解锁高效编程:深度剖析C++11核心语法与标准库实战精要
目录
一、引言
二、核心语法革新
(一)类型推导系统
1. 统一初始化语法
2. initializer_list 机制
(三)函数增强
1. Lambda表达式
2. 可变参数模版
3. 数对象包装和参数绑定
(四)内存管理
1. 右值引用与移动语义
(五)语法糖优化
1. 范围for循环
2. 类型别名
三、标准库关键扩展
四、最佳实践建议
五、结语
一、引言
- 里程碑意义:首个重大现代版本
- 核心改进方向:语法简化/类型安全/表达力提升
- 典型应用场景:系统开发/高性能计算/跨平台项目
二、核心语法革新
(一)类型推导系统
auto x = 5; // 自动类型推导
decltype(x) y = 10; // 表达式类型捕获(二)初始化革命
1. 统一初始化语法
C++11之前存在多种初始化方式:
int a = 5; // 赋值初始化
int b(10); // 构造函数式初始化
int arr[] = {1,2,3}; // 列表初始化(仅部分场景可用)这种混乱容易引发歧义(如著名的"most vexing parse"问题)。
C++11引入大括号{}统一初始化规则:
int x{5}; // 基础类型
std::vector<int> vec{1,2,3}; // STL容器
Point p{10, 20}; // 自定义类关键特性:
a. 禁止隐式窄化转换
int y{5.0}; // 编译错误!double→int存在精度损失b. 避免歧义
class Timer {
public:Timer(int seconds); // 构造函数
};
Timer t1(10); // 正确
Timer t2{10}; // 正确
Timer t3(); // 被解析为函数声明!😱
Timer t4{}; // 明确调用默认构造函数✅2. initializer_list 机制
1. 编译器如何处理{ }
当使用{elem1, elem2...}时:编译器自动构造std::initializer_list<T>对象
优先匹配带有initializer_list参数的构造函数
示例分析:
std::vector<int> v1(5, 10); // 5个元素,每个都是10
std::vector<int> v2{5, 10}; // 两个元素:5和10v2的初始化过程:
编译器生成initializer_list<int>{5, 10}
调用vector::vector(initializer_list<int>)构造函数
#include <initializer_list>
#include <vector>class CustomVector {std::vector<int> data;
public:// 自定义initializer_list构造函数CustomVector(std::initializer_list<int> list) {for(auto& item : list) {data.push_back(item);}}
};void demo(std::initializer_list<std::string> args) {for(const auto& s : args) {// 处理参数...}
}int main() {// 标准库应用std::vector<int> v1{1,2,3,4}; // 4个元素std::vector<int> v2(4,2); // [2,2,2,2]// 自定义类型使用CustomVector cv{1,2,3,4,5};// 函数参数传递demo({"hello", "world", "!"});// 注意优先级问题std::vector<int> tricky{5, 2}; // 包含两个元素5和2,而不是5个2!
}(三)函数增强
1. Lambda表达式
C++11引入的lambda表达式为开发者提供了一种简洁优雅的匿名函数定义方式。相较于传统的函数对象(functor),lambda具有以下核心优势:
- 就地定义:无需单独定义函数或类
- 闭包特性:支持捕获上下文变量
- 语法简洁:减少样板代码量
[capture-list](params) mutable exception -> ret { body }a. 捕获列表(Capture List)
| 捕获方式 | 语法 | 效果 |
|---|---|---|
| 值捕获 | [x] | 创建变量副本 |
| 引用捕获 | [&x] | 绑定变量引用 |
| 隐式值捕获 | [=] | 捕获所有外部变量副本 |
| 隐式引用捕获 | [&] | 捕获所有外部变量引用 |
| 混合捕获 | [=, &x] | 默认值捕获,x单独引用捕获 |
int main() {int a = 1, b = 2;auto lambda = [a, &b](int x) mutable {a++; // 修改副本b++; // 修改原变量return a + b + x;};lambda(3); // a=2, b=3 → return 8
} b. 参数列表
与传统函数参数完全一致,支持:
- 值传递、引用传递
- 默认参数
- 可变参数模板(C++14起)
c. mutable修饰符
允许修改值捕获的变量副本:
int x = 10;
auto l = [x]() mutable { x++; }; // 合法
auto m = [x]() { x++; }; // 编译错误 d. 返回类型推导
当函数体仅包含单个return语句时,编译器可自动推导返回类型。复杂逻辑需显式指定:
auto l1 = [](int x) { return x * 1.5; }; // 推导为double
auto l2 = [](int x) -> float { return x*1.5; }; // 显式指定典型应用场景
std::vector<int> nums {5,3,8,1};
std::sort(nums.begin(), nums.end(), [](int a, int b) { return a > b; }); // 降序排列2. 可变参数模版
想象你要写一个打印函数,可以接受任意数量任意类型的参数。在C++11之前,你只能用:
- 函数重载(只能支持有限参数)
- va_list(类型不安全)
而可变参数模板可以:
- 支持任意数量参数
- 保持类型安全
- 在编译期完成类型检查
| 场景 | 语法 | 示例 |
|---|---|---|
| 声明模板参数包 | typename... Args | template<typename... Args> |
| 声明函数参数包 | Args... args | void func(Args... args) |
| 展开参数包 | args... | func(args...) |
| 包扩展 | 模式... | std::tuple<Args...> |
| 右折叠表达式 | (args op ...) | (args + ...) |
| 左折叠表达式 | (... op args) | (... + args) |
1. 模板参数包声明
template<typename... Args> // Args是模板参数包
void func(Args... args) { // args是函数参数包// 操作参数包
}2. 参数包大小获取
