Python在机器学习与数据分析领域的深度应用:从基础到实战
在当今数字化时代,数据如同宝贵的矿产资源,蕴含着无尽的价值等待挖掘。Python作为一门强大而灵活的编程语言,凭借其丰富的库和工具,在机器学习和数据分析领域扮演着举足轻重的角色。它不仅为数据科学家和开发者提供了高效处理和分析数据的手段,还助力构建各种智能模型,实现精准预测和决策支持。本文将深入探讨Python在机器学习和数据分析领域的应用,涵盖机器学习基础概念、Pandas库的使用技巧、数据分析实战案例,以及机器学习算法的实践应用。
一、机器学习基础
(一)机器学习的定义与目标
机器学习是人工智能的一个重要分支,它赋予计算机系统从数据中自动学习模式和规律的能力,而无需进行明确的编程指令。其核心目标是通过对大量历史数据的学习,构建模型来预测未来事件、识别模式或进行决策。例如,在图像识别领域,机器学习模型可以通过学习大量图像数据,识别出不同的物体类别;在金融领域,模型可以根据历史市场数据预测股票价格走势,帮助投资者做出更明智的决策。
(二)机器学习的类型
1. 监督学习:监督学习是最常见的机器学习类型之一。在这种学习方式中,训练数据包含了输入特征(自变量)和对应的输出标签(因变量)。模型通过学习输入特征与输出标签之间的关系,来预测新的输入数据对应的输出值。常见的监督学习算法包括线性回归、逻辑回归、决策树、支持向量机等。以预测房价为例,训练数据中包含房屋面积、房间数量、地理位置等输入特征,以及对应的房价作为输出标签。通过这些数据训练线性回归模型,当输入新的房屋特征时,模型可以预测出相应的房价。
2. 无监督学习:与监督学习不同,无监督学习的训练数据中只有输入特征,没有预先定义的输出标签。其目的是发现数据中的潜在结构、模式或分组。聚类算法(如K-Means聚类)和主成分分析(PCA)是无监督学习的典型代表。在客户细分场景中,使用K-Means聚类算法对客户的消费行为数据进行分析,将具有相似消费模式的客户划分到同一组,从而为企业制定个性化的营销策略提供依据。
(三)机器学习的实现步骤
1. 数据收集:数据是机器学习的基础,高质量的数据对于构建准确有效的模型至关重要。数据可以从各种来源收集,如数据库、网络爬虫、传感器等。例如,在医疗领域,收集患者的病历数据、生理指标数据等;在电商领域,收集用户的购买记录、浏览行为数据等。
2. 数据准备:收集到的数据往往存在噪声、缺失值、异常值等问题,需要进行预处理。这包括数据清洗,去除噪声和异常值;数据填充,处理缺失值;数据归一化或标准化,使不同特征的数据具有相同的尺度,以提高模型的性能和收敛速度。
3. 数据分析:通过数据分析,了解数据的特征和分布,发现数据中的规律和趋势。常用的数据分析方法包括描述性统计分析、相关性分析、可视化分析等。例如,使用直方图展示数据的分布情况,使用散点图分析两个变量之间的相关性。
4. 选择训练算法:根据问题的类型和数据的特点,选择合适的机器学习算法。不同的算法适用于不同的场景,例如线性回归适用于连续值预测问题,逻辑回归适用于二分类问题,决策树适用于分类和回归问题等。
5. 训练模型:将准备好的数据输入到选择的算法中,进行模型训练。在训练过程中,模型不断调整自身的参数,以最小化预测结果与实际标签之间的误差。训练过程中可以使用交叉验证等技术,评估模型的性能,并防止过拟合。
6. 测试模型:使用测试数据集对训练好的模型进行评估,计算模型的准确率、召回率、F1值等指标,以衡量模型的性能。如果模型性能不符合要求,可以调整算法参数、增加数据量或尝试其他算法,重新进行训练和测试。
7. 应用模型:当模型性能满足要求后,将其应用到实际场景中,对新的数据进行预测和分析,为决策提供支持。
二、Pandas库的使用
(一)Pandas库概述
Pandas是Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。它使得数据读取、清洗、处理和分析变得高效而便捷,是Python数据分析生态系统中不可或缺的一部分。
(二)数据读取与写入
1. 读取常见文件格式:Pandas可以轻松读取CSV、Excel、SQL数据库等多种常见文件格式的数据。例如,使用 read_csv 函数读取CSV文件:
import pandas as pd
data = pd.read_csv('data.csv')
2. 写入文件:将处理后的数据保存到文件中,使用 to_csv 函数将DataFrame对象保存为CSV文件:
data.to_csv('new_data.csv', index=False)
(三)数据选择与过滤
1. 基于索引选择数据:Pandas中的DataFrame和Series对象都有索引,可以通过索引来选择特定的数据行或列。例如,选择DataFrame中的某一行数据:
row_data = data.loc[0] # 选择第一行数据
2. 条件过滤数据:根据条件筛选数据是数据分析中常用的操作。例如,筛选出年龄大于30岁的用户数据:
filtered_data = data[data['age'] > 30]
(四)数据清洗与预处理
1. 处理缺失值:数据中常常存在缺失值,Pandas提供了多种处理缺失值的方法。可以使用 dropna 函数删除含有缺失值的行或列,也可以使用 fillna 函数填充缺失值:
# 删除含有缺失值的行
cleaned_data = data.dropna()
