Python----数据可视化(Seaborn二:绘图一)
常见方法
barplot方法 单独绘制条形图
catplot方法 可以条形图、散点图、盒图、小提亲图、等
countplot方法 统计数量
一、柱状图
seaborn.barplot(data=None, x=None, y=None, hue=None, color=None, palette=None)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| color | 用于变量的不同级别的颜色。应该 可以是可以解释的 ,或者是 字典将色调级别映射到 matplotlib 颜色。 |
| palette | 用于绘制填充颜色的原始饱和度的比例。大 面片通常使用不饱和的颜色看起来更好,但如果您希望颜色与输入值完美匹配,请将其设置为。1 |
1.1、常规柱状图
import seaborn as sns
import pandas as pd
# 示例数据
tips=pd.read_csv('tips.csv')
# 单变量柱状图
sns.barplot(x="day", y="total_bill", data=tips)
# 显示图表
plt.show()
1.2、横向条形图
import seaborn as sns
import pandas as pd
# 示例数据
tips=pd.read_csv('tips.csv')
# 单变量柱状图
sns.barplot(x="total_bill", y="day", data=tips)
# 显示图表
plt.show()
1.3、分组条图
import seaborn as sns
import pandas as pd
# 示例数据
tips=pd.read_csv('tips.csv')
import seaborn as sns
# 分组柱状图
sns.barplot(x="day", y="total_bill", hue="sex", data=tips)
# 显示图表
plt.show()
1.4、设置颜色
import seaborn as sns
# 示例数据
tips=pd.read_csv('tips.csv')
# 设置颜色
sns.barplot(x="day", y="total_bill", data=tips,color='salmon')
sns.barplot(x="day", y="total_bill", hue="sex", data=tips,palette='dark:salmon')
# 显示图表
plt.show()

1.5、 统计数量
seaborn.countplot(data=None, *, x=None, y=None, hue=None, color=None, palette=None)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| color | 用于变量的不同级别的颜色。应该 可以是可以解释的 ,或者是 字典将色调级别映射到 matplotlib 颜色。 |
| palette | 用于绘制填充颜色的原始饱和度的比例。大 面片通常使用不饱和的颜色看起来更好,但如果您希望颜色与输入值完美匹配,请将其设置为。1 |
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd tips = pd.read_csv('tips.csv') # 通过按天数对数据进行分组并计数
# display(tips.groupby('day').count()) # 使用ountplot 方法绘制当天小费数量的条形图
sns.countplot(x="day", data=tips) # 显示绘制的图形
plt.show()
二、直方图
方法
-
histplot方法 绘制单变量或双变量直方图来显示数据集的分布
-
displot方法 绘制直方图、核密度图。可以比较多个变量分布情况
seaborn.histplot(data=None,x=None, y=None, hue=None, bins='auto',multiple='layer', element='bars', kde=False, palette=None,color=None)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| color | 用于变量的不同级别的颜色。应该 可以是可以解释的 ,或者是 字典将色调级别映射到 matplotlib 颜色。 |
| palette | 用于绘制填充颜色的原始饱和度的比例。大 面片通常使用不饱和的颜色看起来更好,但如果您希望颜色与输入值完美匹配,请将其设置为。1 |
| bins | 通用 bin 参数,可以是引用规则的名称, 分箱数或分箱的分隔线。 |
| multiple | 语义映射创建子集时解析多个元素的方法。 仅与单变量数据相关。 {“layer”, “减淡”, “stack”, “fill”} |
| elment | 直方图统计量的可视化表示形式。 仅与单变量数据相关。 {“bars”, “step”, “poly”} |
seaborn.displot(data=None, *, x=None, y=None, hue=None, row=None, col=None, weights=None, kind='hist', rug=False, rug_kws=None, log_scale=None, legend=True, palette=None, hue_order=None, hue_norm=None, color=None, col_wrap=None, row_order=None, col_order=None, height=5, aspect=1, facet_kws=None, **kwargs)| row | 定义子集以在不同 facet 上绘制的变量。 |
| col | 定义子集以在不同 facet 上绘制的变量。 |
2.1、常规直方图
sns.histplot(tips['total_bill']) 

sns.displot(tips['total_bill'])2.2、核密度估计
核密度估计的作用是用来估计概率密度函数的,它可以用来描述随机变量的密度分布
sns.histplot(tips['total_bill'],kde=True)
sns.displot(tips['total_bill'], kde=True)