sizeof...(Args) // 获取类型参数数量
sizeof...(args) // 获取函数参数数量2.1参数包扩展
参数包扩展的本质是编译器在编译期将参数包展开为一连串具体元素。这个过程类似于把压缩文件解压为具体文件列表,但发生在编译阶段。
核心语法:
pattern... → 元素1, 元素2, ..., 元素N展开的四种基本形态
1. 直接展开(裸展开)
template<typename... Ts>
void func(Ts... args) {other_func(args...); // 直接展开为arg1, arg2, ..., argN
}类比:把一盒饼干直接倒出来
2. 带修饰展开
template<typename... Ts>
void func(Ts... args) {other_func((args + 1)...); // 每个参数+1
} 调用func(1,2,3)展开为:other_func(2,3,4)
3. 类型+值组合展开
template<typename... Ts>
void create_objects() {std::tuple<Ts...> objects; // 展开类型std::tuple<Ts*...> pointers; // 每个类型指针
} create_objects<int, string>()生成:
std::tuple<int, string> objects;
std::tuple<int*, string*> pointers;4. 多重包同步展开
template<typename... Ts, typename... Us>
void zip(Ts... ts, Us... us) {std::tuple<std::pair<Ts,Us>...> pairs; // 同步展开两个包
} zip<int,double>(1, 3.14, "a", "b")生成:
std::tuple<std::pair<int,char[2]>, std::pair<double,char[2]>> pairs;6大展开位置深度解析
根据C++标准,参数包只能在以下位置展开:
1. 函数参数列表
template<typename... Ts>
void forward(Ts... args) {target(args...); // ✅ 正确展开
}2. 初始化列表
template<typename... Ts>
std::vector<int> make_vec(Ts... args) {return {args...}; // 生成初始化列表
}3. 基类列表
template<typename... Bases>
class Derived : public Bases... { // 展开为多个基类// ...
};4. 模板参数列表
template<typename... Ts>
struct Tuple {std::tuple<std::shared_ptr<Ts>...> ptrs; // 生成shared_ptr类型列表
};5. 属性列表(C++11起)
template<typename... Validators>
[[ Validators::check... ]] // 展开多个属性
void validate() {// ...
}高级展开技巧
1. 索引技巧(index_sequence)
template<typename Tuple, size_t... Is>
void print_tuple_impl(const Tuple& t, std::index_sequence<Is...>) {( (std::cout << std::get<Is>(t) << " "), ... );
}template<typename... Ts>
void print_tuple(const std::tuple<Ts...>& t) {print_tuple_impl(t, std::index_sequence_for<Ts...>{});
}2. 条件展开
template<typename T>
void process() { /* 默认处理 */ }template<>
void process<int>() { /* 特殊处理int */ }template<typename... Ts>
void run_all() {(process<Ts>(), ...); // 展开执行所有类型的process
}3. 多模式组合展开
template<typename... Ts>
auto make_shared_tuple() {return std::tuple<std::shared_ptr<Ts>...>(std::make_shared<Ts>()...);
}
// 同时展开类型参数和值参数典型错误分析
// 错误示例1:非法的展开位置
template<typename... Ts>
void error() {int arr[] = { Ts... }; // ❌ 类型不能直接初始化int数组
}// 错误示例2:参数包不匹配
template<typename T, typename... Ts>
void print(T first, Ts... rest) {std::cout << first;print(rest...); // ❌ 当rest为空时找不到匹配函数
}
// 需要添加终止函数
void print() {} // ✅ 终止条件 将参数包、右值引用和emplace_back结合使用时,可以实现高效的对象构造和参数转发。
#include <iostream>
#include <vector>
#include <string>class Person {
public:// 构造函数接受任意参数包template<typename... Args>Person(Args&&... args) : name(std::forward<Args>(args)...) {}void print() const {std::cout << name << std::endl;}private:std::string name;
};int main() {std::vector<Person> people;// 直接传递参数包构造Person对象people.emplace_back(3, 'A'); // 构造 std::string(3, 'A')people.emplace_back("Alice"); // 构造 std::string("Alice")people.emplace_back(std::string("Bob"));// 移动构造for (const auto& p : people) {p.print();}return 0;
}关键机制分析
1. 参数包与完美转发
- 模板参数包
Args&&...
在Person的构造函数中,Args&&...是通用引用(Universal Reference),可以接受任意类型的左值或右值参数包。 std::forward<Args>(args)...
将参数包完美转发到std::string的构造函数,保留参数的左值/右值属性。例如:3, 'A→ 右值 → 调用std::string(size_t, char)。"Alice"→ 左值(const char*)→ 调用std::string(const char*)。std::string("Bob")→ 右值 → 调用移动构造函数。
