Hive-优化(语法优化篇)
列裁剪与分区裁剪
在生产环境中,会面临列很多或者数据量很大时,如果使用select * 或者不指定分区进行全列或者全表扫描时效率很低。Hive在读取数据时,可以只读取查询中所需要的列,忽视其他的列,这样做可以节省读取开销(中间表存储开销和数据整合开销)
1.列裁剪:在查询时只读取需要的列。避免select *
2.分区裁剪:在查询中只读取需要的分区。
遵循一个原则:尽量少的读入数据,尽早地数据收敛!
分组聚合优化
Map端聚合
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,在Hive的Map阶段开启预聚合,先在Map阶段预聚合,然后在Reduce阶段进行全局的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
通俗理解:假设有张8000w数据表,聚合后30组数据,有10个map,若是没有开启分组聚合,则会map将8000w条数据传给reduce,开启分组聚合后,就会每个map先进行分组,10个map各有30组,再将这30*10组数据从map传给reduce,这样效率就会大大增加
map-side 聚合相关的参数如下:
|
|
默认为开启状态

|
|
默认为0.5和10w条
(会先从大的数据表内,先抽取10w数据进行检测,判断看(分组后的数据)/10w是否在0.5以下,若是则会启用map的分组聚合)

|
|
优化案例
示例SQL
|
|
开启分组聚合后,执行时间26s左右 application_1716866155638_175450


关闭分组聚合后,执行时间在60s左右,效率提升了34s application_1716866155638_175451


由上图的详细执行过程分析可知,开启map聚合后,map输出--reduce接受的数据是340,而关闭map分组聚合后,map数据--reduce接受的数据是8000w条,传输时间大大影响
大致的运行前后的步骤对比:

Count Distinct 的优化
在Hive中,DISTINCT关键字用于对查询结果进行去重,以返回唯一的值。其主要作用是消除查询结果中的重复记录,使得返回的结果集中每个值只出现一次。
具体而言,当你在Hive中使用SELECT DISTINCT时,系统会对指定的列或表达式进行去重操作。尽管Hive中的DISTINCT关键字对于去重查询是非常有用的,但在某些情况下可能存在一些缺点:性能开销、数据倾斜、内存需求等。
group by 操作的具体实现原理。

1.map阶段,将group by后的字段组合作为一个key,如果group by单个字段,那么key就一个。将group by之后要进行的聚合操作字段作为值,如果要进行count,则value是赋1;如要sum另一个字段,那么value就是该字段。
2.shuffle阶段,按照key的不同分发到不同的reducer。注意此时可能因为key分布不均匀而出现数据倾斜的问题。这个问题是我们处理数据倾斜比较常规的查找原因的方法之一,也是我们解决数据倾斜的处理阶段。(当执行过程中,出现其他任务都已完成,持续等待一个reudce过程的时候,就看出现了数据倾斜问题)
3.reduce阶段,如果是count将相同key的值累加,如果是其他操作,按需要的聚合操作,得到结果。
distinct 的具体实现,当执行Distinct操作时,Hive会将操作转化为一个MapReduce作业,并按照指定的列进行分组。在Map阶段,每个Mapper会读取输入数据,并将指定的列作为输出的key,然后,通过Shuffle过程将具有相同key的数据发送到同一个Reducer中。

当distinct一个字段时,这里会将group by的字段和distinct的字段组合在一起作为map输出的key,value设置为1,同时将group by的字段定为分区键,这一步非常重要,这样就可以将GroupBy字段作为reduce的key,在reduce阶段,利用mapreduce的排序,输入天然就是按照组合key排好序的。根据分区键将记录分发到reduce端后,按顺序取出组合键中的distinct字段,这时distinct字段也是排好序的。依次遍历distinct字段,每找到一个不同值,计数器就自增1,即可得到count distinct结果。
count(distinct)全局合操作的时候,即使我们设定了reduce task的具体个数,例如set mapred.reduce.tasks=100;hive最终也只会启动一个reducer。这就造成了所有map端传来的数据都在一个tasks中执行,这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得这个操作成为整个作业的IO和运算瓶颈。
针对上述说的问题,我们可以修改对应的sql来进行优化, count+group by 或者sum+group by的方案来优化,在第一阶段选出全部的非重复的字段id,在第二阶段再对这些已消重的id进行计数
重到细粒度的(日),再聚合到粗粒度(省份)
(目前测试结果不能完全验证如上理论,暂放,确定后再更新)
| -- count(distinct) select count(distinct province_id) from ds_hive.ch12_order_detail_orc ; |
| -- 优化版 count + group by
|

