c++的基础排序算法
一、快速排序
1. 选择基准值(Pivot)
- 作用 :从数组中选择一个元素作为基准(Pivot),用于划分数组。
- 常见选择方式 :
- 固定选择最后一个元素(如示例代码)。
- 随机选择(优化最坏情况)。
- 选择中间元素或“三数取中”(避免极端情况)。
- 示例 :对数组
[10, 7, 8, 9, 1, 5],选择最后一个元素5作为基准。
2. 分区操作(Partition)
- 目标 :将数组分为两部分,使得:
- 左半部分所有元素 ≤ 基准值。
- 右半部分所有元素 > 基准值。
- 具体步骤 :
- 初始化两个指针:
i:标记小于基准的边界(初始为low-1)。j:遍历数组的指针(从low到high-1)。
- 遍历数组:
- 如果
arr[j] ≤ pivot,则i++,并交换arr[i]和arr[j]。 - 否则,不做操作,继续移动
j。
- 如果
- 最后,将基准值交换到正确位置(
i+1)。
- 初始化两个指针:
- 示例 :
- 初始数组:
[10, 7, 8, 9, 1, 5](基准为5)。 - 分区后:
[1, 5, 8, 9, 7, 10](基准位置为索引1)。
- 初始数组:
3. 递归排序子数组
- 分治策略 :
- 对左半部分(
low到pivotIndex-1)递归调用快速排序。 - 对右半部分(
pivotIndex+1到high)递归调用快速排序。
- 对左半部分(
- 终止条件 :当子数组长度 ≤1 时,无需排序(递归结束)。
- 示例 :
- 左子数组
[1](已有序)。 - 右子数组
[8, 9, 7, 10],继续递归分区。
- 左子数组
4. 代码实现
#include <algorithm> // 提供 std::swap 函数
#include <cstdlib> // 提供 rand() 和 srand()
#include <ctime> // 提供 time() 函数用于初始化随机数种子
#include <iostream> // 提供输入输出功能
#include <vector> // 提供动态数组 vectorusing namespace std;// 分区函数:将数组划分为两部分,并返回基准值的最终位置
int partition(vector<int>& nums, int low, int high)
{// 随机选择一个索引作为基准值,并将其与最后一个元素交换int index = low + (rand() % (high - low + 1)); // 随机选择 [low, high] 范围内的索引swap(nums[index], nums[high]); // 将基准值放到末尾int pivot = nums[high]; // 基准值为当前区间最后一个元素int i = low - 1; // i 表示小于基准值的边界// 遍历区间 [low, high-1],将小于基准值的元素放到左边for (int j = low; j < high; j++) {if (nums[j] < pivot) { // 如果当前元素小于基准值++i; // 扩展小于基准值的区域swap(nums[j], nums[i]); // 将当前元素与边界后的元素交换}}// 将基准值放到正确的位置(即小于基准值区域的后一个位置)swap(nums[++i], nums[high]);return i; // 返回基准值的最终位置
}// 快速排序主函数:递归地对数组进行排序
void quick_sort(vector<int>& nums, int low, int high)
{// 如果区间有效(low < high),则继续分区和递归排序if (low < high) {int index = partition(nums, low, high); // 对当前区间进行分区,获取基准值位置quick_sort(nums, low, index - 1); // 递归排序左分段(小于基准值的部分)quick_sort(nums, index + 1, high); // 递归排序右分段(大于基准值的部分)}
}int main()
{srand(time(0)); // 初始化随机数种子,确保每次运行生成不同的随机数// 定义测试用例vector<int> nums1 = {10, 7, 8, 9, 1, 5}; // 普通数组vector<int> nums2 = {1}; // 单元素数组vector<int> nums3 = {}; // 空数组vector<int> nums4 = {5, 5, 5, 5}; // 全部相等的数组// 对每个数组进行快速排序quick_sort(nums1, 0, nums1.size() - 1);quick_sort(nums2, 0, nums2.size() - 1);quick_sort(nums3, 0, nums3.size() - 1);quick_sort(nums4, 0, nums4.size() - 1);// 输出排序结果cout << "nums1: ";for (auto& x : nums1)cout << x << " "; // 输出普通数组的排序结果cout << endl;cout << "nums2: ";for (auto& x : nums2)cout << x << " "; // 输出单元素数组的排序结果cout << endl;cout << "nums3: ";for (auto& x : nums3)cout << x << " "; // 输出空数组的排序结果cout << endl;cout << "nums4: ";for (auto& x : nums4)cout << x << " "; // 输出全部相等数组的排序结果cout << endl;return 0;
}运行结果:

