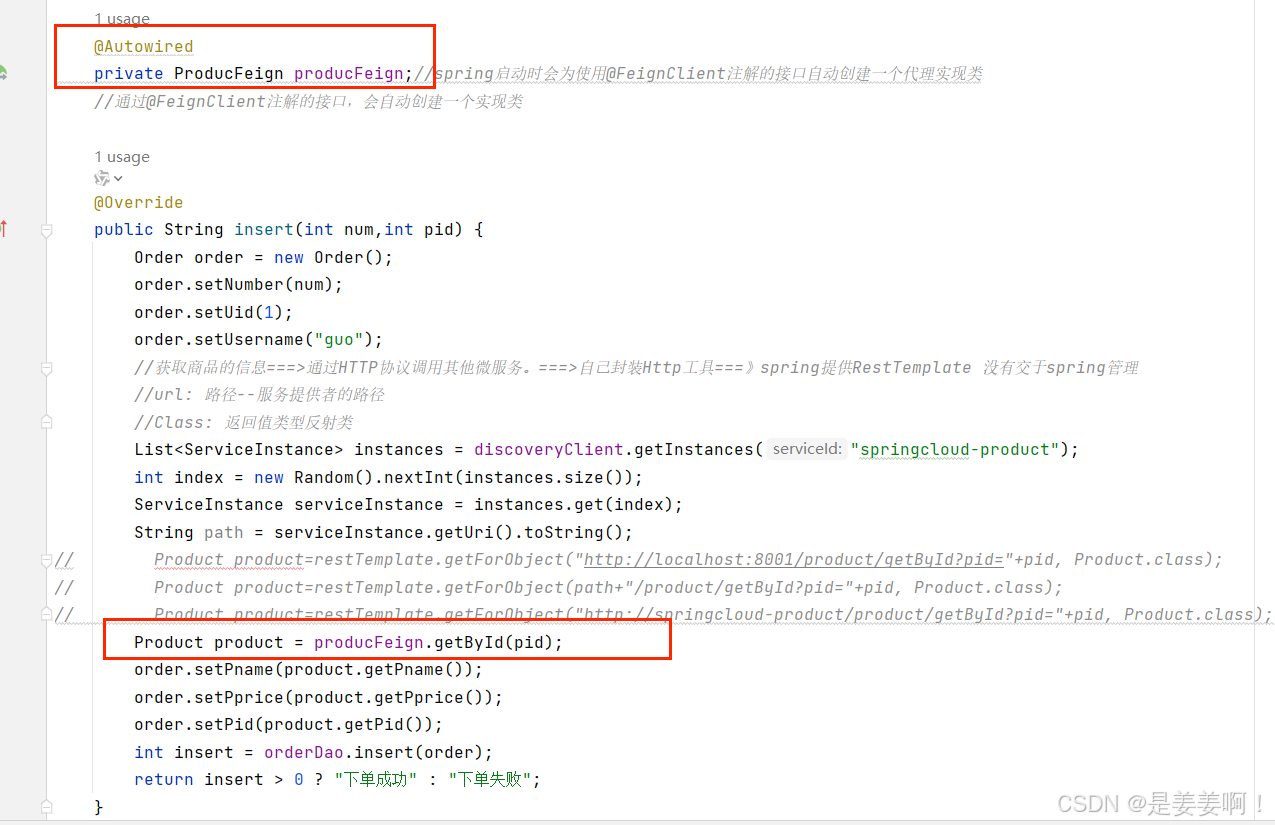
微服务,服务治理nacos,负载均衡LOadBalancer,OpenFeign
1.微服务 简单来说,微服务架构风格[1]是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在 自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并 且可通过全自动部署机制独立部署。这…...

服务器租用:静态BGP和动态BGP分别指什么?
今天小编主要来带大家一起了解一下静态BGP和动态BGP分别是指什么? BGP主要是用在不同网络之间进行交换路由信息的协议,通常是用在互联网当中,而静态BGP和动态BGP是两种不同的方法来配置BGP路由,静态BGP路由是由手动配置的…...

栈和队列的模拟实现
文章目录 一. 回顾栈和队列二. stack的模拟实现stack.hstack.cpp 三. queue的模拟实现queue.htest.cpp 四. 了解dequeuevector和list都有各自的缺陷deque 总结 一. 回顾栈和队列 回顾一下栈和队列 栈:stack:后进先出 _ 队列:queue…...
:从写作到个人IP的体系化构建(完结篇))
CSDN博客写作教学(五):从写作到个人IP的体系化构建(完结篇)
导语 (第一篇)Markdown编辑器基础 (第二篇)Markdown核心语法 (第三篇)文章结构化思维 (第四篇)标题优化与SEO实战 通过前四篇教程,你已掌握技术写作的“术”——排版、标题、流量与数据。但真正的价值在于将技能升维为“道”:用技术博客为支点,撬动个人品牌与职业发…...