第一阶段我们可以通过增大Reduce的并发数,并发处理Map输出。在第二阶段,由于id已经消重,因此COUNT(*)操作在Map阶段不需要输出原id数据,只输出一个合并后的计数即可。这样即使第二阶段Hive强制指定一个Reduce Task的时候,极少量的Map输出数据也不会使单一的Reduce Task成为瓶颈。
其实在实际运行时,Hive还对这两阶段的作业做了额外的优化。它将第二个MapReduce作业Map中的Count过程移到了第一个作业的Reduce阶段。这样在第一阶Reduce就可以输出计数值,而不是消重的全部id。这一优化大幅地减少了第一个作业的Reduce输出IO以及第二个作业Map的输入数据量。最终在同样的运行环境下优化后的语句可以说是大大提升了执行效率。
Join优化
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明:
Common Join (完整进行map-reduce阶段)
Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。

如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。
整个过程包含Map、Shuffle、Reduce阶段。
(1)Map阶段
Step1: 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Step2: Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
Step3: 按照key进行排序。
(2)Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中。
(3)Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
举个例子:
|
|
执行计划如下,完整的common join 会完整的经过map-reduce阶段

执行过程如下:

JOIN操作涉及合并两个或多个表的数据,以便通过共同的列值将它们关联起来。这样的关联操作在处理大规模数据时可能会面临一些性能挑战,因此有必要进行优化。
性能开销: JOIN操作通常涉及将分布在不同节点上的数据进行合并。在传统的MapReduce执行环境中,这意味着需要进行数据的分发、排序和聚合操作,这些操作都会带来较大的性能开销。
Shuffle开销: 在传统的MapReduce中,JOIN操作的Shuffle阶段涉及将相同键的数据合并到一起。这个过程需要大量的网络通信和数据传输,尤其是当数据分布不均匀时。
内存消耗: 处理大规模数据的JOIN操作可能需要大量的内存,特别是在进行排序和合并时。这可能导致内存不足的问题,进而影响性能。
复杂度: JOIN操作可能涉及复杂的计算,特别是在关联多个表或在多列上进行关联时。这增加了查询的复杂性,可能导致较长的执行时间。
Map Join (大表join小表)
Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。因为只经map+map阶段,减少了shuffle的处理,reduce的读取和处理过程,从而进行性能优化。若某join操作满足要求,则:
第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至每个执行任务的NodeManager节点本地磁盘)。
第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。

Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另外一种是Hive优化器根据参与join表的数据量大小,自动触发。
1)Hint提示
用户可通过如下方式,指定通过map join算法,并且将作为map join中的小表。这种方式已经过时,不推荐使用。
|
|
2)自动触发
Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。
之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
但有些Common Join任务所需的表大小,在SQL的编译阶段是未知的(例如对子查询进行join操作),所以这种Common Join任务是否能转换成Map Join任务在编译阶是无法确定的。
针对这种情况,Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。最终具体采用哪个计划,是在运行时决定的。大致思路如下图所示:

Map join自动转换的具体判断逻辑如下图所示

参数如下:
|
|
3)示例SQL
|
explain |
参数设置为false(未优化):既有map,又有reduce,然后join是在reduce阶段

执行完时间 161s

参数设置为true(优化):第一个map加载本地文件,第二个map进行join

执行时间35s

结论:未开启mapjoin,进行commonjoin,执行时间161s,使用mapjoin,执行时间35s,执行效率大大提升
接着我们再来测试另外一个参数。调整hive.auto.convert.join.noconditionaltask.size参数(小于此设置的表会识别为小表),使其小于t3 表 的大小
|
explain
|
第一个sql,因为设置了.noconditionaltask.size=252300,小于表的大小,最终选择了commonjoin执行,第二遍我们关闭有条件执行,由于smalltable.filesize大于小表只有commonjoin,这时候调大set hive.mapjoin.smalltable.filesize=379000002;让其小表大于smalltable.filesize,这时候最终会选择mapjoin。
Bucket Map Join(大表join大表)
两张表都相对较大,若采用普通的Map Join算法,则Map端需要较多的内存来缓存数据,当然可以选择为Map段分配更多的内存,来保证任务运行成功。但是,Map端的内存不可能无上限的分配,所以当参与Join的表数据量均过大时,就可以考虑采用Bucket Map Join算法。Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
Bucket Map Join的核心思想是:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。其原理如图所示:

优化条件:
1) set hive.optimize.bucketmapjoin = true;
2) 一个表的bucket数是另一个表bucket数的整数倍
3) bucket列 == join列
4) 必须是应用在map join的场景中
Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用。
1)Hint提示
|
|
2)相关参数
|
|
Sort Merge Bucket Map Join(大表join大表)
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
Hash Join和Sort Merge Join均为关系型数据库中常见的Join实现算法。Hash Join的原理相对简单,就是对参与join的一张表构建hash table,然后扫描另外一张表,然后进行逐行匹配。Sort Merge Join需要在两张按照关联字段排好序的表中进行,其原理如图所示:

Hive中的SMB Map Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
Sort Merge Bucket Map Join有两种触发方式,包括Hint提示和自动转换。Hint提示已过时,不推荐使用。下面是自动转换的相关参数:
|
|
两张表都相对较大,除了可以考虑采用Bucket Map Join算法,还可以考虑SMB Join。相较于Bucket Map Join,SMB Map Join对分桶大小是没有要求的。
谓词下推
谓词下推(predicate pushdown)是指,尽量将过滤操作前移,以减少后续计算步骤的数据量。数仓实际开发中经常会涉及到多表关联,这个时候就会涉及到on与where的使用。一般在面试的时候会提问:条件写在where里和写在on有什么区别?
相关参数为:
|
|
示例SQL语句
|
|
关闭谓词下推优化
|
|
通过执行计划可以看到,当我们把谓词下推关闭以后,数据是所有数据关联以后才进行过滤的,这样如果量表数据量大,就大大降低了我们的执行效率

开启谓词下推优化
|
|

通过执行计划可以看出,过滤操作位于执行计划中的join操作之前。大大减少了关联的数据量。对整体执行效率有很大提升。
开启谓词执行做关联,优化一下SQL
|
|

通过执行计划可以看出,t1和t2过滤操作都位于执行计划中的join操作之前,对俩个表都是先过滤再关联,效率更一步提升。
当我们使用左关联的时候:1.所有条件写在where中,只有左边的条件先过滤;2.当所有条件写在 on 里面只有右边的条件起作用,3.为了可以让条件都起作用,就把左表条件写在where里,右边条件写在 on 里,两者都先过滤。
结论:
- 对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别,join谓词下推都生效,Full outer Join都不生效;
- 对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
- 对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;

合理选择排序
order by
全局排序,只走一个reducer,当表数据量较大时容易计算不出来,性能不佳慎用,在严格模式下需要加limit
sort by
局部排序,即保证单个reduce内结果有序,但没有全局排序的能力。
distribute by
按照指定的字段把数据划分输出到不同的reducer中,是控制数据如何从map端输出到reduce端,hive会根据distribute by后面的字段和对应reducer的个数进行hash分发
cluster by
拥有distrubute by的能力,同时也拥有sort by的能力,所以可以理解cluster by是 distrubute by+sort by
实例代码优化:
-- 优化前
select
id
,count(*) as cnt
from ds_hive.ch12_order_detail_orc t1
group by id
order by cnt
limit 100
;
执行时间109.9s