以数组 [10, 7, 8, 9, 1, 5] 为例:
- 第一次分区 :
- 基准值为
5。 - 分区后数组变为
[1, 5, 8, 9, 7, 10],基准位置为索引1。
- 基准值为
- 递归处理左子数组
[1](无需操作)。 - 递归处理右子数组
[8, 9, 7, 10]:- 选择基准
10,分区后数组变为[8, 9, 7, 10],基准位置为索引3。 - 递归处理左子数组
[8, 9, 7]:- 选择基准
7,分区后[7, 9, 8],基准位置为索引0。 - 递归处理右子数组
[9, 8],最终排序为[8, 9]。
- 选择基准
- 合并结果得到
[7, 8, 9, 10]。
- 选择基准
- 最终排序结果 :
[1, 5, 7, 8, 9, 10]。
二、归并排序
1. 分治策略
- 分解 :将数组不断对半分割,直到每个子数组长度为1(天然有序)
- 解决 :递归地对左右子数组进行排序
- 合并 :将两个有序子数组合并成一个更大的有序数组
2. 归并排序的分解过程
1、初始数组
索引:0 1 2 3 4 5
值: 10 7 8 9 1 5
2、 第一层分解 (整个数组)
[10, 7, 8, 9, 1, 5] → 左半部分 [10, 7, 8] 和 右半部分 [9, 1, 5]
3、第二层分解 (左半部分 [10,7,8])
[10,7,8] → 左半部分 [10] 和 右半部分 [7,8]
4、第三层分解 (右半部分 [7,8])
[7,8] → 左半部分 [7] 和 右半部分 [8]
5、第二层分解 (右半部分 [9,1,5])
[9,1,5] → 左半部分 [9] 和 右半部分 [1,5]
6、第三层分解 (右半部分 [1,5])
[1,5] → 左半部分 [1] 和 右半部分 [5]
3. 归并排序的合并过程
1)、合并层级 1
-
合并 [7] 和 [8] →
[7,8] -
合并 [1] 和 [5] →
[1,5]
2)、合并层级 2
-
合并 [10] 和 [7,8] →
[7,8,10]
10 vs 7 → 取7 → 新数组[7]
10 vs 8 → 取8 → 新数组[7,8]
剩余10 → 追加 → [7,8,10]
- 合并 [9] 和 [1,5] →
[1,5,9]
9 vs 1 → 取1 → 新数组[1]
9 vs 5 → 取5 → 新数组[1,5]
剩余9 → 追加 → [1,5,9]
3)、 合并层级 3(最终合并)
左数组:7,8,10
右数组:1,5,9
初始指针:i=0(左), j=0(右)1. 比较 7 vs 1 → 取1 → 新数组[1]
2. 比较 7 vs 5 → 取5 → 新数组[1,5]
3. 比较 7 vs 9 → 取7 → 新数组[1,5,7]
4. 比较 8 vs 9 → 取8 → 新数组[1,5,7,8]
5. 比较 10 vs 9 → 取9 → 新数组[1,5,7,8,9]
6. 右数组耗尽,追加剩余左数组元素 → [1,5,7,8,9,10]
4、代码实现
#include <iostream>
#include <vector>
using namespace std;/*** 合并两个有序子数组* @param nums 原始数组* @param l 左边界索引(包含)* @param r 右边界索引(包含)* @param mid 中间分割点索引*/
void merge(vector<int>& nums, int l, int r, int mid)
{// 创建左右子数组(左闭右开区间)vector<int> left(nums.begin() + l,nums.begin() + mid + 1); // 左子数组 [l, mid]vector<int> right(nums.begin() + mid + 1,nums.begin() + r + 1); // 右子数组 [mid+1, r]int i = 0, j = 0, k = l; // i:左数组指针,j:右数组指针,k:原数组指针// 合并两个有序数组while (i < left.size() && j < right.size()) {// 使用 <= 保持稳定性:相等元素保留原始顺序if (left[i] <= right[j]) {nums[k++] = left[i++];}else {nums[k++] = right[j++];}}// 处理剩余元素(如果有的话)while (i < left.size())nums[k++] = left[i++];while (j < right.size())nums[k++] = right[j++];
}/*** 归并排序递归函数* @param nums 待排序数组* @param l 当前处理范围的左边界(包含)* @param r 当前处理范围的右边界(包含)*/
void merge_sort(vector<int>& nums, int l, int r)
{if (l >= r)return; // 递归终止条件:子数组长度≤1int mid = l + (r - l) / 2; // 防溢出的中间点计算merge_sort(nums, l, mid); // 递归排序左半部分merge_sort(nums, mid + 1, r); // 递归排序右半部分merge(nums, l, r, mid); // 合并有序子数组
}/*** 归并排序辅助函数(对外接口)* @param nums 待排序数组*/
void merge_sort(vector<int>& nums)
{if (!nums.empty()) { // 非空时才执行排序merge_sort(nums, 0, nums.size() - 1);}
}/*** 测试用例执行函数* @param nums 测试数组* @param testName 测试用例名称*/
void runTest(vector<int>& nums, const string& testName)
{cout << "========== " << testName << " ==========\n";cout << "原始数组: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << endl;merge_sort(nums); // 执行排序cout << "排序结果: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << "\n\n";
}int main()
{// 测试用例定义vector<int> nums1 = {10, 7, 8, 9, 1, 5}; // 普通无序数组vector<int> nums2 = {1}; // 单元素数组vector<int> nums3 = {}; // 空数组vector<int> nums4 = {5, 5, 5, 5}; // 全相等元素数组vector<int> nums5 = {3, 1, 2, 4, 5}; // 部分有序数组vector<int> nums6 = {5, 4, 3, 2, 1}; // 完全逆序数组// 执行测试runTest(nums1, "普通数组");runTest(nums2, "单元素数组");runTest(nums3, "空数组");runTest(nums4, "全部相等的数组");runTest(nums5, "部分有序数组");runTest(nums6, "完全逆序数组");return 0;
}运行结果