2. emplace_back 的工作流程
当调用 people.emplace_back(...) 时:
- 参数包解包
将参数直接传递给Person的构造函数,无需创建临时对象。 - 直接构造对象
在vector的内存空间中直接构造Person对象,避免拷贝或移动操作。
3. 代码执行步骤
people.emplace_back(3, 'A'):- 参数包
Args→int, char - 构造
std::string(3, 'A')→Person对象直接在vector中创建。
- 参数包
people.emplace_back("Alice"):- 参数包
Args→const char* - 构造
std::string("Alice")。
- 参数包
people.emplace_back(std::string("Bob")):- 参数包
Args→std::string&& - 移动构造
std::string,避免拷贝
- 参数包
性能优势
- 零拷贝:直接在容器内存中构造对象。
- 完美转发:根据参数类型选择最优构造函数(左值调用拷贝,右值调用移动)。
- 灵活性:支持任意数量和类型的参数。
错误用法示例
// 错误:未使用完美转发,导致不必要的拷贝
template<typename... Args>
Person(Args... args) : name(args...) {} // args 作为拷贝传递// 错误:未使用 emplace_back,先构造临时对象再移动
people.push_back(Person("Charlie")); // 需要一次移动构造3. 数对象包装和参数绑定
std::function 是一个模板类,用于包装任意可调用对象(如普通函数、成员函数、Lambda 表达式、函数对象等),提供统一的调用接口。
用法示例:
#include <functional>
#include <iostream>int add(int a, int b) { return a + b; }int main() {// 包装普通函数std::function<int(int, int)> func = add;std::cout << func(2, 3) << std::endl; // 输出 5// 包装 Lambda 表达式func = [](int a, int b) { return a * b; };std::cout << func(2, 3) << std::endl; // 输出 6
}std::bind:参数绑定器
std::bind 用于将可调用对象与其参数绑定,生成一个新的可调用对象。支持参数绑定、占位符(_1, _2)和参数顺序调整。
#include <functional>
#include <iostream>void print(int a, int b, int c) {std::cout << a << ", " << b << ", " << c << std::endl;
}class MyClass {
public:void memberFunc(int x) { std::cout << "Value: " << x << std::endl; }
};int main() {using namespace std::placeholders; // 引入占位符 _1, _2, ...// 绑定普通函数参数auto bound1 = std::bind(print, 10, _1, _2);bound1(20, 30); // 输出 10, 20, 30// 调整参数顺序auto bound2 = std::bind(print, _3, _2, _1);bound2(1, 2, 3); // 输出 3, 2, 1// 绑定成员函数MyClass obj;auto bound3 = std::bind(&MyClass::memberFunc, &obj, _1);bound3(42); // 输出 Value: 42
}结合使用 std::function 和 std::bind
#include <functional>
#include <iostream>int multiply(int a, int b) { return a * b; }int main() {using namespace std::placeholders;// 绑定 multiply 的第一个参数为 5auto bound = std::bind(multiply, 5, _1);std::function<int(int)> func = bound;std::cout << func(4) << std::endl; // 输出 20 (5 * 4)
}关键特性
- 占位符:
_1,_2等表示调用时传入的第 1、2 个参数。 - 绑定成员函数:需传递对象指针或引用作为第一个参数。
- 类型擦除:
std::function可以存储任意可调用对象,但可能有轻微性能开销。 - 兼容性:支持与 Lambda 表达式、函数对象等结合使用。
应用场景
- 实现回调机制。
- 延迟函数调用(如事件处理)。
- 简化参数传递(固定部分参数)。
通过 std::function 和 std::bind,C++11 显著提升了函数式编程的灵活性和代码可维护性。
(四)内存管理
左值(lvalue)和右值(rvalue)是C++中表达式的分类方式,C++11进一步细化了右值并引入右值引用和移动语义,以提高代码效率。等号左边是左值,右边是右值。
左值(lvalue)
定义:具有明确内存地址、可被取地址的表达式。
特点:
- 可出现在赋值运算符的左侧或右侧。
- 生命周期通常超出当前表达式。
- 可重复使用。
示例:
int a = 10; // a是左值
int* p = &a; // 可取地址
int& func(); // 返回左值引用的函数调用是左值
++a; // 前置自增结果是左值右值(rvalue)
定义:临时值,不能被取地址,通常用于赋值运算符的右侧。
分类(C++11引入):
- 纯右值(prvalue):传统右值,如字面量、算术表达式结果。
- 将亡值(xvalue):与资源移动相关的右值,如std::move的结果。
特点:
- 通常为临时对象,生命周期限于当前表达式。
- 不可被重复使用。
示例:
int b = 5 + 3; // 5+3是纯右值
std::string s = "hello"; // "hello"是纯右值
int&& func_rval(); // 返回右值引用的函数调用是将亡值关键规则
右值引用本身是左值:
若右值引用有名称(如函数参数),则视为左值,需用std::move再次转换为右值。
1. 右值引用与移动语义
右值引用(&&)就像一张"资源转移许可证",允许我们安全地操作即将销毁的临时对象:
// 普通引用(左值引用)
int a = 10;
int& lref = a; // ✅ 合法绑定左值
// int& e = 10; // ❌ 不能绑定右值// 右值引用
int&& rref1 = 10; // ✅ 直接绑定字面量
int&& rref2 = a + 5; // ✅ 绑定临时计算结果