-- 优化后
select
id
,cnt
from
(select id ,count(*) as cntfrom ds_hive.ch12_order_detail_orc t1group by id
) t1
distribute by cnt
sort by id
limit 100
;执行时间69s

通过优化前后时间对比,可以看到优化效果
注意实际企业运维可以通过参数 set hive.mapred.mode=strict 来设置严格模式,这个时候使用 orderby 全局排序必须加 limit;建议如果不是非要全局有序的话,局部有序的话建议使用 sortby,它会视情况启动多个 reducer 进行排序,并且保证每个 reducer 内局部有序。为了控制map 端数据分配到 reducer 的 key,往往还要配合 distribute by 一同使用。如果不加 distribute by 的话,map 端数据就会随机分配到 reducer。
相关文章:
Hive-优化(语法优化篇)
列裁剪与分区裁剪 在生产环境中,会面临列很多或者数据量很大时,如果使用select * 或者不指定分区进行全列或者全表扫描时效率很低。Hive在读取数据时,可以只读取查询中所需要的列,忽视其他的列,这样做可以节省读取开销…...
中的网络层简介)
物联网(Internet of Things, IoT)中的网络层简介
物联网(Internet of Things, IoT)中的网络层是物联网架构中的关键组成部分,负责设备之间的数据传输和通信。网络层的主要任务是将感知层(传感器、设备等)收集到的数据通过互联网或其他通信网络传输到应用层(数据处理和分析平台)。以下是物联网网络层的知识简介: 1. 物联…...

C++ 提供了多种数据类型组合方式
C 提供了多种数据类型组合方式,允许开发者将基本类型组合成更复杂的数据结构,以满足不同场景的需求。以下是主要的组合方式及其示例: 1. 数组(Array) 同类型元素的集合,可以是静态或动态。 int staticArr…...

八字排盘宝 2025.1.8 | 多模式排盘工具,精准解析八字信息,轻量易用
八字排盘宝是一款轻量高效的排盘工具,实现多模式排盘功能,界面简洁易用,适合命理爱好者和专业人士。支持多种排盘方式,精准解析八字信息,提供快速、便捷的命理分析体验,是日常排盘和命理学习的得力助手。 …...

MySQL面试篇——性能优化
MySQL性能优化 在MySQL中,如何定位慢查询 慢查询表象:页面加载过慢、接口压测响应时间过长(超过1s)。造成慢查询的原因通常有:聚合查询、多表查询、表数据量过大查询、深度分页查询 方案一:开源工具 调试工…...

c#财务软件专业版企业会计做账软件财务管理系统软件
本软件为绍兴客户开发的仿某碟财务软件专业版 功能:可以按会计科目做账录入会计凭证、结转损益、期末结账、拉资产负债表 github下载:https://github.com/oyangxizhe/financial.git...

常见 JVM 工具介绍
1. jps(Java Virtual Machine Process Status Tool) 功能:列出当前用户的所有 Java 进程及其 PID。 常用场景:快速定位目标 Java 应用的进程 ID。 常用命令: bash复制 jps -l # 显示主类全名 jps -v # 显示 JVM 启…...

【含文档+PPT+源码】Python爬虫人口老龄化大数据分析平台的设计与实现
项目介绍 本课程演示的是一款Python爬虫人口老龄化大数据分析平台的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Python学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本…...

生成对抗网络(GAN)原理与应用
目录 一、引言 二、GAN的基本原理 (一)生成器(Generator)的工作机制 (二)判别器(Discriminator)的工作机制 (三)对抗训练的过程 三、GAN在AIGC生图中的应…...

Linux安装升级docker
Linux 安装升级docker Linux 安装升级docker背景升级停止docker服务备份原docker数据目录移除旧版本docker安装docker ce恢复数据目录启动docker参考 安装找到docker官网找到docker文档删除旧版本docker配置docker yum源参考官网继续安装docker设置开机自启配置加速测试 Linux …...

clickhouse源码分析
《ClickHouse源码分析》 当我们谈论数据库时,ClickHouse是一个不容忽视的名字。它是一个用于联机分析处理(OLAP)的列式数据库管理系统(DBMS),以其快速的数据查询能力而闻名。对于想要深入了解这个高效工具…...