三、插入排序
1、算法步骤
- 初始状态 :默认第一个元素是已排序的。
- 迭代过程 :
- 从第二个元素开始,依次取出每个元素(称为“当前元素”)。
- 将当前元素与已排序序列中的元素从后向前 依次比较。
- 如果已排序的元素大于当前元素,则将其后移一位,为当前元素腾出位置。
- 直到找到已排序元素小于或等于当前元素的位置,将当前元素插入此处。
- 终止条件 :所有元素均被插入到已排序序列中。
2、代码实现
#include <iostream>
#include <vector>
using namespace std;/*** @brief 插入排序算法实现** 通过逐步构建有序序列,将未排序元素插入到已排序序列的正确位置。* 时间复杂度:O(n²) 最坏/平均情况,O(n) 最好情况(已有序)* 空间复杂度:O(1) 原地排序* 稳定性:稳定排序算法** @param nums 待排序的整型向量(引用传递,直接修改原数组)*/
void insert_sort(vector<int>& nums)
{if(nums.empty() && nums.size() == 1) return;for (int i = 1; i < nums.size(); i++) {int temp = nums[i]; // 保存当前待插入元素int j = i - 1;// 将大于temp的已排序元素后移,腾出插入空间while (j >= 0 && nums[j] > temp) {nums[j + 1] = nums[j];--j;}// 因为内层循环结束后,j 必定在待插入元素的前一位// 比如:插入位置为0,那么j 必定等于 -1nums[j + 1] = temp; // 插入到正确位置}
}/*** 测试用例执行函数* @param nums 测试数组* @param testName 测试用例名称*/
void runTest(vector<int>& nums, const string& testName)
{cout << "========== " << testName << " ==========\n";cout << "原始数组: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << endl;insert_sort(nums); // 执行排序cout << "排序结果: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << "\n\n";
}int main()
{// 测试用例定义vector<int> nums1 = {10, 7, 8, 9, 1, 5}; // 普通无序数组vector<int> nums2 = {1}; // 单元素数组vector<int> nums3 = {}; // 空数组vector<int> nums4 = {5, 5, 5, 5}; // 全相等元素数组vector<int> nums5 = {3, 1, 2, 4, 5}; // 部分有序数组vector<int> nums6 = {5, 4, 3, 2, 1}; // 完全逆序数组// 执行测试runTest(nums1, "普通数组");runTest(nums2, "单元素数组");runTest(nums3, "空数组");runTest(nums4, "全部相等的数组");runTest(nums5, "部分有序数组");runTest(nums6, "完全逆序数组");return 0;
}运行结果