// int&& rref3 = a; // ❌ 不能直接绑定左值右值引用变量本身存储的是临时对象的引用信息(可理解为编译器自动管理的地址信息),而真正需要转移的资源(如指针指向的堆内存、文件句柄等)仍然存在于被引用的对象内部。移动语义的本质是通过右值引用获取临时对象的访问权,进而转移其内部资源。
为什么需要右值引用?
传统C++在处理对象传递时,会产生不必要的拷贝:
class BigData {
public:BigData() { /* 分配大量内存 */ }~BigData() { /* 释放内存 */ }// 拷贝构造函数BigData(const BigData& other) {/* 深拷贝内存数据(耗时操作) */}
};void process(BigData data) {// 处理数据
}int main() {BigData data;process(data); // 触发拷贝构造return 0;
}解决方案:移动语义的引入
1. 移动构造函数
class BigData {
public:// 移动构造函数BigData(BigData&& other) noexcept {// 直接接管other的资源ptr_ = other.ptr_;other.ptr_ = nullptr; // 置空原对象指针}
};总结:
右值引用通过以下方式提升程序性能:
- ✅ 减少不必要的拷贝操作
- ✅ 实现资源的高效转移
- ✅ 支持完美转发机制
掌握右值引用后,可以更高效地使用标准库容器、智能指针等现代C++特性。
右值引用的折叠是 C++11 引入的类型推导规则,用于处理引用的引用场景。其核心目的是支持模板编程中的完美转发和移动语义。以下是关键理解点:
1. 基本规则
引用折叠遵循以下原则:
T& &→T&T& &&→T&T&& &→T&T&& &&→T&&
简化为:只有两个 && 叠加时才会保留右值引用,其他情况均折叠为左值引用。
引用折叠主要出现在以下三种场景中:
1. 模板类型推导
当模板参数为 T&&(通用引用)时,传入左值会推导 T 为左值引用类型,触发折叠:
template<typename T>
void func(T&& arg) {// 若传递左值,T 推导为 T& → T&& & → 折叠为 T&
}2. 类型别名(typedef/using)
using LRef = int&;
using RRef = int&&;LRef&& l = ...; // 折叠为 int&
RRef& r = ...; // 折叠为 int&3. auto 类型推导
int x = 10;
auto&& a = x; // auto → int& → int& && → 折叠为 int&
auto&& b = 42; // auto → int → int&& 引用折叠是 std::forward 实现完美转发的核心:
template<typename T>
T&& forward(typename std::remove_reference<T>::type& arg) {return static_cast<T&&>(arg); // 根据 T 类型折叠为左值或右值引用
}- 若
T是左值引用(如int&),则T&&→int& &&→ 折叠为int&。 - 若
T是右值引用(如int&&),则T&&→int&& &&→ 折叠为int&&。
(五)语法糖优化
1. 范围for循环
特性概述
C++11引入的range-based for循环通过自动迭代器处理机制,为容器遍历提供了简洁明了的语法形式。其基本语法结构为:
for (declaration : expression)statement核心优势
- 代码精简:减少传统迭代器或下标操作的模板代码
- 安全增强:自动处理迭代边界,避免越界访问
- 类型推导:支持auto关键字自动推导元素类型
- 通用适配:支持所有提供begin()/end()方法的容器
应用场景
// 传统遍历方式
std::vector<int> vec{1,2,3};
for(auto it=vec.begin(); it!=vec.end(); ++it) {std::cout << *it << " ";
}// C++11范围for循环
for(const auto& num : vec) {std::cout << num << " ";
}// 支持引用修改元素
for(auto& num : vec) {num *= 2;
}2. 类型别名
特性演进
C++11通过using关键字提供了更直观的类型别名定义方式:
// 传统typedef语法
typedef std::map<std::string, std::vector<int>> MyOldType;// C++11 using语法
using MyNewType = std::map<std::string, std::vector<int>>;核心优势
- 可读性提升:符合赋值语句的阅读习惯
- 模板支持:支持模板别名定义(typedef无法实现)
- 复杂类型简化:特别适用于函数指针等复杂类型
典型应用
// 函数指针类型别名
using Handler = void (*)(int, const std::string&);// 模板别名
template<typename T>
using Matrix3D = std::vector<std::vector<std::vector<T>>>;// 使用示例
Matrix3D<float> tensor(5, std::vector<std::vector<float>>(4, std::vector<float>(3)));三、标准库关键扩展
(一)容器增强
-
std::array
- 固定大小数组容器,替代传统C数组
- 提供STL容器接口(如size()、迭代器)
- 栈上分配内存,无动态内存开销
-
std::forward_list
- 单向链表实现
- 比std::list节省33%内存(无反向指针)
- 仅支持前向迭代
-
无序容器
- unordered_set/unordered_multiset
- unordered_map/unordered_multimap
- 基于哈希表实现,平均O(1)复杂度
-
emplace系列方法
- 支持直接构造(emplace_back/emplace)
- 避免临时对象拷贝
- 完美转发参数到构造函数
(二)智能指针
-
std::unique_ptr
- 独占所有权的智能指针
- 支持自定义删除器
- 禁止拷贝,允许移动语义
- 替代有缺陷的auto_ptr
-
std::shared_ptr
- 共享所有权的引用计数指针
- 线程安全的引用计数操作
- 支持weak_ptr打破循环引用
- 自定义删除器保持类型擦除
-
std::weak_ptr
- 不增加引用计数的观察指针
- 解决shared_ptr循环引用问题
- 必须通过lock()获取临时shared_ptr
-
创建函数
- make_shared<T>():高效创建shared_ptr
- (C++14补充make_unique<T>())
- 减少内存分配次数(合并控制块和对象存储)
四、最佳实践建议
- 优先使用{}初始化
- 合理搭配auto与显式类型
- 移动语义使用场景
五、结语
- 版本演进路线:C++14/17/20的延续
- 学习路径推荐:cppreference.com +《Effective Modern C++》
相关文章:

