PromQL计算gateway指标增量最佳实践及常见问题答疑
普米官方网站
普米官方帮助:Getting started | Prometheus
普米下载地址:Download | Prometheus
普米查询语法:Querying basics | Prometheus
普米函数参考:Query functions | Prometheus
promql计算增量
在PromQL(Prometheus Query Language)中,计算增量(即两个时间点之间的差异)通常涉及到使用rate()函数或者increase()函数。这两种方法各有其适用的场景,下面我将分别解释它们并展示如何在PromQL中实现。
1. 使用rate()函数
rate()函数用于计算在指定时间内的平均速率。这对于计算随着时间的推移而增长的速率非常有用。例如,如果你想计算每秒的请求数,可以使用rate()。
rate(http_requests_total[5m])这里,http_requests_total是一个计数器,[5m]表示在过去5分钟内的数据。rate()函数会计算这5分钟内请求的平均增长速率。
2. 使用increase()函数
increase()函数用于计算在指定时间范围内的绝对增量。如果你需要知道在两个时间点之间有多少次事件发生,使用increase()是合适的。
increase(http_requests_total[5m])这行代码会返回在过去5分钟内http_requests_total计数的增加量,即总共增加了多少次请求。
3. 使用delta()函数(Prometheus 2.8.0及以后版本)
从Prometheus 2.8.0版本开始,还可以使用delta()函数来计算两个时间点之间的差异。这对于需要精确计算两次查询之间差异的场景非常有用。
delta(http_requests_total[5m])这里,delta()同样计算过去5分钟内http_requests_total的增加量,但是它直接返回增加的数量,而不是平均速率。
选择哪种方法?
-
如果你关心的是速率(比如每秒的增长率),使用
rate()。 -
如果你需要知道在特定时间段内发生了多少次事件,使用
increase()或delta()(取决于你的Prometheus版本)。 -
如果你需要精确知道两个时间点之间的差异,使用
delta()。
示例:比较不同方法
假设你想要知道在过去1小时内,每小时有多少个HTTP请求:
使用rate():
rate(http_requests_total[1h]) * 60 * 60 // 将结果转换为每小时的请求数使用increase():
