pandas-基础(数据结构及文件访问)
1 Pandas的数据结构
1.1 Series
特点:一维的数据型对象,包含一个值序列和数据标签(即索引)
创建Series:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)参数说明:
data:Series 的数据部分,可以是列表、数组、字典、标量值等。如果不提供此参数,则创建一个空的 Series。index:Series 的索引部分,用于对数据进行标记。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。dtype:指定 Series 的数据类型。可以是 NumPy 的数据类型,例如np.int64、np.float64等。如果不提供此参数,则根据数据自动推断数据类型。name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
常用方法:
Series 方法
下面是 Series 中一些常用的方法:
| 方法名称 | 功能描述 |
|---|---|
index | 获取 Series 的索引 |
values | 获取 Series 的数据部分(返回 NumPy 数组) |
head(n) | 返回 Series 的前 n 行(默认为 5) |
tail(n) | 返回 Series 的后 n 行(默认为 5) |
dtype | 返回 Series 中数据的类型 |
shape | 返回 Series 的形状(行数) |
describe() | 返回 Series 的统计描述(如均值、标准差、最小值等) |
isnull() | 返回一个布尔 Series,表示每个元素是否为 NaN |
notnull() | 返回一个布尔 Series,表示每个元素是否不是 NaN |
unique() | 返回 Series 中的唯一值(去重) |
value_counts() | 返回 Series 中每个唯一值的出现次数 |
map(func) | 将指定函数应用于 Series 中的每个元素 |
apply(func) | 将指定函数应用于 Series 中的每个元素,常用于自定义操作 |
astype(dtype) | 将 Series 转换为指定的类型 |
sort_values() | 对 Series 中的元素进行排序(按值排序) |
sort_index() | 对 Series 的索引进行排序 |
dropna() | 删除 Series 中的缺失值(NaN) |
fillna(value) | 填充 Series 中的缺失值(NaN) |
replace(to_replace, value) | 替换 Series 中指定的值 |
cumsum() | 返回 Series 的累计求和 |
cumprod() | 返回 Series 的累计乘积 |
shift(periods) | 将 Series 中的元素按指定的步数进行位移 |
rank() | 返回 Series 中元素的排名 |
corr(other) | 计算 Series 与另一个 Series 的相关性(皮尔逊相关系数) |
cov(other) | 计算 Series 与另一个 Series 的协方差 |
to_list() | 将 Series 转换为 Python 列表 |
to_frame() | 将 Series 转换为 DataFrame |
iloc[] | 通过位置索引来选择数据 |
loc[] | 通过标签索引来选择数据 |
1.2 DataFrame
构造方法:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)参数说明:
data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如np.int64、np.float64等。如果不提供此参数,则根据数据自动推断数据类型。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
DataFrame 方法
DataFrame 的常用操作和方法如下表所示:
| 方法名称 | 功能描述 |
|---|---|
head(n) | 返回 DataFrame 的前 n 行数据(默认前 5 行) |
tail(n) | 返回 DataFrame 的后 n 行数据(默认后 5 行) |
info() | 显示 DataFrame 的简要信息,包括列名、数据类型、非空值数量等 |
describe() | 返回 DataFrame 数值列的统计信息,如均值、标准差、最小值等 |
shape | 返回 DataFrame 的行数和列数(行数, 列数) |
columns | 返回 DataFrame 的所有列名 |
index | 返回 DataFrame 的行索引 |
dtypes | 返回每一列的数值数据类型 |
sort_values(by) | 按照指定列排序 |
sort_index() | 按行索引排序 |
dropna() | 删除含有缺失值(NaN)的行或列 |
fillna(value) | 用指定的值填充缺失值 |
isnull() | 判断缺失值,返回一个布尔值 DataFrame |
notnull() | 判断非缺失值,返回一个布尔值 DataFrame |
loc[] | 按标签索引选择数据 |
iloc[] | 按位置索引选择数据 |
at[] | 访问 DataFrame 中单个元素(比 loc[] 更高效) |
iat[] | 访问 DataFrame 中单个元素(比 iloc[] 更高效) |
apply(func) | 对 DataFrame 或 Series 应用一个函数 |
applymap(func) | 对 DataFrame 的每个元素应用函数(仅对 DataFrame) |
groupby(by) | 分组操作,用于按某一列分组进行汇总统计 |
pivot_table() | 创建透视表 |
merge() | 合并多个 DataFrame(类似 SQL 的 JOIN 操作) |
concat() | 按行或按列连接多个 DataFrame |
to_csv() | 将 DataFrame 导出为 CSV 文件 |
to_excel() | 将 DataFrame 导出为 Excel 文件 |
to_json() | 将 DataFrame 导出为 JSON 格式 |
to_sql() | 将 DataFrame 导出为 SQL 数据库 |
query() | 使用 SQL 风格的语法查询 DataFrame |
