使用easyocr、PyPDF2对图像及PDF文档进行识别
一、概述
本 Python 脚本的主要功能是对当前目录及其子目录下的图片和 PDF 文件进行光学字符识别(OCR)处理。它使用 easyocr 库处理图片中的文字,使用 PyPDF2 库提取 PDF 文件中的文本,并将处理结果保存为文本文件。同时,脚本会记录详细的处理日志,方便用户跟踪处理过程和排查问题。
二、环境要求
- Python 版本:建议使用 Python 3.6 及以上版本。
- 依赖库:
easyocr:用于图片的 OCR 识别。PyPDF2:用于读取 PDF 文件并提取文本。Pillow(PIL):虽然脚本中未直接使用,但easyocr处理图像时可能依赖。
你可以使用以下命令安装这些依赖库:
收起
bash
pip install easyocr PyPDF2 Pillow
三、脚本结构与功能模块
1. 导入必要的库
收起
python
import os
import time
import easyocr
from PyPDF2 import PdfReader
from PIL import Image
导入了处理文件系统、时间、OCR 识别、PDF 读取和图像处理所需的库。
2. 设置模型下载路径
收起
python
model_storage_directory = './easyocr_models'
os.makedirs(model_storage_directory, exist_ok=True)
定义了 easyocr 模型的存储目录,并确保该目录存在。
3. 检查网络连接
收起
python
def check_network():try:import urllib.requesturllib.request.urlopen('https://www.baidu.com', timeout=5)return Trueexcept:return False
该函数尝试访问百度网站,以检查网络连接是否正常。如果能成功访问,则返回 True,否则返回 False。
4. 初始化 EasyOCR reader
收起
python
try:print("Initializing EasyOCR...")print(f"Model storage directory: {os.path.abspath(model_storage_directory)}")if not check_network():print("Network connection failed. Please check your internet connection.")exit(1)print("Downloading models (this may take several minutes)...")reader = easyocr.Reader(['ch_sim', 'en'],model_storage_directory=model_storage_directory,download_enabled=True,verbose=True)print("EasyOCR initialized successfully")
except Exception as e:print(f"Failed to initialize EasyOCR: {str(e)}")exit(1)
- 打印初始化信息和模型存储目录的绝对路径。
- 检查网络连接,若网络异常则输出错误信息并退出程序。
- 下载
easyocr所需的模型,支持中文(简体)和英文识别。 - 若初始化成功,打印成功信息;若出现异常,打印错误信息并退出程序。
5. 处理图片文件
收起
python
def process_image(image_path):"""处理图片文件"""try:result = reader.readtext(image_path)text = '\n'.join([item[1] for item in result])return textexcept Exception as e:print(f"Error processing image {image_path}: {str(e)}")return ""
- 接受图片文件路径作为参数。
- 使用
easyocr对图片进行 OCR 识别,提取识别结果中的文本并拼接成字符串返回。 - 若处理过程中出现异常,打印错误信息并返回空字符串。
6. 处理 PDF 文件
收起
python
def process_pdf(pdf_path):"""处理PDF文件"""try:text = ""reader = PdfReader(pdf_path)for page in reader.pages:text += page.extract_text()return textexcept Exception as e:print(f"Error processing PDF {pdf_path}: {str(e)}")return ""
- 接受 PDF 文件路径作为参数。
- 使用
PyPDF2读取 PDF 文件的每一页,并提取文本拼接成字符串返回。 - 若处理过程中出现异常,打印错误信息并返回空字符串。
7. 保存提取的文本
收起
python
def save_text(text, output_path):"""保存提取的文本"""with open(output_path, 'w', encoding='utf-8') as f:f.write(text)
- 接受文本内容和输出文件路径作为参数。
- 将文本内容以 UTF-8 编码写入指定的输出文件。
8. 主函数 main
收起
python
def main():# 尝试多个可能的输出目录位置output_folders = ['./output_text', # 当前目录os.path.expanduser('~/ocr_output'), # 用户主目录os.path.join(os.getcwd(), 'ocr_output') # 当前工作目录]output_folder = Nonefor folder in output_folders:try:os.makedirs(folder, exist_ok=True)output_folder = folderprint(f"Using output directory: {os.path.abspath(output_folder)}")breakexcept Exception as e:print(f"Failed to create output directory {folder}: {str(e)}")if output_folder is None:print("Error: Could not create any output directory")exit(1)# 初始化日志log_file = os.path.join(output_folder, 'ocr_log.txt')# 重定向标准输出到日志文件import sysclass Logger(object):def __init__(self, filename):self.terminal = sys.stdoutself.log = open(filename, "a", encoding='utf-8')def write(self, message):self.terminal.write(message)self.log.write(message)def flush(self):passsys.stdout = Logger(log_file)print("OCR Processing Log\n")print(f"Starting OCR processing at {time.strftime('%Y-%m-%d %H:%M:%S')}")# 支持的图片格式image_extensions = ['.bmp', '.jpg', '.jpeg', '.png', '.tiff', '.gif']# 遍历当前目录及子目录for root, dirs, files in os.walk('.'):for file in files:file_path = os.path.join(root, file)base_name, ext = os.path.splitext(file)try:# 处理图片文件if ext.lower() in image_extensions:print(f"Processing image: {file_path}")text = process_image(file_path)output_path = os.path.join(output_folder, f"{base_name}.txt")save_text(text, output_path)print(f"Successfully processed image: {file_path} -> {output_path}")with open(log_file, 'a') as f:f.write(f"Success: {file_path} -> {output_path}\n")# 处理PDF文件elif ext.lower() == '.pdf':print(f"Processing PDF: {file_path}")text = process_pdf(file_path)output_path = os.path.join(output_folder, f"{base_name}.txt")save_text(text, output_path)print(f"Successfully processed PDF: {file_path} -> {output_path}")with open(log_file, 'a') as f:f.write(f"Success: {file_path} -> {output_path}\n")except Exception as e:error_msg = f"Error processing {file_path}: {str(e)}"print(error_msg)with open(log_file, 'a') as f:f.write(error_msg + "\n")