四、冒泡排序
1、算法步骤
- 遍历数组 :从头开始,比较相邻元素。
- 交换操作 :如果前一个元素 > 后一个元素,交换两者。
- 重复遍历 :每一轮遍历后,最大的元素会被移动到末尾,下一轮可减少一次比较。
- 提前终止 :如果某次遍历没有发生交换,说明已有序,可提前结束排序。
2、代码实现
#include <iostream>
#include <vector>using namespace std;/*** @brief 冒泡排序算法实现** 通过重复遍历数组,比较相邻元素并在顺序错误时交换它们。* 每轮遍历将最大的元素"浮"到数组末尾,并通过优化标志提前终止有序数组的排序。** 时间复杂度:* - 最坏/平均情况:O(n²)(完全逆序时)* - 最好情况:O(n)(已有序时)* 空间复杂度:O(1)(原地排序)* 稳定性:稳定排序(相同元素相对位置不变)** @param nums 待排序的整型向量(引用传递,直接修改原数组)*/
void bubble_sort(vector<int>& nums)
{if (nums.empty() || nums.size() == 1)return;// 用与检查该次循环是否发生交换bool isSwap;for (int i = 0; i < nums.size() - 1; i++) {isSwap = false;// 每轮结束后都会将该轮最大的值排到最后// 那么,就没必要再比较最后 i 个元素for (int j = 0; j < nums.size() - i - 1; j++) {if (nums[j] > nums[j + 1]) {swap(nums[j], nums[j + 1]);isSwap = true;}}// 如果该轮循环没有交换// 代表数组已经有序,可以提前结束了if (!isSwap) {break;}}
}/*** 测试用例执行函数* @param nums 测试数组* @param testName 测试用例名称*/
void runTest(vector<int>& nums, const string& testName)
{cout << "========== " << testName << " ==========\n";cout << "原始数组: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << endl;bubble_sort(nums); // 执行排序cout << "排序结果: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << "\n\n";
}int main()
{// 测试用例定义vector<int> nums1 = {10, 7, 8, 9, 1, 5}; // 普通无序数组vector<int> nums2 = {1}; // 单元素数组vector<int> nums3 = {}; // 空数组vector<int> nums4 = {5, 5, 5, 5}; // 全相等元素数组vector<int> nums5 = {3, 1, 2, 4, 5}; // 部分有序数组vector<int> nums6 = {5, 4, 3, 2, 1}; // 完全逆序数组// 执行测试runTest(nums1, "普通数组");runTest(nums2, "单元素数组");runTest(nums3, "空数组");runTest(nums4, "全部相等的数组");runTest(nums5, "部分有序数组");runTest(nums6, "完全逆序数组");return 0;
}运行结果