increase(http_requests_total[1h]) // 直接返回过去1小时内的总增加量使用delta():
delta(http_requests_total[1h]) // 直接返回过去1小时内的总增加量选择哪种方法取决于你的具体需求和场景。
最佳实践
场景一:springcloud gateway近二分钟的请求数量(绝对增量)
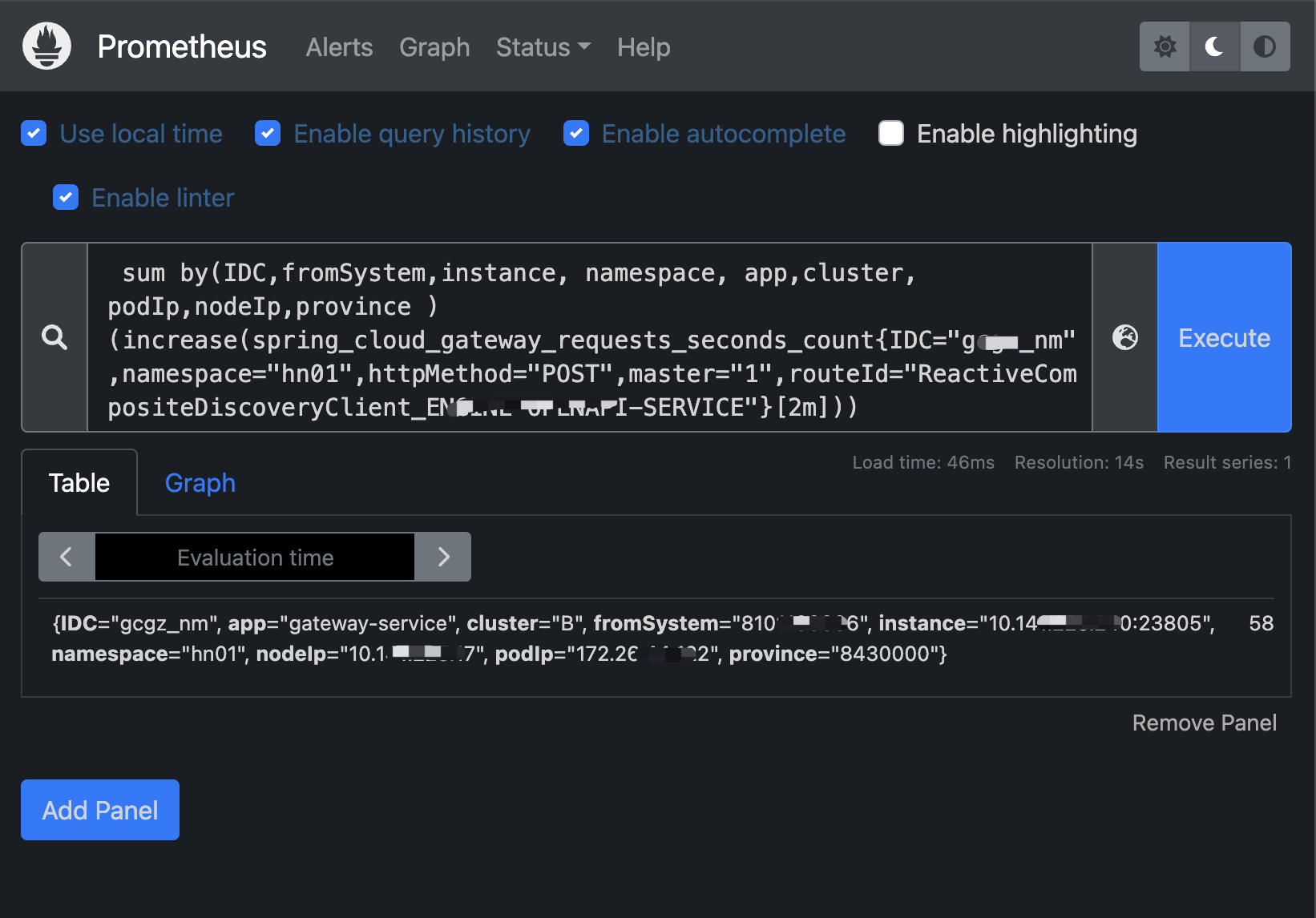
# 近两分钟的调用量(增量查询)
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))注意:查增量时时间区t>=2m(采集间隔的两陪时间) ,否则查不出数据
表达式详解:
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))
IDC: 资源池代码,如:北京、上海、深圳、新加坡(服务器资源)
fromSystem: 来源系统代码(哪个系统的指标数据)
instance: 集群指标采集端点地址
namespace:命名空间,如:湖南集群1
nodeip:gateway所在物理机ip
podIp:gateway 在k8s上的pod ip
province:(内部)省份代码
58 -- 指标值:区间内(2分钟)有58次调用
场景二:近5分钟每分钟的平均调用量