解锁高效编程:深度剖析C++11核心语法与标准库实战精要
目录 一、引言 二、核心语法革新 (一)类型推导系统 1. 统一初始化语法 2. initializer_list 机制 (三)函数增强 1. Lambda表达式 2. 可变参数模版 3. 数对象包装和参数绑定 (四)内存管理 1. 右值引用与…...

基于提示驱动的潜在领域泛化的医学图像分类方法(Python实现代码和数据分析)
摘要 医学图像分析中的深度学习模型易受数据集伪影偏差、相机差异、成像设备差异等导致的分布偏移影响,导致在真实临床环境中诊断不可靠。领域泛化(Domain Generalization, DG)方法旨在通过多领域训练提升模型在未知领域的性能,但…...

深度学习-大白话解释循环神经网络RNN
目录 一、RNN的思想 二、RNN的基本结构 网络架构 关键点 三、RNN的前向传播 四、RNN的挑战:梯度爆炸和梯度消失 问题分析 示例推导 五、LSTM:RNN的改进 核心组件 网络架构 3. LSTM 的工作流程 4. 数学公式总结 5. LSTM 的优缺点 优点 缺点 6. LSTM 的…...
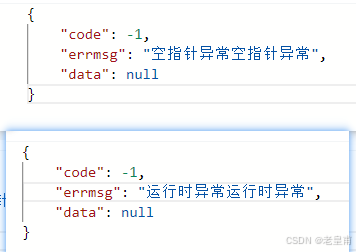
Spring统一格式返回
目录 一:统一结果返回 1:统一结果返回写法 2:String类型报错问题 解决方法 二:统一异常返回 统一异常返回写法 三:总结 同志们,今天咱来讲一讲统一格式返回啊,也是好久没有讲过统一格式返…...

