【高并发内存池】释放内存 + 申请和释放总结
高并发内存池
- 1. 释放内存
- 1.1 thread cache
- 1.2 central cache
- 1.3 page cache
- 2. 申请和释放剩余补充

点赞👍👍收藏🌟🌟关注💖💖
你的支持是对我最大的鼓励,我们一起努力吧!😃😃
1. 释放内存
1.1 thread cache
释放内存:
- 当释放内存小于256k时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push到_freelists[i]。
- 当链表的长度过长,则回收⼀部分内存对象到central cache。
//ConcurrentAlloc.h
static void ConcurrentFree(void* ptr,size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}
以什么标准来判断ThradCache当前某个桶的自由链表的长度过长了呢?
我们在给ThreadCache的桶加一个Size成员,记录当前这个桶空闲内存块的个数。如果当前这个桶空闲内存块的个数大于等于这个桶下一次找CentralCache要的一批量的内存块个数。那就把这一批量从当前桶拿到然后还给CentralCache。
其实还可以给ThreadCache一个记录它占了多大内存的成员,如果这个遍历大于2M,就从上到下遍历桶还一部分空闲内存块回去,避免一个ThreadCache占据太多内存。我们这个项目的原型考虑了更多这里的细节。我们就简单一下用个Size记录当前桶空闲内存块个数就行了。
//Common.hstatic void*& NextObj(void* obj)
{return *(void**)obj;
}class Freelist
{
public://释放内存void Push(void* obj){//头插assert(obj);NextObj(obj) = _freelist;_freelist = obj;++_size;}//申请内存void* Pop(){//头删assert(_freelist);void* obj = _freelist;_freelist = NextObj(obj);--_size;return obj;}//一次挂一批void PushRange(void* start,void* end,size_t n){NextObj(end) = _freelist;_freelist = start;_size += n;}//一次拿一批void PopRange(void*& start, void*& end, size_t n){assert(_size >= n);start = end = _freelist;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freelist = NextObj(end);NextObj(end) = nullptr;_size -= n;}//链表是否为空bool IsEmpty(){return _freelist == nullptr;}//获取当前桶获取下一批内存块的个数size_t& GetMaxSize(){return _maxSize;}//当前桶的空闲内存块的个数size_t GetSize(){return _size;}private:void* _freelist = nullptr;size_t _maxSize = 1;//记录当前桶下一次找ContraltCache一次要一批量是多少个内存对象size_t _size = 0;//当前桶空闲内存块个数
};
//ThreadCache.hclass ThreadCache
{
public://申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);// 释放对象时,链表过长时,回收内存回到中心缓存void ListTooLong(Freelist& list, size_t size);
private:Freelist _freelists[NFREELIST];
};// TLS thread local storage 线程局部存储
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
//ThreadCache.hppvoid ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freelists[index].Push(ptr);//当前桶空闲内存块个数大于等于下一次申请一批量内存块个数//就还下一批量内存块的个数给CentralCacheif (_freelists[index].GetSize() >= _freelists[index].GetMaxSize()){//从当前桶获取一批量内存块ListTooLong(_freelists[index], size);}
}void ThreadCache::ListTooLong(Freelist& list, size_t size)
{void* start = nullptr;void* end = nullptr;//获取一批量内存块对象list.PopRange(start, end, list.GetMaxSize());//将这一批内存块对象还给CentralCache对应桶下的对应Span对象CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}
1.2 central cache
释放内存:
- 当thread_cache过长或者线程销毁,则会将内存释放回central cache中的,释放回来时 --use_count。当use_count减到0时则表示所有对象都回到了span,则将span释放回page cache,page cache中会对前后相邻的空闲页进行合并。
//CentralCache.h//所有线程共享,整个进程仅有一个,所有弄成单例模上:饿汉(静态对象)
class CentralCache
{
public://获取单例对象static CentralCache* GetInstance(){return &_sInst;}// 获取一个非空的spanSpan* GetOneSpan(Spanlist& list, size_t size);// 从中心缓存获取一定数量的内存块对象给thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);// 将一定数量的内存块对象释放到对应桶下的对应span对象中void ReleaseListToSpans(void* start, size_t size);private:CentralCache(){}CentralCache(const CentralCache&) = delete;CentralCache& operator=(const CentralCache&) = delete;
private:Spanlist _spanlists[NFREELIST];static CentralCache _sInst;
};
考虑这样一个问题,ThreadCache还回来的内存块还到CentralCache对应桶中,但是对应桶可能有多个Span对象,那这些还回来的内存块对象是属于那个Span呢?
比如说目前有两个Span对象,分别管理一页,2000是Span1管理,2001是Span2管理。下面有四个内存块还回来了?假设1、2内存块是从Span1拿的,3、4是从Span2拿的。那怎么确定对应内存块是从那个Span中拿的呢?