# 近5分钟每分钟的平均调用量
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[5m]))/5解析:增量/时间
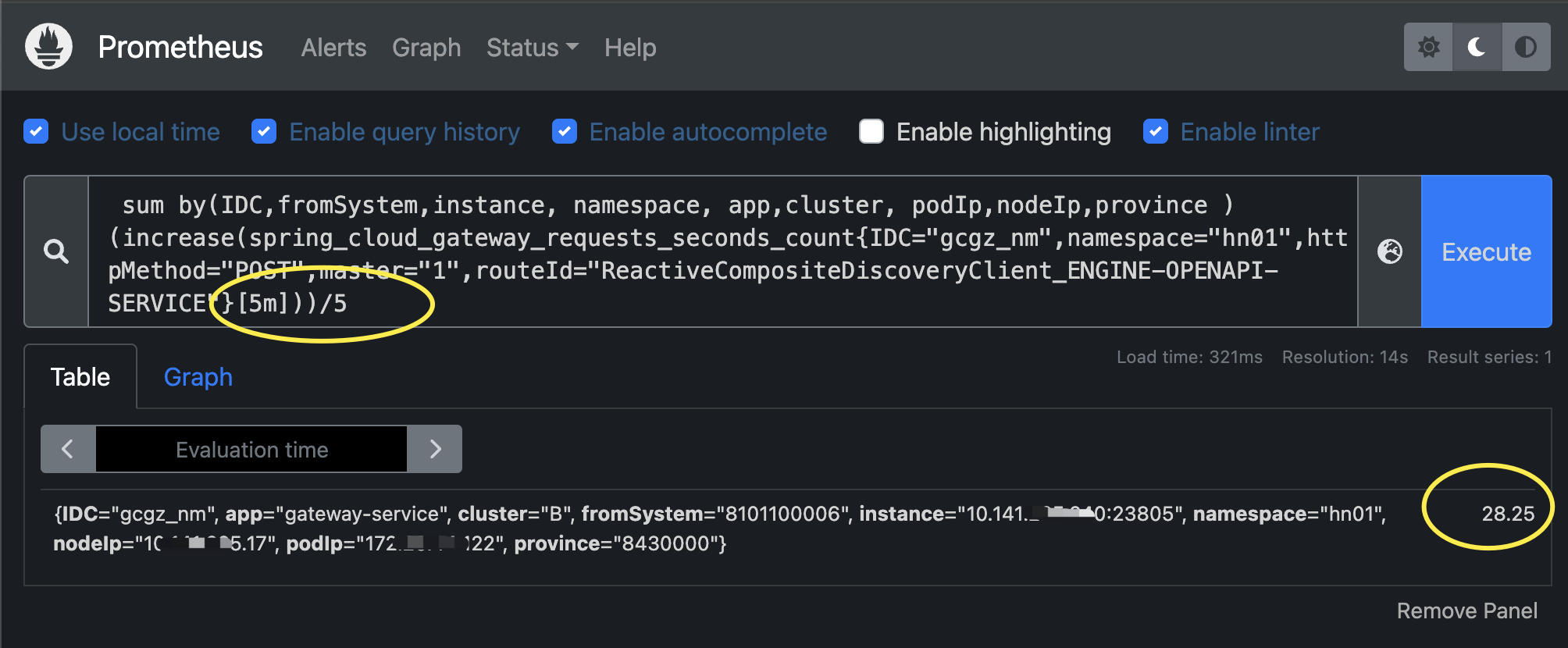
场景三:近2分钟的调用平均耗时
# 近2分钟的调用平均耗时
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_sum{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))/sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))解析:sum/count,sum是耗时,count时调用量
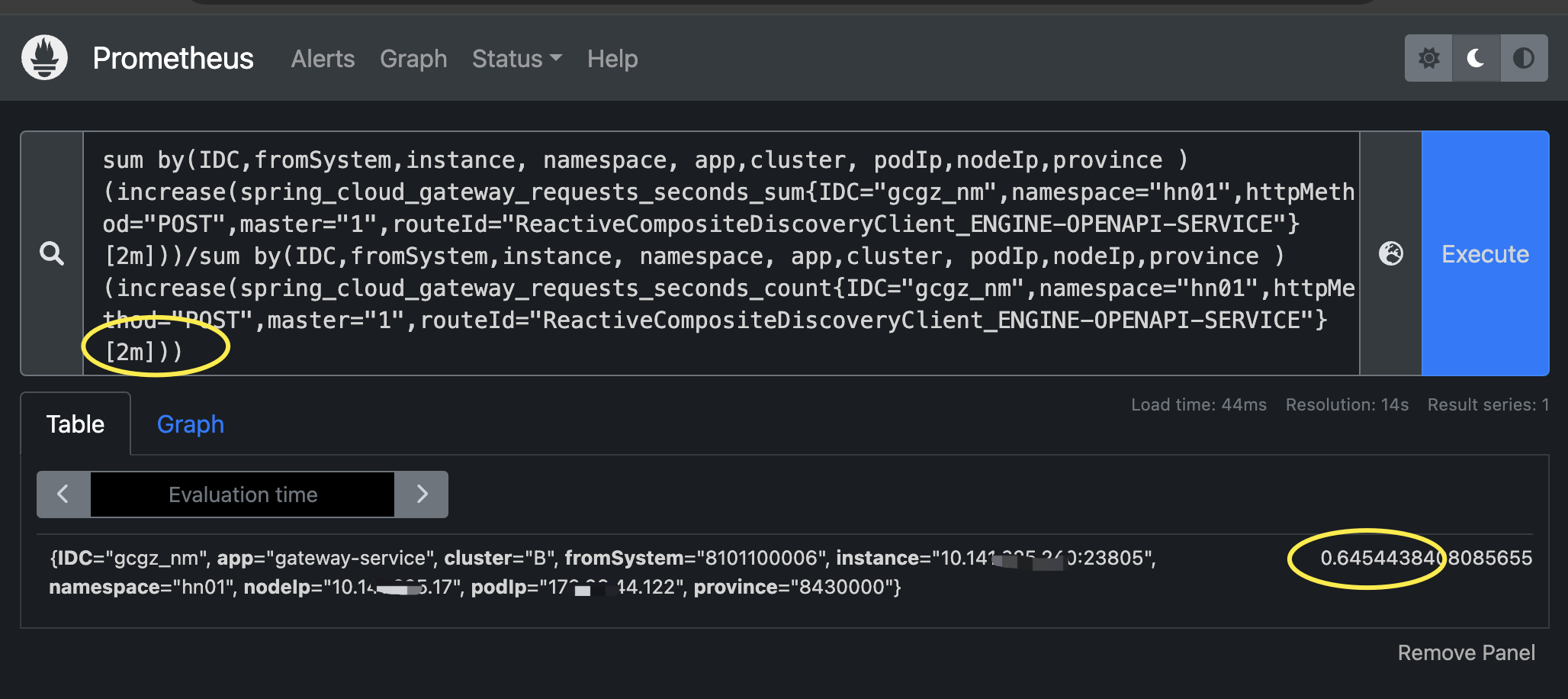
场景四:近2分钟的调用成功率
# 近2分钟的调用成功率
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",httpStatusCode="200",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))/sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))解析:分母表达式多了个条件:httpStatusCode="200"