- 输出目录处理:尝试在多个预设位置创建输出目录,若创建成功则使用该目录,若所有尝试均失败则输出错误信息并退出程序。
- 日志初始化:在输出目录下创建
ocr_log.txt日志文件,将标准输出重定向到该日志文件,同时保留在终端的输出。记录日志头部信息和处理开始时间。 - 文件遍历与处理:遍历当前目录及其子目录下的所有文件,对图片文件调用
process_image函数处理,对 PDF 文件调用process_pdf函数处理。将处理结果保存为文本文件,并在日志中记录成功或失败信息。
9. 程序入口
收起
python
if __name__ == "__main__":main()
当脚本作为主程序运行时,调用 main 函数开始执行。
四、使用方法
- 将脚本保存为一个 Python 文件(例如
ocr_process.py)。 - 确保所需的依赖库已安装。
- 打开终端或命令提示符,进入脚本所在的目录。
- 运行脚本:
收起
bash
python ocr_process.py
- 脚本会自动处理当前目录及其子目录下的图片和 PDF 文件,并将处理结果保存到指定的输出目录中,同时生成处理日志。
五、注意事项
- 由于
easyocr模型下载可能需要一定时间,首次运行脚本时请确保网络连接稳定,耐心等待模型下载完成。 - 对于 PDF 文件,
PyPDF2只能提取文本内容,若 PDF 为扫描版或加密文件,可能无法正常提取文本。 - 若处理过程中出现错误,请查看日志文件
ocr_log.txt以获取详细的错误信息。
完成代码
import os
import time
import easyocr
from PyPDF2 import PdfReader
from PIL import Image# 设置模型下载路径
model_storage_directory = './easyocr_models'
os.makedirs(model_storage_directory, exist_ok=True)# 检查网络连接
def check_network():try:import urllib.requesturllib.request.urlopen('https://www.baidu.com', timeout=5)return Trueexcept:return False# 初始化EasyOCR reader
try:print("Initializing EasyOCR...")print(f"Model storage directory: {os.path.abspath(model_storage_directory)}")if not check_network():print("Network connection failed. Please check your internet connection.")exit(1)print("Downloading models (this may take several minutes)...")reader = easyocr.Reader(['ch_sim', 'en'],model_storage_directory=model_storage_directory,download_enabled=True,verbose=True)print("EasyOCR initialized successfully")
except Exception as e:print(f"Failed to initialize EasyOCR: {str(e)}")exit(1)def process_image(image_path):"""处理图片文件"""try:# 使用EasyOCR提取文本result = reader.readtext(image_path)# 合并所有识别结果text = '\n'.join([item[1] for item in result])return textexcept Exception as e:print(f"Error processing image {image_path}: {str(e)}")return ""def process_pdf(pdf_path):"""处理PDF文件"""try:text = ""reader = PdfReader(pdf_path)for page in reader.pages:text += page.extract_text()return textexcept Exception as e:print(f"Error processing PDF {pdf_path}: {str(e)}")return ""def save_text(text, output_path):"""保存提取的文本"""with open(output_path, 'w', encoding='utf-8') as f:f.write(text)def main():# 尝试多个可能的输出目录位置output_folders = ['./output_text', # 当前目录os.path.expanduser('~/ocr_output'), # 用户主目录os.path.join(os.getcwd(), 'ocr_output') # 当前工作目录]output_folder = Nonefor folder in output_folders:try:os.makedirs(folder, exist_ok=True)output_folder = folderprint(f"Using output directory: {os.path.abspath(output_folder)}")breakexcept Exception as e:print(f"Failed to create output directory {folder}: {str(e)}")if output_folder is None:print("Error: Could not create any output directory")exit(1)# 初始化日志log_file = os.path.join(output_folder, 'ocr_log.txt')# 重定向标准输出到日志文件import sysclass Logger(object):def __init__(self, filename):self.terminal = sys.stdoutself.log = open(filename, "a", encoding='utf-8')def write(self, message):self.terminal.write(message)self.log.write(message)def flush(self):passsys.stdout = Logger(log_file)print("OCR Processing Log\n")print(f"Starting OCR processing at {time.strftime('%Y-%m-%d %H:%M:%S')}")# 支持的图片格式image_extensions = ['.bmp', '.jpg', '.jpeg', '.png', '.tiff', '.gif']# 遍历当前目录及子目录for root, dirs, files in os.walk('.'):for file in files:file_path = os.path.join(root, file)base_name, ext = os.path.splitext(file)try:# 处理图片文件if ext.lower() in image_extensions:print(f"Processing image: {file_path}")text = process_image(file_path)output_path = os.path.join(output_folder, f"{base_name}.txt")save_text(text, output_path)print(f"Successfully processed image: {file_path} -> {output_path}")with open(log_file, 'a') as f:f.write(f"Success: {file_path} -> {output_path}\n")# 处理PDF文件elif ext.lower() == '.pdf':print(f"Processing PDF: {file_path}")text = process_pdf(file_path)output_path = os.path.join(output_folder, f"{base_name}.txt")save_text(text, output_path)print(f"Successfully processed PDF: {file_path} -> {output_path}")with open(log_file, 'a') as f:f.write(f"Success: {file_path} -> {output_path}\n")except Exception as e:error_msg = f"Error processing {file_path}: {str(e)}"print(error_msg)with open(log_file, 'a') as f:f.write(error_msg + "\n")if __name__ == "__main__":main()
相关文章:

使用easyocr、PyPDF2对图像及PDF文档进行识别
一、概述 本 Python 脚本的主要功能是对当前目录及其子目录下的图片和 PDF 文件进行光学字符识别(OCR)处理。它使用 easyocr 库处理图片中的文字,使用 PyPDF2 库提取 PDF 文件中的文本,并将处理结果保存为文本文件。同时ÿ…...

MAUI(C#)安卓开发起步
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

oracle decode
1. 基本语法 DECODE(expression, search1, result1, search2, result2, ..., default_result) expression :需要比较的表达式或列。search1, search2, ... :要匹配的值。result1, result2, ... :当 expression 等于 search 时返回的结果。def…...

826考研
初试总分第一的hh佬小红书:https://www.xiaohongshu.com/user/profile/64e106aa000000000100fe33 深研院巨佬经验贴:https://zhuanlan.zhihu.com/p/690464528 本部羊神经验贴:https://zhuanlan.zhihu.com/p/689494655 本部学硕佬经验贴&#…...

PPT小黑第26套
对应大猫28 层次级别是错的,看着是十页,导入ppt之后四十多页 选中所有 红色蓝色黑色 文本选择标题:选择 -格式相似文本(检查有没有漏选 漏选的话 按住ctrl 点下一个) 要求新建幻灯片中不包含原素材中的任何格式&…...

【Linux-网络】HTTP的清风与HTTPS的密语
🎬 个人主页:谁在夜里看海. 📖 个人专栏:《C系列》《Linux系列》《算法系列》 ⛰️ 道阻且长,行则将至 目录 📚 引言 📚 一、HTTP 📖 1.概述 📖 2.URL ǵ…...

Vue 与 Nuxt 的区别
Nuxt 实现服务端渲染SSR Nuxt.js 是基于 Vue.js 的一个框架,它为构建 Vue.js 应用提供了更高级的功能和更便捷的开发体验。 一、定位与功能 Vue.js 是一个前端 JavaScript 框架,专注于构建用户界面和单页应用(SPA)。 核心功能…...
)
华为OD机试-最长的密码(Java 2024 E卷 100分)
题目描述 小王正在进行游戏大闯关,有一个关卡需要输入一个密码才能通过。密码获得的条件如下: 在一个密码本中,每一页都有一个由26个小写字母组成的密码,每一页的密码不同。需要从这个密码本中寻找这样一个最长的密码,从它的末尾开始依次去掉一位得到的新密码也在密码本…...