以1、2内存块从Span1拿的为例,既然是从Span1管理2000这一页拿,这一页是划分为固定大小的小内存块你才拿的。那1、2这个内存块的地址是不是就在FA000和FA2000之间的,拿它们的地址/8KB算出的整数还是2000。

因此我们可以用unordered_map或者map建立一个页号与Span一对一的映射关系。拿到内存块的地址/8KB 看它是那一页的,然后根据页号就可以知道它是那个Span了。
这里我们使用unordered_map查找更快一些,这个哈希桶等会PageCache也要用,因此放在PageCache里。
//PageCache.h#include"Common.h"
//所有线程共享一个PageCache
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}//从PageCache第k号桶中获取一个span对象Span* NewSpan(size_t k);// 获取从对象到span的映射Span* MapObjectToSpan(void* obj);// 释放空闲span回到Pagecache,并合并相邻的spanvoid ReleaseSpanToPageCache(Span* span);private:PageCache(){}PageCache(const PageCache&) = delete;PageCache& operator=(const PageCache&) = delete;static PageCache _sInst;
private:Spanlist _spanlists[NPAGES];std::unordered_map<PAGE_ID, Span*> _idSpanMap;//记录页号和span一一对应关系
public:std::mutex _pageMtx; //整个锁
};
然后在处理一下,当CentralCache从PageCache拿到一个Span,返回之前,我们要把这个Span管理的页号与Span建立关系。
//从PageCache第k号桶中获取一个span对象
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//这里加锁递归会有死锁问题,除非用递归互斥锁,还有在外面调用这个函数之前加锁// 先检查第k个桶里面有没有spanif (!_spanlists[k].Empty()){Span* Kspan = _spanlists[k].PopFront();//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}//走到这里第k个桶没有span,那就继续往下面的桶找for (size_t i = k + 1; i < NPAGES; ++i){if (!_spanlists[i].Empty()){//将一个管理更多页的span,变成两个span,一个管理k页,一个管理i-k页Span* Ispan = _spanlists[i].PopFront();//Span* Kspan = new Span;Span* Kspan = _spanPool.New();Kspan->_pageid = Ispan->_pageid;Kspan->_n = k;Ispan->_pageid += k;Ispan->_n -= k;//将Ispan挂在对应大小的桶_spanlists[Ispan->_n].PushFront(Ispan);//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}}//走到这里说明,后面的位置都没有大页的span//那就去找堆申请一个128page的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageid = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;//span挂在对应桶下_spanlists[bigSpan->_n].PushFront(bigSpan);//重复上述过程寻找k号桶的span,一定还回一个spanreturn NewSpan(k);
}
在增加一个地址转成页号找到对应Span的函数
// 获取从对象到span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}
}
接下来CentralCache就可以把一批内存块还给PageCache了。这里也需要记住在取PageCache之前先把对应桶锁解掉。不如别的线程来对应桶上申请释放就阻塞了。
// 将一定数量的内存块对象释放到对应桶下的对应span对象中
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanlists[index]._mtx.lock();//遍历将内存块对象还给对应的span//如何知道一个内存块对象是从那个span对象中拿走的?//用内存块中的地址/8kb,得到对应的页号,根据页号走到对应的span//如何根据页号找到对应span,用unordered_map记录页号和span一一对应关系//因为PageCache等会也要用到这个哈希桶,因为哈希桶定义到PageCache中while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);//将start头插进对应span中NextObj(start) = span->_freelist;span->_freelist = start;span->_usecount--;//检查当前span中切分的内存块个数是否已经被还完了//如果还完,就将该span从CentralCache中删除,然后还给PageCache//PageCache看是否能将该span前后空闲span合并,减少内存碎片if (span->_usecount == 0){//将该span从桶中删除_spanlists[index].Erase(span);span->_freelist = nullptr;span->_prev = nullptr;span->_next = nullptr;//从CentarlCache去PageCache之前先把桶锁释放//如果不释放,万一其他线程来这个桶找span申请或者释放内存块,就阻塞住_spanlists[index]._mtx.unlock();//所有线程共享PageCache,所以先加锁PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();//回来再把对应桶锁加上_spanlists[index]._mtx.lock();}start = next;}_spanlists[index]._mtx.unlock();
}
1.3 page cache
释放内存:
- 如果central cache释放回一个span,则依次寻找span的前后page id的没有在使用的空闲span,看是否可以合并,如果合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。
假设Span管理的页是起始页是2000,一共管理5页,和它相邻的前后Span如何找到?
和它的前一个相邻的Span最后一页就是1999,后一个相邻的Span的首先就是2005。我们还是可以通过找到页号就可以找到对应的Span。