IDEA 基础配置: maven配置 | 服务窗口配置
文章目录 IDEA版本与MAVEN版本对应关系maven配置镜像源插件idea打开服务工具窗口IDEA中的一些常见问题及其解决方案IDEA版本与MAVEN版本对应关系 查找发布时间在IDEA版本之前的dea2021可以使用maven3.8以及以前的版本 比如我是idea2021.2.2 ,需要将 maven 退到 apache-maven-3.…...

【redis】type命令和定时器的两种实现方式(优先级队列、时间轮)
type——返回 key 对应的数据类型 此处 Redis 所有的 key 都是 string,但是 key 对应的 value 可能会存在多种类型 none —— key 不存在string ——字符串list ——列表set ——集合zset ——有序集合hash ——哈希表stream ——Redis 作为消息队列的时候&#x…...

高并发下订单库存防止超卖策略
文章目录 什么是超卖问题?推荐策略:Redis原子操作(Redis incr)乐观锁lua脚本利用Redis increment 的原子操作,保证库存数安全update使用乐观锁LUA脚本保持库存原子性 什么是超卖问题? 在并发的场景下,比如商城售卖商品…...

task01
1:大模型能够专业的回答各种问题,并且擅长文本处理,代码编写,可以减少一部分人类的工作。 本节学习了大模型提示词的三要素,角色,背景,输出样式,在kimi上我复现了教材的任务…...

【Kotlin】Kotlin基础笔记
一、数据类型 1.1 变量声明与类型推导 变量声明 使用 val 声明不可变变量(相当于常量);使用 var 声明可变变量。 val a 10 // 类型自动推断为 Int,不可变 var b: Double 5.0 // 显示声明为 Double,可变变量…...

DeepSeek教我写词典爬虫获取单词的音标和拼写
Python在爬虫领域展现出了卓越的功能性,不仅能够高效地抓取目标数据,还能便捷地将数据存储至本地。在众多Python爬虫应用中,词典数据的爬取尤为常见。接下来,我们将以dict.cn为例,详细演示如何编写一个用于爬取词典数据…...

祛魅 Manus ,从 0 到 1 开源实现
背景介绍 Manus 是最近一个现象级的大模型 Agent 工具,自从发布以来,被传出各种神乎其神的故事,自媒体又开始炒作人类大量失业的鬼故事,Manus 体验码也被炒作为 10w 的高价。 之后又出现反转,被爆出实际体验效果不佳…...

C++入门——输入输出、缺省参数
C入门——输入输出、缺省参数 一、C标准库——命名空间 std C标准库std是一个命名空间,全称为"standard",其中包括标准模板库(STL),输入输出系统,文件系统库,智能指针与内存管理&am…...

Spring Boot应用开发:从零到生产级实战指南
Spring Boot应用开发:从零到生产级实战指南 Spring Boot应用开发:从零到生产级实战指南一、Spring Boot的核心价值二、快速构建第一个Spring Boot应用2.1 使用Spring Initializr初始化项目2.2 项目结构解析2.3 编写第一个REST接口 三、Spring Boot的核心…...

【2025前端高频面试题——系列一之MVC和MVVM】
前端高频面试题——系列一之MVC和MVVM 前言一、MVC的基本逻辑二、MVVM的基本逻辑总结 提示:片尾总结了要点,硬背的话直接跳到最后 前言 相信持续关注我文章的小伙伴知道我之前就MVC和MVVM做过较为详细的讲解,但是我发现,他依旧是…...

基于遗传算法的IEEE33节点配电网重构程序
一、配电网重构原理 配电网重构(Distribution Network Reconfiguration, DNR)是一项优化操作,旨在通过改变配电网中的开关状态,优化电力系统的运行状态,以达到降低网损、均衡负载、改善电压质量等目标。配电网重构的核…...