# 使用指定值填充缺失值
data.fillna(0, inplace=True)
2. 处理重复值:使用 duplicated 函数检测数据中的重复行,并使用 drop_duplicates 函数删除重复行:
duplicate_rows = data[data.duplicated()]
unique_data = data.drop_duplicates()
(五)数据合并与重塑
1. 数据合并:在数据分析中,经常需要将多个数据集进行合并。Pandas提供了 merge 和 concat 函数来实现数据的合并操作。 merge 函数用于根据指定的键进行数据合并,类似于SQL中的JOIN操作; concat 函数用于沿着轴进行数据拼接。
# 合并两个DataFrame
merged_data = pd.merge(data1, data2, on='common_column')
# 拼接两个DataFrame
concatenated_data = pd.concat([data1, data2])
2. 数据重塑: pivot 函数和 melt 函数是Pandas中用于数据重塑的重要工具。 pivot 函数可以将数据从长格式转换为宽格式, melt 函数则相反,将宽格式数据转换为长格式,以满足不同的分析需求。
三、数据分析实战案例
(一)案例背景与数据来源
假设我们是一家电商公司的数据分析师,为了了解用户的购买行为和产品销售情况,以便制定营销策略和优化产品布局,我们收集了一段时间内的用户购买记录数据。数据包含用户ID、购买时间、购买产品、购买数量、购买金额等字段,存储在CSV文件中。
(二)数据加载与初步探索
使用Pandas读取数据文件,并进行初步的探索性分析。查看数据的基本信息,包括数据形状、列的数据类型、缺失值情况等:
import pandas as pd
data = pd.read_csv('ecommerce_data.csv')
data.info()
通过分析发现,数据中存在部分缺失值,需要进行处理。
(三)数据清洗与预处理
1. 处理缺失值:对于购买金额等重要字段的缺失值,采用均值填充的方法进行处理:
mean_amount = data['purchase_amount'].mean()
data['purchase_amount'].fillna(mean_amount, inplace=True)
2. 处理异常值:通过绘制箱线图,发现购买数量存在异常值,将其进行截断处理,使其在合理范围内。
(四)数据分析与可视化
1. 用户购买行为分析:计算每个用户的购买次数和购买总金额,分析用户的购买频率和消费能力:
user_purchase_summary = data.groupby('user_id').agg({'purchase_count':'count', 'total_amount':'sum'})
使用Matplotlib和Seaborn进行数据可视化,绘制用户购买次数和购买总金额的分布直方图,直观展示用户的购买行为特征。
2. 产品销售分析:分析不同产品的销售数量和销售金额,找出畅销产品和滞销产品:
product_sales_summary = data.groupby('product_name').agg({'quantity_sold':'sum','revenue':'sum'})
绘制产品销售金额的柱状图,帮助公司了解产品的销售情况,以便调整产品策略。
四、机器学习算法实践应用
(一)线性回归算法实现与应用
1. 算法原理:线性回归是一种简单而常用的监督学习算法,用于建立一个线性模型来预测连续值。其基本原理是通过最小化预测值与实际值之间的误差平方和,来确定模型的参数。
2. Python实现:使用 scikit-learn 库中的 LinearRegression 类实现线性回归模型。以预测房屋价格为例,准备房屋面积、房间数量等特征数据和对应的房价数据,进行模型训练和预测:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
# 准备数据
X = np.array([[100, 3], [120, 4], [80, 2], [150, 5]])
y = np.array([200, 250, 150, 300])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
(二)决策树算法实现与应用
1. 算法原理:决策树是一种基于树结构的分类和回归算法。它通过对特征进行递归划分,构建决策树模型,根据输入特征的不同取值来做出决策。
2. Python实现:使用 scikit-learn 库中的 DecisionTreeClassifier 类实现决策树分类模型。以鸢尾花数据集为例,进行模型训练和分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy}")
Python在机器学习和数据分析领域展现出了强大的功能和广泛的应用前景。通过深入学习机器学习基础概念,熟练掌握Pandas库的使用技巧,以及进行数据分析实战和机器学习算法实践,我们能够更好地挖掘数据中的价值,为各行业的决策和发展提供有力支持,在数据驱动的时代中抢占先机,实现创新与突破。
相关文章:

Python在机器学习与数据分析领域的深度应用:从基础到实战
在当今数字化时代,数据如同宝贵的矿产资源,蕴含着无尽的价值等待挖掘。Python作为一门强大而灵活的编程语言,凭借其丰富的库和工具,在机器学习和数据分析领域扮演着举足轻重的角色。它不仅为数据科学家和开发者提供了高效处理和分…...

网络安全ctf试题 ctf网络安全大赛真题
MISC 1 签到 难度 签到 复制给出的flag输入即可 2 range_download 难度 中等 flag{6095B134-5437-4B21-BE52-EDC46A276297} 0x01 分析dns流量,发现dns && ip.addr1.1.1.1存在dns隧道数据,整理后得到base64: cGFzc3dvcmQ6IG5zc195eWRzIQ 解…...

分布式和微服务的理解
分布式系统和微服务是现代化软件架构中两个关键概念,它们共同支撑了高可用、高扩展的互联网应用,但侧重点和解决的问题有所不同。以下是它们的核心理解: 一、分布式系统(Distributed System) 定义: 分…...
Embedding技术:DeepWalkNode2vec
引言 在推荐系统中,Graph Embedding技术已经成为一种强大的工具,用于捕捉用户和物品之间的复杂关系。本文将介绍Graph Embedding的基本概念、原理及其在推荐系统中的应用。 什么是Graph Embedding? Graph Embedding是一种将图中的节点映射…...

基于IMM算法的目标跟踪,四模型IMM|三维环境|4个模型分别是:CV、左转CT、右转CT、CA(基于EKF,订阅专栏后可获得完整源代码)
这段MATLAB代码实现了基于交互多模型(IMM)算法的目标跟踪,结合了四种运动模型(匀速直线、左转圆周、右转圆周和匀加速直线)。通过定义状态方程、生成带噪声的测量数据,以及执行IMM迭代,该代码有效地实现了多模型的状态估计和融合。最终,用户可以通过可视化结果观察目标…...
:检索增强生成(RAG))
大模型工程师日记(十三):检索增强生成(RAG)
Document loaders和Text splitters Document loaders(文档加载器) Document loaders(文档加载器) 这些类加载文档对象。LangChain与各种数据源有数百个集成,可以从中加载数据:Slack、Notion、Google Drive等。 每个文档加载器都有自己特定的参数&#…...

HOW - React 如何在在浏览器绘制之前同步执行 - useLayoutEffect
目录 useEffect vs useLayoutEffectuseEffectuseLayoutEffect主要区别总结选择建议注意事项 useLayoutEffect 使用示例测量 DOM 元素的尺寸和位置示例:自适应弹出框定位 同步更新样式以避免闪烁示例:根据内容动态调整容器高度 图像或 Canvas 绘制前的准备…...