合并相邻的页,通过页号找到相邻的页看是否能合并,如果该页的Span在PageCache说明该Span还没被使用可以合并。如果在CentralCache说明该Span正在被使用不能合并。
那如何确定一个Span是否在被使用呢?能不能用Span中的_usecount==0来判断?
不能!因为有时间间隔。如果线程thread1找PageCache拿到一个Span,记住_usecount初始可是0,然后切分成一块块小内存块,在挂到CentralCache对应桶中,然后正准备从这个Span拿一批内存块,这个时候_usecount可还是0,只有真正拿到了才会++。另一个线程thread2在PageCache合并相邻的空闲的Span,如果相邻的就是thread1正准备拿的Span,你用_usecount==0判断是否被使用,那不就造成线程安全的问题了吗!!
所以不能用Span中的_usecount==0判断一个Span是否在使用。我们再给Span加一个_isuse成员来判断Span是否在使用,拿到CentralCache的Span就在使用,在PageCache的Span就没有在使用。
//Span管理一个跨度的大块内存//管理以页为单位的大快内存
struct Span
{PAGE_ID _pageid = 0;//管理一大块连续内存块的起始页的页号size_t _n = 0;//管理几页Span* _prev = nullptr;//带头双向循环链表前指针Span* _next = nullptr;//带头双向循环链表后指针size_t _usecount = 0;//记录Span对象中自由链表挂的内存块对象使用数量void* _freelist = nullptr;//自由链表挂的是Span对象一块大连续内存块按照桶位置大小切分的一块块小的内存块bool _isuse = false;//当前Span是否被使用
};
当CentralPage从PageCache获取到一个新的Span就已经被用了,增加一句代码。
// 获取一个非空的span
Span* CentralCache::GetOneSpan(Spanlist& list, size_t size)
{//遍历对应桶中是否有span或者span中是否有内存对象Span* it = list.Begin();while (it != list.End()){if (it->_freelist){return it;}else{it = it->_next;}}//当Central Cache对应桶下面没有span,那就往下一层Page Cache找,但是首先要先把对应桶锁释放//如果再来一个线程是申请内存但是没有内存锁住也没问题,但是如果这个线程是来还内存的呢?//锁住那不就还不了了,因此往下走之前先把桶锁释放list._mtx.unlock();//走到这里说明该桶中并没有span或者span中没有内存对象,Central Cache那就找到下一层Page Cache要一个span//Page Cache 是一个按桶下标映射的哈希桶,第i号桶表示这个桶下面的span管理的都是i页page//central找page要,关注的是要的span是管理k页的span,然后就去k号桶去要//PageCache的锁是一把整锁,虽然也可以是桶锁但是消耗性能//当PageCache对应桶没有span就往下面桶继续找,就涉及多个桶加锁解锁,//因此我们在最外面直接把PageCache锁住,只加锁解锁一次即可PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//在CentralCache中的span是已经被使用的spanspan->_isuse = true;//span被使用PageCache::GetInstance()->_pageMtx.unlock();//从PageCache拿上来的span是每一个线程独享的,因此切片时不需要加锁//把从PageCache拿回的span切分成size大小的一个个内存块挂在自由链表,最后再把span挂在对应的桶中//根据页号找到span管理的一大块内存的起始地址//地址用char* 方便下面地址++char* start = (char*)(span->_pageid << PAGE_SHIFT);//计算这块内存有多大size_t bytes = span->_n << PAGE_SHIFT;//结尾地址char* end = start + bytes;//使用尾插法将大内存变成大小为size的一快快小内存挂在自由链表上span->_freelist = start;start += size;void* tail = span->_freelist;while (start < end){NextObj(tail) = start;tail = start;start += size;}//自由链表最后为nullptrNextObj(tail) = nullptr;//切好span以后,需要把span挂到桶里面去的时候,再加锁list._mtx.lock();//再把span挂在对应桶list.PushFront(span);return span;
}
现在先别急着就去unordered_map去找在PageCache中相邻的Span,你现在肯定也找不到,还记得unordered_map目前记录的是什么吗?它当前只记录了在CentralCache中的Span管理的页号与Span的对应关系,也就是已经使用的Span的页号和Span的关系,根本就没有记录在PageCache中Span管理的页号SPan对应的关系。因此还要在修改一下代码。
在PageCache的Span,只需要记录它管理的首页和尾页与Span的映射关系就行了。合并我们就找相邻Span的首页和尾页就找到对应的Span了。对于在CentralCache中Span因为要被切分成一块块小内存然后才给ThreadCache用,当小内存块回来的时候,可能是这个Span中任意一页的小内块,然后/8KB,找到页号,在找到对应的SPan。因此要把Span中每一页和Span对应关系都保存。
//从PageCache第k号桶中获取一个span对象
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//这里加锁递归会有死锁问题,除非用递归互斥锁,还有在外面调用这个函数之前加锁// 先检查第k个桶里面有没有spanif (!_spanlists[k].Empty()){Span* Kspan = _spanlists[k].PopFront();//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}//走到这里第k个桶没有span,那就继续往下面的桶找for (size_t i = k + 1; i < NPAGES; ++i){if (!_spanlists[i].Empty()){//将一个管理更多页的span,变成两个span,一个管理k页,一个管理i-k页Span* Ispan = _spanlists[i].PopFront();//Span* Kspan = new Span;Span* Kspan = _spanPool.New();Kspan->_pageid = Ispan->_pageid;Kspan->_n = k;Ispan->_pageid += k;Ispan->_n -= k;//将Ispan挂在对应大小的桶_spanlists[Ispan->_n].PushFront(Ispan);//记录挂在PageCache中还未被使用的Ispan的页号和span对应关系//这里仅需记录这个span的首页和尾页与Ispan的对应关系即可,//不像返回给CentralCache的Kspan的需要把这个Kspan管理的每一页都和Kspan建立映射关系//因为合并仅需知道每个Ispan的首页和尾页就可以找到Ispan,而返回给CentralCache的Kspan,//首先需要将Kspan切成一块块小内存才行才能再给ThreadCache用,//当小内存回来/8kb可能是Kspan管理的其中某一页,才能知道该页对应span//_idSpanMap[Ispan->_pageid] = Ispan;//_idSpanMap[Ispan->_pageid + Ispan->_n - 1] = Ispan;_idSpanMap.set(Ispan->_pageid, Ispan);_idSpanMap.set(Ispan->_pageid + Ispan->_n - 1, Ispan);//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}}//走到这里说明,后面的位置都没有大页的span//那就去找堆申请一个128page的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageid = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;//span挂在对应桶下_spanlists[bigSpan->_n].PushFront(bigSpan);//重复上述过程寻找k号桶的span,一定还回一个spanreturn NewSpan(k);
}
准备工作做完了,接下来就是CentralPage还回来一个Span,看相邻的Span是否能合并,解决内存碎片的问题。