2.3、多变量直方图
multiple='layer' # 默认值,以层叠的形式展示
multiple='dodge' # 以并列的形式展示
multiple='stack' # 以堆叠的形式展示
multiple='fill' # 以百分比堆叠的形式展示sns.histplot(x='total_bill', hue='sex', data=tips) 
sns.histplot(x='total_bill', hue='sex', data=tips, multiple='stack') 
sns.histplot(x='total_bill', hue='sex', data=tips, multiple='dodge') 
sns.histplot(x='total_bill', hue='sex', data=tips, multiple='fill') 
2.4、修改一些参数
sns.histplot(x='total_bill', data=tips, bins=20, color='skyblue', edgecolor='black', linewidth=1.2)
sns.displot(x='total_bill', data=tips, bins=20, color='skyblue', edgecolor='black', linewidth=1.2)


2.5、 累积直方图
sns.histplot(x='total_bill', data=tips, element='step')
sns.displot(x='total_bill', data=tips, element='step',col='time')

三、折线图
方法
-
lineplot方法 单独绘制折线图
-
relplot方法 绘制折线图、散点图
seaborn.lineplot(data=None, x=None, y=None, hue=None)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
seaborn.relplot(data=None, *, x=None, y=None, hue=None, row=None, col=None kind='scatter')| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| row | 定义子集以在不同 facet 上绘制的变量。 |
| col | 定义子集以在不同 facet 上绘制的变量。 |
| kind | 要绘制的情节类型,对应于 seaborn 关系情节。 选项包括 或 。"scatter""line" |
sns.lineplot(x=[1,2,3,4,5],y=[1,2,3,4,5])
sns.relplot(x=[1,2,3,4,5],y=[1,2,3,4,5],kind='line')
import seaborn as sns
# 示例数据
tips = pd.read_csv('tips.csv') sns.lineplot(x="day", y="total_bill", data=tips)
sns.relplot(x="day", y="total_bill", data=tips, kind='line')# 多变量折线图
sns.lineplot(x="day", y="total_bill", data=tips,hue='time')
sns.relplot(x="day", y="total_bill", data=tips,hue='time',kind='line')# 使用relplot绘制折线图
sns.relplot(x="day", y="total_bill", data=tips,kind='line',# 图像类型hue='sex',# 分类变量col='time') # 分图变量



四、散点图
方法
-
scatterplot方法 主要用于绘制两个数值变量之间的散点图
-
relplot方法 可以绘制多种类型的关系图,包括散点图
seaborn.scatterplot(data=None, x=None, y=None, hue=None)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
seaborn.relplot(data=None, *, x=None, y=None, hue=None, row=None, col=None kind='scatter')| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| row | 定义子集以在不同 facet 上绘制的变量。 |
| col | 定义子集以在不同 facet 上绘制的变量。 |
| kind | 要绘制的情节类型,对应于 seaborn 关系情节。 选项包括 或 。"scatter""line" |
import seaborn as sns# 加载数据
tips=pd.read_csv('tips.csv')
# 常规散点图
sns.scatterplot(data=tips,x='total_bill', y='tip')
sns.relplot( data=tips, x='total_bill', y='tip',kind='scatter')
# 多组散点图
sns.scatterplot(data=tips,x='total_bill', y='tip', hue='smoker')
sns.relplot(data=tips,x='total_bill', y='tip', hue='smoker')
# 多变量散点图
sns.relplot(data=tips,x='total_bill', y='tip', hue='smoker',col='time')



五、分散散点图
方法
-
stripplot方法 利用抖动功能绘制分类散点图,以减少过度绘图
-
swarmplot方法 绘制分类散点图,并将点调整为不重叠
-
catplot方法 可以绘制以上2种图,并且可以分图
seaborn.stripplot(data=None, *, x=None, y=None, hue=None,dodge=False)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| dodge | 当一个变量被赋值时,将其设置为 will 沿分类分隔不同色相级别的条带 轴并缩小分配给每个条带的空间量。否则 每个级别的点将绘制在同一条带中。 |
seaborn.swarmplot(data=None, *, x=None, y=None, hue=None,dodge=False)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| dodge | 当一个变量被赋值时,将其设置为 will 沿分类分隔不同色相级别的条带 轴并缩小分配给每个条带的空间量。否则 每个级别的点将绘制在同一条带中。 |
seaborn.catplot(data=None, *, x=None, y=None, hue=None, row=None, col=None, kind='strip')| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| row | 定义子集以在不同 facet 上绘制的变量。 |
| col | 定义子集以在不同 facet 上绘制的变量。 |
| kind | 要绘制的绘图类型对应于分类的名称 轴级绘图功能。选项有: “strip”, “swarm”, “box”, “violin”, “boxen”、“point”、“bar” 或 “count”。 |
import seaborn as sns
import pandas as pdtips=pd.read_csv('tips.csv')sns.catplot(y="total_bill", x="day", data=tips,hue='sex',dodge=True,marker="D",col='smoker')