前端开发10大框架深度解析
摘要 在现代前端开发中,框架的选择对项目的成功至关重要。本文旨在为开发者提供一份全面的前端框架指南,涵盖 React、Vue.js、Angular、Svelte、Ember.js、Preact、Backbone.js、Next.js、Nuxt.js 和 Gatsby。我们将从 简介、优缺点、适用场景 以及 实际…...

图像形成与计算机视觉基础
1. 图像形成的基本原理 图像形成是物理世界与传感器(如胶片、CCD/CMOS)交互的过程,核心是光线的传播与记录。 1.1 直接放置胶片模型 物理原理:物体表面反射的光线直接照射到胶片上,但无任何遮挡或聚焦机制。 问题&a…...

【显示】3.1 Android 从Activity到Display链路概括
目录 一,Activity上屏Flow总结 二,链路拆解 2.1 Activity 的创建和 UI 初始化 2.2 Window 和 DecorView 的创建 2.3 Surface 的创建 2.4 View 的绘制流程 2.5 Surface 的提交和合成 2.6 上屏显示 三,多个Activity的处理方式 一,Activity上屏Flow总结 Activity → s…...

【leetcode hot 100 240】搜索二维矩阵Ⅱ
解法一:直接查找 class Solution {public boolean searchMatrix(int[][] matrix, int target) {for(int i0; i<matrix.length; i){for(int j0; j<matrix[0].length; j){if(matrix[i][j]>target){break;}if(matrix[i][j]target){return true;}}}return fal…...

Spring Boot 缓存最佳实践:从基础到生产的完整指南
Spring Boot 缓存最佳实践:从基础到生产的完整指南 引言 在现代分布式系统中,缓存是提升系统性能的银弹。Spring Boot 通过 spring-boot-starter-cache 模块提供了开箱即用的缓存抽象,但如何根据业务需求实现灵活、可靠的缓存方案…...

Ubuntu20.04双系统安装及软件安装(一):系统安装
Ubuntu20.04双系统安装及软件安装(一):系统安装 Ubuntu系统卸载Ubuntu20.04安装BIOS进入系统安装 许久没写博客了,今天开始重新回归了。首先记录我在双系统上重装Ubuntu20.04的安装过程记录以及个人见解。 Ubuntu系统卸载 参考双…...

Linux14-io多路复用
UDP:单循环服务器,服务器同一时刻只能响应一个客户端的请求 TCP:并发服务器,服务器同一时刻只能响应多个客户端的请求 一、构建TCP并发服务器 让TCP服务端具备同时响应多个客户端的能力。 1.多进程 资源消耗大,同资源平台下,并发量小。 2.多线程 创建线程、进程,比…...

【人工智能学习之优化为什么会失败】
【人工智能学习之优化为什么会失败与方案建议】 一、优化为什么会失败?1. 局部极小值和鞍点2. 梯度消失/爆炸(Vanishing/Exploding Gradients)2. 病态条件(Ill-Conditioning)3. 参数初始化不当4. 学习率不当5. 过拟合&…...
)
flask学习2-应用(博客)
flask学习2-应用(博客) 项目目录应用程序工厂连接到数据库建表初始化数据库文件蓝图和视图第一个视图:注册注册登录根据用户id查询用户注销模板基本布局注册登录注册用户静态文件博客蓝图索引创建更新-根据id查询更新-根据id更新删除使项目可安装描述项目安装项目测试覆盖率…...

Next.js项目实战-ai助手帮我写文章发布视频第1节(共89节)
😂Ai在国内外已经杀疯了,老板要求我们把速度再提升快一些,哪怕是几秒,几百毫秒也行~现在,马上就要,就地就要,只好搬出前端服务端(大保健)😓。没错,今天我要分…...