// 释放空闲span回到Pagecache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{// 如何知道相邻的span是否能合并?// 通过自己的页号找到相邻的span看是否能合并,如果该页的span在PageCache说明该span还没有被使用,可以合并// 如果在CentralCache说明该span正在被使用,不能合并// 如何知道一个span是否被使用? 是用span中的usecount是否等于0吗? 不能!!// 这里有一个空档时间,当thread1线程通过TLS找到自己threadcache申请内存块,但是没有,// 就去找CentralCache,但是CentralCache对应桶下也没有,那就只能去找PageCache了// PageCache返回给CentralCache一个span,这个span的usecount初始可是0,// CentralCache拿到后对span这一大块内存切成一块块小内存// 在挂到对应桶下,但是这时候thread2,要合并这个span,那就有问题了,thread1正准备从这span拿一批量// 但是还没有拿到,这个span的usecount可还是0,只有拿走了usecount才会++// thread2把这个span和自己span合并了,那就造成线程安全的问题!!// 因此需要给span对象加一个isuse成员记录这个span是否被使用// 如何通过页号找到相邻的页? 还是得用unordered_map记录页号合span对应关系// 但是目前的unordered_map只记录了给CentralCache已经被使用的span的页号和span对应关系// 并没有记录在PageCache的span的页号和span对应关系// 因此需要把在PageCache的span的页号和span对应关系也要记录在unordered_map中//先走前面相邻的span是否能合并,能合并就一直合while (1){PAGE_ID prevId = span->_pageid - 1;auto ret = _idSpanMap.find(prevId);// 前面的页号没有,不合并了(堆申请内存已经到了起始地址)if (ret == _idSpanMap.end()){break;}Span* prevSpan = ret->second;// 前面相邻页的span在使用,不合并了if (prevSpan->_isuse == true){break;}// 合并出超过128页的span没办法挂在桶下,不合并了if (prevSpan->_n + span->_n > NPAGES - 1){break;}// 用span合并prevSpanspan->_pageid = prevSpan->_pageid;span->_n += prevSpan->_n;// 将pevSpan从对应的桶中删除_spanlists[prevSpan->_n].Erase(prevSpan);delete prevSpan;// 这里可能有疑问,那遗留unordered_map中被合并的对应页和prevSpan之间一对一的关系难道不删除吗?// 因为prevSpan已经被删除了,在去通过已有页去找span那就是野指针了! 但其实并不用删除.// 首先被合并的页已经被span管理起来了,合并结束之后会被挂在对应桶下,并且记录该span首页和尾页与span的对应关系.// 当CentralCache要的时候,在把span切分成两个span,返回给CentralCache的Kspan每页都和Kspan重新进行映射// 留在PageCache的Ispan的首页和尾页也会和Ispan重新映射// 这样的话,以前被合并,遗留下来的页又和新得span建立了映射关系,就不会有通过页找span会有野指针的问题}//找后面相邻的span合并while (1){PAGE_ID nextId = span->_pageid + span->_n;auto ret = _idSpanMap.find(nextId);// 后面的页号没有,不合并了(堆申请内存已经到了结尾地址)if (ret == _idSpanMap.end()){break;}Span* nextSpan = ret->second;// 后面相邻页的span在使用,不合并了if (nextSpan->_isuse == true){break;}// 合并出超过128页的span没办法挂在桶下,不合并了if (nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanlists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}//合并好的span挂在对应桶下_spanlists[span->_n].PushFront(span);span->_isuse = false;//重新映射在PageCace的Span的首页和尾页与Span映射关系_idSpanMap[span->_pageid] = span;_idSpanMap[span->_pageid + span->_n - 1] = span;
}
关于释放内存就到这里了,下面我们在对细节进行优化。
2. 申请和释放剩余补充
当要的内存小于256KB,每个线程通过TLS找到自己的ThreadCache要,如果没有就找CentralCache要,在没有就找PageCache要,在没有就找堆去要。
之前我们一直没谈的是大于256KB怎么办?
其实这里分为分成两种情况,256KB/8KB=32Page,PageCache最大的桶是128Page。因此就有 大于32Page 小于等于128Page,找PageCache要。大于128Page直接找堆要。
不管是找PageCache要还是找堆要,都是按页为单位对齐的。
//Common.hclass SizeClass
{//...static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else//找PageCache或者堆按页为单位对齐{return _RoundUp(size, 1 << PAGE_SHIFT);}return -1;}