IPOIB 驱动中的发送完成处理机制
1. ipoib_napi_add_rss 函数 ipoib_napi_add_rss 函数的主要作用是为 InfiniBand 设备的每个接收队列和发送队列添加 NAPI 结构,并注册相应的轮询函数。NAPI(New API)是一种网络接口卡(NIC)的轮询机制,用于高效处理网络数据包,避免频繁的中断处理开销。 static void i…...

BambuStudio学习笔记:format格式化输出
# Slic3r::format 字符串格式化工具说明## 概述本头文件提供了基于 boost::format 的 C 字符串格式化工具封装,旨在简化多参数格式化操作,支持类似 C20 std::format 的调用语法。## 核心设计目标- **简化调用语法**:替代 boost::format 的链式…...
软件测试基础:功能测试知识总结
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 一、测试项目启动与研读需求文档 (一) 组建测试团队 1、测试团队中的角色 2、测试团队的基本责任 尽早地发现软件程序、系统或产品中…...

wheel_legged_genesis 开源项目复现与问题记录
Reinforcement learning of wheel-legged robots based on Genesis System Requirements Ubuntu 20.04/22.04/24.04 python > 3.10 开始配置环境! 点击releases后进入,下载对应最新版本的代码: 将下载后的代码包解压到你的自定义路径下&…...