探秘Transformer系列之(9)--- 位置编码分类
探秘Transformer系列之(9)— 位置编码分类 文章目录 探秘Transformer系列之(9)--- 位置编码分类0x00 概述0x01 区别1.1 从直观角度来看1.2 从模型处理角度来看1.3 优劣 0x02 绝对位置编码2.1 基础方案2.2 训练式2.3 三角函数式2.4…...
(2/2))
文件操作(详细讲解)(2/2)
你好呀这里是我说风俗,各位客官走过路过,关关注,点点赞,收收藏,您的鼓励是对我最大的认可,我也会努力更行下去的!!!大一学生不易(》《) 5. 文件的…...

笔记四:C语言中的文件和文件操作
Faye:只要有正确的伴奏,什么都能变成好旋律。 ---------《寻找天堂》 目录 一、文件介绍 1.1程序文件 1.2 数据文件 1.3 文件名 二、文件的打开和关闭 2.1 文件指针 2.2.文件的打开和关闭 2.3 文件读取结束的判定 三、 文件的顺序读写 3.1 顺序读写…...

Zabbix+Deepseek实现AI告警分析(非本地部署大模型版)
目录 前言技术架构DeepSeek API获取1. 注册账号2. 申请API-Key Zabbix告警AI分析 实现1. 创建Scripts2. Scripts关键参数说明3. 需要注意 测试参考链接 前言 最近手伤了,更新频率下降…… 近期在Zabbix社区看到了一篇文章:张世宏老师分享的《Zabbix告警分…...

基于Celery+Supervisord的异步任务管理方案
一、架构设计背景 1.1 需求场景分析 在Web应用中,当遇到以下场景时需要异步任务处理方案: 高延迟操作(大文件解析/邮件发送/复杂计算)请求响应解耦(客户端快速响应)任务队列管理(任务优先级/…...
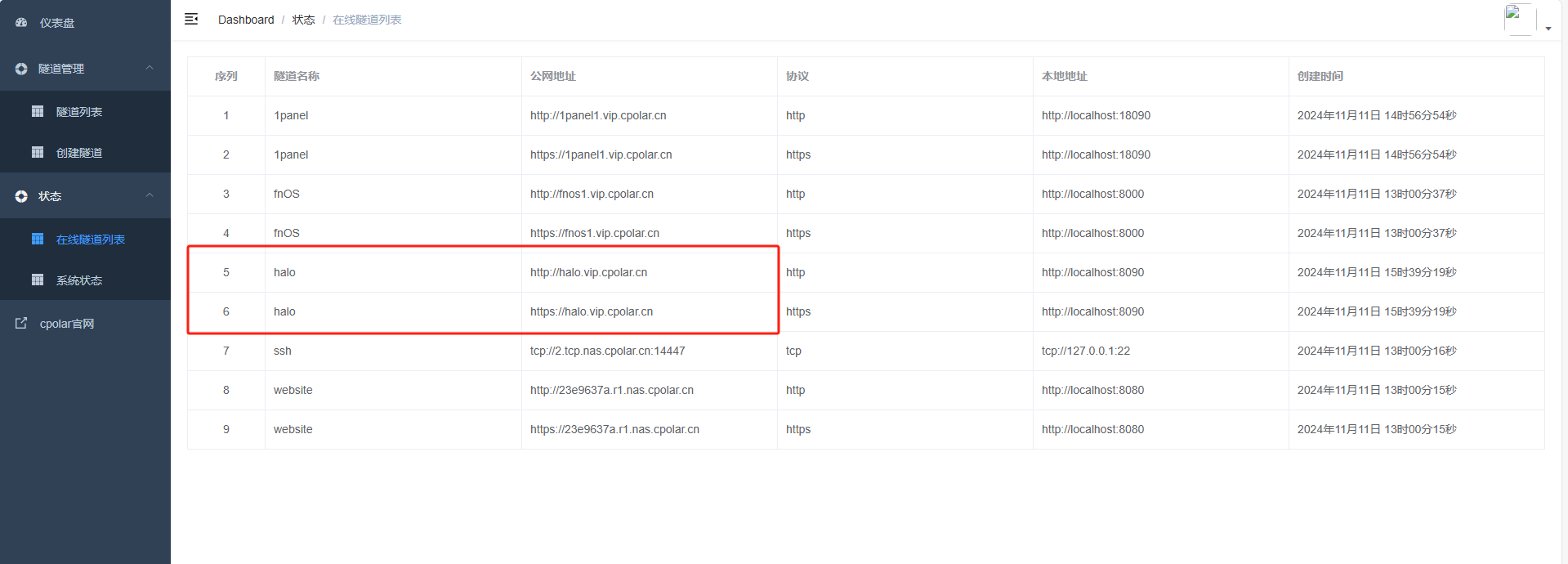
国产NAS系统飞牛云fnOS深度体验:从运维面板到博客生态全打通
文章目录 前言1. 飞牛云本地部署1Panel2. 1Panel功能介绍3. 公网访问1Panel控制面板4. 固定1Panel公网地址5. 1Panel搭建Halo博客6. 公网访问Halo个人博客 前言 嘿,小伙伴们!是不是厌倦了服务器管理的繁琐和搭建个人网站的复杂?今天就来一场…...