};//ConcurrentAlloc.hstatic void* ConcurrentAlloc(size_t size)
{//大于256KB/8KB=13page 小于等于128page 找PageCache要//大于128page找堆要if (size > MAX_BYTES){//找PageCache或者堆要都是以页为单位对齐size_t alignnum = SizeClass::RoundUp(size);//在PageCache那个桶size_t kpage = alignnum >> PAGE_SHIFT;//在PageCache内部处理找是否找堆要PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kpage);//这里不需要记录这个span已经被使用,因为还得时候合并的这个span相邻页的span看是否在使用PageCache::GetInstance()->_pageMtx.unlock();//得到地址返回void* ptr = (void*)(span->_pageid << PAGE_SHIFT);return ptr;}else//小于256KB通过三层缓存要{//通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);}
}
这里在把找PageCache要一个Span处理一下
//从PageCache第k号桶中获取一个span对象
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);//大于 128page找堆要if (k > NPAGES - 1){void* ptr = SystemAlloc(k);//申请一个span对象管理这块内存,释放内存的时候要对应的spanSpan* span = new Span;span->_pageid = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;_idSpanMap[span->_pageid] = span;return span;}//这里加锁递归会有死锁问题,除非用递归互斥锁,还有在外面调用这个函数之前加锁// 先检查第k个桶里面有没有spanif (!_spanlists[k].Empty()){Span* Kspan = _spanlists[k].PopFront();//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}//走到这里第k个桶没有span,那就继续往下面的桶找for (size_t i = k + 1; i < NPAGES; ++i){if (!_spanlists[i].Empty()){//将一个管理更多页的span,变成两个span,一个管理k页,一个管理i-k页Span* Ispan = _spanlists[i].PopFront();Span* Kspan = new Span;Kspan->_pageid = Ispan->_pageid;Kspan->_n = k;Ispan->_pageid += k;Ispan->_n -= k;//将Ispan挂在对应大小的桶_spanlists[Ispan->_n].PushFront(Ispan);//记录挂在PageCache中还未被使用的Ispan的页号和span对应关系//这里仅需记录这个span的首页和尾页与Ispan的对应关系即可,//不像返回给CentralCache的Kspan的需要把这个Kspan管理的每一页都和Kspan建立映射关系//因为合并仅需知道每个Ispan的首页和尾页就可以找到Ispan,而返回给CentralCache的Kspan,//首先需要将Kspan切成一块块小内存才行才能再给ThreadCache用,//当小内存回来/8kb可能是Kspan管理的其中某一页,才能知道该页对应span_idSpanMap[Ispan->_pageid] = Ispan;_idSpanMap[Ispan->_pageid + Ispan->_n - 1] = Ispan;//将Kspan给CentralCache之前,先将页号和span对应关系记录for (size_t i = 0; i < Kspan->_n; ++i){_idSpanMap[Kspan->_pageid + i] = Kspan;}//将管理k页的span给Central Cachereturn Kspan;}}//走到这里说明,后面的位置都没有大页的span//那就去找堆申请一个128page的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageid = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;//span挂在对应桶下_spanlists[bigSpan->_n].PushFront(bigSpan);//重复上述过程寻找k号桶的span,一定还回一个spanreturn NewSpan(k);
}
释放也是一样,小于256KB的通过TLS找自己的ThreadCache释放,大于32Page小于等于128Page还给PageCache,大于128Page还直接返给堆。
static void ConcurrentFree(void* ptr,size_t size)
{//大于32page小于等于128page直接还给PageCache,//大于128page直接还给堆if (size > MAX_BYTES){//根据地址找转换为对应的页号,通过页号找到对应的span,在找到对应内存大小Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}
相关文章:
【高并发内存池】释放内存 + 申请和释放总结
高并发内存池 1. 释放内存1.1 thread cache1.2 central cache1.3 page cache 2. 申请和释放剩余补充 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃&#x…...