duplicated() | 返回布尔值 DataFrame,指示每行是否是重复的 |
drop_duplicates() | 删除重复的行 |
set_index() | 设置 DataFrame 的索引 |
reset_index() | 重置 DataFrame 的索引 |
transpose() | 转置 DataFrame(行列交换) |
数据选择和切片
| 函数 | 说明 |
|---|---|
| df[column_name] | 选择指定的列; |
| df.loc[row_index, column_name] | 通过标签选择数据; |
| df.iloc[row_index, column_index] | 通过位置选择数据; |
| df.ix[row_index, column_name] | 通过标签或位置选择数据; |
| df.filter(items=[column_name1, column_name2]) | 选择指定的列; |
| df.filter(regex='regex') | 选择列名匹配正则表达式的列; |
| df.sample(n) | 随机选择 n 行数据。 |
索引设置
将索引重置成自然数-reset_index()
pandas中将索引重置成自然数的方法,不会改变原始数据的内容和排列顺序。
import pandas as pd
import numpy as npprint("\n")
print("reset_index")
df = pd.DataFrame({'Col-1': [1, 3, 5], 'Col-2': [5, 7, 9]}, index=['A', 'B', 'C'])
print("df:\n",df)
df1 = df.reset_index()
print("df1:\n",df1)print("drop=True:\n",df.reset_index(drop=True))'''
输出结果:
reset_index
df:Col-1 Col-2
A 1 5
B 3 7
C 5 9
df1:index Col-1 Col-2
0 A 1 5
1 B 3 7
2 C 5 9
drop=True:Col-1 Col-2
0 1 5
1 3 7
2 5 9
'''按照指定索引对齐当前数据-reindex()
reindex()是pandas中实现数据对齐的基本方法,对齐是指沿着指定轴,让数据与给定的一组标签(行列索引)进行匹配。
import pd as pandasprint("\n")
df = pd.DataFrame({'Col-1': [1, 3, 5], 'Col-2': [5, 7, 9]}, index=['A', 'B', 'C'])
print("df:\n",df)
# 默认传给labels参数
df2 = df.reindex(['C', 'B', 'A'])
print("df2:\n",df2)'''
输出结果:
df:Col-1 Col-2
A 1 5
B 3 7
C 5 9
df2:Col-1 Col-2
C 5 9
B 3 7
A 1 5
'''print("axis='columns'")
# 指定重设的是行索引还是列索引,默认是行索引
df3 = df.reindex(['Col-2', 'c3', 'Col-1'], axis='columns')
print("df3:\n",df3)
# 同时调整行和列
df4 = df.reindex(index=['C', 'B', 'A'], columns=['Col-2', 'c3', 'Col-1'])
print("df4:\n",df4)'''
输出结果:
axis='columns'
df3:Col-2 c3 Col-1
A 5 NaN 1
B 7 NaN 3
C 9 NaN 5
df4:Col-2 c3 Col-1
C 9.0 NaN 5.0
B 7.0 NaN 3.0
A 5.0 NaN 1.0
'''用另一个DataFrame的索引来更新当前DataFrame的索引-reindex_like()
如果是原数据中不存在的索引值,则默认填充空值NaN,也可以使用method参数设置向前填充还是向后填充。
注意:reindex_like()中没有fill_value参数,不支持用指定值填充。
import pd as pandasdfa = pd.DataFrame({'Col-1': [1, 3, 5], 'Col-2': [5, 7, 9]}, index=['A', 'B', 'C'])
print("dfa:\n",dfa)
dfb = pd.DataFrame({'Col-1': [1, 3, 5, 7, 9], 'Col-2': [2, 4, 6, 8, 10]},index=['A', 'B', 'C', 'D', 'E'])
print("dfb:\n" ,dfb, '\n', end='*'*30+'\n')
dfc = dfa.reindex_like(dfb)
print("dfc:\n",dfc)'''
输出结果:
dfa:Col-1 Col-2
A 1 5
B 3 7
C 5 9
dfb:Col-1 Col-2
A 1 2
B 3 4
C 5 6
D 7 8
E 9 10
******************************
dfc:Col-1 Col-2
A 1.0 5.0
B 3.0 7.0
C 5.0 9.0
D NaN NaN
E NaN NaN
'''2 文件访问
2.1 csv文件
Pandas 可以很方便的处理 CSV 文件,常用方法有:
| 方法名称 | 功能描述 | 常用参数 |
|---|---|---|
pd.read_csv() | 从 CSV 文件读取数据并加载为 DataFrame | filepath_or_buffer (路径或文件对象),sep (分隔符),header (行标题),names (自定义列名),dtype (数据类型),index_col (索引列) |
DataFrame.to_csv() | 将 DataFrame 写入到 CSV 文件 | path_or_buffer (目标路径或文件对象),sep (分隔符),index (是否写入索引),columns (指定列),header (是否写入列名),mode (写入模式) |
pd.read_csv() - 读取 CSV 文件
read_csv() 是从 CSV 文件中读取数据的主要方法,将数据加载为一个 DataFrame。
import pandas as pd# 读取 CSV 文件,并自定义列名和分隔符