使用QT + 文件IO + 鼠标拖拽事件 + 线程 ,实现大文件的传输
第一题、使用qss,通过线程,使进度条自己动起来 mythread.h #ifndef MYTHREAD_H #define MYTHREAD_H#include <QObject> #include <QThread> #include <QDebug>class mythread : public QThread {Q_OBJECT public:mythread(QObject* …...

【LeetCode 热题 100】438. 找到字符串中所有字母异位词 | python 【中等】
继续学!嗨起来!!!(正确率已经下30%了,我在干什么) 题目: 438. 找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的子串,返回这些子串的…...

博查搜索API日调用量突破3000万次,达到Bing API的1/3。
根据第三方机构统计,2024年Bing Search API 全球日均调用量为1.1亿次。截至2025年3月,博查 Search API日均调用量已达到3000万次(约为Bing的1/3),承接着国内AI应用60%的联网搜索请求。...

【蓝桥杯集训·每日一题2025】 AcWing 5539. 牛奶交换 python
AcWing 5539. 牛奶交换 Week 3 3月6日 题目描述 农夫约翰的 N N N 头奶牛排成一圈,使得对于 1 , 2 , … , N − 1 1,2,…,N−1 1,2,…,N−1 中的每个 i i i,奶牛 i i i 右边的奶牛是奶牛 i 1 i1 i1,而奶牛 N N N 右边的奶牛是奶牛 …...
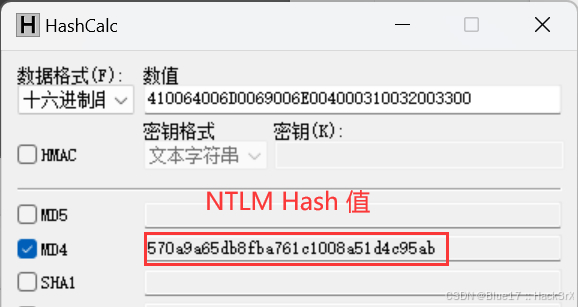
[内网安全] Windows 本地认证 — NTLM 哈希和 LM 哈希
关注这个专栏的其他相关笔记:[内网安全] 内网渗透 - 学习手册-CSDN博客 0x01:SAM 文件 & Windows 本地认证流程 0x0101:SAM 文件简介 Windows 本地账户的登录密码是存储在系统本地的 SAM 文件中的,在登录 Windows 的时候&am…...

输电线路杆塔倾斜智能监测:守护电网安全的智慧之眼
2023年夏,某超高压输电线路突发倒塔事故,导致三省市大面积停电,直接经济损失超2.3亿元。事后调查显示,杆塔倾斜角度早已超出安全阈值,但传统巡检未能及时发现。这个刺痛行业的案例,揭开了电力设施监…...

FastGPT 引申:奥运选手知识图谱构建与混合检索应用
目录 FastGPT 引申:奥运选手知识图谱构建与混合检索应用第一部分:数据构建流程1. 数据抽取与预处理2. 向量化处理3. 知识图谱构建4. 数据持久化 第二部分:混合检索应用1. 用户查询处理2. 混合检索技术细节3. 返回结果示例4. 性能指标 FastGPT…...