自然语言处理:最大期望值算法
介绍 大家好,博主又来给大家分享知识了,今天给大家分享的内容是自然语言处理中的最大期望值算法。那么什么是最大期望值算法呢? 最大期望值算法,英文简称为EM算法,它的核心思想非常巧妙。它把求解模型参数的过程分成…...

Python绘制数据分析中经典的图形--列线图
Python绘制数据分析中经典的图形–列线图 列线图是数据分析中的经典图形,通过背后精妙的算法设计,展示线性模型(logistic regression 和Cox)中各个变量对于预测结果的总体贡献(线段长短),另外&…...

11. 盛最多水的容器(力扣)
11. 盛最多水的容器 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不…...
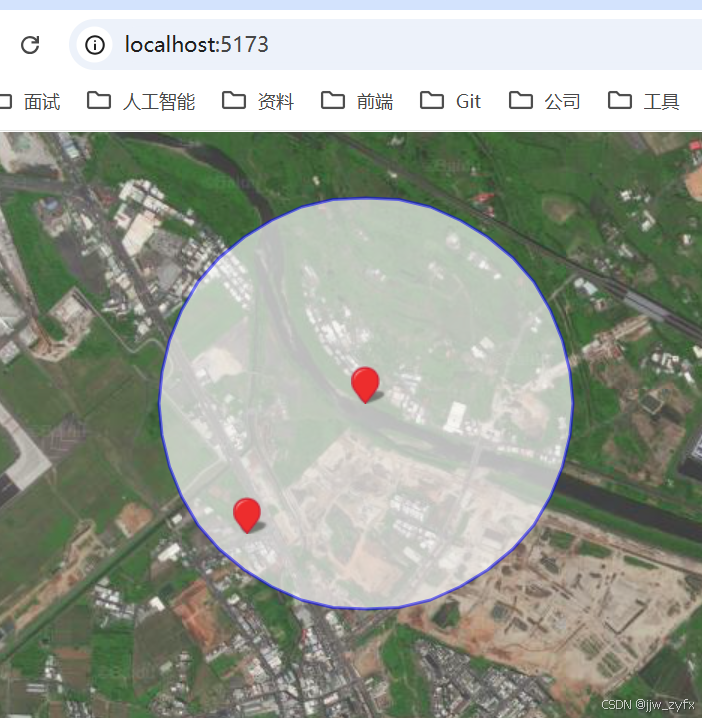
vue3 vite或者vue2 百度地图(卫星图)离线使用详细讲解
1、在Windows上下载瓦片,使用的工具为: 全能电子地图下载器3.0最新版(推荐) 下载后解压,然后进入目录"全能电子地图下载器3.0最新版(推荐)\全能电子地图下载器3.0\MapTileDownloader" 在这个目录…...