五、选择排序
1、算法步骤
- 初始化 :将数组视为未排序部分 。
- 选择最小元素 :从未排序部分中找到最小值。
- 交换位置 :将最小值与未排序部分的第一个元素交换,将其加入已排序部分。
- 重复 :缩小未排序范围,直到所有元素有序。
2、代码实现
#include <iostream>
#include <vector>using namespace std;/*** @brief 选择排序算法实现** 核心思想:每次从未排序部分选择最小元素,放到已排序序列的末尾。** 时间复杂度:O(n²)(所有情况下均为 O(n²))* 空间复杂度:O(1)(原地排序)* 稳定性:不稳定(可能改变相等元素的相对位置)** @param nums 待排序的整型向量(引用传递,直接修改原数组)*/
void selection_sort(vector<int>& nums)
{// 处理空数组或单元素数组(无需排序)if (nums.empty() || nums.size() == 1) {return;}int n = nums.size();for (int i = 0; i < n - 1; i++) {int minIndex = i; // 初始化最小值索引为当前未排序部分的起始位置// 在未排序部分 [i+1, n-1] 寻找最小值的索引for (int j = i + 1; j < n; j++) {if (nums[j] < nums[minIndex]) {minIndex = j;}}// 将最小值交换到已排序部分的末尾(i 位置)swap(nums[i], nums[minIndex]);}
}/*** 测试用例执行函数* @param nums 测试数组* @param testName 测试用例名称*/
void runTest(vector<int>& nums, const string& testName)
{cout << "========== " << testName << " ==========\n";cout << "原始数组: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << endl;selection_sort(nums); // 执行排序cout << "排序结果: ";if (nums.empty()) {cout << "(空数组)";}else {for (int num : nums)cout << num << " ";}cout << "\n\n";
}int main()
{// 测试用例定义vector<int> nums1 = {10, 7, 8, 9, 1, 5}; // 普通无序数组vector<int> nums2 = {1}; // 单元素数组vector<int> nums3 = {}; // 空数组vector<int> nums4 = {5, 5, 5, 5}; // 全相等元素数组vector<int> nums5 = {3, 1, 2, 4, 5}; // 部分有序数组vector<int> nums6 = {5, 4, 3, 2, 1}; // 完全逆序数组// 执行测试runTest(nums1, "普通数组");runTest(nums2, "单元素数组");runTest(nums3, "空数组");runTest(nums4, "全部相等的数组");runTest(nums5, "部分有序数组");runTest(nums6, "完全逆序数组");return 0;
}运行结果

相关文章:
c++的基础排序算法
一、快速排序 1. 选择基准值(Pivot) 作用 :从数组中选择一个元素作为基准(Pivot),用于划分数组。常见选择方式 : 固定选择最后一个元素(如示例代码)。随机选择…...

基于Spring3的抽奖系统
注:项目git仓库地址:demo.lottery 小五Z/Spring items - 码云 - 开源中国 目录 注:项目git仓库地址:demo.lottery 小五Z/Spring items - 码云 - 开源中国 项目具体代码可参考仓库源码,本文只讲解重点代码逻辑 一…...

基于qiime2的16S数据分析全流程:从导入数据到下游分析一条龙
目录 创建metadata 把数据导入qiime2 去除引物序列 双端合并 (dada2不需要) 质控 (dada2不需要) 使用deblur获得特征序列 使用dada2生成代表序列与特征表 物种鉴定 可视化物种鉴定结果 构建进化树(ITS一般不构建进化树…...

【Linux系统编程】基本IO函数
目录 1、open 函数2、create 函数3、write 函数4、read 函数5、lseek 函数6、access 函数7、unlink 函数8、remove 函数9、fcntl 函数写锁互斥锁示例读锁共享锁示例 1、open 函数 头文件 #include<sys/types.h> #include<sys/stat.h>#include<fcntl.h>…...

Deepseek应用技巧-chatbox搭建前端问答
目标:书接上回,由于本地私有化部署了deepseek的大模型,那怎么能够投入生产呢,那就必须有一个前端的应用界面,好在已经有很多的前人已经帮我们把前段应用给搭建好了,我们使用就可以啦,今天我们就…...