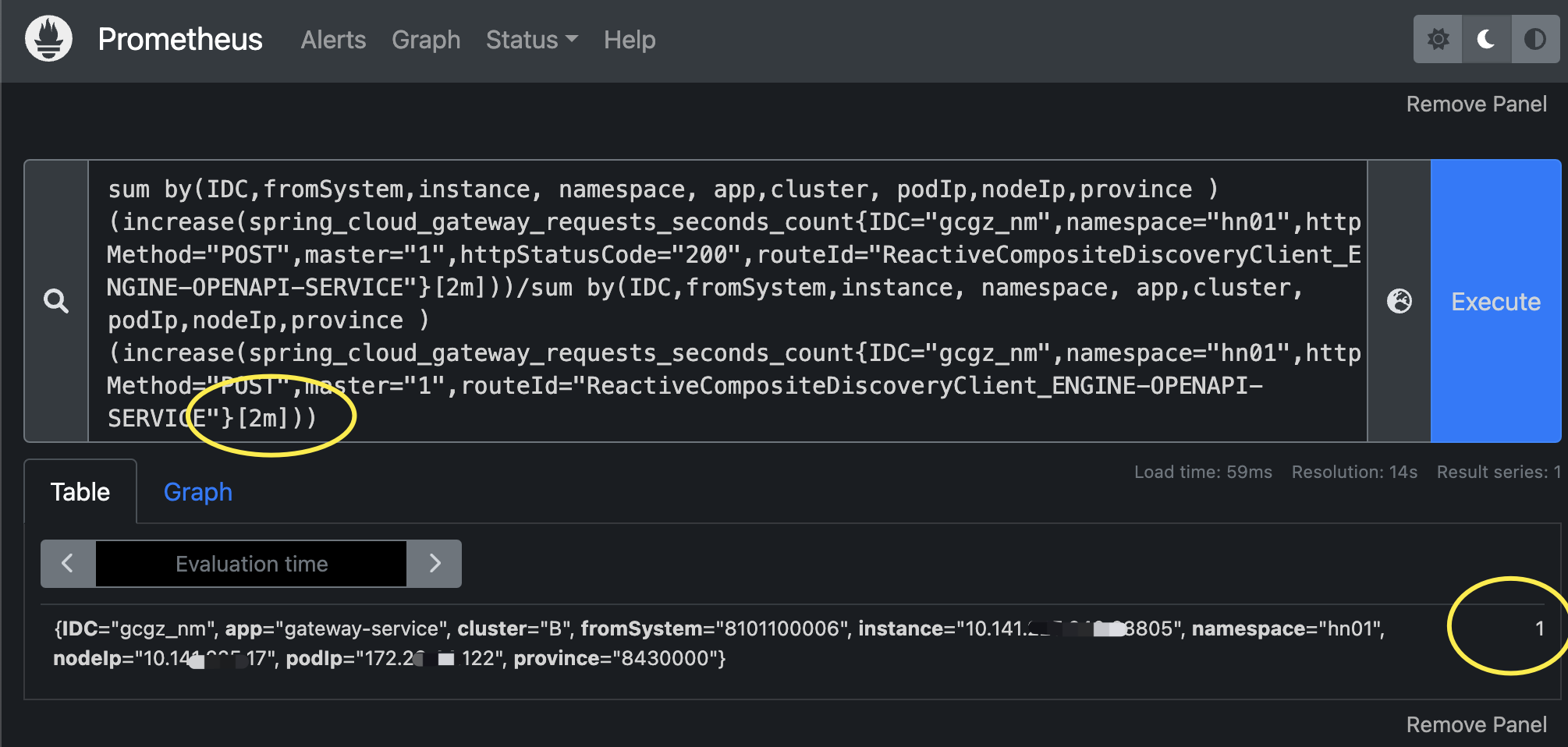
解析:成功率等于1表示100%(存在四舍五入的可能)
常见问题FAQ
Q1:为什么promql 使用increase函数查14分钟的增量与15分钟的增量为什么相差甚远?
A:受时间窗口和采样间隔影响,可能产生较大误差,如:某个时间点的指标丢失。增量就会是累计调用量(差了几个数量级)。实际有时间并不一定是14分钟和15分钟,可能是任意时间点在其范围内查询增量准确,范围外不准确。所以增量尽量缩省范围(减少出错频率、但并不能做到彻底不出错)
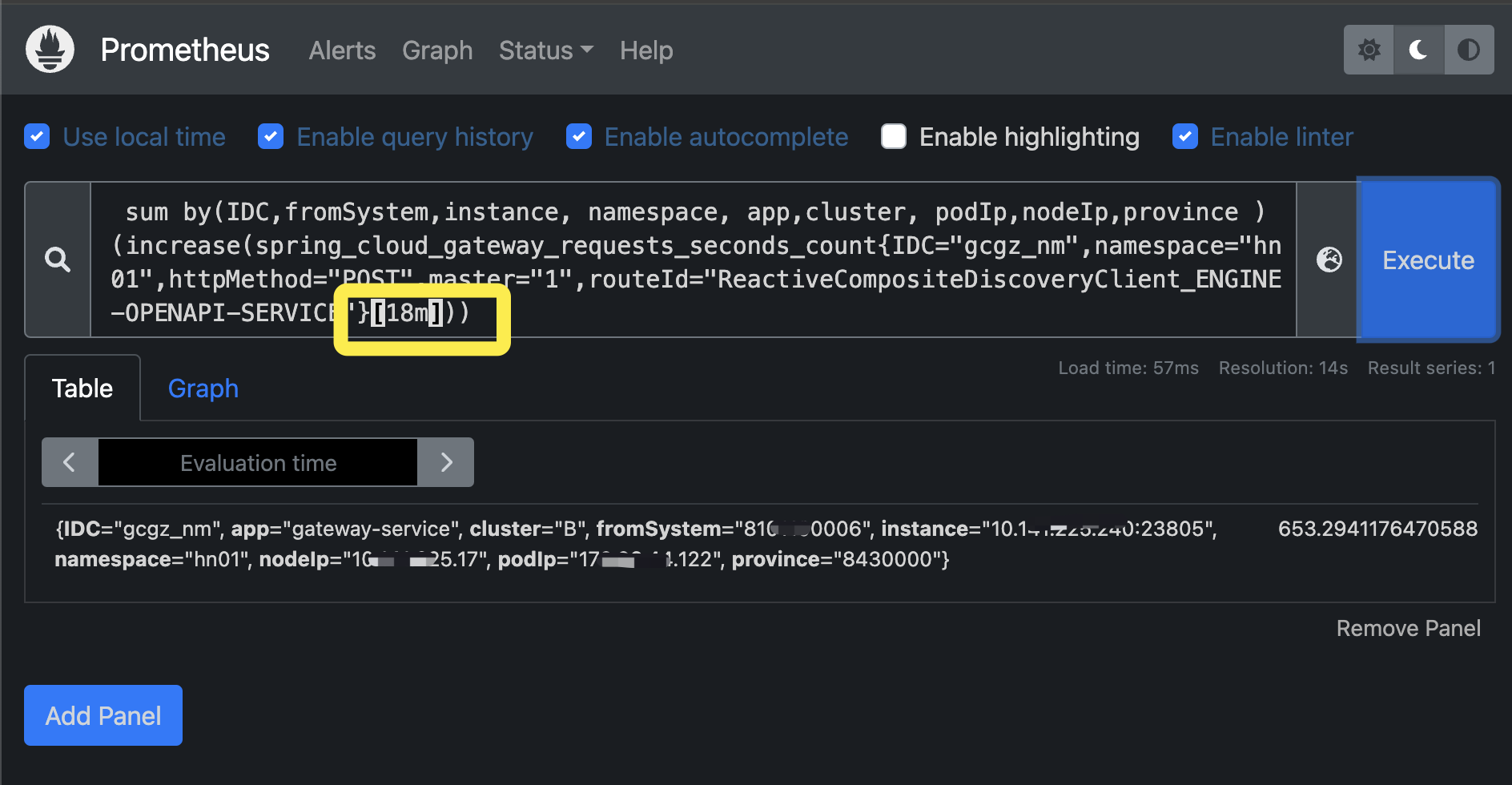
举例:这里查1分钟还是18分钟的增量都是准的,平均每分钟的增量约30(次调用),但19分钟区间查增量就不准了(变成了gateway的累计调用量400多万)
查近二分钟的gateway调用量指标增量数据
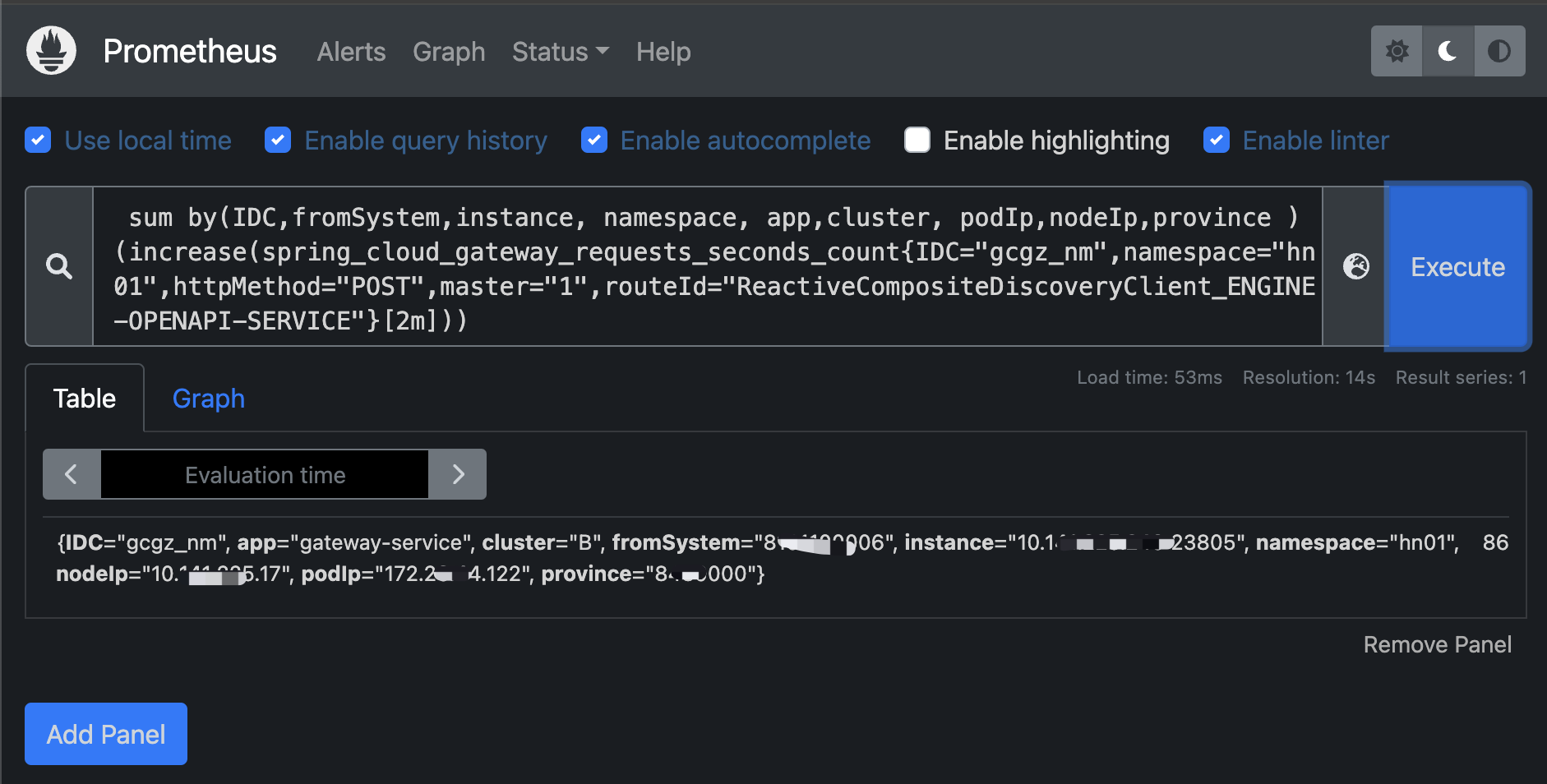
注意:查增量时时间区t>=2m(采集间隔的两陪时间) ,否则查不出数据
查近18分钟的gateway调用量指标增量数据
查近19分钟的gateway调用量指标增量数据(数据异常)