df = pd.read_csv('data.csv', sep=';', header=0, names=['A', 'B', 'C'], dtype={'A': int, 'B': float})
print(df)read_csv 常用参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
filepath_or_buffer | CSV 文件的路径或文件对象(支持 URL、文件路径、文件对象等) | 必需参数 |
sep | 定义字段分隔符,默认是逗号(,),可以改为其他字符,如制表符(\t) | ',' |
header | 指定行号作为列标题,默认为 0(表示第一行),或者设置为 None 没有标题 | 0 |
names | 自定义列名,传入列名列表 | None |
index_col | 用作行索引的列的列号或列名 | None |
usecols | 读取指定的列,可以是列的名称或列的索引 | None |
dtype | 强制将列转换为指定的数据类型 | None |
skiprows | 跳过文件开头的指定行数,或者传入一个行号的列表 | None |
nrows | 读取前 N 行数据 | None |
na_values | 指定哪些值应视为缺失值(NaN) | None |
skipfooter | 跳过文件结尾的指定行数 | 0 |
encoding | 文件的编码格式(如 utf-8,latin1 等) | None |
df.to_csv() - 将 DataFrame 写入 CSV 文件
to_csv() 是将 DataFrame 写入 CSV 文件的方法,支持自定义分隔符、列名、是否包含索引等设置。import pandas as pd# 假设 df 是一个已有的 DataFrame
df.to_csv('output.csv', index=False, header=True, columns=['A', 'B'])to_csv 常用参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
path_or_buffer | CSV 文件的路径或文件对象(支持文件路径、文件对象) | 必需参数 |
sep | 定义字段分隔符,默认是逗号(,),可以改为其他字符,如制表符(\t) | ',' |
index | 是否写入行索引,默认 True 表示写入索引 | True |
columns | 指定写入的列,可以是列的名称列表 | None |
header | 是否写入列名,默认 True 表示写入列名,设置为 False 表示不写列名 | True |
mode | 写入文件的模式,默认是 w(写模式),可以设置为 a(追加模式) | 'w' |
encoding | 文件的编码格式,如 utf-8,latin1 等 | None |
line_terminator | 定义行结束符,默认为 \n | None |
quoting | 设置如何对文件中的数据进行引号处理(0-3,具体引用方式可查文档) | None |
quotechar | 设置用于引用的字符,默认为双引号 " | '"' |
date_format | 自定义日期格式,如果列包含日期数据,则可以使用此参数指定日期格式 | None |
doublequote | 如果为 True,则在写入时会将包含引号的文本使用双引号括起来 | True |
2.2 Excel 文件
Pandas 提供了丰富的 Excel 文件操作功能,帮助我们方便地读取和写入 .xls 和 .xlsx 文件,支持多表单、索引、列选择等复杂操作,是数据分析中必备的工具。
| 操作 | 方法 | 说明 |
|---|---|---|
| 读取 Excel 文件 | pd.read_excel() | 读取 Excel 文件,返回 DataFrame |
| 将 DataFrame 写入 Excel | DataFrame.to_excel() | 将 DataFrame 写入 Excel 文件 |
| 加载 Excel 文件 | pd.ExcelFile() | 加载 Excel 文件并访问多个表单 |
| 使用 ExcelWriter 写多个表单 | pd.ExcelWriter() | 写入多个 DataFrame 到同一 Excel 文件的不同表单 |
pd.read_excel() - 读取 Excel 文件
pd.read_excel() 方法用于从 Excel 文件中读取数据并加载为 DataFrame。它支持读取 .xls 和 .xlsx 格式的文件。
语法格式如下:
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=<no_default>, date_format=None, thousands=None, decimal='.', comment=None, skipfooter=0, storage_options=None, dtype_backend=<no_default>, engine_kwargs=None)参数说明:
-
io:这是必需的参数,指定了要读取的 Excel 文件的路径或文件对象。 -
sheet_name=0:指定要读取的工作表名称或索引。默认为0,即第一个工作表。 -
header=0:指定用作列名的行。默认为0,即第一行。 -
names=None:用于指定列名的列表。如果提供,将覆盖文件中的列名。 -
index_col=None:指定用作行索引的列。可以是列的名称或数字。 -
usecols=None:指定要读取的列。可以是列名的列表或列索引的列表。 -
dtype=None:指定列的数据类型。可以是字典格式,键为列名,值为数据类型。 -
engine=None:指定解析引擎。默认为None,pandas 会自动选择。 -
converters=None:用于转换数据的函数字典。 -
true_values=None:指定应该被视为布尔值True的值。 -
false_values=None:指定应该被视为布尔值False的值。 -
skiprows=None:指定要跳过的行数或要跳过的行的列表。 -
nrows=None:指定要读取的行数。 -
na_values=None:指定应该被视为缺失值的值。 -
keep_default_na=True:指定是否要将默认的缺失值(例如NaN)解析为NA。 -
na_filter=True:指定是否要将数据转换为NA。 -
verbose=False:指定是否要输出详细的进度信息。 -