OpenAI API模型ChatGPT各模型功能对比,o1、o1Pro、GPT-4o、GPT-4.5调用次数限制附ChatGPT订阅教程
本文包含OpenAI API模型对比页面以及ChatGPT各模型功能对比表 - 截至2025最新整理数据:包含模型分类及描述;调用次数限制; 包含模型的类型有: Chat 模型(如 GPT-4o、GPT-4.5、GPT-4)专注于对话,…...

Fast DDS Security--秘钥交换
Fast DDS Security模块中默认使用Diffie-Hellman算法进行秘钥交换。Diffie-Hellman 算法(简称 DH 算法)是一个非常重要的加密协议,用于在不安全的通信通道中安全地交换密钥。该算法通过利用数学中的离散对数问题来生成共享密钥,使…...
从0开始的操作系统手搓教程33:挂载我们的文件系统
目录 代码实现 添加到初始化上 上电看现象 挂载分区可能是一些朋友不理解的——实际上挂载就是将我们的文件系统封装好了的设备(硬盘啊,SD卡啊,U盘啊等等),挂到我们的默认分区路径下。这样我们就能访问到了ÿ…...

基于muduo+mysql+jsoncpp的简易HTTPWebServer
一、项目介绍 本项目基于C语言、陈硕老师的muduo网络库、mysql数据库以及jsoncpp,服务器监听两个端口,一个端口用于处理http请求,另一个端口用于处理发送来的json数据。 此项目在实现时,识别出车牌后打包为json数据发送给后端服务…...

【Go学习实战】03-2-博客查询及登录
【Go学习实战】03-2-博客查询及登录 读取数据库数据初始化数据库首页真实数据分类查询分类查询测试 文章查询文章查询测试 分类文章列表测试 登录功能登录页面登录接口获取json参数登录失败测试 md5加密jwt工具 登录成功测试 文章详情测试 读取数据库数据 因为我们之前的数据都…...

《Python实战进阶》No20: 网络爬虫开发:Scrapy框架详解
No20: 网络爬虫开发:Scrapy框架详解 摘要 本文深入解析Scrapy核心架构,通过中间件链式处理、布隆过滤器增量爬取、Splash动态渲染、分布式指纹策略四大核心技术,结合政府数据爬取与动态API逆向工程实战案例,构建企业级爬虫系统。…...

2021 年 9 月青少年软编等考 C 语言六级真题解析
目录 T1. 合法出栈序列思路分析T2. 奇怪的括号思路分析T3. 区间合并思路分析T4. 双端队列思路分析T1. 合法出栈序列 题目链接:SOJ D1110 给定一个由不同小写字母构成的长度不超过 8 8 8 的字符串 x x x,现在要将该字符串的字符依次压入栈中,然后再全部弹出。要求左边的字…...

Linux:多线程(单例模式,其他常见的锁,读者写者问题)
目录 单例模式 什么是设计模式 单例模式介绍 饿汉实现方式和懒汉实现方式 其他常见的各种锁 自旋锁 读者写者问题 逻辑过程 接口介绍 单例模式 什么是设计模式 设计模式就是一些大佬在编写代码的过程中,针对一些经典常见场景,给定对应解决方案&…...

shell 脚本的编写学习
学习编写 Shell 脚本是 Linux/Unix 系统管理和自动化的一个非常有用的技能。Shell 脚本是一些 Shell 命令的集合,用户可以用它来自动执行任务、简化工作流程、管理系统等。下面是一个 Shell 脚本学习的入门指南: 1. Shell 脚本基础 Shell 脚本通常是以…...

【氮化镓】高输入功率应力诱导的GaN 在下的退化LNA退化
2019年,中国工程物理研究院电子工程研究所的Tong等人基于实验与第一性原理计算方法,研究了Ka波段GaN低噪声放大器(LNA)在高输入功率应力下的退化机制。实验结果表明,在27 GHz下施加1 W连续波(CW)输入功率应力后,LNA的增益下降约1 dB,噪声系数(NF)增加约0.7 dB。进一…...