【金融量化】Ptrade中如何量化策略的交易持久化?
交易持久化是指在实际交易中交易相关的数据(如订单信息、持仓状态、策略参数等)保存到本地或远程存储中,以便在程序重启、系统崩溃或网络中断后能够恢复交易状态,确保策略的连续性和稳定性。以下是如何在策略中实现交易持久化的方…...

qt实践教学(编写一个代码生成工具)持续更新至完成———
前言: 我的想法是搭建一个和STM32cubemux类似的图形化代码生成工具,可以把我平时用到的代码整合一下全部放入这个软件中,做一个我自己专门的代码生成工具,我初步的想法是在下拉选框中拉取需要配置的功能,然后就弹出对…...

设置 CursorRules 规则
为什么要设置CursorRules? 设置 CursorRules 可以帮助优化代码生成和开发流程,提升工作效率。具体的好处包括: 1、自动化代码生成 :通过定义规则,Cursor 可以根据你的开发需求自动生成符合规定的代码模板,…...

AI 芯片全解析:定义、市场趋势与主流芯片对比
1. 引言:什么是 AI 芯片? 随着人工智能(AI)的快速发展,AI 计算的需求不断增长,从云计算到边缘计算,AI 芯片成为推动智能化时代的核心动力。那么,什么样的芯片才算 AI 芯片ÿ…...

Axure高保真Element框架元件库
点击下载《Axure高保真Element框架元件库》 原型效果:https://axhub.im/ax9/9da2109b9c68749a/#g1 摘要 本文详细阐述了在 Axure 环境下打造的一套高度还原 Element 框架的组件元件集。通过对 Element 框架组件的深入剖析,结合 Axure 的强大功能&#…...

21.<基于Spring图书管理系统②(图书列表+删除图书+更改图书)(非强制登录版本完结)>
PS: 开闭原则 定义和背景 开闭原则(Open-Closed Principle, OCP),也称为开放封闭原则,是面向对象设计中的一个基本原则。该原则强调软件中的模块、类或函数应该对扩展开放,对修改封闭。这意味着一个软件实体…...

【2025年后端开发终极指南:云原生、AI融合与性能优化实战】
一、2025年后端开发的五大核心趋势 1. 云原生架构的全面普及 云原生(Cloud Native)已经成为企业级应用的核心底座。通过容器化技术(DockerKubernetes)和微服务架构,开发者能够实现应用的快速部署、弹性伸缩和故障自愈…...
)
Docker新手入门(持续更新中)
一、定义 快速构建、运行、管理应用的工具。 Docker可以帮助我们下载应用镜像,创建并运行镜像的容器,从而快速部署应用。 所谓镜像,就是将应用所需的函数库、依赖、配置等应用一起打包得到的。 所谓容器,为每个镜像的应用进程创建…...

微信小程序读取写入NFC文本,以及NFC直接启动小程序指定页面
一、微信小程序读取NFC文本(yyy优译小程序实现),网上有很多通过wx.getNFCAdapter方法来监听读取NFC卡信息,但怎么处理读取的message文本比较难找,现用下面方法来实现,同时还解决几个问题,1、在回调方法中this.setData不更新信息,因为this的指向问题,2、在退出页面时,…...

【Spring Boot 应用开发】-05 命令行参数
Spring Boot 常用命令行参数 Spring Boot 支持多种命令行参数,这些参数可以在启动应用时通过命令行直接传递。以下是一些常用的命令行参数及其详细说明: 1. 基本配置参数 --server.port端口号 指定应用程序运行的HTTP端口,默认为8080。 jav…...
DeepSeek提示词)
选择研究方向(28条)DeepSeek提示词
选择研究方向(28条) 在学术研究的旅程中,确定研究方向和主题是至关重要的第一步。一个明确且具有创新性的研究主题不仅能够为研究提供清晰的方向,还能激发研究者的热情和动力。以下是一些优化后的提示词,目的在于帮助…...