Django 项目模块化开发指南:实现 Vue 风格的组件化
在 Django 项目中,我们经常需要 复用 HTML 代码,避免重复编写相同的模板。例如,博客系统中,博客列表页 和 文章详情页 可能都有相同的 导航栏、模态框、页脚 等。如何像 Vue 一样进行 模块化开发,让代码更加清晰、可维护呢? 本文将详细介绍 Django 的模板继承 和 {% incl…...

unity pico开发 四 物体交互 抓取 交互层级
文章目录 手部设置物体交互物体抓取添加抓取抓取三种类型抓取点偏移抓取事件抓取时不让物体吸附到手部 射线抓取交互层级 手部设置 为手部(LeftHandController)添加XRDirInteractor脚本 并添加一个球形碰撞盒,勾选isTrigger,调整大小为0.1 …...

opencv 模板匹配方法汇总
在OpenCV中,模板匹配是一种在较大图像中查找特定模板图像位置的技术。OpenCV提供了多种模板匹配方法,通过cv2.matchTemplate函数实现,该函数支持的匹配方式主要有以下6种,下面详细介绍每种方法的原理、特点和适用场景。 1. cv2.T…...

【PromptCoder + Cursor】利用AI智能编辑器快速实现设计稿
【PromptCoder Cursor】利用AI智能编辑器快速实现设计稿 官网:PromptCoder 在现代前端开发中,将设计稿转化为可运行的代码是一项耗时的工作。然而,借助人工智能工具,这一过程可以变得更加高效和简单。本文将介绍如何结合 Promp…...

MySQL面试01
MySQL 索引的最左原则 🍰 最左原则本质 ͟͟͞͞( •̀д•́) 想象复合索引是电话号码簿! 索引 (a,b,c) 的排列顺序: 先按a排序 → a相同按b排序 → 最后按c排序 生效场景三连: 1️⃣ WHERE a1 ✅ 2️⃣ WHERE a1 AND b2 ✅ 3️…...

webpack一篇
目录 一、构建工具 1.1简介 二、Webpack 2.1概念 2.2使用步骤 2.3配置文件(webpack.config.js) mode entry output loader plugin devtool 2.4开发服务器(webpack-dev-server) grunt/glup的对比 三、Vite 3.1概念 …...

健康饮食,健康早餐
营养早餐最好包含4大类食物:谷薯类;碳水;蛋白质;膳食纤维。 1.优质碳水 作用:提供持久的能量,避免血糖大幅波动等 例如:全麦面包、红薯🍠、玉米🌽、土豆🥔、…...

常见的排序算法 【复习笔记】
注意: 1. 后面的排序算法实现都只考虑升序,对于逆序,只有知道原理,实现很容易 2. 案例题: 题目描述:将读入的 N 个数从小到大输出 ( 1 < N <10e5) 输入描述:第一行一个正整数 N 第二行…...

【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决)
【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决) 前言一、问题分析二、解决方案 前言 我们在使用虚拟机过程中,经常会碰到即使删除了一些文件,但是存储空间还是越来越小的问题。今天我们来解决下这个问题。 一…...

Jenkins-自动化部署-通知
场景 使用jenkins部署,但有时不能立马部署,需要先通知相关人员,再部署,如果确实不能部署,可以留时间撤销。 方案 1.开始前我们添加,真正开始执行的等待时间;可供选择(Choice Param…...

Qt 文件操作+多线程+网络
文章目录 1. 文件操作1.1 API1.2 例子1,简单记事本1.3 例子2,输出文件的属性 2. Qt 多线程2.1 常用API2.2 例子1,自定义定时器 3. 线程安全3.1 互斥锁3.2 条件变量 4. 网络编程4.1 UDP Socket4.2 UDP Server4.3 UDP Client4.4 TCP Socket4.5 …...

《基于Hadoop的青岛市旅游景点游客行为分析系统设计与实现》开题报告
目录 一、选题依据 1.选题背景 2.国内外研究现状 (1)国内研究现状 (2)国外研究现状 3.发展趋势 4.应用价值 二、研究内容 1.学术构想与思路 2. 拟解决的关键问题 3. 拟采取的研究方法 4. 技术路线 (1)旅游前准备阶段 …...

pycharm debug卡住
pycharm debug时一直出现 collecting data, 然后点击下一行就卡住。 勾选 Gevent compatible解决 https://stackoverflow.com/questions/39371676/debugger-times-out-at-collecting-data...