sns.swarmplot(y="total_bill", x="day", data=tips,hue='sex',marker="v") 

sns.catplot(y="total_bill", x="day", data=tips,hue='sex',marker="v",col='smoker',kind='swarm')
六、盒图
方法
-
boxplot方法
-
catplot方法
seaborn.boxplot(data=None, *, x=None, y=None, hue=None,fill=True,width=0.8, gap=0,notch=False)| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| fill | 定义子集以在不同 facet 上绘制的变量。 |
| gap | 箱体间隔 |
| width | 箱体宽度 |
| notch | 箱体是否缺口 |
seaborn.catplot(data=None, *, x=None, y=None, hue=None, row=None, col=None, kind='strip')| 函数 | 描述 |
|---|---|
| data | 用于绘图的数据集。 |
| x | 用于绘制长格式数据的输入。 |
| y | 用于绘制长格式数据的输入。 |
| hue | 用于绘制长格式数据的输入。对原有的属性进行更加细致的分组 |
| row | 定义子集以在不同 facet 上绘制的变量。 |
| col | 定义子集以在不同 facet 上绘制的变量。 |
| kind | 要绘制的绘图类型对应于分类的名称 轴级绘图功能。选项有: “strip”, “swarm”, “box”, “violin”, “boxen”、“point”、“bar” 或 “count”。 |
import seaborn as sns
import pandas as pdtips = pd.read_csv('tips.csv')sns.boxplot(x="day", y="total_bill", data=tips,hue="smoker",fill=False, # 填充箱体,默认为Truegap=0.1, # 箱体间隔width=0.5, # 箱体宽度notch=True # 箱体是否缺口)
sns.catplot(x="day", y="total_bill", data=tips,kind="box",col="sex")
相关文章:
Python----数据可视化(Seaborn二:绘图一)
常见方法 barplot方法 单独绘制条形图 catplot方法 可以条形图、散点图、盒图、小提亲图、等 countplot方法 统计数量 一、柱状图 seaborn.barplot(dataNone, xNone, yNone, hueNone, colorNone, paletteNone) 函数描述data用于绘图的数据集。x用于绘制长格式数据的输入。…...

加速科技Flex10K-L测试机:以硬核创新重塑显示驱动芯片测试新标杆!
在2024年召开的世界显示产业创新发展大会上,加速科技自主研发的高密度显示驱动芯片测试设备Flex10K-L凭借其突破性技术创新,成功入选"十大创新技术(产品)"。作为国内显示驱动芯片测试领域的标杆性设备,Flex1…...

linux-文本处理命令(echo,cut,sort,uniq,wc,tr,grep)
echo 打印(标准输入输出命令) [rootlocalhost ~]# echo $HOSTNAME-----$引用变量 localhost [rootlocalhost ~]# echo "$HOSTNAME"----“”弱引用符(可以解释特殊含义的字符) localhost [rootlocalhost ~]# echo $HOSTN…...

DeepSeek私有化部署7:openEuler 24.03-LTS-SP1安装Open WebUI
Open WebUI是一个 Open WebUI 是一个可扩展的、功能丰富、用户友好的自托管 AI 平台,专为完全离线运行而设计。 它支持多种 LLM 运行环境,包括 Ollama 和 OpenAI 兼容的 API,并内置了用于 RAG 的推理引擎,是一个强大的 AI 部署解决…...

spring-boot-starter和spring-boot-starter-web的关联
maven的作用是方便jar包的管理,所以每一个依赖都是对应着相应的一个或者一些jar包,从网上看到很多对spring-boot-starter的描述就是“这是Spring Boot的核心启动器,包含了自动配置、日志和YAML。”没看太明白,所参与的项目上也一直…...

群晖DS223 Docker搭建为知笔记
群晖DS223 Docker搭建为知笔记,打造你的专属知识宝库 一、引言 在数字化信息爆炸的时代,笔记软件成为了我们管理知识、记录灵感的得力助手。为知笔记,作为一款专注于工作笔记和团队协作的云笔记产品,以其丰富的功能和便捷的使用体…...
NLP文本分析之依存句法分析(理论及技术实践)
引言 在自然语言处理(NLP)领域中,理解句子的语法结构是实现语义理解的基础。依存句法分析(Dependency Parsing) 作为句法分析的核心任务之一,通过揭示句子中词语之间的依存关系,为机器翻译、信…...