根据开始和结束日期,获取每一天和每个月的开始和结束日期的list
获取开始日期与结束日期之间每天的list /*** 根据传入的开始时间和结束时间,筛选出所有的天的list;** param startTime* param endTime*/public Map<String, List<String>> fetchDayListBetweenStartAndEnd(String startTime, String endTime) {// 创建mapMap<…...

Javaweb后端文件上传@value注解
文件本地存储磁盘 阿里云oss准备工作 阿里云oss入门程序 要重启一下idea,上面有cmd 阿里云oss案例集成 优化 用spring中的value注解...

git规范提交之commitizen conventional-changelog-cli 安装
一、引言 使用规范的提交信息可以让项目更加模块化、易于维护和理解,同时也便于自动化工具(如发布工具或 Changelog 生成器)解析和处理提交记录。 通过编写符合规范的提交消息,可以让团队和协作者更好地理解项目的变更历史和版本…...

Java/Kotlin逆向基础与Smali语法精解
1. 法律警示与道德边界 1.1 司法判例深度剖析 案例一:2021年某游戏外挂团伙刑事案 犯罪手法:逆向《王者荣耀》通信协议,修改战斗数据包 技术细节:Hook libil2cpp.so的SendPacket函数 量刑依据:非法经营罪ÿ…...

非软件开发项目快速上手:14款管理软件精选
文章介绍了以下14款项目管理系统:1.Worktile;2.Teambition;3.Microsoft Project;4.Forbes;5.WorkOtter;6.Trello;7.Smartsheet;8.Taiga;9.ClickUp;10.Monday.…...

Redis四种模式在Spring Boot框架下的配置
在Spring Boot框架下配置Redis的四种模式(单机模式、主从模式、哨兵模式、集群模式)可以通过以下方式实现: 1. 单机模式 在application.properties或application.yml中配置Redis的连接信息: # application.properties spring.redi…...

夸父工具箱(安卓版) 手机超强工具箱
如今,人们的互联网活动日益频繁,导致手机内存即便频繁清理,也会莫名其妙地迅速填满,许多无用的垃圾信息悄然占据空间。那么,如何有效应对这一难题呢?答案就是今天新推出的这款工具软件,它能从根…...

混元图生视频-腾讯混元开源的图生视频模型
混元图生视频是什么 混元图生视频是腾讯混元推出的开源图生视频模型,用户可以通过上传一张图片进行简短描述,让图片动起来生成5秒的短视频。模型支持对口型、动作驱动和背景音效自动生成等功能。模型适用于写实、动漫和CGI等多种角色和场景,…...

从零开始打造一个通用的 Vue 卡片组件
前言 大家好,最近在做项目的时候发现我们系统里到处都是各种卡片样式的 UI 元素,每次都要重写一遍真的很烦。于是我花了点时间,封装了一个通用的卡片组件,今天就来分享一下我的开发思路和实现过程。希望能对大家有所帮助…...

选择排序算法OpenMP并行优化
一 选择排序算法原理 时间复杂度,O(n 2)。 每次从未排序序列中选择最小元素,交换到已排序序列末尾。 二 具体步骤 1)初始状态 已排序区间为空,未排序区间为[0,n-1]。 2)第i次迭代 在未排序区间[i, n-1]中找最小值索引min_idx 交换arr[i]与arr[min_idx]。 3)重复…...

Debian系统grub新增启动项
参考链接 给grub添加自定义启动项_linux grub定制 启动项名称自定义-CSDN博客 www.cnblogs.com 1. boot里面的grub.cfg 使用vim打开boot里面的grub.cfg sudo vim /boot/grub/grub.cfg 这时候会看到文件最上方的提示 2. 真正配置grub的文件 从刚才看到的文件提示中&#x…...