parse_dates=False:指定是否要解析日期。 -
date_parser=<no_default>:用于解析日期的函数。 -
date_format=None:指定日期的格式。 -
thousands=None:指定千位分隔符。 -
decimal='.':指定小数点字符。 -
comment=None:指定注释字符。 -
skipfooter=0:指定要跳过的文件末尾的行数。 -
storage_options=None:用于云存储的参数字典。 -
dtype_backend=<no_default>:指定数据类型后端。 -
engine_kwargs=None:传递给引擎的额外参数字典。
DataFrame.to_excel() - 将 DataFrame 写入 Excel 文件
to_excel() 方法用于将 DataFrame 写入 Excel 文件,支持 .xls 和 .xlsx 格式。
语法格式如下:
DataFrame.to_excel(excel_writer, *, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, inf_rep='inf',freeze_panes=None, storage_options=None, engine_kwargs=None)参数说明:
-
excel_writer:这是必需的参数,指定了要写入的 Excel 文件路径或文件对象。 -
sheet_name='Sheet1':指定写入的工作表名称,默认为'Sheet1'。 -
na_rep='':指定在 Excel 文件中表示缺失值(NaN)的字符串,默认为空字符串。 -
float_format=None:指定浮点数的格式。如果为None,则使用 Excel 的默认格式。 -
columns=None:指定要写入的列。如果为None,则写入所有列。 -
header=True:指定是否写入列名作为第一行。如果为False,则不写入列名。 -
index=True:指定是否写入索引作为第一列。如果为False,则不写入索引。 -
index_label=None:指定索引列的标签。如果为None,则不写入索引标签。 -
startrow=0:指定开始写入的行号,默认从第0行开始。 -
startcol=0:指定开始写入的列号,默认从第0列开始。 -
engine=None:指定写入 Excel 文件时使用的引擎,默认为None,pandas 会自动选择。 -
merge_cells=True:指定是否合并单元格。如果为True,则合并具有相同值的单元格。 -
inf_rep='inf':指定在 Excel 文件中表示无穷大值的字符串,默认为'inf'。 -
freeze_panes=None:指定冻结窗格的位置。如果为None,则不冻结窗格。 -
storage_options=None:用于云存储的参数字典。 -
engine_kwargs=None:传递给引擎的额外参数字典。
ExcelFile - 加载 Excel 文件
ExcelFile 是一个用于读取 Excel 文件的类,它可以处理多个表单,并在不重新打开文件的情况下访问其中的数据。
语法格式如下:
excel_file = pd.ExcelFile('data.xlsx')常用方法:
方法 | 功能描述 |
|---|---|
| 返回文件中所有表单的名称列表 |
| 解析指定表单并返回一个 DataFrame |
| 关闭文件,以释放资源 |
ExcelWriter - 写入 Excel 文件
ExcelWriter 是 pandas 提供的一个类,用于将 DataFrame 或 Series 对象写入 Excel 文件。使用 ExcelWriter,你可以在一个 Excel 文件中写入多个工作表,并且可以更灵活地控制写入过程。
语法格式如下:
pandas.ExcelWriter(path, engine=None, date_format=None, datetime_format=None, mode='w', storage_options=None, if_sheet_exists=None, engine_kwargs=None)参数说明:
-
path:这是必需的参数,指定了要写入的 Excel 文件的路径、URL 或文件对象。可以是本地文件路径、远程存储路径(如 S3)、URL 链接或已打开的文件对象。 -
engine:这是一个可选参数,用于指定写入 Excel 文件的引擎。如果为None,则 pandas 会自动选择一个可用的引擎(默认优先选择openpyxl,如果不可用则选择其他可用引擎)。常见的引擎包括'openpyxl'(用于.xlsx文件)、'xlsxwriter'(提供高级格式化和图表功能)、'odf'(用于 OpenDocument 格式如.ods)等。 -
date_format:这是一个可选参数,指定写入 Excel 文件中日期的格式字符串,例如"YYYY-MM-DD"。 -
datetime_format:这是一个可选参数,指定写入 Excel 文件中日期时间对象的格式字符串,例如"YYYY-MM-DD HH:MM:SS"。 -
mode:这是一个可选参数,默认为'w',表示写入模式。如果设置为'a',则表示追加模式,向现有文件中添加数据(仅支持部分引擎,如openpyxl)。 -
storage_options:这是一个可选参数,用于指定与存储后端连接的额外选项,例如认证信息、访问权限等,适用于写入远程存储(如 S3、GCS)。 -
if_sheet_exists:这是一个可选参数,默认为'error',指定如果工作表已经存在时的行为。选项包括'error'(抛出错误)、'new'(创建一个新工作表)、'replace'(替换现有工作表的内容)、'overlay'(在现有工作表上覆盖写入)。 -
engine_kwargs:这是一个可选参数,用于传递给引擎的其他关键字参数。这些参数会传递给相应引擎的函数,例如xlsxwriter.Workbook(file, **engine_kwargs)或openpyxl.Workbook(**engine_kwargs)等。
相关文章:
)
pandas-基础(数据结构及文件访问)
1 Pandas的数据结构 1.1 Series 特点:一维的数据型对象,包含一个值序列和数据标签(即索引) 创建Series: pandas.Series(dataNone, indexNone, dtypeNone, nameNone, copyFalse, fastpathFalse) 参数说明: data&a…...