回溯-子集
78.子集 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。输入:整型数组 输出:二元列表 思路:利用二进制&…...

Nginx(基础安装+配置文件)
目录 一.Nginx基础 1.基础知识点 2.异步非阻塞机制 二.Nginx安装 2.1安装nginx3种方式 1.包管理工具安装(yum/apt) 2.本地包安装(rpm/dpkg) 3.源码编译安装 3.1 源码编译安装nginx流程(ubuntu) 1.…...

Cryptography 与 PyCryptodome 源码级解析
目录 Cryptography 与 PyCryptodome 源码级解析一、引言二、Cryptography 库源码解析2.1 Cryptography 库概述与设计理念2.2 核心模块与数据流分析2.2.1 目录结构与模块划分2.2.2 以 AES-GCM 模式为例的加解密实现2.2.3 源码示例解析2.3 错误处理与边界检测三、PyCryptodome 源…...

uni-app+vue3学习随笔
目录相关 static文件 编译器会把static目录中的内容整体复制到最终编译包内, 非 static 目录下的文件(vue组件、js、css 等)只有被引用时,才会被打包编译。 css、less/scss 等资源不要放在 static 目录下,建议这些…...

边缘计算的业务种类划分
Pcdn的业务可以根据不同的分类标准来划分 一、按线路类型划分 汇聚模式:一个地方有多条线路,业务种类较多。通常使用X86或X99主板组装的服务器,或各品牌的准系统服务器。收益通常比单线模式更高。 单线模式:一个地方只有一条线路&…...

prompt大师高效提示词解析
Prompt大师李继刚高效提示词示例解析 一、「汉语新解」提示词 核心结构 采用Lisp语言框架嵌套中文语义,通过(defun 新汉语老师 ()...)定义角色风格(融合奥斯卡王尔德、鲁迅的批判性语言),用(隐喻 (一针见血...))构建解释逻辑链。…...
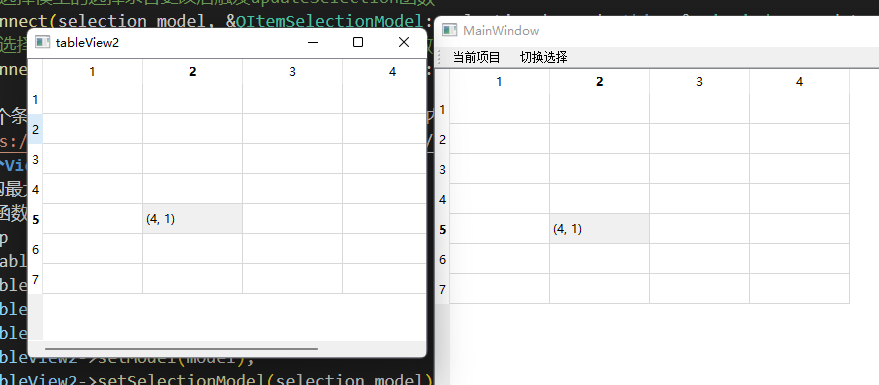
QT系列教程(18) MVC结构之QItemSelectionModel模型介绍
视频教程 https://www.bilibili.com/video/BV1FP4y1z75U/?vd_source8be9e83424c2ed2c9b2a3ed1d01385e9 QItemSelectionModel Qt的MVC结构支持多个View共享同一个model,包括该model的选中状态等。我们可以通过设置QItemSelectionModel,来更改View的选…...

【Java面试题汇总】Java面试100道最新合集!
1.说说你对面向对象的理解 得分点 封装,继承,多态、概念、实现方式和优缺点 面向对象的三大基本特征是:封装、继承、多态。 封装:将对象的状态和行为包装在一个类中并对外界隐藏实现的细节,可以通过访问修饰符控制成员的访问权限,…...

Vue 实现智能检测文字是否溢出,溢出显示省略号,鼠标悬浮显示全部【附封装组件完整代码+详细注释+粘贴即食】
一、场景需求 在项目中,经常会遇到文本内容超出容器的情况。为了提高用户体验,我希望在文字溢出时显示悬浮提示,未溢出时则不显示。 二、效果演示 三、实现原理 DOM宽度对比法:通过比较元素的scrollWidth(实际内容宽…...

51c大模型~合集10
我自己的原文哦~ https://blog.51cto.com/whaosoft/11547799 #Llama 3.1 美国太平洋时间 7 月 23 日,Meta 公司发布了其最新的 AI 模型 Llama 3.1,这是一个里程碑时刻。Llama 3.1 的发布让我们看到了开源 LLM 有与闭源 LLM 一较高下的能力。 Meta …...