VSCode快捷键整理
VSCode快捷键整理 文章目录 VSCode快捷键整理1-VSCode 常用快捷键1-界面操作2-单词移动3-删除操作4-编程相关5-多光标操作6-文件、符号、函数跳转7-鼠标操作8-自动补全操作9-代码折叠操作 1-VSCode 常用快捷键 1-界面操作 文件资源管理器:Ctrl Shift E 跨文件搜…...

刘火良 FreeRTOS内核实现与应用之1——列表学习
重要数据 节点的命名都以_ITEM后缀进行,链表取消了后缀,直接LIST 普通的节点数据类型 /* 节点结构体定义 */ struct xLIST_ITEM { TickType_t xItemValue; /* 辅助值,用于帮助节点做顺序排列 */ struct xLIST_I…...
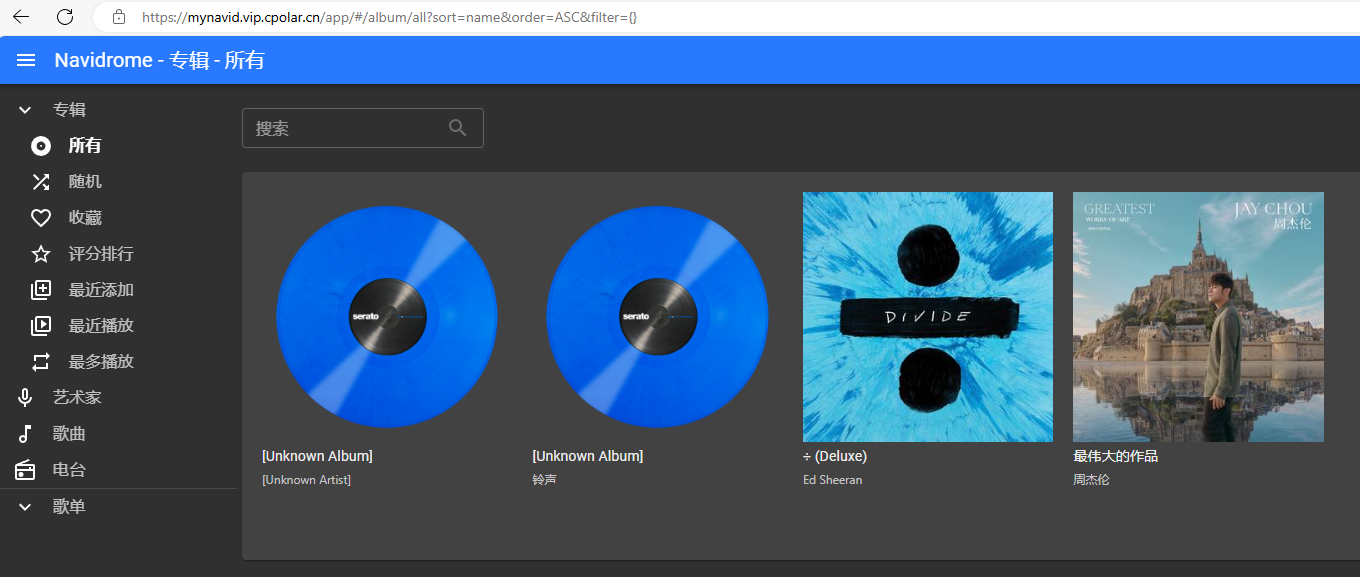
本地部署Navidrome个人云音乐平台随时随地畅听本地音乐文件
文章目录 前言1. 安装Docker2. 创建并启动Navidrome容器3. 公网远程访问本地Navidrome3.1 内网穿透工具安装3.2 创建远程连接公网地址3.3 使用固定公网地址远程访问 前言 今天我要给大家安利一个超酷的私有化音乐神器——Navidrome!它不仅让你随时随地畅享本地音乐…...

数据集构建与训练前准备
训练数据集目录结构与格式 作者笨蛋学法,先将其公式化,后面逐步自己进行修改,读者觉得看不懂可以理解成,由结果去推过程,下面的这个yaml文件就是结果,我们去推需要的文件夹(名字可以不固定,但是…...