Linux中读写锁详细介绍
读写锁介绍 Linux 中的读写锁(Read-Write Lock)是一种用于线程同步的机制,它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种机制在读操作远多于写操作的场景下,可以显著提高并发性能。读写锁主要有…...

flink分布式事务 - 两阶段提交
分布式事务与两阶段提交协议详解 分布式事务是分布式系统中保证数据一致性和可靠性的核心技术之一。在大数据处理、微服务架构以及实时流处理等领域,分布式事务的应用场景越来越广泛。两阶段提交协议(Two-Phase Commit, 2PC)作为一种经典的分布式事务管理协议,在保证强一致…...

《DataWorks:为人工智能算法筑牢高质量数据根基》
在当今数字化时代,人工智能(AI)技术的迅猛发展深刻地改变着各个行业的面貌。从智能推荐系统到医疗影像诊断,从自动驾驶到自然语言处理,AI正以前所未有的速度渗透到我们生活和工作的方方面面。而在这一系列AI应用的背后…...

机器学习(五)
一,多类(Multiclass) 多类是指输出不止有两个输出标签,想要对多个种类进行分类。 Softmax回归算法: Softmax回归算法是Logistic回归在多类问题上的推广,和线性回归一样,将输入的特征与权重进行…...

DeepSeek搭配Excel,制作自定义按钮,实现办公自动化!
今天跟大家分享下我们如何将DeepSeek生成的VBA代码,做成按钮,将其永久保存在我们的Excel表格中,下次遇到类似的问题,直接在Excel中点击按钮,就能10秒搞定,操作也非常的简单. 一、代码准备 代码可以直接询问…...

利用Git和wget批量下载网页数据
一、Git的下载(参考文章) 二. wget下载(网上很多链接) 三、git和wget结合使用 1.先建立一个文本,将代码写入文本(代码如下),将txt后缀改为sh(download_ssebop.sh…...

人工智能之数学基础:线性代数中的行列式的介绍
本文重点 行列式是一种重要的数学工具,更是连接众多数学概念和实际应用的桥梁。本文将介绍矩阵的行列式,你可以把它看成对方阵的一种运算,将方阵映射成一个标量。 行列式的定义 行列式是一个由数值组成的方阵所确定的一个标量值。对于一个n*n的矩阵A=(aij),其行列式记为d…...

[自然语言处理]pytorch概述--什么是张量(Tensor)和基本操作
pytorch概述 PyTorch 是⼀个开源的深度学习框架,由 Facebook 的⼈⼯智能研究团队开发和维护,于2017年在GitHub上开源,在学术界和⼯业界都得到了⼴泛应⽤ pytorch能做什么 GPU加速自动求导常用网络层 pytorch基础 量的概念 标量…...

[杂学笔记]HTTP1.0和HTTP1.1区别、socket系列接口与TCP协议、传输长数据的时候考虑网络问题、慢查询如何优化、C++的垃圾回收机制
目录 1.HTTP1.0和HTTP1.1区别 2.socket系列接口与TCP协议 3.传输长数据的时候考虑网络问题 4.慢查询如何优化 5.C的垃圾回收机制 1.HTTP1.0和HTTP1.1区别 在连接方式上,HTTP1.0默认采用的是短链接的方式,就建立一次通信,也就是说即使在…...

电商主图3秒法则
1. 基础铁律 ▸ 首图点击率曝光量/点击量 ▸ 黄金3秒:触发冲动 > 信息堆砌 2. 必守三原则 ✔ 单点爆破 → 1核心功能 > 10卖点叠加(反例:电子类目点击率↓18%) ✔ 场景植入 → 带场景主图点击率↑34%(数据源:20…...

DeepSeek DeepEP学习(一)low latency dispatch
背景 为了优化延迟,low lantency使用卡间直接收发cast成fp8的数据的方式,而不是使用normal算子的第一步执行机间同号卡网络发送,再通过nvlink进行转发的两阶段方式。进一步地,normal算子的dispatch包含了notify_dispatch传输meta…...