利用golang embed特性嵌入前端资源问题解决
embed嵌入前端资源,配置前端路由的代码如下 func StartHttpService(port string, assetsFs embed.FS) error {//r : gin.Default()gin.SetMode(gin.ReleaseMode)r : gin.New()r.Use(CORSMiddleware())// 静态文件服务dist, err : fs.Sub(assetsFs, "assets/di…...

解决docker认证问题 failed to authorize: failed to fetch oauth token
报错信息[bash1]解决方案 全局代理打开“buildkit”: false ,见[图1] [bash1] >docker build -t ffpg . [] Building 71.8s (3/3) FINISHED docker:desktop-linux> [internal] load bui…...

【Flink银行反欺诈系统设计方案】3.欺诈的7种场景和架构方案、核心表设计
【Flink银行反欺诈系统设计方案】3.欺诈的7种场景和架构方案、核心表设计 1. **欺诈场景分类与案例说明**1.1 **大额交易欺诈**1.2 **异地交易欺诈**1.3 **高频交易欺诈**1.4 **异常时间交易欺诈**1.5 **账户行为异常**1.6 **设备指纹异常**1.7 **交易金额突变** 2. **普适性软…...

docker拉取失败
备份原始配置文件 sudo cp /etc/docker/daemon.json /etc/docker/daemon.json.bak 清理或修复 daemon.json 文件 sudo nano /etc/docker/daemon.json 删除 文件中的所有内容,确保文件为空。 cv下面这个文件内容 { "registry-mirrors": [ &…...

无人机应用探索:玻纤增强复合材料的疲劳性能研究
随着无人机技术的快速发展,轻量化已成为其结构设计的核心需求。玻纤增强复合材料凭借高强度、低密度和优异的耐环境性能,成为无人机机身、旋翼支架等关键部件的理想选择。然而,无人机在服役过程中需应对复杂多变的环境:高空飞行时…...

Visual Studio工具
高亮显示匹配的标签(小括号,中括号,大括号)...

STM32Cubemx配置E22-xxxT22D lora模块实现定点传输
文章目录 一、STM32Cubemx配置二、定点传输**什么是定点传输?****定点传输的特点****定点传输的工作方式****E22 模块定点传输配置****如何启用定点传输?****示例** **应用场景****总结** **配置 1:C0 00 07 00 02 04 62 00 17 40****解析** …...

iterm2更新后主题报错
报错 .oh-my-zsh/themes/agnoster.zsh-theme:307: parse error near <<<。方法1:更新Oh My Zsh主题(以agnoster为例) 适用场景:使用Oh My Zsh自带主题(如agnoster)时出现语法错误。 备份当前主题…...
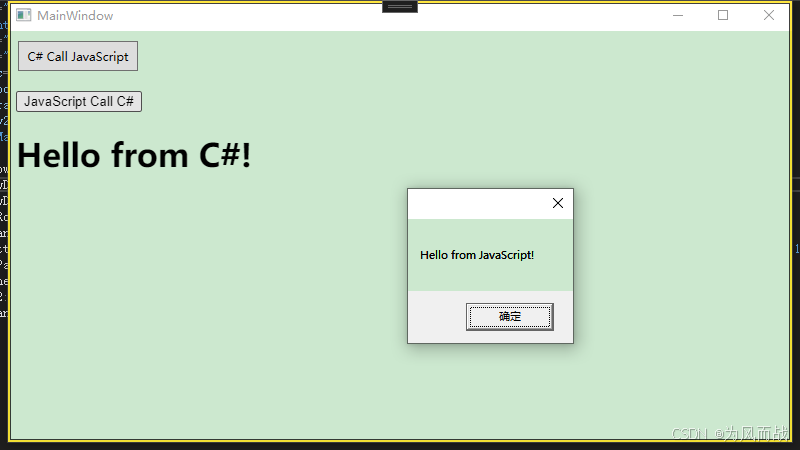
WPF+WebView 基础
1、基于.NET8,通过NuGet添加Microsoft.Web.WebView2。 2、MainWindow.xaml代码如下。 <Window x:Class"Demo.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/win…...
->removeWidget(bar);)
不懂ui->layout()->removeWidget(bar);
ui->layout()->removeWidget(bar);解释起来就是:ui->layout()返回一个指针,然后这个指针再调用->removeWidget(bar)。 你提到的语法 ui->layout()->removeWidget(bar) 确实可能让人感到困惑,尤其是如果你对 Qt 的 UI 系统不…...