简单记录一下Oracle数据库与mysql数据库注入的不同。
Oracle数据库的注入比mysql较复制。 一确定注入点:与mysql一样。 and 11 -- #文章有出现. and 12 -- #文章不见了。 二。确定列数。 ’order by 1,2 -- #没问题 order by 1,2,3 -- #保错,所以有两列。 三,所有uni…...

前端小食堂 | Day11 - Vue.js の烹饪秘籍
🎨 今日主菜:Vue 常用技巧全家桶 1. 响应式烹饪秘籍 <script setup> // 🍳 精准控制响应式 const counter ref(0); // 基本类型用ref const user reactive({ name: 小明, age: 18 }); // 对象用reactive // 🔥 自…...

如何将本地已有的仓库上传到gitee (使用UGit)
1、登录Gitee。 2、点击个人头像旁边的加号,选择新建仓库: 3、填写仓库相关信息 4、复制Gitee仓库的地址 5、绑定我们的本地仓库与远程仓库 6、将本地仓库发布(推送)到远程仓库: 注意到此处报错ÿ…...
电子拍卖系统)
多方安全计算(MPC)电子拍卖系统
目录 一、前言二、多方安全计算(MPC)与电子拍卖系统概述2.1 多方安全计算(MPC)的基本概念2.2 电子拍卖系统背景与需求三、MPC电子拍卖系统设计原理3.1 系统总体架构3.2 电子拍卖中的安全协议3.3 数学与算法证明四、数据加解密模块设计五、GPU加速与系统性能优化六、GUI设计与系…...