Docker常用命令清单
一、镜像管理 拉取镜像 docker pull [镜像名]:[标签] 示例:docker pull nginx:latest (记忆:pull拉取,类似git拉取代码) 构建镜像 docker build -t [镜像名]:[标签] . 示例:docker build -t myapp:v1 . &a…...

大语言模型从理论到实践(第二版)-学习笔记(绪论)
大语言模型的基本概念 1.理解语言是人工智能算法获取知识的前提 2.语言模型的目标就是对自然语言的概率分布建模 3.词汇表 V 上的语言模型,由函数 P(w1w2 wm) 表示,可以形式化地构建为词序列 w1w2 wm 的概率分布,表示词序列 w1w2 wm…...

Unity 通用UI界面逻辑总结
概述 在游戏开发中,常常会遇到一些通用的界面逻辑,它不论在什么类型的游戏中都会出现。为了避免重复造轮子,本文总结并提供了一些常用UI界面的实现逻辑。希望可以帮助大家快速开发通用界面模块,也可以在次基础上进行扩展修改&…...
)
入门到入土,Java学习day15(常用API下)
group存数据 public String[] matches(String regex)判断字符串是否满足正则表达式的规则 public String replaceAll(String regex,String newStr)按照正则表达式的规则进行替换 public String[] split(String regex)按照正则表达式的规则切割字符串 通常是创建网页对象&am…...

Navigation的进阶知识与拦截器配置
Navigation的进阶知识与拦截器配置 写的不是很详细,后续有时间会补充,建议参考官方文档食用 1.如何配置路由信息 1.1 创建工程结构 src/main/ets ├── pages │ └── navigation │ ├── views │ │ ├── Mine.ets //…...

基于大模型的小脑扁桃体下疝畸形全流程预测与诊疗方案研究报告
目录 一、引言 1.1 研究背景与目的 1.2 研究意义 二、小脑扁桃体下疝畸形概述 2.1 定义与分类 2.2 发病机制与病因 2.3 临床表现 2.4 诊断方法 三、大模型在小脑扁桃体下疝畸形预测中的应用 3.1 大模型介绍 3.2 数据收集与处理 3.3 模型训练与验证 四、术前预测与…...
Java数据结构第二十一期:解构排序算法的艺术与科学(三)
专栏:Java数据结构秘籍 个人主页:手握风云 目录 一、常见排序算法的实现 1.1. 归并排序 二、排序算法复杂度及稳定性分析 一、常见排序算法的实现 1.1. 归并排序 归并排序是建⽴在归并操作上的⼀种有效的排序算法,该算法是采⽤分治法的一个⾮常典型的…...

go切片定义和初始化
1.简介 切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制。切片的使用和数组类似,遍历切片、访问切片的元素和切片的长度都一样。。切片的长度是可以变化的,因此切片是一个可以动态变化的数…...

使用 Docker 部署 Nginx,配置后端 API 轮询与多个子域名前端应用
使用 Docker 部署 Nginx,配置后端 API 轮询与多个子域名前端应用 在这篇博客中,我们将介绍如何通过 Docker 部署 Nginx 服务器,并配置 多个后端 API 的轮询负载均衡,同时通过 子域名 部署多个不同的前端应用。Nginx 将作为反向代…...

【NLP 39、激活函数 ⑤ Swish激活函数】
我的孤独原本是座荒岛,直到你称成潮汐,原来爱是让个体失序的永恒运动 ——25.2.25 Swish激活函数是一种近年来在深度学习中广泛应用的激活函数,由Google Brain团队在2017年提出。其核心设计结合了Sigmoid门控机制和线性输入的乘积,…...

C语言经典案例-菜鸟经典案例
1.输入某年某月某日,判断这一天是这一年的第几天? //输入某年某月某日,判断这一天是这一年的第几天? #include <stdio.h>int isLeapYear(int year) {// 闰年的判断规则:能被4整除且(不能被100整除或…...