最佳解决方案:
1、使用表达式指标时丢掉较大的指标(如图中丢掉1000以上的指标)从普米采集时直接丢掉
2、使用普米原始指标配置告警时增加上限条件。
可能由以下原因导致:
1. 时间窗口与采样间隔的匹配问题
increase()函数基于时间序列数据的外推算法估算增量,其计算结果受时间窗口与数据采样间隔的倍数关系影响。- 若采样间隔(如 1 分钟)与时间窗口(14 或 15 分钟)不成整数倍,会导致外推算法对首尾样本的修正系数不同。例如:
- 15 分钟窗口可能刚好覆盖整数倍的数据点(如 15 个 1 分钟样本),计算结果更准确。
- 14 分钟窗口可能因未完整覆盖数据周期,导致外推修正后的值与实际偏差较大。
2. 数据点对齐与中断问题
increase()依赖时间窗口内的第一个和最后一个样本值计算增量。若时间窗口存在以下情况,可能导致结果波动:- 数据采集中断:14 分钟内可能存在数据空白(如采集器故障),导致外推算法对缺失数据的补偿不准确。
- 首尾样本异常:若首尾样本值因抖动或异常值突变,14 分钟窗口的短周期会放大这种波动,而 15 分钟窗口可能通过更多样本平滑异常。
3. 计数器重置(Counter Reset)的影响
- Counter 类型指标在发生重置(如应用重启)时,
increase()会自动处理重置事件。 - 若 14 分钟窗口内发生多次重置,可能导致算法对外推增量的修正与 15 分钟窗口不同,进而造成差异。
4. 外推算法的修正系数差异
- Prometheus 的
increase()会对时间窗口边缘的样本进行外推修正,修正系数为时间窗口/采样间隔。- 例如:假设采样间隔为 1 分钟,15 分钟窗口的修正系数为 15,而 14 分钟窗口为 14。两者修正后的增量可能因系数差异而显著不同。
建议解决方案
- 确保时间窗口是采样间隔的整数倍(如采样间隔 1 分钟时,使用 15 分钟而非 14 分钟)。
- 检查数据连续性:通过
up指标或原始时序数据确认是否存在采集中断。 - 结合
rate()验证:对比rate(v[15m]) * 15 * 60与increase(v[15m]),观察外推算法的影响。 - 使用表达式指标时丢掉较大的指标(如图中丢掉1000以上的指标),从普米采集时直接丢掉
- 使用普米原始指标配置告警表达式时增加上限条件。
相关文章:
PromQL计算gateway指标增量最佳实践及常见问题答疑
普米官方网站 普米官方帮助:Getting started | Prometheus 普米下载地址:Download | Prometheus 普米查询语法:Querying basics | Prometheus 普米函数参考:Query functions | Prometheus promql计算增量 在PromQLÿ…...