Day04 模拟原生开发app过程 Androidstudio+逍遥模拟器
1、用Androidstudio打开已经写好了的music项目 2、逍遥模拟器打开apk后缀文件 3、在源文件搜索关键字 以后的测试中做资产收集...

C# Channel
核心概念创建Channel无界通道有界通道FullMode选项 生产者-消费者模式生产者写入数据消费者读取数据 完整示例高级配置优化选项:取消操作:通过 CancellationToken 取消读写。 错误处理适用场景Channel的类型创建Channel写入和读取消息使用场景示例代码注…...

17网商品列表的HTML结构是怎样的?
根据搜索结果,目前没有直接提供17网(17zwd)商品列表的HTML结构的详细信息。不过,我们可以根据一般的电商网站结构进行推测,并结合已有的爬虫代码示例来分析可能的HTML结构。 17网商品列表的HTML结构推测 一般来说&am…...

若依ry-vue分离板(完整版)前后端部署
目录 1.目标 2.准备工作 3.源码下载 4.整理前后端目录 5.先部署后端 (1)导入数据库 (2)改代码数据库配置 (3)运行redis (4)运行执行文件 (5)后端启…...

【YOLOv8】YOLOv8改进系列(5)----替换主干网络之EfficientFormerV2
主页:HABUO🍁主页:HABUO 🍁YOLOv8入门改进专栏🍁 🍁如果再也不能见到你,祝你早安,午安,晚安🍁 【YOLOv8改进系列】: 【YOLOv8】YOLOv8结构解读…...

深入理解 HTML 文本格式化
在网页开发中,HTML 文本格式化是一项基础且关键的技能。通过合理运用 HTML 格式化标签,我们能够让网页上的文本以丰富多样的形式呈现,从而提升用户体验。本文将详细介绍 HTML 文本格式化的相关知识。 一、HTML 文本格式化基础 加粗文本…...

时序和延时
1、延迟模型的类型 verilog有三种类型的延迟模型:分布延迟 、 集总延迟 、 路径延迟(pin to pin) 1.1、 分布延迟 分布延迟是在每个独立元件的基础上进行定义的。 module M(output wire out ,input wire a …...

北大一二三四版全套DeepSeek教学资料
DeepSeek学习资料合集:https://pan.quark.cn/s/bb6ebf0e9b4d DeepSeek实操变现指南:https://pan.quark.cn/s/76328991eaa2 你是否渴望深入探索人工智能的前沿领域?是否在寻找一份能引领你从理论到实践,全面掌握AI核心技术的学习…...