MyBatis-Plus 元对象处理器 @TableField注解 反射动态赋值 实现字段自动填充
目录 🌰 举个直观例子 🛠️ 核心作用原理 📜 代码级工作流程 📜 完整代码 🔍 关键概念拆解 ⚠️ 常见问题排查 🌟 设计意义 🌰 举个直观例子 package work.dduo.ans.domain;import com.b…...

ISP 常见流程
1.sensor输出:一般为raw-OBpedestal。加pedestal避免减OB出现负值,同时保证信号超过ADC最小电压阈值,使信号落在ADC正常工作范围。 2. pedestal correction:移除sensor加的基底,确保后续处理信号起点正确。 3. Linea…...

Python Cookbook-2.27 从微软 Word 文档中抽取文本
任务 你想从 Windows 平台下某个目录树中的各个微软 Word 文件中抽取文本,并保存为对应的文本文件。 解决方案 借助 PyWin32 扩展,通过COM 机制,可以利用 Word 来完成转换: import fnmatch,os,sys,win32com.client wordapp w…...

java数据结构_Map和Set(一文理解哈希表)_9.3
目录 5. 哈希表 5.1 概念 5.2 冲突-概念 5.3 冲突-避免 5.4 冲突-避免-哈希函数的设计 5.5 冲突-避免-负载因子调节 5.6 冲突-解决 5.7 冲突-解决-闭散列 5.8 冲突-解决-开散列 / 哈希桶 5.9 冲突严重时的解决办法 5. 哈希表 5.1 概念 顺序结构以及平衡树中&#x…...

基于SpringBoot的“数据驱动的资产管理系统站”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“数据驱动的资产管理系统站”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 局部E-R图 系统登录界…...

excel 斜向拆分单元格
右键-合并单元格 右键-设置单元格格式-边框 在设置好分割线后,你可以开始输入文字。 需要注意的是,文字并不会自动分成上下两行。 为了达到你期望的效果,你可以通过 同过左对齐、上对齐 空格键或使用【AltEnter】组合键来调整单元格中内容的…...

深入理解推理语言模型(RLM)
大语言模型从通用走向推理,万字长文解析推理语言模型,建议收藏后食用。 本文基于苏黎世联邦理工学院的论文《Reasoning Language Models: A Blueprint》进行整理,你将会了解到: 1、RLM的演进与基础:RLM融合LLM的知识广…...

2025年具有百度特色的软件测试面试题
百度业务场景 如何测试一个高并发的搜索系统(如百度搜索)?如何测试一个在线地图服务(如百度地图)?如何测试一个大型推荐系统(如百度推荐)的性能?百度技术栈 你对百度的 PaddlePaddle 框架有了解吗?如何测试基于 PaddlePaddle 的服务?如何测试百度云的 API 服务?你对…...

HOW - 在Windows浏览器中模拟MacOS的滚动条
目录 一、原生 CSS 代码实现模拟 macOS 滚动条额外优化应用到某个特定容器 二、使用第三方工具/扩展 如果你想让 Windows 里的滚动条 模拟 macOS 的效果(细窄、圆角、隐藏默认轨道)。 可以使用以下几种方案: 一、原生 CSS 代码实现 模拟 m…...

Lua | 每日一练 (5)
💢欢迎来到张胤尘的技术站 💥技术如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 Lua | 每日一练 (5)题目参考答案浅拷贝深拷贝使用场景…...

C# Unity 唐老狮 No.5 模拟面试题
本文章不作任何商业用途 仅作学习与交流 安利唐老狮与其他老师合作的网站,内有大量免费资源和优质付费资源,我入门就是看唐老师的课程 打好坚实的基础非常非常重要: 全部 - 游习堂 - 唐老狮创立的游戏开发在线学习平台 - Powered By EduSoho 如果你发现了文章内特殊的字体格式,…...

云原生事件驱动架构:构建实时响应的数字化神经系统
引言:重塑企业实时决策能力 Uber实现事件驱动架构升级后,实时供需匹配延迟降至8ms,动态定价策略响应速度提升1200倍。Netflix通过事件流处理实现个性化推荐,用户点击率提高34%,事件处理吞吐量达2000万/秒。Confluent基…...