vue使用slot时子组件的onUpdated执行问题
vue使用slot时子组件的onUpdated执行问题 在使用 Vue 的插槽 (slot) 功能时,可能会遇到一个问题:当父组件的任何状态更新时,子组件的 onUpdated 事件会被触发。这个问题在使用默认插槽时尤为明显。 为了避免这种情况,可以使用作用…...

从零到多页复用:我的WPF MVVM国际化实践
文章目录 第一步:基础实现,资源文件入门第二步:依赖属性,提升WPF体验第三步:多页面复用,减少重复代码第四步:动态化,应对更多字符串总结与反思 作为一名WPF开发者,我最近…...

C++11新特性 3.constexpr
目录 一.简介 1.基本概念 2.语法 (1)constexpr 变量 (2)constexpr 函数 二.使用示例 示例1:constexpr 修饰变量 示例2:constexpr 修饰函数 示例3:constexpr 修饰构造函数 三.注意事项 …...

什么是AI Agent
AI Agent(人工智能代理)是一种能够感知环境、自主决策并采取行动以实现特定目标的智能实体。它结合了人工智能技术(如机器学习、自然语言处理、计算机视觉等),能够通过与环境交互不断学习和优化行为。 核心特征 自主…...

LeetCode 解题思路 12(Hot 100)
解题思路: 定义三个指针: prev(前驱节点)、current(当前节点)、nextNode(临时保存下一个节点)遍历链表: 每次将 current.next 指向 prev,移动指针直到 curre…...

HTML-05NPM使用踩坑
2025-03-04-NPM使用踩坑 本文讲述了一个苦逼程序员在使用NPM的时候突然来了一记nmp login天雷,然后一番折腾之后,终究还是没有解决npm的问题😞😞😞,最终使用cnpm完美解决的故事。 文章目录 2025-03-04-NPM使用踩坑[toc…...

学校地摊尝试实验
学校地摊尝试实验 诸位,我要告诉诸位一件大消息,那就是,我将会利用学校时光的最后一段时间进行疯狂摆摊练习,如何进行摆摊,大家 听我娓娓道来。我要确定摆摊的目的, 第一,赚钱,第二…...

MHA集群
一.MHA集群 MHA master high avavibility 主服务器高可用 如上图所示,我们之前说过,如果在主从复制架构中主服务器出现故障,就需要我们将从服务器作为主服务器,等故障的主服务器修复好之后,再将修好的主服务器作为从服…...

Bazel搭建CUDA工程入门
环境版本: 工程目录: 测试输出: WORKSPACE 参考仓库:CUDA rules for Bazel 及 examples load("bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")http_archive(name "rules_cuda…...

linux awk命令和awk语言
linux awk和awk语言 通常大家说的awk几乎都是在linux/unix中使用的awk命令,见下, https://www.geeksforgeeks.org/awk-command-unixlinux-examples/ 作为命令使用的话,存在下内容 Awk 是一个工具,使程序员能够编写小巧但有效的…...

基于字符的卷积网络在文本分类中的应用与探索
该论文探讨了使用基于字符的卷积网络(ConvNets)进行文本分类的方法,并通过构建大规模数据集展示了其在文本分类任务中的优越性能。与传统的词袋模型、N-gram模型及其TF-IDF变体,以及基于词的卷积网络和循环神经网络等深度学习模型进行了对比。研究发现,基于字符的卷积网络…...

uniapp使用蓝牙,usb,局域网,打印机打印
使用流程(支持安卓和iOS) 引入SDK 引入原生插件包地址如下 https://github.com/oldfive20250214/UniPrinterDemo 连接设备 安卓支持经典蓝牙、ble蓝牙、usb、局域网(参考API) iOS支持ble蓝牙、局域网(参考API&…...

MyBatis 与 JDBC 的关系?
MyBatis 与 JDBC 存在密切的关系,可以理解为:MyBatis 是对 JDBC 的封装和增强,但并没有完全取代 JDBC。 1. JDBC (Java Database Connectivity): 底层 API: JDBC 是 Java 访问数据库的底层 API,它提供了一套标准的接口和类&…...

QILSTE灯珠:尺寸光电全解析
QILSTE灯珠:尺寸光电全解析 🌟 型号H4-115BGRYA/5M,由QILSTE(HongKong)Technology Co., Ltd精心打造,以其1.6x1.5x0.4mm的紧凑外观尺寸,展现高亮红光、翠绿、蓝的缤纷色彩。 📏 尺寸…...

golang从入门到做牛马:第一篇-我与golang的缘分,go语言简介
还记得2018年的夏天,刚毕业的我不知道该做些什么,于是自学了一周的go语言,想要找一份go语言工作的代码,当时的go还没有go mod来管理依赖包,在北京找了一个月的工作,找到了一个小公司做了后端开发,当然使用go语言开发,带着兴奋劲,年轻身体也好,边努力学习,边工作。 时…...