垃圾收集算法与收集器
在 JVM 中,垃圾收集(Garbage Collection, GC)算法的核心目标是自动回收无用对象的内存,同时尽量减少对应用性能的影响。以下是 JVM 中主要垃圾收集算法的原理、流程及实际应用场景的详细介绍: 一、标记-清除算法&#…...
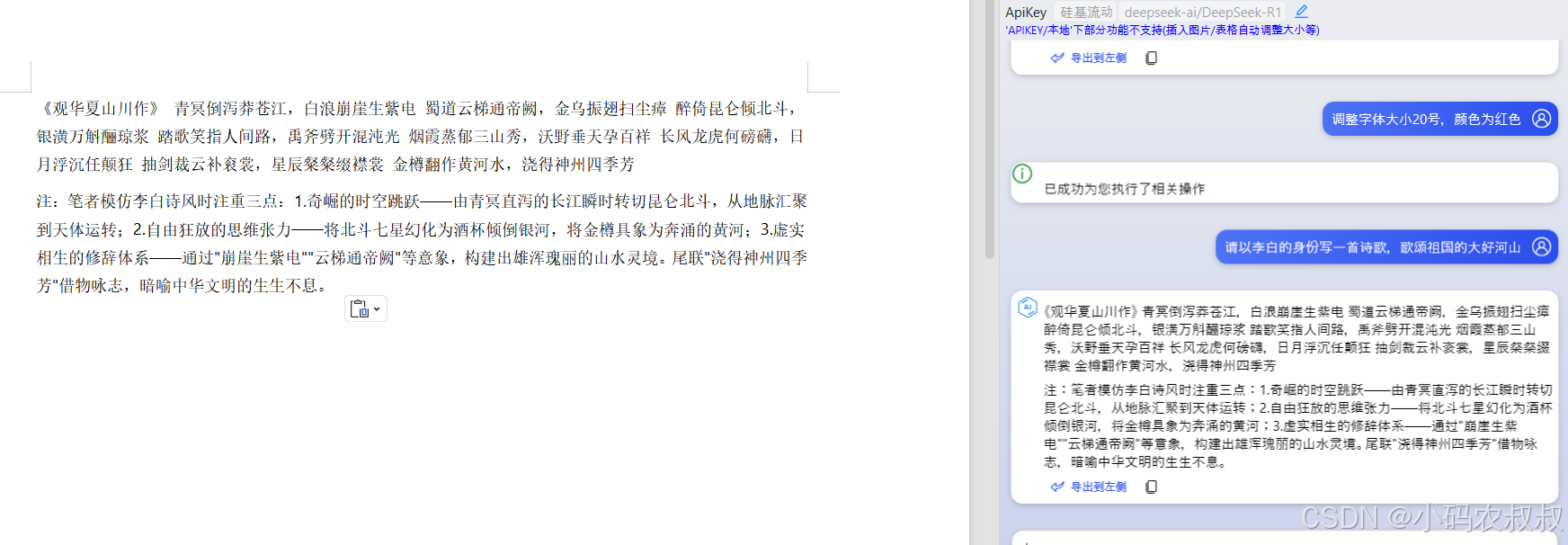
【大模型】WPS 接入 DeepSeek-R1详解,打造全能AI办公助手
目录 一、前言 二、WPS接入AI工具优势 三、WPS接入AI工具两种方式 3.1 手动配置的方式 3.2 Office AI助手 四、WPS手动配置方式接入AI大模型 4.1 安装VBA插件 4.1.1 下载VBA插件并安装 4.2 配置WPS 4.3 WPS集成VB 4.4 AI助手效果测试 4.5 配置模板文…...

STM32步进电机驱动全解析(上) | 零基础入门STM32第五十七步
主题内容教学目的/扩展视频步进电机电路原理,跳线设置,驱动程序,调用控制。熟悉驱动程序,能调用控制。 师从洋桃电子,杜洋老师 📑文章目录 一、步进电机核心原理图解二、核心特性与优势三、关键驱动方式对比…...
)
Spring Boot 多数据源解决方案:dynamic-datasource-spring-boot-starter 的奥秘(上)
在 Spring Boot 生态中,dynamic-datasource-spring-boot-starter 是一个非常实用的组件,它为我们在多数据源场景下提供了便捷的解决方案。在上一篇文章《一分钟上手:如何创建你的第一个 Spring Boot Starter》中,我们学习了如何创…...

[NewStarCTF 2023 公开赛道]ez_sql1 【sqlmap使用/大小写绕过】
题目: 发现id处可以sql注入: 虽然输入id1;show databases;#没什么回显,但是知道这里是字符型注入了 这次利用sqlmap注入 --dbs:列出所有数据库名字 python .\sqlmap.py -u http://a40b2f0a-823f-4c99-b43c-08b94ed0abb2.node5.…...
】后台管理系统基础搭建:从0到1构建电商中枢)
【商城实战(18)】后台管理系统基础搭建:从0到1构建电商中枢
【商城实战】专栏重磅来袭!这是一份专为开发者与电商从业者打造的超详细指南。从项目基础搭建,运用 uniapp、Element Plus、SpringBoot 搭建商城框架,到用户、商品、订单等核心模块开发,再到性能优化、安全加固、多端适配…...