为什么要使用前缀索引,以及建立前缀索引:sql示例
背景: 你想啊,数据库里有些字段,它老长了,就像那种 varchar(255) 的字段,这玩意儿要是整个字段都拿来建索引,那可太占地方了。打个比方,这就好比你要在一个超级大的笔记本上记东西,每…...
关于C/C++语言的初学者在哪刷题,怎么刷题
引言: 这篇博客主要是针对初学者关于怎么在网上刷题,以及在哪里刷题。 1.介绍平台(在哪刷题): 1.牛客牛客网https://www.nowcoder.com/ :有许多面试题,也有许多供学习者练习的题 2.洛谷洛谷 …...

AI自动化编程初探
先说vscodeclinemodelscope方案,后面体验trae或者cursor再写写其它的。vscode和trae方案目前来说是免费的,cursor要用claud需要付费,而且不便宜,当然效果可能是最好的。 vscode方案,我的经验是最好在ubuntu上ÿ…...

《人月神话》:软件工程的成本寓言与生存法则
1975年,Fred Brooks在《人月神话》中写下那句振聋发聩的断言——“向进度落后的项目增加人力,只会让进度更加落后”——时,他或许未曾料到,这一观点会在半个世纪后的人工智能与云原生时代,依然如达摩克利斯之剑般悬在每…...

深入理解Java中的static关键字及其内存原理
static是Java中实现类级共享资源的核心修饰符,它突破了对象实例化的限制,使得变量和方法能够直接与类本身绑定。这种特性让static成为构建工具类、全局配置等场景的利器,但同时也带来独特的内存管理机制需要开发者关注。 static修饰成员变量…...

Nest.js全栈开发终极实践:TypeORM+微服务+Docker构建高可用企业级应用
文章目录 **第一部分:认识Nest.js与基础环境搭建****1.1 什么是Nest.js?****1.2 环境准备****1.3 创建第一个项目****1.4 启动开发服务器****1.5 核心文件解读** **第二部分:基础控制器与路由****2.1 控制器的作用****2.2 创建自定义控制器**…...

20250310-组件基础2
通过插槽来分配内容 一些情况下我们会希望能和 HTML 元素一样向组件中传递内容: <AlertBox>传入的内容 </AlertBox> 我们期望能渲染成这样: 这可以通过 Vue 的自定义 <slot> 元素来实现: <template><div clas…...

Fedora41安装MySQL8.4.4
Fedora41安装MySQL8.4.4 Fedora41用yum仓库安装MySQL8.4.4 笔记250310下载安装启动mysqld服务查看生成的初始密码 , 用初始密码登录登录后,必须修改初始密码才能执行其它操作可选设置降低密码强度要求, 使用简单密码降低 validate_password 组件对密码强度的要求 用SET GLOBAL命…...

基于YOLO11深度学习的运动品牌LOGO检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...
-多项选择任务(MultipleChoice)训练与推理模板)
NLP常见任务专题介绍(2)-多项选择任务(MultipleChoice)训练与推理模板
一、 使用 BigBird 进行多项选择任务训练与推理 本示例展示如何使用 BigBirdForMultipleChoice 训练一个多项选择模型,适用于考试答题、阅读理解、常识推理等任务。 1️⃣ 任务描述 目标:给定一个问题和多个选项,模型预测正确答案。 数据格式:输入包含 (问题, 选项1, 选项…...

java BCC异或校验例子
需求 对一个十六进制的字符串进行BCC校验 方法 private static String XORCheck(String rawMsg) {// 16进制字符串需要转成10进制数组进行校验,然后再返回16进制字符串用于与原来的字符匹配byte[] bytes HexDumpMsgFormat.hexStr2DesBytes(rawMsg);return BytesUt…...

Python第十六课:深度学习入门 | 神经网络解密
🎯 本节目标 理解生物神经元与人工神经网络的映射关系掌握激活函数与损失函数的核心作用使用Keras构建手写数字识别模型可视化神经网络的训练过程掌握防止过拟合的基础策略一、神经网络基础(大脑的数字化仿生) 1. 神经元对比 生物神经元人工神经元树突接收信号输入层接收特…...

若依-导出后端解析
针对若依框架微服务版本学习 若依导入导出功能的具体使用详见:后台手册 | RuoYi 1.导出逻辑: 导出文件的逻辑是先创建一个临时文件,等待前端请求下载结束后马上删除这个临时文件。但是有些下载插件,例如迅雷(他们是二…...