南开提出1Prompt1Story,无需训练,可通过单个连接提示实现一致的文本到图像生成。
(1Prompt1Story)是一种无训练的文本到图像生成方法,通过整合多个提示为一个长句子,并结合奇异值重加权(SVR)和身份保持交叉注意力(IPCA)技术,解决了生成图像中身份不一致…...

STM32驱动OLED屏幕全解析:从原理到温度显示实战(上) | 零基础入门STM32第五十三步
主题内容教学目的/扩展视频OLED显示屏重点课程电路原理,手册分析,驱动程序。初始化,清屏,ASCII字库,显示分区。调用显示函数。做带有加入图形和汉字显示的RTC时钟界面。讲字库的设计原理。 师从洋桃电子,杜…...

MySQL语法总结
本篇博客说明: !!!.注意此系列都用的是MySQL语句,和SQLServer,PostgreSQL有些细节上的差别!!! 1.每个操作都是先展示出语法格式 2.然后是具体例子 3.本篇注脚与文本顺讯息…...

从预测到控制:电力RK3568边缘计算机在电网调度中的全面应用
在智能电网的快速发展中,电力Ubuntu工控机(简称“电力工控机”)作为核心设备,扮演着不可或缺的角色。特别是在智能电网调度场景中,电力工控机的高效、稳定和智能化特性,为电网的稳定运行和高效管理提供了强…...

Spring Batch 概览
Spring Batch 是什么? Spring Batch 是 Spring 生态系统中的一个轻量级批处理框架,专门用于处理大规模数据任务。它特别适合企业级应用中需要批量处理数据的场景,比如数据迁移、报表生成、ETL(Extract-Transform-Load)…...

day-106 统计放置房子的方式数
思路 动态规划:因为中间有街道隔开,所以只需计算一边街道的排列方式,最后计算平方即可 解题过程 动态转换方程:f[i]f[i-1]f[i-2] Code class Solution {int num 1000000007;public int countHousePlacements(int n) {int arr[…...

PostgreSQL安装和mcp PostgreSQL
文章目录 一. 安装之后修改权限并登录1. 确保当前用户具有sudo权限2. 修改/etc/postgresql/<版本号>/main/pg_hba.conf配置文件为trust,可以免密登录3. 进行免密登录4. 添加root用户和修改postgres用户密码1. postgres用户密码2. 添加root用户3. 为root用户设…...
——桌面问题)
解决电脑问题(10)——桌面问题
电脑桌面出现问题的情况多样,以下是一些常见问题及解决方法: 桌面图标问题 图标显示异常:如果图标模糊、失真或显示为未知图标,可能是图标缓存出现问题。在 Windows 系统中,可通过在任务管理器中重启 “Windows 资源管…...

LPZero: Language Model Zero-cost Proxy Search from Zero(未更新完预览版本)
LPZero代码 摘要 神经架构搜索 (NAS) 有助于自动执行有效的神经网络搜索,同时需要大量的计算资源,尤其是对于语言模型。零样本 NAS 利用零成本 (ZC) 代理来估计模型性能,从而显着降低计算需求。然而,现有的 ZC 代理严重依赖于深…...

字典树运用
字典树运用 字典树LC208 创建字典树0-1字典树 字典树 字典树又叫 前缀树, 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。 LC208 创建字典树 这是一个字符串字典树…...

RReadWriteLock读写锁应用场景
背景 操作涉及一批数据,如订单,可能存在多个场景下操作,先使用读锁,从redis缓存中获取操作中数据 比如 关闭账单, 发起调账, 线下结算, 合并支付 先判断当前操作的数据,是否在…...

26.卷1的答案
1.已知2010年小明的生日在8月28日——周六 ,从2011到2020,有几次生日在周末? 做法:一个一个算下去,注意,平年365天,闰年366天,一共2次。 2.前序:ABDGKEHCFIJ,中序&…...

0087.springboot325基于Java的企业OA管理系统的设计与实现+论文
一、系统说明 基于springbootvue的企业OA管理系统,系统功能齐全, 代码简洁易懂,适合小白学编程。 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数…...

Spring Boot 3 整合 MinIO 实现分布式文件存储
引言 文件存储已成为一个做任何应用都不可回避的需求。传统的单机文件存储方案在面对大规模数据和高并发访问时往往力不从心,而分布式文件存储系统则提供了更好的解决方案。本篇文章我将基于Spring Boot 3 为大家讲解如何基于MinIO来实现分布式文件存储。 分布式存…...