蓝桥杯算法——铠甲合体
问题描述 暗影大帝又开始搞事情了!这次他派出了 MM 个战斗力爆表的暗影护法,准备一举摧毁 ERP 研究院!MM 个暗影护法的战斗力可分别用 B1,⋯,BMB1,⋯,BM 表示。 ERP 研究院紧急召唤了 NN 位铠甲勇士前来迎战!每位铠甲勇士都…...

JAVA毕设项目-基于SSM框架的百色学院创新实践学分认定系统源码+设计文档
文末获取源码数据库文档 感兴趣的可以先收藏,有毕设问题,项目以及论文撰写等问题都可以和博主沟通,尽最大努力帮助更多的人! 百色学院创新实践学分认定系统设计与实现 摘 要 本百色学院创新实践学分认定系统是针对目前实践学分认定…...

【LangChain】存储与管理对话历史
0. 代码演示 from langchain_community.chat_message_histories import SQLChatMessageHistorydef get_session_history(session_id):# 通过 session_id 区分对话历史,并存储在 sqlite 数据库中return SQLChatMessageHistory(session_id, "sqlite:///memory.d…...

[machine learning] MACS、MACs、FLOPS、FLOPs
本文介绍机器学习中衡量一个模型计算复杂度的四个指标:MACS、MACs、FLOPS、FLOPs。 首先从含义上讲,可以分类两类:MACS/FLOPS和MACs/FLOPs。MACs/FLOPs表示总的操作数(后缀s可以看成是表示复数),MACS/FLOPS表示每秒可以执行的操作…...

学习笔记-AMD CPU 命名
AMD的AI处理器主要分为锐龙AI 1代(基于Zen4架构XDNA 1 NPU)和锐龙AI 2代(基于Zen5架构XDNA 2 NPU),以下是两代的详细说明: 一、锐龙AI 1代(2024年发布) 1. 命名规则 结构…...
网页设计案例)
【Javascript】计算器(Calculator)网页设计案例
代码如下: <!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>计算器</title…...

Stable Diffusion模型高清算法模型类详解
Stable Diffusion模型高清算法模型类详细对比表 模型名称核心原理适用场景参数建议显存消耗细节增强度优缺点4x-UltraSharp残差密集块(RDB)结构优化纹理生成真实人像/建筑摄影重绘幅度0.3-0.4,分块尺寸768px★★★★★☆皮肤纹理细腻,但高对比场景易出现…...

十大经典排序算法简介
一 概述 本文对十大经典排序算法做简要的总结(按常用分类方式排列),包含核心思想、时间/空间复杂度及特点。 二、比较类排序 1. 冒泡排序 (BUBBLE SORT) 思想:重复交换相邻逆序元素,像气泡上浮 复杂度: 时间:O(n^2)(最好情况O(n)) 空间:O(1) 特点:简单但效率低,稳…...

迷你世界脚本玩家接口:Player
玩家接口:Player 彼得兔 更新时间: 2024-07-28 17:49:05 继承自 Actor 具体函数名及描述如下: 序号 函数名 函数描述 1 getAttr(...) 玩家属性获取 2 setAttr(...) 玩家属性设置 3 getHostUin(...) 获取房主uin 4 isMainPlayer(...) …...

探秘 C 语言:编程世界的基石与传奇
一、C 语言的前世今生 C 语言诞生于 20 世纪 70 年代,由贝尔实验室的丹尼斯・里奇(Dennis Ritchie)开发。它最初是为了配合 UNIX 操作系统的开发,旨在提供一种高效、灵活且可移植的编程语言。在那个硬件资源有限的年代࿰…...

docker:Dockerfile案例之自定义centos7镜像
1 案例需求 自定义centos7镜像。要求: 默认登录路径为 /usr可以使用vim 2 实施步骤 编写dockerfile脚本 vim centos_dockerfile 内容如下: #定义父镜像 FROM centos:7#定义作者信息 MAINTAINER handsome <handsomehandsome.com># 设置阿里云…...

1、语言的本质
语言的本质 1.1 语言的产生生物重演律 1.2 语言的本质1.3 语系1.4 文字的起源汉字的构成和使用 后记 语言是人类传递信息的工具,其本质是信息的载体。 语音和文字是构成语言的两个基本属性,语音是语言承载的物理信号,文字是记录语言的逻辑符…...