新能源汽车充电综合解决方案:安科瑞电气助力绿色出行
安科瑞 华楠 18706163979 随着新能源汽车的迅猛发展,充电基础设施的建设成为了推动行业进步的关键。然而,充电技术滞后、运营效率低下、车桩比失衡等问题,依然困扰着广大车主和运营商。今天,我们要为大家介绍一款新能源汽车充电…...

蓝桥杯java-B组真题—动态规划
目录 一.什么是动态规划? 二.题目 第一种情况:集合本身之和为奇数 第二种情况:集合本身之和为偶数 下面是代码实现: 一.什么是动态规划? 这里就简单的解释一下,动态规划就是记录之前的计算结果,避免重复的计算之前已经计算过的结果,用…...

【网络编程】事件选择模型
十、基于I/O模型的网络开发 10.9 事件选择模型 10.0.1 基本概念 事件选择(WSAEventSelect) 模型是另一个有用的异步 I/O 模型。和 WSAAsyncSelect 模 型类似的是,它也允许应用程序在一个或多个套接字上接收以事件为基础的网络事件通知,最 主要的差别在…...

网易邮箱如何用大数据任务调度实现海量邮件数据处理?Apache DolphinScheduler用户交流会上来揭秘!
你是否对大数据领域的前沿应用充满好奇?网易邮箱作为互联网大厂网易的重要业务线,在大数据应用方面有着诸多值得借鉴的实践经验。你是否渴望深入了解网易邮箱如何借助 Apache DolphinScheduler 实现海量邮件数据处理、用户行为分析、实时监控等核心业务场…...

前端知识点---路由模式-实例模式和单例模式(ts)
在 ArkTS(Ark UI 框架)中,路由实例模式(Standard Instance Mode)主要用于管理页面跳转。当创建一个新页面时,可以选择标准实例模式(Standard Mode)或单实例模式(Single M…...

固定表头、首列 —— uniapp、vue 项目
项目实地:也可以在 【微信小程序】搜索体验:xny.handbook 另一个体验项目:官网 一、效果展示 二、代码展示 (1)html 部分 <view class"table"><view class"tr"><view class&quo…...

langchain系列(九)- LangGraph 子图详解
目录 一、导读 二、原理说明 1、简介 2、子图图示 3、使用说明 三、基础代码实现 1、实现功能 2、Graph 图示 3、代码实现 4、输出 5、分析 四、人机交互 1、实现中断 2、历史状态(父图) 3、历史状态(子图) 4、历史…...

搜索引擎是如何理解你的查询并提供精准结果的?
目录 一、搜索引擎简单介绍 二、搜索引擎整体架构和工作过程 (一)整体分析 (二)爬虫系统 三个基本点 爬虫系统的工作流程 关键考虑因素和挑战 (三)索引系统 网页处理阶段 预处理阶段 反作弊分析…...

【前端】【组件】【vue2】封装一个vue2的ECharts组件,不用借助vue-echarts
在Vue2项目中使用ECharts 5.6的完整实现步骤如下: 安装依赖 npm install echarts5.6.2 --save # 指定安装5.x最新版本基础组件实现(新建components/ECharts.vue) <template><div ref"chartDom" class"echarts-co…...

18天 - 常见的 HTTP 状态码有哪些?HTTP 请求包含哪些内容,请求头和请求体有哪些类型?HTTP 中 GET 和 POST 的区别是什么?
常见的 HTTP 状态码有哪些? HTTP 状态码用于指示服务器对客户端请求的响应结果,常见的 HTTP 状态码可以分为以下几类: 1. 信息类(1xx) 100 Continue:客户端应继续发送请求。101 Switching Protocols&…...

IDEA软件安装环境配置中文插件
一、Java环境配置 1. JDK安装8 访问Oracle官网下载JDK8(推荐JDK8,11)Java Downloads | Oracle 双击安装程序,保持默认设置连续点击"下一步"完成安装 验证JDK安装,winR键 然后输入cmd,输入java…...