用IdleHandler来性能优化及原理源码分析
背景: 经常在做一些app冷启动速度优化等性能优化工作时候,经常可能会发现有时候需要引入一些第三方sdk,或者库,这些库一般会要求我们在onCreate中进行初始化等,但是onCreate属于生命周期的回调方法,如果on…...

如何在WPS中接入DeepSeek并使用OfficeAI助手(超细!成功版本)
目录 第一步:下载并安装OfficeAI助手 第二步:申请API Key 第三步:两种方式导入WPS 第一种:本地大模型Ollama 第二种APIKey接入 第四步:探索OfficeAI的创作功能 工作进展汇报 PPT大纲设计 第五步:我的使用体验(体验建议) …...
学习指南)
长短期记忆网络(LSTM)学习指南
长短期记忆网络(LSTM)学习指南 1. 定义和背景 长短期记忆网络(Long Short-Term Memory, LSTM)是一种递归神经网络(RNN)的变体,旨在解决传统RNN在处理长期依赖关系时遇到的梯度消失或爆炸问题。…...

Swagger-01.介绍和使用方式
一.Swagger介绍 有了接口文档,我们就可以根据接口文档来开发后端的代码了。如果我们开发完了某个功能,后端如何验证我们开发的是否正确呢?我们就需要测试,使用Swagger就可以帮助后端生成接口文档,并且可以进行后端的接…...

Unity 使用NGUI制作无限滑动列表
原理: 复用几个子物体,通过子物体的循环移动实现,如下图 在第一个子物体滑动到超出一定数值时,使其放到最下方 --------------------------------------------------------------》 然后不停的循环往复,向下滑动也是这…...

【并发编程】聊聊定时任务ScheduledThreadPool的实现原理和源码解析
ScheduledThreadPoolExecutor 是在线程池的基础上 拓展的定时功能的线程池,主要有四种方式,具体可以看代码, 这里主要描述下 scheduleAtFixedRate : 除了第一次执行的时间,后面任务执行的时间 为 time MAX(任务执行时…...

HarmonyOS Next元服务网络请求封装实践
【HarmonyOS Next实战】元服务网络通信涅槃:深度封装如何实现80%性能跃升与零异常突破 ————从架构设计到工程落地的全链路优化指南 一、架构设计全景 1.1 分层架构模型 #mermaid-svg-VOia4RMx7iqmLnu7 {font-family:"trebuchet ms",verdana,arial,…...

如何在语言模型的参数中封装知识?——以T5模型为例
【摘要】 这篇论文探讨了大型语言模型在无需外部知识的情况下,能否通过预训练来存储和检索知识以回答开放领域的问题。作者通过微调预训练模型来回答问题,而这些模型在训练时并未提供任何额外的知识或上下文。这种方法随着模型规模的增加而表现出良好的…...

微服务的认识与拆分
微服务架构通过将应用分解为一组小的、独立的服务来实现,每个服务围绕特定业务功能构建,并能独立部署与扩展。这种架构增强了开发灵活性、提高了系统的可维护性和扩展性,使得团队可以更快地响应变化和市场需求。 目录 认识微服务 单体架构 …...

Java-servlet(三)Java-servlet-Web环境搭建(下)详细讲解利用maven和tomcat搭建Java-servlet环境
Java-servlet(三)Java-servlet-Web环境搭建(下)利用maven和tomcat搭建Java-servlet环境 前言一、配置maven阿里镜像二、利用IDEA创建maven文件创建maven文件删除src文件创建新的src模版删除example以及org文件 三、在第二个xml文件…...

Spring 构造器注入和setter注入的比较
一、比较说明 在 Spring 框架中,构造器注入(Constructor Injection)和 Setter 注入(Setter Injection)是实现依赖注入(DI)的两种主要方式。它们的核心区别在于依赖注入的时机、代码设计理念以及…...

如何选择DevOps平台?GitHub、GitLab、BitBucket、Jenkins对比与常见问题解答
本文内容来源github.com,由GitHub中国授权合作伙伴-创实信息进行翻译整理。 欢迎通过021-61210910、customershcsinfo.com联系我们,免费试用GitHub企业版。 软件是当今领先企业的核心,而开发者则是软件的核心。GitHub作为一个完整的开发者平台…...

react中的fiber和初次渲染
源码中定义了不同类型节点的枚举值 组件类型 文本节点HTML标签节点函数组件类组件等等 src/react/packages/react-reconciler/src/ReactWorkTags.js export const FunctionComponent 0; export const ClassComponent 1; export const IndeterminateComponent 2; // Befo…...

闭包+求解候选码+最小函数依赖集
一、闭包 直接上例题 简单明了 A的闭包ABC ABC的闭包ABCD ABCD的闭包ABCDE ABCDE的闭包ABCDEG 等于集合R的全集 所以A的闭包为ABCDEG AB的闭包为ABC 二、候选码 答案: 三、最小函数依赖集 求F的最小函数依赖集 去掉多余的 然后! 化为最简...