HTTP协议与Web开发
🌐 HTTP协议与Web开发完全指南:从原理到实战 一、HTTP协议是什么? HTTP(超文本传输协议) 是互联网上应用最广泛的网络协议,作为Web开发的基石,它具有以下核心特性: 无状态协议&am…...

容器编排革命:从 Docker Run 到 Docker Compose 的进化之路20250309
容器编排革命:从 Docker Run 到 Docker Compose 的进化之路 一、容器化部署的范式转变 在 Docker 生态系统的演进中,容器编排正从“手动操作”走向“自动化管理”。根据 Docker 官方 2023 年开发者调查报告,78% 的开发者已采用 Docker Compo…...

【高并发内存池】释放内存 + 申请和释放总结
高并发内存池 1. 释放内存1.1 thread cache1.2 central cache1.3 page cache 2. 申请和释放剩余补充 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃&#x…...

自然语言处理:最大期望值算法
介绍 大家好,博主又来给大家分享知识了,今天给大家分享的内容是自然语言处理中的最大期望值算法。那么什么是最大期望值算法呢? 最大期望值算法,英文简称为EM算法,它的核心思想非常巧妙。它把求解模型参数的过程分成…...

Python绘制数据分析中经典的图形--列线图
Python绘制数据分析中经典的图形–列线图 列线图是数据分析中的经典图形,通过背后精妙的算法设计,展示线性模型(logistic regression 和Cox)中各个变量对于预测结果的总体贡献(线段长短),另外&…...

11. 盛最多水的容器(力扣)
11. 盛最多水的容器 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不…...
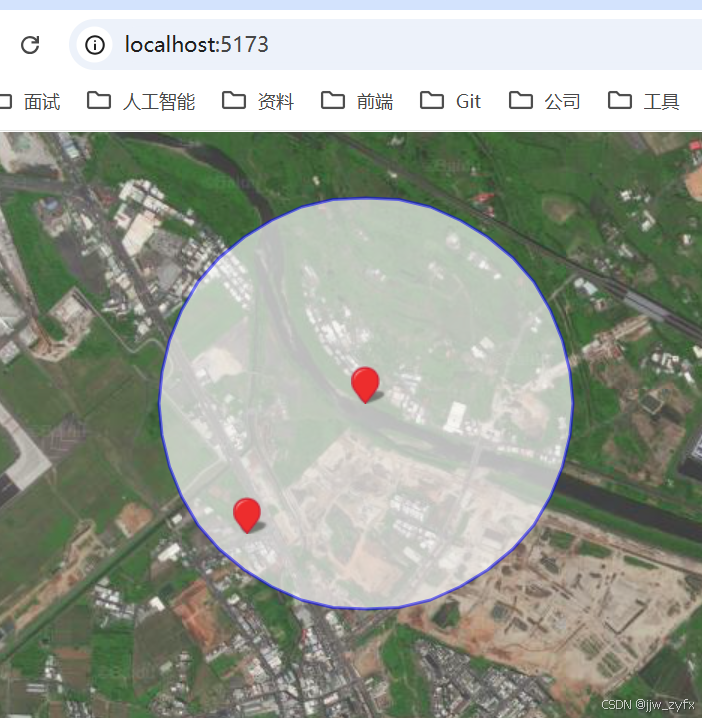
vue3 vite或者vue2 百度地图(卫星图)离线使用详细讲解
1、在Windows上下载瓦片,使用的工具为: 全能电子地图下载器3.0最新版(推荐) 下载后解压,然后进入目录"全能电子地图下载器3.0最新版(推荐)\全能电子地图下载器3.0\MapTileDownloader" 在这个目录…...

Docker常用命令清单
一、镜像管理 拉取镜像 docker pull [镜像名]:[标签] 示例:docker pull nginx:latest (记忆:pull拉取,类似git拉取代码) 构建镜像 docker build -t [镜像名]:[标签] . 示例:docker build -t myapp:v1 . &a…...